
Knowledge-Based Image Analysis: Bayesian Evidences Enable the Comparison of Different Image Segmentation Pipelines †


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
2.2. Workflow
- User input: The experimenter manually marks regions with and without cells, resulting in a manually segmented image from the time series (see Figure 1).
- Bayesian parameter and evidence estimation: Bayesian inference is applied to different parameter-dependent image segmentation pipelines using the manually segmented image as input data. A metric distance is applied to measure the difference between the manually segmented image and the pipeline-generated images (see below). During parameter estimation, the distance between the manually and the pipeline-segmented image will be optimized, resulting in the conversion of the expert knowledge to machine-readable posterior distributions of parameters.
- Application: Based on the estimated Bayesian evidences as quality criteria of the image segmentation pipelines, one image segmentation pipeline can be chosen, and the optimized parameter set can be applied to the entire image series.
2.3. Image Segmentation Pipelines
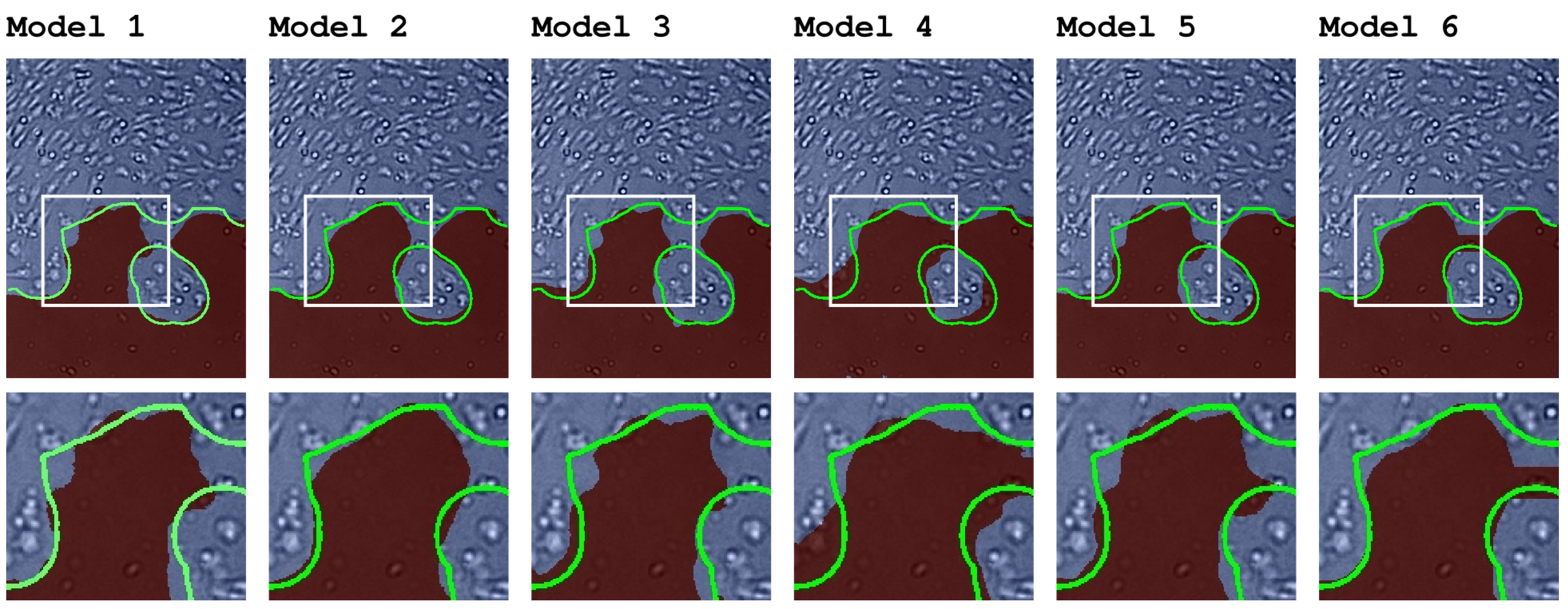
- Model 1
- consists of the following elements: A canny edge detection with two free parameters is performed under the assumption that cell-covered areas have more edges than cell-free areas. Consecutively, the resulting image is blurred by using a box blur filter to merge the previously found edges into an area. An intensity threshold is used to obtain a binary image. Furthermore, on the binary image, two size thresholds for contiguous small areas of black or white pixels are applied under the assumption that, most likely, small areas represent artifacts. Model 1 has 6 free parameters.In the following, the variations of Models 2–6 in comparison with Model 1 are highlighted.
- Model 2
- uses a Gaussian filter instead of the box blur. While the Gaussian filter is computationally more expensive than the box blur, it is assumed to better reproduce the natural curves of the cells in the image than the rectangular box blur. Model 2 has 6 free parameters.
- Model 3
- uses the Sobel filter with a fixed parameter set (of kernel size 3 pixels) instead of the canny edge detection. The Sobel filter is a less computational expensive edge detection algorithm and a more general approach. Model 3 has 4 free parameters.
- Model 4
- also uses a Sobel filter. Further, Model 4 does not apply size thresholds for small areas of black or white pixels. Thus, it is the least computational expensive model in this series, but does not correct for any artifacts. Model 4 has 2 free parameters.
- Model 5
- is the same as Model 1 without size thresholds and, therefore, does also not correct for small artifacts. Model 5 has 4 free parameters.
- Model 6
- is similar to Model 2 as it uses Gaussian blurring, but instead of size thresholds, it applies opening and closing image filters, which are commonly used to filter out small regions. Model 6 has 6 free parameters.
2.4. Distance Metrics
2.5. Bayesian Inference
2.6. Numerical Implementation
3. Results
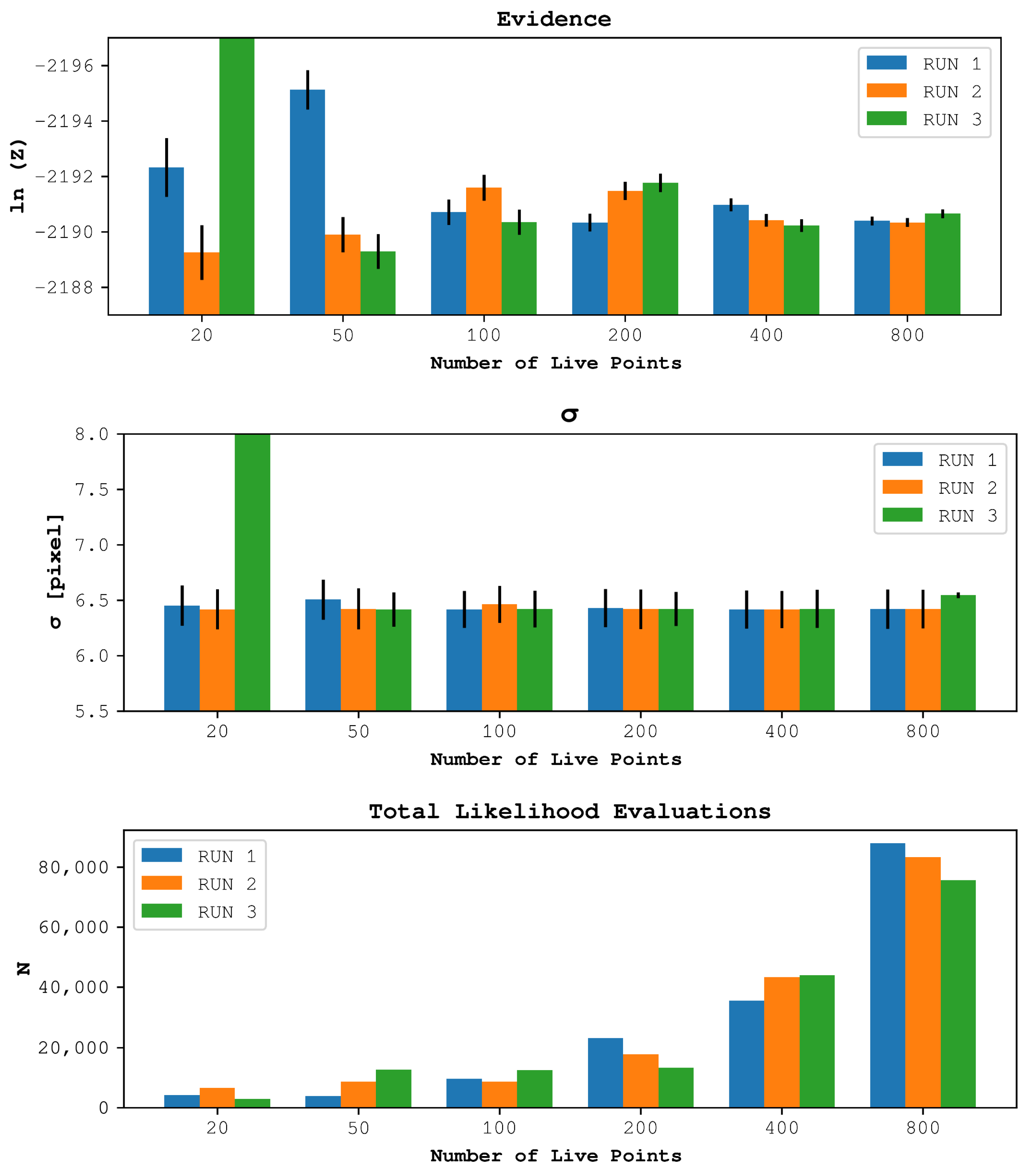
3.1. Determining the Necessary Number of Live Points
3.2. Image Segmentation Using the Estimated Posterior Parameters
3.3. Choosing the Image Segmentation Pipeline
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Moskopp, M.L.; Deussen, A.; Dieterich, P. Bayesian inference for the automated adjustment of an image segmentation pipeline—A modular approach applied to wound healing assays. Knowl.-Based Syst. 2019, 173, 52–61. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Burger, W.; Burge, M.J. Digitale Bildverarbeitung: Eine Einführung mit Java und ImageJ; mit 16 Tabellen; eXamen.press; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Jonkman, J.E.N.; Cathcart, J.A.; Xu, F.; Bartolini, M.E.; Amon, J.E.; Stevens, K.M.; Colarusso, P. An introduction to the wound healing assay using live-cell microscopy. Cell Adhes. Migr. 2014, 8, 440–451. [Google Scholar] [CrossRef] [PubMed]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- The OpenCV Reference Manual; Manual, Edition: 2.4.13.7; OpenCV: Palo Alto, CA, USA, 2014.
- Chalana, V.; Kim, Y. A methodology for evaluation of boundary detection algorithms on medical images. IEEE Trans. Med. Imaging 1997, 16, 642–652. [Google Scholar] [CrossRef] [PubMed]
- Feroz, F.; Hobson, M.P. Multimodal nested sampling: An efficient and robust alternative to Markov Chain Monte Carlo methods for astronomical data analyses: Multimodal nested sampling. Mon. Not. R. Astron. Soc. 2008, 384, 449–463. [Google Scholar] [CrossRef]
- Skilling, J. Nested sampling for general Bayesian computation. Bayesian Anal. 2006, 1, 833–859. [Google Scholar] [CrossRef]
- Von Toussaint, U. Bayesian inference in physics. Rev. Mod. Phys. 2011, 83, 943–999. [Google Scholar] [CrossRef]
- Buchner, J.; Georgakakis, A.; Nandra, K.; Hsu, L.; Rangel, C.; Brightman, M.; Merloni, A.; Salvato, M.; Donley, J.; Kocevski, D. X-ray spectral modelling of the AGN obscuring region in the CDFS: Bayesian model selection and catalogue. Astron. Astrophys. 2014, 564, A125. [Google Scholar] [CrossRef]
- Arganda-Carreras, I.; Kaynig, V.; Rueden, C.; Eliceiri, K.W.; Schindelin, J.; Cardona, A.; Sebastian Seung, H. Trainable Weka Segmentation: A machine learning tool for microscopy pixel classification. Bioinformatics 2017, 33, 2424–2426. [Google Scholar] [CrossRef] [PubMed]
- Buchner, J. UltraNest—A robust, general purpose Bayesian inference engine. J. Open Source Softw. 2021, 6, 3001. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ln(Z) | [pxl] | Calc. Time * | |
| Model 1 | 02 min 59 s | ||
| Model 2 | 11 min 15 s | ||
| Model 3 | 01 min 11 s | ||
| Model 4 | 00 min 20 s | ||
| Model 5 | 01 min 03 s | ||
| Model 6 | 27 min 23 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moskopp, M.L.; Deussen, A.; Dieterich, P. Knowledge-Based Image Analysis: Bayesian Evidences Enable the Comparison of Different Image Segmentation Pipelines. Phys. Sci. Forum 2023, 9, 20. https://doi.org/10.3390/psf2023009020
Moskopp ML, Deussen A, Dieterich P. Knowledge-Based Image Analysis: Bayesian Evidences Enable the Comparison of Different Image Segmentation Pipelines. Physical Sciences Forum. 2023; 9(1):20. https://doi.org/10.3390/psf2023009020
Chicago/Turabian StyleMoskopp, Mats Leif, Andreas Deussen, and Peter Dieterich. 2023. "Knowledge-Based Image Analysis: Bayesian Evidences Enable the Comparison of Different Image Segmentation Pipelines" Physical Sciences Forum 9, no. 1: 20. https://doi.org/10.3390/psf2023009020