

Ensemble Methods to Optimize Automated Text Classification in Avatar Therapy



Abstract
:1. Introduction
2. Materials and Methods
2.1. Recruitment and Participants
2.2. Dataset: Corpus of Avatar Therapy and Features
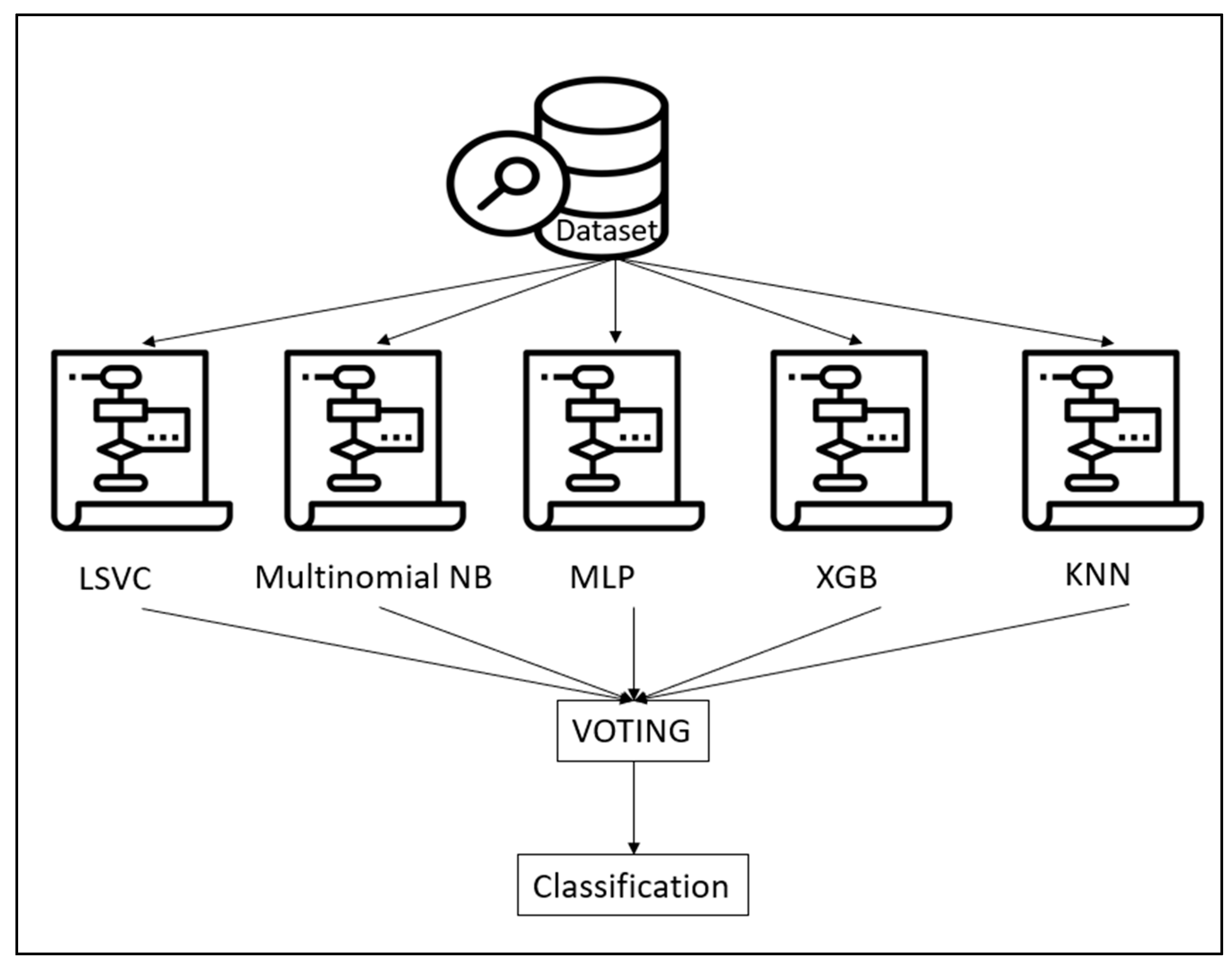
2.3. Ensemble Modeling
2.4. Machine Learning Algorithms
- LSVC: The Support Vector Machine (SVM) approach aims to determine the optimal hyperplane for dividing various classes of data points in a high-dimensional feature space. This involves maximizing the margin between classes to achieve robust generalization performance. The method identifies support vectors, a subset of training samples serving as pivotal points for the decision boundary. Unlike SVC, the LSVC uses a linear kernel. A kernel is a mathematical function transforming data into a higher-dimensional feature space, crucial in handling complex problems that may be challenging or impossible in the original input space. A linear kernel is applied when data separation can be achieved linearly. The implementation of SVC in this study utilized Scikit-Learn, specifically the SVC class from the SVM library [37].
- The Multinomial Naive Bayes method is a derivative of the Naïve Bayes technique, which, based on the Bayes theorem, assumes conditional independence of features given the class. This method is developed using the Bayes theorem, which enables the updating of the probability of Event A occurring in light of new information or additional supporting evidence from Event B. It calculates the posterior probability (P(A|B)) by combining the prior probability (P(A)) and the likelihood (P(B|A)). Specifically designed to handle discrete features in text data, such as word counts or frequencies, the Multinomial Naive Bayes classifier is implemented using Scikit-Learn, with the Multinomial NB class from the naive_bayes module employed in this study [37].
- MLP: The Multi-Layer Perceptron (MLP) classifier serves for classification and various machine learning applications. It constitutes a feedforward neural network model characterized by multiple layers of interconnected neurons. The typical structure of the MLP classifier includes an input layer, one or more hidden layers, and an output layer. Each layer comprises numerous neurons that conduct computations on incoming data and transmit the results to the subsequent layer. In an MLP, every neuron in each layer is connected to every other neuron in both the layers above and below, indicating full connectivity. The strengths and relevance of information flow across the network are influenced by weights associated with neuron connections. In this study, the MLP implementation is derived from Scikit-Learn, specifically utilizing the MLPClassifier class from the neural_network library [37].
- XGB: XGB works by sequentially iteratively generating an ensemble of weak learners such as decision trees. Each successive model is then used to correct the mistakes of the prior ones. This is performed to optimize the ensemble’s predictive capability while reducing overfitting by minimizing a user-defined loss function. XGboost library, namely the XGBoost class of the XGBClassifier module, provided the XGB implementation used in this study [37].
- KNN: This widely employed technique is based on the principles of k-means clustering, aiming to group similar data in a comprehensible, relatively swift, and scalable manner while ensuring convergence. It assesses whether two items are identical and organizes them based on their Euclidean distance, representing the length of a line drawn between two data points. The number of clusters is predetermined, and the process unfolds iteratively. Beginning with the random selection of the center (centroid) for each cluster, the Euclidean distance from all data points to the centroids is computed, and the data points are assigned to their closest clusters. Subsequently, for each cluster, a new centroid is determined by calculating the mean of all data points within the cluster. This process is repeated until all points converge, and the cluster centers cease to move. The KNN implementation in this study is sourced from Scikit-Learn, specifically utilizing the neighbors class from the SVM library [37].
2.5. Voting Technique
2.6. Data Analysis and Validation
3. Results
3.1. Characteristics of the Participants
3.2. Performance of Ensemble Modeling
3.2.1. Automated Classification of Avatar Interactions
3.2.2. Automated Classification of Patient Interactions
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Carrà, G.; Crocamo, C.; Angermeyer, M.; Brugha, T.; Toumi, M.; Bebbington, P. Positive and negative symptoms in schizophrenia: A longitudinal analysis using latent variable structural equation modelling. Schizophr. Res. 2018, 204, 58–64. [Google Scholar] [CrossRef] [PubMed]
- Correll, C.U.; Schooler, N.R. Negative Symptoms in Schizophrenia: A Review and Clinical Guide for Recognition, Assessment, and Treatment. Neuropsychiatr. Dis. Treat. 2020, 16, 519–534. [Google Scholar] [CrossRef]
- Patel, K.R.; Cherian, J.; Gohil, K.; Atkinson, D. Schizophrenia: Overview and treatment options. Peer Rev. J. Formul. Manag. 2014, 39, 638–645. [Google Scholar]
- Stępnicki, P.; Kondej, M.; Kaczor, A.A. Current Concepts and Treatments of Schizophrenia. Molecules 2018, 23, 2087. [Google Scholar] [CrossRef]
- Siskind, D.; Siskind, V.; Kisely, S. Clozapine Response Rates among People with Treatment-Resistant Schizophrenia: Data from a Systematic Review and Meta-Analysis. Can. J. Psychiatry 2017, 62, 772–777. [Google Scholar] [CrossRef]
- Corripio, I.; Roldán, A.; Sarró, S.; McKenna, P.J.; Alonso-Solís, A.; Rabella, M.; Díaz, A.; Puigdemont, D.; Pérez-Solà, V.; Álvarez, E.; et al. Deep brain stimulation in treatment resistant schizophrenia: A pilot randomized cross-over clinical trial. EBioMedicine 2020, 51, 102568. [Google Scholar] [CrossRef]
- Huckle, P.L.; Palia, S.S. Managing resistant schizophrenia. Br. J. Hosp. Med. 1993, 50, 467–471. [Google Scholar] [PubMed]
- Suzuki, T.; Remington, G.; Mulsant, B.H.; Uchida, H.; Rajji, T.K.; Graff-Guerrero, A.; Mimura, M.; Mamo, D.C. Defining treatment-resistant schizophrenia and response to antipsychotics: A review and recommendation. Psychiatry Res. 2012, 197, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Correll, C.U.; Howes, O.D. Treatment-Resistant Schizophrenia: Definition, Predictors, and Therapy Options. J. Clin. Psychiatry 2021, 82. [Google Scholar] [CrossRef]
- Chakrabarti, S. Clozapine resistant schizophrenia: Newer avenues of management. World J. Psychiatry 2021, 11, 429–448. [Google Scholar] [CrossRef]
- Potkin, S.G.; Kane, J.M.; Correll, C.U.; Lindenmayer, J.-P.; Agid, O.; Marder, S.R.; Olfson, M.; Howes, O.D. The neurobiology of treatment-resistant schizophrenia: Paths to antipsychotic resistance and a roadmap for future research. Schizophrenia 2020, 6, 1. [Google Scholar] [CrossRef]
- Bighelli, I.; Huhn, M.; Schneider-Thoma, J.; Krause, M.; Reitmeir, C.; Wallis, S.; Schwermann, F.; Pitschel-Walz, G.; Barbui, C.; Furukawa, T.A.; et al. Response rates in patients with schizophrenia and positive symptoms receiving cognitive behavioural therapy: A systematic review and single-group meta-analysis. BMC Psychiatry 2018, 18, 380. [Google Scholar] [CrossRef]
- Morrison, A.P.; Pyle, M.; Gumley, A.; Schwannauer, M.; Turkington, D.; MacLennan, G.; Norrie, J.; Hudson, J.; E Bowe, S.; French, P.; et al. Cognitive behavioural therapy in clozapine-resistant schizophrenia (FOCUS): An assessor-blinded, randomised controlled trial. Lancet Psychiatry 2018, 5, 633–643. [Google Scholar] [CrossRef] [PubMed]
- Aali, G.; Kariotis, T.; Shokraneh, F. Avatar Therapy for people with schizophrenia or related disorders. Cochrane Database Syst. Rev. 2020, 2020, Cd011898. [Google Scholar] [CrossRef]
- Leff, J.; Williams, G.; Huckvale, M.A.; Arbuthnot, M.; Leff, A.P. Computer-assisted therapy for medication-resistant auditory hal-lucinations: Proof-of-concept study. Br. J. Psychiatry 2013, 202, 428–433. [Google Scholar] [CrossRef] [PubMed]
- Bisso, E.; Signorelli, M.S.; Milazzo, M.; Maglia, M.; Polosa, R.; Aguglia, E.; Caponnetto, P. Immersive Virtual Reality Applications in Schizo-phrenia Spectrum Therapy: A Systematic Review. Int. J. Env. Res. Public. Health 2020, 17, 6111. [Google Scholar] [CrossRef]
- Leff, J.; Williams, G.; Huckvale, M.; Arbuthnot, M.; Leff, A.P. Avatar therapy for persecutory auditory hallucinations: What is it and how does it work? Psychosis 2014, 6, 166–176. [Google Scholar] [CrossRef] [PubMed]
- Craig, T.K.; Rus-Calafell, M.; Ward, T.; Leff, J.P.; Huckvale, M.; Howarth, E.; Emsley, R.; Garety, P.A. AVATAR therapy for auditory verbal hallucinations in people with psychosis: A single-blind, randomised controlled trial. Lancet Psychiatry 2017, 5, 31–40. [Google Scholar] [CrossRef]
- Dellazizzo, L.; Potvin, S.; Phraxayavong, K.; Dumais, A. One-year randomized trial comparing virtual reality-assisted therapy to cognitive–behavioral therapy for patients with treatment-resistant schizophrenia. Schizophrenia 2021, 7, 9. [Google Scholar] [CrossRef]
- Dellazizzo, L.; du Sert, O.P.; Phraxayavong, K.; Potvin, S.; O’Connor, K.; Dumais, A. Exploration of the dialogue components in Avatar Therapy for schizophrenia patients with refractory auditory hallucinations: A content analysis. Clin. Psychol. Psychother. 2018, 25, 878–885. [Google Scholar] [CrossRef]
- Beaudoin, M.; Potvin, S.; Machalani, A.; Dellazizzo, L.; Bourguignon, L.; Phraxayavong, K.; Dumais, A. The therapeutic processes of avatar therapy: A content analysis of the dialogue between treatment-resistant patients with schizophrenia and their avatar. Clin. Psychol. Psychother. 2021, 28, 500–518. [Google Scholar] [CrossRef] [PubMed]
- Szymańska, A.; Dobrenko, K.; Grzesiuk, L. Characteristics and experience of the patient in psychotherapy and the psychother-apy’s effectiveness. A Struct. Approach. Psychiatr. Pol. 2017, 51, 619–631. [Google Scholar] [CrossRef]
- Runciman, W.B. Qualitative versus quantitative research—Balancing cost, yield and feasibility. Qual. Saf. Health Care 2002, 11, 146–147. [Google Scholar] [CrossRef] [PubMed]
- Pannucci, C.J.; Wilkins, E.G. Identifying and Avoiding Bias in Research. Plast. Reconstr. Surg. 2010, 126, 619–625. [Google Scholar] [CrossRef] [PubMed]
- Althubaiti, A. Information bias in health research: Definition, pitfalls, and adjustment methods. J. Multidiscip. Healthc. 2016, 9, 211–217. [Google Scholar] [CrossRef] [PubMed]
- Dogra, V.; Verma, S.; Kavita; Chatterjee, P.; Shafi, J.; Choi, J.; Ijaz, M.F. A Complete Process of Text Classification System Using State-of-the-Art NLP Models. Comput. Intell. Neurosci. 2022, 2022, 1883698. [Google Scholar] [CrossRef]
- Jovel, J.; Greiner, R. An Introduction to Machine Learning Approaches for Biomedical Research. Front. Med. 2021, 8, 771607. [Google Scholar] [CrossRef]
- Hey, T.; Butler, K.; Jackson, S.; Thiyagalingam, J. Machine learning and big scientific data. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2020, 378, 20190054. [Google Scholar] [CrossRef]
- Hudon, A.; Beaudoin, M.; Phraxayavong, K.; Dellazizzo, L.; Potvin, S.; Dumais, A. Use of Automated Thematic Annotations for Small Data Sets in a Psychotherapeutic Context: Systematic Review of Machine Learning Algorithms. JMIR Ment. Health 2021, 8, e22651. [Google Scholar] [CrossRef]
- Hudon, A.; Beaudoin, M.; Phraxayavong, K.; Dellazizzo, L.; Potvin, S.; Dumais, A. Implementation of a machine learning algorithm for automated thematic annotations in avatar: A linear support vector classifier approach. Health Inform. J. 2022, 28, 14604582221142442. [Google Scholar] [CrossRef] [PubMed]
- Hudon, A.; Couture, J.; Dellazizzo, L.; Beaudoin, M.; Phraxayavong, K.; Potvin, S.; Dumais, A. Dyadic Interactions of Treatment-Resistant Schizophrenia Patients Having Followed Virtual Reality Therapy: A Content Analysis. J. Clin. Med. 2023, 12, 2299. [Google Scholar] [CrossRef]
- Bhavsar, H.; Ganatra, A. A comparative study of training algorithms for supervised machine learning. Int. J. Soft Comput. Eng. (IJSCE) 2012, 2, 2231–2307. [Google Scholar]
- Ganaie, M.A.; Minghui, H.; Malik, A.K.; Tanveer, M.; Suganthan, P.N. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Verma, A.; Mehta, S. A comparative study of ensemble learning methods for classification in bioinformatics. In Proceedings of the 2017 7th International Conference on Cloud Computing, Data Science & Engineering—Confluence (Confluence), Noida, India, 12–13 January 2017; pp. 155–158. [Google Scholar]
- Pintelas, P.; Livieris, I.E. Special Issue on Ensemble Learning and Applications. Algorithms 2020, 13, 140. [Google Scholar] [CrossRef]
- Lewis, R.B.; Maas, S.M. QDA Miner 2.0: Mixed-model qualitative data analysis software. Field Methods 2007, 19, 87–108. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hudon, A.; Beaudoin, M.; Phraxayavong, K.; Potvin, S.; Dumais, A. Unsupervised Machine Learning Driven Analysis of Verbatims of Treatment-Resistant Schizophrenia Patients Having Followed Avatar Therapy. J. Pers. Med. 2023, 13, 801. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Yuan, P.; Zhou, X.; Tang, X. (Eds.) Performance Comparison of TF*IDF, LDA and Paragraph Vector for Document Classification; Springer: Singapore, 2016. [Google Scholar]
- Kabari, L.G.; Onwuka, U.C. Comparison of bagging and voting ensemble machine learning algorithm as a classifier. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2019, 9, 19–23. [Google Scholar]
- Peppes, N.; Daskalakis, E.; Alexakis, T.; Adamopoulou, E.; Demestichas, K. Performance of machine learning-based multi-model voting ensemble methods for network threat detection in agriculture 4.0. Sensors 2021, 21, 7475. [Google Scholar] [CrossRef] [PubMed]
- Alsulami, B.; Almalawi, A.; Fahad, A. Toward an Efficient Automatic Self-Augmentation Labeling Tool for Intrusion Detection Based on a Semi-Supervised Approach. Appl. Sci. 2022, 12, 7189. [Google Scholar] [CrossRef]
- Manconi, A.; Armano, G.; Gnocchi, M.; Milanesi, L. A Soft-Voting Ensemble Classifier for Detecting Patients Affected by COVID-19. Appl. Sci. 2022, 12, 7554. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. (Eds.) A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In European Conference on Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Opitz, J.; Burst, S. Macro f1 and macro f1. arXiv 2019, arXiv:191103347. [Google Scholar]
- Gholamy, A.; Kreinovich, V.; Kosheleva, O. Why 70/30 or 80/20 Relation between Training and Testing Sets: A Pedagogical Explanation; The University of Texas at El Paso: El Paso, TX, USA, 2018. [Google Scholar]
- Birba, D.E. A Comparative Study of Data Splitting Algorithms for Machine Learning Model Selection; Kth Royal Institute of Technology: Stockholm, Sweden, 2020; Available online: https://www.diva-portal.org/smash/get/diva2:1506870/FULLTEXT01.pdf (accessed on 2 July 2023).
- Ibrahim, Y.; Okafor, E.; Yahaya, B.; Yusuf, S.M.; Abubakar, Z.M.; Bagaye, U.Y. Comparative Study of Ensemble Learning Techniques for Text Classification. In Proceedings of the 2021 1st International Conference on Multidisciplinary Engineering and Applied Science (ICMEAS), Abuja, Nigeria, 15–16 July 2021; pp. 1–5. [Google Scholar]
- Ammar, M.; Rania, K. An effective ensemble deep learning framework for text classification. J. King Saud Univ. Comput. Inf. Sci. 2022, 34 Pt A, 8825–8837. [Google Scholar]
- Palanivinayagam, A.; El-Bayeh, C.Z.; Damaševičius, R. Twenty Years of Machine-Learning-Based Text Classification: A Systematic Review. Algorithms 2023, 16, 236. [Google Scholar] [CrossRef]
- Chung, J.; Teo, J. Single classifier vs. ensemble machine learning approaches for mental health prediction. Brain Inform. 2023, 10, 1. [Google Scholar] [CrossRef]
- Dietterich, T.G. (Ed.) Ensemble methods in machine learning. In International Workshop on Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Chan, J.Y.-L.; Leow, S.M.H.; Bea, K.T.; Cheng, W.K.; Phoong, S.W.; Hong, Z.-W.; Chen, Y.-L. Mitigating the Multicollinearity Problem and Its Machine Learning Approach: A Review. Mathematics 2022, 10, 1283. [Google Scholar] [CrossRef]
- Taubitz, F.-S.; Büdenbender, B.; Alpers, G.W. What the future holds: Machine learning to predict success in psychotherapy. Behav. Res. Ther. 2022, 156, 104116. [Google Scholar] [CrossRef] [PubMed]
- Habli, I.; Lawton, T.; Porter, Z. Artificial intelligence in health care: Accountability and safety. Bull. World Health Organ. 2020, 98, 251–256. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Avatar Themes | Samples | Patient Themes | Samples |
|---|---|---|---|
| Accusations | “You’ve carried out this task.” | Approbation | “Your observation is accurate.” “I’m capable of achieving this.” |
| Omnipotence | “I’m feeling scattered everywhere.” | Self-deprecation | |
| Beliefs | “In my opinion, your behavior seems irrational.” | Self-appraisal | “I consider myself a kind individual.” |
| Active listening, empathy | “Take your time to unwind, please.” | Other beliefs | “You’re the one with control over me.” |
| Incitements, orders | “I recommend discontinuing this activity.” | Counterattack | “You’re responsible for this, not me!” |
| Coping mechanisms | “Can you explain why my mentioning this makes you sad?” | Maliciousness of the voice | “You seem to be intentionally complicating things for everyone.” |
| Threats | “I’ll bring about your downfall.” | Negative | “This is quite challenging.” |
| Negative emotions | “Coming to terms with that is challenging for me.” | Negation | “I didn’t perform this action.” |
| Self-perceptions | “I view myself as being insignificant.” | Omnipotence | “I possess unmatched abilities.” |
| Positive emotions | “I’m unparalleled in the entire world.” | Disappearance of the voice | “Please disappear!” |
| Provocation | “Try preventing me from causing you harm.” | Positive | “I’m experiencing a positive emotional state.” |
| Reconciliation | “Shall we work towards reconciliation?” | Prevention | “I’ll attempt to ignore your presence.” |
| Reinforcement | “Give this another attempt.” | Reconciliation of the voice | “Shall we become friends?” |
| Self-affirmation | “I am capable of accomplishing this.” |
| Characteristics | Value (n = 18) |
|---|---|
| Sex (# male, # female) | 16, 2 |
| Age (mean in years) | 42.6 ± 6.2 |
| Education (mean in years) | 12.8 ± 3.6 |
| Ethnicity (Caucasian, others) | 94.4%, 5.6% |
| % on Clozapine | 61.1% |
| Models | Accuracy (Range) | Precision (Range) | Recall (Range) | f1-Score (Range) |
|---|---|---|---|---|
| LSVC | 0.66 (0.64–0.67) | 0.70 (0.69–0.71) | 0.66 (0.65–0.67) | 0.66 (0.65–0.67) |
| Multinomial NB | 0.48 (0.47–0.48) | 0.62 (0.47–0.49) | 0.48 (0.47–0.49) | 0.42 (0.41–0.43) |
| MLP | 0.66 (0.64–0.67) | 0.68 (0.65–0.69) | 0.66 (0.65–0.67) | 0.66 (0.65–0.67) |
| XGB | 0.54 (0.54–0.55) | 0.64 (0.64–0.65) | 0.56 (0.56–0.57) | 0.56 (0.56–0.57) |
| KNN | 0.57 (0.55–0.58) | 0.65 (0.63–0.67) | 0.58 (0.56–0.60) | 0.56 (0.54–0.58) |
| Ensemble | 0.71 (0.69–0.72) | 0.71 (0.69–0.72) | 0.71 (0.69–0.72) | 0.70 (0.69–0.71) |
| Models | Accuracy (Range) | Precision (Range) | Recall (Range) | f1-Score (Range) |
|---|---|---|---|---|
| LSVC | 0.57 (0.56–0.58) | 0.62 (0.60–0.63) | 0.57 (0.56–0.58) | 0.58 (0.57–0.9) |
| Multinomial NB | 0.44 (0.44–0.45) | 0.50 (0.50–0.51) | 0.44 (0.43–0.44) | 0.40 (0.39–0.41) |
| MLP | 0.54 (0.53–0.55) | 0.57 (0.55–0.57) | 0.54 (0.53–0.55) | 0.55 (0.54–0.56) |
| XGB | 0.48 (0.48–0.49) | 0.50 (0.49–0.51) | 0.48 (0.48–0.49) | 0.49 (0.48–0.50) |
| KNN | 0.45 (0.43–0.46) | 0.51 (0.48–0.53) | 0.46 (0.45–0.47) | 0.46 (0.45–0.47) |
| Ensemble | 0.58 (0.57–0.9) | 0.58 (0.57–0.9) | 0.58 (0.57–0.9) | 0.58 (0.57–0.9) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hudon, A.; Phraxayavong, K.; Potvin, S.; Dumais, A. Ensemble Methods to Optimize Automated Text Classification in Avatar Therapy. BioMedInformatics 2024, 4, 423-436. https://doi.org/10.3390/biomedinformatics4010024
Hudon A, Phraxayavong K, Potvin S, Dumais A. Ensemble Methods to Optimize Automated Text Classification in Avatar Therapy. BioMedInformatics. 2024; 4(1):423-436. https://doi.org/10.3390/biomedinformatics4010024
Chicago/Turabian StyleHudon, Alexandre, Kingsada Phraxayavong, Stéphane Potvin, and Alexandre Dumais. 2024. "Ensemble Methods to Optimize Automated Text Classification in Avatar Therapy" BioMedInformatics 4, no. 1: 423-436. https://doi.org/10.3390/biomedinformatics4010024