
Intelligent Network Service Optimization in the Context of 5G/NFV
 , , , and
, , , and
Abstract
:1. Introduction
2. Related Work
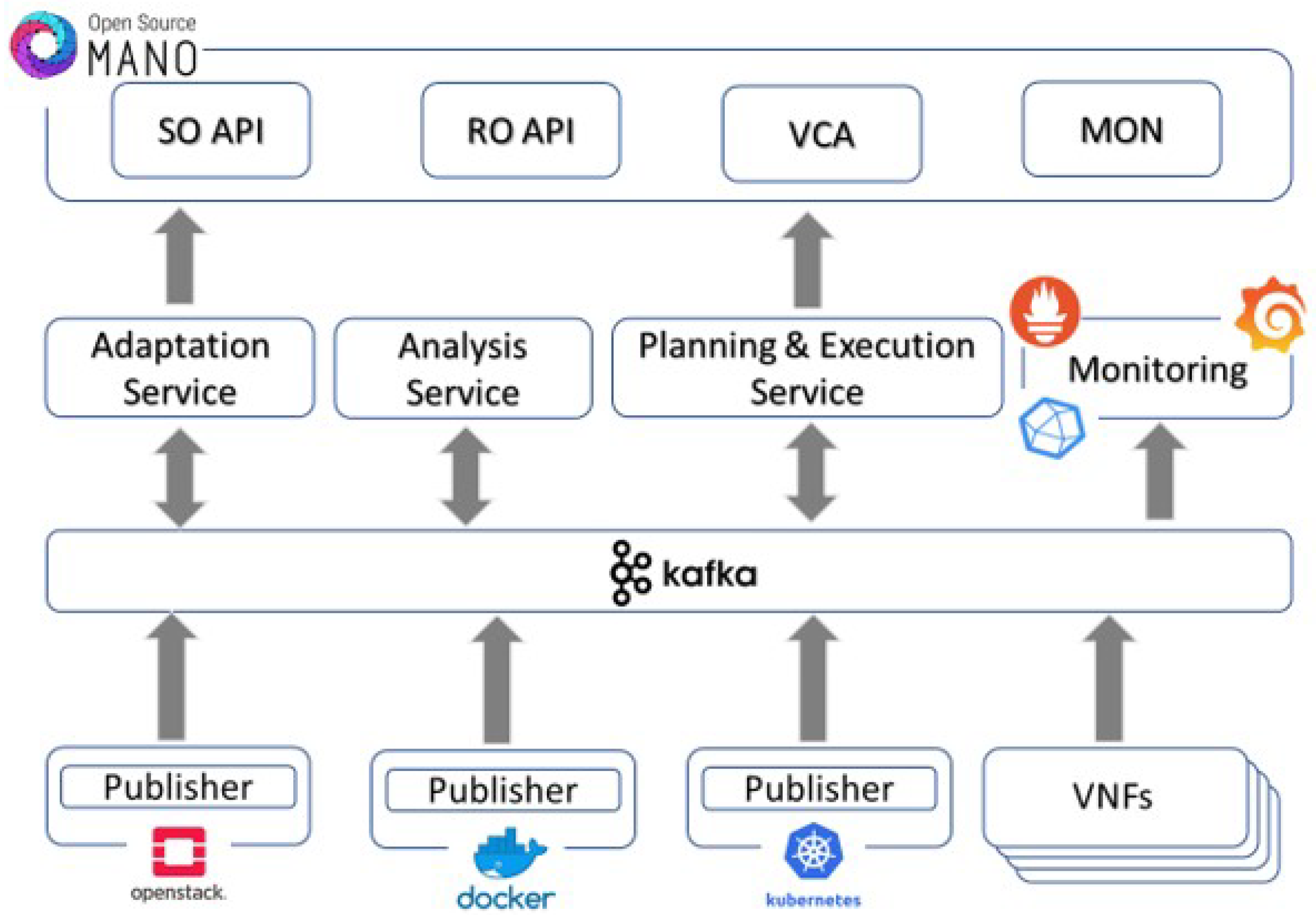
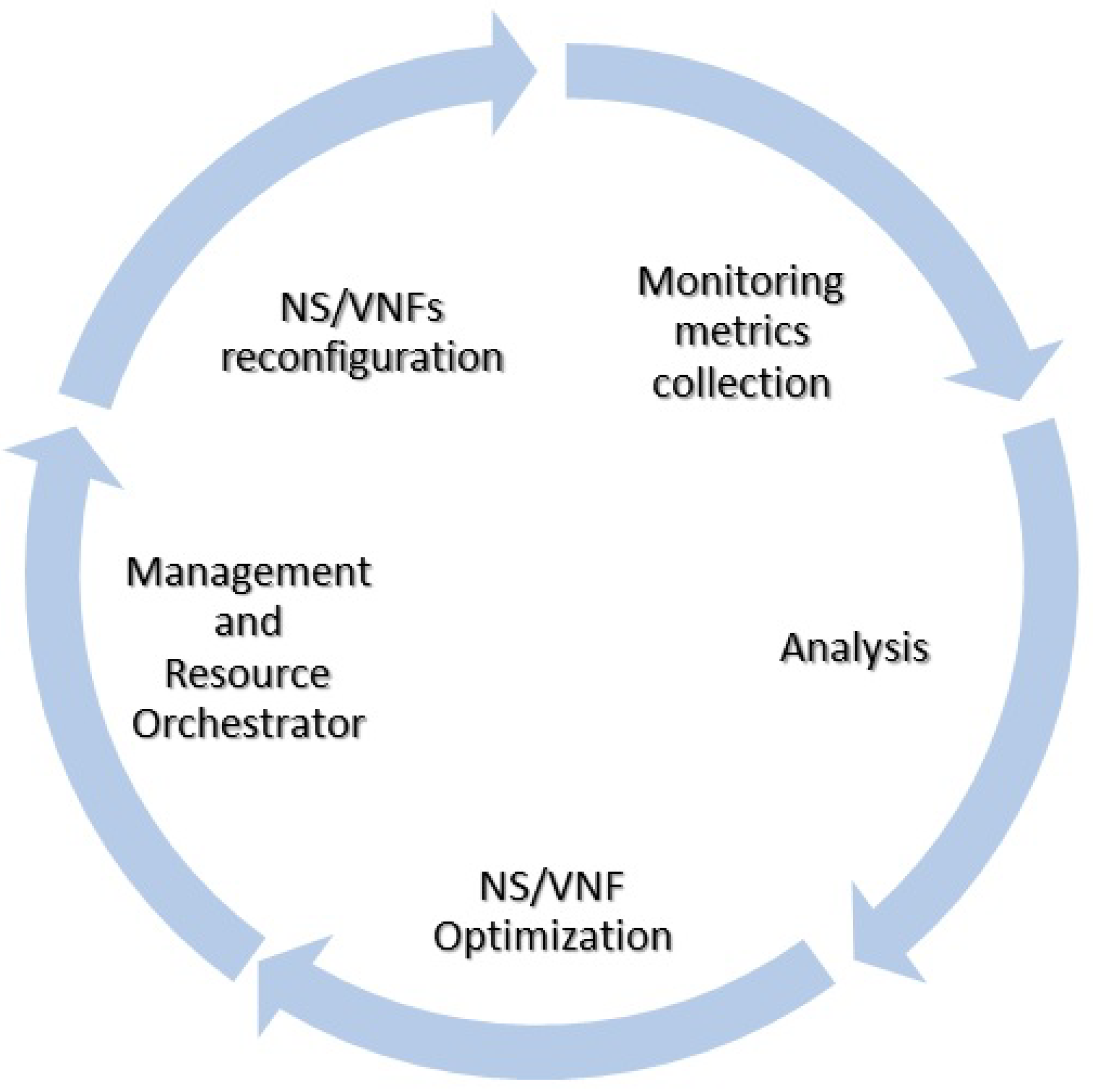
3. MAPE Framework Architecture
3.1. Monitoring and Metrics Acquisition
- (a)
- Various data adaptation and transformation services wishing to push data from monitored environments, enrich the collected metrics, and prepare their proper consumption by other MAPE services.
- (b)
- An InfluxDB database that keeps records of collected metrics, either raw or processed, for future reference by external services.
- (c)
- ML-based processing and planning, with the goal of optimizing the performance of the running services based on QoS criteria.
3.2. Analysis and Optimization Services
Quality of Experience
4. Methodology of MAPE’s Analysis Service
4.1. Supervised Learning: A Deep Learning Approach
4.2. Reinforcement Learning: State-Space Modelling and Rewards
- Mean Opinion Score: This reward component is defined as the percentage increment or decrement in the MOS, following the execution of a certain optimization action. If the MOS value is reduced after an action, then the reward is negative, otherwise it is positive. Therefore, assuming are the computed MOS values before and after an action’s execution, respectively, the reward is defined as:
- Bit Rate and Frame Rate: This reward component depends on the percentage increment or decrement in certain parameters, specifically the video transmission’s bit rate and frame rate. This reward is computed as a mean of the increment or decrement in both types of measurements. Let be the values of bit rate and frame rate before and after the execution of an optimization action. Then, this reward component is defined as:
- Number of VNF Instances: This reward component depends on the number VNFs that are running per NS, also considering the ones that might occur after a scale-out or scale-in operation. A positive reward is produced in cases where the number of running VNFs is decreased, and a negative reward is produced if the number of running VNFs increases. Let be the number of VNFs before and after an action’s execution. Then, this reward component is defined as:
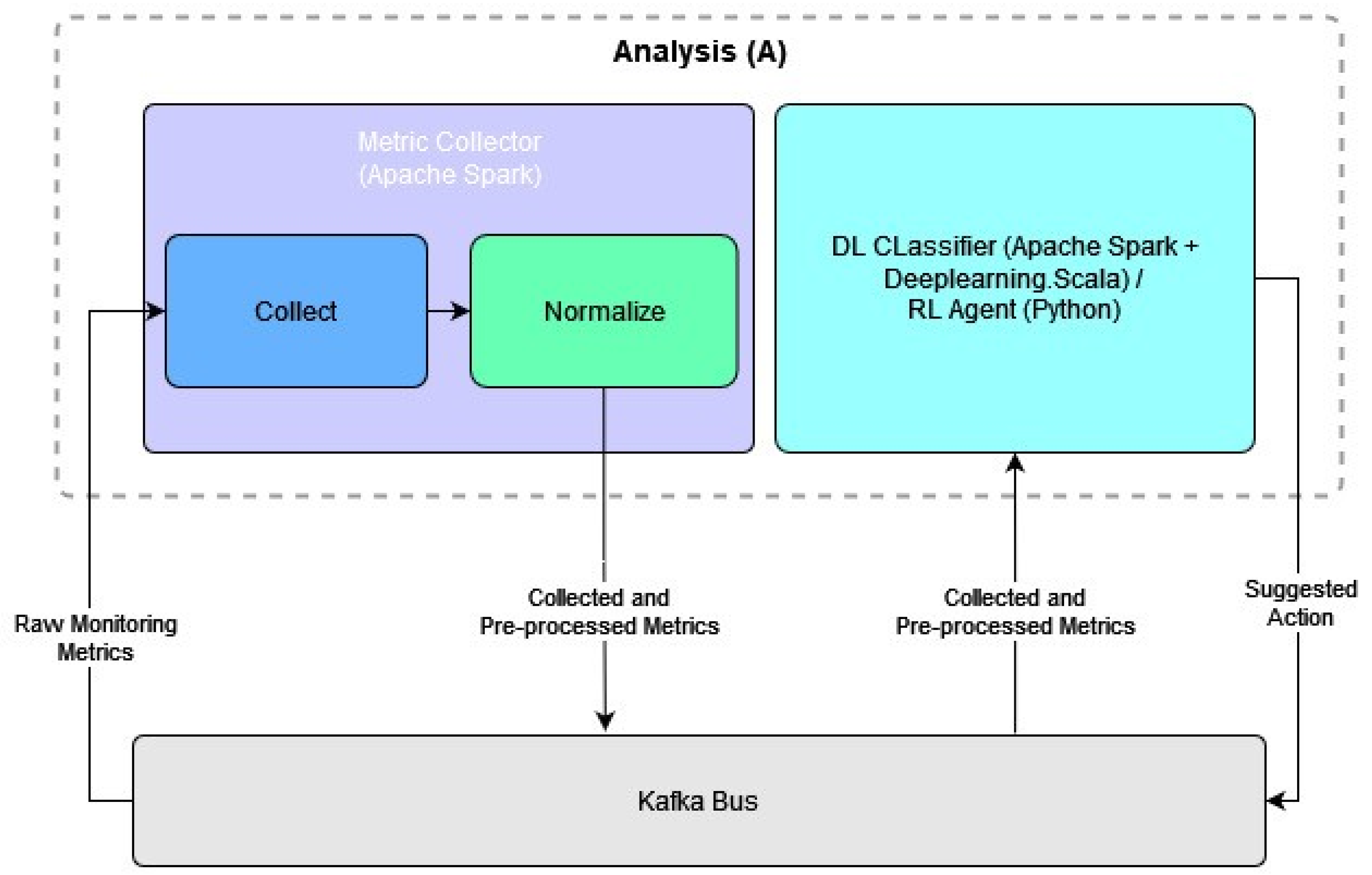
4.3. Analysis Flow and Components
4.3.1. Metric Collector
4.3.2. DL Classifier
4.3.3. RL Agent
4.4. Employed Metrics
4.5. Opinion Model for Video Content Streaming
4.6. Optimization Actions
4.7. Collection of Training Datasets
4.8. Planning and Execution
5. Experimental Results
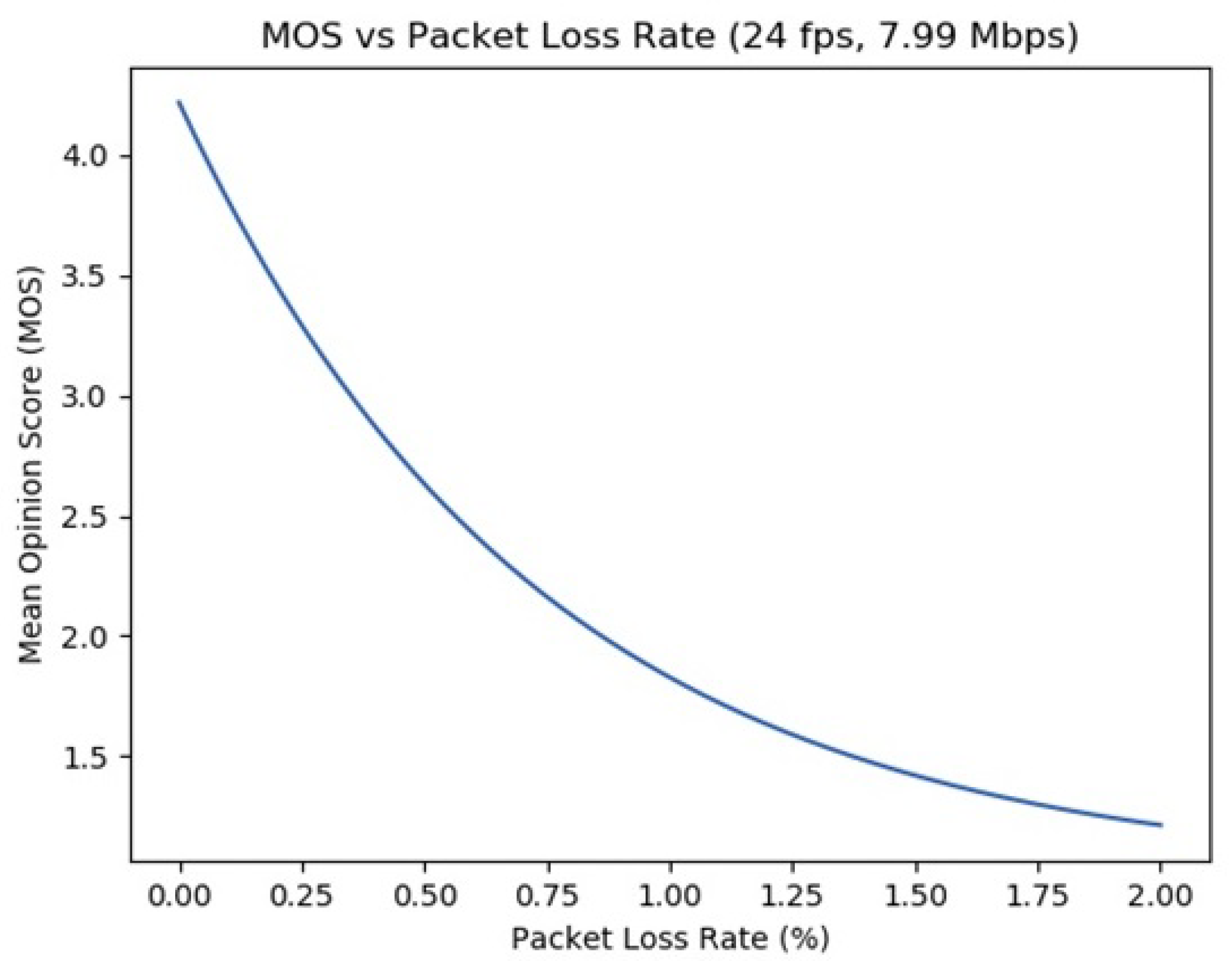
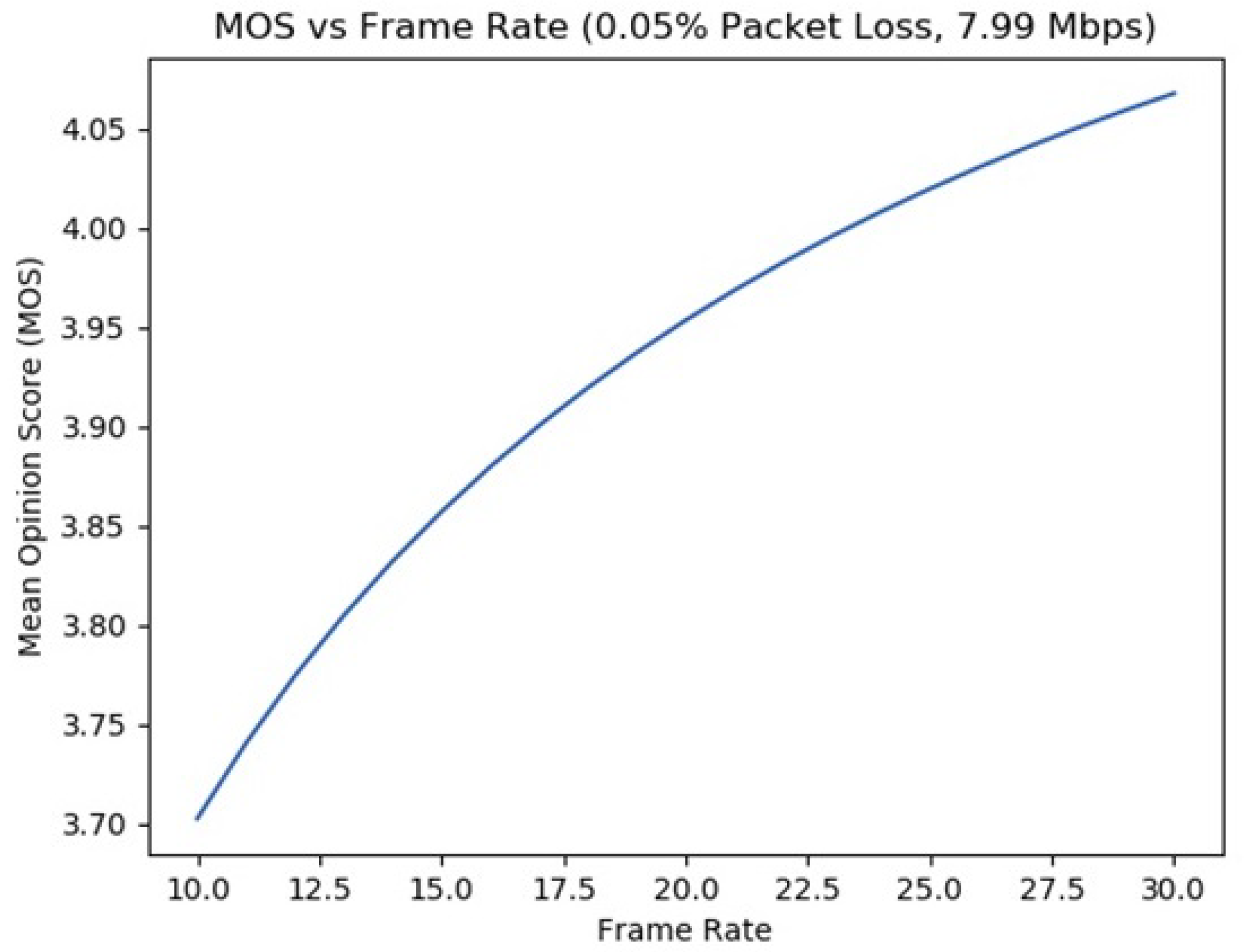
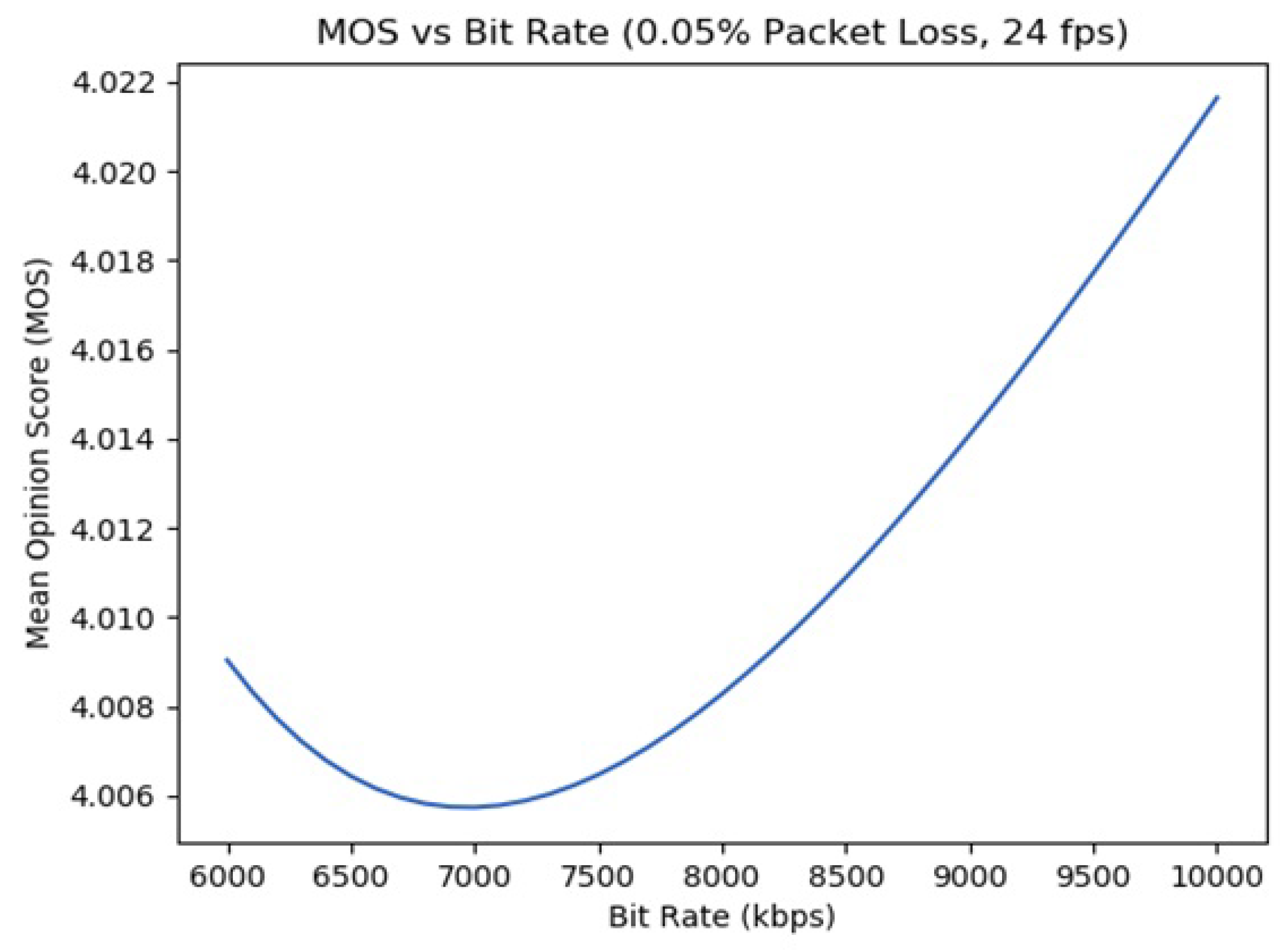
5.1. QoE: Experimenting with Frame Rate, Bit Rate, and Packet Loss
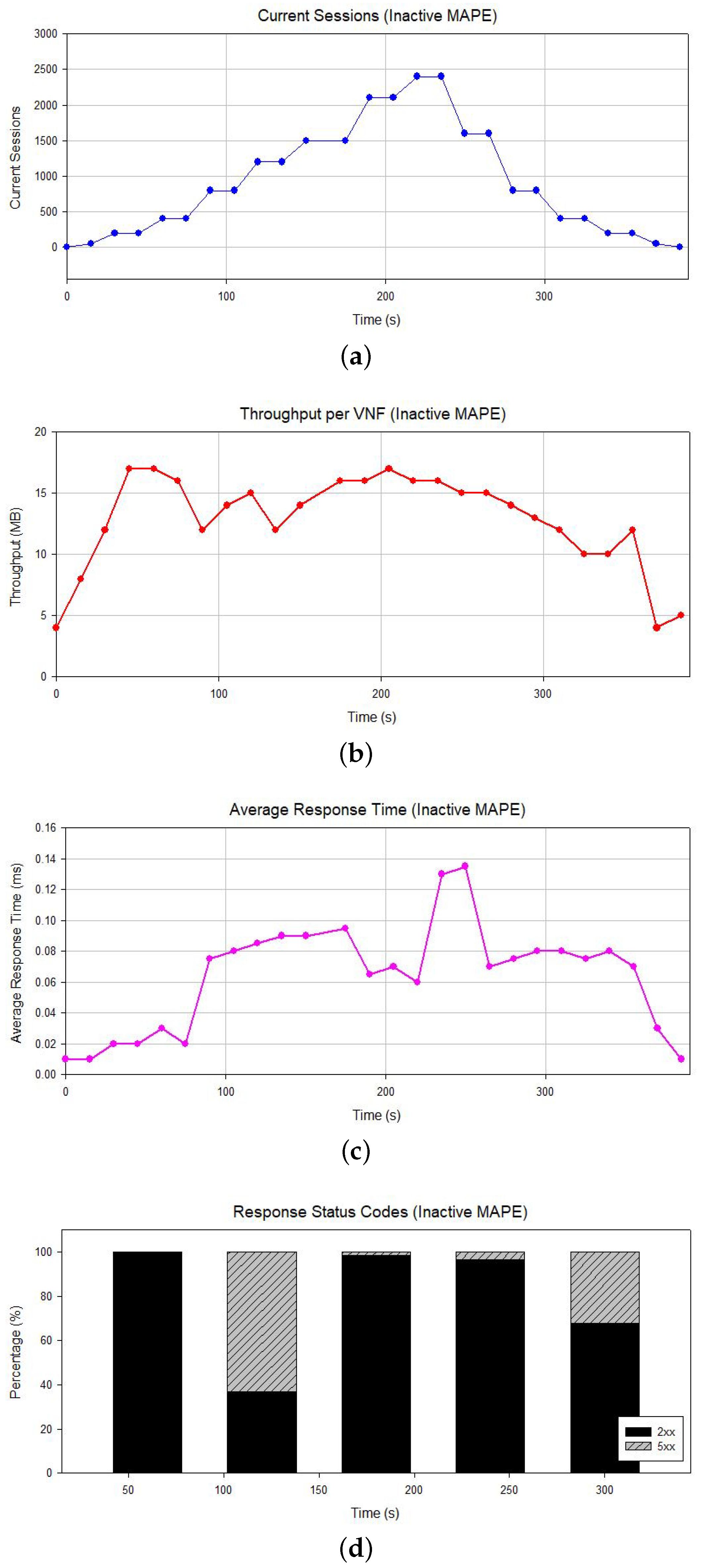
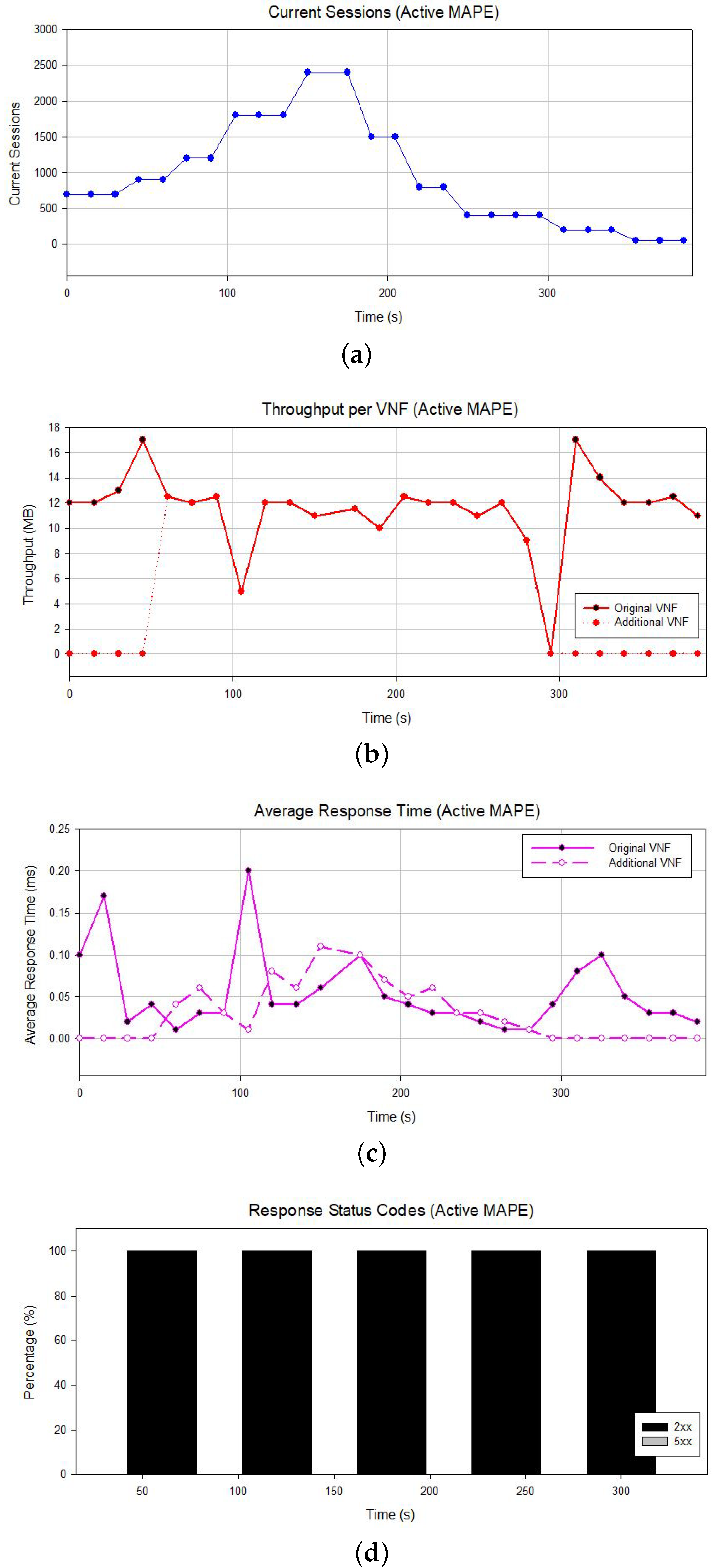
5.2. Statistics for Inactive and Active MAPE
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AD | Automatic Differentiation |
| AS | Analysis Service |
| AST | Abstract Syntax Trees |
| CNA | Cloud Native Applications |
| CNC | Cloud Native Computing |
| CNI | Cloud Native Infrastructure |
| DL | Deep Learning |
| DLS | DeepLearning.scala |
| ES | Execution Service |
| FFNN | Feed-Forward Neural Network |
| GDPR | General Data Protection Regulation |
| IoT | Internet of Things |
| ITU | International Telecommunication Union |
| MANO | Management and Orchestration |
| MAPE | Monitoring Analysis Planning Execution |
| MC | Metric Collector |
| MDP | Markov Decision Processes |
| ML | Machine Learning |
| MOS | Mean Opinion Score |
| MS | Monitoring Service |
| NBI | Northbound Interface |
| NFV | Network Function Virtualization |
| NFVI | Network Function Virtualization Infrastructure |
| NFVO | NFV Orchestrator |
| NGN | Next-Generation Networks |
| NMS | Network Management Systems |
| NS | Network Services |
| OE | Optimization Engine |
| OSM | Open-Source MANO |
| PS | Prioritized Sweeping |
| QoE | Quality of Experience |
| QoS | Quality of Service |
| RL | Reinforcement Learning |
| SDN | Software-Defined Networks |
| SL | Supervised Learning |
| UL | Unsupervised Learning |
| UX | User Experience |
| VLM | Virtual Link Mapping |
| VM | Virtual Machines |
| VN | Virtual Networks |
| VNE | Virtual Network Embedding |
| VNF | Virtual Network Functions |
| VNM | Virtual Node Mapping |
| VNR | Virtual Network Requests |
| Mathematical Symbols | |
| Video bit rate | |
| Degree of video robustness due to frame rate | |
| Degree of video quality robustness due to packet loss | |
| Frame bit rate | |
| Mean opinion score | |
| n | Number of running VNFs |
| Optimal frame rate | |
| Packet loss rate | |
| Video quality | |
References
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef]
- Dos Anjos, J.C.; Gross, J.L.; Matteussi, K.J.; González, G.V.; Leithardt, V.R.; Geyer, C.F. An algorithm to minimize energy consumption and elapsed time for IoT workloads in a hybrid architecture. Sensors 2021, 21, 2914. [Google Scholar] [CrossRef]
- Garrison, J.; Nova, K. Cloud Native Infrastructure: Patterns for Scalable Infrastructure and Applications in a Dynamic Environment; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Balalaie, A.; Heydarnoori, A.; Jamshidi, P. Microservices architecture enables devops: Migration to a cloud-native architecture. IEEE Softw. 2016, 33, 42–52. [Google Scholar] [CrossRef]
- Gannon, D.; Barga, R.; Sundaresan, N. Cloud-native applications. IEEE Cloud Comput. 2017, 4, 16–21. [Google Scholar] [CrossRef]
- Zafeiropoulos, A.; Fotopoulou, E.; Peuster, M.; Schneider, S.; Gouvas, P.; Behnke, D.; Müller, M.; Bök, P.B.; Trakadas, P.; Karkazis, P. Benchmarking and Profiling 5G Verticals’ Applications: An Industrial IoT Use Case. In Proceedings of the 2020 6th IEEE Conference on Network Softwarization (NetSoft), Ghent, Belgium, 29 June–3 July 2020; pp. 310–318. [Google Scholar] [CrossRef]
- Soenen, T.; Van Rossem, S.; Tavernier, W.; Vicens, F.; Valocchi, D.; Trakadas, P.; Karkazis, P.; Xilouris, G.; Eardley, P.; Kolometsos, S. Insights from SONATA: Implementing and integrating a microservice-based NFV service platform with a DevOps methodology. In Proceedings of the NOMS 2018-2018 IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Shekhawat, Y.; Piesk, J.; Sprengel, H.; Gómez, I.D.; Vicens, F.; Carrillo, S.C.; Trakadas, P.; Karkazis, P.; Zahariadis, T.; Touloupou, M. Orchestrating Live Immersive Media Services Over Cloud Native Edge Infrastructure. In Proceedings of the 2019 IEEE 2nd 5G World Forum (5GWF), Dresden, Germany, 30 September–2 October 2019; pp. 316–322. [Google Scholar] [CrossRef]
- Merkel, D. Docker: Lightweight linux containers for consistent development and deployment. Linux J. 2014, 2014, 2. [Google Scholar]
- Bernstein, D. Containers and cloud: From lxc to docker to kubernetes. IEEE Cloud Comput. 2014, 1, 81–84. [Google Scholar] [CrossRef]
- Yi, B.; Wang, X.; Li, K.; Huang, M. A comprehensive survey of network function virtualization. Comput. Netw. 2018, 133, 212–262. [Google Scholar] [CrossRef]
- Trakadas, P.; Karkazis, P.; Leligou, H.C.; Zahariadis, T.; Tavernier, W.; Soenen, T.; Van Rossem, S.; Miguel Contreras Murillo, L. Scalable monitoring for multiple virtualized infrastructures for 5G services. In Proceedings of the International Symposium on Advances in Software Defined Networking and Network Functions Virtualization (SoftNetworking 2018), Athens, Greece, 22–26 April 2018; pp. 1–4. [Google Scholar]
- Ericsson, T.L. A Guide to 5G Network Security. 2021. Available online: https://www.ericsson.com/en/security/a-guide-to-5g-network-security (accessed on 20 June 2022).
- CableLabs. A Comparative Introduction to 4G and 5G Authentication. 2021. Available online: https://www.cablelabs.com/insights/a-comparative-introduction-to-4g-and-5g-authentication (accessed on 20 June 2022).
- Pereira, F.; Crocker, P.; Leithardt, V.R. PADRES: Tool for PrivAcy, Data REgulation and Security. SoftwareX 2022, 17, 100895. [Google Scholar] [CrossRef]
- Computing Autonomic. An architectural blueprint for autonomic computing. In IBM White Paper; IBM: Armonk, NY, USA, 2006; Volume 31, pp. 1–6. [Google Scholar]
- SONATA MANO Framework. 2021. Available online: https://github.com/sonata-nfv/son-mano-framework/ (accessed on 28 June 2021).
- Garlan, D.; Schmerl, B.; Cheng, S.W. Software Architecture-Based Self-Adaptation. In Software Architecture-Based Self-Adaptation; Springer: Berlin/Heidelberg, Germany, 2009; pp. 31–55. [Google Scholar] [CrossRef]
- Leng, J.; Zhou, M.; Xiao, Y.; Zhang, H.; Liu, Q.; Shen, W.; Su, Q.; Li, L. Digital twins-based remote semi-physical commissioning of flow-type smart manufacturing systems. J. Clean. Prod. 2021, 306, 127278. [Google Scholar] [CrossRef]
- Leng, J.; Yan, D.; Liu, Q.; Zhang, H.; Zhao, G.; Wei, L.; Zhang, D.; Yu, A.; Chen, X. Digital twin-driven joint optimisation of packing and storage assignment in large-scale automated high-rise warehouse product-service system. Int. J. Comput. Integr. Manuf. 2021, 34, 783–800. [Google Scholar] [CrossRef]
- Majidha Fathima, K.M. A Survey of the Exemplary Practices in Network Operations and Management. In Data Intelligence and Cognitive Informatics; Jeena Jacob, I., Kolandapalayam Shanmugam, S., Piramuthu, S., Falkowski-Gilski, P., Eds.; Springer: Singapore, 2021; pp. 181–194. [Google Scholar] [CrossRef]
- Luan, Z.; Qian, D.; Zhang, X.; Liu, T.; Chen, H. A Novel Model and Architecture on NMS – Dynamically Constructed Network Management. In Advanced Parallel Processing Technologies; Zhou, X., Xu, M., Jähnichen, S., Cao, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 398–403. [Google Scholar] [CrossRef]
- Tennenhouse, D.L.; Smith, J.M.; Sincoskie, W.D.; Wetherall, D.J.; Minden, G.J. A survey of active network research. IEEE Commun. Mag. 1997, 35, 80–86. [Google Scholar] [CrossRef]
- Fischer, A.; Botero, J.F.; Beck, M.T.; De Meer, H.; Hesselbach, X. Virtual Network Embedding: A Survey. IEEE Commun. Surv. Tutor. 2013, 15, 1888–1906. [Google Scholar] [CrossRef]
- Yu, M.; Yi, Y.; Rexford, J.; Chiang, M. Rethinking virtual network embedding: Substrate support for path splitting and migration. SIGCOMM Comput. Commun. Rev. 2008, 38, 17–29. [Google Scholar] [CrossRef]
- Toutouh, J.; Muñoz, A.; Nesmachnow, S. Evolution Oriented Monitoring Oriented to Security Properties for Cloud Applications. In Proceedings of the ARES 2018: The 13th International Conference on Availability, Reliability and Security, Hamburg, Germany, 27–30 August 2018. [Google Scholar] [CrossRef]
- Waller, A.; Sandy, I.; Power, E.; Aivaloglou, E.; Skianis, C.; Muñoz, A.; Maña, A. Policy based management for security in cloud computing. In Proceedings of the FTRA International Conference on Secure and Trust Computing, Data Management, and Application, Loutraki, Greece, 28–30 June 2011; pp. 130–137. [Google Scholar]
- Cheng, S.W.; Garlan, D. Handling uncertainty in autonomic systems. In Proceedings of the 22nd International Conference on Automated Software Engineering (ASE’07), Atlanta, GA, USA, 5 November 2007. [Google Scholar]
- Liu, H.; Ding, S.; Wang, S.; Zhao, G.; Wang, C. Multi-objective Optimization Service Function Chain Placement Algorithm Based on Reinforcement Learning. J. Netw. Syst. Manag. 2022, 30, 1–25. [Google Scholar] [CrossRef]
- Chiu, Y.S.; Yen, L.H.; Wang, T.H.; Tseng, C.C. A Cloud Native Management and Orchestration Framework for 5G End-to-End Network Slicing. Available online: https://people.cs.nctu.edu.tw/~lhyen/files/papers/main_r3.pdf (accessed on 20 June 2022).
- Zhou, H.; Xu, W.; Chen, J.; Wang, W. Evolutionary V2X technologies toward the Internet of vehicles: Challenges and opportunities. Proc. IEEE 2020, 108, 308–323. [Google Scholar] [CrossRef]
- Garg, N. Apache Kafka; Packt Publishing Ltd.: Birmingham, UK, 2013. [Google Scholar]
- InfluxDB. 2021. Available online: https://https://www.influxdata.com/ (accessed on 30 June 2021).
- Sathya, R.; Abraham, A. Comparison of supervised and unsupervised learning algorithms for pattern classification. Int. J. Adv. Res. Artif. Intell. 2013, 2, 34–38. [Google Scholar] [CrossRef]
- Gullapalli, V. A comparison of supervised and reinforcement learning methods on a reinforcement learning task. In Proceedings of the 1991 IEEE international Symposium on Intelligent Control, Arlington, VA, USA, 13–15 August 1991; pp. 394–399. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1. [Google Scholar]
- Apache Spark. 2021. Available online: https://spark.apache.org/ (accessed on 30 June 2021).
- ThoughtWorks. DeepLearning.scala. 2021. Available online: https://www.thoughtworks.com/deeplearning-scala (accessed on 18 June 2021).
- Puterman, M.L. Markov decision processes. Handb. Oper. Res. Manag. Sci. 1990, 2, 331–434. [Google Scholar]
- Barrett, E.; Howley, E.; Duggan, J. Applying reinforcement learning towards automating resource allocation and application scalability in the cloud. Concurr. Comput. Pract. Exp. 2013, 25, 1656–1674. [Google Scholar] [CrossRef]
- Werbos, P.J. Backpropagation through time: What it does and how to do it. Proc. IEEE 1990, 78, 1550–1560. [Google Scholar] [CrossRef]
- Baydin, A.G.; Pearlmutter, B.A.; Radul, A.A.; Siskind, J.M. Automatic differentiation in machine learning: A survey. J. Mach. Learn. Res. 2018, 18, 1–43. [Google Scholar]
- Baxter, I.D.; Yahin, A.; Moura, L.; Sant’Anna, M.; Bier, L. Clone detection using abstract syntax trees. In Proceedings of the International Conference on Software Maintenance (Cat. No. 98CB36272), Bethesda, MD, USA, 20 November 1998; pp. 368–377. [Google Scholar] [CrossRef]
- ThoughtWorks. Monadic Deep Learning. 2021. Available online: https://deeplearning.thoughtworks.school/assets/paper.pdf (accessed on 30 June 2021).
- Moore, A.W.; Atkeson, C.G. Prioritized sweeping: Reinforcement learning with less data and less time. Mach. Learn. 1993, 13, 103–130. [Google Scholar] [CrossRef]
- Matignon, L.; Laurent, G.J.; Le Fort-Piat, N. Reward function and initial values: Better choices for accelerated goal-directed reinforcement learning. In Proceedings of the International Conference on Artificial Neural Networks, Athens, Greece, 10–14 September 2006; pp. 840–849. [Google Scholar] [CrossRef]
- Prekas, S.; Karkazis, P.; Trakadas, P.; Nikolakakis, V. Comparison of VNE heuristic solutions with similar objective functions. In Proceedings of the 24th Pan-Hellenic Conference on Informatics, Athens, Greece, 20–22 November 2020. [Google Scholar] [CrossRef]
- Collectd. 2022. Available online: https://collectd.org/ (accessed on 30 June 2022).
- ITU-T. Opinion model for video-telephony applications. In ITU-T Recommendation P. 1070; ITU: Geneva, Switzerland, 2007. [Google Scholar]
- Israel, A.; Hoban, A.; Sepúlveda, A.; Salguero, F.; de Blas, G.; Kashalkar, K.; Ceppi, M.; Shuttleworth, M.; Harper, M.; Marchetti, M.; et al. OSM release three. In Open Source MANO, Technical Overview; ETSI: Sophia Antipolis, France, 2017. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
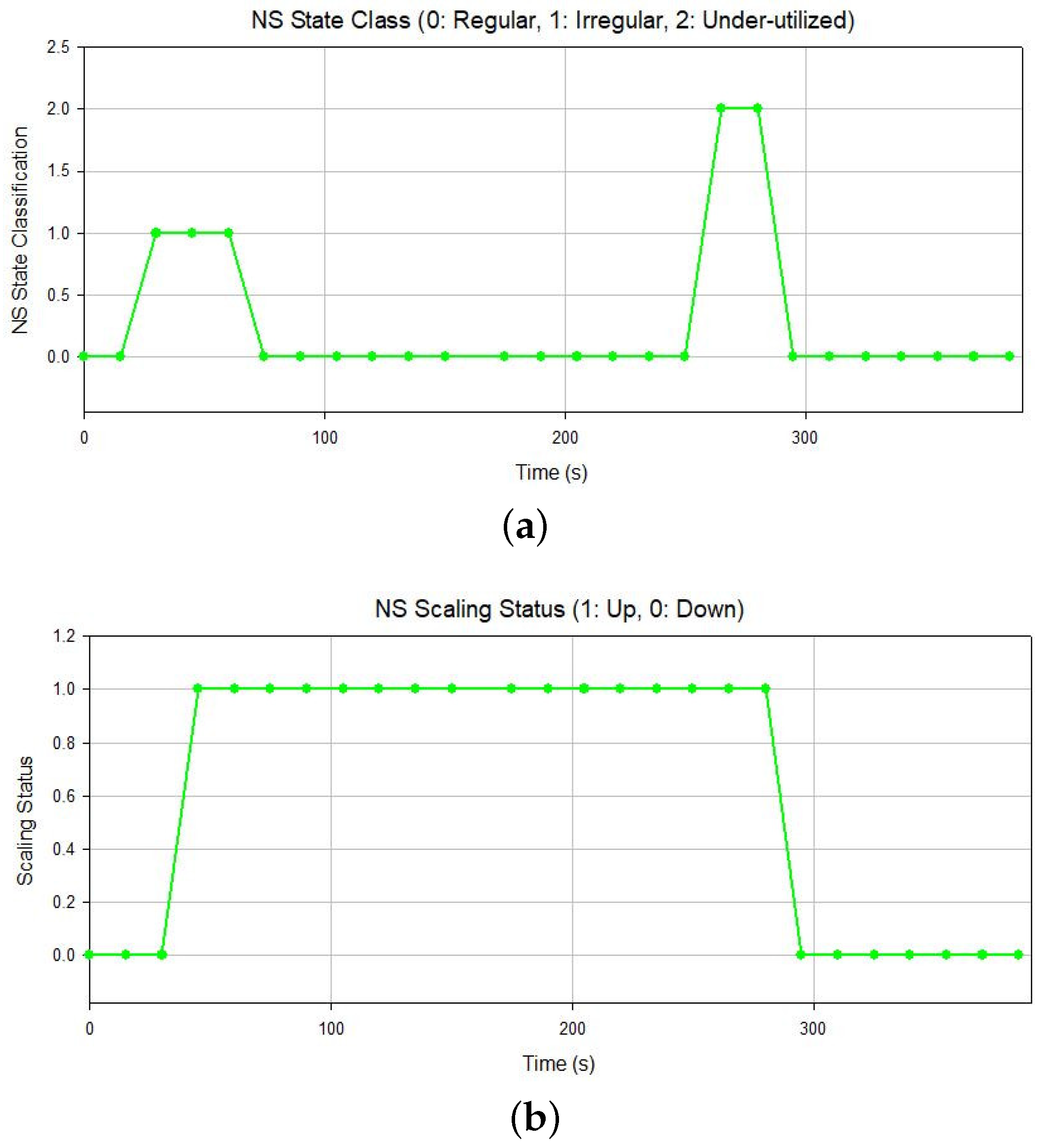
| Class | Description |
|---|---|
| Regular | The system operates as expected, and the deployed resources are adequate. |
| Irregular | The system does not operate as expected, and the deployed resources are inadequate. |
| Underutilized | The system is underutilized, and the deployed resources are more than actually needed. |
| Origin of Metric | Metric Name | Description |
|---|---|---|
| OpenStack NFVI | cpu_util memory_util network.incoming.packets.rate network.outgoing.packets.rate | The CPU’s utilization as a percentage The memory’s utilization as a percentage The rate of incoming packets The rate of outgoing packets |
| Application | frame_rate bit_rate packet_loss | The frame rate of the video transmission The bit rate of the video transmission Network packet loss |
| collectd | aggregation_cpu-average_user aggregation_cpu-average_system interface_if_octets_rx interface_if_octets_tx interface_if_packets_rx interface_if_packets_tx load_load_shorterm load_load_midterm load_load_longterm memory_percent_free memory_percent_used processes_fork_rate processes_ps_state_running processes_ps_state_sleeping tcpconns_tcp_connections_ESTABLISHED | The aggregated user CPU usage The aggregated system CPU usage Count of bytes received on the interface Count of bytes transmitted by the interface Count of packets received on the interface Count of packets transmited by the interface The short-term load The mid-term load The long-term load The percentage of free memory The percentage of used memory The fork rate of processes Count of running processes Count of sleeping processes Number of established TCP connections |
| QoE | mean_opinion_score | The MOS value, denoting the quality of the transmitted content |
| Actions | Description |
|---|---|
| Scaling out | A VNF is added into the existing NS, and the NS is reconfigured to balance the traffic flow |
| Scaling in | A VNF is removed from the existing NS, and the NS is reconfigured to balance the traffic flow through the remaining ones |
| No operation | The NS is in a stable state, and no corrective action needs to be executed |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karkazis, P.A.; Railis, K.; Prekas, S.; Trakadas, P.; Leligou, H.C. Intelligent Network Service Optimization in the Context of 5G/NFV. Signals 2022, 3, 587-610. https://doi.org/10.3390/signals3030036
Karkazis PA, Railis K, Prekas S, Trakadas P, Leligou HC. Intelligent Network Service Optimization in the Context of 5G/NFV. Signals. 2022; 3(3):587-610. https://doi.org/10.3390/signals3030036
Chicago/Turabian StyleKarkazis, Panagiotis A., Konstantinos Railis, Stelios Prekas, Panagiotis Trakadas, and Helen C. Leligou. 2022. "Intelligent Network Service Optimization in the Context of 5G/NFV" Signals 3, no. 3: 587-610. https://doi.org/10.3390/signals3030036