
Estimating Fuel Consumption of an Agricultural Robot by Applying Machine Learning Techniques during Seeding Operation

Abstract
:1. Introduction
2. Materials and Methods
2.1. Research Hypotheses
2.2. Supervised Learning (SL)
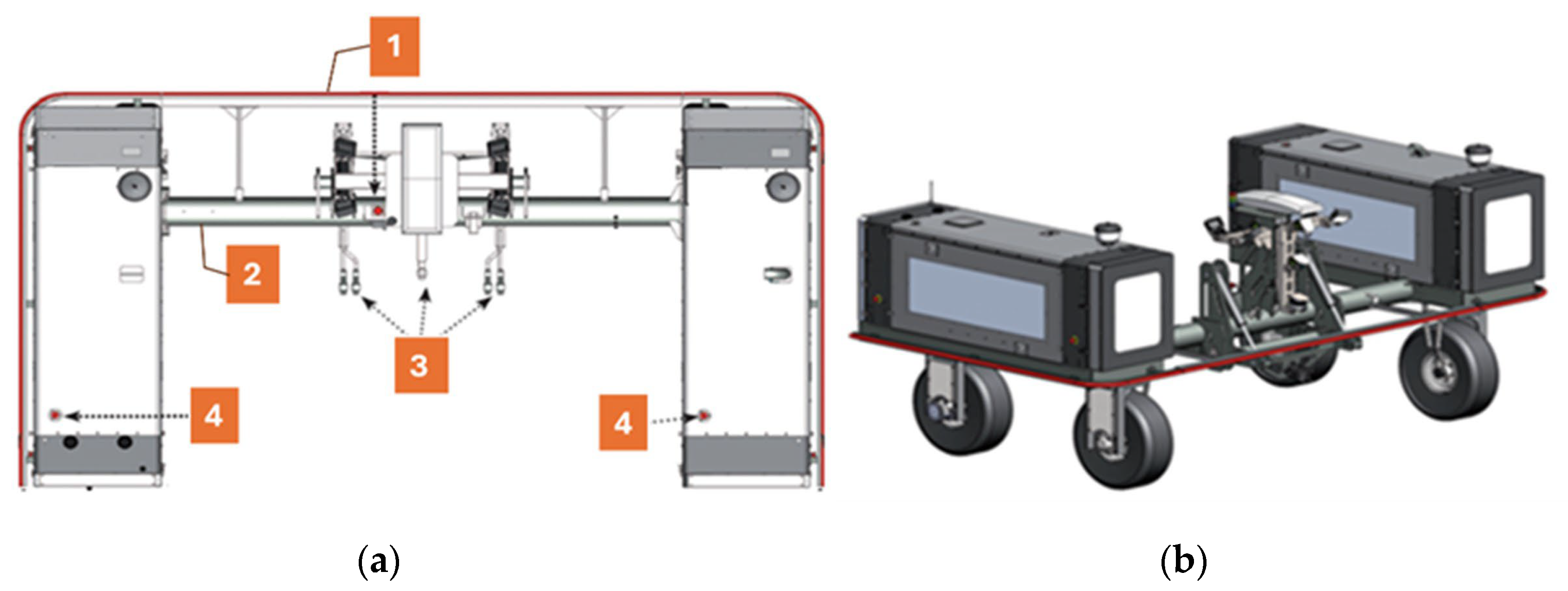
2.3. Robotic System
2.4. Data Acquisition
2.5. First Model (Based on ASABE Fuel Consumption Model)
2.6. Second Model (Based on Gaussian Process Regression Model)
2.6.1. Dataset Preparation
2.6.2. Feature Selection and Hyperparameter Optimization
2.7. Assess Model Performance
3. Results and Discussion
3.1. First Model (Based on ASABE Model)
3.2. Second Model (Predictive Model Using Machine Learning)
3.2.1. Feature Selection
3.2.2. Hyperparameter Optimization
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rahimi-Ajdadi, F.; Abbaspour-Gilandeh, Y. Artificial Neural Network and Stepwise Multiple Range Regression Methods for Prediction of Tractor Fuel Consumption. Measurement 2011, 44, 2104–2111. [Google Scholar] [CrossRef]
- Tetteh, E.K.; Amankwa, M.O.; Yeboah, C. Emerging carbon abatement technologies to mitigate energy-carbon footprint—A review. Clean. Mater. 2021, 2, 100020. [Google Scholar] [CrossRef]
- Mohammadi, A.; Rafiee, S.; Jafari, A.; Keyhani, A.; Mousavi-Avval, S.H.; Nonhebel, S. Energy use efficiency and greenhouse gas emissions of farming systems in north Iran. Renew. Sustain. Energy Rev. 2014, 30, 724–733. [Google Scholar] [CrossRef]
- Vahdanjoo, M.; Gislum, R.; Aage Grøn Sørensen, C. Operational, Economic, and Environmental Assessment of an Agricultural Robot in Seeding and Weeding Operations. AgriEngineering 2023, 5, 299–324. [Google Scholar] [CrossRef]
- Søgaard, H.T.; Aage Grøn Sørensen, C. A Model for Optimal Selection of Machinery Sizes within the Farm Machinery System. Biosyst. Eng. 2004, 1, 13–28. [Google Scholar] [CrossRef]
- Yang, L.; Weize, T.; Weixin, Z.; Xinxin, W.; Zhibo, C.; Long, W.; Yuanyuan, X.; Caicong, W. Behavior Recognition and Fuel Consumption Prediction of Tractor Sowing Operations Using Smartphone. Int. J. Agric. Biol. Eng. 2022, 4, 154–162. [Google Scholar] [CrossRef]
- Kichler, C.M.; Fulton, J.P.; Raper, R.L.; McDonald, T.P.; Zech, W.C. Effects of Transmission Gear Selection on Tractor Performance and Fuel Costs during Deep Tillage Operations. Soil Tillage Res. 2011, 2, 105–111. [Google Scholar] [CrossRef]
- Kocher, M.F.; Smith, B.J.; Hoy, R.M.; Woldstad, J.C.; Pitla, S.K. Fuel Consumption Models for Tractor Test Reports. Trans. ASABE 2017, 3, 693–701. [Google Scholar] [CrossRef]
- Kim, S.C.; Kim, K.U.; Kim, D.C. Prediction of Fuel Consumption of Agricultural Tractors. Appl. Eng. Agric. 2011, 5, 705–709. [Google Scholar] [CrossRef]
- Grisso, R.D.; Kocher, M.F.; Vaughan, D.H. Predicting Tractor Fuel Consumption. Appl. Eng. Agric. 2004, 20, 553–561. [Google Scholar] [CrossRef]
- Paraforos, D.S.; Griepentrog, H.W. Tractor fuel rate modeling and simulation using switching markov chains on can-bus data. IFAC-PapersOnLine 2019, 52, 379–384. [Google Scholar] [CrossRef]
- Naik, V.S.; Raheman, H. Factors affecting fuel consumption of tractor operating active tillage implement and its prediction. Eng. Agric. Environ. Food 2019, 12, 548–555. [Google Scholar] [CrossRef]
- Asinyetogha, H.I.; Raymond, A.E.; Silas, O.N. Predicting tractor fuel consumption during ridging on a sandy loam soil in a humid tropical climate. J. Eng. Technol. Res. 2019, 11, 29–40. [Google Scholar] [CrossRef]
- Michael, W.B.; Azlinah, M.; Bee, W.Y. Supervised and Unsupervised Learning for Data Science, 1st ed.; Springer Nature Switzerland AG: Cham, Switzerland, 2020; pp. 3–21. ISBN 978-3-030-22474-5. [Google Scholar]
- Dike, H.U.; Yimin, Z.; Kranthi, K.D.; Qingtian, W. Unsupervised Learning Based on Artificial Neural Network: A Review. In Proceedings of the IEEE International Conference on Cyborg and Bionic Systems (CBS), Shenzhen, China, 25–27 October 2018. [Google Scholar] [CrossRef]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis, 6th ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2021. [Google Scholar]
- Archontoulis, S.V.; Miguez, F.E. Nonlinear Regression Models and Applications in Agricultural Research. Agron. J. 2015, 107, 786–798. [Google Scholar] [CrossRef]
- Zhang, F.; O’Donnell, L.J. Support Vector Regression. In Machine Learning; Academic Press: Cambridge, MA, USA, 2020; pp. 123–140. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and regression trees. WIREs Data Min. Knowl. Discov. 2017, 1, 14–23. [Google Scholar] [CrossRef]
- Taki, M.; Rohani, A.; Soheili-Fard, F.; Abdeshahi, A. Assessment of Energy Consumption and Modeling of Output Energy for Wheat Production by Neural Network (MLP and RBF) and Gaussian Process Regression (GPR) Models. J. Clean. Prod. 2018, 172, 3028–3041. [Google Scholar] [CrossRef]
- Bataineh, M.; Marler, T. Neural Network for Regression Problems with Reduced Training Sets. Neural Netw. 2017, 95, 1–9. [Google Scholar] [CrossRef]
- American Society of Agricultural and Biological Engineers (ASABE). Agricultural Machinery Management Data—ASAE D497.7 MAR2011; ASABE: St. Joseph, MI, USA, 2011. [Google Scholar]
- MathWorks. Statistics and Machine Learning Toolbox User’s Guide R2022b; MathWorks Inc.: Natick, MA, USA, 2022. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar] [CrossRef]
- Whang, S.E.; Roh, Y.; Song, H.; Lee, J.G. Data Collection and Quality Challenges in Deep Learning: A Data-Centric AI Perspective. VLDB J. 2023, 32, 791–813. [Google Scholar] [CrossRef]
- Martin, B.; Moosbauer, J.; Thomas, J.; Bischl, B. Multi-Objective Hyperparameter Tuning and Feature Selection Using Filter Ensembles. In Proceedings of the 2020 Genetic and Evolutionary Computation Conference, Cancún, Mexico, 8–12 July 2020. [Google Scholar] [CrossRef]
- Yan, W.; Sherry Ni, X. A XGBOOST Risk Model via Feature Selection and Bayesian Hyper-Parameter Optimization. Int. J. Database Manag. Syst. 2019, 11, 1–17. [Google Scholar] [CrossRef]
- Simon, F.; Wong, R.; Vasilakos, A.V. Accelerated PSO Swarm Search Feature Selection for Data Stream Mining Big Data. IEEE Trans. Serv. Comput. 2016, 9, 33–45. [Google Scholar] [CrossRef]
- Li, Y.; Shami, A. On Hyperparameter Optimization of Machine Learning Algorithms: Theory and Practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Schulz, E.; Speekenbrink, M.; Krause, A. A tutorial on gaussian process regression: Modelling, exploring, and exploiting functions. J. Math. Psychol. 2018, 85, 1–16. [Google Scholar] [CrossRef]
- Li, L.L.; Zhang, X.B.; Tseng, M.L.; Zhou, Y.T. Optimal scale gaussian process regression model in insulated gate bipolar transistor remaining life prediction. Appl. Soft Comput. 2019, 78, 261–273. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Minimum | Maximum | Mean | Median | Standard Deviation | |
|---|---|---|---|---|---|
| fuelConsumption | 0.101 | 13.96 | 3.015 | 0.998 | 4.372 |
| traveledDist | 9.941 | 9197 | 1863 | 335.1 | 2678 |
| autoWorkDist | 0 | 8805 | 1723 | 245.5 | 2579 |
| autoTurnDist | 0.101 | 1213 | 120.9 | 54.86 | 197.1 |
| totalTime | 71 | 8843 | 1831 | 646 | 2405 |
| N | Predicted (by ASABE) | Measured | Error |
|---|---|---|---|
| 1 | 10.08 | 9.86 | 0.02 |
| 2 | 9.75 | 8.96 | 0.08 |
| 3 | 7.63 | 10.28 | 0.26 |
| 4 | 12.44 | 9.37 | 0.25 |
| 5 | 2.26 | 4.85 | 0.53 |
| 6 | 1.64 | 1.41 | 0.14 |
| 7 | 0.076 | 0.046 | 0.39 |
| 8 | 1.39 | 2.21 | 0.37 |
| 9 | 0.077 | 0.047 | 0.39 |
| 10 | 2.57 | 1.91 | 0.26 |
| 11 | 10.18 | 6.1 | 0.40 |
| 12 | 9.46 | 6.71 | 0.29 |
| 13 | 7.82 | 6.59 | 0.16 |
| 14 | 6.65 | 10 | 0.33 |
| 15 | 9.91 | 8.09 | 0.18 |
| 16 | 5.39 | 3.34 | 0.38 |
| 17 | 9.58 | 7.21 | 0.25 |
| 18 | 7.1 | 6.95 | 0.02 |
| 19 | 2.86 | 4.45 | 0.36 |
| 20 | 0.19 | 0.34 | 0.44 |
| Training Results | ||||||
|---|---|---|---|---|---|---|
| Model | RMSE (Validation) | R-Squared (Validation) | MSE (Validation) | MAE (Validation) | Prediction Speed (obs/s) | Training Time (s) |
| Ensemble | 1.253 | 0.92 | 1.569 | 0.695 | 590 | 4.397 |
| Fine Tree | 1.378 | 0.90 | 1.899 | 0.671 | 3000 | 7.194 |
| SVM | 1.669 | 0.85 | 2.789 | 0.852 | 2100 | 1.742 |
| GPR | 1.659 | 0.85 | 2.751 | 0.814 | 1500 | 6.263 |
| ANN | 2.328 | 0.71 | 5.42 | 1.046 | 2100 | 19.20 |
| Test Results | ||||
|---|---|---|---|---|
| Model | RMSE (Test) | R-Squared (Test) | MSE (Test) | MAE (Test) |
| Ensemble | 1.274 | 0.93 | 1.622 | 0.779 |
| Fine Tree | 0.986 | 0.96 | 0.973 | 0.539 |
| SVM | 0.79 | 0.97 | 0.624 | 0.508 |
| GPR | 0.998 | 0.96 | 0.995 | 0.644 |
| ANN | 1.256 | 0.94 | 1.577 | 0.631 |
| MRMR | F-Test | RReliefF | |
|---|---|---|---|
| totalTime | 0.821 | 53.90 | 0.057 |
| autoTurnDist | 0.547 | 42.93 | 0.04 |
| autoWorkDist | 0.421 | 67.76 | 0.061 |
| traveledDist | 0.342 | 85.04 | 0.065 |
| Training Results (Three Features) | |||||||
|---|---|---|---|---|---|---|---|
| Ranking Features Method | Best Predictive Model | RMSE (Validation) | R-Squared (Validation) | MSE (Validation) | MAE (Validation) | Prediction Speed (obs/s) | Training Time (s) |
| MRMR | Ensemble | 1.589 | 0.87 | 2.528 | 0.884 | 860 | 5.688 |
| F-Test | Fine Tree | 1.379 | 0.90 | 1.901 | 0.702 | 5300 | 2.75 |
| RReliefF | GPR | 1.364 | 0.90 | 1.861 | 0.657 | 2700 | 9.457 |
| Test Results (Three Features) | |||||
|---|---|---|---|---|---|
| Ranking Features Method | Best Predictive Model | RMSE (Test) | R-Squared (Test) | MSE (Test) | MAE (Test) |
| MRMR | Ensemble | 0.806 | 0.96 | 0.65 | 0.519 |
| F-Test | Fine Tree | 1.772 | 0.82 | 3.141 | 0.937 |
| RReliefF | GPR | 0.868 | 0.96 | 0.753 | 0.51 |
| Training Results (Two Features) | |||||||
|---|---|---|---|---|---|---|---|
| Ranking Features Method | Best Predictive Model | RMSE (Validation) | R-Squared (Validation) | MSE (Validation) | MAE (Validation) | Prediction Speed (obs/s) | Training Time (s) |
| MRMR | Fine Tree | 1.396 | 0.90 | 1.949 | 0.74 | 6800 | 6.639 |
| F-Test | SVM | 1.457 | 0.89 | 2.122 | 0.775 | 5000 | 0.662 |
| RReliefF | GPR | 1.38 | 0.90 | 1.905 | 0.783 | 2800 | 5.92 |
| Test Results (Two Features) | |||||
|---|---|---|---|---|---|
| Ranking Features Method | Best Predictive Model | RMSE (Test) | R-Squared (Test) | MSE (Test) | MAE (Test) |
| MRMR | Fine Tree | 1.268 | 0.92 | 1.608 | 0.901 |
| F-Test | SVM | 1.325 | 0.87 | 1.755 | 0.904 |
| RReliefF | GPR | 0.678 | 0.98 | 0.459 | 0.473 |
| Training Results (One Feature) | |||||||
|---|---|---|---|---|---|---|---|
| Ranking Features Method | Best Predictive Model | RMSE (Validation) | R-Squared (Validation) | MSE (Validation) | MAE (Validation) | Prediction Speed (obs/s) | Training Time (s) |
| MRMR | Ensemble | 1.274 | 0.91 | 1.622 | 0.693 | 1200 | 7.456 |
| F-Test | GPR | 1.169 | 0.93 | 1.368 | 0.762 | 3900 | 3.456 |
| RReliefF | GPR | 1.019 | 0.95 | 1.039 | 0.662 | 4500 | 2.639 |
| Test Results (One Feature) | |||||
|---|---|---|---|---|---|
| Ranking Features Method | Best Predictive Model | RMSE (Test) | R-Squared (Test) | MSE (Test) | MAE (Test) |
| MRMR | Ensemble | 1.298 | 0.95 | 1.685 | 0.929 |
| F-Test | GPR | 0.474 | 0.97 | 0.224 | 0.375 |
| RReliefF | GPR | 0.614 | 0.98 | 0.377 | 0.447 |
| Training Results | ||||||
|---|---|---|---|---|---|---|
| Model | RMSE (Validation) | R-Squared (Validation) | MSE (Validation) | MAE (Validation) | Prediction Speed (obs/s) | Training Time (s) |
| Tree | 1.271 | 0.91 | 1.616 | 0.732 | 1600 | 32.76 |
| SVM | 1.704 | 0.84 | 2.903 | 0.898 | 2100 | 61.94 |
| GPR | 1.107 | 0.93 | 1.224 | 0.583 | 1800 | 115.7 |
| Ensemble | 1.391 | 0.89 | 1.936 | 0.744 | 790 | 874 |
| ANN | 1.97 | 0.79 | 3.882 | 1.021 | 3300 | 473.7 |
| Test Results | ||||
|---|---|---|---|---|
| Model | RMSE (Test) | R-Squared (Test) | MSE (Test) | MAE (Test) |
| Tree | 0.308 | 1.00 | 0.095 | 0.242 |
| SVM | 1.819 | 0.88 | 3.308 | 0.961 |
| GPR | 0.277 | 1.00 | 0.077 | 0.216 |
| ANOVA Table | |||||
|---|---|---|---|---|---|
| Source | SS | df | MS | F | Prob > F |
| Columns | 3.14 | 4 | 0.784 | 0.04 | 0.996 |
| Error | 7559.93 | 415 | 18.217 | ||
| Total | 7563.07 | 419 | |||
| Sensitivity Analysis | ||||
|---|---|---|---|---|
| Input Parameters | Observed | 1 | 2 | 3 |
| Automatic working distance (m) | 4770.7 | 8804.6 | 4770.7 | 8804.6 |
| Automatic turning distance (m) | 241.7 | 241.7 | 1213.3 | 1213.3 |
| Traveled distance (m) | 5012.5 | 9046.3 | 5984 | 10017.9 |
| Total time (s) | 6104 | 7005.6 | 6802.5 | 9704.5 |
| Fuel consumption (L) (predicted by 2nd model) | 5.3 | 6.4 | 5.9 | 8.5 |
| Fuel consumption (L) (read) | 5.1 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vahdanjoo, M.; Gislum, R.; Aage Grøn Sørensen, C. Estimating Fuel Consumption of an Agricultural Robot by Applying Machine Learning Techniques during Seeding Operation. AgriEngineering 2024, 6, 754-772. https://doi.org/10.3390/agriengineering6010043
Vahdanjoo M, Gislum R, Aage Grøn Sørensen C. Estimating Fuel Consumption of an Agricultural Robot by Applying Machine Learning Techniques during Seeding Operation. AgriEngineering. 2024; 6(1):754-772. https://doi.org/10.3390/agriengineering6010043
Chicago/Turabian StyleVahdanjoo, Mahdi, René Gislum, and Claus Aage Grøn Sørensen. 2024. "Estimating Fuel Consumption of an Agricultural Robot by Applying Machine Learning Techniques during Seeding Operation" AgriEngineering 6, no. 1: 754-772. https://doi.org/10.3390/agriengineering6010043