
A Robust Indicator Mean-Based Method for Estimating Generalizability Theory Absolute Error and Related Dependability Indices within Structural Equation Modeling Frameworks

Abstract
:1. Introduction
2. Background
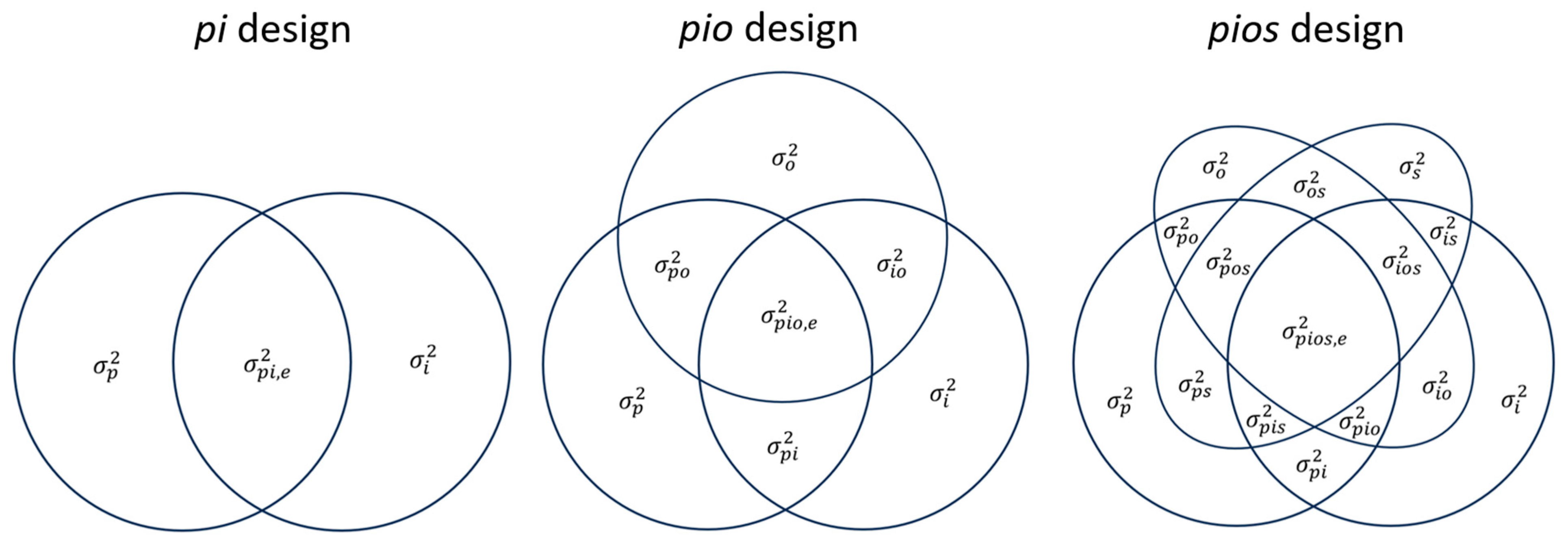
2.1. Generalizability Theory
2.2. Estimation of Universe Scores and Relative Error Using SEMs
2.3. Overview of Absolute Error Estimation within SEMs
2.4. The Indicator Mean-Based Method for Estimating Absolute Error Indices
2.5. Jorgensen’s Procedure for Estimating Absolute Error Indices
2.6. Advantages of Analyzing GT Designs Using SEMs
3. This Investigation
4. Methods
Participants, Measures, and Procedure
5. Analyses
6. Results
6.1. Descriptive Statistics and Conventional Reliability Estimates
6.2. Comparisons of Variance Components, G Coefficients, and Global D Coefficients across Methods
6.2.1. persons × items (pi) designs
6.2.2. persons × items × occasions (pio) designs
6.2.3. persons × items × occasions × skills (pios) design
6.3. Cut-Score-Specific D Coefficients
7. Discussion
7.1. Overview
7.2. Discrepancies between SEM Methods for Estimating Absolute Error Indices
7.3. Summary of Advantages of the Indicator Mean-Based Method and Future Applications
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cronbach, L.J.; Rajaratnam, N.; Gleser, G.C. Theory of generalizability: A liberalization of reliability theory. Br. J. Stat. Psychol. 1963, 16, 137–163. [Google Scholar] [CrossRef]
- Cronbach, L.J.; Gleser, G.C.; Nanda, H.; Rajaratnam, N. The Dependability of Behavioral Measurements: Theory of Generalizability for Scores and Profiles; Wiley: New York, NY, USA, 1972. [Google Scholar]
- Shavelson, R.J.; Webb, N.M. Generalizability Theory: A Primer; Sage: Thousand Oaks, CA, USA, 1991. [Google Scholar]
- Brennan, R.L. Generalizability Theory; Springer: New York, NY, USA, 2001. [Google Scholar]
- Chen, D.; Hebert, M.; Wilson, J. Examining human and automated ratings of elementary students’ writing quality: A multivariate generalizability theory application. Am. Educ. Res. J. 2022, 59, 1122–1156. [Google Scholar] [CrossRef]
- Anderson, T.N.; Lau, J.N.; Shi, R.; Sapp, R.W.; Aalami, L.R.; Lee, E.W.; Tekian, A.; Park, Y.S. The utility of peers and trained raters in technical skill-based assessments a generalizability theory study. J. Surg. Educ. 2022, 79, 206–215. [Google Scholar] [CrossRef]
- Tindal, G.; Yovanoff, P.; Geller, J.P. Generalizability theory applied to reading assessments for students with significant cognitive disabilities. J. Spec. Educ. 2010, 44, 3–17. [Google Scholar] [CrossRef]
- Mantzicopoulos, P.; French, B.F.; Patrick, H.; Watson, J.S.; Ahn, I. The stability of kindergarten teachers’ effectiveness: A generalizability study comparing the framework for teaching and the classroom assessment scoring system. Educ. Assess. 2018, 23, 24–46. [Google Scholar] [CrossRef]
- Lightburn, S.; Medvedev, O.N.; Henning, M.A.; Chen, Y. Investigating how students approach learning using generalizability theory. High. Educ. Res. Dev. 2021, 41, 1618–1632. [Google Scholar] [CrossRef]
- Ohta, R.; Plakans, L.M.; Gebril, A. Integrated writing scores based on holistic and multi-trait scales: A generalizability analysis. Assess. Writ. 2018, 38, 21–36. [Google Scholar] [CrossRef]
- Shin, J. Investigating and optimizing score dependability of a local ITA speaking test across language groups: A generalizability theory approach. Lang. Test. 2022, 39, 313–337. [Google Scholar] [CrossRef]
- Hollo, A.; Staubitz, J.L.; Chow, J.C. Applying generalizability theory to optimize analysis of spontaneous teacher talk in elementary classrooms. J. Speech Lang. Hear. R. 2020, 63, 1947–1957. [Google Scholar] [CrossRef] [PubMed]
- Bergee, M.J. Performer, rater, occasion, and sequence as sources of variability in music performance assessment. J. Res. Music Educ. 2007, 55, 344–358. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Lee, H.; Chen, T.; Hong, H. Using structural equation modeling to reproduce and extend ANOVA-based generalizability theory analyses for psychological assessments. Psych 2023, 5, 249–273. [Google Scholar] [CrossRef]
- Kumar, S.S.; Merkin, A.G.; Numbers, K.; Sachdev, P.S.; Brodaty, H.; Kochan, N.A.; Trollor, J.N.; Mahon, S.; Medvedev, O. A novel approach to investigate depression symptoms in the aging population using generalizability theory. Psychol. Assess 2022, 34, 684–696. [Google Scholar] [CrossRef]
- Winterstein, B.P.; Willse, J.T.; Kwapil, T.R.; Silvia, P.J. Assessment of score dependability of the Wisconsin Schizotypy Scales using generalizability analysis. J. Psychopathol. Behav. Assess. 2010, 32, 575–585. [Google Scholar] [CrossRef]
- Truong, Q.C.; Krägeloh, C.U.; Siegert, R.J.; Landon, J.; Medvedev, O.N. Applying generalizability theory to differentiate between trait and state in the Five Facet Mindfulness Questionnaire (FFMQ). Mindfulness 2020, 11, 953–963. [Google Scholar] [CrossRef]
- LoPilato, A.C.; Carter, N.T.; Wang, M. Updating generalizability theory in management research: Bayesian estimation of variance components. J. Manag. 2015, 41, 692–717. [Google Scholar] [CrossRef]
- Wang, L.; Finn, A. Measuring CBBE across brand portfolios: Generalizability theory perspective. J. Target. Meas. Anal. Mark. 2012, 20, 109–116. [Google Scholar] [CrossRef]
- Finn, A. Generalizability modeling of the foundations of customer delight. J. Model. Manag. 2006, 1, 18–32. [Google Scholar] [CrossRef]
- Highhouse, S.; Broadfoot, A.; Yugo, J.E.; Devendorf, S.A. Examining corporate reputation judgments with generalizability theory. J. Appl. Psychol. 2009, 94, 782. [Google Scholar] [CrossRef]
- Andersen, S.A.W.; Nayahangan, L.J.; Park, Y.S.; Konge, L. Use of generalizability theory for exploring reliability of and sources of variance in assessment of technical skills: A systematic review and meta-analysis. Acad. Med. 2021, 96, 1609–1619. [Google Scholar] [CrossRef]
- Lagha, R.A.R.; Boscardin, C.K.; May, W.; Fung, C.C. A comparison of two standard-setting approaches in high-stakes clinical performance assessment using generalizability theory. Acad. Med. 2012, 87, 1077–1082. [Google Scholar] [CrossRef] [PubMed]
- Spring, A.M.; Pittman, D.J.; Aghakhani, Y.; Jirsch, J.; Pillay, N.; Bello-Espinosa, L.E.; Josephson, C.; Federico, P. Generalizability of high frequency oscillation evaluations in the ripple band. Front. Neurol. 2018, 9, 510. [Google Scholar] [CrossRef]
- Kreiter, C.; Zaidi, N.B. Generalizability theory’s role in validity research: Innovative applications in health science education. Health Prof. Educ. 2020, 6, 282–290. [Google Scholar] [CrossRef]
- Kreiter, C.D.; Wilson, A.B.; Humbert, A.J.; Wade, P.A. Examining rater and occasion influences in observational assessments obtained from within the clinical environment. Med. Educ. Online 2016, 21, 29279. [Google Scholar] [CrossRef] [PubMed]
- Medvedev, O.; Truong, Q.C.; Merkin, A.; Borotkanics, R.; Krishnamurthi, R.; Feigin, V. Cross-cultural validation of the stroke riskometer using generalizability theory. Sci. Rep. 2021, 11, 19064. [Google Scholar] [CrossRef]
- Preuss, R.A. Using generalizability theory to develop clinical assessment protocols. Phys. Ther. 2013, 93, 562–569. [Google Scholar] [CrossRef]
- O’Brien, J.; Thompson, M.S.; Hagler, D. Using generalizability theory to inform optimal design for a nursing performance assessment. Eval. Health Prof. 2019, 42, 297–327. [Google Scholar] [CrossRef] [PubMed]
- Baldwin, S.A.; Larson, M.J.; Clayson, P.E. The dependability of electrophysiological measurements of performance monitoring in a clinical sample: A generalizability and decision analysis of the ERN and Pe. Psychophysiology 2015, 52, 790–800. [Google Scholar] [CrossRef] [PubMed]
- Carbine, K.A.; Clayson, P.E.; Baldwin, S.A.; LeCheminant, J.; Larson, M.J. Using generalizability theory and the ERP reliability analysis (ERA) toolbox for assessing test- retest reliability of ERP scores Part 2: Application to food- based tasks and stimuli. Int. J. Psychophysiol. 2021, 166, 188–198. [Google Scholar] [CrossRef]
- Clayson, P.E.; Carbine, K.A.; Baldwin, S.A.; Olsen, J.A.; Larson, M.J. Using generalizability theory and the ERP reliability analysis (ERA) toolbox for assessing test- retest reliability of ERP scores Part 1: Algorithms, framework, and implementation. Int. J. Psychophysiol. 2021, 166, 174–187. [Google Scholar] [CrossRef]
- Lafave, M.R.; Butterwick, D.J. A generalizability theory study of athletic taping using the Technical Skill Assessment Instrument. J. Athl. Training 2014, 49, 368–372. [Google Scholar] [CrossRef]
- Wickel, E.E.; Welk, G.J. Applying generalizability theory to estimate habitual activity levels. Med. Sci. Sports Exerc. 2010, 42, 1528–1534. [Google Scholar] [CrossRef] [PubMed]
- Coussens, A.H.; Rees, T.; Freeman, P. Applying generalizability theory to examine the antecedents of perceived coach support. J. Sport Exerc. Psychol. 2015, 37, 51–62. [Google Scholar] [CrossRef]
- Jiang, Z.; Raymond, M.; Shi, D.; DiStefano, C. Using a linear mixed-effect model framework to estimate multivariate generalizability theory parameters in R. Behav. Res. Methods 2020, 52, 2383–2393. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Lee, H.; Hong, H. Applying multivariate generalizability theory to psychological assessments. Psychol. Methods 2023, 1–23. [Google Scholar] [CrossRef] [PubMed]
- Ark, T.K. Ordinal Generalizability Theory Using an Underlying Latent Variable Framework. Ph.D. Thesis, University of British Columbia, Vancouver, BC, Canada, 2015. Available online: https://open.library.ubc.ca/soa/cIRcle/collections/ubctheses/24/items/1.0166304 (accessed on 23 December 2023).
- Marcoulides, G.A. Estimating variance components in generalizability theory: The covariance structure analysis approach. Struct. Equ. Modeling 1996, 3, 290–299. [Google Scholar] [CrossRef]
- Morris, C.A. Optimal Methods for Disattenuating Correlation Coefficients under Realistic Measurement Conditions with Single-Form, Self-Report Instruments (Publication No. 27668419). Ph.D. Thesis, University of Iowa, Iowa City, IA, USA; p. 2020.
- Raykov, T.; Marcoulides, G.A. Estimation of generalizability coefficients via a structural equation modeling approach to scale reliability evaluation. Int. J. Test. 2006, 6, 81–95. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Morris, C.A.; Kilinc, M. Applications of generalizability theory and their relations to classical test theory and structural equation modeling. Psychol. Methods 2018, 23, 1–26. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Morris, C.A.; Kilinc, M. Practical applications of generalizability theory for designing, evaluating, and improving psychological assessments. J. Pers. Assess. 2018, 100, 53–67. [Google Scholar] [CrossRef]
- Jorgensen, T.D. How to estimate absolute-error components in structural equation models of generalizability theory. Psych 2021, 3, 113–133. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Morris, C.A.; Kilinc, M. Using generalizability theory with continuous latent response variables. Psychol. Methods 2019, 24, 153–178. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Hong, H.; Lee, H. Benefits of doing generalizability theory analyses within structural equation modeling frameworks: Illustrations using the Rosenberg Self-Esteem Scale [Teacher’s corner]. Struct. Equ. Model. 2024, 31, 165–181. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Lee, H.; Chen, T. Estimating Reliability, Measurement Error from Multiple Sources, and Subscale Added Value within Multivariate Structural Equation Model Designs. 2024; manuscript submitted for publication. [Google Scholar]
- Vispoel, W.P.; Xu, G.; Kilinc, M. Expanding G-theory models to incorporate congeneric relationships: Illustrations using the Big Five Inventory. J. Personal. Assess. 2021, 104, 429–442. [Google Scholar] [CrossRef] [PubMed]
- Vispoel, W.P.; Xu, G.; Schneider, W.S. Interrelationships between latent state-trait theory and generalizability theory within a structural equation modeling framework. Psychol. Methods 2022, 27, 773–803. [Google Scholar] [CrossRef] [PubMed]
- Vispoel, W.P.; Lee, H.; Chen, T.; Hong, H. Analyzing and comparing univariate, multivariate, and bifactor generalizability theory designs for hierarchically structured personality traits. J. Pers. Assess. 2023, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Vispoel, W.P.; Lee, H.; Hong, H. Analyzing multivariate generalizability theory designs within structural equation modeling frameworks. Struct. Equ. Modeling 2023, 1–22. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Lee, H.; Chen, T.; Hong, H. Extending applications of generalizability theory-based bifactor model designs. Psych 2023, 5, 545–575. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Lee, H.; Xu, G.; Hong, H. Expanding bifactor models of psychological traits to account for multiple sources of measurement error. Psychol. Assess. 2022, 34, 1093–1111. [Google Scholar] [CrossRef]
- Vispoel, W.P.; Lee, H.; Xu, G.; Hong, H. Integrating bifactor models into a generalizability theory-based structural equation modeling framework. J. Exp. Educ. 2023, 91, 718–738. [Google Scholar] [CrossRef]
- Jorgensen, T.D.; Pornprasertmanit, S.; Schoemann, A.M.; Rosseel, Y.; Miller, P.; Quick, C.; Garnier-Villarreal, M.; Selig, J.; Boulton, A.; Preacher, K. Package ‘Semtools’. 2022. Available online: https://cran.r-project.org/web/packages/semTools/semTools.pdf (accessed on 23 December 2023).
- Preacher, K.J.; Selig, J.P. Advantages of Monte Carlo confidence intervals for indirect effects. Commun. Methods Meas. 2012, 6, 77–98. [Google Scholar] [CrossRef]
- Crick, J.E.; Brennan, R.L. Manual for GENOVA: A Generalized Analysis of Variance System; American College Testing Technical Bulletin 43; ACT, Inc.: Iowa City, IA, USA, 1983. [Google Scholar]
- Moore, C.T. gtheory: Apply Generalizability Theory with R. R Package Version 1.2. 2016. Available online: https://CRAN.R-project.org/package=gtheory (accessed on 23 December 2023).
- Huebner, A.; Lucht, M. Generalizability Theory in R. Pract. Assess. Res. Eval. 2019, 24, 1–12. [Google Scholar]
- Rosseel, Y. lavaan: An R package for structural equation modeling. J. Stat. Softw. 2012, 48, 1–36. [Google Scholar] [CrossRef]
- Rosseel, Y.; Jorgensen, T.D.; Rockwood, N. Package ‘lavaan’. R Package Version (0.6-15). 2023. Available online: https://cran.r-project.org/web/packages/lavaan/lavaan.pdf (accessed on 23 December 2023).
- Vispoel, W.P. Measuring and understanding self-perceptions of musical ability. In International Advances in Self Research; Marsh, H.W., Craven, R.G., McInerney, D.M., Eds.; Information Age: Greenwich, CT, USA, 2003; Volume 1, pp. 151–180. [Google Scholar]
- Vispoel, W.P. Integrating self-perceptions of music skill into contemporary models of self-concept. Vis. Res. Music. Educ. 2021, 16, 33. [Google Scholar]
- Vispoel, W.P.; Lee, H. Understanding the Structure of Music Self-Concept from Multiple Analytic Perspectives. In Proceedings of the Annual Meeting of the American Psychological Association, Washington, DC, USA., 5 August 2023. [Google Scholar]
- Brennan, R.L.; Kane, M.T. An index of dependability for mastery tests. J. Educ. Meas. 1977, 14, 277–289. [Google Scholar] [CrossRef]
- Kane, M.T.; Brennan, R.L. Agreement coefficients as indices of dependability for domain-referenced tests. Appl. Psych. Meas. 1980, 4, 105–126. [Google Scholar] [CrossRef]
- Brennan, R.L. Examining the dependability of scores. In R. A. Berk A Guide to Criterion-Referenced Test Construction; John Hopkins University Press: Baltimore, MD, USA, 1984; pp. 293–332. [Google Scholar]
- Vispoel, W.P.; Hong, H.; Lee, H.; Jorgensen, T.R. Analyzing complete generalizability theory designs using structural equation models. Appl. Meas. Educ. 2023, 36, 372–393. [Google Scholar] [CrossRef]
- Little, T.D.; Siegers, D.W.; Card, N.A. A non-arbitrary method or identifying and scaling latent variables in SEM and MACS models. Struct. Equ. Model. 2006, 13, 59–72. [Google Scholar] [CrossRef]
- Bates, D.; Maechler, M.; Bolker, B. Package ‘lme4’. R Package Version (1.1-32). 2023. Available online: https://cran.r-project.org/web/packages/lme4/lme4.pdf (accessed on 23 December 2023).
- Marcoulides, G.A. An alternative method for estimating variance components in generalizability theory. Psychol. Rep. 1990, 66, 379–386. [Google Scholar] [CrossRef]
- Deng, L.; Chan, W. Testing the difference between reliability coefficients alpha and omega. Educ. Psychol. Meas. 2017, 77, 185–203. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Design/VC | Method | |
|---|---|---|
| Indicator Mean | Jorgensen | |
| pi design | ||
where = the number of items, = intercept of item, and . | where = the number of items, = intercept of item, and . | |
| pio design | ||
where , | where = item factor mean, = intercept of the item on the occasion, for each item, = the number of occasions, and | |
where | where = occasion factor mean, for each occasion, and . | |
| . | ||
| pios design | ||
where ,= intercept of the item on the occasion for the skill, and = the number of skills. | where item factor mean, = intercept of the item on the occasion and the skill, for each item, = the number of skills, and . | |
where . | where for each occasion, and . | |
where . | where = skill factor mean, for each skill, and . | |
where . | where = item occasion interaction factor mean, for each item and occasion, | |
where . | where = item skill interaction factor mean, for each item and skill, and . | |
where . | where = occasion and skill interaction factor mean, for each occasion and skill, and | |
| Design/Index | Formula |
|---|---|
| pi design | . |
| G coefficient | |
| Global D coefficient | . |
| Cut-score-specific D coefficient | |
| pio design | . |
| G coefficient | |
| Global D coefficient | . |
| Cut-score-specific D coefficient | where |
| pios design | . |
| G coefficient | |
| Global D coefficient | . |
| Cut-score-specific D coefficient | where |
| Metric/Subscale | Index/Occasion | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Time 1 | Time 2 | ||||||||
| Mean Scale (Item) | SD Scale (Item) | ω | Mean Scale (Item) | SD Scale (Item) | ω | Test-Retest | |||
| 2-point metric | |||||||||
| Composing | 16.64 (1.39) | 4.53 (0.38) | 0.942 | 0.942 | 16.64 (1.39) | 4.75 (0.40) | 0.954 | 0.953 | 0.894 |
| Listening | 18.34 (1.53) | 4.98 (0.42) | 0.960 | 0.960 | 18.34 (1.53) | 4.97 (0.41) | 0.960 | 0.960 | 0.885 |
| Reading Music | 17.63 (1.47) | 5.09 (0.42) | 0.966 | 0.966 | 17.83 (1.49) | 5.09 (0.42) | 0.965 | 0.965 | 0.937 |
| Instrument Playing | 17.76 (1.48) | 4.98 (0.41) | 0.960 | 0.960 | 17.91 (1.49) | 5.01 (0.42) | 0.962 | 0.962 | 0.930 |
| Mean | 17.59 (1.47) | 4.90 (0.41) | 0.957 | 0.957 | 17.68 (1.47) | 4.96 (0.41) | 0.960 | 0.960 | 0.912 |
| 4-point metric | |||||||||
| Composing | 25.90 (2.16) | 10.71 (0.89) | 0.959 | 0.959 | 25.90 (2.16) | 11.02 (0.92) | 0.971 | 0.971 | 0.911 |
| Listening | 29.93 (2.49) | 12.27 (1.02) | 0.974 | 0.974 | 29.93 (2.49) | 11.97 (1.00) | 0.975 | 0.975 | 0.920 |
| Reading Music | 28.27 (2.36) | 12.78 (1.07) | 0.978 | 0.978 | 28.69 (2.39) | 12.49 (1.04) | 0.980 | 0.980 | 0.950 |
| Instrument Playing | 28.73 (2.39) | 12.52 (1.04) | 0.977 | 0.977 | 29.02 (2.42) | 12.42 (1.04) | 0.978 | 0.978 | 0.946 |
| Mean | 28.21 (2.35) | 12.07 (1.01) | 0.972 | 0.972 | 28.39 (2.37) | 11.98 (1.00) | 0.976 | 0.976 | 0.932 |
| 8-point metric | |||||||||
| Composing | 45.45 (3.79) | 22.38 (1.86) | 0.965 | 0.965 | 45.45 (3.79) | 22.91 (1.91) | 0.975 | 0.975 | 0.919 |
| Listening | 53.43 (4.45) | 25.36 (2.11) | 0.977 | 0.978 | 53.43 (4.45) | 24.76 (2.06) | 0.979 | 0.979 | 0.928 |
| Reading Music | 50.06 (4.17) | 26.83 (2.24) | 0.981 | 0.981 | 50.83 (4.24) | 26.07 (2.17) | 0.983 | 0.983 | 0.950 |
| Instrument Playing | 51.09 (4.26) | 26.40 (2.20) | 0.980 | 0.980 | 51.68 (4.31) | 25.91 (2.16) | 0.982 | 0.982 | 0.948 |
| Mean | 50.01 (4.17) | 25.24 (2.10) | 0.976 | 0.976 | 50.35 (4.20) | 24.91 (2.08) | 0.980 | 0.980 | 0.936 |
| Scale Metric/Index | Procedure | |||
|---|---|---|---|---|
| GENOVA | gtheory Package in R | Jorgensen | Indicator Mean | |
| 2-point metric | ||||
| G coefficient | 0.942 | 0.942 | 0.942 (0.924, 0.959) | 0.942 (0.924, 0.959) |
| Global D coefficient | 0.940 | 0.940 | 0.940 (0.921, 0.955) | 0.940 (0.921, 0.955) |
| 0.134 | 0.134 | 0.134 (0.124, 0.145) | 0.134 (0.124, 0.145) | |
| 0.099 | 0.099 | 0.099 (0.072, 0.127) | 0.099 (0.072, 0.127) | |
| 0.004 | 0.004 | 0.004 (0.003, 0.010) | 0.004 (0.003, 0.010) | |
| 4-point metric | ||||
| G coefficient | 0.959 | 0.959 | 0.959 (0.956, 0.962) | 0.959 (0.956, 0.962) |
| Global D coefficient | 0.957 | 0.957 | 0.957 (0.954, 0.960) | 0.957 (0.954, 0.960) |
| 0.765 | 0.765 | 0.765 (0.754, 0.775) | 0.765 (0.754, 0.775) | |
| 0.389 | 0.389 | 0.389 (0.362, 0.416) | 0.389 (0.362, 0.416) | |
| 0.023 | 0.023 | 0.024 * (0.018, 0.035) | 0.024 * (0.018, 0.035) | |
| 8-point metric | ||||
| G coefficient | 0.965 | 0.965 | 0.965 (0.964, 0.965) | 0.965 (0.964, 0.965) |
| Global D coefficient | 0.963 | 0.963 | 0.962 * (0.962, 0.963) | 0.962 * (0.962, 0.963) |
| 3.355 | 3.355 | 3.355 (3.344, 3.366) | 3.355 (3.344, 3.366) | |
| 1.471 | 1.470 * | 1.470 * (1.442, 1.497) | 1.470 * (1.442, 1.497) | |
| 0.096 | 0.096 | 0.099 * (0.085, 0.118) | 0.099 * (0.085, 0.118) | |
| Scale Point/Index | Procedure | |
|---|---|---|
| Jorgensen | Indicator Mean | |
| 2-point metric | ||
| G coefficient | 0.986 (0.982, 0.989) | 0.986 (0.982, 0.989) |
| Global D coefficient | 0.983 (0.979, 0.986) | 0.983 (0.979, 0.986) |
| 5.899 (4.612, 7.185) | 5.899 (4.612, 7.184) | |
| 1.000 (1.000, 1.000) | 1.000 (1.000, 1.000) | |
| 0.199 (0.138, 0.290) | 0.199 (0.138, 0.290) | |
| 4-point metric | ||
| G coefficient | 0.980 (0.976, 0.982) | 0.980 (0.976, 0.982) |
| Global D coefficient | 0.977 (0.973, 0.980) | 0.977 (0.973, 0.980) |
| 4.032 (3.388, 4.675) | 4.032 (3.388, 4.674) | |
| 1.000 (1.000, 1.000) | 1.000 (1.000, 1.000) | |
| 0.123 (0.093, 0.166) | 0.123 (0.093, 0.166) | |
| 8-point metric | ||
| G coefficient | 0.979 (0.976, 0.982) | 0.979 (0.976, 0.982) |
| Global D coefficient | 0.977 (0.973, 0.980) | 0.977 (0.973, 0.980) |
| 3.966 (3.398, 4.534) | 3.966 (3.398, 4.534) | |
| 1.000 (1.000, 1.000) | 1.000 (1.000, 1.000) | |
| 0.109 (0.083, 0.144) | 0.109 (0.083, 0.144) | |
| Scale Point/Index | Procedure | |||
|---|---|---|---|---|
| GENOVA | gtheory Package in R | Jorgensen | Indicator Mean | |
| 2-point | ||||
| G coefficient | 0.884 | 0.884 | 0.884 (0.821, 0.951) | 0.884 (0.821, 0.951) |
| Global D coefficient | 0.882 | 0.882 | 0.882 (0.816, 0.946) | 0.882 (0.817, 0.947) |
| 0.132 | 0.132 | 0.132 (0.125, 0.140) | 0.132 (0.125, 0.140) | |
| 0.016 | 0.016 | 0.016 (−0.010, 0.043) | 0.016 (−0.010, 0.043) | |
| 0.010 | 0.010 | 0.010 (−0.001, 0.020) | 0.010 (−0.001, 0.020) | |
| 0.077 | 0.077 | 0.077 (0.044, 0.109) | 0.077 (0.044, 0.109) | |
| 0.004 | 0.004 | 0.004 (0.003, 0.007) | 0.004 (0.003, 0.007) | |
| 0.000 | 0.000 | 0.000 (0.000, 0.001) | 0.000 (0.000, 0.001) | |
| 0.000 | 0.000 | 0.000 (0.001, 0.004) | 0.000 (0.000, 0.002) | |
| 4-point | ||||
| G coefficient | 0.905 | 0.905 | 0.905 (0.893, 0.917) | 0.905 (0.893, 0.917) |
| Global D coefficient | 0.902 | 0.902 | 0.902 (0.890, 0.914) | 0.902 (0.890, 0.914) |
| 0.742 | 0.742 | 0.742 (0.734, 0.749) | 0.742 (0.734, 0.749) | |
| 0.058 | 0.058 | 0.058 (0.032, 0.084) | 0.058 (0.032, 0.084) | |
| 0.050 | 0.050 | 0.050 (0.039, 0.061) | 0.050 (0.039, 0.061) | |
| 0.281 | 0.281 | 0.281 (0.249, 0.314) | 0.281 (0.249, 0.314) | |
| 0.021 | 0.021 | 0.022 * (0.017, 0.028) | 0.022 * (0.017, 0.028) | |
| 0.000 | 0.000 | 0.001 * (0.000, 0.002) | 0.001 * (0.000, 0.002) | |
| 0.000 | 0.000 | 0.001 * (0.001, 0.005) | 0.000 (0.000, 0.003) | |
| 8-point | ||||
| G coefficient | 0.913 | 0.913 | 0.913 (0.910, 0.916) | 0.913 (0.910, 0.916) |
| Global D coefficient | 0.911 | 0.911 | 0.910 * (0.908, 0.913) | 0.911 (0.908, 0.913) |
| 3.251 | 3.251 | 3.251 (3.243, 3.258) | 3.251 (3.243, 3.258) | |
| 0.237 | 0.237 | 0.237 (0.210, 0.263) | 0.237 (0.210, 0.263) | |
| 0.204 | 0.204 | 0.204 (0.193, 0.214) | 0.204 (0.193, 0.214) | |
| 1.037 | 1.037 | 1.037 (1.004, 1.070) | 1.037 (1.005, 1.070) | |
| 0.087 | 0.087 | 0.089 * (0.079, 0.102) | 0.089 * (0.079, 0.102) | |
| 0.001 | 0.001 | 0.002 * (0.000, 0.005) | 0.002 * (0.000, 0.005) | |
| 0.002 | 0.002 | 0.003 * (0.002, 0.009) | 0.002 (0.001, 0.005) | |
| Scale Point/Index | Procedure | |
|---|---|---|
| Jorgensen | Indicator Mean | |
| 2-point | ||
| G coefficient | 0.920 (0.896, 0.937) | 0.920 (0.896, 0.937) |
| Global D coefficient | 0.917 (0.893, 0.935) | 0.917 (0.893, 0.935) |
| 11.570 (8.294, 14.839) | 11.570 (8.297, 14.842) | |
| 0.717 (0.429, 1.003) | 0.717 (0.431, 1.003) | |
| 0.864 (0.628, 1.101) | 0.864 (0.628, 1.101) | |
| 1.000 (1.000, 1.000) | 1.000 (1.000, 1.000) | |
| 0.354 (0.241, 0.507) | 0.354 (0.242, 0.507) | |
| 0.005 (0.000, 0.032) | 0.005 (0.000, 0.032) | |
| 0.013 * (0.010, 0.048) | 0.009 (0.007, 0.030) | |
| 4-point | ||
| G coefficient | 0.915 (0.900, 0.927) | 0.915 (0.900, 0.927) |
| Global D coefficient | 0.913 (0.896, 0.925) | 0.913 (0.897, 0.925) |
| 6.238 (5.170, 7.305) | 6.238 (5.171, 7.307) | |
| 0.342 (0.281, 0.402) | 0.342 (0.281, 0.403) | |
| 0.466 (0.402, 0.530) | 0.466 (0.402, 0.531) | |
| 1.000 (1.000, 1.000) | 1.000 (1.000, 1.000) | |
| 0.182 (0.143, 0.233) | 0.182 (0.143, 0.233) | |
| 0.004 (0.000, 0.017) | 0.004 (0.000, 0.017) | |
| 0.007 * (0.004, 0.019) | 0.004 (0.002, 0.010) | |
| 8-point | ||
| G coefficient | 0.899 (0.884, 0.911) | 0.899 (0.884, 0.911) |
| Global D coefficient | 0.897 (0.881, 0.909) | 0.897 (0.881, 0.909) |
| 6.325 (5.340, 7.308) | 6.325 (5.336, 7.310) | |
| 0.354 (0.311, 0.397) | 0.354 (0.311, 0.397) | |
| 0.597 (0.543, 0.650) | 0.597 (0.543, 0.650) | |
| 1.000 (1.000, 1.000) | 1.000 (1.000, 1.000) | |
| 0.167 (0.132, 0.211) | 0.167 (0.132, 0.211) | |
| 0.004 (0.000, 0.016) | 0.004 (0.000, 0.016) | |
| 0.006 * (0.004, 0.016) | 0.003 (0.002, 0.009) | |
| Scale Point/Index | Procedure | |||
|---|---|---|---|---|
| GENOVA | gtheory Package in R | Jorgensen | Indicator Mean | |
| 2-point | ||||
| G coefficient | 0.860 | 0.860 | 0.860 (0.839, 0.881) | 0.860 (0.839, 0.881) |
| Global D coefficient | 0.852 | 0.852 | 0.856 * (0.835, 0.876) | 0.852 (0.830, 0.871) |
| 0.111 | 0.111 | 0.111 (0.109, 0.113) | 0.111 (0.109, 0.113) | |
| 0.007 | 0.007 | 0.007 (−0.001, 0.014) | 0.007 (−0.001, 0.014) | |
| 0.004 | 0.004 | 0.004 (0.001, 0.007) | 0.004 (0.001, 0.007) | |
| 0.042 | 0.042 | 0.042 (0.038, 0.046) | 0.042 (0.038, 0.046) | |
| 0.006 | 0.006 | 0.006 (−0.005, 0.016) | 0.006 (−0.005, 0.016) | |
| 0.008 | 0.008 | 0.007 * (−0.008, 0.023) | 0.007 * (−0.008, 0.023) | |
| 0.005 | 0.005 | 0.005 (−0.001, 0.012) | 0.005 (−0.001, 0.012) | |
| 0.063 | 0.063 | 0.063 (0.043, 0.082) | 0.063 (0.043, 0.082) | |
| 0.002 | 0.002 | 0.001 * (0.000, 0.001) | 0.002 (0.001, 0.003) | |
| 0.000 | 0.000 | 0.000 (0.000, 0.000) | 0.000 (0.000, 0.001) | |
| 0.004 | 0.004 | 0.002 * (0.001, 0.002) | 0.004 (0.003, 0.005) | |
| 0.000 | 0.000 | 0.000 (0.000, 0.001) | 0.000 (0.000, 0.001) | |
| 0.000 | 0.000 | 0.000 (0.001, 0.002) | 0.000 (0.001, 0.002) | |
| 0.000 | 0.000 | 0.000 (0.000, 0.001) | 0.000 (0.000, 0.000) | |
| 0.000 | 0.000 | 0.000 (0.000, 0.001) | 0.000 (0.000, 0.001) | |
| 4-point | ||||
| G coefficient | 0.884 | 0.884 | 0.884 (0.881, 0.887) | 0.884 (0.880, 0.887) |
| Global D coefficient | 0.876 | 0.876 | 0.880 * (0.876, 0.883) | 0.876 (0.872, 0.879) |
| 0.717 | 0.717 | 0.717 (0.715, 0.719) | 0.717 (0.715, 0.719) | |
| 0.027 | 0.027 | 0.027 (0.019, 0.034) | 0.027 (0.020, 0.035) | |
| 0.025 | 0.025 | 0.025 (0.022, 0.028) | 0.025 (0.022, 0.028) | |
| 0.219 | 0.219 | 0.219 (0.214, 0.223) | 0.219 (0.214, 0.223) | |
| 0.019 | 0.019 | 0.019 (0.008, 0.030) | 0.019 (0.010, 0.031) | |
| 0.026 | 0.026 | 0.026 (0.011, 0.041) | 0.026 (0.013, 0.043) | |
| 0.021 | 0.021 | 0.021 (0.015, 0.027) | 0.021 (0.015, 0.028) | |
| 0.237 | 0.237 | 0.237 (0.218, 0.257) | 0.237 (0.218, 0.257) | |
| 0.016 | 0.016 | 0.005 * (0.005, 0.006) | 0.017 * (0.015, 0.019) | |
| 0.001 | 0.001 | 0.000 * (0.000, 0.001) | 0.001 (0.000, 0.002) | |
| 0.020 | 0.020 | 0.008 * (0.007, 0.010) | 0.021 * (0.018, 0.024) | |
| 0.000 | 0.000 | 0.002 * (0.001, 0.002) | 0.000 (0.000, 0.001) | |
| 0.002 | 0.002 | 0.002 (0.002, 0.003) | 0.002 (0.002, 0.003) | |
| 0.000 | 0.000 | 0.002 * (0.002, 0.002) | 0.000 (0.000, 0.001) | |
| 0.000 | 0.000 | 0.000 (0.001, 0.001) | 0.001 * (0.001, 0.002) | |
| 8-point | ||||
| G coefficient | 0.889 | 0.889 | 0.889 (0.888, 0.890) | 0.889 (0.888, 0.890) |
| Global D coefficient | 0.882 | 0.882 | 0.884 * (0.883, 0.885) | 0.882 (0.881, 0.883) |
| 3.183 | 3.183 | 3.183 (3.181, 3.185) | 3.183 (3.181, 3.185) | |
| 0.112 | 0.112 | 0.112 (0.105, 0.120) | 0.112 (0.105, 0.120) | |
| 0.114 | 0.114 | 0.114 (0.110, 0.117) | 0.114 (0.110, 0.117) | |
| 0.908 | 0.908 | 0.908 (0.904, 0.912) | 0.908 (0.904, 0.912) | |
| 0.075 | 0.075 | 0.075 (0.064, 0.085) | 0.075 (0.064, 0.085) | |
| 0.099 | 0.099 | 0.099 (0.084, 0.114) | 0.099 (0.084, 0.114) | |
| 0.083 | 0.083 | 0.083 (0.077, 0.089) | 0.083 (0.077, 0.089) | |
| 0.858 | 0.858 | 0.858 (0.839, 0.877) | 0.858 (0.839, 0.877) | |
| 0.065 | 0.065 | 0.022 * (0.021, 0.024) | 0.068 * (0.064, 0.073) | |
| 0.002 | 0.002 | 0.003 * (0.002, 0.004) | 0.003 * (0.002, 0.004) | |
| 0.081 | 0.081 | 0.066 * (0.063, 0.070) | 0.083 * (0.078, 0.090) | |
| 0.001 | 0.001 | 0.006 * (0.006, 0.007) | 0.001 (0.001, 0.002) | |
| 0.008 | 0.008 | 0.008 (0.008, 0.011) | 0.007 * (0.006, 0.009) | |
| 0.000 | 0.000 | 0.001 * (0.001, 0.001) | 0.000 (0.000, 0.001) | |
| 0.001 | 0.001 | 0.001 (0.001, 0.002) | 0.001 (0.001, 0.002) | |
| Scale Point/ Index | Procedure | |
|---|---|---|
| Jorgensen | Indicator Mean | |
| 2-point | ||
| G coefficient | 0.899 (0.877, 0.918) | 0.899 (0.877, 0.918) |
| Global D coefficient | 0.895 * (0.872, 0.913) | 0.890 (0.866, 0.909) |
| 23.544 * (15.012, 32.092) | 23.541 (15.002, 32.083) | |
| 1.098 (0.591, 1.613) | 1.098 (0.588, 1.610) | |
| 0.843 * (0.482, 1.208) | 0.844 (0.481, 1.207) | |
| 5.875 (3.698, 8.057) | 5.875 (3.713, 8.050) | |
| 0.797 (0.294, 1.302) | 0.797 (0.296, 1.298) | |
| 0.200 * (−0.057, 0.456) | 0.199 (−0.057, 0.457) | |
| 0.564 (0.308, 0.820) | 0.564 (0.308, 0.819) | |
| 1.000 (1.000, 1.000) | 1.000 (1.000, 1.000) | |
| 0.142 * (0.088, 0.214) | 0.435 (0.270, 0.655) | |
| 0.016 * (0.002, 0.045) | 0.029 (0.003, 0.080) | |
| 0.340 * (0.198, 0.535) | 0.852 (0.497, 1.339) | |
| 0.044 * (0.032, 0.070) | 0.010 (0.006, 0.025) | |
| 0.090 * (0.066, 0.146) | 0.079 (0.058, 0.133) | |
| 0.076 * (0.046, 0.120) | 0.002 (0.000, 0.012) | |
| 0.011 * (0.012, 0.031) | 0.012 (0.013, 0.032) | |
| 4-point | ||
| G coefficient | 0.900 (0.883, 0.914) | 0.900 (0.883, 0.914) |
| Global D coefficient | 0.895 * (0.877, 0.909) | 0.892 (0.873, 0.907) |
| 8.783 (7.232, 10.336) | 8.783 (7.236, 10.333) | |
| 0.312 (0.237, 0.387) | 0.312 (0.237, 0.387) | |
| 0.370 (0.288, 0.453) | 0.370 (0.288, 0.453) | |
| 2.059 (1.765, 2.355) | 2.059 (1.765, 2.355) | |
| 0.160 (0.103, 0.218) | 0.160 (0.104, 0.217) | |
| 0.091 (0.046, 0.136) | 0.091 (0.046, 0.136) | |
| 0.118 (0.080, 0.156) | 0.118 (0.080, 0.156) | |
| 1.000 (1.000, 1.000) | 1.000 (1.000, 1.000) | |
| 0.068 * (0.061, 0.078) | 0.199 (0.156, 0.252) | |
| 0.001 * (0.000, 0.006) | 0.008 (0.001, 0.022) | |
| 0.113 * (0.084, 0.151) | 0.255 (0.178, 0.356) | |
| 0.083 * (0.076, 0.092) | 0.003 (0.002, 0.006) | |
| 0.028 * (0.024, 0.038) | 0.019 (0.015, 0.028) | |
| 0.045 * (0.035, 0.057) | 0.001 (0.000, 0.003) | |
| 0.002 * (0.003, 0.007) | 0.003 (0.003, 0.007) | |
| 8-point | ||
| G coefficient | 0.891 (0.875, 0.904) | 0.891 (0.875, 0.904) |
| Global D coefficient | 0.773 * (0.743, 0.796) | 0.884 (0.867, 0.898) |
| 10.150 * (8.463, 11.839) | 10.149 (8.462, 11.840) | |
| 0.354 (0.286, 0.422) | 0.354 (0.286, 0.422) | |
| 0.460 (0.373, 0.547) | 0.460 (0.374, 0.546) | |
| 2.424 (2.139, 2.710) | 2.424 (2.140, 2.709) | |
| 0.193 (0.140, 0.245) | 0.193 (0.140, 0.245) | |
| 0.194 (0.150, 0.237) | 0.194 (0.150, 0.237) | |
| 0.407 * (0.368, 0.445) | 0.406 (0.368, 0.445) | |
| 1.000 (1.000, 1.000) | 1.000 (1.000, 1.000) | |
| 0.212 * (0.201, 0.225) | 0.207 (0.162, 0.260) | |
| 1.254 * (1.154, 1.360) | 0.008 (0.001, 0.023) | |
| 0.888 * (0.776, 1.010) | 0.258 (0.181, 0.361) | |
| 0.364 * (0.351, 0.378) | 0.003 (0.002, 0.006) | |
| 0.261 * (0.256, 0.271) | 0.022 (0.018, 0.031) | |
| 0.861 * (0.828, 0.898) | 0.001 (0.000, 0.003) | |
| 0.003 (0.003, 0.007) | 0.003 (0.003, 0.007) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, H.; Vispoel, W.P. A Robust Indicator Mean-Based Method for Estimating Generalizability Theory Absolute Error and Related Dependability Indices within Structural Equation Modeling Frameworks. Psych 2024, 6, 401-425. https://doi.org/10.3390/psych6010024
Lee H, Vispoel WP. A Robust Indicator Mean-Based Method for Estimating Generalizability Theory Absolute Error and Related Dependability Indices within Structural Equation Modeling Frameworks. Psych. 2024; 6(1):401-425. https://doi.org/10.3390/psych6010024
Chicago/Turabian StyleLee, Hyeryung, and Walter P. Vispoel. 2024. "A Robust Indicator Mean-Based Method for Estimating Generalizability Theory Absolute Error and Related Dependability Indices within Structural Equation Modeling Frameworks" Psych 6, no. 1: 401-425. https://doi.org/10.3390/psych6010024