In the work of Bader and Priest [
14], single carbon fibres were tested under tension at gauge lengths of 20 mm and 10 mm, having their strength measured in GPa. The data for both lengths are compared to assess which is statistically higher than the other. These data sets were modelled previously in several works (see, for example, [
15]). For the convenience of the reader, data sets of length 20 mm (
) and length 10 mm (
) are presented below:
and
Using Theorem 1 and Algorithm 1, the values of
,
and the
bootstrap confidence interval
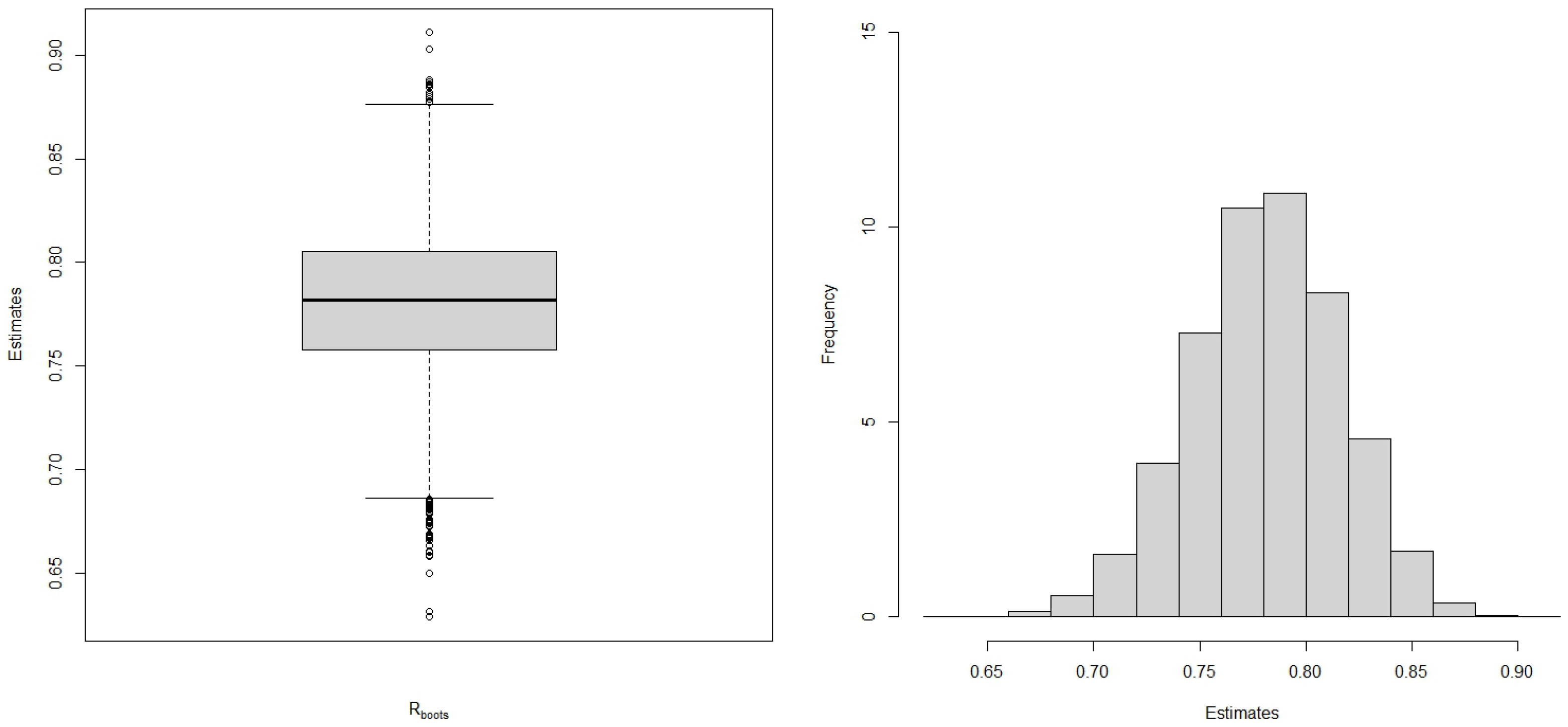
were obtained. The spread of the bootstrap estimates can be assessed in
Figure 6. From the results, it is possible to say that since
and
is not within the CI of the Bootstrap estimates, carbon fibres with a length of 20 mm (sampled from
X) show less strength when compared to carbon fibres with a length of 10 mm (sampled from
Y).
As mentioned, this dataset has already been analysed in the stress–strength context previously. Valiollahi et al. [
15] estimated
R after transforming the original data (so that the transformed data had the same scale parameter) and modelling it using the Weibull distribution. They considered MLE, approximate MLE (AML) and Bayes estimator obtaining the values
,
and
, respectively. They also obtained the 95% Boot-p and Boot-t confidence intervals as
and
. Their results cannot provide conclusive evidence of the true problem, as the transformation severely impairs the reliability calculations (now
is within the CI). In the present analysis, such a transformation is not needed since the BS distribution was a good candidate for modelling the data and Theorem 1 does not require equality of parameters between
and
. To compare the findings of the present study with their transformed datasets, using Tables 4 and 5 of [
15], it was estimated that
,
and
, which also sits on the reported confidence interval even though
distributions are considered.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}