1.1. Motivation
Globally, the continuous increase (which is expected to more than double by 2050) in electricity demand is constantly depleting the Earth’s non-renewable resources, such as coal, natural gas, and oil [
1]. With the current impetus towards renewable energy, wind power generation is growing in popularity [
2,
3], as it is a cost-effective and sustainable alternative to generating electricity. In addition to mitigating the increase in carbon footprint by curbing fossil fuel use, wind energy also contributes to sustainable economic progress [
4]. The literature shows that adequate energy supplies improve economic stability [
1,
4]. Furthermore, economic stability, infrastructure development, and improved quality of life are inextricably linked to a sufficient supply of clean and renewable energy [
1]. As wind power has attained high penetration on power grids, complex management tasks have emerged due to the high randomness and intrinsic character of wind energy resources [
3,
5]. Wind energy resources’ electric output is directly affected by various weather phenomena, such as pressure gradient and local weather conditions. The resulting imbalance between power supply and demand compromises grid reliability. As can be seen from the equation below, wind power (generated from a particular wind turbine) is proportional to its speed [
6].
where
denotes the wind power,
is the area intercepting wind,
is the density of air (
) reliant on temperature, humidity, and air pressure,
is the drag power coefficient of the wind turbine, and
is the wind speed (m/s). From the equation above, the main influencing component is the variable
(wind speed). The wind power increases eight-fold when the wind speed doubles. Thus, a small increase in wind speed results in a larger increase in wind power. Wind speed forecasts are essential for the effective operation and management of electric power grids as wind energy output changes due to wind speed fluctuations [
7,
8,
9]. In particular, short-term wind speed forecasts (up to 24 h-ahead) are essential for wind power dispatching and scheduling, load reasonable decisions, and operational security in the electricity market [
2,
10,
11].
The urgency for decarbonisation, coupled with an increase in electricity prices and an abundance of wind resources in South Africa, makes investment in wind technologies an obvious decarbonisation strategy [
12]. In addition, South Africa has yet to take advantage of or consider its abundance of wind energy resources [
12]. We aim to quantify these wind energy resources in order to inform key stakeholders of their importance and untapped potential. Hence, this study focuses on short-term wind speed forecasting as a way of providing concise and accurate information to policymakers and strategists, thereby facilitating the effective integration of large volumes of wind power into existing grids.
A plethora of wind speed forecasting models exist in the literature, which can be classified into three major categories [
13], viz., physical approaches, statistical methods, and machine learning (a branch of artificial intelligence). To overcome profound challenges to operations and planning practices to the integration of the electric system owing to wind energy’s inherent discontinuity and limited predictability, hybrid versions of these models exist in the literature but to a lesser extent. The prior use of individual classes of models focused on prediction, ignoring other characteristics of the wind speed time series. However, it is necessary to discover useful information in the data via preprocessing and to characterise the data before prediction [
14]. Thus, denoising techniques such as variational mode decomposition (VMD) [
11,
15,
16], empirical mode decomposition (EMD) [
11,
17], and wavelet transforms (WTs) [
18] are pivotal, as they aim to reduce random disturbances in the data sequence and increase prediction accuracy. Our novelty and originality of the proposed ensemble method are premised on the basis that wind speed is characterised by inherent linearity, nonlinearity, and nonstationarity phenomena that cannot be simultaneously captured by one single class of models. We summarise our motivations to exploit an ensemble of stochastic methods, wavelets, and gradient boosting decision tree (GBDT) modelling, namely, the following:
The WT, which is superior to the Fourier Transform (FT) in that it can handle nonstationary data and use different time resolutions for varying frequencies, is used to decompose the signal into different scale components with statistically more sound properties to improve prediction.
We unleash the power of the technique of GBDTs, extreme gradient boosting (XGBoost), as they have quicker training times than artificial neural networks (ANNs), improved accuracy and flexibility, and the ability to effectively handle large datasets and inherent nonlinearity in the data.
We make use of the autoregressive integrated moving average (ARIMA) model to capture inherent linearity in the data.
We employ the support vector machine (SVR) model to reconcile ARIMA and XGBoost predictions with high speed and accuracy.
Thus, our new novel hybrid model, namely WT-ARIMA-XGBoost-SVR, can capture the inherent linearity, nonlinearity, and nonstationarity phenomena.
The practicability and efficacy of the proposed forecasting model were confirmed empirically via prediction metrics.
The study has been conducted in a way that is reliable and easy to replicate.
The study uses high-resolution minute-based granularity wind speed data measured by a R.M. Young (05103 or 03001) anemometer instrument. These data were downloaded (
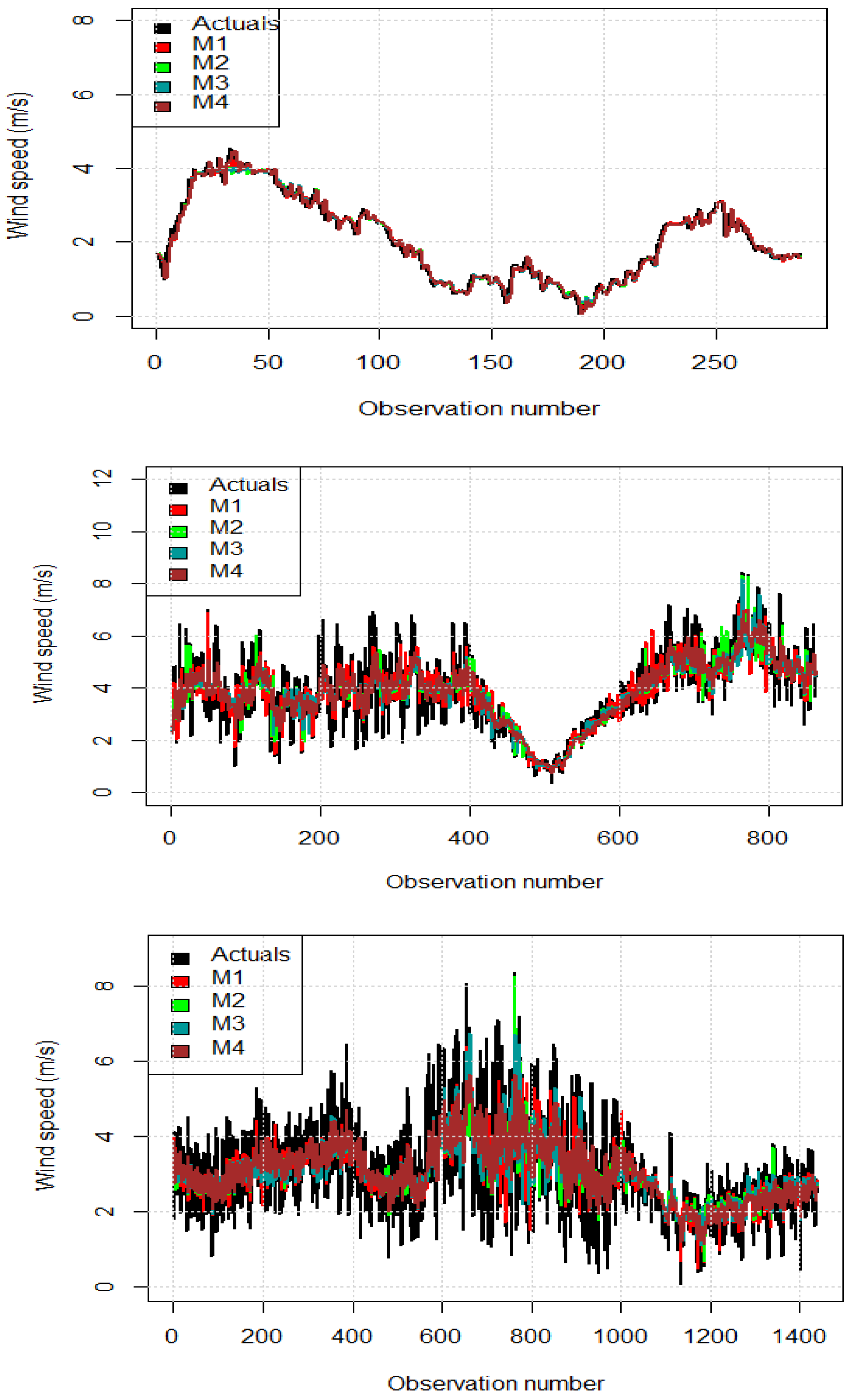
http://www.sauran.ac.za) (accessed on 15 December 2022) from Richtersveld (RVD), Central University of Technology (CUT), and University of Pretoria (UPR) radiometric stations in South Africa. The CUT station is located on the roof of a building at the CUT university, in the Free State province, at latitude −29.121337, longitude 26.215909, and an elevation of 1397 m. The RVD station is located in the desert region of the Northern Cape at latitude −28.56084061 and longitude 16.76145935, with an elevation of 141 m. The UPR station is located on the roof of a building at the University of Pretoria, in the Gauteng province, at latitude −25.75308037, longitude 28.22859001, and an elevation of 1410 m. We deliberately selected the stations to test how robust the proposed modelling and prediction approach would be under varying weather conditions. To our knowledge, a study of this type has not been conducted at these three Southern African Universities Radiometric Network (SAURAN) stations.
1.2. Overview of Related Studies
Several forecasting methods, including physical methods, statistical methods, hybrid models, and machine learning techniques, have been applied in an attempt to accurately forecast wind speed (see e.g., [
5,
10,
11,
19,
20,
21,
22,
23,
24]). Although physical models (e.g., numerical weather prediction (NWP)) can effectively predict atmospheric dynamics, they have many limitations, including the use of a large amount of numerical weather data and the need for large computational time [
2], which is costly and beyond the reach of a developing country such as South Africa. These methods are often reserved for medium- to long-term forecasting [
7].
Statistical methods, on the other hand, make use of historical wind speed time series data to construct time series models, such as the linear autoregressive moving average (ARMA) model [
2,
4]. These models are generally reserved for capturing short-time phenomena [
25,
26,
27,
28]. For instance, ref. [
15] presented an ARMA model to predict wind speed. The ARMA model was able to represent the actual features of wind speed. However, the ARMA model does not directly take into account changes in other related random variables or other exogenous variables. In essence, ARMA captures only a linear relationship, and it is generally suited to establishing a low-order time series model. To circumvent the nonstationarity inherent in the data, ARMA models have been extended to ARIMA models [
29,
30], seasonal ARIMA (SARIMA) models [
31,
32], and multiple linear regression coupled with SARIMA (SARIMAX) models, i.e., SARIMA models with exogenous variables [
33].
Unlike statistical models, machine learning techniques are nonlinear approximators that can effectively capture nonlinear characteristics inherent in wind speed data that are impossible to capture using statistical methods. Hence, these techniques have gained popularity in wind speed forecasting [
34]. Recent advances in machine learning algorithms have led to GBDTs becoming increasingly popular due to their quick training times, improved accuracy and flexibility, support for central processing units (CPU) (better than graphics processing units (GPU) used by ANNs), and ability to effectively handle large datasets [
35,
36,
37,
38,
39,
40,
41,
42]. Among the GBDTs, XGBoost, light gradient boosting machine (LGB), and stochastic gradient boosting machine (SGB) have been successfully applied in various fields, ranging from finance [
36] to renewable energy [
35,
37,
38,
39,
40,
42]. For instance, ref. [
38] employed the improved XGBoost to improve the accuracy of wind speed predictions. The authors compared the XGBoost with backpropagation neural networks (BPNN) and linear regression (LR) models and found that XGBoost has high predictive accuracy. In [
40], the authors explored short-term wind speed forecasting using ANNs, SGBs, and generalised additive models (GAMs). The results showed that the SGB outperforms other models based on mean absolute error (MAE) and mean percentage error (MAPE). Overall, GBDTs have several advantages over other machine learning models: high efficiency in the prediction domain, the robustness of model tuning, improved prediction accuracy, and ease of interpretation [
35,
36,
37,
38,
39,
40,
41] (also see
Table 1).
Hybrid models combine more than one forecasting method to form a new one (see, e.g., [
37,
43,
44,
45]). Using different time-varying datasets, ref. [
46] concluded that hybridisation ensures the accurate modelling of complex autocorrelation structures that are often inherent in time series data. As a result, hybrid methods have been proven to yield high prediction accuracy when handling time-series data with complex structures (see, e.g., [
46]). For instance, to optimise the ARIMA model’s parameters, ref. [
45] implemented an enhanced hybrid technique that combines an ARIMA and Kalman filter (KF) model via particle swarm optimisation (PSO). From the study results, the proposed approach improved the forecasting accuracy of the ARIMA model. In a similar study, ref. [
37] proposed a new hybrid machine learning model that combines the LGB model and the Gaussian Process Regression (GPR) model to solve the probabilistic prediction problem of wind speed. In predicting wind speeds for a real wind farm in the United States, the proposed LGB-GPR model improved the point forecast accuracy and probabilistic forecast reliability when compared to individual SVR, LR, random forest (RF), GPR, ANN, long-term short memory (LSTM), and LGB.
To enhance the accuracy of the wind speed forecasting model, nonlinear, and nonstationary wind speed data must be pre-processed using an appropriate data decomposition technique. In recent years, WTs have gained some attention [
18] in wind speed forecasting due to their excellent properties in both time and frequency domain time series analysis. Furthermore, WT is known to reveal patterns, discontinuities, and trends in time series by splitting them into low-frequency and high-frequency signals [
47]. In essence, the WTs decompose original wind speed data to construct constitutive series that are statistically more sound (i.e., less variant) than the original, thereby reducing forecasting complexity [
2,
4,
8,
27]. For instance, ref. [
25] proposed a repeated WT-ARIMA model (RWT-ARIMA). The RWT-ARIMA model was found to be more effective in improving the forecasting accuracy of the WT-ARIMA model in very short-term wind speed forecasting. In a similar study, ref. [
44] combined WT, ARIMA, and machine learning algorithms (SVR and RF) in short-term wind speed forecasting using 10-min interval wind speed data. After fitting an ordinary ARIMA model to capture linear components, the residuals were decomposed using db3 level 5 WT and fed into the SVR or/and RF. Compared to the individual ARIMA model, the proposed strategy produced more accurate results. The authors of [
43] proposed a hybrid model comprising WT, genetic algorithm (GA), and SVM in wind speed forecasting. A case study of a wind farm in North China demonstrated that this method provides more accurate and robust forecasts by fine-tuning the parameters in SVM using the GA to ensure generalisation. In contrast to the ARIMA model, GA and SVR are advantageous since they can avoid local optima, which is a deficiency of the ARIMA model [
48,
49,
50,
51,
52] (also see
Table 1). Despite the GA’s greater reliability, these techniques have a slower convergence rate than SVR algorithms.
Table 1.
Summary of the strengths and weaknesses of the models employed in developing the WT-ARIMA-GBDTs-SVR model.
Table 1.
Summary of the strengths and weaknesses of the models employed in developing the WT-ARIMA-GBDTs-SVR model.
| Category | Model | Merit | Demerit | References |
|---|
| Statistical | ARIMA | Excellent in handling linearity. | Difficulty in capturing nonlinearity. | [25,29,30,44,51,53] |
| Machine Learning | SVR | High convergence speed. Handles small data excellently. | Inefficiency in handling large-scale dataset. | [15,48,50,52,54] |
| Machine Learning | XGBoost | Faster and robust model tuning; highly scalable; flexible and versatile. | Can overfit small datasets. | [35,36,37,38,39,55] |
| Machine Learning | LGB | High training speed; Better accuracy; Support GPU learning; Capable of handling large-scale data. | It produces more complex trees, and can overfit small datasets. | [35,36,37,38,39] |
| Machine Learning | SGB | Highly predictive accuracy and flexibility.Can handle both categorical and numerical values. | Require lots of trees and can overfit data. Can be computationally expensive. | [40,41,42] |
| Signal processing | WT | Excellent features in the time and frequency domain. Can handle non-stationary data. | Difficult to identify the most appropriate decomposition level. | [56,57] |
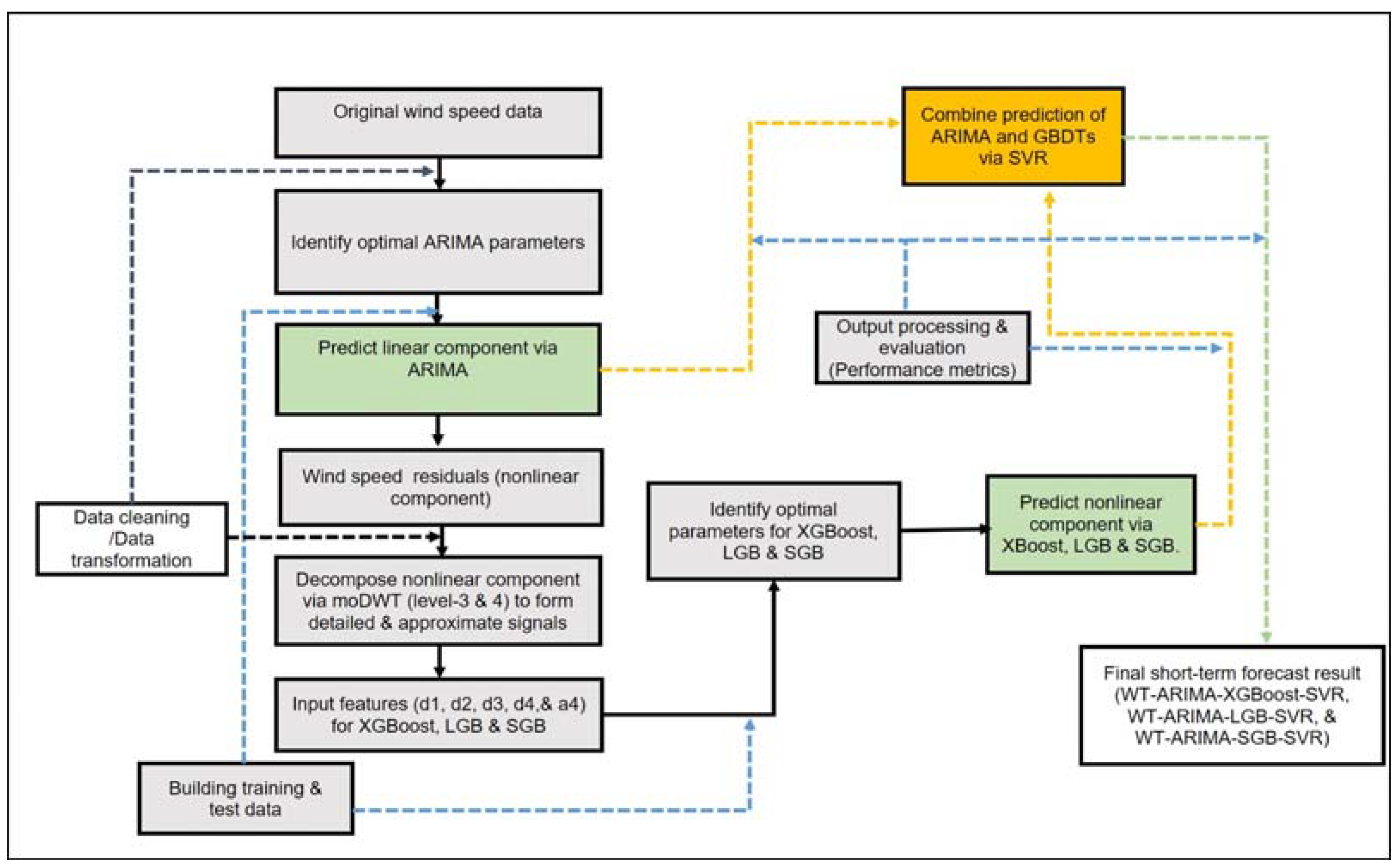
1.3. Suggested Modelling Approach
Wind speed is chaotically intermittent and is often characterised by inherent linear and nonlinear patterns as well as nonstationary behaviour; thus, it is generally difficult to predict it accurately and efficiently using a single linear or nonlinear model [
25,
46,
53,
54]. We suggest combining WT, ARIMA, and XGBoost via SVR to predict high-resolution short-term wind speeds.
In the literature, wavelet decomposition of a signal is followed by separate modelling of subseries using appropriate techniques. In the last step, sub-series predictions are reconciled (through summation) (see, e.g., [
25]). In addition to its simplicity, this conventional approach (individual modelling and summation of subseries predictions) incorporates errors from each subseries into the final predictions. This compromises the accuracy and robustness of the final predictions. The authors of [
25] discussed the difficulty in capturing high-frequency subseries when using the ARIMA model, which led to large errors when predicting using the WT-ARIMA model. High-frequency wind speed subseries (particularly at low levels) with nonlinear features adversely affect the accuracy and reliability of wind speed predictions from the ARIMA model. In this case, the uncertainty and inaccuracy of wind power predictions will result in energy costs rising, as additional reserves are required to maintain energy balance and ensure optimal unit commitment. Furthermore, ref. [
58] also showed that wind turbine energy costs associated with forecast errors can reach 10% of total wind energy turnover.
Although the RWT-ARIMA model was found to reduce error accumulation to some extent, these techniques require more computational time than highly efficient machine learning algorithms such as the XGBoost and RF (see, e.g., [
59]). Hence, this study proposes a new novel hybrid model, namely WT-ARIMA-XGBoost-SVR to circumvent error accumulation in the final wind speed predictions. In essence, the proposed strategy leverages the advantages of WT (excellent at denoising high variant signals), ARIMA (captures linearity very well), GBDTs (high accuracy, robust model tuning, highly scalable, sparse with computational efficiency), and SVR algorithms (high convergence speed with small sample sizes) to predict short-term wind speed with high precision and efficiency. In the aforementioned hybrid modelling strategy, the ARIMA model is employed to capture the linear component infused in the original wind speed data. The resultant residuals (i.e., nonlinear component) from fitting the ARIMA model are disaggregated into several less noisy subseries by WT. As input features, these subseries are fed into an XGBoost model to capture the nonlinear component that could not be captured by an ARIMA model. The final predicted value is determined by combining the predicted values from the ARIMA model and XGBoost using SVR. The efficacy of the proposed WT-ARIMA-XGBoost-SVR in short-term wind speed prediction is evaluated against the WT-ARIMA-LGB-SVR and WT-ARIMA-SGB-SVR. Although recent advances in computing power have led to more advanced and accurate machine-learning algorithms, ARIMA is still one of the most widely used models for wind speed short-term forecasting and benchmarking. For instance, in [
60], the ARIMA model outcompeted Gated Recurrent Unit (GRU) and LSTM algorithms in short-term wind speed forecasting. Therefore, both the point and interval predictions of the proposed approach are also benchmarked against the ARIMA model to better evaluate its efficacy.
Overall, the current study will contribute to the existing renewable energy literature in the following ways: (a) In an effort to enhance short-term wind speed prediction accuracy, boosting and vector machine learning techniques are introduced; (b) High efficient and robust gradient decision trees are used instead of the classical ARIMA models, which are prone to struggling with nonlinearity and large datasets; (c) The effect of each subseries prediction error on overall wind speed prediction is minimised by utilising all wavelet decomposed subseries as input features into the XGBoost; (d) To some extent, the developed hybrid approach accurately, and efficiently captures nonlinear components associated with wind speed turbulence and gusts; (e) The proposed model is applied on different datasets from different locations as well as terrain complexity and used for forecasting over different time spans within the short-term forecasting framework to assess its robustness.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




