

A Methodological Approach to Extracting Patterns of Service Utilization from a Cross-Continuum High Dimensional Healthcare Dataset to Support Care Delivery Optimization for Patients with Complex Problems
 , ,
, ,  , ,
, , 
Abstract
:
1. Introduction
1.1. Patterns of Service Utilization (PSUs) for Health-Service-System Optimization
1.2. Abundance and Scarcity of Published Work in ML-Derived Supports for Effective Service System Operations
Element # 1—‘-Omic’ Layers:
Element # 2—Symptoms, Signs, Problems:
Element # 3—Working Diagnoses and Rule-Outs:
Element # 4—Procedures, Treatments, Expected Outcomes:
Element # 5—Problem-Specific Protocols—And Expected Outcomes:
Element # 6—Clinical Guidelines/Clinical Pathways
Element # 7—Service Pathways
Element # 8—Patient Journeys
Element # 9—Epidemiological Aspects
1.3. Objectives
- What mechanism can be used to address the cross-continuum data granularity and nomenclature issues to generate intelligible dataset that can be analyzed?
- For cohorts with large volumes of interactions with diverse arrays of services spanning the continuum, can graph machine learning methods (community detection) be employed to extract clinically understandable clusters of services (PSUs), which reflect distinctive needs?
- Methodologically, what mechanism can be used to determine the optimal number of communities?
- Within a given community of services, can one separate out those services that reflect common features of cohorts, such as need or risk, versus those services that are keyed to variable features of persons within cohorts? Stated in slightly different terms, can one separate out services that “belong” in communities versus services that are forced into one community or another by the community detection algorithms?
- Can one generate results that are readily and correctly interpretable by persons who do not have a background in statistics, research, or data science?
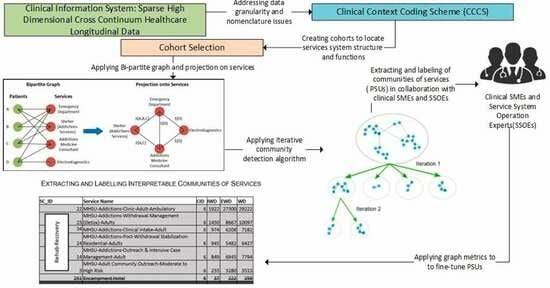
2. Methodological Approach
2.1. Source Data
2.2. Features Selection
2.3. Data Pre-Processing and Data Re-Engineering—Addressing Nomenclature and Data Granularity Issues
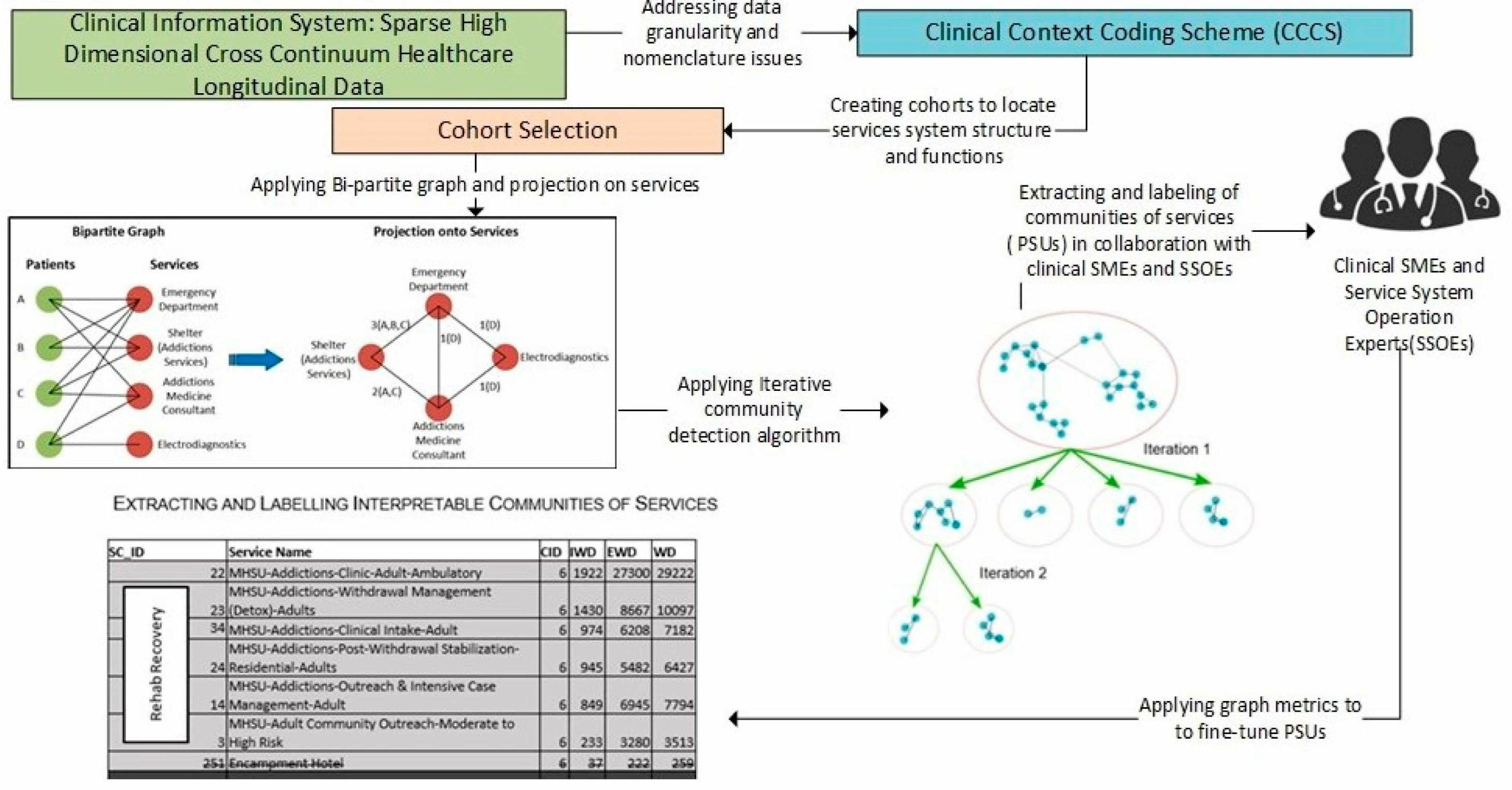
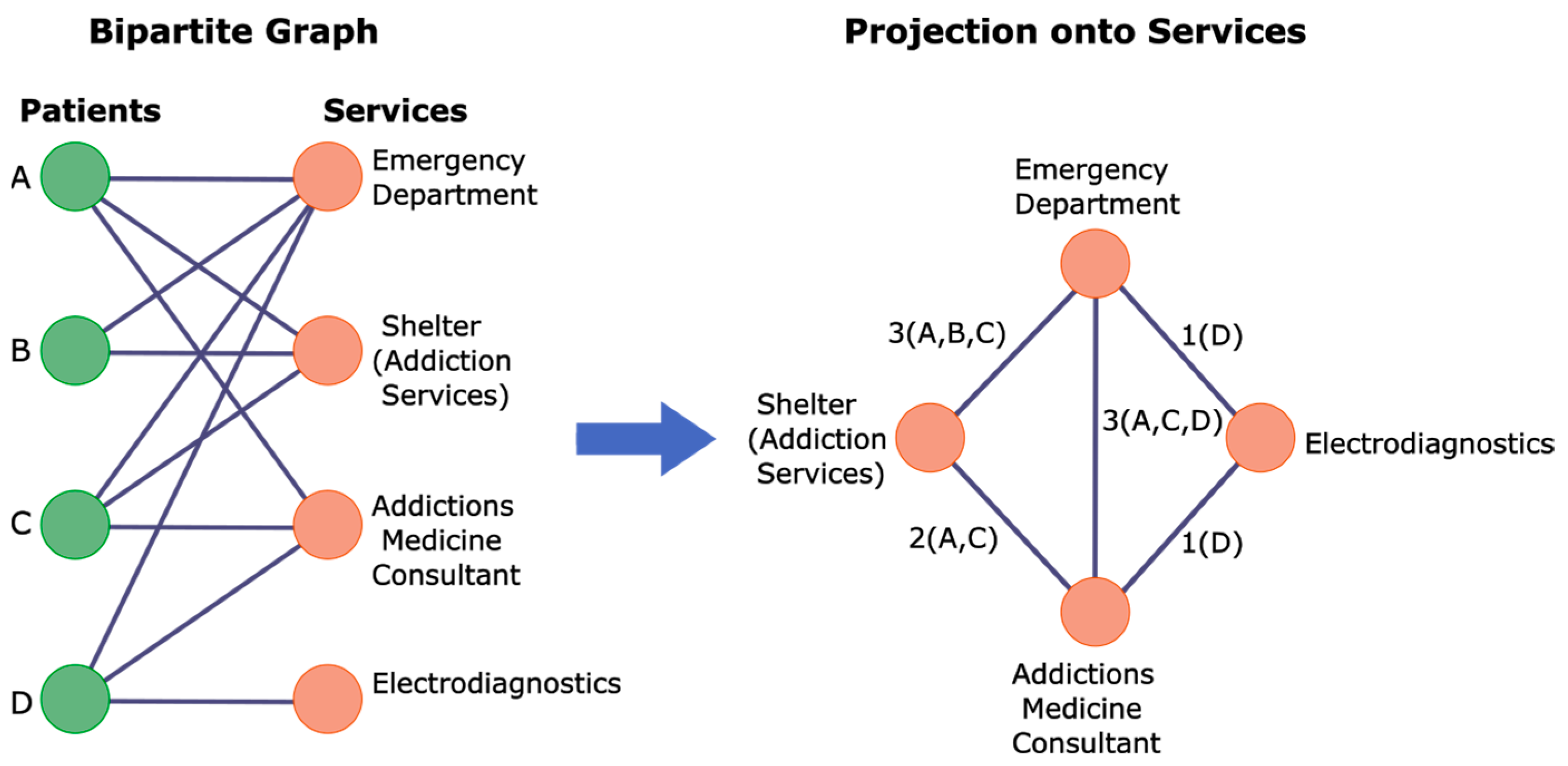
2.4. Creating Cohorts to Locate Service System Structures and Functions
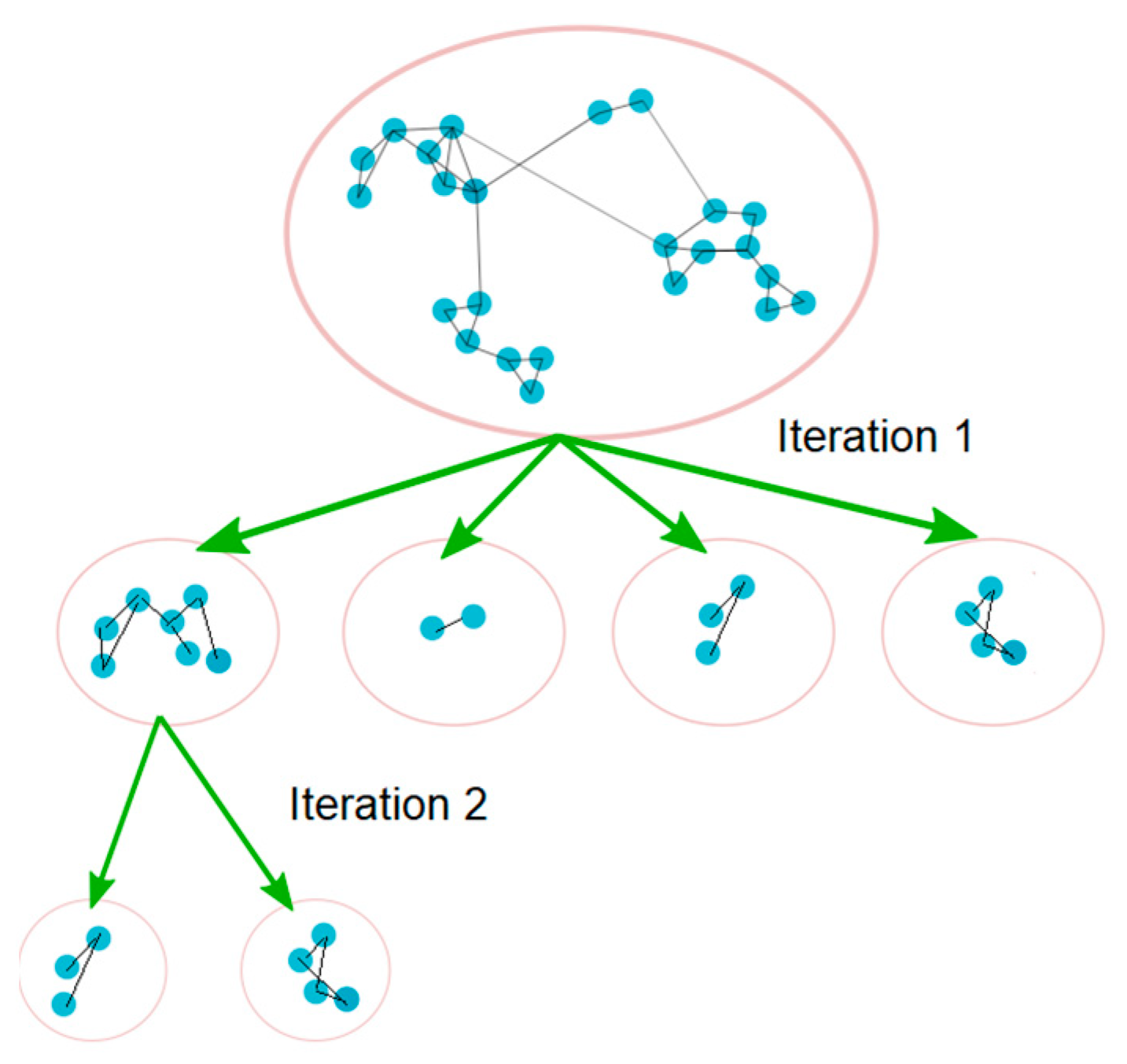
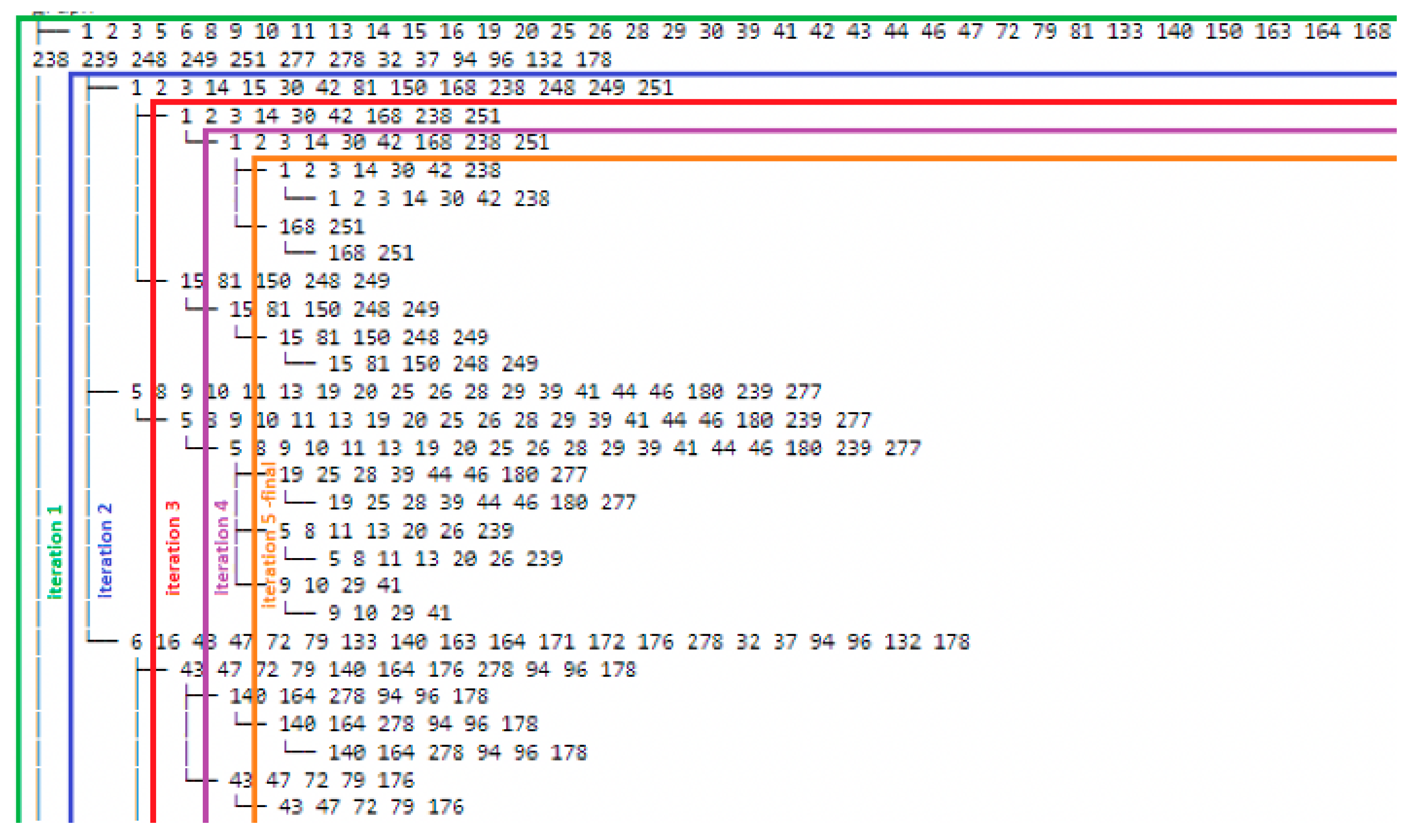
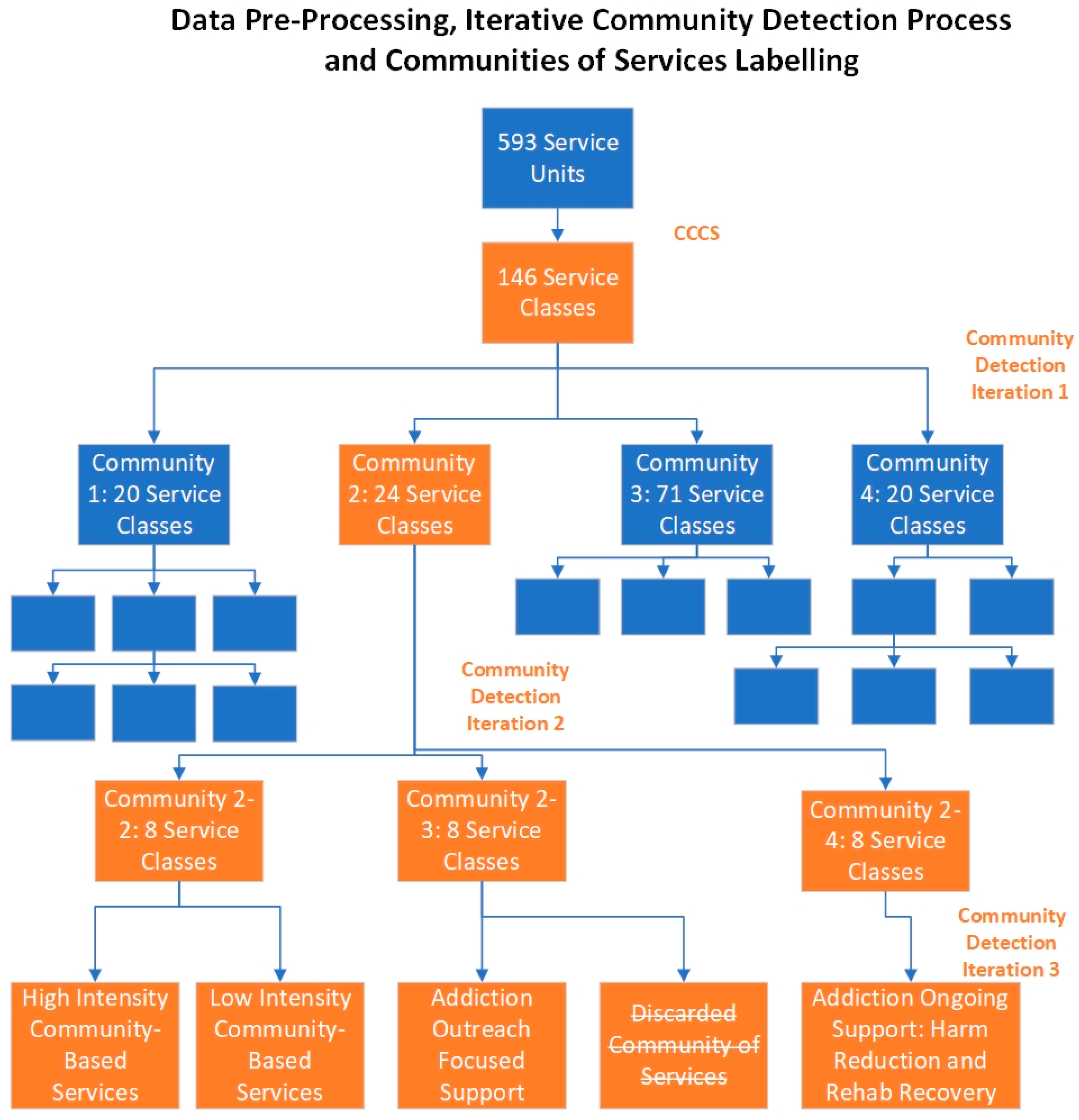
2.5. Generating Communities of Services
2.6. Extracting PSUs from Communities of Services
- Quantitative criteria using metadata: graph metrics including the graph internal weighted degree, the external weighted degree, and the weighted degree (sum of internal and external weighted degrees) were used, to determine the cut-off point.
- Qualitative criteria: these include judgments from clinical cohort-specific subject matter experts regarding the characteristics of the cohorts within which the community detection has been run.
3. Analysis and Results
3.1. Analysis Setup: Cohort Creation
3.2. Generating Communities of Services
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McVeigh, S.E. Sepsis management in the emergency department. Nurs. Clin. 2020, 55, 71–79. [Google Scholar] [CrossRef] [PubMed]
- Laursen, T.M.; Nordentoft, M.; Mortensen, P.B. Excess Early Mortality in Schizophrenia. Annu. Rev. Clin. Psychol. 2014, 10, 425–448. [Google Scholar] [CrossRef] [PubMed]
- Laursen, T.M.; Munk-Olsen, T.; Vestergaard, M. Life expectancy and cardiovascular mortality in persons with schizophrenia. Curr. Opin. Psychiatry 2012, 25, 83–88. [Google Scholar] [CrossRef] [PubMed]
- BC Guidelines. 2024. Available online: https://www2.gov.bc.ca/gov/content/health/practitioner-professional-resources/bc-guidelines (accessed on 7 March 2024).
- Thor, J.; Lundberg, J.; Ask, J.; Olsson, J.; Carli, C.; Härenstam, K.P.; Brommels, M. Application of statistical process control in healthcare improvement: Systematic review. BMJ Qual. Saf. 2007, 16, 387–399. [Google Scholar] [CrossRef] [PubMed]
- Blondel, V.D.; Guillaume, J.-L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Moselle, K.; Bambi, J.; Santoso, Y.; Sadri, H.S.; Robertson, S.; Howie, J.; Rudnick, A.; Chang, E. Abundance andScarcity of Published Work in MachineLearning Derived Supports for Effective ServiceSystem Operations, University of Victoria, Victoria, BC, Canada. 2024; unpublished. [Google Scholar]
- Barabási, A.-L.; Loscalzo, J.; Silverman, E.K. Network Medicine: Complex Systems in Human Disease and Therapeutics; Harvard University Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Ahmedt-Aristizabal, D.; Armin, M.A.; Denman, S.; Fookes, C.; Petersson, L. Graph-based deep learning for medical diagnosis and analysis: Past, present and future. Sensors 2021, 21, 4758. [Google Scholar] [CrossRef] [PubMed]
- Jaremko, J.L.; Felfeliyan, B.; Hareendranathan, A.; Thejeel, B.; Vanessa, Q.-L.; Østergaard, M.; Conaghan, P.G.; Lambert, R.G.W.; Ronsky, J.L.; Maksymowych, W.P. Volumetric Quantitative Measurement of Hip Effusions by Manual Versus Automated Artificial Intelligence Techniques: An Omeract Preliminary Validation Study, 3rd ed.; Elsevier: Amsterdam, The Netherlands, 2021; Volume 51, pp. 623–626. [Google Scholar]
- Banerjee, I.; Madhavan, S.; Goldman, R.E.; Rubin, D.L. Intelligent word embeddings of free-text radiology reports. In Proceedings of the AMIA Annual Symposium Proceedings, American Medical Informatics Association, Washington, DC, USA, 4–8 November 2017; p. 411. [Google Scholar]
- Elkin, P.L.; Froehling, D.; Wahner-Roedler, D.; Trusko, B.; Welsh, G.; Ma, H.; Asatryan, A.X.; Tokars, J.I.; Rosenbloom, S.T.; Brown, S.H. NLP-Based Identification of Pneumonia Cases from Free-Text Radiological Reports; American Medical Informatics Association: Bethesda, MD, USA, 2008; p. 172. [Google Scholar]
- Garla, V.; Taylor, C.; Brandt, C. Semi-supervised clinical text classification with Laplacian SVMs: An application to cancer case management. J. Biomed. Inform. 2013, 46, 869–875. [Google Scholar] [CrossRef] [PubMed]
- Martinez, D.; Ananda-Rajah, M.R.; Suominen, H.; Slavin, M.A.; Thursky, K.A.; Cavedon, L. Automatic detection of patients with invasive fungal disease from free-text computed tomography (CT) scans. J. Biomed. Inform. 2015, 53, 251–260. [Google Scholar] [CrossRef]
- Stewart, R.; Velupillai, S. Applied natural language processing in mental health big data. Neuropsychopharmacology 2021, 46, 252. [Google Scholar] [CrossRef]
- Rost, B.; Radivojac, P.; Bromberg, Y. Protein function in precision medicine: Deep understanding with machine learning. FEBS Lett. 2016, 590, 2327–2341. [Google Scholar] [CrossRef]
- Alabi, R.O.; Almangush, A.; Elmusrati, M.; Mäkitie, A.A. Deep machine learning for oral cancer: From precise diagnosis to precision medicine. Front. Oral Health 2022, 2, 794248. [Google Scholar] [CrossRef] [PubMed]
- Carlisle, A.; Caceres, I.; Mehta, S.; Schindler, J.; Sharma, J. A combined machine learning and bioinformatic analysis approach identifies biological pathways that predict clinical stage and survival outcome in neuroblastoma patients. Cancer Res. 2015, 75, 3758. [Google Scholar] [CrossRef]
- Ge, L.; Chen, Y.; Yan, C.; Zhao, P.; Zhang, P.; Liu, J. Study progress of radiomics with machine learning for precision medicine in bladder cancer management. Front. Oncol. 2019, 9, 1296. [Google Scholar] [CrossRef]
- Hase, T.; Ghosh, S.; Palaniappan, S.K.; Kitano, H. Cancer network medicine. Netw. Med. 2017, 294–323. [Google Scholar] [CrossRef]
- Nakagawa, H.; Fujita, M. Whole genome sequencing analysis for cancer genomics and precision medicine. Cancer Sci. 2018, 109, 513–522. [Google Scholar] [CrossRef]
- Piccialli, F.; Calabrò, F.; Crisci, D.; Cuomo, S.; Prezioso, E.; Mandile, R.; Troncone, R.; Greco, L.; Auricchio, R. Precision medicine and machine learning towards the prediction of the outcome of potential celiac disease. Sci. Rep. 2021, 11, 5683. [Google Scholar] [CrossRef]
- Gökçay Canpolat, A.; Şahin, M. Glucose lowering treatment modalities of type 2 diabetes mellitus. Diabetes Res. Clin. Pract. 2021, 4, 7–27. [Google Scholar]
- Shamji, M.H.; Ollert, M.; Adcock, I.M.; Bennett, O.; Favaro, A.; Sarama, R.; Riggioni, C.; Annesi-Maesano, I.; Custovic, A.; Fontanella, S. EAACI guidelines on environmental science in allergic diseases and asthma–leveraging artificial intelligence and machine learning to develop a causality model in exposomics. Allergy 2023, 78, 1742–1757. [Google Scholar] [CrossRef]
- Pike, F.; Yealy, D.M.; Kellum, J.A.; Huang, D.T.; Barnato, A.E.; Eaton, T.L.; Angus, D.C.; Weissfeld, L.A. Protocolized care for early septic shock (ProCESS) statistical analysis plan. Crit. Care Resusc. 2013, 15, 301–310. [Google Scholar] [CrossRef]
- Norman, C.; Van Nguyen, T.; Névéol, A. Contribution of natural language processing in predicting rehospitalization risk. Med. Care 2017, 55, 781. [Google Scholar] [CrossRef]
- Orangi-Fard, N.; Akhbardeh, A.; Sagreiya, H. Predictive Model for Icu Readmission Based on Discharge Summaries Using Machine Learning and Natural Language Processing, 1st ed.; MDPI: Basel, Switzerland, 2022; p. 10. [Google Scholar]
- Rumshisky, A.; Ghassemi, M.; Naumann, T.; Szolovits, P.; Castro, V.M.; McCoy, T.H.; Perlis, R.H. Predicting early psychiatric readmission with natural language processing of narrative discharge summaries. Transl. Psychiatry 2016, 6, e921. [Google Scholar] [CrossRef]
- Panteli, D.; Legido-Quigley, H.; Reichebner, C.; Ollenschläger, G.; Schäfer, C.; Busse, R. Clinical practice guidelines as a quality strategy. Improv. Healthc. Qual. Eur. 2019, 233. [Google Scholar] [CrossRef]
- Rotter, T.; de Jong, R.B.; Lacko, S.E.; Ronellenfitsch, U.; Kinsman, L. Clinical pathways as a quality strategy. Improv. Healthc. Qual. Eur. 2019, 309. [Google Scholar] [CrossRef]
- Allen, M.; Pearn, K.; Monks, T.; Bray, B.D.; Everson, R.; Salmon, A.; James, M.; Stein, K. Can clinical audits be enhanced by pathway simulation and machine learning? An example from the acute stroke pathway. BMJ Open 2019, 9, e028296. [Google Scholar] [CrossRef] [PubMed]
- Huo, T.; George Jr, T.J.; Guo, Y.; He, Z.; Prosperi, M.; Modave, F.; Bian, J. Explore Care Pathways of Colorectal Cancer Patients with Social Network Analysis. Stud. Health Technol. Inform. 2017, 245, 1270. [Google Scholar] [PubMed]
- Carroll, N.; Richardson, I. Mapping a careflow network to assess the connectedness of connected health. Health Inform. J. 2019, 25, 106–125. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, N.; Ahmed, M.; Basu, S.; Curtin, J.J.; Evans, B.J.; Matheny, M.E.; Nundy, S.; Sendak, M.P.; Shachar, C.; Shah, R.U. Advancing artificial intelligence in health settings outside the hospital and clinic. NAM Perspect. 2020, 2020. [Google Scholar] [CrossRef] [PubMed]
- Lin, Z.; Yang, D.; Yin, X. Patient similarity via joint embeddings of medical knowledge graph and medical entity descriptions. IEEE Access 2020, 8, 156663–156676. [Google Scholar] [CrossRef]
- Rose, S. Intersections of machine learning and epidemiological methods for health services research. Int. J. Epidemiol. 2020, 49, 1763–1770. [Google Scholar] [CrossRef]
- El Emam, K.; Arbuckle, L. Anonymizing Health Data: Case Studies and Methods to Get You Started; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2013. [Google Scholar]
- Bambauer, J.; Muralidhar, K.; Sarathy, R. Fool’s gold: An illustrated critique of differential privacy. Vand. J. Ent. Tech. L. 2013, 16, 701. [Google Scholar]
- Xu, C.; Ren, J.; Zhang, Y.; Qin, Z.; Ren, K. DPPro: Differentially Private High-Dimensional Data Release via Random Projection. IEEE Trans. Inf. Forensics Secur. 2017, 12, 3081–3093. [Google Scholar] [CrossRef]
- Malin, B.; Goodman, K. Between access and privacy: Challenges in sharing health data. Yearb. Med. Inform. 2018, 27, 55–59. [Google Scholar] [CrossRef] [PubMed]
- Koval, A.; Moselle, K. Clinical Context Coding Scheme-Describing Utilisation of Services of Island Health between 2007–2017. In Proceedings of the Conference of the International Population Data Linkage Association, Banf, AB, Canada, 12–14 September 2018. [Google Scholar]
- Chejara, P.; Godfrey, W.W. Comparative Analysis of Community Detection Algorithms; IEEE: Minneapolis, MN, USA, 2017; pp. 1–5. [Google Scholar]
- Niyirora, J.; Aragones, O. Network analysis of medical care services. Health Inform. J 2020, 26, 1631–1658. [Google Scholar] [CrossRef] [PubMed]
- Palmer, R.; Utley, M.; Fulop, N.J.; O’Connor, S. Using visualisation methods to analyse referral networks within community health care among patients aged 65 years and over. Health Inform. J. 2020, 26, 354–375. [Google Scholar] [CrossRef]
- Khazaee, A.; Ebrahimzadeh, A.; Babajani-Feremi, A. Application of pattern recognition and graph theoretical approaches to analysis of brain network in Alzheimer’s disease. J. Med. Imaging Health Inform. 2015, 5, 1145–1155. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patient_ID | Service Class ID |
|---|---|
| P1 | 22 |
| P2 | 34 |
| P3 | 161 |
| P4 | 22 |
| P1 | 13 |
| … | … |
| P5 | 243 |
| SC_ID | Service Class Name | CID | IWD | EWD | WD |
|---|---|---|---|---|---|
| 22 | MHSU-Addictions-Clinic-Adult-Ambulatory | 1-2 | 369 | 2158 | 2527 |
| 34 | MHSU-Addictions-Clinical Intake-Adult | 1-2 | 367 | 1615 | 1982 |
| 161 | Addictions Medicine Specialist Consultation to Acute Care | 1-2 | 293 | 2318 | 2611 |
| 23 | MHSU-Addictions-Withdrawal Management (Detox)-Adults | 1-2 | 201 | 682 | 883 |
| 13 | MHSU-Assertive Community Treatment (ACT)-Adult | 1-2 | 196 | 1209 | 1405 |
| 203 | Overdose-Related Services | 1-2 | 185 | 812 | 997 |
| 243 | MHSU-Addictions-Rapid/High-Intensity Assessment and Follow-Up | 1-2 | 185 | 895 | 1080 |
| 21 | MHSU-Addictions-Sobering and Assessment Centre | 1-2 | 162 | 592 | 754 |
| 14 | MHSU-Addictions-Outreach and Intensive Case Management-Adult | 1-2 | 144 | 552 | 696 |
| 29 | MHSU-Residential Care-Licensed | 1-2 | 113 | 1040 | 1153 |
| 24 | MHSU-Addictions-Post-Withdrawal Stabilization-Residential-Adults | 1-2 | 108 | 351 | 459 |
| 26 | MHSU-Residential Care-Lower-Level Support | 1-2 | 108 | 707 | 815 |
| 10 | Tertiary Specialized Residential Care-Adult | 1-2 | 75 | 338 | 413 |
| 20 | MHSU-Rehab Services-Adult-Moderate Intensity | 1-2 | 45 | 256 | 301 |
| 270 | COVID-19 Outreach Assessment | 1-2 | 29 | 136 | 165 |
| 272 | COVID-19 Outreach Assessment Team-Provider | 1-2 | 28 | 43 | 71 |
| 81 | MHSU-Crisis Response-Walk-In | 1-2 | 26 | 192 | 218 |
| 171 | MHSU-Developmental Disabilities-Adults-Assessment and Support-Ambulatory | 1-2 | 23 | 211 | 234 |
| 175 | MHSU-Addictions-Supervised Consumption-Ambulatory | 1-2 | 21 | 70 | 91 |
| 30 | MHSU-Crisis-Residential | 1-2 | 20 | 87 | 107 |
| 3 | MHSU-Adult Community Outreach-Moderate to High Risk | 1-2 | 17 | 136 | 153 |
| 275 | COVID-19 MHSU Health Monitoring | 1-2 | 15 | 40 | 55 |
| 74 | Adjunctive Therapies in Acute Care-Respiratory | 1-2 | 4 | 15 | 19 |
| 158 | Telehealth-Miscellaneous | 1-2 | 2 | 12 | 14 |
| SC_ID | Service Name | CID | IWD | EWD | WD |
|---|---|---|---|---|---|
| 13 | MHSU-Assertive Community Treatment (ACT)-Adult | 2-2 | 63 | 1342 | 1405 |
| 26 | MHSU-Residential Care-Lower-Level Support | 2-2 | 53 | 762 | 815 |
| 29 | MHSU-Residential Care-Licensed | 2-2 | 52 | 1101 | 1153 |
| 10 | Tertiary Specialized Residential Care-Adult | 2-2 | 34 | 379 | 413 |
| 20 | MHSU-Rehab Services-Adult-Moderate Intensity | 2-2 | 28 | 273 | 301 |
| 81 | MHSU-Crisis Response-Walk-In | 2-2 | 11 | 207 | 218 |
| 3 | MHSU-Adult Community Outreach-Moderate to High Risk | 2-2 | 8 | 145 | 153 |
| 74 | Adjunctive Therapies in Acute Care-Respiratory | 2-2 | 3 | 16 | 19 |
| 14 | MHSU-Addictions-Outreach and Intensive Case Management-Adult | 2-3 | 32 | 664 | 696 |
| 243 | MHSU-Addictions-Rapid/High-Intensity Assessment and Follow-Up | 2-3 | 31 | 1049 | 1080 |
| 270 | COVID-19 Outreach Assessment | 2-3 | 13 | 152 | 165 |
| 272 | COVID-19 Outreach Assessment Team-Provider | 2-3 | 11 | 60 | 71 |
| 275 | COVID-19 MHSU Health Monitoring | 2-3 | 7 | 48 | 55 |
| 30 | MHSU-Crisis-Residential | 2-3 | 6 | 101 | 107 |
| 171 | MHSU-Developmental Disabilities-Adults-Assessment and Support-Ambulatory | 2-3 | 6 | 228 | 234 |
| 175 | MHSU-Addictions-Supervised Consumption-Ambulatory | 2-3 | 6 | 85 | 91 |
| 34 | MHSU-Addictions-Clinical Intake-Adult | 2-4 | 256 | 1726 | 1982 |
| 22 | MHSU-Addictions-Clinic-Adult-Ambulatory | 2-4 | 247 | 2280 | 2527 |
| 161 | Addictions Medicine Specialist Consultation to Acute Care | 2-4 | 189 | 2422 | 2611 |
| 23 | MHSU-Addictions-Withdrawal Management (Detox)-Adults | 2-4 | 148 | 735 | 883 |
| 203 | Overdose-Related Services | 2-4 | 113 | 884 | 997 |
| 21 | MHSU-Addictions-Sobering and Assessment Centre | 2-4 | 103 | 651 | 754 |
| 24 | MHSU-Addictions-Post-Withdrawal Stabilization-Residential-Adults | 2-4 | 86 | 373 | 459 |
| 158 | Telehealth-Miscellaneous | 2-4 | 2 | 12 | 14 |
| Category | SC_ID | Service Name | CID | IWD | EWD | WD |
|---|---|---|---|---|---|---|
| High intensity community-based treatment for people with severe psychiatric illness | 13 | MHSU-Assertive Community Treatment (ACT)-Adult | 3-2 | 24 | 1381 | 1405 |
| 10 | Tertiary Specialized Residential Care-Adult | 3-2 | 20 | 393 | 413 | |
| 4 | ||||||
| Lower intensity community-based treatment for people with severe psychiatric illness | 26 | MHSU-Residential Care-Lower-Level Support | 3-3 | 33 | 782 | 815 |
| 29 | MHSU-Residential Care-Licensed | 3-3 | 29 | 1124 | 1153 | |
| 20 | MHSU-Rehab Services-Adult-Moderate Intensity | 3-3 | 18 | 283 | 301 | |
| 81 | MHSU-Crisis Response-Walk-In | 3-3 | 8 | 210 | 218 | |
| Addiction-outreach focused support for high risk/high needs addictions problems | 14 | MHSU-Addictions-Outreach and Intensive Case Management-Adult | 3-4 | 24 | 672 | 696 |
| 243 | MHSU-Addictions-Rapid/High-Intensity Assessment and Follow-Up | 3-4 | 23 | 1057 | 1080 | |
| 270 | COVID-19 Outreach Assessment | 3-4 | 11 | 154 | 165 | |
 | 30 | MHSU-Crisis-Residential | 3-5 | 3 | 104 | 107 |
| 171 | MHSU-Developmental Disabilities-Adults-Assessment and Support-Ambulatory | 3-5 | 3 | 231 | 234 | |
| 272 | COVID-19 Outreach Assessment Team-Provider | 3-5 | 3 | 68 | 71 | |
| 275 | COVID-19 MHSU Health Monitoring | 3-5 | 3 | 52 | 55 | |
| Additions ongoing support: harm reduction and/or rehab recovery. | 34 | MHSU-Addictions-Clinical Intake-Adult | 3-6 | 256 | 1726 | 1982 |
| 22 | MHSU-Addictions-Clinic-Adult-Ambulatory | 3-6 | 247 | 2280 | 2527 | |
| 161 | Addictions Medicine Specialist Consultation to Acute Care | 3-6 | 189 | 2422 | 2611 | |
| 23 | MHSU-Addictions-Withdrawal Management (Detox)-Adults | 3-6 | 148 | 735 | 883 | |
| 203 | Overdose-Related Services | 3-6 | 113 | 884 | 997 | |
| 21 | MHSU-Addictions-Sobering and Assessment Centre | 3-6 | 103 | 651 | 754 | |
| 24 | MHSU-Addictions-Post-Withdrawal Stabilization-Residential-Adults | 3-6 | 86 | 373 | 459 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bambi, J.; Santoso, Y.; Sadri, H.; Moselle, K.; Rudnick, A.; Robertson, S.; Chang, E.; Kuo, A.; Howie, J.; Dong, G.Y.; et al. A Methodological Approach to Extracting Patterns of Service Utilization from a Cross-Continuum High Dimensional Healthcare Dataset to Support Care Delivery Optimization for Patients with Complex Problems. BioMedInformatics 2024, 4, 946-965. https://doi.org/10.3390/biomedinformatics4020053
Bambi J, Santoso Y, Sadri H, Moselle K, Rudnick A, Robertson S, Chang E, Kuo A, Howie J, Dong GY, et al. A Methodological Approach to Extracting Patterns of Service Utilization from a Cross-Continuum High Dimensional Healthcare Dataset to Support Care Delivery Optimization for Patients with Complex Problems. BioMedInformatics. 2024; 4(2):946-965. https://doi.org/10.3390/biomedinformatics4020053
Chicago/Turabian StyleBambi, Jonas, Yudi Santoso, Hanieh Sadri, Ken Moselle, Abraham Rudnick, Stan Robertson, Ernie Chang, Alex Kuo, Joseph Howie, Gracia Yunruo Dong, and et al. 2024. "A Methodological Approach to Extracting Patterns of Service Utilization from a Cross-Continuum High Dimensional Healthcare Dataset to Support Care Delivery Optimization for Patients with Complex Problems" BioMedInformatics 4, no. 2: 946-965. https://doi.org/10.3390/biomedinformatics4020053