Information Properties of Boundary Line Models for N2O Emissions from Agricultural Soils

 , and
, and
Abstract
:1. Introduction
2. Models and Data
2.1. Boundary Line Models

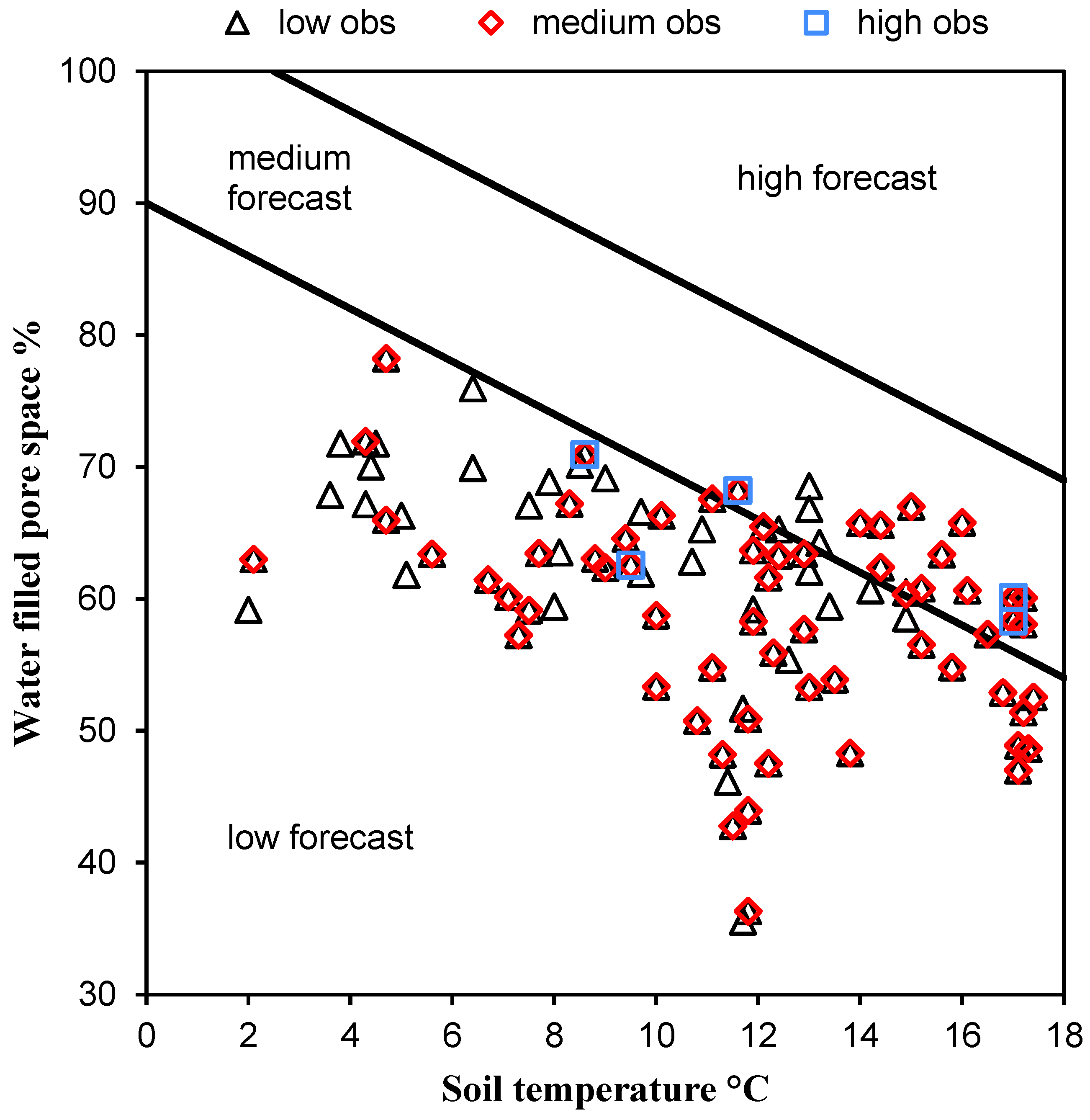
2.2. Data

{kind=link}
{kind=link}
{kind=link}
| Forecast category, fi | Observed category, oj | Row sums | ||
|---|---|---|---|---|
| 1. Low | 2. Medium | 3. High | ||
| 1. Low | 0.2841 | 0.0554 | 0.0074 | 0.3469 |
| 2. Medium | 0.1181 | 0.1513 | 0.0959 | 0.3653 |
| 3. High | 0.0480 | 0.0812 | 0.1587 | 0.2878 |
| Column sums | 0.4502 | 0.2878 | 0.2620 | 1.0000 |
3. Analysis of Information Properties
3.1. Information Content
3.2. Expected Mutual Information
3.2.1. The G2-test
3.2.2. Conditional Entropy
3.2.3. Normalized Mutual Information
3.3. Specific Information

3.4. Relative Entropy

3.5. A Second Data Set
| Forecast category, fi | Observed category, oj | Row sums | ||
|---|---|---|---|---|
| 1. Low | 2. Medium | 3. High | ||
| 1. Low | 0.7854 | 0.0324 | 0.0000 | 0.8178 |
| 2. Medium | 0.0972 | 0.0445 | 0.0040 | 0.1457 |
| 3. High | 0.0121 | 0.0202 | 0.0040 | 0.0364 |
| Column sums | 0.8947 | 0.0972 | 0.0081 | 1.0000 |
| Information quantity | Equation (boldface indicates equation used for calculation) | Value (nits) for pasture and sugarcane soils data (Table 1) | Value (nits) for cereal cropping soils data (Table 2) |
|---|---|---|---|
| H(O) | 1 | 1.0687 | 0.3650 |
| H(F) | 2 | 1.0936 | 0.5659 |
| H(O,F) | 3 | 1.9585 | 0.8430 |
| IM(O,F) | 4, 5, 6, 7, 12, 16, 17 | 0.2038 | 0.0879 |
| H(O|F) | Component of 6 | 0.8649 | 0.2772 |
| H(F|O) | Component of 7 | 0.8898 | 0.4780 |
| normalized IM(O,F) | 8 | 0.1907 | 0.2407 |
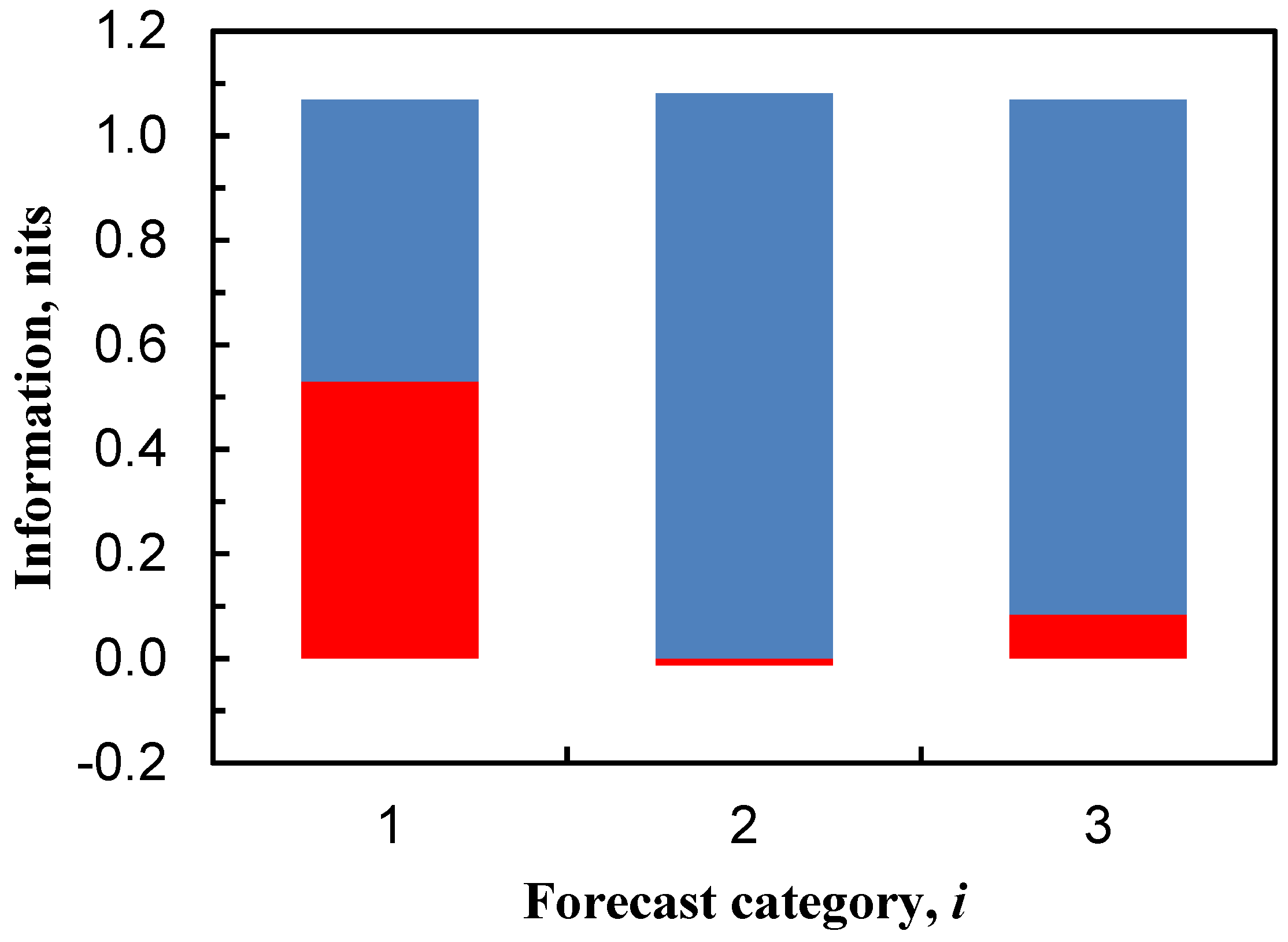
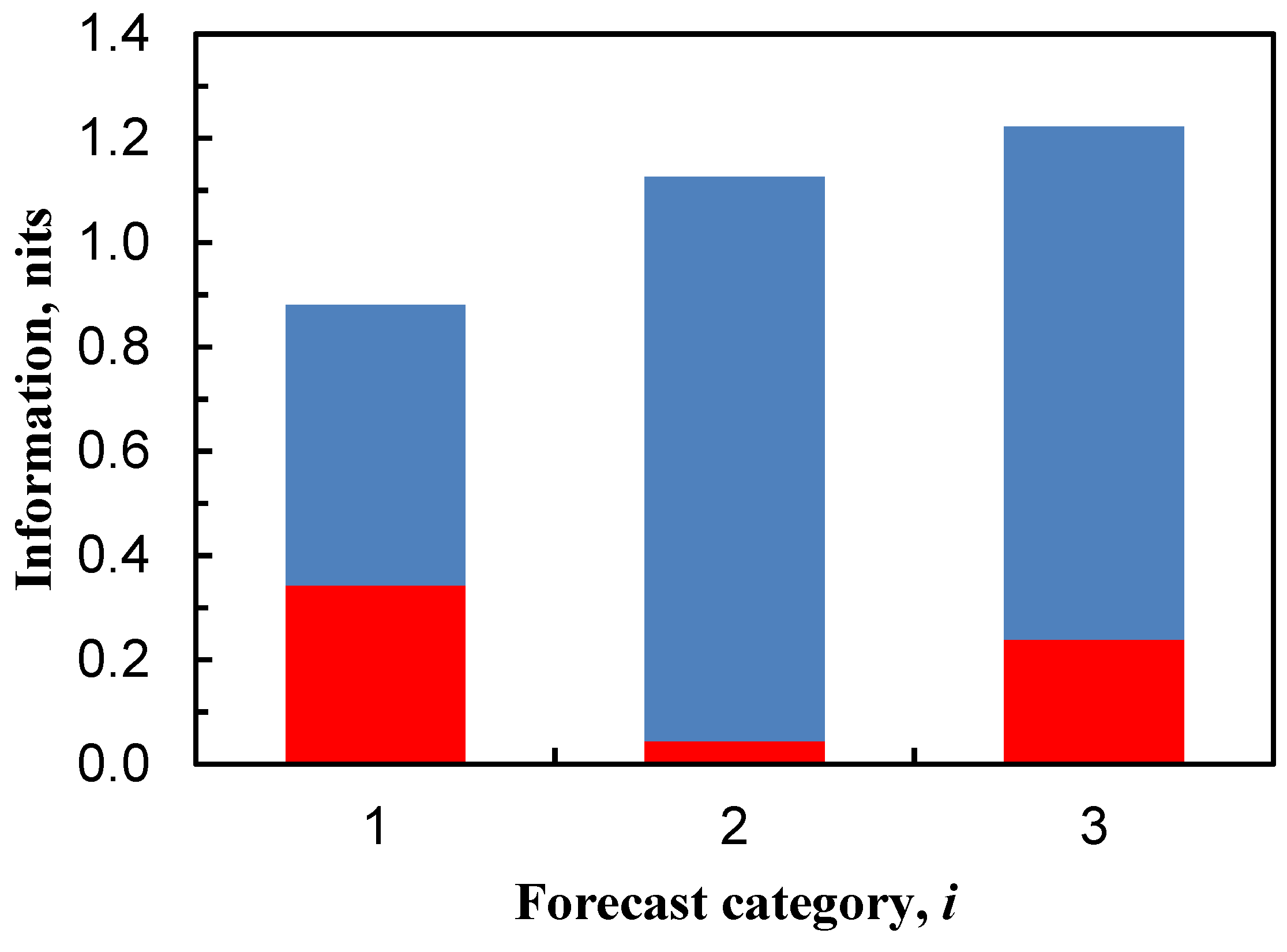
| H(O|f1) | 9 | 0.5382 a,b | 0.1667 |
| H(O|f2) | 9 | 1.0813 a,b | 0.7321 |
| H(O|f3) | 9 | 0.9839 a,b | 0.9369 |
| IS(f1) | 10, 11 | 0.5305 a | 0.1984 |
| IS(f2) | 10, 11 | −0.0126 a | −0.3671 |
| IS(f3) | 10, 11 | 0.0848 a | −0.5718 |
| I(f1) | 15 | 0.3428 b | 0.0325 |
| I(f2) | 15 | 0.0442 b | 0.1882 |
| I(f3) | 15 | 0.2388 b | 0.9305 |
4. Results and Discussion
- for cereal cropping soils, information properties of the three sub-region model largely depend on the prior (i.e., pre-forecast) probabilities Pr(o1) (≈0.9), Pr(o2) (≈0.1) and Pr(o3) (<0.01) of the observed N2O flux categories o1 (‘low’), o2 (‘medium’) and o3 (‘high’) respectively;
- for pasture and sugarcane soils, information properties of the three sub-region model indicate that observed N2O flux categories o1 (‘low’), o2 (‘medium’) and o3 (‘high’) are poorly distinguished in the f2 forecast category.
- Conen et al. [15] observed that “During most days of the year, emissions tend to be within the ‘low’ range, increasing to ‘medium’ or ‘high’ only after fertilizer applications, depending on soil temperature or WFPS limitations.”
- Recalling the data set from Figure 1, we note that as in [15], most emissions were in the ‘low’ observed range. The proportions of emissions in the ‘low’ (<10 g N2O-N ha−1 day−1), ‘medium’ (10-100 g N2O-N ha−1 day−1) and ‘high’ (>100 g N2O-N ha−1 day−1) observed ranges were ≈0.68, ≈0.30 and ≈0.02, respectively.
5. Conclusions
Acknowledgments
References
- Mosier, A.R.; Duxbury, J.M.; Freney, J.R.; Heinemeyer, O.; Minami, K. Assessing and mitigating N2O emissions from agricultural soils. Climatic Change 1998, 40, 7–38. [Google Scholar] [CrossRef]
- IPCC (Intergovernmental Panel on Climate Change). Greenhouse gas emissions from agricultural soils. In Revised 1996 IPCC Guidelines for National Greenhouse Gas Inventories, Volume 3, Greenhouse Gas Inventory Reference Manual; Houghton, J.T., Meira Filho, L.G., Lim, B., Treanton, K., Mamaty, I., Bonduki, Y., Griggs, D.J., Callender, B.A., Eds.; IPCC/OECD/IEA: UK Meteorological Office, Bracknell, UK, 1997. [Google Scholar]
- Bouwman, A.F. Direct emissions of nitrous oxide from agricultural soils. Nutr. Cycl. Agroecosys. 1996, 46, 53–70. [Google Scholar] [CrossRef]
- Bouwman, A.F.; Boumans, L.J.M.; Batjes, N.H. Emissions of N2O and NO from fertilized fields: Summary of available measurement data. Global Biogeochem. Cy. 2002, 16, 6.1–6.13. [Google Scholar] [CrossRef]
- Skiba, U.; Ball, B. The effect of soil texture and soil drainage on emissions of nitric oxide and nitrous oxide. Soil Use Manage. 2002, 18, 56–60. [Google Scholar] [CrossRef]
- Flechard, C.R.; Ambus, P.; Skiba, U.; Rees, R.M.; Hensen, A.; van Amstel, A.; van den Pol-van Dasselaar, A.V.; Soussana, J.-F.; Jones, M.; et al. Effects of climate and management intensity on nitrous oxide emissions in grassland systems across Europe. Agr. Ecosyst. Environ. 2007, 121, 135–152. [Google Scholar] [CrossRef]
- Abdalla, M.; Jones, M.; Williams, M. Simulation of N2O fluxes from Irish arable soils: effect of climate change and management. Biol. Fert. Soils 2010, 46, 247–260. [Google Scholar] [CrossRef]
- Hartmann, A.A.; Niklaus, P.A. Effects of simulated drought and nitrogen fertilizer on plant productivity and nitrous oxide (N2O) emissions of two pastures. Plant Soil 2012, 361, 411–426. [Google Scholar] [CrossRef]
- Rees, R.M. Global nitrous oxide emissions: sources and opportunities for mitigation. In Understanding Greenhouse Gas Emissions from Agricultural Management; Guo, L., Gunasekara, A.S., McConnell, L.L., Eds.; ACS Publications: Washington DC, USA, 2012; pp. 257–273. [Google Scholar]
- Lesschen, J.P.; Velthof, G.L.; de Vries, W.; Kros, J. Differentiation of nitrous oxide emission factors for agricultural soils. Environ. Pollut. 2011, 159, 3215–3222. [Google Scholar] [CrossRef] [PubMed]
- Pappa, V.A.; Rees, R.M.; Walker, R.L.; Baddeley, J.A.; Watson, C.A. Nitrous oxide emissions and nitrate leaching in an arable rotation resulting from the presence of an intercrop. Agr. Ecosyst. Environ. 2011, 141, 153–161. [Google Scholar] [CrossRef]
- Del Grosso, S.J.; Parton, W.J.; Mosier, A.R.; Ojima, D.S.; Kulmala, A.E.; Phongpan, S. General model for N2O and N2 gas emissions from soils due to dentrification. Global Biogeochem. Cy. 2000, 14, 1045–1060. [Google Scholar] [CrossRef]
- Li, C.S.; Frolking, S.; Frolking, T.A. A model of nitrous oxide evolution from soil driven by rainfall events: 1. Model structure and sensitivity. J. Geophys. Res. 1992, 97, 9759–9776. [Google Scholar] [CrossRef]
- Li, C.S.; Frolking, S.; Frolking, T.A. A model of nitrous oxide evolution from soil driven by rainfall events: 2. Model applications. J. Geophys. Res. 1992, 97, 9777–9783. [Google Scholar] [CrossRef]
- Conen, F.; Dobbie, K.E.; Smith, K.A. Predicting N2O emissions from agricultural land through related soil parameters. Global Change Biol. 2000, 6, 417–426. [Google Scholar] [CrossRef]
- Wang, W.; Dalal, R. Assessment of the boundary line approach for predicting N2O emission ranges from Australian agricultural soils. In Proceedings of the 19th World Congress of Soil Science: Soil Solutions for a Changing World, Brisbane, Australia, 1–6 August 2010; Gilkes, R.J., Prakongkep, N., Eds.; IUSS. Published on DVD, http://www.iuss.org (accessed on 1 March 2013).
- Tribus, M.; McIrvine, E.C. Energy and information. Sci. Am. 1971, 225, 179–188. [Google Scholar] [CrossRef]
- Theil, H. Economics and Information Theory; North-Holland: Amsterdam, The Netherlands, 1967. [Google Scholar]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; University of Illinois Press: Urbana, IL, USA, 1949. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Attneave, F. Applications of Information Theory to Psychology: A Summary of Basic Concepts, Methods, and Results; Holt, Rinehart and Winston: New York, NY, USA, 1959. [Google Scholar]
- Hughes, G. Applications of Information Theory to Epidemiology; APS Press: St Paul, MN, USA, 2012. [Google Scholar]
- MacDonald, D.K.C. Information theory and its application to taxonomy. J. Appl. Phys. 1952, 23, 529–531. [Google Scholar] [CrossRef]
- Agresti, A. Categorical Data Analysis, 3rd ed.; Wiley: Chichester, UK, 2012. [Google Scholar]
- Forbes, A.D. Classification-algorithm evaluation: five performance measures based on confusion matrices. J. Clin. Monitor. 1995, 11, 189–206. [Google Scholar] [CrossRef]
- DelSole, T. Predictability and information theory. Part I: Measures of predictability. J. Atmos. Sci. 2004, 61, 2425–2450. [Google Scholar]
- De Wolf, E.D.; Madden, L.V.; Lipps, P.E. Risk assessment models for wheat Fusarium head blight epidemics based on within-season weather data. Phytopathology 2003, 93, 428–435. [Google Scholar] [CrossRef] [PubMed]
- Madden, L.V. Botanical epidemiology: some key advances and its continuing role in disease management. Eur. J. Plant Pathol. 2006, 115, 3–23. [Google Scholar] [CrossRef]
- Schmidt, U.; Thöni, H.; Kaupenjohann, M. Using a boundary line approach to analyze N2O flux data from agricultural soils. Nutr. Cycl. Agroecosys. 2000, 57, 119–129. [Google Scholar] [CrossRef]
- Farquharson, R.; Baldock, J. Concepts in modelling N2O emissions from land use. Plant Soil 2008, 309, 147–167. [Google Scholar] [CrossRef]
- DelSole, T. Predictability and information theory. Part II: Imperfect forecasts. J. Atmos. Sci. 2005, 62, 3368–3381. [Google Scholar]
- Weijs, S.; Van Nooijen, R.; Van de Giesen, N. Kullback-Leibler divergence as a forecast skill score with classic reliability-resolution-uncertainty decomposition. Mon. Weather Rev. 2010, 138, 3387–3399. [Google Scholar] [CrossRef]
- Tödter, J.; Ahrens, B. Generalization of the ignorance score: continuous ranked version and its decomposition. Mon. Weather Rev. 2012, 140, 2005–2017. [Google Scholar] [CrossRef]
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Topp, C.F.E.; Wang, W.; Cloy, J.M.; Rees, R.M.; Hughes, G. Information Properties of Boundary Line Models for N2O Emissions from Agricultural Soils. Entropy 2013, 15, 972-987. https://doi.org/10.3390/e15030972
Topp CFE, Wang W, Cloy JM, Rees RM, Hughes G. Information Properties of Boundary Line Models for N2O Emissions from Agricultural Soils. Entropy. 2013; 15(3):972-987. https://doi.org/10.3390/e15030972
Chicago/Turabian StyleTopp, Cairistiona F.E., Weijin Wang, Joanna M. Cloy, Robert M. Rees, and Gareth Hughes. 2013. "Information Properties of Boundary Line Models for N2O Emissions from Agricultural Soils" Entropy 15, no. 3: 972-987. https://doi.org/10.3390/e15030972