
Entropy-Based Experimental Design for Optimal Model Discrimination in the Geosciences

Abstract
:1. Introduction
2. Methods
2.1. Bayesian Multi-Model Framework
2.2. Statistical Representation of Uncertainty in Model Choice
2.3. Preposterior Analysis for Model Choice Indicators
2.4. Formulation of OD for Model Choice
2.5. Alternative OD Formulations in the Presence of Model Choice Uncertainty
2.6. Limits on Mutual Information in Experimental Design for Model Choice
3. Application
- Sorption is often assumed to be a sufficiently fast mechanism compared to diffusion, so that sorbed concentrations and dissolved concentrations are always in local equilibrium. Then, sorption may be described by so-called sorption isotherms. There are many different sorption isotherm models available [6], and this is the uncertain model choice we are featuring here.
- Most sorption isotherms are parametric models. The corresponding inherent parametric uncertainty poses a nuisance in all model identification endeavors. Recognized ways to construct prior estimates for sorption parameters exist only for the so-called linear isotherm model. Prior estimates are based on the fraction of organic matter and other properties of the sorbent (here: clay) and on easily available literature values on the equilibrium of TCE between water and organic reference chemicals [91].
- There are further challenges: the molecular diffusion coefficients for dissolved chemicals in water are unclear in the literature [92,93,94]. Additionally, the effective diffusion in clay is reduced by two uncertain factors, which are the porosity and the tortuosity of the clay [95]. Porosity is the fraction of void space in the pores to a total volume of clay, and tortuosity measures the excess length of curvilinear paths through the porous medium relative to the straight paths along which transport processes can act in pure water.
- There are diverging literature values for the solubility of TCE in water [96,97]. Solubility dictates the maximum possible dissolved concentration that occurs when TCE dissolves from the pool into the underlying water-filled pores of the clay, and these concentrations are the driving force for diffusion and sorption.
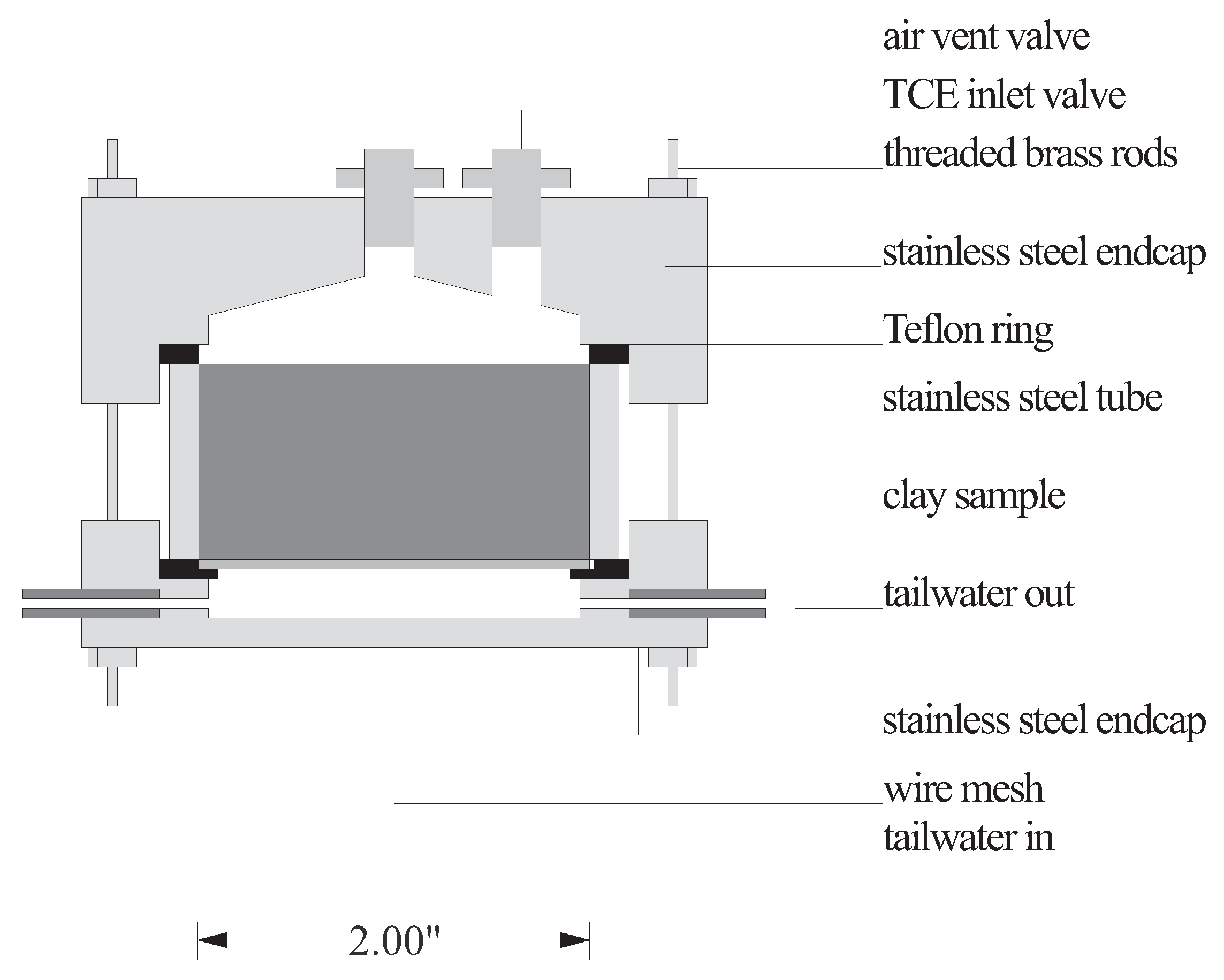
3.1. Experimental Setup and Sampling Design
3.2. Mathematical Model Formulation
3.3. Statistical Formulation
3.4. Formulation and Implementation of the Optimal Design Problem
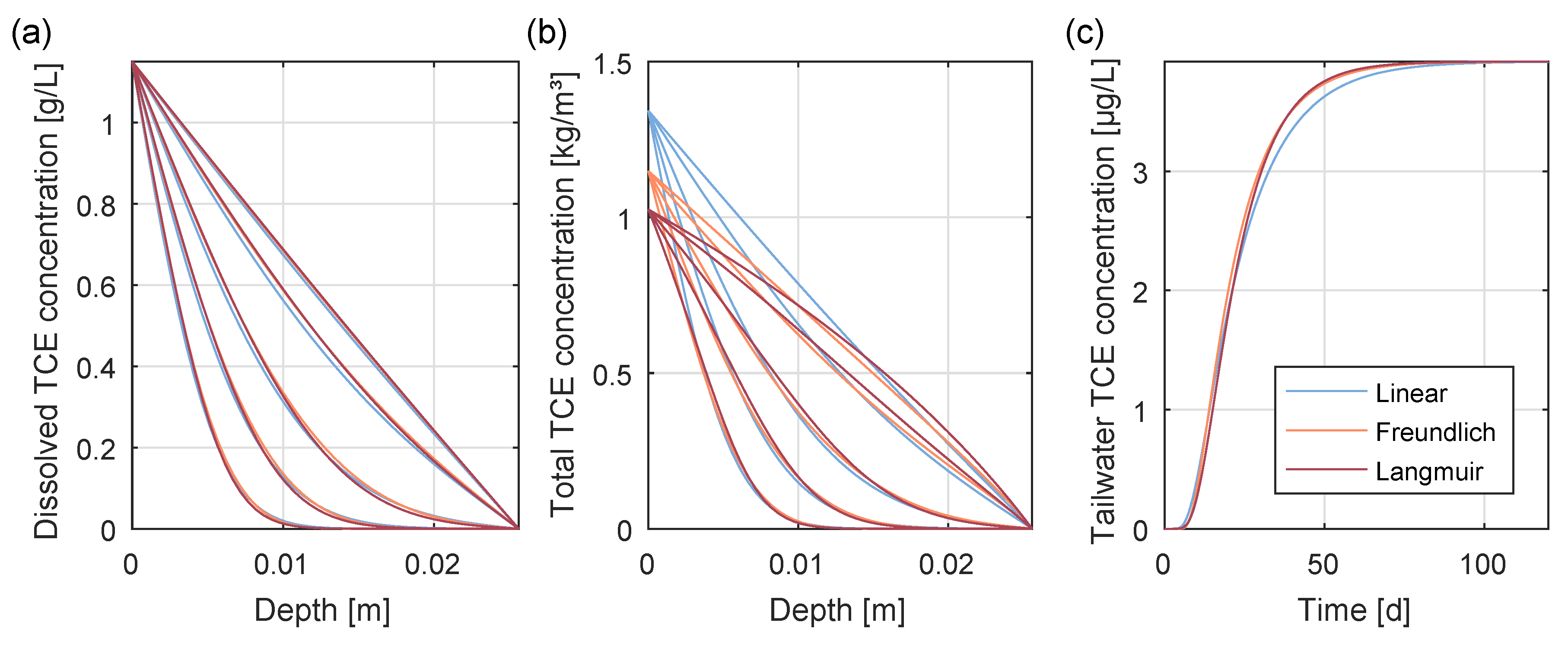
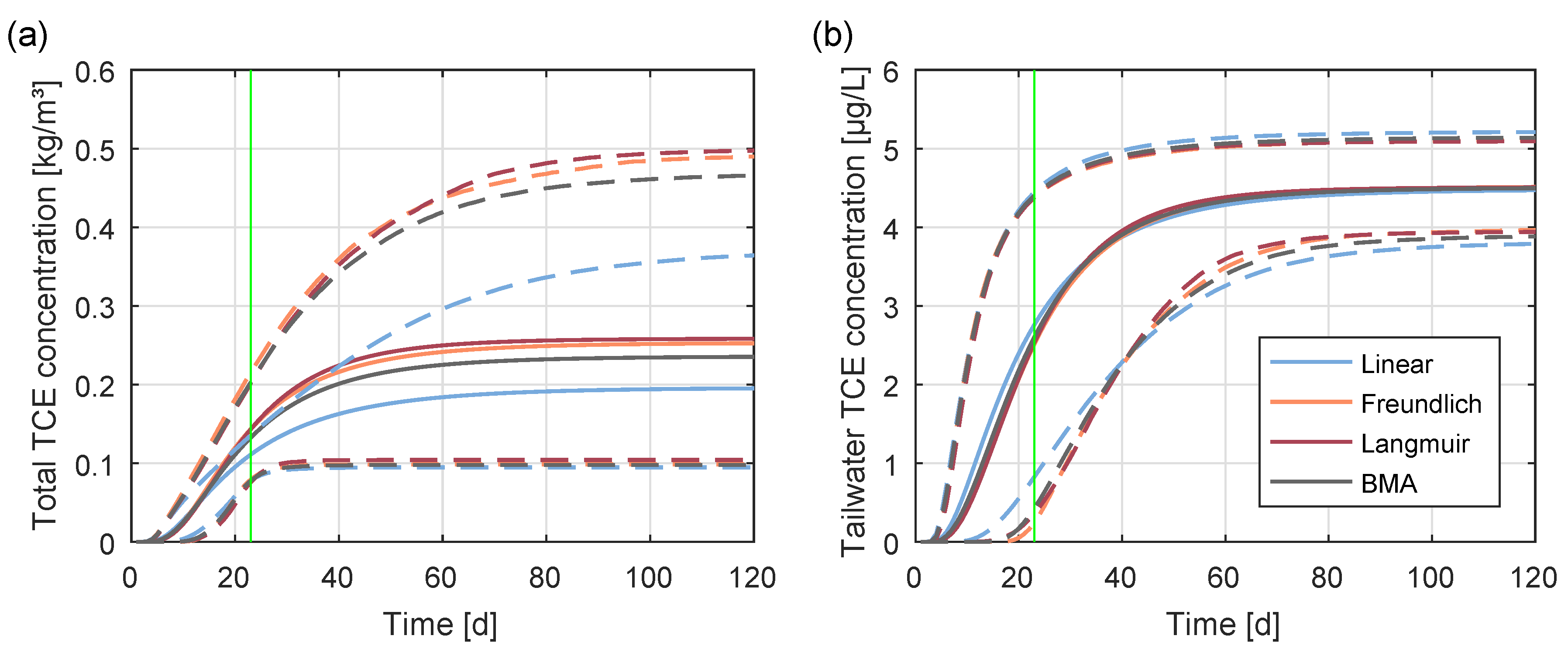
4. Results and Discussion
5. Summary and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| BMA | Bayesian model averaging |
| BME | Bayesian model evidence |
| BMS | Bayesian model selection |
| BTC | Breakthrough curve |
| DNAPL | Dense non-aqueous phase liquid |
| KL | Kullback–Leibler |
| MCMC | Monte Carlo Markov Chain |
| OD | Optimal experimental design |
| PreDIA | Preposterior Data Impact Assessor |
| TCE | Trichloroethylene |
Appendix A. Additional Considerations for the Statistical Formulation of the Case Study
- Per definition, we find that porosity , so that we choose the beta distribution. Multiple measurements of porosity for the specific clay formation analyzed in Nowak [70] indicate that . Based on sample statistics, we assign a credible interval of . The resulting parameters of the chosen parametric distribution for porosity (and also for all of the following quantities) are shown in Table 1.
- Densities are non-negative per definition. Thus, we choose a lognormal distribution for the solids density of the featured clay. The featured density is slightly higher than that of Quartz (with kg/m). Sample statistics indicate a modal value of kg/m and a credible interval of kg/m.
- Solubilities are upper bounds for concentrations and hence non-negative, leading us to the lognormal distribution. TCE solubility experiments with site-specific groundwater indicated a modal value of and a credible interval of .
- Molecular diffusion coefficients are once again non-negative quantities, so we again use the lognormal distribution. For TCE, the different values that can be found in literature suggest for us to choose a credible interval of m/s.
- The distribution of follows implicitly through Equation (25).
- The distribution for the partitioning coefficient in the linear isotherm follows from Equation (31); i.e., we need to define distributions for and .
- is a fraction in the interval , leading to the beta distribution. The available single datum is , with an estimated (by subjective expert opinion) coefficient of variation that is half of the measured value.
- is non-negative and hence lognormal. Schwarzenbach and Westall [104] provide a range of values that leads us to choose a credible interval of mL/kg.
Appendix B. Numerical Implementation of OD in the Case Study
References
- Winsberg, E. Simulated Experiments: Methodology for a Virtual World. Philos. Sci. 2003, 70, 105–125. [Google Scholar] [CrossRef]
- Beven, K.J. Uniqueness of place and process representations in hydrological modelling. Hydrol. Earth Syst. Sci. 2000, 4, 203–213. [Google Scholar] [CrossRef]
- Christie, M.A.; Blunt, M.J. Tenth SPE Comparative Solution Project: A Comparison of Upscaling Techniques. SPE Res. Eval. Eng. 2001, 4, 308–317. [Google Scholar]
- Oreskes, N.; Shrader-Frechette, K.; Belitz, K. Verification, validation, and confirmation of numerical models in the earth sciences. Science 1994, 263, 641–646. [Google Scholar] [CrossRef] [PubMed]
- Neuman, S.P.; Tartakovsky, D.M. Perspective on theories of non-Fickian transport in heterogeneous media. Adv. Water Resour. 2009, 32, 670–680. [Google Scholar] [CrossRef]
- Limousin, G.; Gaudet, J.P.; Charlet, L.; Szenknect, S.; Barthès, V.; Krimissa, M. Sorption isotherms: A review on physical bases, modeling and measurement. Appl. Geochem. 2007, 22, 249–275. [Google Scholar] [CrossRef]
- Wang, N.; Brennan, J.G. Moisture sorption isotherm characteristics of potatoes at four temperatures. J. Food Eng. 1991, 14, 269–287. [Google Scholar] [CrossRef]
- Joekar-Niasar, V.; Hassanizadeh, S.M.; Leijnse, A. Insights into the Relationships Among Capillary Pressure, Saturation, Interfacial Area and Relative Permeability Using Pore-Network Modeling. Transp. Porous Media 2008, 74, 201–219. [Google Scholar] [CrossRef]
- Lötgering-Lin, O.; Gross, J. Group Contribution Method for Viscosities Based on Entropy Scaling Using the Perturbed-Chain Polar Statistical Associating Fluid Theory. Ind. Eng. Chem. Res. 2015, 54, 7942–7952. [Google Scholar] [CrossRef]
- Beven, K. Causal models as multiple working hypotheses about environmental processes. C. R. Geosci. 2012, 344, 77–88. [Google Scholar] [CrossRef]
- Beven, K. Towards a coherent philosophy for modelling the environment. Proc. R. Soc. Lond. A Math. Phys. Eng. Sci. R. Soc. 2002, 458, 2465–2484. [Google Scholar] [CrossRef] [Green Version]
- Luis, S.J.; McLaughlin, D. Validation of Geo-hydrological Models: Part 1. A stochastic approach to model validation. Adv. Water Resour. 1992, 15, 15–32. [Google Scholar] [CrossRef]
- Walker, W.E.; Harremoës, P.; Rotmans, J.; van der Sluijs, J.P.; van Asselt, M.B.A.; Janssen, P.; Krayer von Krauss, M.P. Defining Uncertainty: A Conceptual Basis for Uncertainty Management in Model-Based Decision Support. Integr. Assess. 2003, 4, 5–17. [Google Scholar] [CrossRef]
- Bernardo, J.M.; Rueda, R. Bayesian Hypothesis Testing: a Reference Approach. Int. Stat. Rev. 2002, 70, 351–372. [Google Scholar] [CrossRef]
- Raftery, A.E. Bayesian Model Selection in Social Research. Sociol. Methodol. 1995, 25, 111–163. [Google Scholar] [CrossRef]
- Huelsenbeck, J.P.; Larget, B.; Alfaro, M.E. Bayesian Phylogenetic Model Selection Using Reversible Jump Markov Chain Monte Carlo. Mol. Biol. Evol. 2004, 21, 1123–1133. [Google Scholar] [CrossRef] [PubMed]
- Hoeting, J.A.; Madigan, D.; Raftery, A.E.; Volinsky, C.T. Bayesian model averaging: A tutorial. Stat. Sci. 1999, 14, 382–401. [Google Scholar]
- Najafi, M.R.; Moradkhani, H.; Jung, I.W. Assessing the uncertainties of hydrologic model selection in climate change impact studies. Hydrol. Proc. 2011, 25, 2814–2826. [Google Scholar] [CrossRef]
- Seifert, D.; Sonnenborg, T.O.; Refsgaard, J.C.; Højberg, A.L.; Troldborg, L. Assessment of hydrological model predictive ability given multiple conceptual geological models. Water Resour. Res. 2012, 48, W06503. [Google Scholar] [CrossRef]
- Tsai, F.T.C.; Elshall, A.S. Hierarchical Bayesian model averaging for hydrostratigraphic modeling: Uncertainty segregation and comparative evaluation. Water Resour. Res. 2013, 49, 5520–5536. [Google Scholar] [CrossRef]
- Rojas, R.; Feyen, L.; Dassargues, A. Conceptual model uncertainty in groundwater modeling: Combining generalized likelihood uncertainty estimation and Bayesian model averaging. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
- Troldborg, M.; Nowak, W.; Tuxen, N.; Bjerg, P.L.; Helmig, R.; Binning, P.J. Uncertainty evaluation of mass discharge estimates from a contaminated site using a fully Bayesian framework. Water Resour. Res. 2010, 46. [Google Scholar] [CrossRef]
- Ye, M.; Pohlmann, K.F.; Chapman, J.B.; Pohll, G.M.; Reeves, D.M. A model-averaging method for assessing groundwater conceptual model uncertainty. Ground Water 2010, 48, 716–728. [Google Scholar] [CrossRef] [PubMed]
- MacKay, D.J.C. Bayesian Interpolation. Neural Comput. 1992, 4, 415–447. [Google Scholar] [CrossRef]
- Neretnieks, I. Diffusion in the rock matrix: An important factor in radionuclide retardation? J. Geophys. Res. Solid Earth 1980, 85, 4379–4397. [Google Scholar] [CrossRef]
- Frster, A.; Norden, B.; Zinck-Jrgensen, K.; Frykman, P.; Kulenkampff, J.; Spangenberg, E.; Erzinger, J.; Zimmer, M.; Kopp, J.; Borm, G. Baseline characterization of the CO2SINK geological storage site at Ketzin, Germany. Environ. Geosci. 2006, 13, 145–161. [Google Scholar] [CrossRef]
- Pukelsheim, F.; Rosenberger, J.L. Experimental Designs for Model Discrimination. J. Am. Stat. Assoc. 1993, 88, 642–649. [Google Scholar] [CrossRef]
- Christakos, G. Random Field Models in Earth Sciences; Dover Publications, Inc.: Mineola, NY, USA, 2012. [Google Scholar]
- Fishburn, P.C. Utility Theory for Decision Making; Publications in Operations Research; Wiley: New York, NY, USA, 1970; Volume 18. [Google Scholar]
- Lindley, D.V. Bayesian Statistics: A Review; SIAM: Philadelphia, PA, USA, 1972. [Google Scholar]
- Abellan, A.; Noetinger, B. Optimizing subsurface field data acquisition using information theory. Math. Geosci. 2010, 42, 603–630. [Google Scholar] [CrossRef]
- Nowak, W.; de Barros, F.P.J.; Rubin, Y. Bayesian geostatistical design: Task-driven optimal site investigation when the geostatistical model is uncertain. Water Resour. Res. 2010, 46. [Google Scholar] [CrossRef]
- Kollat, J.B.; Reed, P.M.; Maxwell, R.M. Many-objective groundwater monitoring network design using bias-aware ensemble Kalman filtering, evolutionary optimization, and visual analytics. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- Freeze, R.A.; James, B.; Massmann, J.; Sperling, T.; Smith, L. Hydrogeological Decision-Analysis: 4. The Concept of Data Worth and Its Use in the Development of Site Investigation Strategies. Ground Water 1992, 30, 574–588. [Google Scholar] [CrossRef]
- James, B.R.; Gorelick, S.M. When Enough Is Enough: The Worth of Monitoring Data in Aquifer Remediation Design. Water Resour. Res. 1994, 30, 3499–3513. [Google Scholar] [CrossRef]
- Berger, J.O. Statistical Decision Theory and Bayesian Analysis; Springer Science & Business Media: New York, NY, USA, 2013. [Google Scholar]
- Box, G.E.; Tiao, G.C. Bayesian Inference in Statistical Analysis; John Wiley & Sons: New York, NY, USA, 2011; Volume 40. [Google Scholar]
- Chaloner, K.; Verdinelli, I. Bayesian experimental design: A review. Stat. Sci. 1995, 10, 273–304. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Entropy, relative entropy and mutual information. Elem. Inf. Theory 1991, 2, 1–55. [Google Scholar]
- Cirpka, O.A.; Burger, C.M.; Nowak, W.; Finkel, M. Uncertainty and data worth analysis for the hydraulic design of funnel-and-gate systems in heterogeneous aquifers. Water Resour. Res. 2004, 40. [Google Scholar] [CrossRef]
- Sciortino, A.; Harmon, T.C.; Yeh, W.W.G. Experimental design and model parameter estimation for locating a dissolving dense nonaqueous phase liquid pool in groundwater. Water Resour. Res. 2002, 38, 15-1–15-9. [Google Scholar] [CrossRef]
- Altmann-Dieses, A.E.; Schlöder, J.P.; Bock, H.G.; Richter, O. Optimal experimental design for parameter estimation in column outflow experiments. Water Resour. Res. 2002, 38, 4-1–4-11. [Google Scholar] [CrossRef]
- Vrugt, J.A.; Bouten, W.; Gupta, H.V.; Sorooshian, S. Toward improved identifiability of hydrologic model parameters: The information content of experimental data. Water Resour. Res. 2002, 38. [Google Scholar] [CrossRef]
- Müller, W.G. Collecting Spatial Data: Optimum Design of Experiments for Random Fields; Springer Science & Business Media: New York, NY, USA, 2007. [Google Scholar]
- McKinney, D.C.; Loucks, D.P. Network design for predicting groundwater contamination. Water Resour. Res. 1992, 28, 133–147. [Google Scholar] [CrossRef]
- Herrera, G.S.; Pinder, G.F. Space-time optimization of groundwater quality sampling networks. Water Resour. Res. 2005, 41. [Google Scholar] [CrossRef]
- Janssen, G.M.C.M.; Valstar, J.R.; van der Zee, S.E.A.T.M. Measurement network design including traveltime determinations to minimize model prediction uncertainty. Water Resour. Res. 2008, 44, W02405. [Google Scholar] [CrossRef]
- De Barros, F.P.J.; Ezzedine, S.; Rubin, Y. Impact of hydrogeological data on measures of uncertainty, site characterization and environmental performance metrics. Adv. Water Resour. 2012, 36, 51–63. [Google Scholar] [CrossRef]
- Neuman, S.P.; Xue, L.; Ye, M.; Lu, D. Bayesian analysis of data-worth considering model and parameter uncertainties. Adv. Water Resour. 2012, 36, 75–85. [Google Scholar] [CrossRef]
- Lu, D.; Ye, M.; Neuman, S.P.; Xue, L. Multimodel Bayesian analysis of data-worth applied to unsaturated fractured tuffs. Adv. Water Resour. 2012, 35, 69–82. [Google Scholar] [CrossRef]
- Parrish, M.A.; Moradkhani, H.; DeChant, C.M. Toward reduction of model uncertainty: Integration of Bayesian model averaging and data assimilation. Water Resour. Res. 2012, 48. [Google Scholar] [CrossRef]
- Xue, L.; Zhang, D.; Guadagnini, A.; Neuman, S.P. Multimodel Bayesian analysis of groundwater data worth. Water Resour. Res. 2014, 50, 8481–8496. [Google Scholar] [CrossRef]
- Atkinson, A.C. DT-optimum designs for model discrimination and parameter estimation. J. Stat. Plan. Inference 2008, 138, 56–64. [Google Scholar] [CrossRef]
- Wöhling, T.; Schöniger, A.; Gayler, S.; Nowak, W. Bayesian model averaging to explore the worth of data for soil-plant model selection and prediction. Water Resour. Res. 2015, 51, 2825–2846. [Google Scholar] [CrossRef]
- Atkinson, A.C.; Fedorov, V.V. Optimal design: Experiments for discriminating between several models. Biometrika 1975, 62, 289–303. [Google Scholar] [CrossRef]
- Hill, P.D.H. A Review of Experimental Design Procedures for Regression Model Discrimination. Technometrics 1978, 20, 15–21. [Google Scholar] [CrossRef]
- Box, G.E.P.; Hill, W.J. Discrimination among Mechanistic Models. Technometrics 1967, 9, 57–71. [Google Scholar] [CrossRef]
- Cavagnaro, D.R.; Myung, J.I.; Pitt, M.A.; Kujala, J.V. Adaptive Design Optimization: A Mutual Information-Based Approach to Model Discrimination in Cognitive Science. Neural Comput. 2010, 22, 887–905. [Google Scholar] [CrossRef] [PubMed]
- Drovandi, C.C.; McGree, J.M.; Pettitt, A.N. A Sequential Monte Carlo Algorithm to Incorporate Model Uncertainty in Bayesian Sequential Design. J. Comput. Graph. Stat. 2014, 23, 3–24. [Google Scholar] [CrossRef] [Green Version]
- Knopman, D.S.; Voss, C.I. Discrimination among one-dimensional models of solute transport in porous media: Implications for sampling design. Water Resour. Res. 1988, 24, 1859–1876. [Google Scholar] [CrossRef]
- Usunoff, E.; Carrera, J.; Mousavi, S.F. Validation of Geo-hydrological ModelsAn approach to the design of experiments for discriminating among alternative conceptual models. Adv. Water Resour. 1992, 15, 199–214. [Google Scholar] [CrossRef]
- Hunter, W.G.; Reiner, A.M. Designs for Discriminating Between Two Rival Models. Technometrics 1965, 7, 307–323. [Google Scholar] [CrossRef]
- Kikuchi, C.P.; Ferré, T.P.A.; Vrugt, J.A. On the optimal design of experiments for conceptual and predictive discrimination of hydrologic system models. Water Resour. Res. 2015, 51, 4454–4481. [Google Scholar] [CrossRef]
- Pham, H.V.; Tsai, F.T.C. Optimal observation network design for conceptual model discrimination and uncertainty reduction. Water Resour. Res. 2016, 52, 1245–1264. [Google Scholar] [CrossRef]
- Pham, H.V.; Tsai, F.T.C. Bayesian experimental design for identification of model propositions and conceptual model uncertainty reduction. Adv. Water Resour. 2015, 83, 148–159. [Google Scholar] [CrossRef]
- Clark, M.P.; Kavetski, D.; Fenicia, F. Pursuing the method of multiple working hypotheses for hydrological modeling. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- Alfonso, L.; Ridolfi, E.; Gaytan-Aguilar, S.; Napolitano, F.; Russo, F. Ensemble Entropy for Monitoring Network Design. Entropy 2014, 16, 1365–1375. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Leube, P.C.; Geiges, A.; Nowak, W. Bayesian assessment of the expected data impact on prediction confidence in optimal sampling design. Water Resour. Res. 2012, 48. [Google Scholar] [CrossRef]
- Nowak, W. Age Determination of a TCE Source Zone Using Solute Transport Profiles in an Underlying Clayey Aquitard. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2000. [Google Scholar]
- Draper, D. Assessment and Propagation of Model Uncertainty. J. R. Stat. Soc. Ser. B Methodol. 1995, 57, 45–97. [Google Scholar]
- Kass, R.E.; Raftery, A.E. Bayes Factors. J. Am. Stat. Assoc. 1995, 90, 773–795. [Google Scholar] [CrossRef]
- Gull, S.F. Bayesian inductive inference and maximum entropy. In Maximum Entropy and Bayesian Methods in Science and Engineering; Kluwer Academic Publishers: Dordrecht, The Netherlands; Boston, MA, USA; London, UK, 1988; Volume 1, pp. 53–74. [Google Scholar]
- Schöniger, A.; Wöhling, T.; Samaniego, L.; Nowak, W. Model selection on solid ground: Rigorous comparison of nine ways to evaluate Bayesian model evidence. Water Resour. Res. 2014, 50, 9484–9513. [Google Scholar] [CrossRef] [PubMed]
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Second International Symposium on Information Theory; Petrov, B.N., Csaki, F., Eds.; Akadémiai Kiadó: Budapest, Hungary, 1973; pp. 267–281. [Google Scholar]
- Neuman, S.P. Maximum likelihood Bayesian averaging of uncertain model predictions. Stoch. Environ. Res. Risk Assess. 2003, 17, 291–305. [Google Scholar] [CrossRef]
- Beck, J.; Yuen, K. Model Selection Using Response Measurements: Bayesian Probabilistic Approach. J. Eng. Mech. 2004, 130, 192–203. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the Dimension of a Model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Kadane, J.B.; Lazar, N.A. Methods and criteria for model selection. J. Am. Stat. Assoc. 2004, 99, 279–290. [Google Scholar] [CrossRef]
- Poeter, E.; Anderson, D. Multimodel Ranking and Inference in Ground Water Modeling. Ground Water 2005, 43, 597–605. [Google Scholar] [CrossRef] [PubMed]
- Ye, M.; Meyer, P.D.; Neuman, S.P. On model selection criteria in multimodel analysis. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
- Singh, A.; Mishra, S.; Ruskauff, G. Model Averaging Techniques for Quantifying Conceptual Model Uncertainty. Ground Water 2010, 48, 701–715. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Box, G.E.P. Choice of Response Surface Design and Alphabetic Optimality; Technical Report MRC-TSR-2333; Mathematics Research Center, University of Wisconsin-Madison: Madison, WI, USA, 1982. [Google Scholar]
- Raue, A.; Kreutz, C.; Maiwald, T.; Klingmuller, U.; Timmer, J. Addressing parameter identifiability by model-based experimentation. IET Syst. Biol. 2011, 5, 120–130. [Google Scholar] [CrossRef] [PubMed]
- Sun, N.Z. Inverse Problems in Groundwater Modeling; Theory and Applications of Transport in Porous Media; Springer: Dordrecht, The Netherlands, 1999. [Google Scholar]
- Schöniger, A.; Illman, W.A.; Wöhling, T.; Nowak, W. Finding the right balance between groundwater model complexity and experimental effort via Bayesian model selection. J. Hydrol. 2015, 531, 96–110. [Google Scholar] [CrossRef]
- Pankow, J.F.; Cherry, J.A. Dense Chlorinated Solvents and other DNAPLs in Groundwater: History, Behavior, and Remediation; Waterloo Press: Portland, OR, USA, 1996. [Google Scholar]
- Koch, J.; Nowak, W. Predicting DNAPL mass discharge and contaminated site longevity probabilities: Conceptual model and high-resolution stochastic simulation. Water Resour. Res. 2015, 51, 806–831. [Google Scholar] [CrossRef]
- Parker, B.L.; Cherry, J.A.; Chapman, S.W. Field study of TCE diffusion profiles below DNAPL to assess aquitard integrity. J. Contam. Hydrol. 2004, 74, 197–230. [Google Scholar] [CrossRef] [PubMed]
- Schwarzenbach, R.P.; Gschwend, P.M.; Imboden, D.M. Environmental Organic Chemistry; John Wiley & Sons: New York, NY, USA, 2005. [Google Scholar]
- Wilke, C.R.; Chang, P. Correlation of Diffusion Coefficients in Dilute Solutions. AIChE J. 1955, 1, 264–270. [Google Scholar] [CrossRef]
- Hayduk, W.; Laudie, H. Prediction of Diffusion-Coefficients for Nonelectrolytes in Dilute Aqueous-Solutions. AIChE J. 1974, 20, 611–615. [Google Scholar] [CrossRef]
- Worch, E. Eine neue Gleichung zur Berechnung von Diffusionskoeffizienten gelöster Stoffe. Vom Wasser 1993, 81, 289–297. [Google Scholar]
- Grathwohl, P. Diffusion in Natural Porous Media: Contaminant Transport, Sorption/Desorption and Dissolution Kinetics; Springer Science & Business Media: New York, NY, USA, 2012; Volume 1. [Google Scholar]
- Broholm, K.; Feenstra, S. Laboratory measurements of the aqueous solubility of mixtures of chlorinated solvents. Environ. Toxicol. Chem. 1995, 14, 9–15. [Google Scholar] [CrossRef]
- Grathwohl, P. Diffusion in Natural Porous Media, 1st ed.; Topics in Environmental Fluid Mechanics; Springer: New York, NY, USA, 1998; Volume 1. [Google Scholar]
- Helfferich, F.G. Theory of multicomponent, multiphase displacement in porous media. Soc. Pet. Eng. J. 1981, 21, 51–62. [Google Scholar] [CrossRef]
- Fetter, C.W.; Fetter, C. Contaminant Hydrogeology; Prentice Hall: New Jersey, NJ, USA, 1999; Volume 500. [Google Scholar]
- Allen-King, R.M.; Groenevelt, H.; James Warren, C.; Mackay, D.M. Non-linear chlorinated-solvent sorption in four aquitards. J. Contam. Hydrol. 1996, 22, 203–221. [Google Scholar] [CrossRef]
- Leube, P.C.; Nowak, W.; Schneider, G. Temporal moments revisited: Why there is no better way for physically based model reduction in time. Water Resour. Res. 2012, 48. [Google Scholar] [CrossRef]
- Chib, S.; Greenberg, E. Understanding the Metropolis-Hastings Algorithm. Am. Stat. 1995, 49, 327–335. [Google Scholar]
- Knopman, D.S.; Voss, C.I. Multiobjective sampling design for parameter estimation and model discrimination in groundwater solute transport. Water Resour. Res. 1989, 25, 2245–2258. [Google Scholar] [CrossRef]
- Schwarzenbach, R.; Westall, J. Sorption of hydrophobic trace organic compounds in groundwater systems. Water Sci. Technol. 1985, 17, 39–55. [Google Scholar]
- Smith, A.F.M.; Gelfand, A.E. Bayesian statistics without tears—A sampling resampling perspective. Am. Stat. 1992, 46, 84–88. [Google Scholar]
- Schöniger, A.; Wöhling, T.; Nowak, W. A Statistical Concept to Assess the Uncertainty in Bayesian Model Weights and its Impact on Model Ranking. Water Resour. Res. 2015, 51, 7524–7546. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Symbol | Units | Distribution | ||
|---|---|---|---|---|---|
| common parameters | |||||
| porosity | (−) | ||||
| density | (kg/m) | ||||
| solubility | (kg/m) | ||||
| molecular diffusion | (m/s) | ||||
| effective diffusion | (m/s) | follows from Equation (25) | |||
| linear isotherm | |||||
| organic carbon fraction | (−) | ||||
| organic carbon partitioning | (m/kg) | ||||
| Freundlich | |||||
| Freundlich exponent | (−) | follows from MCMC | |||
| Freundlich’s K | K | ((m/kg)) | follows from MCMC | ||
| Langmuir | |||||
| sorption capacity | (m/kg) | follows from MCMC | |||
| half-concentration | K | (kg/m) | follows from MCMC | ||
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nowak, W.; Guthke, A. Entropy-Based Experimental Design for Optimal Model Discrimination in the Geosciences. Entropy 2016, 18, 409. https://doi.org/10.3390/e18110409
Nowak W, Guthke A. Entropy-Based Experimental Design for Optimal Model Discrimination in the Geosciences. Entropy. 2016; 18(11):409. https://doi.org/10.3390/e18110409
Chicago/Turabian StyleNowak, Wolfgang, and Anneli Guthke. 2016. "Entropy-Based Experimental Design for Optimal Model Discrimination in the Geosciences" Entropy 18, no. 11: 409. https://doi.org/10.3390/e18110409