1. Introduction
Recent research findings have demonstrated that properly designed rocking shallow foundations possess many desirable characteristics by effectively acting as geotechnical seismic isolation mechanisms. The mobilization of bearing capacity and yielding of soil during rocking forms a plastic-hinge or a fuse-like mechanism in foundation soil that in turn dissipates seismic energy and reduces the seismic force and flexural drift demands transmitted to the structures e.g., [
1,
2,
3,
4,
5,
6,
7]. ASCE/SEI Standard 41-13 includes some provisions and recommendations for rocking behavior of shallow foundations in seismic evaluation and retrofitting of existing buildings [
8], and rationales and justifications highlighting the benefits of including rocking foundations in seismic design have also been published [
9,
10,
11]. Despite a growing body of knowledge and mounting experimental evidences, foundation rocking is still perceived as an unreliable geotechnical seismic isolation mechanism for improving the seismic performance of structures. The possibility of excessive rotation and settlement of foundation, possible tipping-over failure of structure, and the challenges associated with accurately predicting the performance of rocking foundations amid uncertainties in soil properties and earthquake loading are among primary concerns that hinder the use of foundation rocking as a designed mechanism for reducing seismic force and ductility demands transmitted to structures [
12,
13,
14,
15].
The development and availability of well-documented, large, experimental databases in the recent past has encouraged the application of machine learning (ML) algorithms in predictive modeling in many fields [
16,
17]. Models based on machine learning algorithms have the ability to learn directly from experimental data and generalize experimental behavior, and hence can be used in combination with physics-based theoretical models as complementary measures in practical applications. In the recent past, the application of machine learning algorithms and models in geotechnical engineering has seen an exponential increase [
18]. Of the 783 research articles on the application of machine learning algorithms in geotechnical engineering published in last 35 years, about 70% of the articles were published within the last 10 years [
18]. Artificial neural networks, support vector machines, decision trees, and logistic regression have been used to predict compressive strength and shear strength of soils, slope stability, bearing capacity and settlement of foundations, and liquefaction potential of soils [
19,
20,
21,
22,
23,
24].
The objective of this study is to develop data-driven predictive models for peak rotation and factor of safety for tipping-over failure of structures supported by rocking shallow foundations during earthquake loading using multiple machine learning (ML) algorithms and a supervised learning technique. Data from a globally available rocking foundations database, consisting of dynamic base shaking experiments conducted on centrifuges and shaking tables, were used for training and testing of machine learning models. Three nonlinear machine learning algorithms are considered in this study: distance-weighted k-nearest neighbors regression (KNN), support vector regression (SVR), and decision tree-based random forest regression (RFR). The input features to the machine learning algorithms included critical contact area ratio of foundation (related to the factor of safety for bearing capacity during rocking); slenderness ratio and rocking coefficient of rocking system; peak ground acceleration and Arias intensity of earthquake motion; and a categorical binary feature that separates sandy soil foundations from clayey soil foundations.
Two performance parameters of rocking systems were considered as prediction variables: (i) peak rotation of foundation during rocking and (ii) factor of safety for tipping-over failure of structure, defined as the critical rotation that would cause tipping-over failure divided by the peak rotation of foundation. A randomly split pair of training and testing datasets was used for initial evaluation and hyperparameter turning of ML models. In addition, multiple random training datasets were used to evaluate the importance of input features (their suitability and relative significance for the problem considered) using a RFR model. A repeated k-fold cross validation technique, reshuffling the entire dataset, was then used to further evaluate the performance of the models in terms of bias and variance using the mean absolute error (MAE) and mean absolute percentage error (MAPE) of their predictions. The three nonlinear machine learning model performances were also compared with a multivariate linear regression (MLR) model, a linear parametric machine learning model developed as a baseline model for comparison.
Previous studies related to the application of machine learning algorithms for performance prediction of rocking foundations considered seismic energy dissipation, permanent settlement, and acceleration amplification ratio (acceleration transmitted to the structure) as performance (or prediction) parameters [
25,
26]. The novelty and originality of the present study include the following: (i) this is the first study that applies machine learning algorithms to develop data-driven predictive models for rocking-induced peak rotation and factor of safety for tipping-over failure of rocking foundations and (ii) the present study develops a new ensemble machine learning model for rocking foundations, namely, a random forest model consisting of multiple decision trees.
2. Background: Tipping-Over Stability of Rocking Shallow Foundations
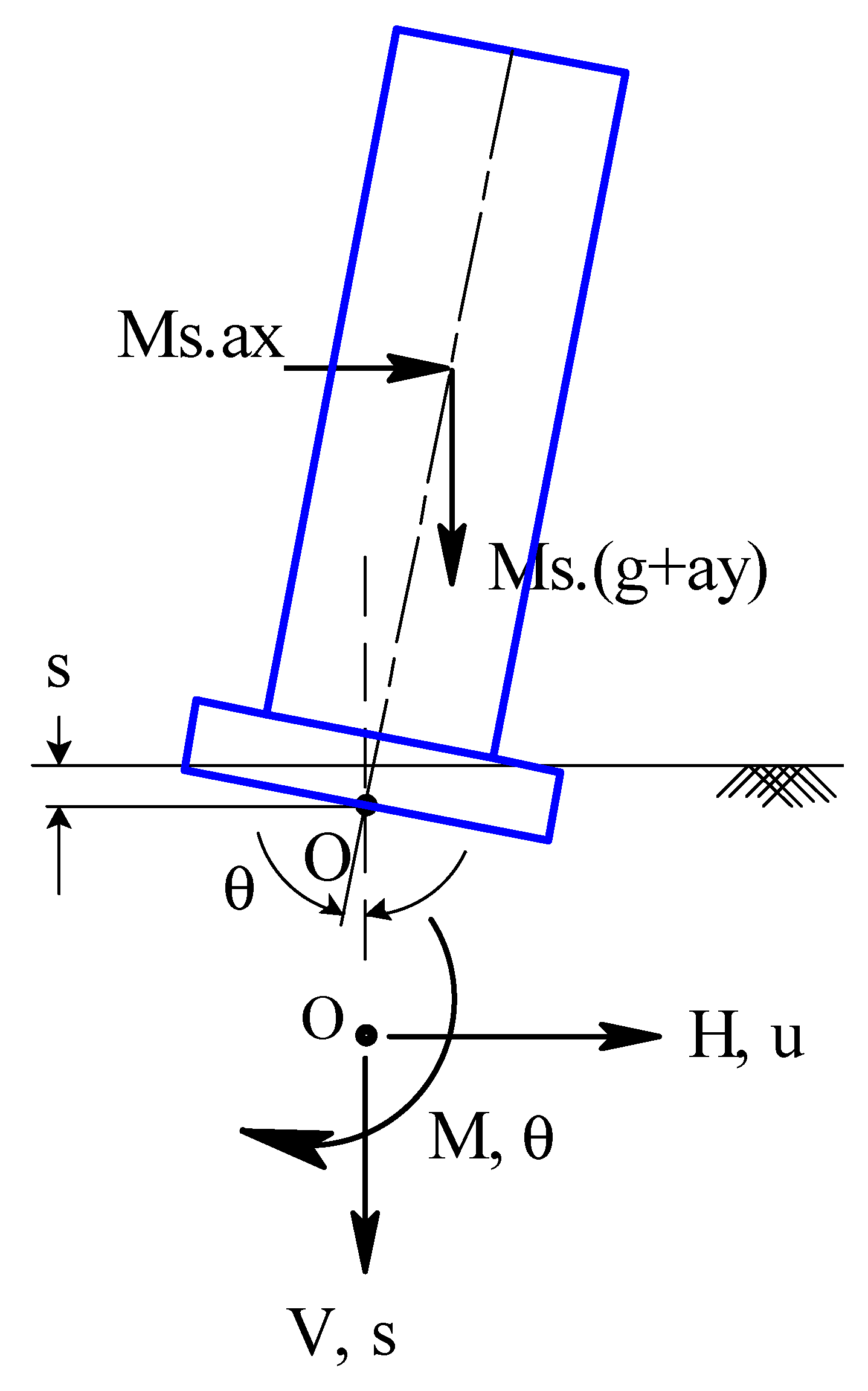
Figure 1 shows the schematic of a rocking structure supported by a shallow foundation and the forces (vertical load (V), horizontal load (H) and moment (M)) and displacements (settlement (s), sliding (u) and rotation (θ)) acting at the soil–footing interface during rocking. The peak rotation of rocking foundation (θ
peak) is defined as the absolute maximum rotation experienced by the foundation during earthquake shaking, which is also the same as the peak rotation of the structure, as the footing and structure are rigidly connected. Gajan and Kayser (2019) [
15], for example, using parametric studies of numerical simulations, demonstrated that the peak rotation of a rocking foundation is strongly correlated to maximum acceleration of base shaking (a
max). The magnitude of rocking-induced rotation of the structure also depends on the slenderness ratio of the rocking system (h/B, where h is the effective height of the structure and B is the width of the footing in the direction of rocking), as h/B predominantly controls the applied moment-to-shear ratio at the footing–soil interface [
27]. The other parameters that affect the peak rotation of rocking foundation include critical contact area ratio, rocking coefficient, Arias intensity of earthquake motion, and type of soil [
7].
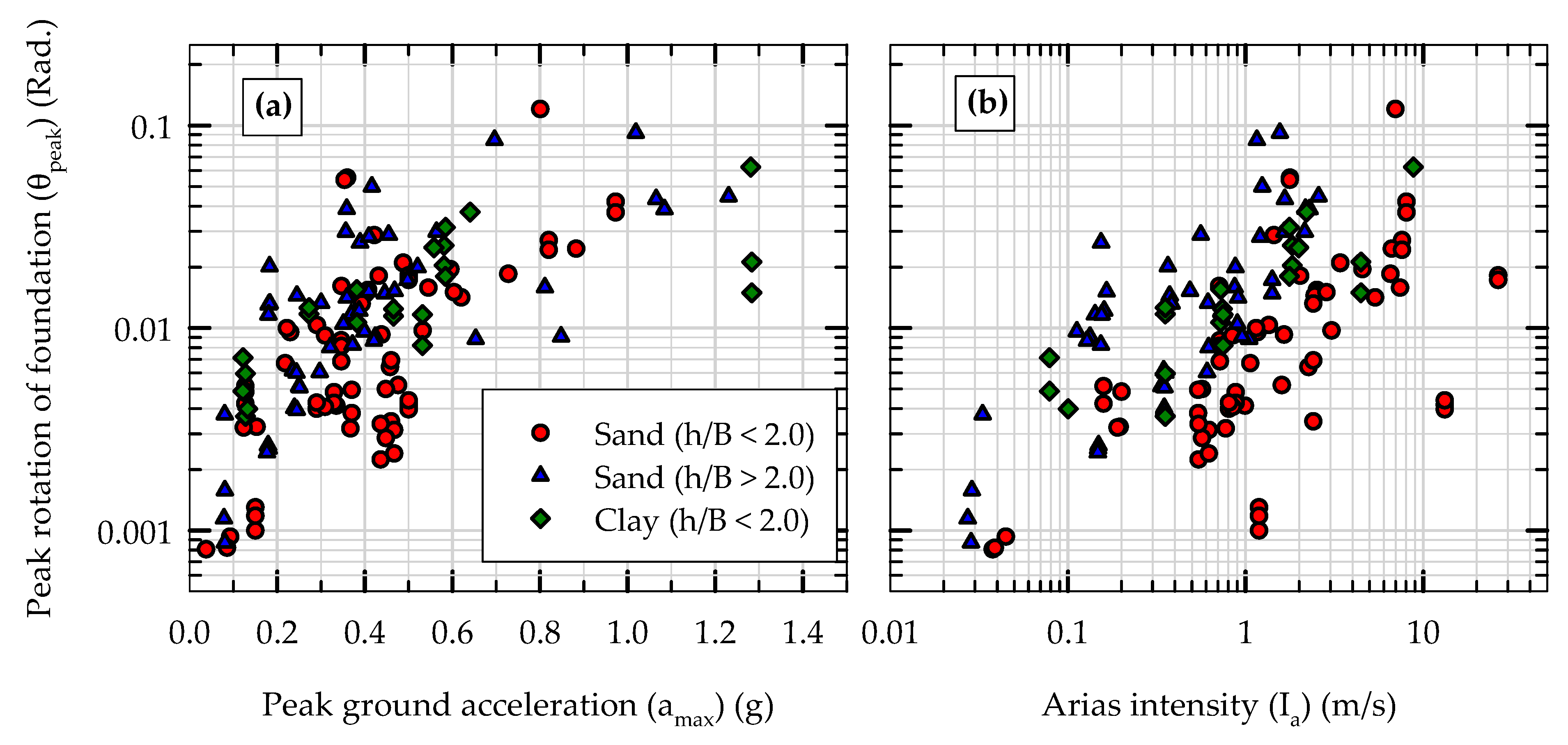
Figure 2a presents the variation of peak rotation of foundation (θ
peak) with peak ground acceleration (a
max) of earthquake motion for three different clusters of slenderness ratio (h/B) of rocking systems (two sets on sand and one set on clay foundations). It should be noted that for all rocking systems presented in
Figure 2 and in this paper, the slenderness ratio (h/B) is greater than 1.0 (i.e., all systems considered are rocking-dominated systems as opposed to sliding-dominated systems). The experimental results presented in
Figure 2 were extracted from 140 centrifuge and shaking table experiments on rocking foundations available in a publicly available database (described further in
Section 3.1). As can be seen from
Figure 2a, in general, and as expected, θ
peak increases as a
max increases; however, there is scatter in the data. Similarly, though the data are scattered, in general, for a given a
max, higher slenderness ratio structure–footing systems rotate more than their lower counterparts, indicating the ability of slender structures to rock more than relatively shorter structures.
Figure 2a also shows that rocking systems on clayey soils rotate more than those on sandy soils with the same range of slenderness ratios (1.0 < h/B < 2.0). This behavior is consistent with the clayey soil foundations’ ability to dissipate more seismic energy compared to sandy soils for a given shaking intensity [
7].
Figure 2b presents the variation of peak rotation of foundation (θ
peak) with Arias intensity (I
a) of earthquake motion for the same data and the same group of rocking foundations (same as in
Figure 2a). In addition to the amplitude of shaking acceleration, I
a also includes the effects of frequency content and duration of shaking, and hence it is not a redundant input feature to correlate and predict peak rotation of rocking foundations. The data in both
Figure 2a,b, in general, show similar trends, although the scatter in data is slightly higher in
Figure 2b. As can be seen from
Figure 2b, as I
a increases, the peak rotation of rocking foundation increases, and for a given I
a, peak rotation increases with increasing h/B ratio. It turns out that I
a is the second most important feature after a
max in predicting the peak rotation of rocking foundations (presented in
Section 5.3: Significance of input features).
Figure 3 shows the schematic of a lumped mass–column–foundation representation of a relatively rigid structure rocking on supporting soil, illustrating the initial (red) and rotated (blue) positions of the structure and footing during rocking. Critical rotation of a rocking structure (θ
crit) can be defined as the magnitude of rotation that would possibly cause tipping-over failure of the structure–foundation system during earthquake. Using static equilibrium conditions on the verge of tipping-over failure, the maximum horizontal displacement at the center of gravity of the structure (Δ
crit) during earthquake shaking that would cause tipping-over failure can be obtained by,
where B
c is the critical contact width of the footing with the soil (in the direction of shaking) that is required to support applied vertical load (B
c is defined and is correlated to the bearing capacity of a square or rectangular foundation in
Section 3.2). The critical rotation (θ
crit) can then be defined as,
In order to quantify the stability of rocking systems against tipping-over failure during shaking, a factor of safety for tipping over (FS
TO) can be defined by comparing the peak rotation with the critical rotation of the rocking system. On the verge of static (limiting) equilibrium during rocking, the factor of safety for tipping-over failure is defined as,
Figure 4a presents the variation of factor safety for tipping over (FS
TO) with peak ground acceleration (a
max) of the earthquake ground motion for different clusters of slenderness ratio (h/B) of the structure–footing systems (the same groups of experiments presented in
Figure 2).
Figure 4b presents the same dataset with Arias intensity of ground motion (I
a) on the
x-axis. It can be seen from
Figure 4 that FS
TO is as high as 400 during shaking for relatively smaller intensity earthquakes and at least 2.0 or greater for higher intensity earthquakes. As expected, FS
TO decreases as a
max and I
a increase, and for a given a
max or I
a, FS
TO decreases as h/B increases. Though there is scatter in the data, none of the FS
TO values approach 1.0 (critical FS
TO on the verge of tipping-over failure). This is consistent with the experimentally observed behavior that none of the structure–footing systems used in any of these 140 experiments tipped over during shaking. Data also show that the tipping-over stability of rocking foundations is higher on clayey soils compared to sandy soil foundations. This behavior is also consistent with the previous research findings. Sharma and Deng (2019) [
28], based on field experiments of rocking foundations on clayey soils, concluded that rocking systems on clay exhibited a re-centering ability that is better than on sand.
5. Results and Discussion
The initial evaluation of machine learning models using a randomly selected pair of training and testing datasets is presented first and it is followed by the results of hyperparameter tuning of the models, input feature importance analysis using multiple random training datasets, and repeated k-fold cross validation tests of the models using multiple random splits of training and testing datasets. The metrics used to evaluate the performance of machine learning models developed in this study include mean absolute error (MAE) and mean absolute percentage error (MAPE), and they are defined as,
where y is the actual output value (experimental data), ỹ is the predicted output value, and the subscript “i” runs from 1 up to the number of predictions (n). As the experimental data considered covers a significant range of values with scatter (
Figure 2 and
Figure 4), MAE and MAPE are preferred and chosen over the commonly used root mean square error measure in machine learning models. In addition, while MAE measures the error in terms of the absolute values of output parameter, MAPE is independent of the absolute values and units of the output parameter (by normalization). For the purpose of comparisons, a multivariate linear regression (MLR) model was also developed using the same input features and supervised learning technique. Since the MLR model is a linear, parametric model, it was used as the baseline model for comparison of performances of different machine learning models. All the machine learning models in this study were developed using the implementations of the algorithms available in “scikit-learn” library of modules in Python (
https://scikit-learn.org/stable/, accessed on 1 August 2022).
5.1. Initial Evaluation of Models
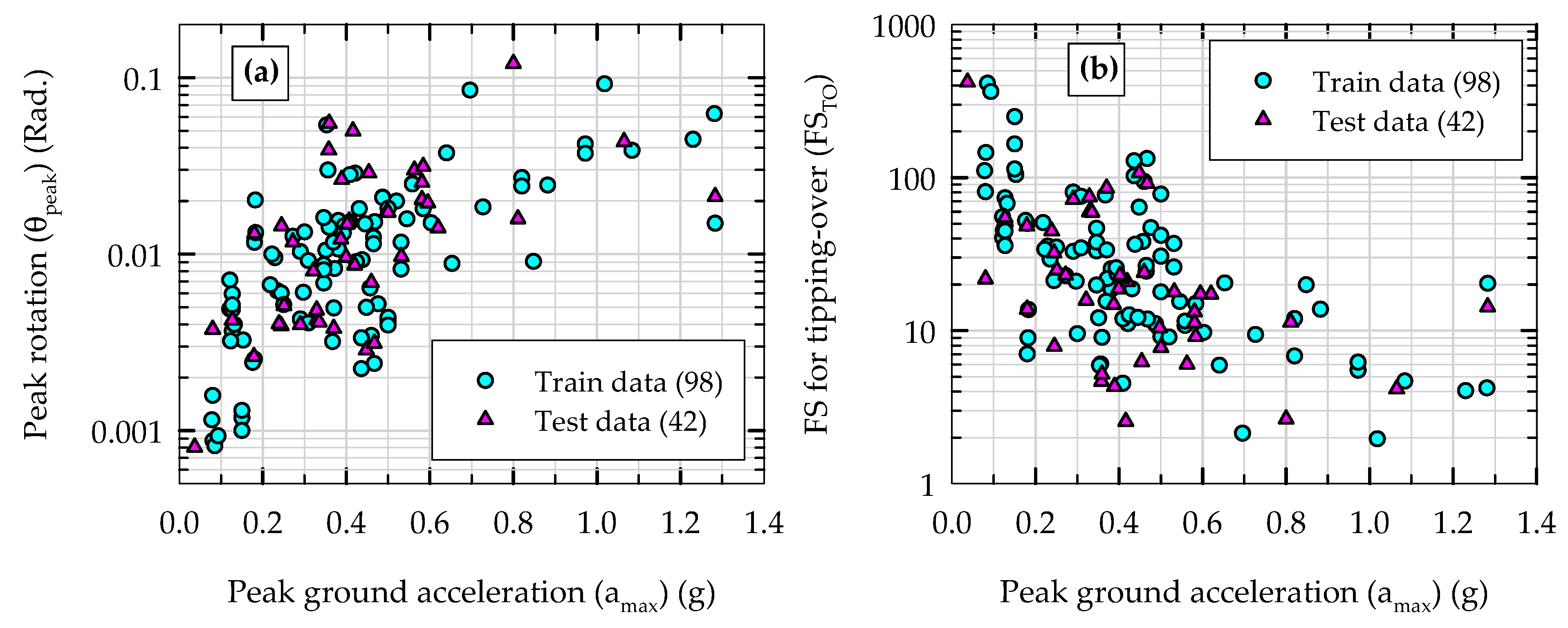
Altogether 140 experimental data (instances) were extracted from the above-mentioned database and are split into two groups for the purpose of initial training (supervised learning) and testing of machine learning models. A 70–30% split was used to randomly create the training dataset (98 instances) and testing dataset (42 instances) using the train-test-split function available in “scikit-learn” library of modules in Python. The 70–30% split is similar to the rule of thumb methods commonly used in supervised machine learning. Note that the random-state variable in this function was kept constant for this splitting of data for initial training and testing of all the models (i) to ensure consistency between different machine learning models and (ii) to ensure repeatability of results.
Figure 6a presents this split of data in θ
peak versus a
max space, while
Figure 6b presents the same split of data in FS
TO versus a
max space. This train–test split was created randomly, and as a result, both training and testing sets of data cover a wide range of values for all the parameters considered reasonably well. The machine learning models were first trained independently using the training dataset and then tested using the testing dataset. It should be noted that as the total number of data instances (140) is relatively small, a separate validation set was not used in this study; instead, hyperparameter tuning was carried out using multiple runs of the training dataset (presented in
Section 5.2).
The variations in predicted peak rotation (θ
peak) with the corresponding experimental θ
peak values on top of 1:1 prediction-to-experiment comparison lines during the testing phase are presented in
Figure 7 for four ML models: (a) KNN, (b) SVR, (c) DTR, and (d) RFR. Also included in
Figure 7 are the testing MAPE values of the predictions of each model. Note that the values of hyperparameters for all the models are kept at their optimum values (obtained from the hyperparameter tuning phase, described in the next section): k = 3 in KNN model, C = 20 and ε = 0.1 in SVR model, maximum depth of tree = 6 in DTR model, and number of trees = 100 and maximum number of random input features used in each tree = 2 in RFR model. As can be seen from
Figure 7, the KNN model outperforms the other three models in terms of the MAPE of prediction (0.33) during the initial testing phase, and it is followed by the SVR model (MAPE = 0.4). The DTR model (a single decision tree) results in a MAPE of 0.48 during testing phase; however, when 100 decision trees are combined as a random forest in the RFR model, the accuracy of the model improves slightly (MAPE = 0.44). To investigate the variance in individual predictions of the models, the standard deviations of the absolute percentage error (APE) in model predictions were also calculated. The standard deviations of the APE in predictions of θ
peak of KNN, SVR, DTR, and RFR models are 0.23, 0.38, 0.42, and 0.31, respectively. This indicates that in terms of variance in predictions of θ
peak, KNN is still the best out of the four models, and that the RFR model is better than both SVR and DTR in terms of variance in predictions.
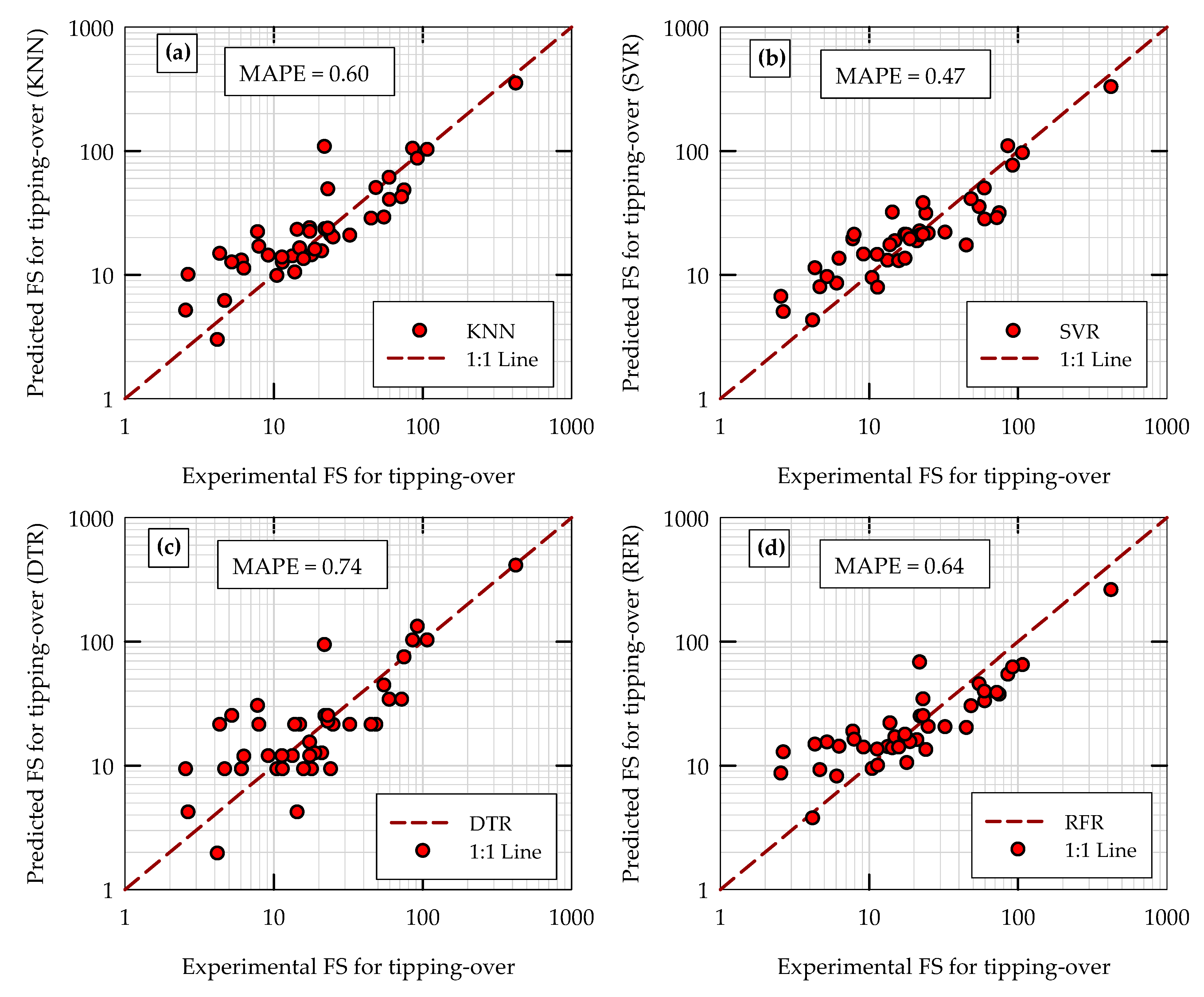
Figure 8 presents the comparisons of different model predictions during the testing phase with experimental results for factor of safety for tipping over (FS
TO) in the same format as in
Figure 7. The hyperparameters used for all four ML models are the same as above (the same as the ones used for the prediction of θ
peak). For the prediction of FS
TO, the SVR model turned out to be the best model during this initial testing phase (MAPE = 0.47). The KNN model (MAPE = 0.6) seems to have more deviations in predictions and is unable to compete with the SVR model. However, as can be seen from
Figure 8, the performance of the KNN model is still better than the DTR model in terms of accuracy of predictions. As in the case with θ
peak, by combining 100 decision trees together as an ensemble model, the RFR model was able to improve the accuracy (MAPE = 0.64) while reducing the variance in predictions of FS
TO compared to the DTR model. The standard deviations of the absolute percentage errors (APE) in predictions of the FS
TO of the KNN, SVR, DTR, and RFR models are 0.84, 0.48, 1.04, and 0.82, respectively. This indicates that in terms of variance in predictions of FS
TO, SVR is still the best out of the four models, and that the performance of the KNN and RFR models are relatively similar or comparable to each other and better than the DTR model in terms of variance in predictions. Note that, for all four machine learning models, the MAPE values and variance in the predictions of FS
TO (
Figure 8) are consistently higher than those of θ
peak (
Figure 7).
It should be noted that after the initial training phase of the ML models, in order to check the applicability of the models to represent the training data and to quantify what the models learned from the training data, all the machine learning models were first tested using the same training dataset (i.e., how well the models predict the same data that are used to train the models; referred to as training error). Another reason for this exercise was to make sure that the models did not overfit the training data, by comparing the testing error with the training error.
Figure 9 presents an all-error comparison for different scenarios to compare and contrast the performance of different machine learning models based on the MAPE in the prediction of θ
peak and FS
TO in initial training and testing phases of the models. Also included in
Figure 9 are the MAPE values of a multivariate linear regression (MLR) machine learning model developed as a baseline model using the same input features and the same training and testing datasets. MLR is a linear, parametric model, where a hyperplane is used to model the relationship between the output and multiple input variables. Based on the MAPE values of the models on training and testing data, it is apparent that all four nonlinear nonparametric machine learning models developed in this study (KNN, SVR, DTR, and RFR) perform better than the baseline MLR model. Among the four nonparametric models, KNN, SVR and RFR models perform better than DTR model in terms of accuracy of predictions (lower testing MAPE values). For all models, the testing MAPE values are greater than those in the training phase. This trend is a typical characteristic of machine learning models, especially when the size of the data is relatively small. This also confirms that the ML models developed in this study do not overfit the training data. The repeated k-fold cross validation test results (based on complete random shuffling and splitting of data) are presented later (
Section 5.4) to complement this error comparison.
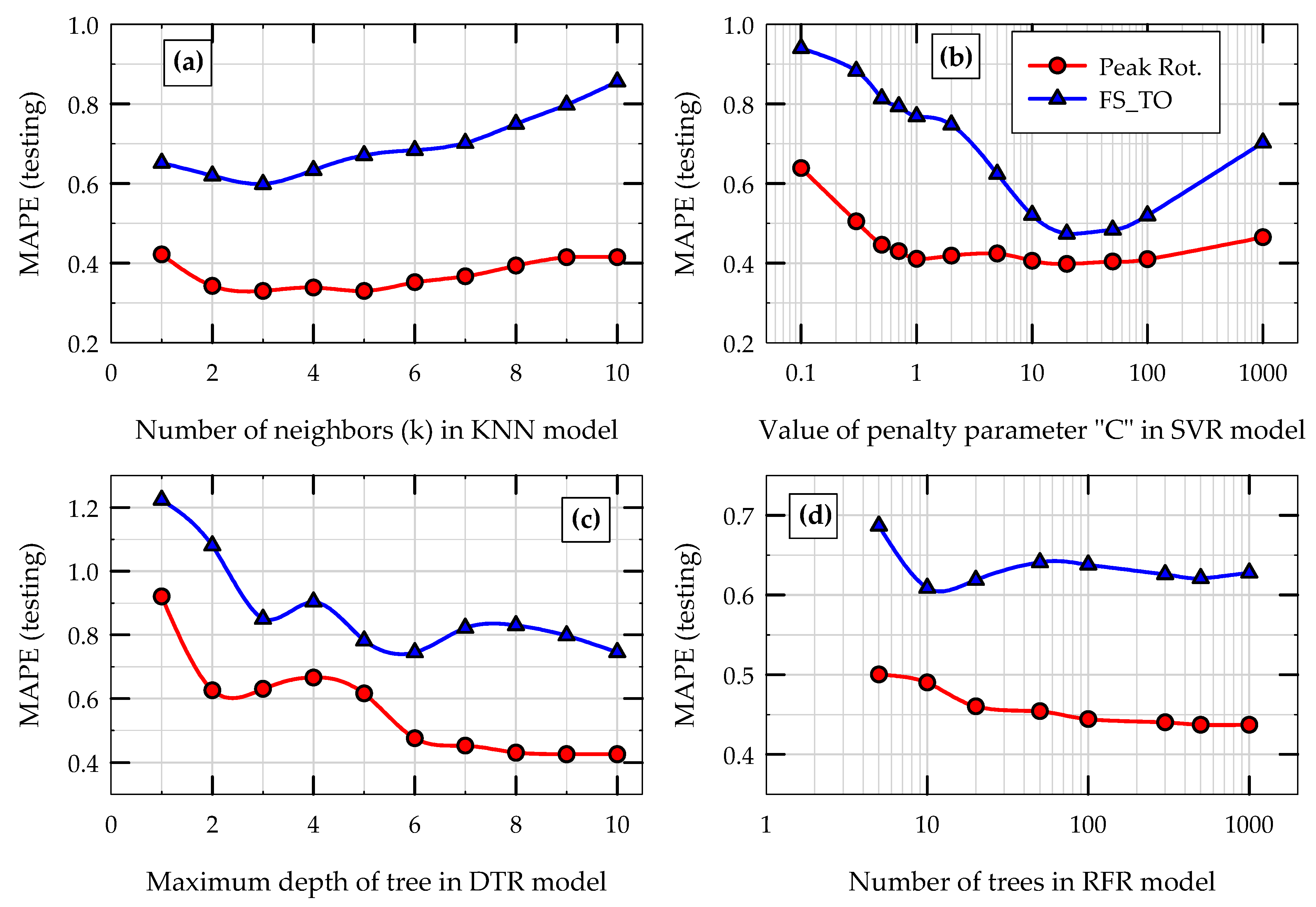
5.2. Hyperparameter Tuning of Models
For each ML model, the key hyperparameters were tuned by minimizing the MAPE values obtained during the initial testing phase of models (testing error). Hyperparameter tuning was carried out (i) to investigate the sensitivity of model predictions to their hyperparameters, (ii) to determine the optimum values of these parameters for the problem considered and data analyzed, and (iii) to ensure that the models neither overfit nor underfit the training data. It should be noted that the hyperparameter tuning was carried out separately for the predictions of θ
peak and FS
TO. The number of nearest neighbors (k), the cost or penalty parameter (C), the maximum depth of the tree, and the number of trees in random forest were varied for the KNN, SVR, DTR, and RFR models, respectively, and the corresponding MAPE values of predictions were calculated. The variations of testing MAPE values in the predictions of θ
peak and FS
TO with the corresponding hyperparameters are presented in
Figure 10 for all four nonlinear ML models.
For both θ
peak and FS
TO, the testing MAPE of the KNN model first decreases as the number of nearest neighbors considered (k) increases and then increases as k increases further (
Figure 10a). This is a typical behavior of the KNN algorithm when tested with previously unseen test data. The minimum MAPE during testing was obtained when k was equal to 3 for θ
peak and when k was in between 3 and 5 for FS
TO. Based on this observation and to be consistent, k = 3 was taken as the optimum value for KNN algorithm for both θ
peak and FS
TO. Any value smaller than the optimum for k would overfit the training data and any value greater than the optimum for k would underfit the training data. Similar to the KNN model, the MAPE during the testing phase of SVR model first decreases and then increases as C increases (
Figure 10b). It should be noted that the value of the margin (ϵ) in SVR model was kept at 0.1 for all cases. Neither a very small value for C (underfitting the training data) nor a very high value for C (overfitting the training data) is preferred. For both θ
peak and FS
TO, the optimum value of C was found to be 20.
Similar to the concept in the KNN and SVR models, for the DTR model (
Figure 10c), neither a very shallow tree (underfitting the training data) nor a very deep tree (overfitting the training data) is preferred and an optimum value for maximum depth of the tree is needed. Based on the trend shown in
Figure 10c, the optimum value for the maximum depth of tree of DTR model was chosen to be 6 for both θ
peak and FS
TO. For the RFR model, as can be seen from
Figure 10d, the testing MAPE decreases as the number of trees in the random forest increases, indicating that the accuracy of the model increases with the number of trees (this is more apparent for the prediction of θ
peak). It should be noted that the maximum number of random features to be considered was kept at 2 and the maximum depth of individual trees was kept at 6 for all trees in the random forest. After about 100 trees in the forest, the MAPE of the RFR model does not seem to decrease further, indicating that the optimum number of trees required is around 100.
5.3. Significance of Input Features
The implementation of the RFR model in the “scikit-learn” library of modules in Python has a function called “feature-importances” that outputs the relative importance of each input feature. This function measures a feature’s importance by looking at how much the tree nodes that use that feature reduce uncertainty in data on average (across all trees in the forest) [
16,
17]. The function computes this score for each feature after training, then it normalizes the results so that the sum of all feature importance values is equal to 1.0.
To investigate the significance of input features, twenty different RFR models were developed for both θ
peak and FS
TO by randomly selecting different sets of training data each time (by changing the random state variable), and the feature importance values were obtained for each random forest. The average values of the feature importance (as boxes) along with their standard deviations (as error bars) are presented in
Figure 11a,b for the prediction of θ
peak and FS
TO respectively. As can be seen from
Figure 11, the effects of different input features on both performance parameters (peak rotation and factor of safety for tipping over) are remarkably similar and consistent, verifying the inter-relationship between the two performance parameters. As expected and consistent with the previously published experimental results [
7], earthquake ground motion intensity parameters (a
max and I
a) have the most influence (30% to 35%) on both performance parameters. Three rocking foundation capacity parameters considered in this study as input features (A/A
c, h/B, and C
r) have quantitatively similar influence (about 10% each) on both performance parameters. The type of soil alone (sand or clay) does not have considerable influence on the performance parameters (less than or around 5% feature importance). These results and observations suggest that the earthquake ground motion intensity parameters contribute more to model predictions than the rocking system capacity parameters and type of soil (in other words, the peak rotation and tipping-over stability of rocking foundations are more sensitive to earthquake demand parameters than the properties of soil, foundation, and structure). The type of soil may be considered as a redundant input feature for the problem considered here; however, it should be noted that the shear strength of soil is already included in A/A
c and C
r through bearing capacity of soil.
5.4. Repeated K-Fold cross Validation Tests of Models
The k-fold cross validation test is a technique for evaluating the performance of machine learning models on multiple, different train–test splits of dataset. It provides a measure of how good the model performance is both in terms of accuracy and variance. In k-fold cross validation, the entire dataset is randomly split into k number of subsets called folds, and the ML model is first trained using (k − 1) folds of data and is tested using the remaining fold. This process is repeated k times, picking a different testing fold every time. A single run of k-fold cross validation (a single value for k) may result in noisy results for model error (MAE and MAPE) and hence multiple runs are carried out by varying k (number of folds) and by using random sampling each time. In this study, the complete dataset was randomly shuffled and split into different groups of train–test sets for k = 5 and 7. On top of this, for each of the 5-fold and 7-fold cross validations, the process was repeated three times (number of repeats = 3) with different randomization of the data in each repetition (repeated k-fold cross validation). With this setup, for each model, the repeated 5-fold and repeated 7-fold cross validation tests yielded 15 and 21 values, respectively, for k-fold testing of MAE and MAPE.
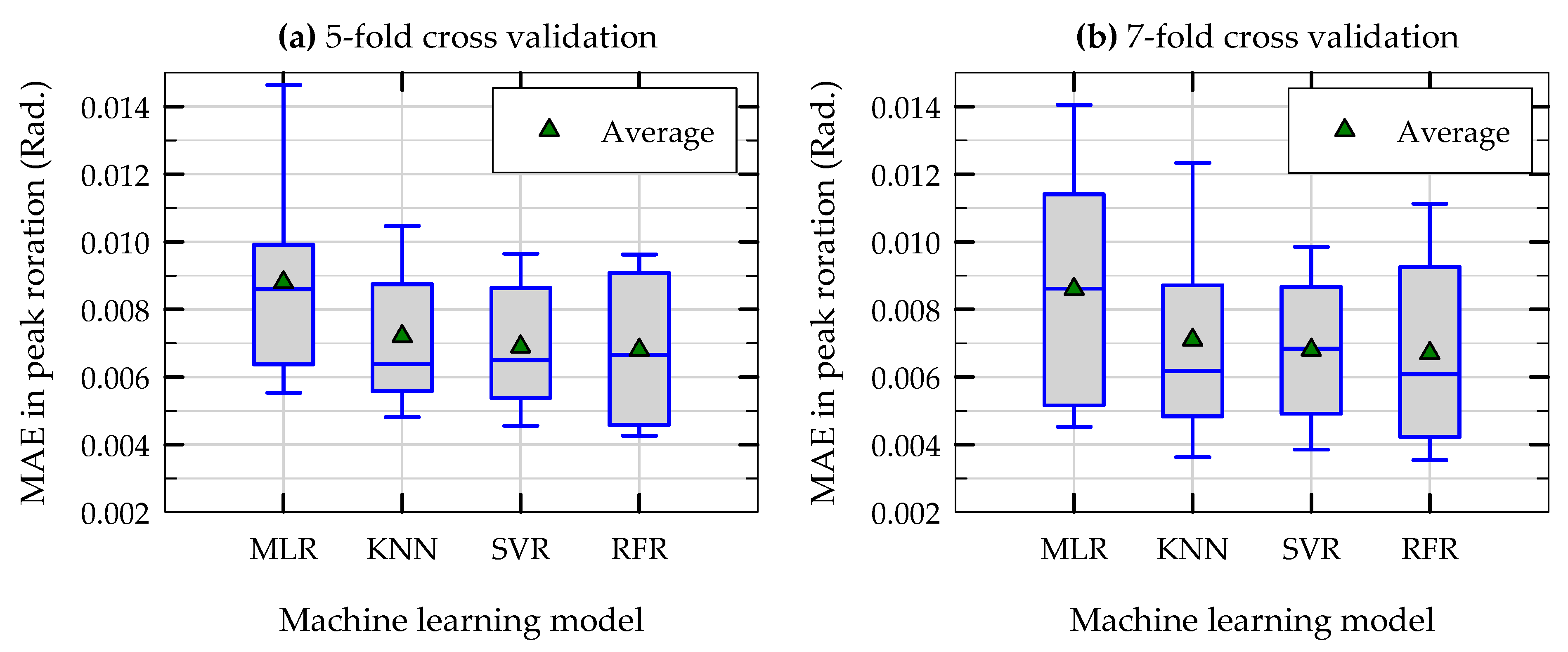
Figure 12 presents the results of MAPE of predictions of peak rotation in (a) repeated 5-fold cross validation tests and (b) repeated 7-fold cross validation tests for three nonlinear ML models (KNN, SVR, and RFR) along with the linear, baseline MLR model. In each case, the results obtained for testing MAPE are plotted in the form of boxplots. For each ML model, the boxplot plots the average of MAPE (triangles), median of MAPE (the horizontal line inside the box), 25th and 75th percentile values of MAPE (bottom and top edges of the box), and the 10th and 90th percentile values of MAPE (bottom and top horizontal lines outside the box). As can be seen from
Figure 12a,b, for all four ML models, the average values of MAPE in repeated 5-fold and 7-fold cross validation tests are remarkably close to each other (0.75 and 0.76 for MLR, 0.48 and 0.48 for KNN, 0.46 and 0.46 for SVR, and 0.53 and 0.51 for RFR), highlighting the overall consistency of all ML models developed in this study. The average MAPE values of all three nonlinear ML models (0.46 to 0.53) are smaller than that of the baseline MLR model (0.75). The average total variance in MAPE (the average of the difference between two extreme values of MAPE in 5-fold and 7-fold cross validation) of the KNN, SVR, and RFR models are 0.2, 0.3 and 0.32, respectively (the corresponding variance value of MLR is 0.46). In general, lower average MAPE (more accurate) and lower variance in MAPE (less sensitive to differences in training dataset) are preferred. Based on these results and observations, it can be concluded that for the prediction of peak rotation of rocking foundations, the three nonlinear models developed in this study perform much better than the linear MLR model, and that among the nonlinear models, the performance of the KNN model is slightly better than the other two.
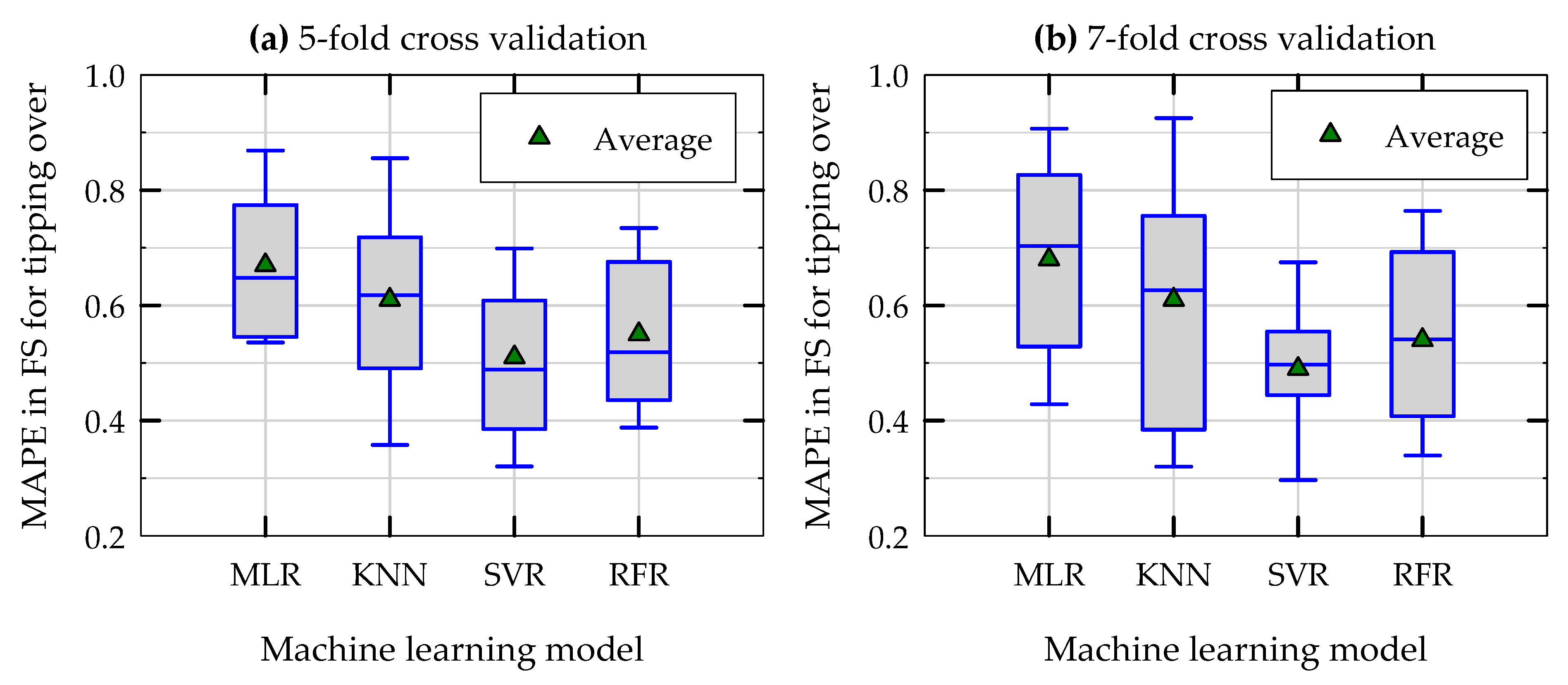
Figure 13 presents the results of MAPE of predictions of factor of safety for tipping over in (a) repeated 5-fold cross validation test and (b) repeated 7-fold cross validation tests for three nonlinear ML models along with the baseline MLR model. The observed trends in
Figure 13 (for FS
TO) are similar to those of in
Figure 12 (for θ
peak), except that the average and variance of MAPE in model predictions are slightly higher for FS
TO. Similar to the prediction of θ
peak, for all four ML models, the average values of MAPE in repeated 5-fold and 7-fold cross validation tests are remarkably close to each other for the prediction of FS
TO as well (0.67 and 0.68 for MLR, 0.61 and 0.61 for KNN, 0.51 and 0.49 for SVR, and 0.55 and 0.54 for RFR). As in the case with peak rotation, the average MAPE values of all three nonlinear ML models for the prediction of FS
TO (0.49 to 0.61) are smaller than that of baseline MLR model (0.67). The average total variance in MAPE of KNN, SVR, and RFR models are 0.55, 0.37, and 0.38, respectively. Based on these observations, it can be concluded that for the prediction of FS
TO of rocking foundations, the three nonlinear models developed in this study perform better than the linear MLR model, and that among the nonlinear models, the performance of the SVR model is better than the other two.
Figure 14 presents the results of MAE of predictions of peak rotation in (a) repeated 5-fold cross validation tests and (b) repeated 7-fold cross validation tests for three nonlinear ML models along with the baseline MLR model. A similar trend is observed for MAE of predictions of different models (similar to the trend observed for MAPE of predictions of peak rotation presented in
Figure 12): the performance of all three nonlinear ML models in terms of the average and variance of MAE of their predictions of θ
peak are better than that of the linear MLR model. The average MAE values of the three nonlinear ML models for peak rotation is around 0.007, indicating that the rocking-induced peak rotation can be predicted with an average accuracy of 0.007 radians (0.4 degrees). This error limit corresponds to a lateral displacement (at effective height of structure) that is approximately equal to 0.7% of the effective height of the structure.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













