1. Introduction
Smart sensors and sensor systems have become increasingly important in a wide range of industries due to their ability to gather, process, and provide data in real time. They are critical in various applications, including environmental monitoring, medical diagnosis, and industrial process control, where timely and accurate data are essential for decision making. Among various types of sensors, optical sensors have shown significant potential due to their high sensitivity, selectivity, and fast response time [
1]. Photoacoustic gas sensors (PAGSs) have emerged as a promising type of optical gas sensor due to their ability to use light to generate sound waves to detect gas molecules [
2,
3]. These sensors have several advantages, including high sensitivity and small size, which make them suitable for a range of gas-detection applications. However, PAGSs also have some limitations, such as their dependence on a high-power light source and sensitivity to environmental factors, which can affect the accuracy and robustness of the measurements they perform [
4]. Therefore, further comprehensive study of the features of PAGSs is crucial to ensuring their effectiveness and reliability.
Improving the performance of PAGSs can be achieved either by enhancing the characteristics of the equipment and underlying technologies or by developing effective algorithms for interpreting the data produced by PAGSs, which are used to estimate the gas concentration.
Enhancing the acoustic reaction and sensitivity of PAD systems can be achieved by employing more powerful radiation sources [
5]. In the visible range, cost-effective and powerful diode lasers can be used for a gas analysis. For example, Yin et al. showed that by employing a diode laser with a wavelength of 447 nm and a power of 3.5 W, a detection sensitivity of 54 pptv for nitrogen dioxide (NO
2) was achieved within 1 s of the integration time [
6]. In the near-infrared (near-IR) range, diode lasers combined with erbium-doped fiber amplifiers (EDFAs) [
7,
8] are commonly used as sources of radiation. Nevertheless, visible and near-IR laser diodes are not suitable for detecting all gases. The molecular transitions in the visible and near-IR ranges are at least ten times less intense than the fundamental absorption lines in the mid-IR part of the spectrum [
5]. In the mid-IR range, CO and CO
2 gas lasers [
9], interband cascade lasers (ICLs) [
10], along with quantum cascade lasers (QCLs) [
11,
12] and sources such as optical parametric oscillators (OPOs) and difference frequency generators (DFGs) [
13,
14] are commonly employed. To increase the average power of mid-IR radiation sources, additional amplification stages are sometimes also used [
15,
16]. Another method to enhance the sensitivity of gas analyzers involves acoustic wave amplification. To amplify the acoustic wave, various detector resonator configurations are used, such as resonant differential cells [
12], Helmholtz cells [
17], multipass cells [
18], and others [
5,
18]. To enhance the sensitivity of gas analyzers, different types of acoustic transducers are used, including electret microphones [
12], quartz tuning forks (QTF, QEPAS technology) [
19], cantilevers (CEPAS technology) [
20], and fiber-optic microphones [
21].
In recent years, machine learning (ML) has demonstrated great potential in the field of sensor data analysis and interpretation [
22,
23]. ML algorithms can identify complex patterns in data, learn from them, and use this knowledge to make predictions based on the data. When combined with sensors, ML algorithms can create a powerful analytical tool for accurate detection and analysis. There have been several examples of successful ML applications for sensors reported in the literature, demonstrating the potential for this approach in improving the performance and reliability of sensor systems.
The paper [
24] explores the integration of artificial intelligence (AI) in photoacoustic spectroscopy—a powerful and nondestructive technique with broad applications. The focus lies in utilizing AI to achieve the precise and real-time determination of photoacoustic signal parameters, addressing the inverse photoacoustic problem. A feedforward multilayer perceptron network is employed to enhance sensitivity and selectivity, enabling the simultaneous determination of crucial parameters, including the vibrational-to-translational relaxation time and laser beam radius.
In the paper [
25], a high-sensitivity gas-detection system for acetylene (C
2H
2) in the ultra-low concentration range is introduced by using photoacoustic spectroscopy (PAS) by Wang et al. This system employs a novel trapezoid compound ellipsoid resonant photoacoustic cell (TCER-PAC) and a partial least square (PLS) regression algorithm. The study concludes that the proposed PAS system, incorporating TCER-PAC and the PLS algorithm, demonstrates improved detection sensitivity and a lower limit of detection compared to PAS systems based on a trapezoid compound cylindrical resonator, providing a novel solution for high sensitivity and ultra-low concentration detection.
The paper [
26] addresses the challenge of selective detection in metal oxide chemiresistive gas sensors with inherent cross-sensitivity. Employing soft computing tools such as Fast Fourier Transform (FFT) and Discrete Wavelet Transform (DWT), the transient response curves of the sensor are processed to extract distinctive features associated with target volatile organic compounds (VOCs). Comparative analysis favors DWT for its superior focus on signal signatures. Extracted features are fed into machine learning algorithms for the qualitative discrimination and quantitative estimation of VOC concentrations. The study emphasizes efficient feature selection, enabling machine learning to achieve an outstanding classification accuracy of 96.84% and precise quantification. The results signify a significant advancement toward automated and real-time gas detection.
The paper [
27] reviews the challenges encountered by phase-sensitive optical time-domain reflectometer (
-OTDR) systems, commonly referred to as distributed acoustic sensing, when monitoring vibrational signals across extensive distances. These systems, operating in complex environments, often face intrusion events and noise interferences, which can affect their overall efficiency. The paper explores several techniques proposed in recent studies to mitigate these challenges, with a specific emphasis on system upgrades, enhancements in data processing, and the integration of ML methods for event classification.
In this study, we propose a novel approach that utilizes a combination of wavelet analysis and neural networks to improve the accuracy and sensitivity of photoacoustic gas sensors. The wavelet analysis method allows for the better detection of gas signals in noisy data, while the use of neural networks with enhanced architectures enables the system to learn complex relationships between the data and the gas concentration. To evaluate the performance of our approach, we conducted laboratory experiments aimed at detecting methane across various concentrations. We then compared our results with those obtained through the conventional Fourier-based method of concentration estimation. Our proposed approach has the potential to provide more accurate and reliable results, resulting in a more efficient gas-detection system. It has the potential to significantly advance the field of gas detection and analysis. The novelty of this work lies in the use of wavelet analysis and machine learning in combination with traditional methods of photoacoustic spectroscopy.
4. Problem Formulation and Proposed Solution
The data-processing algorithm, outlined in
Section 3, proves effective and applicable when the power of the acoustic signal at the resonant frequency significantly exceeds that at other frequencies. This is typically observed in two scenarios: (i) with relatively high gas concentrations and (ii) when utilizing high-quality sensor components like a microphone or radiation source that avoids introducing significant signal distortions. Furthermore, stable environmental conditions are essential to prevent any influence on the measurement process.
However, in scenarios involving low gas concentrations or the use of inexpensive, low-quality sensor components, the power of the acoustic signal may be comparable to the power of the background noise. In such cases, standard algorithms may lack effectiveness, necessitating advanced approaches. These data interpretation approaches hold the potential to enhance the sensitivity threshold of PAGS, reduce costs through the use of more affordable components, and alleviate sensitivity to environmental factors.
To develop and assess the performance of such approaches, we proposed the following methodology based on collected experimental data. We used the experimental data obtained in the laboratory for all concentrations, which were processed by the basic algorithm, as target values. Subsequently, we generated new datasets for further investigation by introducing additive white Gaussian noise to the experimental signal from the microphone for each of the three concentrations. The noise was uniformly added to the data for each concentration, simulating the degradation of the microphone’s performance. To quantify the amount of added noise, we employed the peak signal-to-noise ratio (PSNR), defined as the ratio of the power of the acoustic signal at the resonant frequency to the average power of the background noise at other frequencies. The obtained noisy signal, denoted as , and the signal were utilized as input signals for both the basic and proposed algorithms. To evaluate the performance of both algorithms, we computed metrics (the mean squared error and mean absolute percentage error) between the output of the algorithms on noisy data and the target value .
In the approach proposed in this study, we suggest performing a wavelet transform of the received signals instead of a Fourier transform. The resulting wavelet representation of signals is then used as input data for neural networks with advanced architectures.
4.1. Wavelet Transform
A wavelet analysis is a powerful method for studying the structure of heterogeneous processes. Currently, wavelets are widely used in pattern recognition, signal processing, and the synthesis of various signals such as speech signals and image analysis, as well as for compressing large amounts of information in many other fields [
33]. The one-dimensional wavelet transform involves decomposing a signal into a basis formed by a soliton-like function called a wavelet. Each function in this basis describes the signal in spatial or temporal frequency and its localization in physical space (time) [
34]. Unlike the conventional Fourier transform, the one-dimensional wavelet transform yields a two-dimensional representation of the signal in the time–frequency domain. Wavelet transforms can be either discrete or continuous.
4.1.1. Continuous Wavelet Transform
The mathematical expression for the continuous wavelet transform (CWT) involves the convolution of the wavelet function
with the signal
, defined as:
where
a is the scale coefficient, responsible for wavelet scaling, and
b is the shift parameter, responsible for wavelet translation. The choice of the mother wavelet
is typically guided by the specific task and the information intended to be extracted from the signal.
In our case, working with signals from an optoacoustic gas analyzer, we studied more than twenty wavelet functions and selected the complex Morlet wavelet:
where
B represents the bandwidth and
C denotes the central frequency. For our task, we selected a bandwidth of one and a central frequency of 1780 Hz. We applied continuous wavelet transform to the recorded time series of the acoustic signal from the microphone and the optical signal from the receiver. Then, we computed the real part of the obtained wavelet coefficients. As a result, we obtained two images of size 50 × 48,000 pixels, corresponding to the signals
and
.
Figure 3 illustrates the characteristic pattern of wavelet coefficients for a gas concentration of 954 ppm.
4.1.2. Wavelet Packet Transform
Wavelet packet transform (WPT) is a variation of the Discrete Wavelet Transform widely employed in digital signal processing for analysis and compression. In the WPT process, the signal is divided into a set of sub-bands using low-pass and high-pass filters. Each sub-band can be further subdivided into two sub-bands. This process continues iteratively until the desired level of decomposition is achieved. Each sub-band contains information about different frequency components of the signal. For instance, low-pass filters capture low-frequency features of the signal, while high-pass filters emphasize high-frequency details. The sub-band corresponding to low frequencies is termed the approximation sub-band (A), while the one obtained using the high-pass filter is called the detail sub-band (D).
Figure 4 illustrates the WPT process with a decomposition level of three. Each subsequent sub-band reduces the number of coefficients by approximately half compared to the previous one. The exact reduction depends on the choice of the wavelet function and the method of signal extrapolation at the boundaries.
For decomposing the microphone and laser signals from the optoacoustic gas analyzer, we employed a partial enumeration method and selected a wavelet from the Daubechies family, specifically the fifth order (db5). To improve the decomposition results at the signal boundaries, we applied periodic extrapolation, considering the periodic structure of the original signal. We selected a decomposition level of eight. As a result, from each temporal series with 48,000 measurements, we obtained 256 sub-bands of decomposition. Each sub-band consisted of 196 values. These 256 sub-bands were then organized into a two-dimensional image of size
pixels, accounting for the frequency characteristics of each sub-band. In total, we have two
images, corresponding to the signals
and
. The preprocessed data result is depicted in
Figure 5.
In our investigation, we observed that employing wavelet packet transform instead of continuous wavelet transform leads to a substantial reduction in video card memory requirements, exceeding 40 times. This substantial decrease enhances the speed of prediction calculations and accelerates neural network training. It opens possibilities for exploring deeper convolutional neural network architectures, ultimately improving the accuracy of predictions.
4.2. Neural Networks
Our initial concept was based on employing the outcomes of continuous wavelet transform applied to both acoustic and optical signals. To achieve this, we augmented the initial dataset of 600 measurements to 1200 by duplicating all values twice and then added random additive white Gaussian noise of fixed amplitude to the microphone signal. As a result, we obtained a noisy signal with a parameter PSNR of 5.47, 12.79, and 54.38 dB for concentrations of 1.9, 9.7, and 954 ppm, respectively. The result of the CWT from these signals was used as inputs for a convolution neural network (CNN) with designed architecture, as shown in
Figure 6. Thus, the CNN received two wavelet coefficients images, each sized 50 × 48,000 pixels, as the input. Then, a two-dimensional convolution was applied to each image using a shared kernel of size
. The absolute values of the resulting images were then calculated, followed by a max pooling subsampling layer with a size of
. Then, temporal averaging was performed, resulting in seven values remaining for each image. Following this, a linear combination of these values with trainable weights was computed. The output of the convolutional neural network was the ratio of the value corresponding to the acoustic signal to the value corresponding to the optical signal. The target output signal value was the ratio of the amplitudes of signals
for the noiseless dataset.
To train the neural network, the dataset was divided into training and testing sets, with 840 measurements in the training set and 360 measurements in the testing set. The mean squared error (MSE) was chosen as the loss function. For optimization, we employed the Adam optimization algorithm, adjusting the learning rate dynamically as it reached a plateau. The convolutional neural network was implemented using the PyTorch library 2.1.0 and trained on an Nvidia GTX 1080 Ti graphics card with 11 GB of video memory. The model’s performance evaluation was carried out using the mean absolute percentage error (MAPE) on the predicted values. In the case of the approach employing a continuous wavelet transform in the convolutional neural network, the MAPE error for a concentration of 1.9 ppm was 93%, whereas the Fourier-based approach resulted in an error of 122.3%. The outcomes of the CWT and other approaches are summarized in the
Section 5 (Table 3).
While we observed a slight improvement in prediction outcomes, we noted a constraint when training deep neural networks with input images of substantial dimensions derived from a continuous wavelet transform. Moreover, the training and prediction processes using this wavelet transform approach proved to be time consuming. Consequently, we made a decision to shift from a continuous wavelet transform to a wavelet packet transform.
4.2.1. VGG-Net Architecture
One of the most widely adopted configurations of deep convolutional neural networks is known as the VGG architecture. Originating in 2014 at the University of Oxford, its key innovation lies in employing a
convolutional kernel with a stride of one [
35,
36]. The application of two consecutive
convolutional layers creates a receptive field of size
, requiring only 18 trainable weights. In contrast, using a single
convolutional layer would demand 25 weights. This design choice enables the neural network to achieve greater depth with the same number of trainable weights. The ability to create deeper VGG network models allows for capturing a higher degree of nonlinearity, facilitated by the additional rectified linear unit (ReLU) nonlinearity between layers [
37]. We introduce modifications to adapt this architecture for regression tasks, particularly in the structure of the neural network’s output layer and fully connected layers. Additionally, due to limitations in the data volume, we decide to reduce the number of layers and channels in each layer.
Like in the convolutional neural network designed for continuous wavelet transform (
Figure 6), two images of noisy signals were employed as the input. These images represented wavelet packet transform maps with dimensions of
pixels. Each image underwent processing by a neural network with uniform weights, generating one output value for the microphone signal and another for the laser signal. Subsequently, the ratio between these outputs was computed. Here, the target value was the noiseless result of the baseline Fourier approach. The training dataset, validation dataset, and test dataset include 9000, 2400, and 600 measurements, respectively. In total, our dataset consisted of 12,000 measurements obtained from 600 noiseless measurements using 20 random noise realizations. The validation set was employed for optimizing model hyperparameters, ensuring that the test set was never used for training.
We employed the open-source library Optuna to tune the hyperparameters and find the optimal architecture for the VGG-type convolutional neural network [
38]. The Adam optimization algorithm was chosen as the learning algorithm, and the initial learning rate was optimized in the range from
to
. A learning rate reduction algorithm was applied when the validation metric MSE reached a plateau. The hyperparameter “factor”, responsible for reducing the learning rate when reaching a plateau, was selected in the range of 0.1 to 0.9. Additionally, the number of epochs for patience, after which the learning rate was decreased if there was no improvement in accuracy on the validation dataset, was optimized in the range of 2 to 7. The batch size was adjusted within the range of 2 to 64, and the number of epochs was set to 60. The number of channels in each convolutional layer was adjusted from 1 to 32, and the number of neurons in the hidden fully connected layer was chosen within the range of 2 to 16. The optimal architecture of the VGG-type convolutional neural network is presented in
Table 1. The applied layers of the neural network are shown in the table in the order in which the image passes through the neural network. A ReLU layer was used as an activation function after each convolutional and fully connected layer.
An efficient optimization algorithm called TPE was used to search for optimal hyperparameters. This algorithm is a variation of the Bayesian optimization method [
39]. It operates iteratively, using information about previously evaluated hyperparameters to create a probabilistic model, which is then used to propose the next set of hyperparameters. Additionally, the Hyperband algorithm was employed to early stop unpromising models during the early stages of training. This modern algorithm makes decisions about discarding unsuccessful models based on multiple concurrently computed results. This approach helps avoid discarding models that converge slowly at the beginning but achieve good results in the end [
40]. A total of 60 models were analyzed during the optimization process. The optimization was conducted using Tesla V100 GPUs. It took one week of computational time using two GPUs simultaneously to fine tune the hyperparameters.
4.2.2. ResNet Architecture
The next architecture selected for deep convolutional neural networks was ResNet. In practice, an accuracy degradation is observed when increasing the depth of neural networks. This decline impacts both the training and test datasets. Importantly, this challenge is not associated with overfitting but rather stems from the inherent difficulties in training deep neural networks [
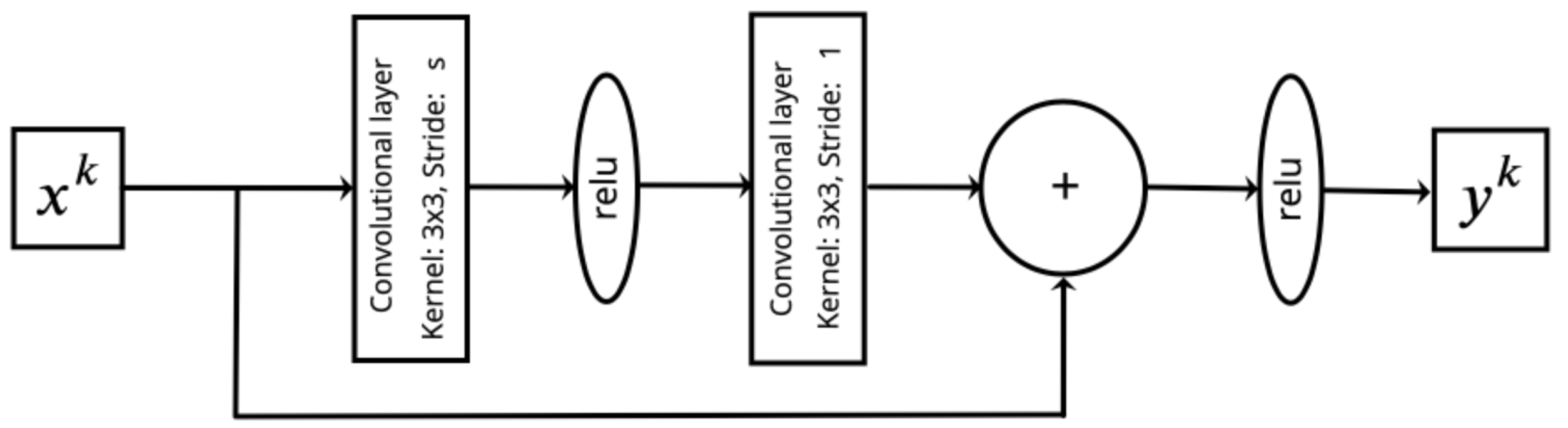
37]. To address the problem of training degradation, the research team at Microsoft Research proposed the concept of deep residual learning, which forms the basis for the ResNet architecture. The residual block serves as the fundamental building block of the residual neural network. The architecture of a single residual block (ResBlock) used for methane concentration restoration from noisy data is shown in
Figure 7. One notable feature of this block is the absence of batch normalization. This is because the information is encoded in the signal amplitude. Adding this layer to the investigated architectures resulted in a significant deterioration in the MSE metric.
For the ResNet neural network architecture, similar to the VGG convolutional neural network, the input comprised two wavelet packet transform images of size
pixels derived from a noisy signal. The training, validation, and test dataset comprise 9000, 2400, and 600 measurements, respectively. The Adam algorithm was used for training, with a reduction in the learning rate when the validation MSE metric reached a plateau. The learning rate hyperparameters were tuned in the same range as for VGG. The batch size was optimized in the range of 2 to 64. The number of epochs was set to 60. The number of channels in each residual block was adjusted in the range of 1 to 64. The number of neurons in the hidden fully connected layer was selected in the range of 2 to 32. The optimal ResNet neural network architecture is presented in
Table 2. The neural network layers used are shown in the table in the order in which the image passes through the neural network. The ReLU layer was used as an activation function after each convolutional and fully connected layer and also inside the residual blocks. The architecture of residual blocks is shown in
Figure 7.
The search for optimal hyperparameters was conducted using the TPE optimization algorithm and the early stopping method Hyperband. A total of 60 models were analyzed. The optimization was conducted using Tesla V100 GPUs. It took two weeks of computational time using two GPUs simultaneously to fine tune the hyperparameters.
5. Results and Discussion
To train the VGG convolutional neural network architecture, as outlined in
Table 1, we generated five independent datasets, each containing 12,000 samples, corresponding to five levels of noise applied to the microphone signal (PSNR = −14.75, −6.73, 5.47, 20.16, 33.74 dB for a concentration of 1.9 ppm). Independent training processes were carried out for each noise level, concurrently addressing three investigated concentrations with the same noise amplitude applied to the microphone signal. Consequently, a separate neural network was trained for each noise amplitude level. The results of the test dataset, which was not employed during the training process, are illustrated in
Figure 8. This figure presents a comparison between the VGG architecture approach using WPT and the baseline Fourier approach for methane concentrations of 9.7 ppm and 1.9 ppm. The vertical axis denotes the MSE metric in ppm
2, while the horizontal axis represents the PSNR parameter.
From
Figure 8, we observed that when the peak signal-to-noise ratio of the microphone signal for a concentration of
ppm is below 20 dB (indicated by the orange dot), a notable reduction in the MSE deviation is observed for the VGG architecture compared to the baseline Fourier-based approach. For these noise levels, the Fourier-based approach struggles to accurately determine the
concentration, rendering it ineffective. Conversely, convolutional neural network architectures like VGG, utilizing wavelet packet decomposition, maintain the accurate recovery of the methane concentration even at high noise levels (purple and blue dots), showcasing a significantly lower MSE on the test dataset. It should be noted that for the low noise level (red dot), the Fourier-based approach outperforms the VGG accuracy, as the PSNR is still high even for the lowest concentration 1.9 ppm, and the signal does not degrade substantially. Additionally, for VGG, we observed a sharp increase in the MSE for a PSNR less than 0 dB for all concentrations. However, VGG neural networks still demonstrate superior performance compared to the standard Fourier-based approach.
To compare the approaches based on the VGG and ResNet architectures, two neural networks were trained at a noise level of PSNR = 5.47 dB for a methane concentration of
ppm. This noise level corresponds to the results presented in
Figure 8 (green dot). The input data consisted of images obtained using wavelet-packet transform. After predicting the concentration in the test dataset, two graphs were plotted for the metrics MSE and MAPE as a function of the analyzed concentration, as shown in
Figure 9.
It can be seen from
Figure 9 that the ResNet architecture also demonstrates strong results in predicting concentration and slightly outperforms the results of the VGG architecture for both metrics. Furthermore, we trained a neural network with the same VGG architecture detailed in
Table 1. However, for the input images, we utilized images obtained through the Short-Time Fourier Transform (STFT). The target value was also the output of the baseline Fourier approach without noise. The STFT transform was computed using a Hann window. The results are depicted in
Figure 9 by the green line. As seen from the figure, this approach performs better than the baseline Fourier-based method but lags behind methods employing wavelet packet transform. The summarized results for the investigated models estimating methane concentration are presented in
Table 3.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}