On the Geodesic Distance in Shapes K-means Clustering


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Geometrical Structures for a Manifold of Probability Distributions
Fisher–Rao Metric for Gaussian Densities
3. Clustering of Shapes
4. K-Means Clustering Algorithm
4.1. Type I Algorithm
- Initial step:Compute the variances of the k-th landmark coordinates , for .Randomly assign the n shapes, into G clusters, .For , calculate the cluster center with k-th component obtained as , where is the number of elements in the cluster and is the k-th coordinate of given by .
- Classification:For each shape , compute the distances to the G cluster centers .The generic distance between the shape and the cluster center is given by:where the distance d could be the distance induced from Fisher–Rao metric or the Wasserstein distance .Assign to cluster h that minimizes the distance:
- Renewal step:Compute the new cluster centers of the renewed clusters .The k-th component of the g-th cluster center is defined as .
- Repeat Steps 2 and 3 until convergence [22].
4.2. Type II Algorithm
- Initial step:Randomly assign the n shapes, into G clusters, .In each cluster, compute the variances of the k-th landmark coordinates , for and .Calculate the cluster center with k-th component obtained as for , where is the number of elements in the cluster and for .
- Classification:For each shape , compute the distances to the G cluster centers .The generic distance between the shape and the cluster center is given by:where the distance d could be the distance induced from Fisher–Rao metric or the Wasserstein distance .Assign to cluster h that minimizes the distance:
- Renewal step:Update the variances of the k-th landmark coordinates in each cluster by computing , for and for .Calculate the new cluster centers of the renewed clusters .The k-th component of the g-th cluster center is defined as .
- Repeat Steps 2 and 3 until convergence [22].
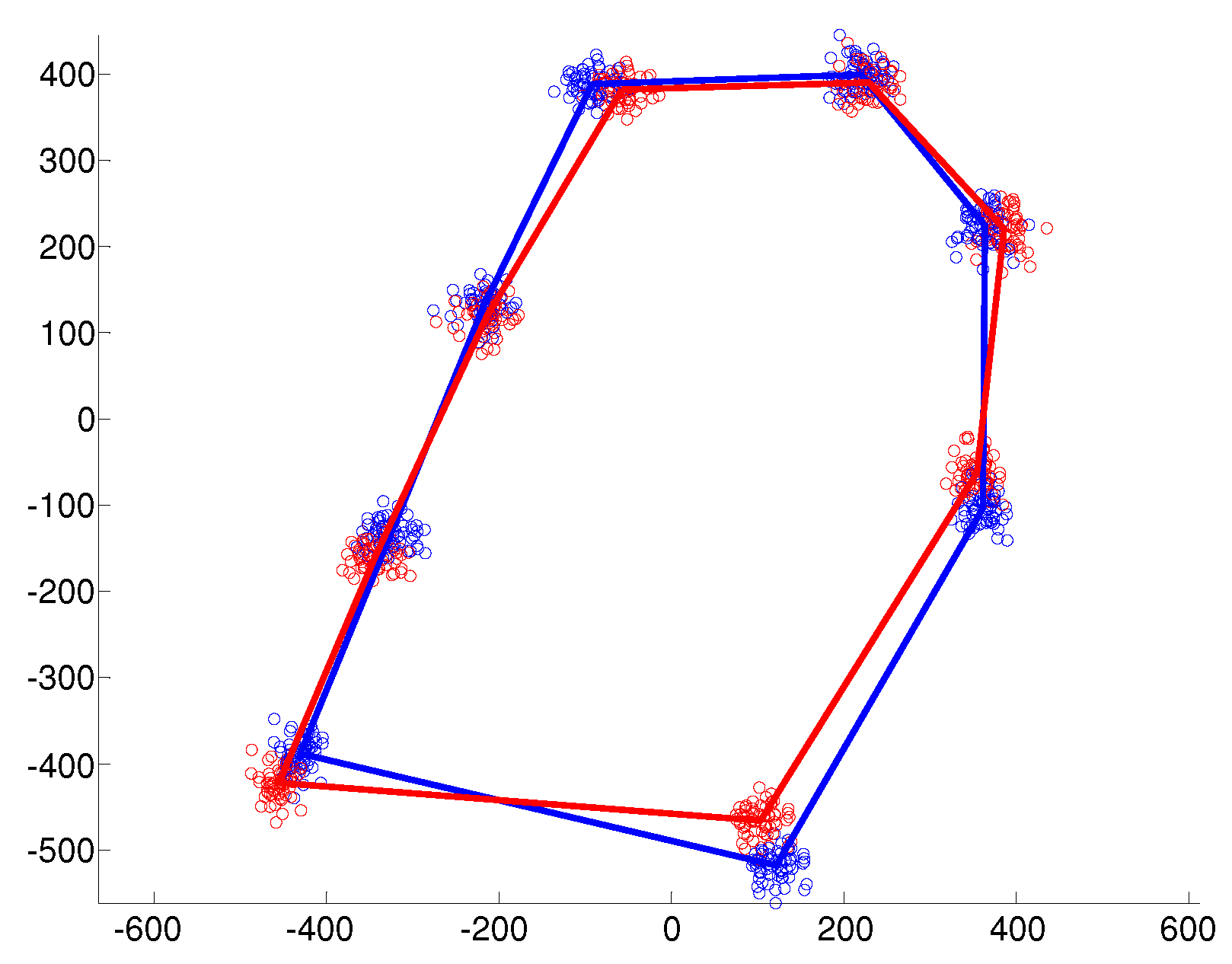
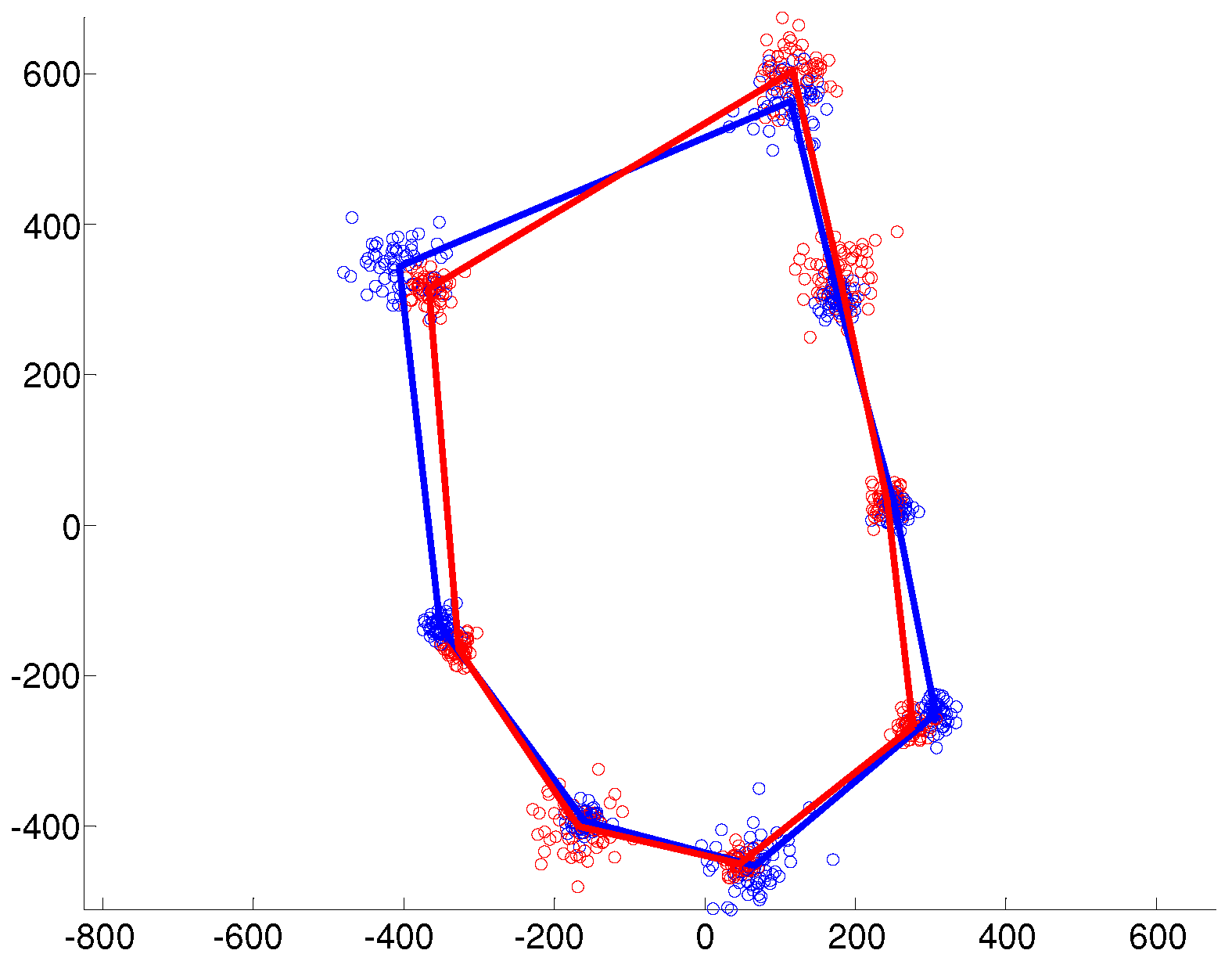
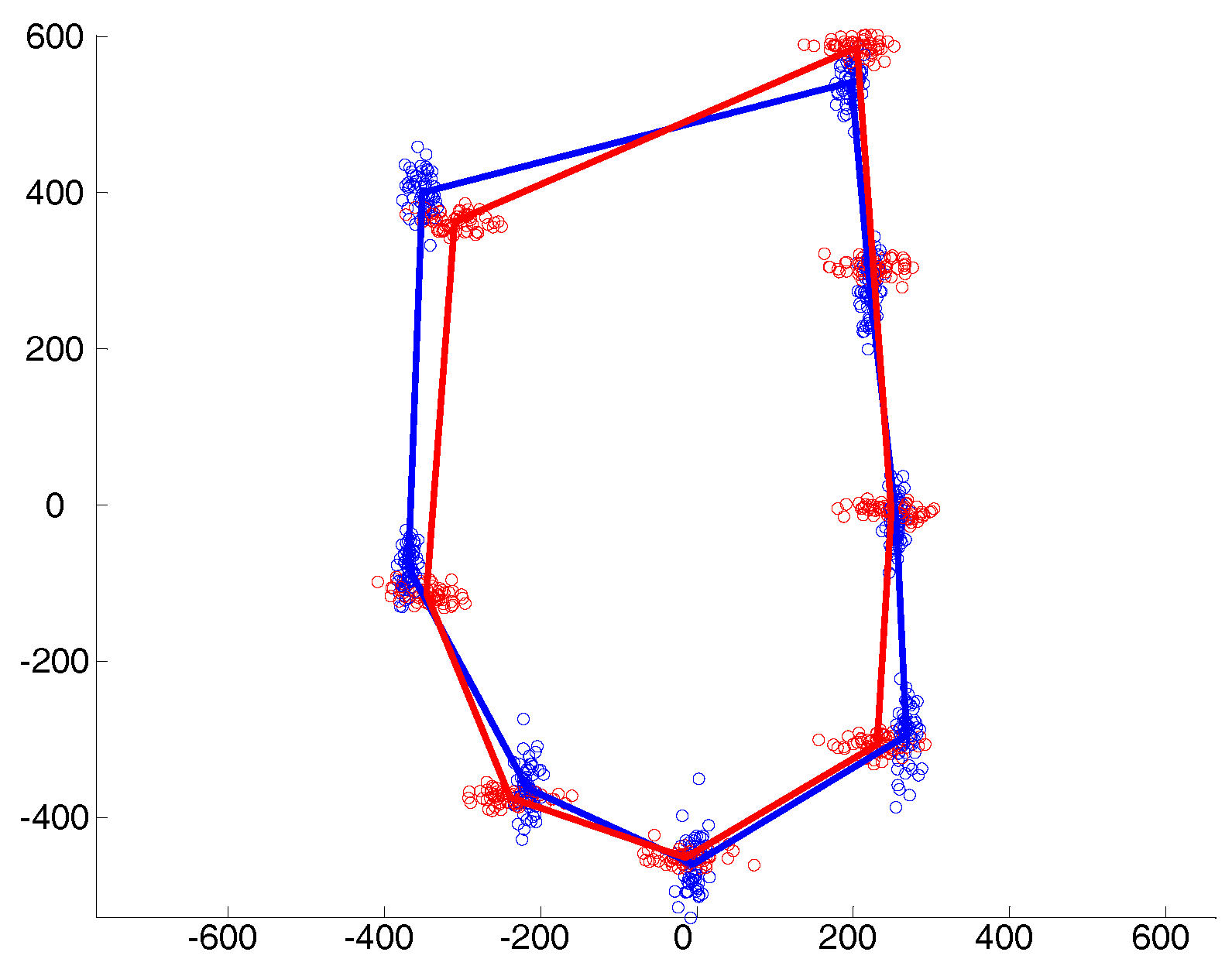
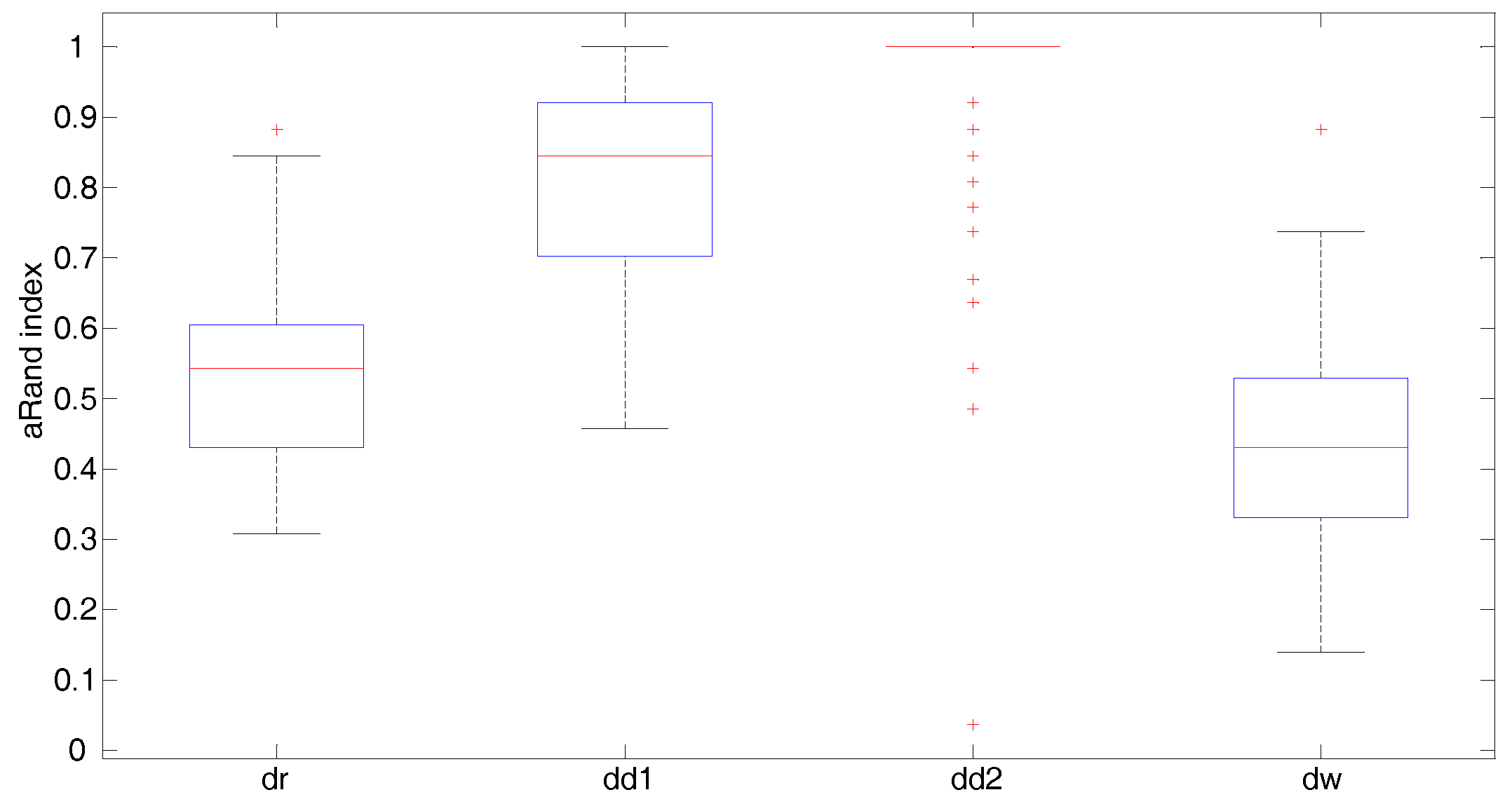
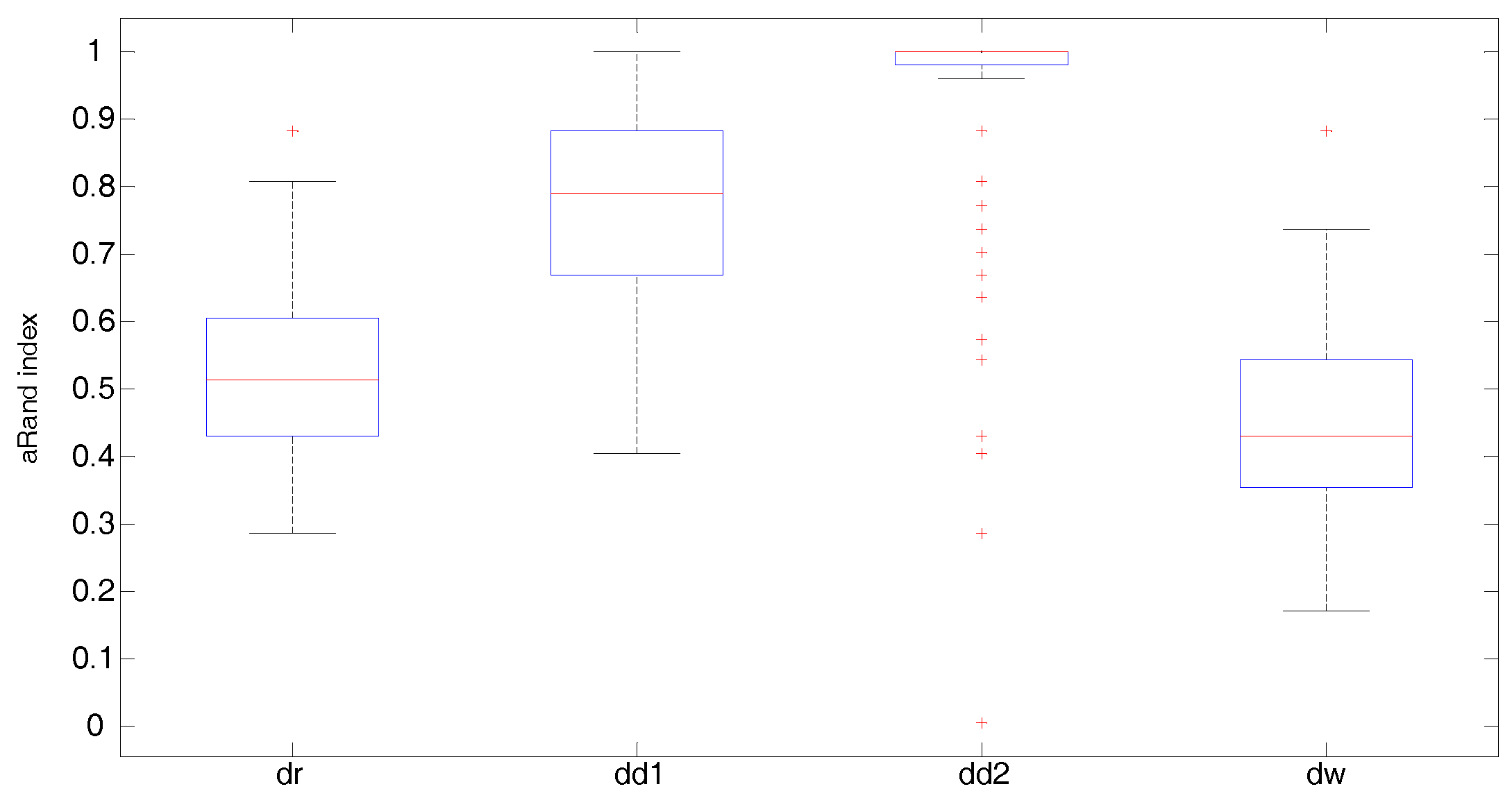
5. Numerical Study
- are zero mean random error matrices simulated from the multivariate Normal distribution with covariance structure ;
- is the mean shape for cluster g;
- is an orthogonal rotation matrix with an angle uniformly produced in the range ; and
- is a uniform translation vector in the range .
- Isotropic with
- Heteroscedastic with
- Anisotropic with with
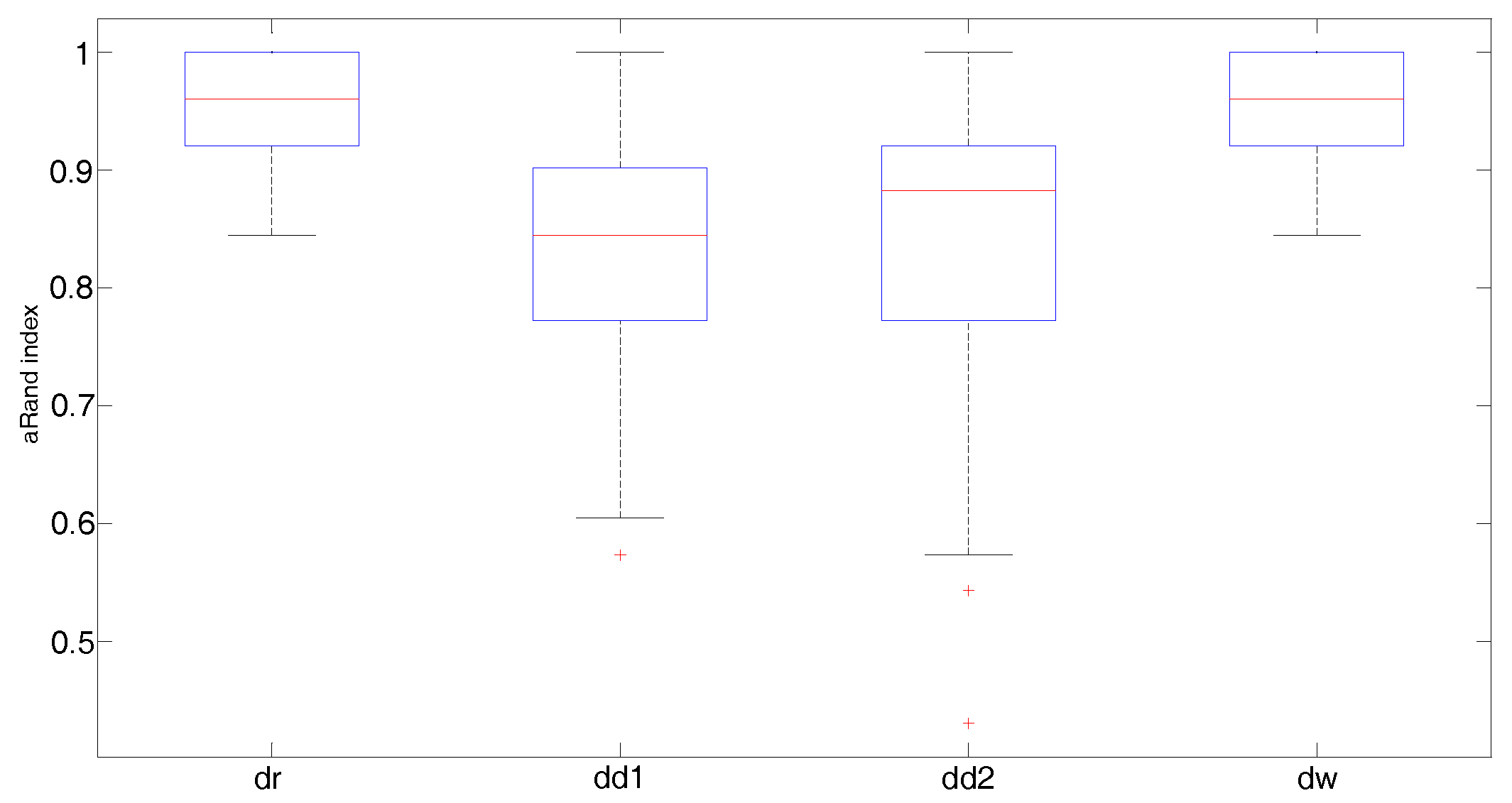
- The Fisher–Rao distance under the round Gaussian model representation (dr) where the variance is considered as a free parameter, which is isotropic across all the landmarks
- The Fisher–Rao distance under the diagonal Gaussian model representation (dd1 (Type I K-means algorithm) and dd2 (Type II K-means algorithm))
- Wasserstein distance (dp)
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bookstein, F.L. Morphometric Tools for Landmark Data: Geometry and Biology; Cambridge University Press: Cambridge, UK, 1991. [Google Scholar]
- Kendall, D.G. Shape manifolds, Procrustean metrics and complex projective spaces. Bull. Lond. Math. Soc. 1984, 16, 81–121. [Google Scholar] [CrossRef]
- Cootes, T.; Taylor, C.; Cooper, D.H.; Graham, J. Active shape models-their training and application. Comput. Vis. Image Underst. 1995, 61, 38–59. [Google Scholar] [CrossRef]
- Dryden, I.L.; Mardia, K.V. Statistical Shape Analysis; John Wiley & Sons: London, UK, 1998. [Google Scholar]
- Stoyan, D.; Stoyan, H. A further application of D.G. Kendall’s Procrustes Analysis. Biom. J. 1990, 32, 293–301. [Google Scholar] [CrossRef]
- Amaral, G.; Dore, L.; Lessa, R.; Stosic, B. K-means Algorithm in Statistical Shape Analysis. Commun. Stat. Simul. Comput. 2010, 39, 1016–1026. [Google Scholar] [CrossRef]
- Lele, S.; Richtsmeier, J. An Invariant Approach to Statistical Analysis of Shapes; Chapman & Hall/CRC: New York, NY, USA, 2001. [Google Scholar]
- Huang, C.; Martin, S.; Zhu, H. Clustering High-Dimensional Landmark-based Twodimensional Shape Data. J. Am. Stat. Assoc. 2015, 110, 946–961. [Google Scholar] [CrossRef] [PubMed]
- Kume, A.; Welling, M. Maximum likelihood estimation for the offset-normal shape distributions using EM. J. Comput. Gr. Stat. 2010, 19, 702–723. [Google Scholar] [CrossRef]
- Gattone, S.A.; De Sanctis, A.; Russo, T.; Pulcini, D. A shape distance based on the Fisher–Rao metric and its application for shapes clustering. Phys. A Stat. Mech. Appl. 2017, 487, 93–102. [Google Scholar] [CrossRef]
- De Sanctis, A.; Gattone, S.A. A Comparison between Wasserstein Distance and a Distance Induced by Fisher-Rao Metric in Complex Shapes Clustering. Proceedings 2018, 2, 163. [Google Scholar] [CrossRef]
- Amari, S.; Nagaoka, H. Translations of Mathematical Monographs. In Methods of Information Geometry; AMS & Oxford University Press: Providence, RI, USA, 2000. [Google Scholar]
- Murray, M.K.; Rice, J.W. Differential Geometry and Statistics; Chapman & Hall: London, UK, 1984. [Google Scholar]
- Srivastava, A.; Joshi, S.H.; Mio, W.; Liu, X. Statistical Shape analysis: Clustering, learning, and testing. IEEE Trans. PAMI 2005, 27, 590–602. [Google Scholar] [CrossRef] [PubMed]
- Mio, W.; Srivastava, A.; Joshi, S.H. On Shape of Plane Elastic Curves. Int. J. Comput. Vis. 2007, 73, 307–324. [Google Scholar] [CrossRef]
- Skovgaard, L.T. A Riemannian geometry of the multivariate normal model. Scand. J. Stat. 1984, 11, 211–223. [Google Scholar]
- Costa, S.; Santos, S.; Strapasson, J. Fisher information distance: A geometrical reading. Discret. Appl. Math. 2015, 197, 59–69. [Google Scholar] [CrossRef] [Green Version]
- Pennec, X.; Fillard, P.; Ayache, N. A Riemannian Framework for Tensor Computing. Int. J. Comput. Vis. 2006, 66, 41–66. [Google Scholar] [CrossRef] [Green Version]
- Bishop, R.L.; O’Neill, B. Manifolds of negative curvature. Trans. Am. Math. Soc. 1969, 145, 1–49. [Google Scholar] [CrossRef]
- Takatsu, A. Wasserstein geometry of Gaussian measures. Osaka J. Math. 2011, 48, 1005–1026. [Google Scholar]
- Amari, S. Applied Mathematical Sciences. In Information Geometry and Its Applications; Springer: Berlin, Germany, 2016. [Google Scholar]
- Banerjee, A.; Merugu, S.; Dhillon, I.; Ghosh, J. Clustering with Bregman Divergence. J. Mach. Learn. Res. 2005, 6, 1705–1749. [Google Scholar]
- Bookstein, F.L. Size and shape spaces for landmark data in two dimensions. Stat. Sci. 1986, 1, 181–242. [Google Scholar] [CrossRef]
- Goodall, C.R. Procrustes methods in the statistical analysis of shape. J. R. Stat. Soc. 1991, 53, 285–339. [Google Scholar]
- Hubert, L.; Arabie, P. Comparing Partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]






© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gattone, S.A.; De Sanctis, A.; Puechmorel, S.; Nicol, F. On the Geodesic Distance in Shapes K-means Clustering. Entropy 2018, 20, 647. https://doi.org/10.3390/e20090647
Gattone SA, De Sanctis A, Puechmorel S, Nicol F. On the Geodesic Distance in Shapes K-means Clustering. Entropy. 2018; 20(9):647. https://doi.org/10.3390/e20090647
Chicago/Turabian StyleGattone, Stefano Antonio, Angela De Sanctis, Stéphane Puechmorel, and Florence Nicol. 2018. "On the Geodesic Distance in Shapes K-means Clustering" Entropy 20, no. 9: 647. https://doi.org/10.3390/e20090647