
Precision-Driven Product Recommendation Software: Unsupervised Models, Evaluated by GPT-4 LLM for Enhanced Recommender Systems


Abstract
:1. Introduction
2. Literature Review
2.1. Personalized Product Recommendation Strategies
2.2. Product Recommendation Models and Algorithms
2.3. Natural Language Processing and Advanced Language Models
2.4. The Evolution of Generative Pre-Trained Transformer (GPT) Models
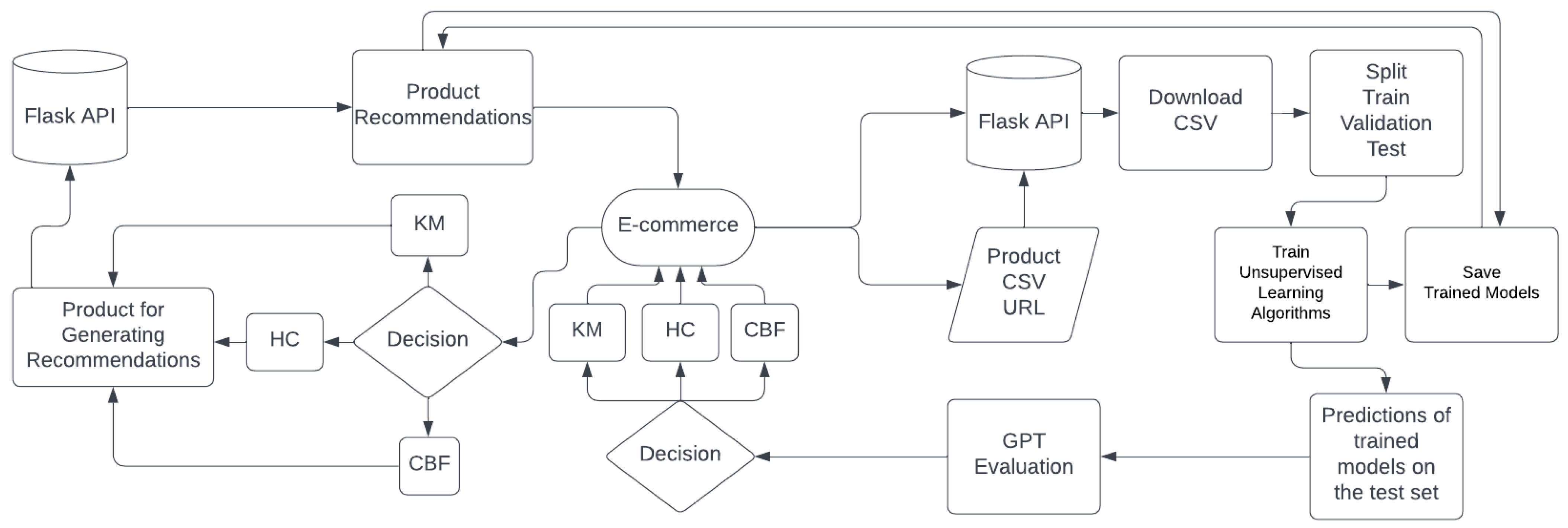
3. Materials and Methods
- K-means clustering algorithm: It is a widely adopted unsupervised machine learning technique designed to organize data points into distinct groups or clusters, leveraging their shared characteristics [37]. The “K” in K-means signifies the algorithm’s objective of identifying a specific number of clusters within the dataset [38]. Through iterative processes, the algorithm assigns data points to clusters and refines cluster centroids until a convergence criterion is satisfied.
- Content-based filtering (CBF): It stands as a distinctive recommendation system methodology, drawing its efficacy from the inherent attributes of items and user inclinations to curate personalized suggestions. Diverging from collaborative filtering, which relies on user–item interactions, CBF zeroes in on the intrinsic content characteristics of items and user profiles (user profiling) [19]. Items are delineated through features or metadata like keywords, genres, or pertinent descriptors. By scrutinizing users’ historical preferences, the system adeptly suggests items aligning with their past choices or explicitly stated preferences [39].
- Hierarchical clustering: It is recognized as a robust technique in data analysis and clustering, orchestrating the arrangement of data into a hierarchical tree or dendrogram structure based on similarities among data points [40]. This method systematically builds clusters by iteratively merging or dividing existing clusters until a comprehensive hierarchy is established. The decision-making process in hierarchical clustering, deciding whether to group or separate data points, relies on a selected distance metric like the Euclidean distance or correlation [41]. The agglomerative approach starts with individual data points, progressively merging them into clusters, whereas the divisive approach begins with a single cluster and iteratively fragments it into smaller clusters [42]. This hierarchical representation provides a nuanced comprehension of relationships and structures within the dataset, unveiling insights into the diverse levels of similarity and dissimilarity between data points.
3.1. Dataset Splitting and Preprocessing
3.2. Training K-Means Clustering, Content-Based Filtering (CBF), and Hierarchical Clustering Models for Product Recommendations
3.2.1. K-Means Clustering Training
3.2.2. Content-Based Filtering (CBF) Training
3.2.3. Hierarchical Clustering Training
3.3. Zero-Shot Evaluation Methodology Using GPT-4 Model for Assessing Product Recommendations
3.4. Development of Flask-Based API Software for Integrated Training and Deployment of Product Recommendation Models
3.5. Critical Factors Shaping Software Effectiveness in Collaborative and Real-Time Environments
- Seamless integration: The flask-based API offers an intuitive interface for integration, streamlining the process for developers and e-commerce proprietors to seamlessly incorporate and deploy the model in real-time applications.
- Automated training and evaluation: The software automates the training and evaluation processes, sparing users the intricacies of managing machine learning algorithms, model validation, and assessment.
- Enhanced natural language understanding with GPT-4: Leveraging GPT-4 for model evaluation harnesses its advanced natural language understanding capabilities, fostering effective human interaction. GPT-4’s adeptness at refining the semantic context of product features has the potential to elevate the precision and relevance of product recommendations.
- Scalability and efficiency: The software stands out as an efficient and scalable solution, tailored to handle varying levels of structured data specific to e-commerce needs. This adaptability is crucial for collaborative projects and real-time scenarios.
- User-centric experience: In real-time scenarios, success often hinges on the user experience. The model generates personalized and effective recommendations, enhancing the likelihood of positive user reception.
4. Research Results
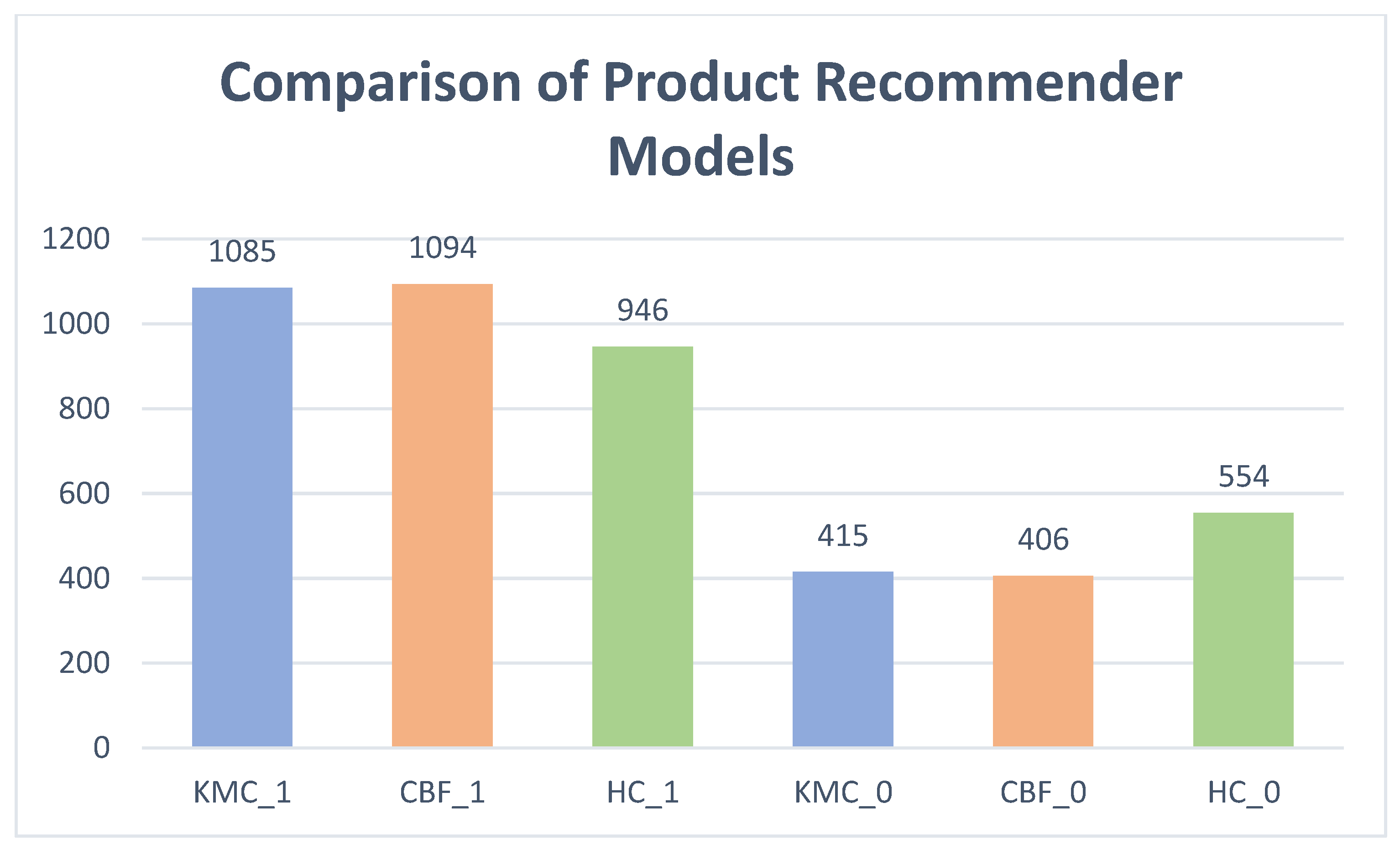
4.1. Comparing Unsupervised Learning Algorithms Trained for Product Recommendation in E-Commerce
- Research Question 1: Which unsupervised recommender system algorithm demonstrates superior efficacy in product recommendation tasks?
- Research Statement 1: The content-based filtering (CBF) and k-means clustering-trained models demonstrate higher accuracy in in-cart product recommendation tasks.
4.2. Evaluation of Models Using the GPT-4 Model
- Research Question 2: Is the GPT-4 model capable of evaluating the predictions of traditional unsupervised models?
- Research Statement 2: The GPT-4 model exhibits significant potential for evaluating predictions from unsupervised models.
4.3. Comparison of LLM Evaluation and Human Evaluation
- Research Question 3: Can LLMs replace human evaluations?
- Research Statement 3: LLMs present a more cost-effective and time-efficient alternative to human evaluations, but they cannot surpass human prowess.
4.4. Natural Language Model Evaluations on Unsupervised Learning Algorithms
- Research Question 4: Do NLPs have the capability to evaluate recommendations from unsupervised learning algorithms?
- Research Statement 4: NLPs, specifically LLMs like the GPT-4 model, have proven through our study to be effective tools for evaluating product recommendations generated by unsupervised learning models.
4.5. The Contribution of the Software to E-Commerce
- Research Question 5: Can the proposed flask-based API contribute to the accessibility and usability of sophisticated recommendation systems for e-commerce owners?
- Research Statement 5: The software proposed in this study has the potential to enhance both the product recommendation capabilities of e-commerce and the resulting benefits from additional sales, thereby providing high accessibility for e-commerce owners aiming to improve their recommendation system and, consequently, their e-commerce sales.
5. Recommender System Evaluation and Discussion
5.1. Assessing Recommender Systems’ Effectiveness
5.2. Threats to Validity
- Data bias and generalization issues: The efficacy of the model hinges on the quality and diversity of the training data. Biased or insufficiently varied data provided by e-commerce owners may result in skewed recommendations that lack generalizability to a broader audience.
- Overfitting: The integration of multiple models, particularly with a substantial language model like GPT-4, raises the risk of overfitting. This occurs when the model excels on training data but struggles to generalize to new, unseen data.
- Computational resources: The use of the GPT-4 model in the proposed recommender system could incur significant API costs for both fine-tuning and predictions, depending on the dataset size. This presents challenges for smaller e-commerce platforms with limited budgets.
- Interpretability: Complex integrated models may lack interpretability, making it difficult to comprehend how the model generates specific recommendations. This lack of transparency can be a concern for businesses that prioritize understanding the decision-making process.
- Privacy concerns: The advanced natural language understanding capabilities bring forth privacy concerns, especially if sensitive or personal information is inadvertently captured and utilized in the recommendation process. The software developed relies on trust in the data provided by e-commerce owners through the API without evaluating potential sensitivity.
- Maintenance and updates: Keeping the recommendation system up-to-date with the latest data and ensuring compatibility with evolving e-commerce platforms pose a challenge. Regular maintenance and updates are imperative, considering the possibility of GPT-4 being deprecated in the future or changes in API functions and Python libraries.
- User engagement and satisfaction: While the experimental results may suggest the effectiveness of the proposed methodology, it is essential to acknowledge that the GPT-powered evaluation tool comprehends the meaning behind each word, diverging from reliance on simple word similarity for its evaluation outcomes. Consequently, it becomes imperative to factor in user satisfaction and engagement. Users may not consistently prioritize the utmost accuracy in recommendations, underscoring the importance of striking a balance between precision and accommodating user preferences.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Agarwal, A.; Chakraborty, M.; Chowdary, C.R. Does Order Matter? Effect of Order in Group Recommendation. Expert Syst. Appl. 2017, 82, 115–127. [Google Scholar] [CrossRef]
- Kalyan, K.S. A Survey of GPT-3 Family Large Language Models Including ChatGPT and GPT-4. Nat. Lang. Process. J. 2023, 6, 100048. [Google Scholar] [CrossRef]
- Products Suggestions for WooCommerce—WordPress Plugin|WordPress.Org. Available online: https://wordpress.org/plugins/cart-products-suggestions-for-woocommerce/ (accessed on 18 February 2024).
- Lai, C.H.; Tseng, K.C. Applying Deep Learning Models to Analyze Users’ Aspects, Sentiment, and Semantic Features for Product Recommendation. Appl. Sci. 2022, 12, 2118. [Google Scholar] [CrossRef]
- Li, B.; Xu, H.; Zhao, Q.; Su, P.; Chabbi, M.; Jiao, S.; Liu, X. OJXPERF: Featherlight Object Replica Detection for Java Programs. In Proceedings of the 44th International Conference on Software Engineering 2022, Pittsburgh, PA, USA, 21–29 May 2022; pp. 1558–1570. [Google Scholar] [CrossRef]
- Li, B.; Zhao, Q.; Jiao, S.; Liu, X. DroidPerf: Profiling Memory Objects on Android Devices. In Proceedings of the Annual International Conference on Mobile Computing and Networking, Madrid, Spain, 2–6 October 2023; pp. 75–89. [Google Scholar] [CrossRef]
- Hell, F.; Taha, Y.; Hinz, G.; Heibei, S.; Müller, H.; Knoll, A. Graph Convolutional Neural Network for a Pharmacy Cross-Selling Recommender System. Information 2020, 11, 525. [Google Scholar] [CrossRef]
- Ghoshal, A.; Mookerjee, V.S.; Sarkar, S. Recommendations and Cross-Selling: Pricing Strategies When Personalizing Firms Cross-Sell. J. Manag. Inf. Syst. 2021, 38, 430–456. [Google Scholar] [CrossRef]
- Vatavwala, S.; Kumar, B.; Sharma, A. Enhancing Upselling and Cross-Selling in Business-to-Business Markets: The Critical Need to Integrate Customer Service and Sales Functions. In Customer Centric Support Services in the Digital Age; Palgrave Macmillan: Cham, Switzerland, 2024; pp. 199–216. [Google Scholar] [CrossRef]
- Lesage, L.; Deaconu, M.; Lejay, A.; Meira, J.A.; Nichil, G.; State, R. A Recommendation System for Car Insurance. Eur. Actuar. J. 2020, 10, 377–398. [Google Scholar] [CrossRef]
- Park, C.H.; Yoon, T.J. The Dark Side of Up-Selling Promotions: Evidence from an Analysis of Cross-Brand Purchase Behavior. J. Retail. 2022, 98, 647–666. [Google Scholar] [CrossRef]
- Zhu, T.; Harrington, P.; Li, J.; Tang, L. Bundle Recommendation in ECommerce. In Proceedings of the SIGIR 2014—37th International ACM SIGIR Conference on Research and Development in Information Retrieval, Gold Coast, Australia, 6–11 July 2014; pp. 657–666. [Google Scholar] [CrossRef]
- Zhou, H.; Xiong, F.; Chen, H.A.; Zhou, H.; Xiong, F.; Chen, H. A Comprehensive Survey of Recommender Systems Based on Deep Learning. Appl. Sci. 2023, 13, 11378. [Google Scholar] [CrossRef]
- Alcaraz-Herrera, H.; Cartlidge, J.; Toumpakari, Z.; Western, M.; Palomares, I. EvoRecSys: Evolutionary Framework for Health and Well-Being Recommender Systems. User Model. User-Adapt. Interact. 2022, 32, 883–921. [Google Scholar] [CrossRef]
- Chen, J.; Chen, W.; Huang, J.; Fang, J.; Li, Z.; Liu, A.; Zhao, L. Co-Purchaser Recommendation for Online Group Buying. Data Sci. Eng. 2020, 5, 280–292. [Google Scholar] [CrossRef]
- Stöckli, D.R.; Khobzi, H. Recommendation Systems and Convergence of Online Reviews: The Type of Product Network Matters! Decis. Support Syst. 2021, 142, 113475. [Google Scholar] [CrossRef]
- Wijaya, I.W.R. Mudjahidin Development of Conceptual Model to Increase Customer Interest Using Recommendation System in E-Commerce. Procedia Comput. Sci. 2022, 197, 727–733. [Google Scholar] [CrossRef]
- Aldino, A.A.; Pratiwi, E.D.; Setiawansyah; Sintaro, S.; Putra, A.D. Comparison of Market Basket Analysis to Determine Consumer Purchasing Patterns Using Fp-Growth and Apriori Algorithm. In Proceedings of the 2021 International Conference on Computer Science, Information Technology, and Electrical Engineering (ICOMITEE), Banyuwangi, Indonesia, 27–28 October 2021; pp. 29–34. [Google Scholar] [CrossRef]
- Tewari, A.S. Generating Items Recommendations by Fusing Content and User-Item Based Collaborative Filtering. Procedia Comput. Sci. 2020, 167, 1934–1940. [Google Scholar] [CrossRef]
- Rahmatillah, I.; Astuty, E.; Sudirman, I.D. An Improved Decision Tree Model for Forecasting Consumer Decision in a Medium Groceries Store. In Proceedings of the 2023 IEEE 17th International Conference on Industrial and Information Systems, ICIIS, Peradeniya, Sri Lanka, 25–26 August 2023; pp. 245–250. [Google Scholar] [CrossRef]
- Jbene, M.; Tigani, S.; Rachid, S.; Chehri, A. Deep Neural Network and Boosting Based Hybrid Quality Ranking for E-Commerce Product Search. Big Data Cogn. Comput. 2021, 5, 35. [Google Scholar] [CrossRef]
- Telikani, A.; Gandomi, A.H.; Shahbahrami, A. A Survey of Evolutionary Computation for Association Rule Mining. Inf. Sci. 2020, 524, 318–352. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, T.; Xue, T.; Lu, Y.; Na, S.G. E-Commerce Personalized Recommendation Analysis by Deeply-Learned Clustering. J. Vis. Commun. Image Represent. 2020, 71, 102735. [Google Scholar] [CrossRef]
- Javed, U.; Javed, U.; Shaukat, K.; Hameed, I.A.; Iqbal, F.; Alam, T.M.; Luo, S. A Review of Content-Based and Context-Based Recommendation Systems. Int. J. Emerg. Technol. Learn. iJET 2021, 16, 274–306. [Google Scholar] [CrossRef]
- Isinkaye, F.O. Matrix Factorization in Recommender Systems: Algorithms, Applications, and Peculiar Challenges. IETE J. Res. 2023, 69, 6087–6100. [Google Scholar] [CrossRef]
- Wu, G.; Sanner, S.; Luo, K.; Soh, H. Deep Language-Based Critiquing for Recommender Systems. In Proceedings of the RecSys 2019—13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 137–145. [Google Scholar] [CrossRef]
- Bhaskaran, S.; Marappan, R.; Santhi, B. Design and Analysis of a Cluster-Based Intelligent Hybrid Recommendation System for E-Learning Applications. Mathematics 2021, 9, 197. [Google Scholar] [CrossRef]
- Ko, H.; Lee, S.; Park, Y.; Choi, A. A Survey of Recommendation Systems: Recommendation Models, Techniques, and Application Fields. Electronics 2022, 11, 141. [Google Scholar] [CrossRef]
- Roumeliotis, K.I.; Tselikas, N.D.; Nasiopoulos, D.K. LLMs in E-Commerce: A Comparative Analysis of GPT and LLaMA Models in Product Review Evaluation. Nat. Lang. Process. J. 2024, 6, 100056. [Google Scholar] [CrossRef]
- Rothman, D. Transformers for Natural Language Processing: Build Innovative Deep Neural Network Architectures for NLP with Python, PyTorch, TensorFlow, BERT; Packt Publishing: Birmingham, UK, 2021. [Google Scholar]
- Li, B.; Hou, Y.; Che, W. Data Augmentation Approaches in Natural Language Processing: A Survey. AI Open 2022, 3, 71–90. [Google Scholar] [CrossRef]
- Fanni, S.C.; Febi, M.; Aghakhanyan, G.; Neri, E. Natural Language Processing. In Introduction to Artificial Intelligence; Springer: Cham, Switzerland, 2023; pp. 87–99. [Google Scholar] [CrossRef]
- de Curtò, J.; de Zarzà, I.; Calafate, C.T. Semantic Scene Understanding with Large Language Models on Unmanned Aerial Vehicles. Drones 2023, 7, 114. [Google Scholar] [CrossRef]
- Roumeliotis, K.I.; Tselikas, N.D.; Nasiopoulos, D.K. Unveiling Sustainability in Ecommerce: GPT-Powered Software for Identifying Sustainable Product Features. Sustainability 2023, 15, 12015. [Google Scholar] [CrossRef]
- Liu, Z.; Yu, X.; Zhang, L.; Wu, Z.; Cao, C.; Dai, H.; Zhao, L.; Liu, W.; Shen, D.; Li, Q.; et al. DeID-GPT: Zero-Shot Medical Text De-Identification by GPT-4. arXiv 2023, arXiv:2303.11032. [Google Scholar]
- Zhang, M.; Li, J. A Commentary of GPT-3 in MIT Technology Review 2021. Fundam. Res. 2021, 1, 831–833. [Google Scholar] [CrossRef]
- Bandyopadhyay, S.; Thakur, S.S.; Mandal, J.K. Product Recommendation for E-Commerce Business by Applying Principal Component Analysis (PCA) and K-Means Clustering: Benefit for the Society. Innov. Syst. Softw. Eng. 2021, 17, 45–52. [Google Scholar] [CrossRef]
- Sinaga, K.P.; Yang, M.S. Unsupervised K-Means Clustering Algorithm. IEEE Access 2020, 8, 80716–80727. [Google Scholar] [CrossRef]
- Nguyen, L.V.; Nguyen, T.H.; Jung, J.J. Content-Based Collaborative Filtering Using Word Embedding: A Case Study on Movie Recommendation. In Proceedings of the RACS’20: International Conference on Research in Adaptive and Convergent Systems, Gwangju, Republic of Korea, 13–16 October 2020; pp. 96–100. [Google Scholar] [CrossRef]
- Sangaiah, A.K.; Javadpour, A.; Ja’fari, F.; Zhang, W.; Khaniabadi, S.M. Hierarchical Clustering Based on Dendrogram in Sustainable Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2023, 24, 15724–15739. [Google Scholar] [CrossRef]
- Lamb, D.S.; Downs, J.; Reader, S. Space-Time Hierarchical Clustering for Identifying Clusters in Spatiotemporal Point Data. ISPRS Int. J. Geo-Inf. 2020, 9, 85. [Google Scholar] [CrossRef]
- Li, T.; Rezaeipanah, A.; Tag El Din, E.S.M. An Ensemble Agglomerative Hierarchical Clustering Algorithm Based on Clusters Clustering Technique and the Novel Similarity Measurement. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 3828–3842. [Google Scholar] [CrossRef]
- Amazon UK Products Dataset 2023 (2.2M Products). Available online: https://www.kaggle.com/datasets/asaniczka/amazon-uk-products-dataset-2023 (accessed on 3 February 2024).
- Sklearn.Model_Selection.Train_Test_Split—Scikit-Learn 1.4.0 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html (accessed on 3 February 2024).
- GitHub—Kroumeliotis/Product-Recommendations-Software-Unsupervised-Models-Evaluated-by-GPT-4-LLM: Precision-Driven Product Recommendations Software: Un-Leashing the Power of Unsupervised Models, Evaluated by GPT-4 LLM for Enhanced Recommender Systems. Available online: https://github.com/kroumeliotis/Product-Recommendations-Software-Unsupervised-Models-Evaluated-by-GPT-4-LLM (accessed on 3 February 2024).
- Colab.Google. Available online: https://colab.google/ (accessed on 3 February 2024).
- Walkowiak, T. Subject Classification of Texts in Polish—From TF-IDF to Transformers. In Proceedings of the Sixteenth International Conference on Dependability of Computer Systems DepCoS-RELCOMEX, Wrocław, Poland, 28 June–2 July 2021; pp. 457–465. [Google Scholar] [CrossRef]
- Kumar, V.; Subba, B. A Tfidfvectorizer and SVM Based Sentiment Analysis Framework for Text Data Corpus. In Proceedings of the 26th National Conference on Communications (NCC), Kharagpur, India, 21–23 February 2020. [Google Scholar] [CrossRef]
- Hong, Y.; Tantithamthavorn, C.; Thongtanunam, P.; Aleti, A. CommentFinder: A Simpler, Faster, More Accurate Code Review Comments Recommendation. In Proceedings of the ESEC/FSE 2022—30th ACM Joint Meeting European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Singapore, 14–18 November 2022; pp. 507–519. [Google Scholar] [CrossRef]
- Hasani, A.M.; Singh, S.; Zahergivar, A.; Ryan, B.; Nethala, D.; Bravomontenegro, G.; Mendhiratta, N.; Ball, M.; Farhadi, F.; Malayeri, A. Evaluating the Performance of Generative Pre-Trained Transformer-4 (GPT-4) in Standardizing Radiology Reports. Eur. Radiol. 2023, 1–9. [Google Scholar] [CrossRef] [PubMed]
- OpenAI API. Available online: https://openai.com/blog/openai-api (accessed on 14 November 2023).




{kind=link}
{kind=link}
{kind=link}
| 0 | 1 | Total | |
|---|---|---|---|
| KMC Evaluation | 415 | 1085 | 1500 |
| CBF Evaluation | 406 | 1094 | 1500 |
| HC Evaluation | 554 | 946 | 1500 |
| In-Cart Product | Recommendation Product | Model | Binary Rating | Justification |
|---|---|---|---|---|
| Holibanna Human Skull Teaching Model Lifesize Human skeleton Anatomical Head Bone Model Halloween Decoration | 267Pcs Molecular Model Organic Inorganic Structure Kit, Atoms Bonds Orbitals Chemistry Structure Kit Atom Link Model, Educational Molecule Set for Teachers Students Student Chemistry Learning | HC | 0 | The customer is purchasing a human skull teaching model for Halloween decoration, which suggests they are interested in anatomical models rather than chemistry models. Recommending a molecular model kit might not align with their current purchase intention. |
| Hellyhansen Women’s Crew Sweatshirt Women’s Sweatshirt | VOIO Men’s Hoodies, Warm Sweatshirt Crew Neck Print Sweatshirt Christmas Tree Plaid Print Sweatshirt 3D Pullover Suitable Autumn Winter Sweatshirt | CBF | 0 | The recommended product is for men, while the customer has added a women’s sweatshirt to their basket. It’s unlikely that the customer would be interested in purchasing a product that is not suitable for their gender. |
| 2 Pack Silicone Foldable Cups BPA-Free Collapsible Travel Mugs 270ML Portable Reusable Cup Set with Plastic Sealing Lid for Outdoor Picnic Camping Hiking Traveling (Grey & Blue) | Light my Fire Camping Mess Kit—Picnic Set 6 Pcs—Lunchkit—Camp Mess Kit—Reusable Camping Plates and Bowls Set—BPA Free—Microwave & Dishwasher—Camping Picnic Set | KMC | 1 | The customer might accept adding the Light my Fire Camping Mess Kit because it complements the Silicone Foldable Cups. The Mess Kit includes reusable camping plates and bowls, which would be useful for outdoor picnics, camping, and hiking. Additionally, the fact that it is microwave and dishwasher safe makes it convenient for the customer to use and clean. Overall, the Camping Mess Kit enhances the customer’s outdoor dining experience and provides them with a complete set of cookware. |
| Metrics | KMC | HC | CBF |
|---|---|---|---|
| count | 1500 | 1500 | 1500 |
| mean | 0.315991 | 0.228553 | 0.304138 |
| std | 0.203004 | 0.163804 | 0.200361 |
| min | 0.000000 | 0.000000 | 0.000000 |
| 25% | 0.151775 | 0.103950 | 0.145600 |
| 50% | 0.276650 | 0.190900 | 0.259550 |
| 75% | 0.440075 | 0.310575 | 0.426925 |
| max | 1.000000 | 0.958000 | 1.000000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roumeliotis, K.I.; Tselikas, N.D.; Nasiopoulos, D.K. Precision-Driven Product Recommendation Software: Unsupervised Models, Evaluated by GPT-4 LLM for Enhanced Recommender Systems. Software 2024, 3, 62-80. https://doi.org/10.3390/software3010004
Roumeliotis KI, Tselikas ND, Nasiopoulos DK. Precision-Driven Product Recommendation Software: Unsupervised Models, Evaluated by GPT-4 LLM for Enhanced Recommender Systems. Software. 2024; 3(1):62-80. https://doi.org/10.3390/software3010004
Chicago/Turabian StyleRoumeliotis, Konstantinos I., Nikolaos D. Tselikas, and Dimitrios K. Nasiopoulos. 2024. "Precision-Driven Product Recommendation Software: Unsupervised Models, Evaluated by GPT-4 LLM for Enhanced Recommender Systems" Software 3, no. 1: 62-80. https://doi.org/10.3390/software3010004