


Survey of Multimodal Medical Question Answering

Abstract
:1. Introduction
1.1. Research Questions
- What capabilities and features are offered by MMQA tools and research methods?
- What are the available datasets and tools in the commercial and open source space, and can the datasets be classified according to size?
- How have recent advances in AI influenced the development and application of medical question answering systems, and what are the key challenges in this evolving field?
1.2. Methodology
1.3. Motivation
1.4. Organization
2. Multimodal Medical Question Answering
2.1. Text Analysis and Understanding
2.2. Image Analysis and Understanding
2.3. Video Analysis and Understanding
3. Datasets
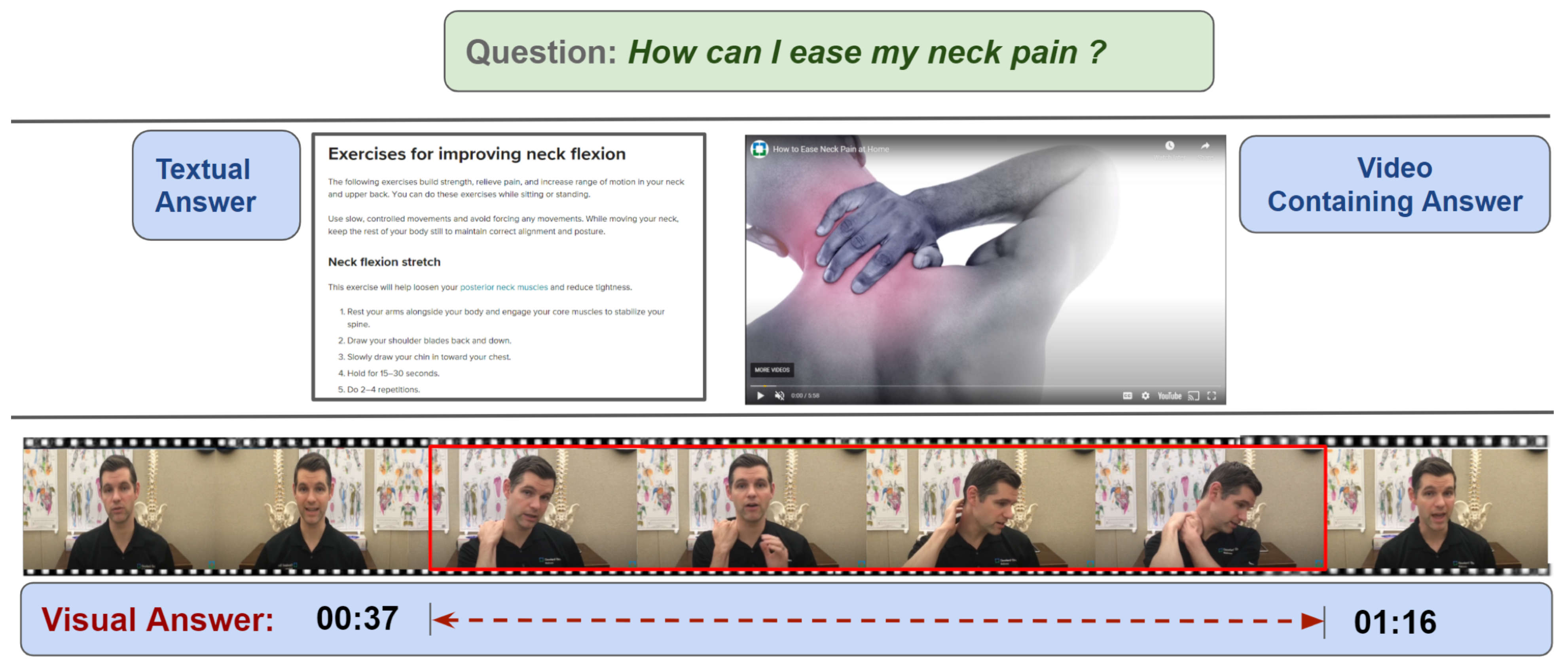
3.1. MedVidQA Dataset

3.2. VQA-Med-2021 Dataset
3.3. SLAKE Dataset
3.4. VQA-Med-2020 Dataset
3.5. PathVQA Dataset
3.6. RadVisDial Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Article Link | Data Link | Dataset Size |
|---|---|---|---|
| MedVidQA [20] | https://arxiv.org/pdf/2201.12888.pdf (accessed on 27 December 2023) | https://doi.org/10.17605/OSF.IO/PC594 (accessed on 27 December 2023) | 6117 videos for MVC, 899 videos for the MVAL task. |
| VQA-Med 2021 [21] | https://ceur-ws.org/Vol-2936/paper-87.pdf (accessed on 27 December 2023) | https://www.aicrowd.com/challenges/imageclef-2021-vqa-med-vqa (accessed on 27 December 2023) | 4500 radiology images |
| SLAKE [22] | https://arxiv.org/abs/2102.09542 (accessed on 27 December 2023) | https://www.med-vqa.com/slake/ (accessed on 27 December 2023) | 642 radiology images |
| VQA-Med 2020 [26] | https://ceur-ws.org/Vol-2696/paper_106.pdf | https://www.aicrowd.com/challenges/imageclef-2020-vqa-med-vqg (accessed on 27 December 2023) | 4000 radiology images |
| PathVQA [24] | https://arxiv.org/abs/2003.10286 (accessed on 27 December 2023) | https://github.com/UCSD-AI4H/PathVQA (accessed on 27 December 2023) | 4998 pathology images |
| RadVisDial [26] | https://aclanthology.org/2020.bionlp-1.6.pdf (accessed on 27 December 2023) | https://physionet.org/content/mimic-cxr/ (accessed on 27 December 2023) | 91,060 radiology images |
| VQA-Med 2019 [26] | https://ceur-ws.org/Vol-2380/paper_272.pdf (accessed on 27 December 2023) | https://www.aicrowd.com/challenges/imageclef-2019-vqa-med (accessed on 27 December 2023) | 4200 radiology images |
| VQA-RAD [27] | https://www.nature.com/articles/sdata2018251 (accessed on 27 December 2023) | https://osf.io/89kps/ (accessed on 27 December 2023) | 315 radiological images |
| VQA-Med 2018 [28] | https://ceur-ws.org/Vol-2125/paper_212.pdf (accessed on 27 December 2023) | https://www.aicrowd.com/challenges/imageclef-2018-vqa-med (accessed on 27 December 2023) | 2866 medical images extracted from PubMed Articles |
| Visual Genome [29] | https://link.springer.com/article/10.1007/s11263-016-0981-7 (accessed on 27 December 2023) | https://https://visualgenome.org (accessed on 27 December 2023) | 101,174 images, 1.7 million questions |
| OK-VQA [30] | https://link.springer.com/article/10.1007/s11263-016-0981-7 (accessed on 27 December 2023) | https://https:/https://okvqa.allenai.org (accessed on 27 December 2023) | 14,031 images, 14,055 questions |
3.7. VQA-Med-2019 Dataset
3.8. VQA-RAD Dataset
3.9. VQA-Med-2018 Dataset
3.10. Visual Genome Dataset
3.11. OK-VQA Dataset
4. Methods Used in Multimodal Medical Question Answering Research
Performance Metrics of Existing Methods
| Name | Article Link | Datasets |
|---|---|---|
| MedFuseNet [38] | https://www.nature.com/articles/s41598-021-98390-1 (accessed on 27 December 2023) | MED-VQA, PathVQA |
| MMBERT [39] | https://arxiv.org/pdf/2104.01394.pdf (accessed on 27 December 2023) | VQA Med 2019, VQA-RAD |
| QC-MLB [16] | https://ieeexplore.ieee.org/abstract/document/9024133 (accessed on 27 December 2023) | VQA Med 2019 |
| KEML [40] | https://link.springer.com/chapter/10.1007/978-3-030-63820-7_22 (accessed on 27 December 2023) | VQA Med 2019 |
| CGMVQA [41] | https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9032109 (accessed on 27 December 2023) | VQA Med 2019 |
| Hanlin [42] | https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9032109 (accessed on 27 December 2023) | VQA Med 2019 |
| Minhvu [43] | https://ceur-ws.org/Vol-2380/paper_64.pdf (accessed on 27 December 2023) | VQA Med 2019 |
| TUA1 [44] | https://ceur-ws.org/Vol-2380/paper_190.pdf (accessed on 27 December 2023) | VQA Med 2019 |
| QCMLB [45] | https://ieeexplore.ieee.org/document/9024133 (accessed on 27 December 2023) | VQA Med 2019 |
| UMMS [46] | https://ceur-ws.org/Vol-2380/paper_123.pdf (accessed on 27 December 2023) | VQA Med 2019 |
| IBM Research AI [47] | https://ceur-ws.org/Vol-2380/paper_112.pdf (accessed on 27 December 2023) | VQA Med 2019 |
| LIST [48] | https://ceur-ws.org/Vol-2380/paper_124.pdf (accessed on 27 December 2023) | VQA Med 2019 |
| TURNER.JCE [49] | https://ceur-ws.org/Vol-2380/paper_116.pdf (accessed on 27 December 2023) | VQA Med 2019 |
| JUST19 [50] | https://ceur-ws.org/Vol-2380/paper_125.pdf (accessed on 27 December 2023) | VQA Med 2019 |
| Team_PwC_Med [51] | https://ceur-ws.org/Vol-2380/paper_147.pdf (accessed on 27 December 2023) | VQA Med 2019 |
| Techno [52] | https://ceur-ws.org/Vol-2380/paper_117.pdf (accessed on 27 December 2023) | VQA Med 2019 |
| Gasmi [53] | https://www.tandfonline.com/doi/full/10.1080/01969722.2021.2018543 (accessed on 27 December 2023) | VQA Med 2019 |
| Xception-GRU [54] | https://ceur-ws.org/Vol-2380/paper_127.pdf (accessed on 27 December 2023) | VQA Med 2019 |
| Thanki [55] | https://ceur-ws.org/Vol-2380/paper_167.pdf (accessed on 27 December 2023) | VQA Med 2019 |
| Chakri [56] | https://ieeexplore.ieee.org/document/8987108 (accessed on 27 December 2023) | VQA Med 2018 |
| UMMS [46] | https://ceur-ws.org/Vol-2125/paper_212.pdf (accessed on 27 December 2023) | VQA Med 2018 |
| TU [57] | https://ceur-ws.org/Vol-2125/paper_107.pdf (accessed on 27 December 2023) | VQA Med 2018 |
| HQS [34] | https://www.sciencedirect.com/science/article/abs/pii/S0957417420307697?via%3Dihub (accessed on 27 December 2023) | VQA Med 2018 |
| MMQ-VQA [58] | https://link.springer.com/chapter/10.1007/978-3-030-87240-3_7 (accessed on 27 December 2023) | PathVQA, VQA-RAD |
| NLM [59] | https://ceur-ws.org/Vol-2125/paper_165.pdf (accessed on 27 December 2023) | VQA Med 2018 |
| JUST [60] | https://ceur-ws.org/Vol-2125/paper_171.pdf (accessed on 27 December 2023) | VQA Med 2018 |
| FSTT [61] | https://ceur-ws.org/Vol-2125/paper_159.pdf (accessed on 27 December 2023) | VQA Med 2018 |
| AIML [62] | https://ceur-ws.org/Vol-2696/paper_78.pdf (accessed on 27 December 2023) | VQA Med 2020 |
| TheInceptionTeam [63] | https://ceur-ws.org/Vol-2696/paper_69.pdf (accessed on 27 December 2023) | VQA Med 2020 |
| Bumjun-jung [64] | https://ceur-ws.org/Vol-2696/paper_87.pdf (accessed on 27 December 2023) | VQA Med 2020 |
| HCP-MIC [65] | https://ceur-ws.org/Vol-2696/paper_74.pdf (accessed on 27 December 2023) | VQA Med 2020 |
| NLM [66] | https://ceur-ws.org/Vol-2696/paper_98.pdf (accessed on 27 December 2023) | VQA Med 2020 |
| HARENDRAKV [67] | https://ceur-ws.org/Vol-2696/paper_62.pdf (accessed on 27 December 2023) | VQA Med 2020 |
| Shengyan [68] | https://ceur-ws.org/Vol-2696/paper_73.pdf (accessed on 27 December 2023) | VQA Med 2020 |
| Kdevqa [69] | https://ceur-ws.org/Vol-2696/paper_81.pdf (accessed on 27 December 2023) | VQA Med 2020 |
| SYSU-HCP [70] | https://ceur-ws.org/Vol-2936/paper-99.pdf (accessed on 27 December 2023) | VQA Med 2021 |
| Yunnan [71] | https://ceur-ws.org/Vol-2936/paper-120.pdf (accessed on 27 December 2023) | VQA Med 2021 |
| TeamS [72] | https://ceur-ws.org/Vol-2936/paper-98.pdf (accessed on 27 December 2023) | VQA Med 2021 |
| Lijie [73] | https://ceur-ws.org/Vol-2936/paper-104.pdf (accessed on 27 December 2023) | VQA Med 2021 |
| IALab_PUC [74] | https://ceur-ws.org/Vol-2936/paper-113.pdf (accessed on 27 December 2023) | VQA Med 2021 |
| TAM [75] | https://ceur-ws.org/Vol-2936/paper-106.pdf (accessed on 27 December 2023) | VQA Med 2021 |
| Sheerin [76] | https://ceur-ws.org/Vol-2936/paper-110.pdf (accessed on 27 December 2023) | VQA Med 2021 |
| CMSA [77] | https://dl.acm.org/doi/10.1145/3460426.3463584 (accessed on 27 December 2023) | VQA-RAD |
| QCR, TCR [78] | https://www4.comp.polyu.edu.hk/~csxmwu/papers/MM-2020-Med-VQA.pdf (accessed on 27 December 2023) | VQA-RAD |
| MMQ [79] | https://arxiv.org/abs/2105.08913 (accessed on 27 December 2023) | VQA-RAD |
| MEVF [80] | https://research.monash.edu/en/publications/overcoming-data-limitation-in-medical-visual-question-answering (accessed on 27 December 2023) | VQA-RAD |
| CPRD [81] | https://miccai2021.org/openaccess/paperlinks/2021/09/01/113-Paper1235.html (accessed on 27 December 2023) | VQA-RAD, SLAKE |
| Silva [82] | https://www.sciencedirect.com/science/article/pii/S2667305323000467 (accessed on 27 December 2023) | VQA-Med |
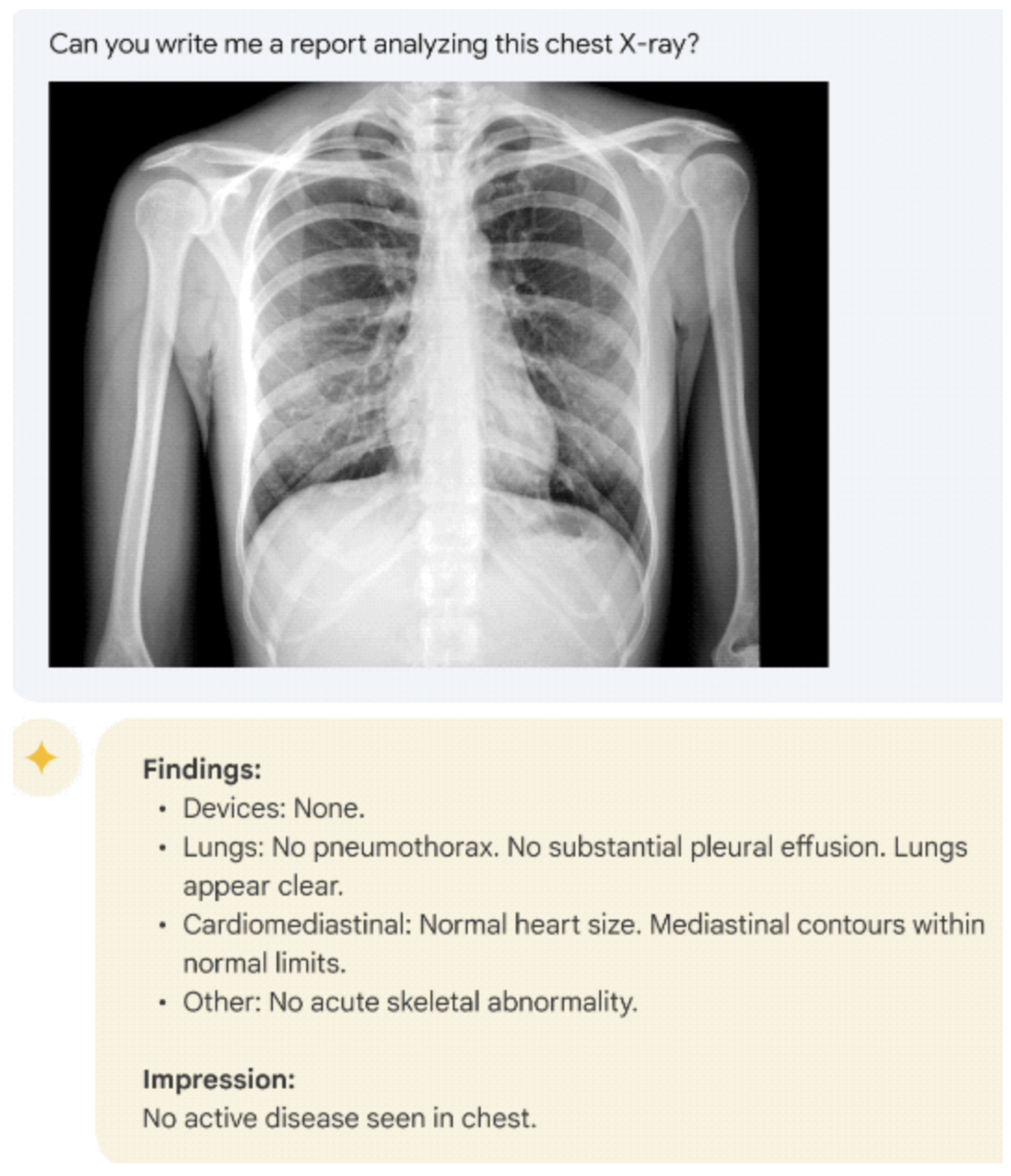
5. Large Language Models for Medical Question Answering
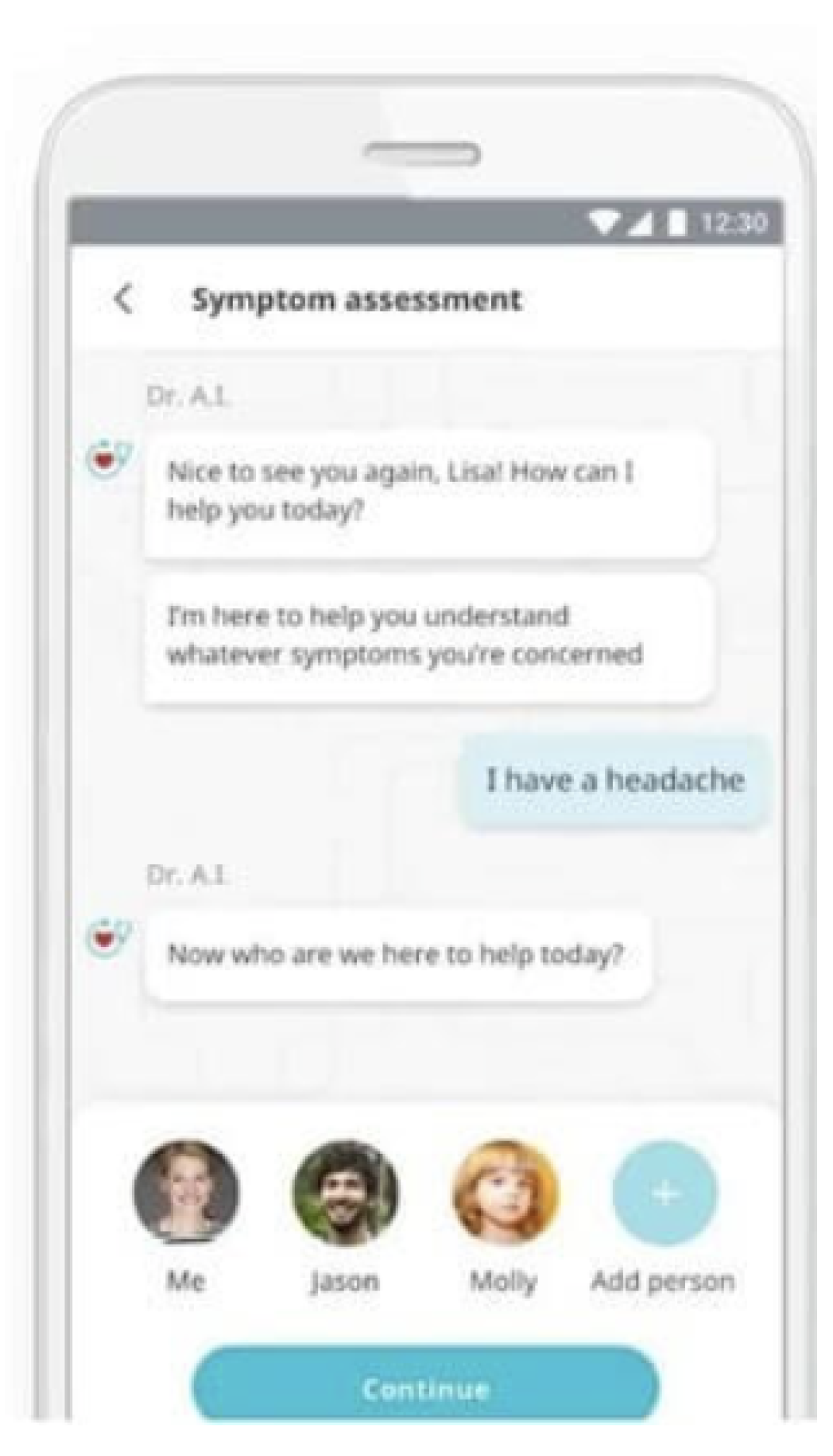
6. Tools and Services
6.1. Clinical Research
6.2. Investment
Startups
7. Challenges of the Research Field
- Limited annotated medical data. Annotated medical imaging datasets for VQA are relatively small compared with general visual question answering datasets;
- Domain-specific knowledge representation. Medical VQA requires understanding complex medical concepts, terminology, and anatomical structures;
- Interpretable and explainable answers. In medical applications, interpretability and explainability of the VQA models are critical;
- Handling variability and uncertainty. Medical imaging exhibits significant variability due to variations in patient demographics, imaging techniques, and pathology;
- Multimodal fusion and alignment. Medical VQA requires effectively fusing information from both the visual and textual modalities;
- Generalization across tasks and domains. Medical VQA models trained on one medical imaging modality or clinical task may not generalize well to other modalities or tasks;
- Ethical considerations and bias. As with any AI application in healthcare, addressing ethical considerations and mitigating biases is important in medical VQA;
- Real-time performance. In clinical settings, real-time or near-real-time performance is often required for VQA systems.
8. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| NLP | Natural Language Processing |
| VQA | Visual Question Answering |
| MMQA | Multimodal Medical Question Answering |
| MVQA | Medical Visual Question Answering |
| AI | Artificial Intelligence |
| FCM | Fuzzy Cognitive Maps |
| BioASQ | Biomedical Semantic Indexing and Question Answering |
| MedVidQA | Medical Video Question Answering Challenge |
| BERT | Bidirectional Encoder Representations from Transformers |
| ABP | American Board of Pathology |
References
- Stylios, C.D.; Georgopoulos, V.C.; Malandraki, G.A.; Chouliara, S. Fuzzy cognitive map architectures for medical decision support systems. Appl. Soft Comput. 2008, 8, 1243–1251. [Google Scholar] [CrossRef]
- Lee, P.; Goldberg, C.; Kohane, I. The AI Revolution in Medicine: GPT-4 and Beyond; Pearson: London, UK, 2023. [Google Scholar]
- Harman, D.K. The First Text Retrieval Conference (TREC-1); US Department of Commerce, National Institute of Standards and Technology: Gaithersburg, MI, USA, 1993; Volume 500.
- Partalas, I.; Gaussier, E.; Ngomo, A.C.N. Results of the first BioASQ workshop. In Proceedings of the BioASQ@ CLEF, Valencia, Spain, 27 September 2013; pp. 1–8. [Google Scholar]
- Malinowski, M.; Fritz, M. Towards a visual turing challenge. arXiv 2014, arXiv:1410.8027. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Gupta, D.; Demner-Fushman, D. Overview of the MedVidQA 2022 shared task on medical video question-answering. In Proceedings of the 21st Workshop on Biomedical Language Processing, Dublin, Ireland, 26 May 2022; pp. 264–274. [Google Scholar]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Torrey, L.; Shavlik, J. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Lehman, L.w.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Anthony Celi, L.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Pollard, T.J.; Johnson, A.E.; Raffa, J.D.; Celi, L.A.; Mark, R.G.; Badawi, O. The eICU Collaborative Research Database, a freely available multi-center database for critical care research. Sci. Data 2018, 5, 1–13. [Google Scholar] [CrossRef] [PubMed]
- CHiQA. Available online: https://chiqa.nlm.nih.gov/welcome (accessed on 18 June 2023).
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K.; et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 590–597. [Google Scholar]
- Ben Abacha, A.; Demner-Fushman, D. A Question-Entailment Approach to Question Answering. BMC Bioinform. 2019, 20, 511. [Google Scholar] [CrossRef] [PubMed]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Mathew, M.; Karatzas, D.; Jawahar, C. Docvqa: A dataset for vqa on document images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikola, HI, USA, 5–9 January 2021; pp. 2200–2209. [Google Scholar]
- Vivoli, E.; Biten, A.F.; Mafla, A.; Karatzas, D.; Gomez, L. MUST-VQA: MUltilingual Scene-Text VQA. arXiv 2022, arXiv:2209.06730. [Google Scholar]
- Ding, Y.; Luo, S.; Chung, H.; Han, S.C. VQA: A New Dataset for Real-World VQA on PDF Documents. arXiv 2023, arXiv:2304.06447. [Google Scholar]
- Gupta, D.; Attal, K.; Demner-Fushman, D. A dataset for medical instructional video classification and question answering. Sci. Data 2023, 10, 158. [Google Scholar] [CrossRef]
- Ben Abacha, A.; Sarrouti, M.; Demner-Fushman, D.; Hasan, S.A.; Müller, H. Overview of the VQA-Med Task at ImageCLEF 2021: Visual Question Answering and Generation in the Medical Domain. In Proceedings of the CLEF 2021 Working Notes, Bucharest, Romania, 21–24 September 2021. [Google Scholar]
- Liu, B.; Zhan, L.M.; Xu, L.; Ma, L.; Yang, Y.; Wu, X.M. Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 1650–1654. [Google Scholar]
- Abacha, A.B.; Datla, V.V.; Hasan, S.A.; Demner-Fushman, D.; Müller, H. Overview of the VQA-Med Task at ImageCLEF 2020: Visual Question Answering and Generation in the Medical Domain. In Proceedings of the CLEF (Working Notes), Thessaloniki, Greece, 17 July 2020. [Google Scholar]
- He, X.; Zhang, Y.; Mou, L.; Xing, E.; Xie, P. Pathvqa: 30000+ questions for medical visual question answering. arXiv 2020, arXiv:2003.10286. [Google Scholar]
- Johnson, A.E.; Pollard, T.J.; Greenbaum, N.R.; Lungren, M.P.; Deng, C.y.; Peng, Y.; Lu, Z.; Mark, R.G.; Berkowitz, S.J.; Horng, S. MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs. arXiv 2019, arXiv:1901.07042. [Google Scholar]
- Abacha, A.B.; Hasan, S.A.; Datla, V.V.; Liu, J.; Demner-Fushman, D.; Müller, H. VQA-Med: Overview of the medical visual question answering task at ImageCLEF 2019. In Proceedings of the CLEF (Working Notes), Lugano, Switzerland, 9–12 September 2019; Volume 2. [Google Scholar]
- Lau, J.J.; Gayen, S.; Ben Abacha, A.; Demner-Fushman, D. A dataset of clinically generated visual questions and answers about radiology images. Sci. Data 2018, 5, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Hasan, S.A.; Ling, Y.; Farri, O.; Liu, J.; Müller, H.; Lungren, M.P. Overview of ImageCLEF 2018 Medical Domain Visual Question Answering Task. In Proceedings of the CLEF (Working Notes), Avignon, France, 10–14 September 2018. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Marino, K.; Rastegari, M.; Farhadi, A.; Mottaghi, R. Ok-vqa: A visual question answering benchmark requiring external knowledge. In Proceedings of the IEEE/cvf Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3195–3204. [Google Scholar]
- Depeursinge, A.; Müller, H. Fusion techniques for combining textual and visual information retrieval. In ImageCLEF: Experimental Evaluation in Visual Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2010; pp. 95–114. [Google Scholar]
- Pan, H.; He, S.; Zhang, K.; Qu, B.; Chen, C.; Shi, K. Muvam: A multi-view attention-based model for medical visual question answering. arXiv 2021, arXiv:2107.03216. [Google Scholar]
- Yusuf, A.A.; Chong, F.; Xianling, M. An analysis of graph convolutional networks and recent datasets for visual question answering. Artif. Intell. Rev. 2022, 55, 6277–6300. [Google Scholar] [CrossRef]
- Gupta, D.; Suman, S.; Ekbal, A. Hierarchical deep multi-modal network for medical visual question answering. Expert Syst. Appl. 2021, 164, 113993. [Google Scholar] [CrossRef]
- Kuo, W.; Piergiovanni, A.; Kim, D.; Luo, X.; Caine, B.; Li, W.; Ogale, A.; Zhou, L.; Dai, A.; Chen, Z.; et al. Mammut: A simple architecture for joint learning for multimodal tasks. arXiv 2023, arXiv:2303.16839. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Li, M.; Cai, W.; Liu, R.; Weng, Y.; Zhao, X.; Wang, C.; Chen, X.; Liu, Z.; Pan, C.; Li, M.; et al. Ffa-ir: Towards an explainable and reliable medical report generation benchmark. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), Online, 15 December 2021. [Google Scholar]
- Sharma, D.; Purushotham, S.; Reddy, C.K. MedFuseNet: An attention-based multimodal deep learning model for visual question answering in the medical domain. Sci. Rep. 2021, 11, 19826. [Google Scholar] [CrossRef]
- Khare, Y.; Bagal, V.; Mathew, M.; Devi, A.; Priyakumar, U.D.; Jawahar, C. Mmbert: Multimodal bert pretraining for improved medical vqa. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 1033–1036. [Google Scholar]
- Zheng, W.; Yan, L.; Wang, F.Y.; Gou, C. Learning from the guidance: Knowledge embedded meta-learning for medical visual question answering. In Proceedings of the Neural Information Processing: 27th International Conference, ICONIP 2020, Bangkok, Thailand, 18–22 November 2020; Proceedings, Part IV 27. Springer: Berlin/Heidelberg, Germany, 2020; pp. 194–202. [Google Scholar]
- Ren, F.; Zhou, Y. Cgmvqa: A new classification and generative model for medical visual question answering. IEEE Access 2020, 8, 50626–50636. [Google Scholar] [CrossRef]
- Yan, X.; Li, L.; Xie, C.; Xiao, J.; Gu, L. Zhejiang University at ImageCLEF 2019 Visual Question Answering in the Medical Domain. In Proceedings of the Conference and Labs of the Evaluation Forum, Lugano, Switzerland, 9–12 September 2019. [Google Scholar]
- Vu, M.; Sznitman, R.; Nyholm, T.; Löfstedt, T. Ensemble of streamlined bilinear visual question answering models for the imageclef 2019 challenge in the medical domain. In Proceedings of the CLEF 2019—Conference and Labs of the Evaluation Forum, Lugano, Switzerland, 9–12 September 2019; Volume 2380. [Google Scholar]
- Zhou, Y.; Kang, X.; Ren, F. TUA1 at ImageCLEF 2019 VQA-Med: A Classification and Generation Model based on Transfer Learning. In Proceedings of the Conference and Labs of the Evaluation Forum, Lugano, Switzerland, 9–12 September 2019. [Google Scholar]
- Vu, M.H.; Löfstedt, T.; Nyholm, T.; Sznitman, R. A Question-Centric Model for Visual Question Answering in Medical Imaging. IEEE Trans. Med. Imaging 2020, 39, 2856–2868. [Google Scholar] [CrossRef]
- Shi, L.; Liu, F.; Rosen, M.P. Deep Multimodal Learning for Medical Visual Question Answering. In Proceedings of the CLEF (Working Notes), Lugano, Switzerland, 13 May 2019. [Google Scholar]
- Kornuta, T.; Rajan, D.; Shivade, C.P.; Asseman, A.; Ozcan, A.S. Leveraging Medical Visual Question Answering with Supporting Facts. arXiv 2019, arXiv:1905.12008. [Google Scholar]
- Allaouzi, I.; Ahmed, M.B.; Benamrou, B. An Encoder-Decoder Model for Visual Question Answering in the Medical Domain. In Proceedings of the CLEF (Working Notes), Lugano, Switzerland, 13 May 2019. [Google Scholar]
- Turner, A.; Spanier, A.B. LSTM in VQA-Med, is It Really Needed? JCE Study on the ImageCLEF 2019 Dataset. In Proceedings of the Conference and Labs of the Evaluation Forum, Lugano, Switzerland, 9–12 September 2019. [Google Scholar]
- Al-Sadi, A.; Talafha, B.; Al-Ayyoub, M.; Jararweh, Y.; Costen, F. JUST at ImageCLEF 2019 Visual Question Answering in the Medical Domain. In Proceedings of the Conference and Labs of the Evaluation Forum, Lugano, Switzerland, 9–12 September 2019. [Google Scholar]
- Bansal, M.; Gadgil, T.; Shah, R.; Verma, P. Medical Visual Question Answering at Image CLEF 2019- VQA Med. In Proceedings of the Conference and Labs of the Evaluation Forum, Lugano, Switzerland, 9–12 September 2019. [Google Scholar]
- Bounaama, R.; Abderrahim, M.E.A. Tlemcen University at ImageCLEF 2019 Visual Question Answering Task. In Proceedings of the Working Notes of CLEF 2019—Conference and Labs of the Evaluation Forum, Lugano, Switzerland, 9–12 September 2019. [Google Scholar]
- Gasmi, K.; Ltaifa, I.B.; Lejeune, G.; Alshammari, H.; Ammar, L.B.; Mahmood, M.A. Optimal deep neural network-based model for answering visual medical question. Cybern. Syst. 2022, 53, 403–424. [Google Scholar] [CrossRef]
- Liu, S.; Ou, X.; Che, J.; Zhou, X.; Ding, H. An Xception-GRU Model for Visual Question Answering in the Medical Domain. In Proceedings of the CLEF (Working Notes), Lugano, Switzerland, 13 May 2019. [Google Scholar]
- Thanki, A.; Makkithaya, K. MIT Manipal at ImageCLEF 2019 Visual Question Answering in Medical Domain. In Proceedings of the Conference and Labs of the Evaluation Forum, Lugano, Switzerland, 9–12 September 2019. [Google Scholar]
- Ambati, R.; Reddy Dudyala, C. A Sequence-to-Sequence Model Approach for ImageCLEF 2018 Medical Domain Visual Question Answering. In Proceedings of the 2018 15th IEEE India Council International Conference (INDICON), Amrita Vishwa Vidyapeetham, India, 15–18 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Zhou, Y.; Kang, X.; Ren, F. Employing Inception-Resnet-v2 and Bi-LSTM for Medical Domain Visual Question Answering. In Proceedings of the Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 10–14 September 2018. [Google Scholar]
- Do, T.; Nguyen, B.X.; Tjiputra, E.; Tran, M.; Tran, Q.D.; Nguyen, A. Multiple meta-model quantifying for medical visual question answering. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part V 24. Springer: Berlin/Heidelberg, Germany, 2021; pp. 64–74. [Google Scholar]
- Abacha, A.B.; Gayen, S.; Lau, J.J.; Rajaraman, S.; Demner-Fushman, D. NLM at ImageCLEF 2018 Visual Question Answering in the Medical Domain. In Proceedings of the Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 10–14 September 2018. [Google Scholar]
- Talafha, B.; Al-Ayyoub, M. JUST at VQA-Med: A VGG-Seq2Seq Model. In Proceedings of the Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 10–14 September 2018. [Google Scholar]
- Allaouzi, I.; Ahmed, M.B. Deep Neural Networks and Decision Tree Classifier for Visual Question Answering in the Medical Domain. In Proceedings of the Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 10–14 September 2018. [Google Scholar]
- Liao, Z.; Wu, Q.; Shen, C.; van den Hengel, A.; Verjans, J.W. AIML at VQA-Med 2020: Knowledge Inference via a Skeleton-based Sentence Mapping Approach for Medical Domain Visual Question Answering. In Proceedings of the Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Al-Sadi, A.; Al-Theiabat, H.; Al-Ayyoub, M. The Inception Team at VQA-Med 2020: Pretrained VGG with Data Augmentation for Medical VQA and VQG. In Proceedings of the Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Jung, B.; Gu, L.; Harada, T. bumjun_jung at VQA-Med 2020: VQA Model Based on Feature Extraction and Multi-Modal Feature Fusion. In Proceedings of the Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Chen, G.; Gong, H.; Li, G. HCP-MIC at VQA-Med 2020: Effective Visual Representation for Medical Visual Question Answering. In Proceedings of the Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Sarrouti, M. NLM at VQA-Med 2020: Visual Question Answering and Generation in the Medical Domain. In Proceedings of the Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Verma, H.; Ramachandran, S. HARENDRAKV at VQA-Med 2020: Sequential VQA with Attention for Medical Visual Question Answering. In Proceedings of the CLEF (Working Notes), Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Liu, S.; Ding, H.; Zhou, X. Shengyan at VQA-Med 2020: An Encoder-Decoder Model for Medical Domain Visual Question Answering Task. In Proceedings of the CLEF (Working Notes), Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Umada, H.; Aono, M. kdevqa at VQA-Med 2020: Focusing on GLU-based Classification. In Proceedings of the Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Gong, H.; Huang, R.; Chen, G.; Li, G. SYSU-HCP at VQA-Med 2021: A Data-centric Model with Efficient Training Methodology for Medical Visual Question Answering. In Proceedings of the Conference and Labs of the Evaluation Forum, Bucharest, Romania, 21–24 September 2021. [Google Scholar]
- Abacha, A.B.; Datla, V.; Hasan, S.A.; Demner-Fushman, D.; Müller, H. Overview of the VQA-Med Task at ImageCLEF 2021: Visual Question Answering and Generation in the Medical Domain. In Proceedings of the Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Eslami, S.; de Melo, G.; Meinel, C. TeamS at VQA-Med 2021: BBN-Orchestra for Long-tailed Medical Visual Question Answering. In Proceedings of the Conference and Labs of the Evaluation Forum, Bucharest, Romania, 21–24 September 2021. [Google Scholar]
- Li, J.; Liu, S. Lijie at ImageCLEFmed VQA-Med 2021: Attention Model-based Efficient Interaction between Multimodality. In Proceedings of the CLEF (Working Notes), Bucharest, Romania, 21–24 September 2021; pp. 1275–1284. [Google Scholar]
- Schilling, R.; Messina, P.; Parra, D.; Löbel, H. PUC Chile team at VQA-Med 2021: Approaching VQA as a classification task via fine-tuning a pretrained CNN. In Proceedings of the CLEF (Working Notes), Bucharest, Romania, 21–24 September 2021; pp. 1346–1351. [Google Scholar]
- Li, Y.; Yang, Z.; Hao, T. TAM at VQA-Med 2021: A Hybrid Model with Feature Extraction and Fusion for Medical Visual Question Answering. In Proceedings of the CLEF (Working Notes), Bucharest, Romania, 21–24 September 2021; pp. 1295–1304. [Google Scholar]
- Sitara, N.M.S.; Srinivasan, K. SSN MLRG at VQA-MED 2021: An Approach for VQA to Solve Abnormality Related Queries using Improved Datasets. In Proceedings of the Conference and Labs of the Evaluation Forum, Bucharest, Romania, 21–24 September 2021. [Google Scholar]
- Gong, H.; Chen, G.; Liu, S.; Yu, Y.; Li, G. Cross-Modal Self-Attention with Multi-Task Pre-Training for Medical Visual Question Answering. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei, Taiwan, 21–24 August 2021. [Google Scholar]
- Liu, B.; Zhan, L.M.; Xu, L.; Wu, X.M. Medical Visual Question Answering via Conditional Reasoning and Contrastive Learning. IEEE Trans. Med. Imaging 2023, 42, 1532–1545. [Google Scholar] [CrossRef]
- Do, T.K.L.; Nguyen, B.X.; Tjiputra, E.; Tran, M.N.; Tran, Q.D.; Nguyen, A.G.T. Multiple Meta-model Quantifying for Medical Visual Question Answering. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021. [Google Scholar]
- Nguyen, B.D.; Do, T.T.; Nguyen, B.X.; Do, T.K.L.; Tjiputra, E.; Tran, Q.D. Overcoming Data Limitation in Medical Visual Question Answering. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019. [Google Scholar]
- Liu, B.; Zhan, L.M.; Wu, X.M. Contrastive pre-training and representation distillation for medical visual question answering based on radiology images. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part II 24. Springer: Berlin/Heidelberg, Germany, 2021; pp. 210–220. [Google Scholar]
- Silva, J.D.; Martins, B.; Magalhães, J. Contrastive training of a multimodal encoder for medical visual question answering. Intell. Syst. Appl. 2023, 18, 200221. [Google Scholar] [CrossRef]
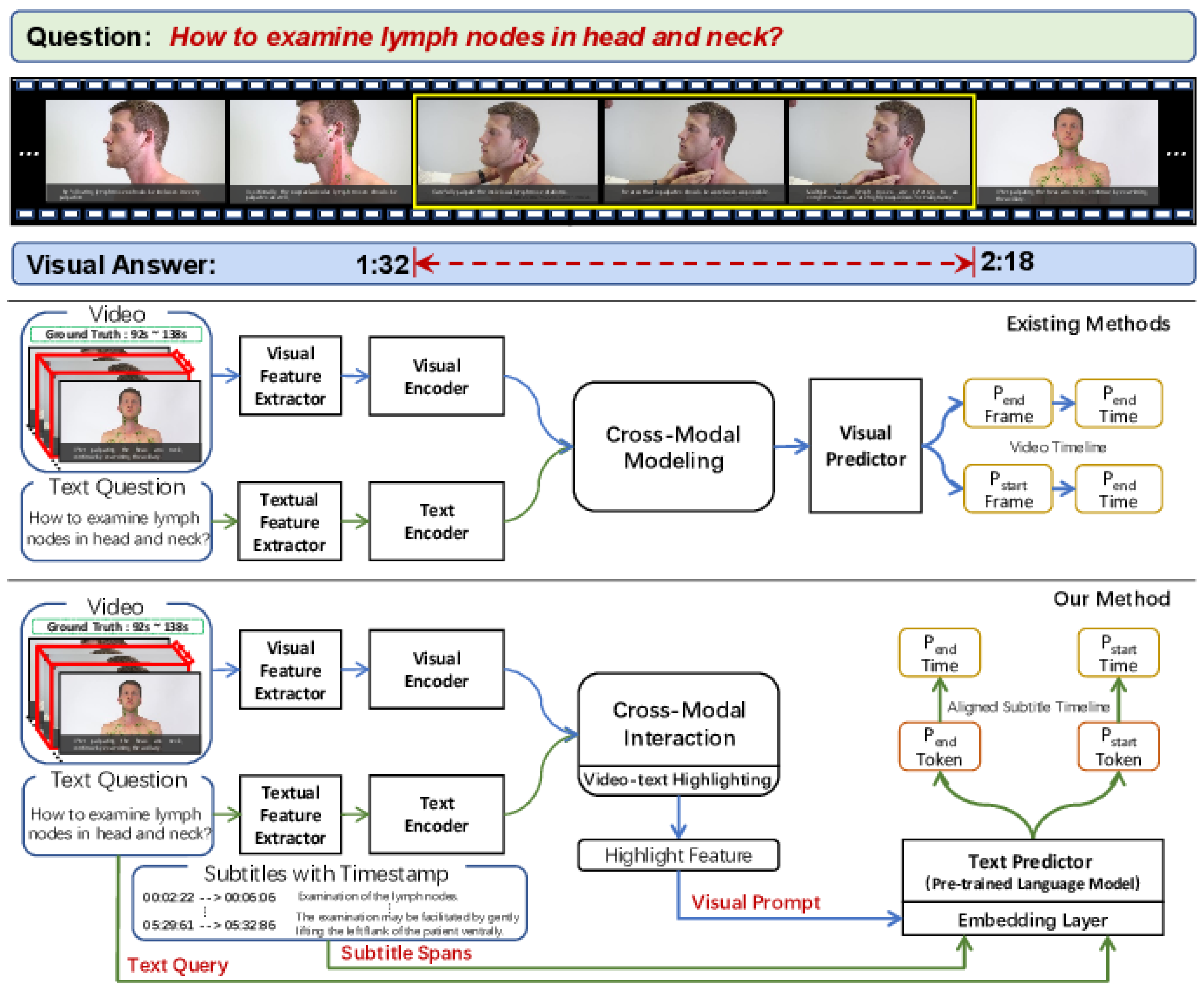
- Li, B.; Weng, Y.; Sun, B.; Li, S. Towards visual-prompt temporal answering grounding in medical instructional video. arXiv 2022, arXiv:2203.06667. [Google Scholar]
- Rodriguez, C.; Marrese-Taylor, E.; Saleh, F.S.; Li, H.; Gould, S. Proposal-free temporal moment localization of a natural-language query in video using guided attention. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Tampa, FL, USA, 7–11 January 2019; pp. 2464–2473. [Google Scholar]
- Zhang, H.; Sun, A.; Jing, W.; Zhou, J.T. Span-based localizing network for natural language video localization. arXiv 2020, arXiv:2004.13931. [Google Scholar]
- Zhang, H.; Sun, A.; Jing, W.; Zhen, L.; Zhou, J.T.; Goh, R.S.M. Natural language video localization: A revisit in span-based question answering framework. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4252–4266. [Google Scholar] [CrossRef]
- Tang, H.; Zhu, J.; Liu, M.; Gao, Z.; Cheng, Z. Frame-wise cross-modal matching for video moment retrieval. IEEE Trans. Multimed. 2021, 24, 1338–1349. [Google Scholar] [CrossRef]
- Gao, J.; Sun, X.; Xu, M.; Zhou, X.; Ghanem, B. Relation-aware video reading comprehension for temporal language grounding. arXiv 2021, arXiv:2110.05717. [Google Scholar]
- DeeplearningAI. Available online: https://www.deeplearning.ai/the-batch/issue-194/ (accessed on 18 June 2023).
- Ben-Shaul, I.; Shwartz-Ziv, R.; Galanti, T.; Dekel, S.; LeCun, Y. Reverse Engineering Self-Supervised Learning. arXiv 2023, arXiv:2305.15614. [Google Scholar]
- Van Uden, C.; Irvin, J.; Huang, M.; Dean, N.; Carr, J.; Ng, A.; Langlotz, C. How to Train Your CheXDragon: Training Chest X-ray Models for Transfer to Novel Tasks and Healthcare Systems. arXiv 2023, arXiv:2305.08017. [Google Scholar]
- Tian, K.; Mitchell, E.; Zhou, A.; Sharma, A.; Rafailov, R.; Yao, H.; Finn, C.; Manning, C.D. Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback. arXiv 2023, arXiv:2305.14975. [Google Scholar]
- Keskar, N.S.; McCann, B.; Socher, R.; Xiong, C. Systems and Methods for Unifying Question Answering and Text Classification via Span Extraction. US Patent 11,281,863, 22 March 2022. [Google Scholar]
- Mikolov, T. Language Modeling and Artificial Intelligence. In Proceedings of the Interspeech, Brno, Czechia, 30 August–3 September 2021. [Google Scholar]
- Singhal, K.; Tu, T.; Gottweis, J.; Sayres, R.; Wulczyn, E.; Hou, L.; Clark, K.; Pfohl, S.; Cole-Lewis, H.; Neal, D.; et al. Towards Expert-Level Medical Question Answering with Large Language Models. arXiv 2023, arXiv:2305.09617. [Google Scholar]
- van Sonsbeek, T.; Derakhshani, M.M.; Najdenkoska, I.; Snoek, C.G.; Worring, M. Open-ended medical visual question answering through prefix tuning of language models. arXiv 2023, arXiv:2303.05977. [Google Scholar]
- Guo, Q.; Cao, S.; Yi, Z. A medical question answering system using large language models and knowledge graphs. Int. J. Intell. Syst. 2022, 37, 8548–8564. [Google Scholar] [CrossRef]
- Ayers, J.W.; Poliak, A.; Dredze, M.; Leas, E.C.; Zhu, Z.; Kelley, J.B.; Faix, D.J.; Goodman, A.M.; Longhurst, C.A.; Hogarth, M.; et al. Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum. JAMA Intern. Med. 2023, 183, 589–596. [Google Scholar] [CrossRef]
- Duong, D.; Solomon, B.D. Analysis of large-language model versus human performance for genetics questions. Eur. J. Hum. Genet. 2023; 1–3, Online ahead of print. [Google Scholar] [CrossRef]
- Oh, N.; Choi, G.S.; Lee, W.Y. ChatGPT goes to the operating room: Evaluating GPT-4 performance and its potential in surgical education and training in the era of large language models. Ann. Surg. Treat. Res. 2023, 104, 269. [Google Scholar] [CrossRef]
- Antaki, F.; Touma, S.; Milad, D.; El-Khoury, J.; Duval, R. Evaluating the performance of chatgpt in ophthalmology: An analysis of its successes and shortcomings. Ophthalmol. Sci. 2023, 3, 100324. [Google Scholar] [CrossRef]
- Luo, R.; Sun, L.; Xia, Y.; Qin, T.; Zhang, S.; Poon, H.; Liu, T.Y. BioGPT: Generative pre-trained transformer for biomedical text generation and mining. Briefings Bioinform. 2022, 23, bbac409. [Google Scholar] [CrossRef]
- Weng, Y.; Li, B.; Xia, F.; Zhu, M.; Sun, B.; He, S.; Liu, K.; Zhao, J. Large Language Models Need Holistically Thought in Medical Conversational QA. arXiv 2023, arXiv:2305.05410. [Google Scholar]
- MedPalm. Available online: https://sites.research.google/med-palm/ (accessed on 18 September 2023).
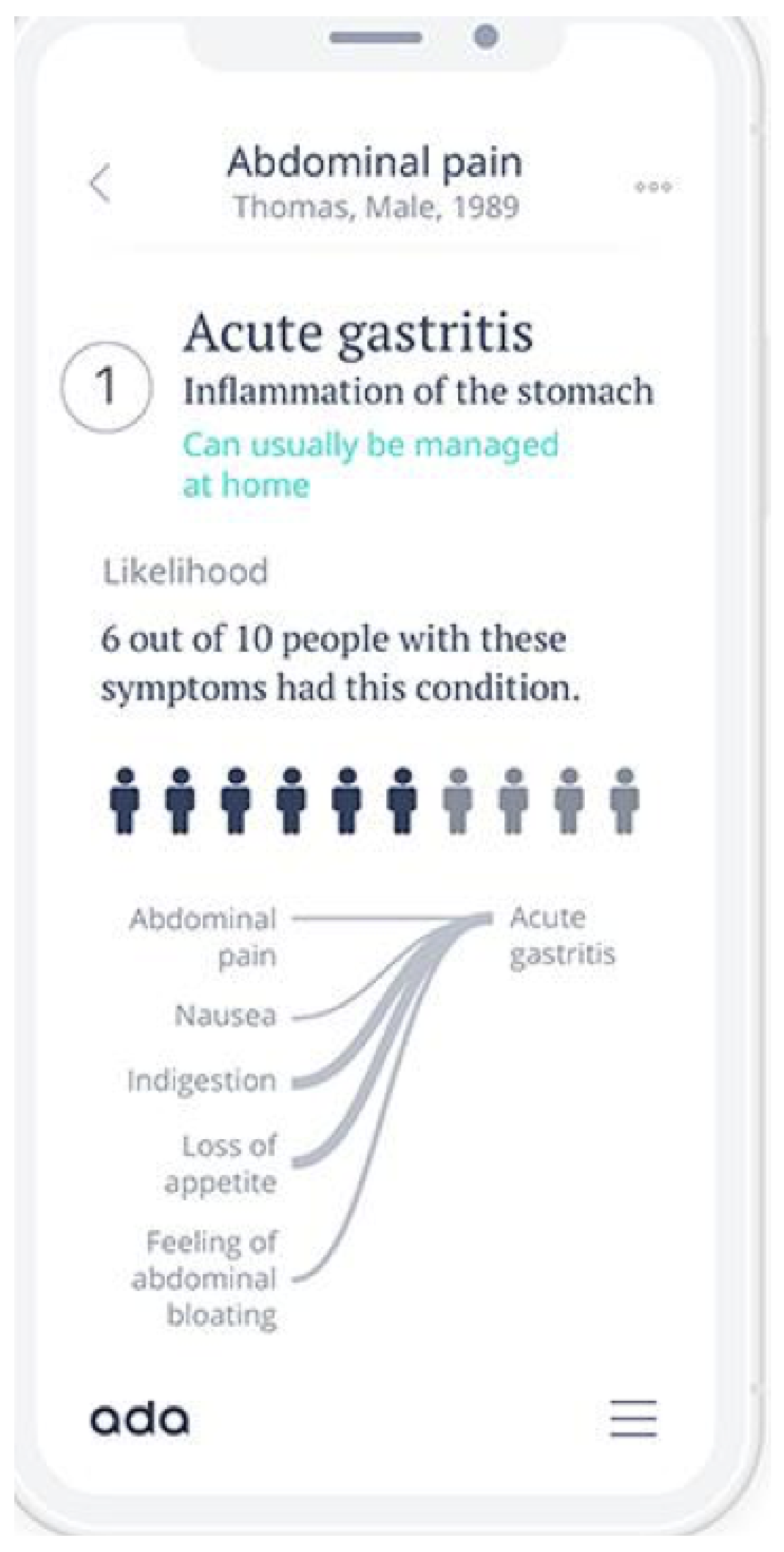
- Ada Health. Available online: https://ada.com (accessed on 18 June 2023).
- Doctor on Demand. Available online: https://doctorondemand.com (accessed on 18 June 2023).
- WebMD. Available online: https://symptoms.webmd.com (accessed on 18 June 2023).
- Mayo Clinic. Available online: https://www.mayoclinic.org/symptoms (accessed on 18 June 2023).
- Google Health. Available online: https://health.google (accessed on 18 June 2023).
- Apple Health. Available online: https://www.apple.com/ios/health/ (accessed on 18 June 2023).
- Buoy Health. Available online: https://www.buoyhealth.com (accessed on 18 June 2023).
- K Health. Available online: https://khealth.com (accessed on 18 June 2023).
- Medwise.AI. Available online: https://www.about.medwise.ai (accessed on 18 June 2023).





| Tool Name | Tool Link |
|---|---|
| AdaHealth [105] | https://ada.com (accessed on 27 December 2023) |
| Doctor on Demand [106] | https://doctorondemand.com (accessed on 27 December 2023) |
| WebMD [107] | https://symptoms.webmd.com/ (accessed on 27 December 2023) |
| Mayo Clinic [108] | https://www.mayoclinic.org/symptoms (accessed on 27 December 2023) |
| Google Health [109] | https://health.google (accessed on 27 December 2023) |
| Apple Health [110] | https://www.apple.com/ios/health/ (accessed on 27 December 2023) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Demirhan, H.; Zadrozny, W. Survey of Multimodal Medical Question Answering. BioMedInformatics 2024, 4, 50-74. https://doi.org/10.3390/biomedinformatics4010004
Demirhan H, Zadrozny W. Survey of Multimodal Medical Question Answering. BioMedInformatics. 2024; 4(1):50-74. https://doi.org/10.3390/biomedinformatics4010004
Chicago/Turabian StyleDemirhan, Hilmi, and Wlodek Zadrozny. 2024. "Survey of Multimodal Medical Question Answering" BioMedInformatics 4, no. 1: 50-74. https://doi.org/10.3390/biomedinformatics4010004