
Functionality-Preserving Adversarial Machine Learning for Robust Classification in Cybersecurity and Intrusion Detection Domains: A Survey




Abstract
:1. Introduction
- The semantic information of the model is held across the model and not localised to specific neurons;
- Neural networks learn input–output mappings that are discontinuous (and discontiguous).
- We conduct a survey of the literature to identify the trends and characteristics of published works on adversarial learning in relation to cybersecurity, addressing both attack vectors and defensive strategies;
- We address the issue of functionality-preservation in adversarial learning in contrast to domains such as computer vision, whereby a malformed input must suitably fool a system process as well as a human user such that the original functionality is maintained despite some modification;
- We summarise this relatively-new research domain to address the future research challenges associated with adversarial machine learning across the cybersecurity domain.
2. Related Works
2.1. Secure and Trustworthy Systems
2.2. Adversarial ML in General
- The difficulty of building a generalizable method;
- The difficulty in controlling the size of perturbation (too small will not result in adversarial examples, and too large can easily be perceived);
- Difficulty in maintaining adversarial stability in real-world applications (some adversarial examples do not hold for transformations such as blurring).
- Construction of adversarial examples with high transferability (high confidence);
- Construction of adversarial examples without perturbing the target image; they suggested that perturbation size will affect the success rate and transferability of adversarial examples;
- Considering and modeling physical transformations (translation, rotation, brightness, and contrast).
2.3. Intrusion Detection
2.4. Cyber-Physical Systems
2.5. Contributions of This Survey
- Collect and collate current knowledge regarding robustness and functionality-preserving attacks in cybersecurity domains;
- Formulate key takeaways based on our presentation of the information, aiming to assist understanding of the field.
3. Background
3.1. Model Training
3.1.1. Resampling
- Oversampling: Random samples of minority classes are duplicated until the bias of majority classes is compensated;
- Undersampling: Random samples from the majority class are discarded until the bias of majority classes is compensated;
- Hybrid Sampling: Combines modest oversampling of minority classes and modest undersampling of majority classes aiming to give better model performance than applying either technique alone.
3.1.2. Loss Functions
3.1.3. Cross Validation
3.1.4. Bootstrapping
3.2. Robustness
3.3. Common Adversarial Example Algorithms
- Accuracy degradation (where the adversary wants to sabotage the effectiveness of the overall classifier accuracy);
- Target misclassification (where the adversary wants to misclassify a particular instance as another given class);
- Untargeted classification (where the adversary wants to misclassify a particular instance to any random class).
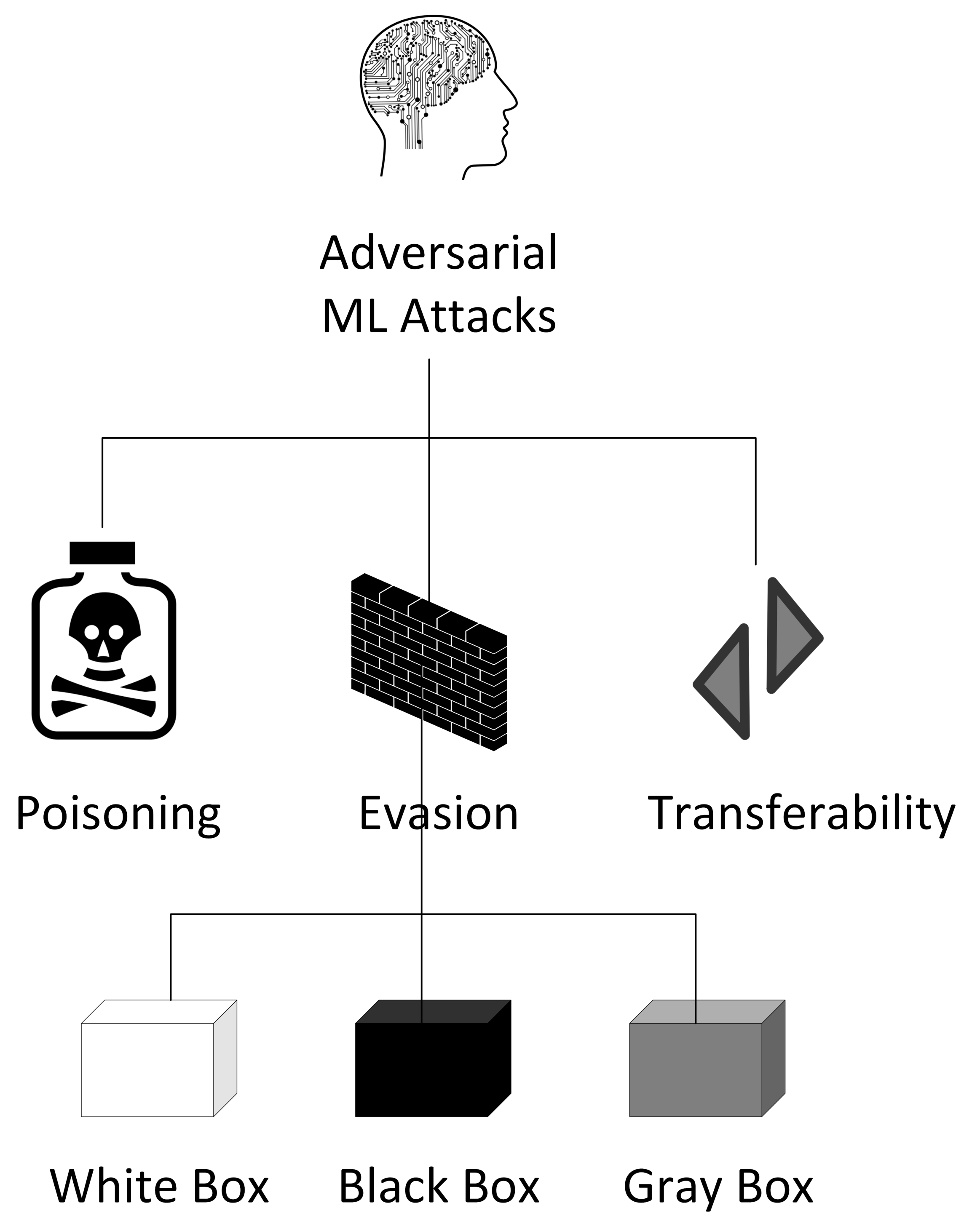
3.4. Threat Model—Adversary Capabilities
3.5. Threat Model—Adversary Goals
3.6. Threat Model—Common Attack Methods
3.6.1. Poisoning
3.6.2. Evasion
3.6.3. Transferability
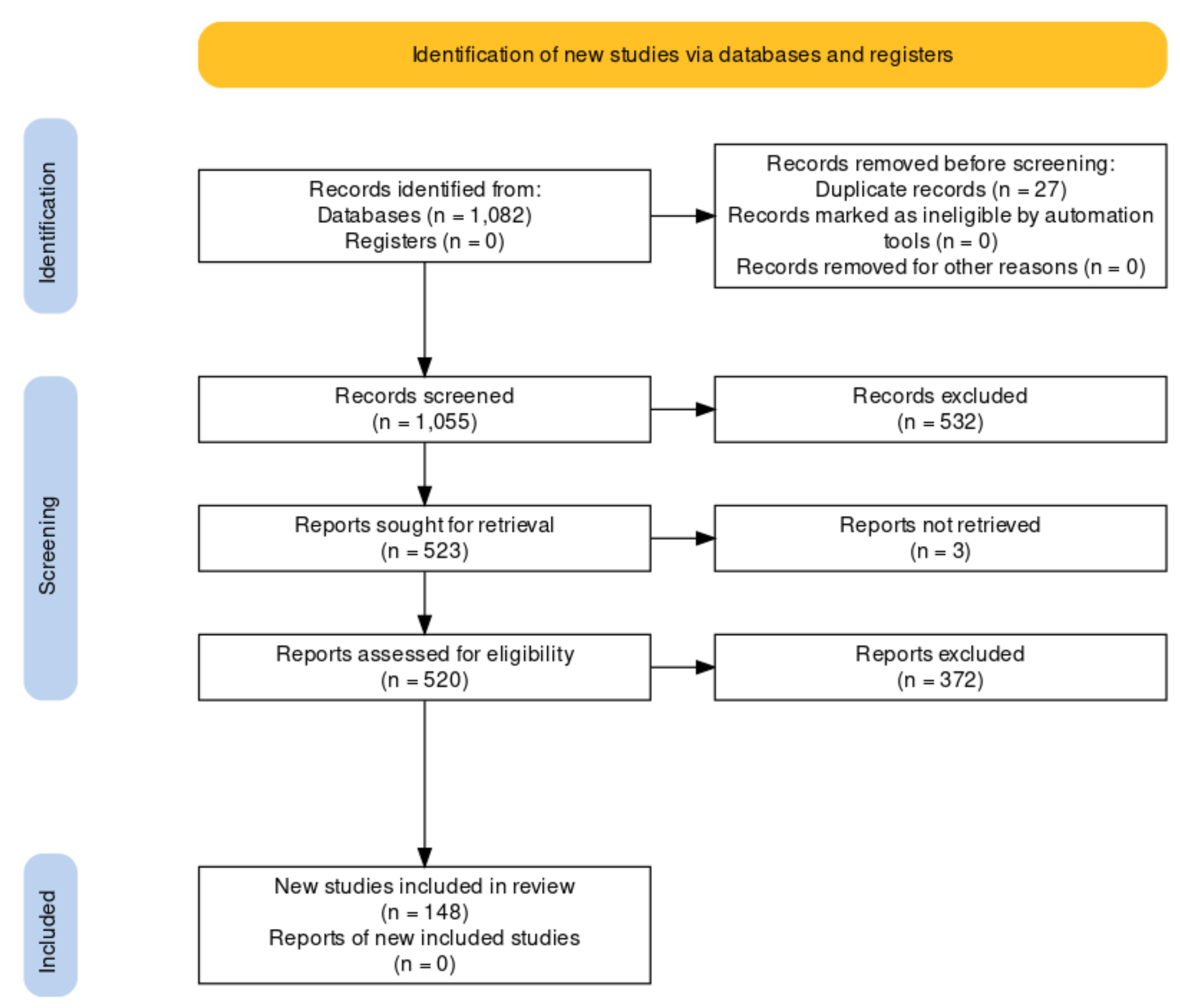
4. Methodology
5. Results
5.1. Classification Scheme
5.2. Adversarial Example Attacks
5.2.1. Adversarial Examples—Similarity Metrics
- Number of altered pixels, ;
- Euclidean distance (, root-mean-square);
- Maximum change to any of the co-ordinates, .
5.2.2. Adversarial Examples-Types of Attack
5.2.3. Adversarial Examples—Attack Objectives
5.2.4. Adversarial Examples in Traditional Domains
5.2.5. Adversarial Examples in Cyber-Security Domains
5.2.6. Adversarial Examples and Model Type
5.2.7. Adversarial Examples and Knowledge Requirement
5.2.8. Adversarial Example Constraints
5.3. Defenses against Adversarial Examples
5.3.1. Pre-Processing as a Defense against Adversarial Examples
5.3.2. Adversarial Training as a Defense against Adversarial Examples
5.3.3. Architectural Defenses against Adversarial Examples
5.3.4. Detecting Adversarial Examples
5.3.5. Defensive Testing
5.3.6. Multi-Classifier Systems
5.3.7. Game Theory
5.3.8. Adversarial Example Defenses in Cybersecurity Domains
6. Discussion and Conclusions
Future Directions and Research Challenges
Key Future Research Challenges
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Andresini, G.; Pendlebury, F.; Pierazzi, F.; Loglisci, C.; Appice, A.; Cavallaro, L. INSOMNIA: Towards Concept-Drift Robustness in Network Intrusion Detection. In Proceedings of the 14th ACM Workshop on Artificial Intelligence and Security (AISec), ACM, Virtual Event, Korea, 15 November 2021. [Google Scholar]
- Raghuraman, C.; Suresh, S.; Shivshankar, S.; Chapaneri, R. Static and dynamic malware analysis using machine learning. In First International Conference on Sustainable Technologies for Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2020; pp. 793–806. [Google Scholar]
- Berger, H.; Hajaj, C.; Dvir, A. Evasion Is Not Enough: A Case Study of Android Malware. In International Symposium on Cyber Security Cryptography and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 167–174. [Google Scholar]
- Hou, R.; Xiang, X.; Zhang, Q.; Liu, J.; Huang, T. Universal Adversarial Perturbations of Malware. In International Symposium on Cyberspace Safety and Security; Springer: Berlin/Heidelberg, Germany, 2020; pp. 9–19. [Google Scholar]
- Parshutin, S.; Kirshners, A.; Kornijenko, Y.; Zabiniako, V.; Gasparovica-Asite, M.; Rozkalns, A. Classification with LSTM Networks in User Behaviour Analytics with Unbalanced Environment. Autom. Control. Comput. Sci. 2021, 55, 85–91. [Google Scholar] [CrossRef]
- Le, D.C.; Zincir-Heywood, N. Exploring anomalous behaviour detection and classification for insider threat identification. Int. J. Netw. Manag. 2021, 31, e2109. [Google Scholar] [CrossRef]
- Biswal, S. Real-Time Intelligent Vishing Prediction and Awareness Model (RIVPAM). In Proceedings of the 2021 International Conference on Cyber Situational Awareness, Data Analytics and Assessment (CyberSA), Dublin, Ireland, 14–18 June 2021; pp. 1–2. [Google Scholar]
- Kumar, N.; Sonowal, S.; Nishant. Email Spam Detection Using Machine Learning Algorithms. In Proceedings of the 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 15–17 July 2020; pp. 108–113.
- Kiela, D.; Firooz, H.; Mohan, A.; Goswami, V.; Singh, A.; Ringshia, P.; Testuggine, D. The hateful memes challenge: Detecting hate speech in multimodal memes. arXiv 2020, arXiv:2005.04790. [Google Scholar]
- Bin Naeem, S.; Kamel Boulos, M.N. COVID-19 misinformation online and health literacy: A brief overview. Int. J. Environ. Res. Public Health 2021, 18, 8091. [Google Scholar] [CrossRef]
- Coan, T.; Boussalis, C.; Cook, J.; Nanko, M. Computer-assisted detection and classification of misinformation about climate change. SocArXiv 2021, 1–12. [Google Scholar]
- Khanam, Z.; Alwasel, B.; Sirafi, H.; Rashid, M. Fake News Detection Using Machine Learning Approaches. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Jeju Island, Korea, 12–14 March 2021; IOP Publishing: Jaipur, India, 2021; Volume 1099, p. 012040. [Google Scholar]
- Papernot, N.; McDaniel, P.; Sinha, A.; Wellman, M.P. Sok: Security and privacy in machine learning. In Proceedings of the2018 IEEE European Symposium on Security and Privacy (EuroS&P), London, UK, 24–26 April 2018; pp. 399–414. [Google Scholar]
- Dhar, S.; Guo, J.; Liu, J.; Tripathi, S.; Kurup, U.; Shah, M. On-device machine learning: An algorithms and learning theory perspective. arXiv 2019, arXiv:1911.00623. [Google Scholar] [CrossRef]
- Gu, X.; Easwaran, A. Towards Safe Machine Learning for CPS: Infer Uncertainty from Training Data. In Proceedings of the 10th ACM/IEEE International Conference on Cyber-Physical Systems, Association for Computing Machinery, New York, NY, USA, 16–18 April 2019; pp. 249–258. [Google Scholar] [CrossRef] [Green Version]
- Ghafouri, A.; Vorobeychik, Y.; Koutsoukos, X. Adversarial regression for detecting attacks in cyber-physical systems. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Wardle, S.G.; Taubert, J.; Teichmann, L.; Baker, C.I. Rapid and dynamic processing of face pareidolia in the human brain. Nat. Commun. 2020, 11, 1–14. [Google Scholar] [CrossRef]
- Summerfield, C.; Egner, T.; Mangels, J.; Hirsch, J. Mistaking a house for a face: Neural correlates of misperception in healthy humans. Cereb. Cortex 2006, 16, 500–508. [Google Scholar] [CrossRef]
- Huang, Y.; Verma, U.; Fralick, C.; Infantec-Lopez, G.; Kumar, B.; Woodward, C. Malware Evasion Attack and Defense. In Proceedings of the 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W), Portland, OR, USA, 24–27 June 2019; pp. 34–38. [Google Scholar] [CrossRef] [Green Version]
- Ayub, M.A.; Johnson, W.A.; Talbert, D.A.; Siraj, A. Model Evasion Attack on Intrusion Detection Systems using Adversarial Machine Learning. In Proceedings of the 2020 54th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 18–20 March 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Satter, R. Experts Who Wrestled with SolarWinds Hackers say Cleanup Could Take Months-or Longer; Reuters: New York, NY, USA, 2020. [Google Scholar]
- Sirota, S. Air Force response to SolarWinds hack: Preserve commercial partnerships, improve transparency into security efforts. Inside Cybersecur. 2021. [Google Scholar]
- Corona, I.; Giacinto, G.; Roli, F. Adversarial attacks against intrusion detection systems: Taxonomy, solutions and open issues. Inf. Sci. 2013, 239, 201–225. [Google Scholar] [CrossRef]
- Hankin, C.; Barrère, M. Trustworthy Inter-connected Cyber-Physical Systems. In International Conference on Critical Information Infrastructures Security; Springer: Berlin/Heidelberg, Germany, 2020; pp. 3–13. [Google Scholar]
- Cho, J.H.; Xu, S.; Hurley, P.M.; Mackay, M.; Benjamin, T.; Beaumont, M. Stram: Measuring the trustworthiness of computer-based systems. ACM Comput. Surv. (CSUR) 2019, 51, 1–47. [Google Scholar] [CrossRef]
- Zhang, J.; Li, C. Adversarial examples: Opportunities and challenges. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 2578–2593. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Apruzzese, G.; Andreolini, M.; Ferretti, L.; Marchetti, M.; Colajanni, M. Modeling Realistic Adversarial Attacks against Network Intrusion Detection Systems. Digit. Threat. Res. Pract. 2021. [Google Scholar] [CrossRef]
- Shannon, C.E. Communication theory of secrecy systems. Bell Syst. Tech. J. 1949, 28, 656–715. [Google Scholar] [CrossRef]
- Taran, O.; Rezaeifar, S.; Voloshynovskiy, S. Bridging machine learning and cryptography in defence against adversarial attacks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wu, Y.; Wei, D.; Feng, J. Network attacks detection methods based on deep learning techniques: A survey. Secur. Commun. Netw. 2020, 2020, 8872923. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- McHugh, J. Testing intrusion detection systems: A critique of the 1998 and 1999 darpa intrusion detection system evaluations as performed by lincoln laboratory. ACM Trans. Inf. Syst. Secur. (TISSEC) 2000, 3, 262–294. [Google Scholar] [CrossRef]
- Cerf, V.G. 2021 Internet Perspectives. IEEE Netw. 2021, 35, 3. [Google Scholar] [CrossRef]
- McKeay, M. Akamai State of the Internet/Security: A Year in Review. Available online: http://akamai.com/soti (accessed on 15 September 2021).
- Kok, S.; Abdullah, A.; Jhanjhi, N.; Supramaniam, M. A review of intrusion detection system using machine learning approach. Int. J. Eng. Res. Technol. 2019, 12, 8–15. [Google Scholar]
- Alatwi, H.A.; Morisset, C. Adversarial Machine Learning In Network Intrusion Detection Domain: A Systematic Review. arXiv 2021, arXiv:2112.03315. [Google Scholar]
- Revathi, S.; Malathi, A. A detailed analysis on NSL-KDD dataset using various machine learning techniques for intrusion detection. Int. J. Eng. Res. Technol. (IJERT) 2013, 2, 1848–1853. [Google Scholar]
- Gharaibeh, M.; Papadopoulos, C. DARPA 2009 intrusion detection dataset. Colo. State Univ. Tech. Rep. 2014. [Google Scholar]
- Garcia, S.; Grill, M.; Stiborek, J.; Zunino, A. An empirical comparison of botnet detection methods. Comput. Secur. 2014, 45, 100–123. [Google Scholar] [CrossRef]
- Song, J.; Takakura, H.; Okabe, Y.; Eto, M.; Inoue, D.; Nakao, K. Statistical analysis of honeypot data and building of Kyoto 2006+ dataset for NIDS evaluation. In Proceedings of the first Workshop on Building Analysis Datasets and Gathering Experience Returns for Security, Salzburg, Austria, 10–13 April 2011; pp. 29–36. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 military communications and information systems conference (MilCIS), Canberra, Australia, 10 November 2015; pp. 1–6. [Google Scholar]
- Almomani, I.; Al-Kasasbeh, B.; Al-Akhras, M. WSN-DS: A dataset for intrusion detection systems in wireless sensor networks. J. Sens. 2016, 2016, 4731953. [Google Scholar] [CrossRef] [Green Version]
- Niyaz, Q.; Sun, W.; Javaid, A.Y. A deep learning based DDoS detection system in software-defined networking (SDN). arXiv 2016, arXiv:1611.07400. [Google Scholar] [CrossRef] [Green Version]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSp 2018, 1, 108–116. [Google Scholar]
- Antonakakis, M.; April, T.; Bailey, M.; Bernhard, M.; Bursztein, E.; Cochran, J.; Durumeric, Z.; Halderman, J.A.; Invernizzi, L.; Kallitsis, M.; et al. Understanding the mirai botnet. In Proceedings of the 26th USENIX Security Symposium (USENIX Security 17), Vancouver, BC, Canada, 16–18 August 2017; pp. 1093–1110. [Google Scholar]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the Internet of things for network forensic analytics: Bot-iot dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef] [Green Version]
- Mirsky, Y.; Doitshman, T.; Elovici, Y.; Shabtai, A. Kitsune: An ensemble of autoencoders for online network intrusion detection. arXiv 2018, arXiv:1802.09089. [Google Scholar]
- Janusz, A.; Kałuza, D.; Chądzyńska-Krasowska, A.; Konarski, B.; Holland, J.; Ślęzak, D. IEEE BigData 2019 cup: Suspicious network event recognition. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, 9–12 December 2019; pp. 5881–5887. [Google Scholar]
- Ferriyan, A.; Thamrin, A.H.; Takeda, K.; Murai, J. Generating Network Intrusion Detection Dataset Based on Real and Encrypted Synthetic Attack Traffic. Appl. Sci. 2021, 11, 7868. [Google Scholar] [CrossRef]
- Martins, N.; Cruz, J.M.; Cruz, T.; Abreu, P.H. Adversarial machine learning applied to intrusion and malware scenarios: A systematic review. IEEE Access 2020, 8, 35403–35419. [Google Scholar] [CrossRef]
- Shafique, M.; Naseer, M.; Theocharides, T.; Kyrkou, C.; Mutlu, O.; Orosa, L.; Choi, J. Robust machine learning systems: Challenges, current trends, perspectives, and the road ahead. IEEE Des. Test 2020, 37, 30–57. [Google Scholar] [CrossRef]
- Labaca-Castro, R.; Biggio, B.; Dreo Rodosek, G. Poster: Attacking malware classifiers by crafting gradient-attacks that preserve functionality. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 2565–2567. [Google Scholar]
- Gonzalez-Cuautle, D.; Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, L.K.; Portillo-Portillo, J.; Olivares-Mercado, J.; Perez-Meana, H.M.; Sandoval-Orozco, A.L. Synthetic minority oversampling technique for optimizing classification tasks in botnet and intrusion-detection-system datasets. Appl. Sci. 2020, 10, 794. [Google Scholar] [CrossRef] [Green Version]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 1–54. [Google Scholar] [CrossRef]
- Sheatsley, R.; Papernot, N.; Weisman, M.; Verma, G.; McDaniel, P. Adversarial Examples in Constrained Domains. arXiv 2020, arXiv:2011.01183. [Google Scholar]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-validation. Encycl. Database Syst. 2009, 5, 532–538. [Google Scholar]
- Bai, T.; Luo, J.; Zhao, J.; Wen, B. Recent Advances in Adversarial Training for Adversarial Robustness. arXiv 2021, arXiv:2102.01356. [Google Scholar]
- Weng, T.W.; Zhang, H.; Chen, P.Y.; Yi, J.; Su, D.; Gao, Y.; Hsieh, C.J.; Daniel, L. Evaluating the robustness of neural networks: An extreme value theory approach. arXiv 2018, arXiv:1801.10578. [Google Scholar]
- Goodfellow, I. Gradient masking causes clever to overestimate adversarial perturbation size. arXiv 2018, arXiv:1804.07870. [Google Scholar]
- Weng, T.W.; Zhang, H.; Chen, P.Y.; Lozano, A.; Hsieh, C.J.; Daniel, L. On extensions of clever: A neural network robustness evaluation algorithm. In Proceedings of the 2018 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Anaheim, CA, USA, 26–28 November 2018; pp. 1159–1163. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (sp), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Papernot, N.; Faghri, F.; Carlini, N.; Goodfellow, I.; Feinman, R.; Kurakin, A.; Xie, C.; Sharma, Y.; Brown, T.; Roy, A.; et al. Technical report on the cleverhans v2. 1.0 adversarial examples library. arXiv 2016, arXiv:1610.00768. [Google Scholar]
- Rauber, J.; Brendel, W.; Bethge, M. Foolbox: A python toolbox to benchmark the robustness of machine learning models. arXiv 2017, arXiv:1707.04131. [Google Scholar]
- Nicolae, M.I.; Sinn, M.; Tran, M.N.; Buesser, B.; Rawat, A.; Wistuba, M.; Zantedeschi, V.; Baracaldo, N.; Chen, B.; Ludwig, H.; et al. Adversarial Robustness Toolbox v1. 0.0. arXiv 2018, arXiv:1807.01069. [Google Scholar]
- Ding, G.W.; Wang, L.; Jin, X. AdverTorch v0. 1: An adversarial robustness toolbox based on pytorch. arXiv 2019, arXiv:1902.07623. [Google Scholar]
- Lashkari, A.H.; Zang, Y.; Owhuo, G.; Mamun, M.; Gil, G. CICFlowMeter. Available online: https://www.unb.ca/cic/research/applications.html (accessed on 19 February 2021).
- Habibi Lashkari, A.; Draper Gil, G.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of Tor Traffic using Time based Features. In Proceedings of the 3rd International Conference on Information Systems Security and Privacy-ICISSP, Porto, Portugal, 19–21 February 2017; pp. 253–262. [Google Scholar] [CrossRef]
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A. Characterization of Encrypted and VPN Traffic using Time-related Features. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy-ICISSP, Rome, Italy, 19–21 February 2016; pp. 407–414. [Google Scholar] [CrossRef]
- Sarker, I.H.; Abushark, Y.B.; Alsolami, F.; Khan, A.I. Intrudtree: A machine learning based cyber security intrusion detection model. Symmetry 2020, 12, 754. [Google Scholar] [CrossRef]
- Almomani, O. A feature selection model for network intrusion detection system based on PSO, GWO, FFA and GA algorithms. Symmetry 2020, 12, 1046. [Google Scholar] [CrossRef]
- McCarthy, A.; Andriotis, P.; Ghadafi, E.; Legg, P. Feature Vulnerability and Robustness Assessment against Adversarial Machine Learning Attacks. In Proceedings of the 2021 International Conference on Cyber Situational Awareness, Data Analytics and Assessment (CyberSA), Dublin, Ireland, 14–18 June 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 582–597. [Google Scholar]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, 1–9. [Google Scholar] [CrossRef]
- Biggio, B.; Corona, I.; Maiorca, D.; Nelson, B.; Šrndić, N.; Laskov, P.; Giacinto, G.; Roli, F. Evasion attacks against machine learning at test time. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2013; pp. 387–402. [Google Scholar]
- Papernot, N.; McDaniel, P.; Swami, A.; Harang, R. Crafting adversarial input sequences for recurrent neural networks. In Proceedings of the MILCOM 2016-2016 IEEE Military Communications Conference, Baltimore, MD, USA, 1–3 November 2016; pp. 49–54. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The Limitations of Deep Learning in Adversarial Settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS P), Saarbrucken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Jia, R.; Liang, P. Adversarial Examples for Evaluating Reading Comprehension Systems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 2021–2031. [Google Scholar]
- Zhao, Z.; Dua, D.; Singh, S. Generating Natural Adversarial Examples. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Lin, Y.C.; Hong, Z.W.; Liao, Y.H.; Shih, M.L.; Liu, M.Y.; Sun, M. Tactics of adversarial attack on deep reinforcement learning agents. arXiv 2017, arXiv:1703.06748. [Google Scholar]
- Rigaki, M. Adversarial Deep Learning against Intrusion Detection Classifiers; Luleå University of Technology: Luleå, Sweden, 2017. [Google Scholar]
- Hu, W.; Tan, Y. Black-box attacks against RNN based malware detection algorithms. In Proceedings of the Workshops at the Thirty-Second AAAI Conference on Artificial Intelligence, Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Homoliak, I.; Teknös, M.; Ochoa, M.; Breitenbacher, D.; Hosseini, S.; Hanacek, P. Improving Network Intrusion Detection Classifiers by Non-payload-Based Exploit-Independent Obfuscations: An Adversarial Approach. EAI Endorsed Trans. Secur. Saf. 2018, 5, e4. [Google Scholar] [CrossRef]
- Rosenberg, I.; Shabtai, A.; Rokach, L.; Elovici, Y. Generic black-box end-to-end attack against state of the art API call based malware classifiers. In International Symposium on Research in Attacks, Intrusions, and Defenses; Springer: Berlin/Heidelberg, Germany, 2018; pp. 490–510. [Google Scholar]
- Wang, Z. Deep learning-based intrusion detection with adversaries. IEEE Access 2018, 6, 38367–38384. [Google Scholar] [CrossRef]
- Warzyński, A.; Kołaczek, G. Intrusion detection systems vulnerability on adversarial examples. In Proceedings of the 2018 Innovations in Intelligent Systems and Applications (INISTA), Thessaloniki, Greece, 3–5 July 2018; pp. 1–4. [Google Scholar]
- Lin, Z.; Shi, Y.; Xue, Z. Idsgan: Generative adversarial networks for attack generation against intrusion detection. arXiv 2018, arXiv:1809.02077. [Google Scholar]
- Yang, K.; Liu, J.; Zhang, C.; Fang, Y. Adversarial examples against the deep learning based network intrusion detection systems. In Proceedings of the MILCOM 2018-2018 IEEE Military Communications Conference (MILCOM), Los Angeles, CA, USA, 29–31 October 2018; pp. 559–564. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef] [Green Version]
- Kuppa, A.; Grzonkowski, S.; Asghar, M.R.; Le-Khac, N.A. Black box attacks on deep anomaly detectors. In Proceedings of the 14th International Conference on Availability, Reliability and Security, Canterbury, UK, 26–29 August 2019; pp. 1–10. [Google Scholar]
- Ibitoye, O.; Shafiq, O.; Matrawy, A. Analyzing adversarial attacks against deep learning for intrusion detection in IoT networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Usama, M.; Asim, M.; Latif, S.; Qadir, J. Generative adversarial networks for launching and thwarting adversarial attacks on network intrusion detection systems. In Proceedings of the 2019 15th International Wireless Communications &Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 78–83. [Google Scholar]
- Huang, W.; Peng, X.; Shi, Z.; Ma, Y. Adversarial Attack against LSTM-based DDoS Intrusion Detection System. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; pp. 686–693. [Google Scholar]
- Ogawa, Y.; Kimura, T.; Cheng, J. Vulnerability Assessment for Machine Learning Based Network Anomaly Detection System. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-Taiwan), Taoyuan, Taiwan, 28–30 September 2020; pp. 1–2. [Google Scholar]
- Chen, J.; Gao, X.; Deng, R.; He, Y.; Fang, C.; Cheng, P. Generating Adversarial Examples against Machine Learning based Intrusion Detector in Industrial Control Systems. IEEE Trans. Dependable Secur. Comput. 2020; PrePrints. [Google Scholar] [CrossRef]
- Demetrio, L.; Biggio, B.; Lagorio, G.; Roli, F.; Armando, A. Functionality-preserving black-box optimization of adversarial windows malware. IEEE Trans. Inf. Forensics Secur. 2021, 16, 3469–3478. [Google Scholar] [CrossRef]
- Labaca-Castro, R.; Muñoz-González, L.; Pendlebury, F.; Rodosek, G.D.; Pierazzi, F.; Cavallaro, L. Universal Adversarial Perturbations for Malware. arXiv 2021, arXiv:2102.06747. [Google Scholar]
- Cai, F.; Li, J.; Koutsoukos, X. Detecting adversarial examples in learning-enabled cyber-physical systems using variational autoencoder for regression. In Proceedings of the 2020 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 21 May 2020; pp. 208–214. [Google Scholar]
- Li, J.; Yang, Y.; Sun, J.S.; Tomsovic, K.; Qi, H. Conaml: Constrained adversarial machine learning for cyber-physical systems. In Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security, Hong Kong, China, 7–11 June 2021; pp. 52–66. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S.; Dong, Y.; Liao, F.; Liang, M.; Pang, T.; Zhu, J.; Hu, X.; Xie, C.; et al. Adversarial attacks and defences competition. In The NIPS’17 Competition: Building Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2018; pp. 195–231. [Google Scholar]
- Sharif, M.; Bhagavatula, S.; Bauer, L.; Reiter, M.K. A General Framework for Adversarial Examples with Objectives. ACM Trans. Priv. Secur. 2019, 22. [Google Scholar] [CrossRef]
- Biggio, B.; Roli, F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef] [Green Version]
- Gilmer, J.; Adams, R.P.; Goodfellow, I.; Andersen, D.; Dahl, G.E. Motivating the rules of the game for adversarial example research. arXiv 2018, arXiv:1807.06732. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1765–1773. [Google Scholar]
- Chernikova, A.; Oprea, A. Fence: Feasible evasion attacks on neural networks in constrained environments. arXiv 2019, arXiv:1909.10480. [Google Scholar]
- Apruzzese, G.; Colajanni, M.; Marchetti, M. Evaluating the effectiveness of adversarial attacks against botnet detectors. In Proceedings of the 2019 IEEE 18th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 26–28 September 2019; pp. 1–8. [Google Scholar]
- Hashemi, M.J.; Cusack, G.; Keller, E. Towards evaluation of nidss in adversarial setting. In Proceedings of the 3rd ACM CoNEXT Workshop on Big DAta, Machine Learning and Artificial Intelligence for Data Communication Networks, Orlando, FL, USA, 9 December 2019; pp. 14–21. [Google Scholar]
- Papadopoulos, P.; Essen, O.T.v.; Pitropakis, N.; Chrysoulas, C.; Mylonas, A.; Buchanan, W.J. Launching Adversarial Attacks against Network Intrusion Detection Systems for IoT. J. Cybersecur. Priv. 2021, 1, 14. [Google Scholar] [CrossRef]
- Anthi, E.; Williams, L.; Rhode, M.; Burnap, P.; Wedgbury, A. Adversarial attacks on machine learning cybersecurity defences in industrial control systems. J. Inf. Secur. Appl. 2021, 58, 102717. [Google Scholar] [CrossRef]
- Han, D.; Wang, Z.; Zhong, Y.; Chen, W.; Yang, J.; Lu, S.; Shi, X.; Yin, X. Evaluating and Improving Adversarial Robustness of Machine Learning-Based Network Intrusion Detectors. IEEE J. Sel. Areas Commun. 2021, 39, 2632–2647. [Google Scholar] [CrossRef]
- Duy, P.T.; Khoa, N.H.; Nguyen, A.G.T.; Pham, V.H. DIGFuPAS: Deceive IDS with GAN and Function-Preserving on Adversarial Samples in SDN-enabled networks. Comput. Secur. 2021, 109, 102367. [Google Scholar] [CrossRef]
- Alhajjar, E.; Maxwell, P.; Bastian, N. Adversarial machine learning in network intrusion detection systems. Expert Syst. Appl. 2021, 186, 115782. [Google Scholar] [CrossRef]
- Han, D.; Wang, Z.; Zhong, Y.; Chen, W.; Yang, J.; Lu, S.; Shi, X.; Yin, X. Practical Traffic-Space Adversarial Attacks on Learning-Based Nidss. arXiv 2005, arXiv:2005.07519. [Google Scholar]
- Wang, J.; Pan, J.; AlQerm, I.; Liu, Y. Def-IDS: An Ensemble Defense Mechanism Against Adversarial Attacks for Deep Learning-based Network Intrusion Detection. In Proceedings of the 2021 International Conference on Computer Communications and Networks (ICCCN), Athens, Greece, 19–22 July 2021; pp. 1–9. [Google Scholar]
- Ali, H.; Khan, M.S.; AlGhadhban, A.; Alazmi, M.; Alzamil, A.; Al-utaibi, K.; Qadir, J. Analyzing the Robustness of Fake-news Detectors under Black-box Adversarial Attacks. IEEE Access 2021, 9, 81678–81692. [Google Scholar] [CrossRef]
- Chenou, J.; Hsieh, G.; Fields, T. Radial Basis Function Network: Its Robustness and Ability to Mitigate Adversarial Examples. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7 December 2019; pp. 102–106. [Google Scholar]
- Wei, W.; Liu, L.; Loper, M.; Truex, S.; Yu, L.; Gursoy, M.E.; Wu, Y. Adversarial examples in deep learning: Characterization and divergence. arXiv 2018, arXiv:1807.00051. [Google Scholar]
- Tramèr, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing machine learning models via prediction apis. In Proceedings of the 5th USENIX Security Symposium (USENIX Security 16), Austin, TX, USA, 10–12 August 2016; pp. 601–618. [Google Scholar]
- Lillicrap, T.P.; Cownden, D.; Tweed, D.B.; Akerman, C.J. Random synaptic feedback weights support error backpropagation for deep learning. Nat. Commun. 2016, 7, 1–10. [Google Scholar] [CrossRef]
- Graese, A.; Rozsa, A.; Boult, T.E. Assessing Threat of Adversarial Examples on Deep Neural Networks. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; pp. 69–74. [Google Scholar] [CrossRef] [Green Version]
- Grosse, K.; Manoharan, P.; Papernot, N.; Backes, M.; McDaniel, P. On the (statistical) detection of adversarial examples. arXiv 2017, arXiv:1702.06280. [Google Scholar]
- Metzen, J.H.; Genewein, T.; Fischer, V.; Bischoff, B. On detecting adversarial perturbations. arXiv 2017, arXiv:1702.04267. [Google Scholar]
- Feinman, R.; Curtin, R.R.; Shintre, S.; Gardner, A.B. Detecting adversarial samples from artifacts. arXiv 2017, arXiv:1703.00410. [Google Scholar]
- Meng, D.; Chen, H. Magnet: A two-pronged defense against adversarial examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 135–147. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Lee, H.; Han, S.; Lee, J. Generative adversarial trainer: Defense to adversarial perturbations with gan. arXiv 2017, arXiv:1705.03387. [Google Scholar]
- Samangouei, P.; Kabkab, M.; Chellappa, R. Defense-gan: Protecting classifiers against adversarial attacks using generative models. arXiv 2018, arXiv:1805.06605. [Google Scholar]
- Dhillon, G.S.; Azizzadenesheli, K.; Lipton, Z.C.; Bernstein, J.; Kossaifi, J.; Khanna, A.; Anandkumar, A. Stochastic activation pruning for robust adversarial defense. arXiv 2018, arXiv:1803.01442. [Google Scholar]
- Tian, Y.; Pei, K.; Jana, S.; Ray, B. Deeptest: Automated testing of deep-neural-network-driven autonomous cars. In Proceedings of the 40th International Conference on Software Engineering, Gothenburg, Sweden, 27 May–3 June 2018; pp. 303–314. [Google Scholar]
- Zhang, M.; Zhang, Y.; Zhang, L.; Liu, C.; Khurshid, S. DeepRoad: GAN-based metamorphic testing and input validation framework for autonomous driving systems. In Proceedings of the 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 3–7 September 2018; pp. 132–142. [Google Scholar]
- Wang, S.; Wang, X.; Zhao, P.; Wen, W.; Kaeli, D.; Chin, P.; Lin, X. Defensive dropout for hardening deep neural networks under adversarial attacks. In Proceedings of the International Conference on Computer-Aided Design, San Diego, CA, USA, 5–8 November 2018; pp. 1–8. [Google Scholar]
- Amer, M.; Maul, T. Weight Map Layer for Noise and Adversarial Attack Robustness. arXiv 2019, arXiv:1905.00568. [Google Scholar]
- Rosenberg, I.; Shabtai, A.; Elovici, Y.; Rokach, L. Defense methods against adversarial examples for recurrent neural networks. arXiv 2019, arXiv:1901.09963. [Google Scholar]
- Apruzzese, G.; Andreolini, M.; Marchetti, M.; Venturi, A.; Colajanni, M. Deep reinforcement adversarial learning against botnet evasion attacks. IEEE Trans. Netw. Serv. Manag. 2020, 17, 1975–1987. [Google Scholar] [CrossRef]
- Apruzzese, G.; Colajanni, M.; Ferretti, L.; Marchetti, M. Addressing adversarial attacks against security systems based on machine learning. In Proceedings of the 2019 11th International Conference on Cyber Conflict (CyCon), Tallinn, Estonia. 28–31 May 2019; Volume 900, pp. 1–18. [Google Scholar]
- Zhou, Y.; Kantarcioglu, M.; Xi, B. A survey of game theoretic approach for adversarial machine learning. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1259. [Google Scholar] [CrossRef]
- Apruzzese, G.; Andreolini, M.; Colajanni, M.; Marchetti, M. Hardening random forest cyber detectors against adversarial attacks. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 4, 427–439. [Google Scholar] [CrossRef]
- Zhang, C.; Tang, Z.; Zuo, Y.; Li, K.; Li, K. A robust generative classifier against transfer attacks based on variational auto-encoders. Inf. Sci. 2021, 550, 57–70. [Google Scholar] [CrossRef]
- Wang, N.; Chen, Y.; Hu, Y.; Lou, W.; Hou, Y.T. MANDA: On Adversarial Example Detection for Network Intrusion Detection System. In Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar]
- Song, D.; Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Tramer, F.; Prakash, A.; Kohno, T. Physical adversarial examples for object detectors. In Proceedings of the 12th USENIX Workshop on Offensive Technologies (WOOT 18), Baltimore, MA, USA, 13–14 August 2018. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2016; pp. 1050–1059. [Google Scholar]
- Carlini, N.; Wagner, D. Adversarial examples are not easily detected: Bypassing ten detection methods. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 3–14. [Google Scholar]
- Pei, K.; Cao, Y.; Yang, J.; Jana, S. Deepxplore: Automated whitebox testing of deep learning systems. In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28–31 October 2017; pp. 1–18. [Google Scholar]
- Biggio, B.; Fumera, G.; Roli, F. Adversarial pattern classification using multiple classifiers and randomisation. In Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR); Springer: Berlin/Heidelberg, Germany, 2008; pp. 500–509. [Google Scholar]
- Carlini, N. A Complete List of All (Arxiv) Adversarial Example Papers. Available online: https://nicholas.carlini.com/writing/2019/all-adversarial-example-papers.html (accessed on 30 January 2022).
- Sculley, D.; Holt, G.; Golovin, D.; Davydov, E.; Phillips, T.; Ebner, D.; Chaudhary, V.; Young, M.; Crespo, J.F.; Dennison, D. Hidden technical debt in machine learning systems. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2503–2511. [Google Scholar]
- Shu, D.; Leslie, N.O.; Kamhoua, C.A.; Tucker, C.S. Generative adversarial attacks against intrusion detection systems using active learning. In Proceedings of the 2nd ACM Workshop on Wireless Security and Machine Learning, Linz, Austria, 13 July 2020; pp. 1–6. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Dataset | Network | Year | Attack Categories |
|---|---|---|---|---|
| [32] | KDD Cup 99 | Traditional | 1999 | DoS, Probe, User 2 Root and Remote to User |
| [38] | NSL-KDD | Traditional | 2009 | DoS, Probe, User 2 Root and Remote to User |
| [39] | DARPA | Traditional | 2009 | DDoS, Malware, Spambots, Scans, Phishing |
| [40] | CTU-13 | Traditional | 2011 | Botnet |
| [41] | Kyoto | Traditional | 2015 | Botnet |
| [42] | UNSW-NB15 | Traditional | 2016 | Backdoors, Fuzzers, DoS, Generic, Shell code, Reconnaissance, Worms, Exploits, Analysis |
| [43] | WSN-D5 | Wireless | 2016 | Greyhole, Blackhole, Scheduling, Flooding. |
| [44] | SDN Traffic | SDN | 2016 | DDoS |
| [45] | CICIDS2017 | Traditional | 2017 | DoS, DDoS, SSH-Patator, Web, PortScan, FTP-Patator, Bot. |
| [46] | Mirai | IoT | 2017 | Botnet |
| [45] | CICIDS2018 | Traditional | 2018 | Bruteforce Web, DoS, DDoS, Botnet, Infiltration. |
| [45] | CICDDoS2019 | Traditional | 2019 | DDoS |
| [47] | Bot-IOT | IoT | 2018 | DDoS, DoS, OS Service Scan, Keylogging, Data exfiltration |
| [48] | Kitsune | IoT | 2018 | Recon, Man in the Middle, DoS, Botnet Malware |
| [49] | IEEE BigData Cup | Traditional | 2019 | N/A |
| [50] | HIKARI-2021 | IoT | 2021 | Brute force attack, Brute force attack (XMLRPC), Vulnerability, probing, Synthetic Traffic |
| Work | Metric | Advantages | Disadvantages |
|---|---|---|---|
| N/A | F1-Score | Commonly used by researchers. | Biased by the majority class |
| [59] | CLEVER | Attack-agnostic and computationally feasible. | CLEVER is less suited to black-box attacks and where gradient masking occurs [60]; However, extensions to CLEVER help mitigate these scenarios [61]. |
| [62] | Empirical robustness | Suitable for very deep neural networks and large datasets. | N/A |
| Work | Library Name | Year | Advantages | Disadvantages |
|---|---|---|---|---|
| [65] | CleverHans | 2016 | Recently updated to v4.0.0, well used by the community. MIT License | Can be complicated to configure. |
| [66] | Foolbox | 2017 | Fast generation of adversarial examples. MIT License | Large number of open issues. |
| [67] | Adversarial robustness toolbox | 2018 | Well maintained and supported. Supports most known machine learning frameworks. Extensive attacks and model robustness tools are supported. | Does not support all models. |
| [68] | Advertorch | 2019 | GNU lesser public license. | Few active contributors. |
| Topic | Search Query |
|---|---|
| Cyber security/intrusion detection | (“cyber security” OR “intrusion detection” OR “IDS”) |
| Adversarial machine learning attacks and defences | (“adversarial machine learning” OR “machine learning” OR “adversarial example”) and (“attack” OR “defence”) |
| Robustness/Functionality Preservation | ((“robustness” OR “generalization error” OR “accuracy” OR “f1score” OR “f-score” OR “TPR” OR “FPR”) OR ((“functionality” OR “payload”) AND “preservation”))) |
| Work | Year | Attack | Type | Obj | Domain | Model | Knowledge | Constraint | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AE | Sequence of AEs | Transferability | Targeted | Untargeted | Visual | Cybersecurity | Text | MLP | CNN | RNN | White-Box | Black-box | Gray-Box | Box | Sparse | Func-Preserving | |||
| [17] | 2014 | L-BFGS | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [77] | 2013 | GradientDescent | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [78] | 2016 | Adversarial Sequences | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [79] | 2016 | JSMA | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [62] | 2016 | Deepfool | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||
| [80] | 2017 | AddSent,AddOneSent | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [81] | 2018 | GAN | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||
| [82] | 2017 | EnchantingAttack | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||
| [82] | 2017 | StrategicAttack | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||
| [64] | 2017 | C&W, , , | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||
| [83] | 2017 | FGSM,JSMA | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||
| [84] | 2018 | Generative RNN | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [85] | 2018 | NPBO | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [86] | 2018 | GADGET | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [87] | 2018 | JSMA,FGSM,DeepFool,CW | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||
| [88] | 2018 | FGSM | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||
| [89] | 2018 | IDS-GAN | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||
| [90] | 2018 | ZOO,GAN | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||
| [91] | 2019 | One Pixel Attack | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [92] | 2019 | ManifoldApproximation | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [93] | 2019 | FGSM,BIM,PGD | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [94] | 2019 | GAN Attack | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [95] | 2020 | PWPSA | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [95] | 2020 | GA | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [96] | 2020 | One Pixel Attack | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [97] | 2020 | Opt Attack,GAN Attack | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [98] | 2021 | GAMMA | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||
| [99] | 2021 | UAP | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [100] | 2020 | Variational Auto Encoder | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [101] | 2021 | Best-Effort Search | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| Method | Computational Complexity | Success Rate |
|---|---|---|
| L-BFGS | High | High |
| FGSM | Low | Low |
| JSMA | High | High |
| DeepFool | Low | Low |
| One-pixel | Low | Low |
| CW Attack | High | High |
| Work | Year | Domain | Generation Method | Realistic Constraints | Findings |
|---|---|---|---|---|---|
| [53] | 2019 | Malware | Gradient-based | Minimal content additions/modification | Experiments showed that we are able to use that information to find optimal sequences of transformations without rendering the malware sample corrupt. |
| [94] | 2019 | IDS | GAN | Preserve functionality | The proposed adversarial attack successfully evades the IDS while ensuring preservation of functional behavior and network traffic features. |
| [108] | 2019 | IDS | Gradient-based | Respects mathematical dependencies and domain constraints. | Evasion attacks achieved by inserting a dozen network connections. |
| [109] | 2019 | IDS | Random modification features: flow duration, sent bytes, received bytes, exchanged packets. | Retains internal logic | Feature removal is insufficient defense against functionality-preserving attacks, which may are possible by modifying very few features. |
| [110] | 2019 | IDS | Legitimate transformations: split, delay, inject | Packets must maintain malicious intent, transformations hold to underlying protocols. | Detection rate of packet-level features dropped by up to 70% and flow-level features dropped by up to 68%. |
| [56] | 2020 | IDS—Flows | Jacobian method (JSMA) | Obeys TCP/IP constraints | Biased distributions with low dimensionality enable constrained adversarial examples. Constrained to five random features, −50% adversarial examples succeed. |
| [95] | 2020 | IDS—packet | Valid packet | Minimal modification/insertion of packets | Experimental results show powerful and effective functionality-preserving attacks. More accurate models are more susceptible to adversarial examples. |
| [98] | 2021 | Malware | Injected unexecuted benign content | Minimal injected content | Section-injection attack can decrease the detection rate. Their analysis highlights that commercial products can be evaded via transfer attacks. |
| [101] | 2021 | CPS | Best-effort search | Real-world linear inequality | Best-effort search algorithms effectively generate adversarial examples meeting linear constraints. Their evaluation shows constrained adversarial examples significantly decrease detection accuracy. |
| [111] | 2021 | IDS | Minimal perturbation of each feature | FGSM | Functionality is not reported, but is less likely to preserve functionality because all features are perturbed. |
| [112] | 2021 | CPS/ICS | JSMA | Minimal number of perturbed features | Functionality is not reported, but is more likely to preserve functionality because relatively few features are perturbed. |
| [113] | 2021 | IDS | PSO-based mutation | Original traffic retained and packet order is unchanged | Measured attack effect, malicious behavior and attack efficiency |
| [114] | 2021 | IDS | GAN | preserving functional features of attack traffic | F1 score drop to zero from around 99% DIGFuPAS adversarial examples. |
| [115] | 2021 | IDS | PSO/GA/GAN | Only modifies features where network functionality is retained | In the network traffic data, it is unrealistic to assume an adversary can alter all traffic features—constraints on features that do not break functionality |
| [116] | 2020 | IDS | GAN/PSO | Original traffic and packet order is retained. | Detection performance and robustness should both be considered in feature extraction systems. |
| Work | Year | Defense | Type | Domain | Model | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pre-Process | Detection | Adv-Training | Testing | Architectural | Distillation | Ensemble | Game Theory | Visual | Cybersecurity | Text | MLP | CNN | RNN | RF | |||
| [63] | 2014 | Adversarial Training | ✓ | ✓ | ✓ | ||||||||||||
| [75] | 2016 | Distillation as defense | ✓ | ✓ | ✓ | ||||||||||||
| [122] | 2016 | Feedback Alignment | ✓ | ✓ | ✓ | ||||||||||||
| [123] | 2016 | Assessing Threat | ✓ | ✓ | ✓ | ||||||||||||
| [124] | 2017 | Statistical Test | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [125] | 2017 | Detector SubNetwork | ✓ | ✓ | ✓ | ||||||||||||
| [126] | 2017 | Artifacts | ✓ | ✓ | ✓ | ||||||||||||
| [127] | 2017 | MagNet | ✓ | ✓ | ✓ | ||||||||||||
| [128] | 2017 | Feature Squeezing | ✓ | ✓ | ✓ | ||||||||||||
| [129] | 2017 | GAT | ✓ | ✓ | ✓ | ||||||||||||
| [102] | 2018 | EAT | ✓ | ✓ | ✓ | ||||||||||||
| [130] | 2018 | Defense-GAN | ✓ | ✓ | ✓ | ||||||||||||
| [103] | 2018 | Assessing Threat | ✓ | ✓ | ✓ | ||||||||||||
| [131] | 2018 | Stochastic Activation Pruning | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [132] | 2018 | DeepTest | ✓ | ✓ | ✓ | ||||||||||||
| [133] | 2018 | DeepRoad | ✓ | ✓ | ✓ | ||||||||||||
| [134] | 2018 | Defensive Dropout | ✓ | ✓ | ✓ | ||||||||||||
| [134] | 2018 | Def-IDS | ✓ | ✓ | ✓ | ||||||||||||
| [105] | 2018 | Multi-Classifier System | ✓ | ✓ | ✓ | ||||||||||||
| [135] | 2019 | Weight Map Layers | ✓ | ✓ | ✓ | ||||||||||||
| [136] | 2019 | Sequence Squeezing | ✓ | ✓ | ✓ | ||||||||||||
| [109] | 2019 | Feature Removal | ✓ | ✓ | ✓ | ||||||||||||
| [137] | 2020 | Adversarial Training | ✓ | ✓ | ✓ | ||||||||||||
| [138] | 2020 | Adversarial Training | ✓ | ✓ | ✓ | ||||||||||||
| [139] | 2019 | Game Theory | ✓ | ✓ | ✓ | ||||||||||||
| [140] | 2020 | Hardening | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [141] | 2021 | Variational Auto-encoder | ✓ | ✓ | ✓ | ||||||||||||
| [142] | 2021 | MANDA | ✓ | ✓ | ✓ | ||||||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
McCarthy, A.; Ghadafi, E.; Andriotis, P.; Legg, P. Functionality-Preserving Adversarial Machine Learning for Robust Classification in Cybersecurity and Intrusion Detection Domains: A Survey. J. Cybersecur. Priv. 2022, 2, 154-190. https://doi.org/10.3390/jcp2010010
McCarthy A, Ghadafi E, Andriotis P, Legg P. Functionality-Preserving Adversarial Machine Learning for Robust Classification in Cybersecurity and Intrusion Detection Domains: A Survey. Journal of Cybersecurity and Privacy. 2022; 2(1):154-190. https://doi.org/10.3390/jcp2010010
Chicago/Turabian StyleMcCarthy, Andrew, Essam Ghadafi, Panagiotis Andriotis, and Phil Legg. 2022. "Functionality-Preserving Adversarial Machine Learning for Robust Classification in Cybersecurity and Intrusion Detection Domains: A Survey" Journal of Cybersecurity and Privacy 2, no. 1: 154-190. https://doi.org/10.3390/jcp2010010