
Advances in Time Series Forecasting Development for Power Systems’ Operation with MLOps


Abstract
:1. Introduction
- i.
- We implement a probabilistic short-term forecasting model based on previous work, which we extend by new scoring and tuning methods,
- ii.
- We compare established forecasting models from research and the TSO’s published forecast from production by means of the sum of time-varying cost for all forecast deviations,
- iii
- We integrate the resulting forecast time series into a day-ahead operations framework and thoroughly discuss the quality of grid state forecasts in the chosen operational environment, and
- iv.
- Finally, we formulate a list of considerations to contrast the model’s scalability, maintainability, and trust, which were in focus during the open-source development of ProLoaF.
2. Methodology
2.1. Statistical Forecast Evaluation Metrics
- -
- MSE: Quantifies the squared distance of the expected value from the target variable , averaged over the prediction horizon from to . This indicator reflects both the bias and variance of the predicted time-series with respect to the observed one. As such, forecasters seek to minimize it. The MSE is strictly positive and takes the squared scale of the observed data.
- -
- RMSE: The positive square root of the MSE describes, in essence, the same information but is more sensitive to outliers, as larger errors have a disproportionately large effect on it. Forecasters seek to minimize it. The RMSE is strictly positive and takes the scale of the observed data.
- -
- MASE: Averages positive and negative forecast errors equally, irrespective of the scale of the observed data. Forecasters seek to minimize it, as values smaller than one indicate that the given method outperforms an in-sample naïve persistence forecast.
- -
- QS: Reflects a balanced calibration of quantile estimates , penalizing deviations proportionally to their amplitude. Forecasters seek to minimize it. Here, q describes the probability that the observation lies within the quantile and F is the cumulative distribution function (CDF) of the observed data [24].
- -
- PICP: Quantifies the unconditional prevalence of observed data that lie within the considered PI. The PI, in turn, indicates a lower and upper limit within which we expect the target variable to be. The is a commonly used significance level. As a high PICP implies a higher reliability, forecasters seek to maximize it. The metric is given in percent.
- -
- MIS: Evaluates the quality of produced prediction intervals on a predefined significance level. The average interval score [23] grows marginally with the sharpness [23]. By adding penalties on any positive or negative observation outside of the PI, the MIS gives a balanced calibration measure over the prediction horizon from to . Thus, it reflects how tightly the predicted distribution covers the actual observation.
2.2. Forecast Implementation
2.2.1. Data Pre-Processing
2.2.2. Auto-ML Model: auto.arima
2.2.3. Auto-ML Model: Facebook Prophet
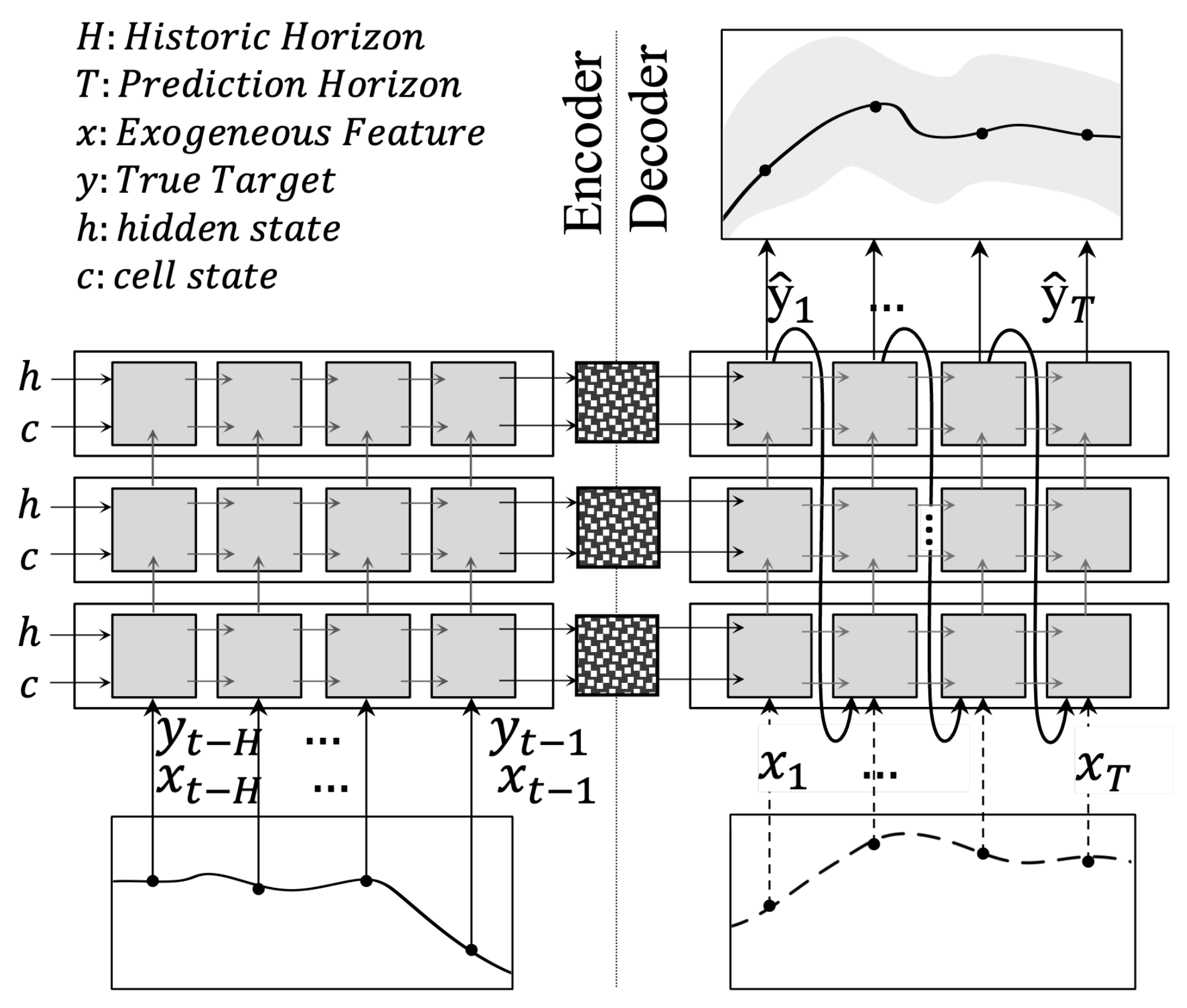
2.2.4. Encoder-Decoder RNN
3. Numerical Results
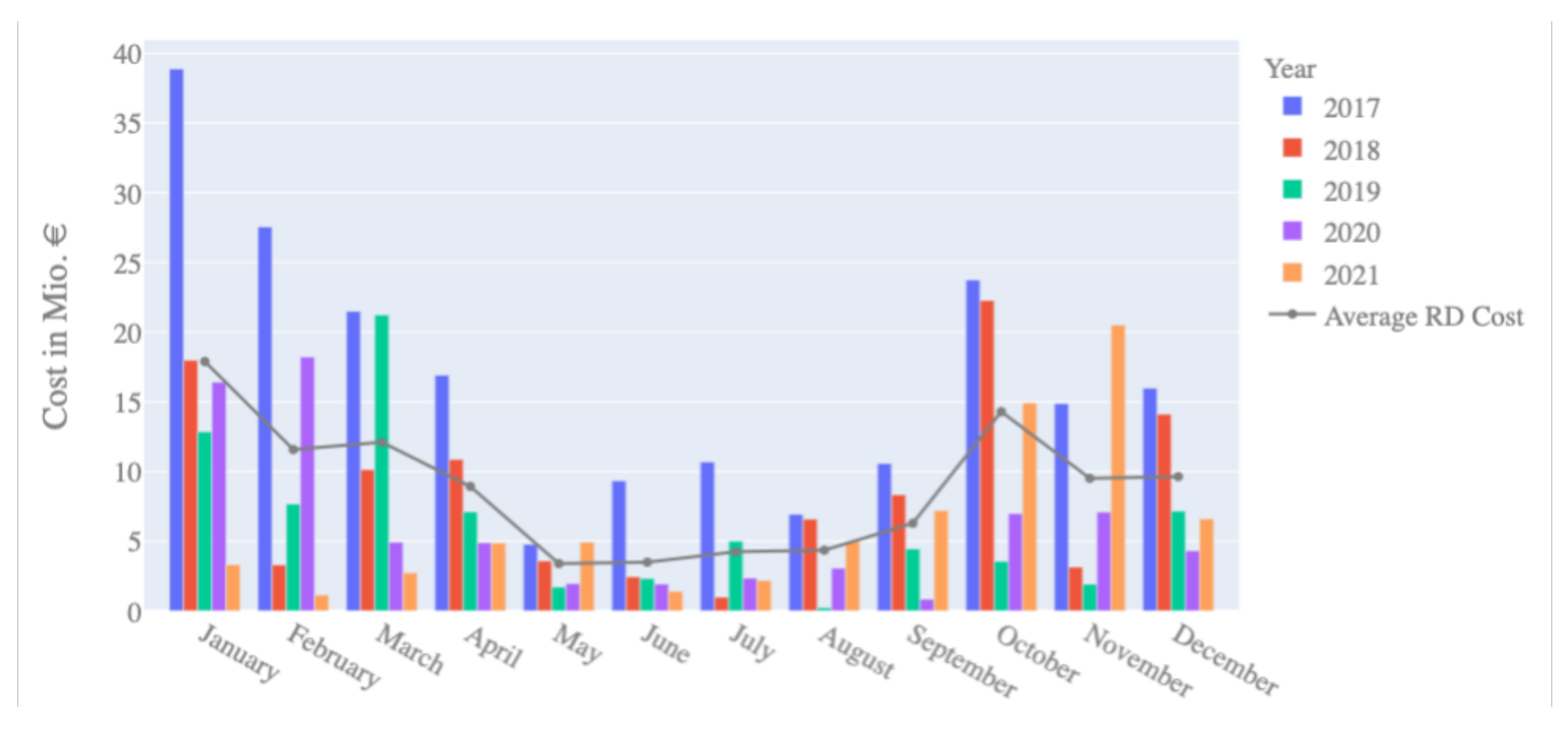
3.1. Operational Planning Context
3.2. Case Study and Data
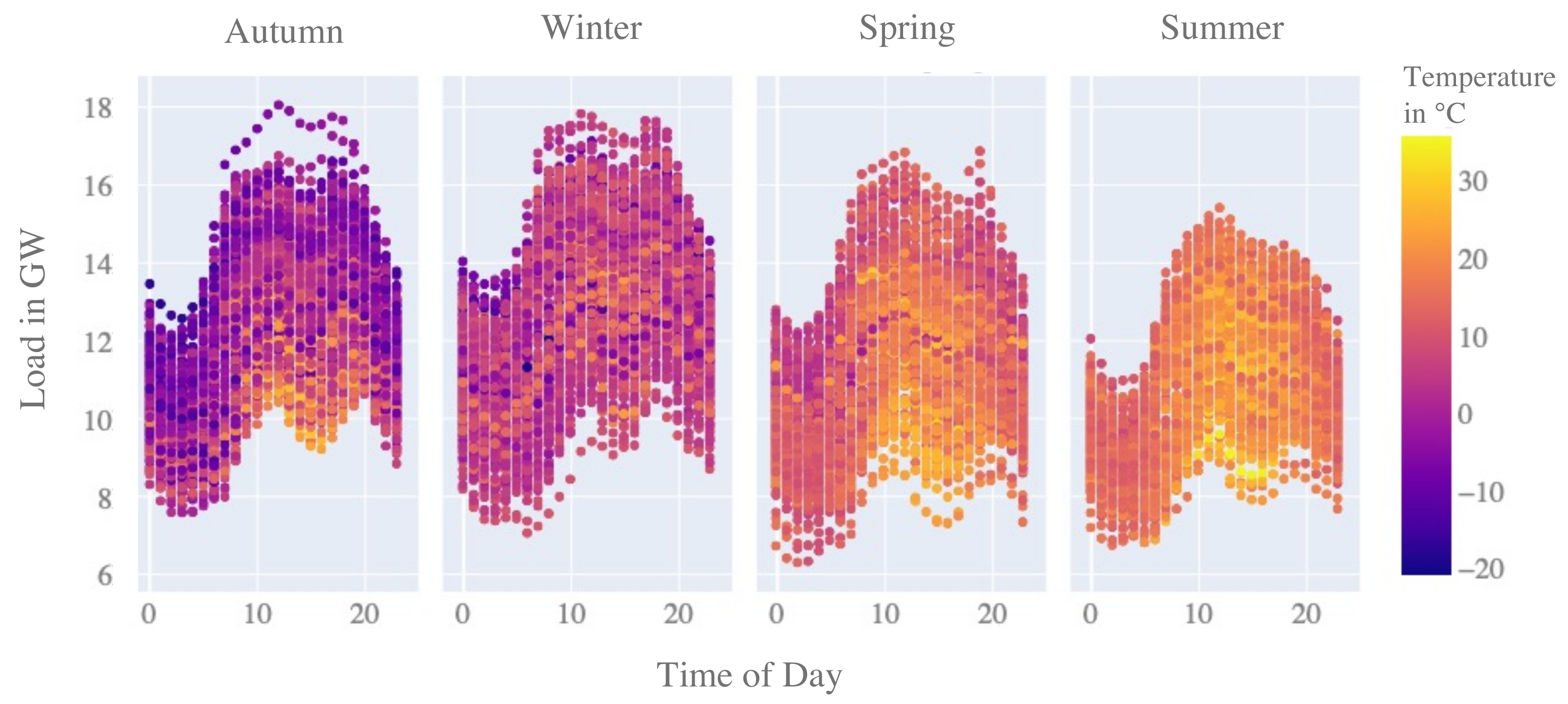
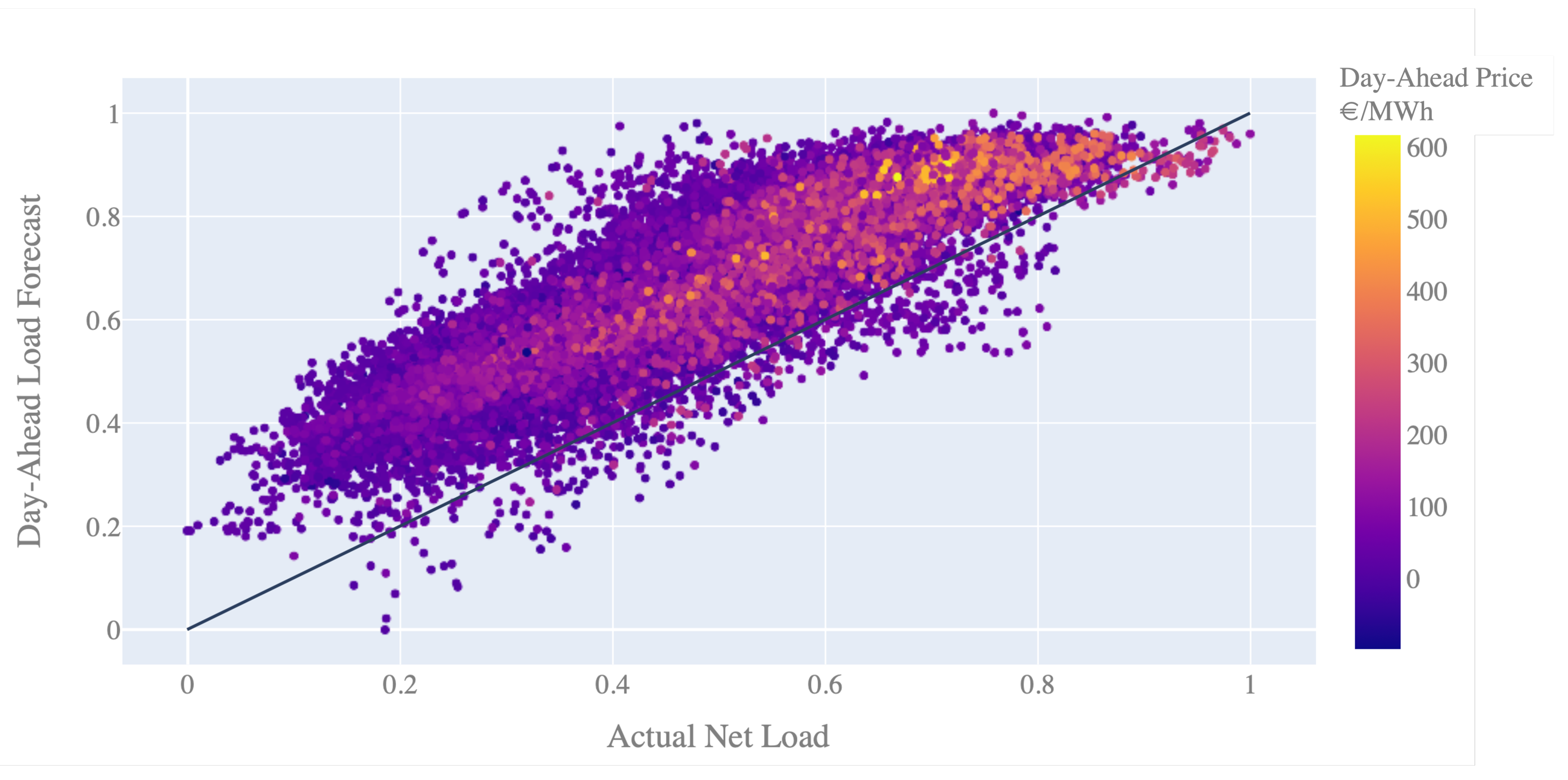
3.3. Correlation Effect
3.4. Data Pre-Processing
- -
- Actual load,
- -
- Actual and forecasted PV and wind energy production,
- -
- Actual local energy generation (conventional Fossil and Other RES),
- -
- Actual temperature,
- -
- Dummy variable for day of the week,
- -
- Dummy variable for hour of day and month of the year (cyclic coding as sine and cosine).
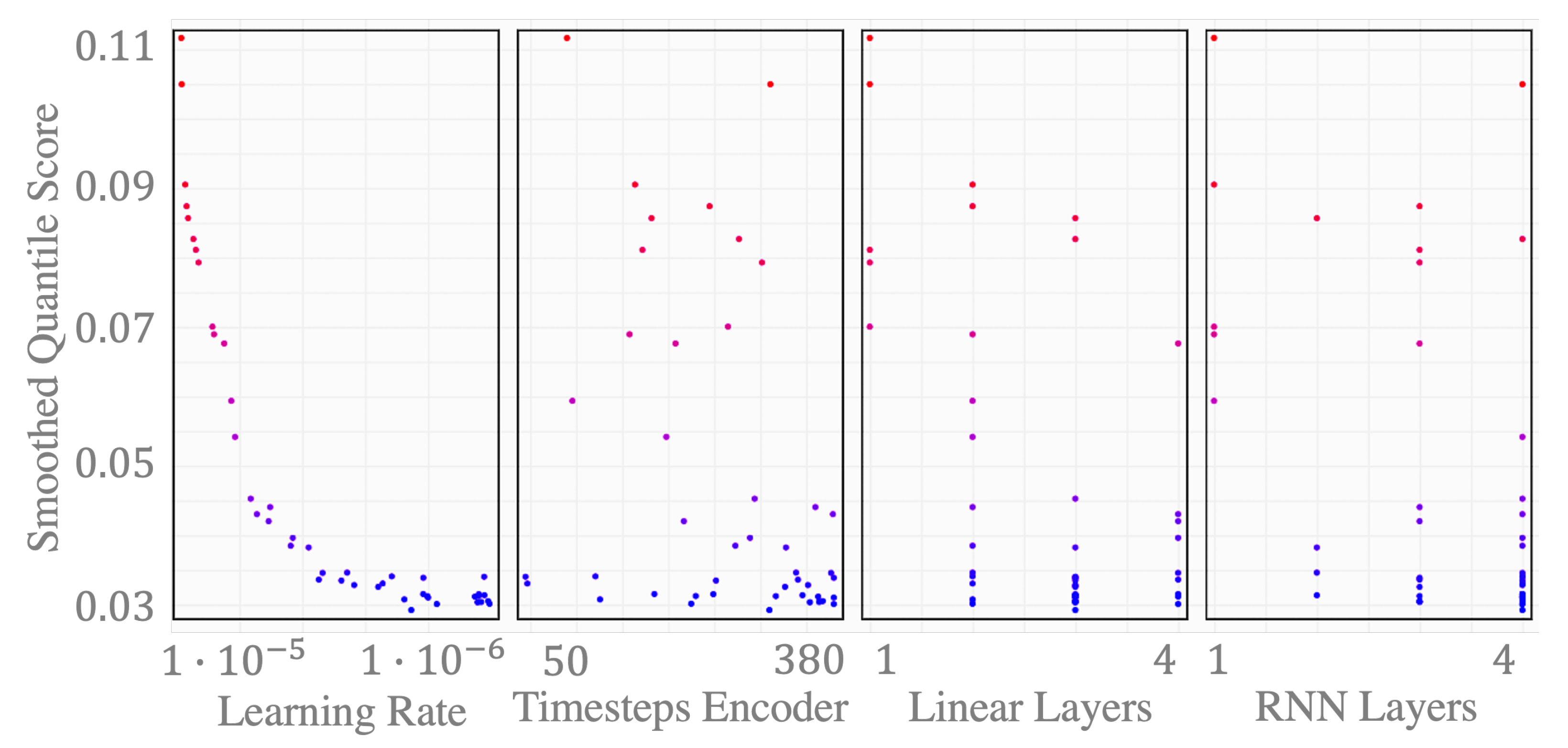
3.5. Model Parameterization
3.6. Computational Resources
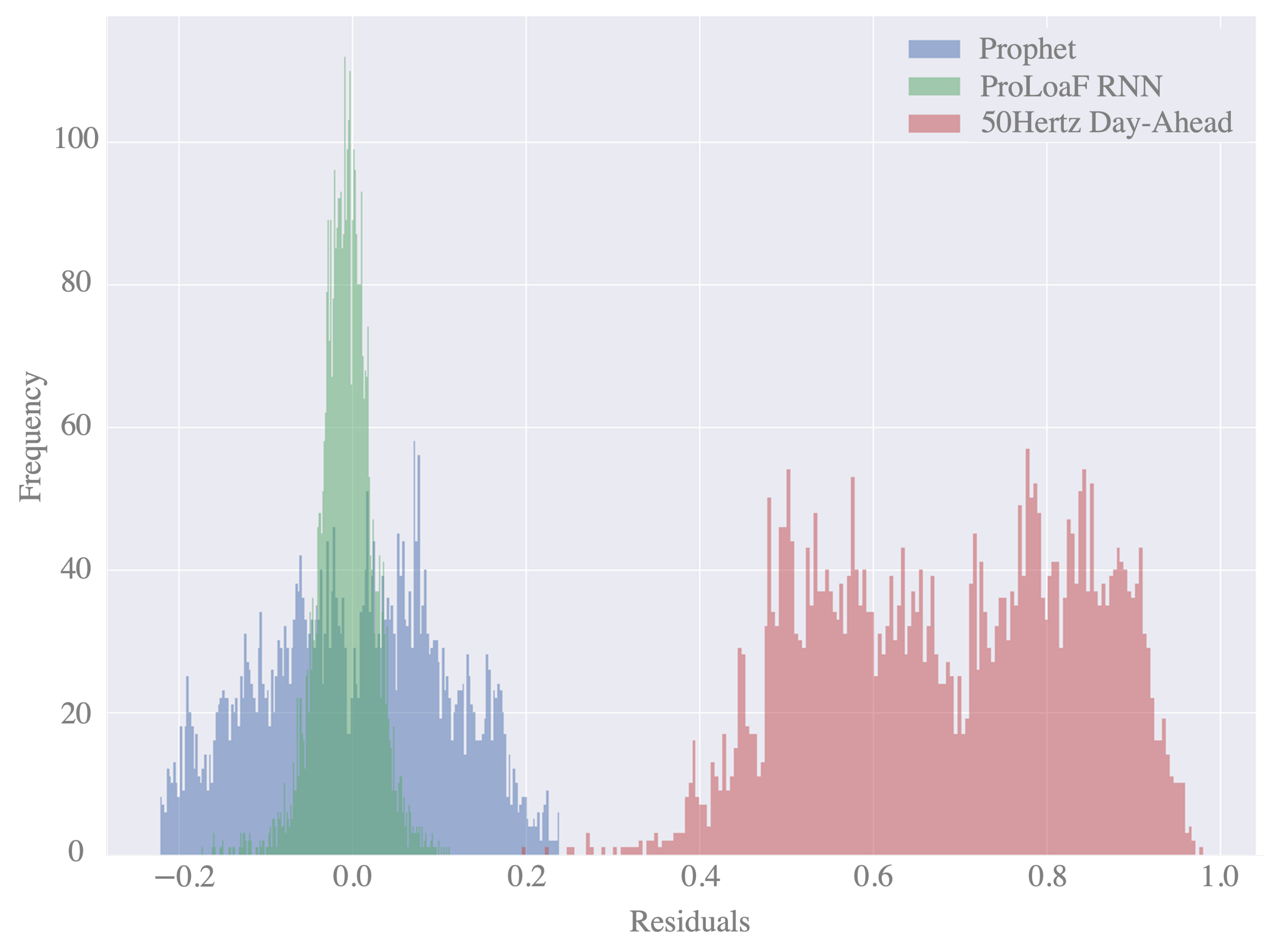
3.7. Statistical Evaluation
4. Discussion
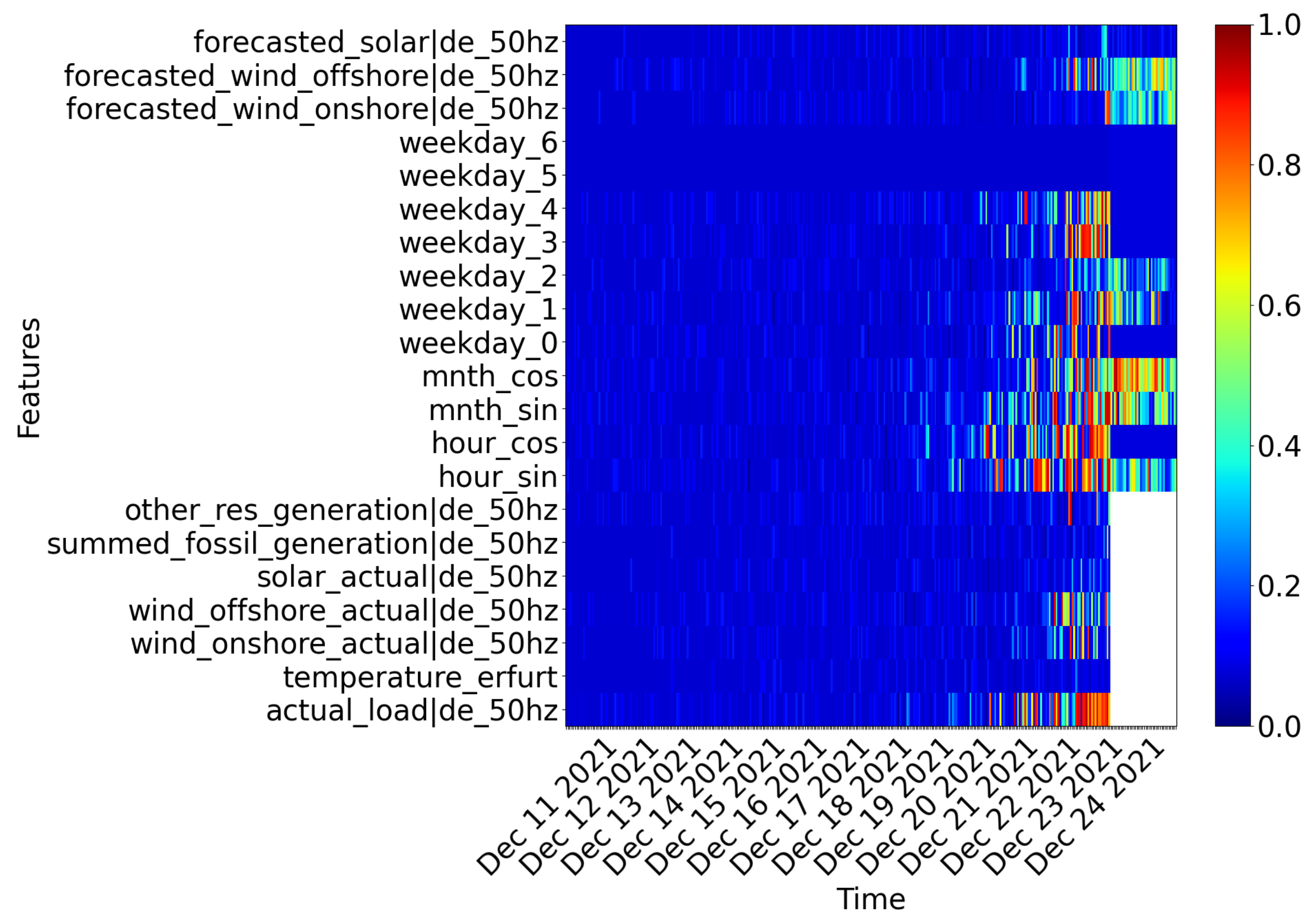
4.1. Making a Black-Box Sequence-to-Sequence Model Intepretable
4.2. Ablation Study
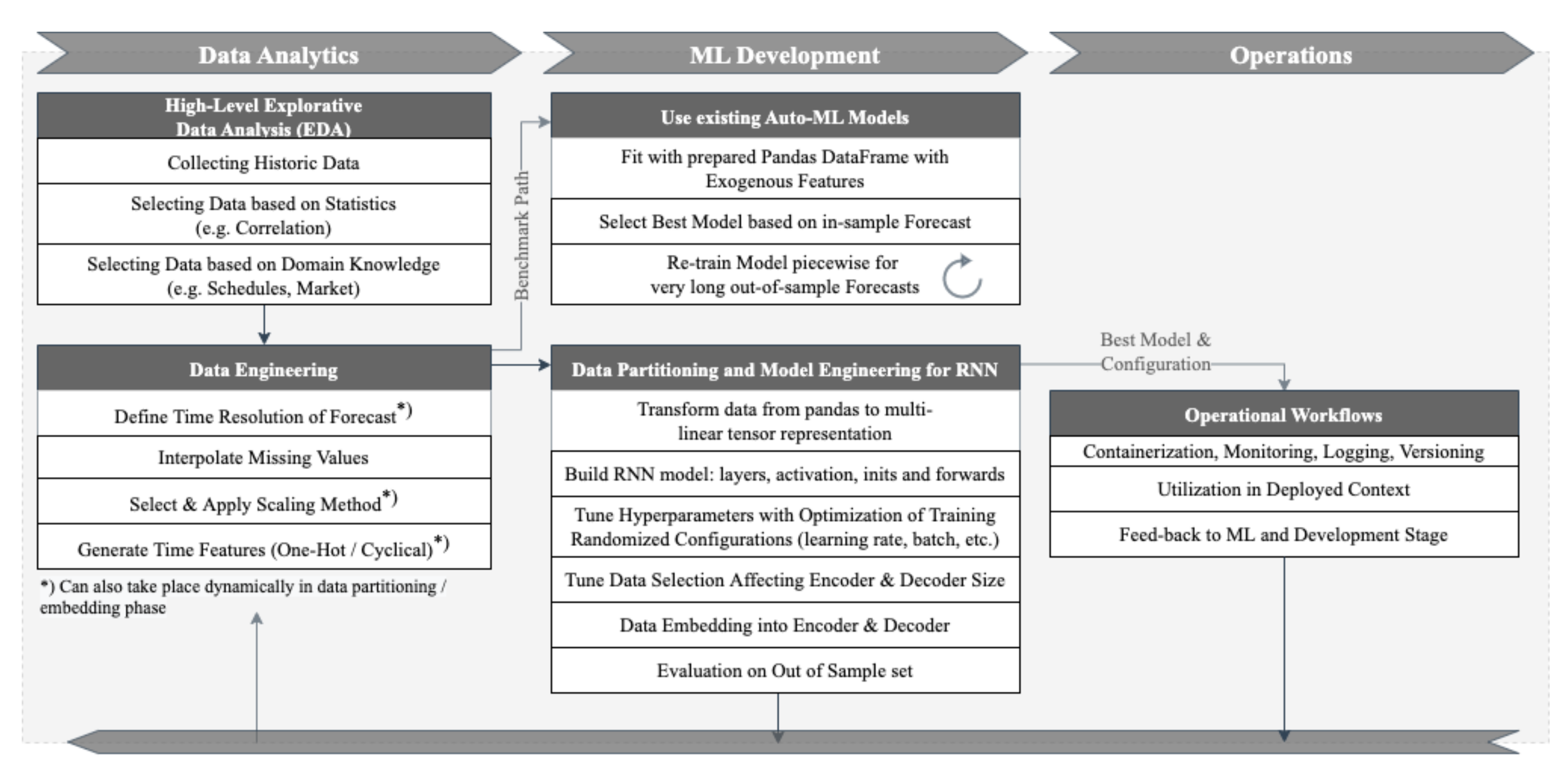
4.3. Designing MLOps
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADAM | Adaptive Moment Estimation |
| AIC | Akaike’s Information Criterion |
| ANN | Artificial Neural Network |
| ARIMA | Autoregressive Integrated Moving Average |
| ASM | Active Power System Management |
| CDF | Cumulative Distribution Function |
| CPU | Central Processing Unit |
| CUDA | Compute Unified Device Architecture |
| DSO | Distribution System Operator |
| DWD | Deutscher Wetterdienst |
| EDA | Explorative Data Analysis |
| GAMs | General Additive Methods |
| GPU | Graphics Processing Unit |
| GRU | Gated Recurrent Unit |
| LSTM | Long-Short-Term Memory Units |
| MASE | Mean Absolute Scaled Error |
| MIS | Mean Interval Score |
| ML | Machine Learning |
| MLOps | Machine Learning Operations |
| MSE | Mean Squared Error |
| PI | Prediction Interval |
| PICP | Prediction Interval Coverage Probability |
| PLF | Probabilistic Load Forecasting |
| PV | Photovoltaics |
| QRF | Quantile Regression Forests |
| QS | Quantile Score |
| RES | Renewable Energy Source |
| RMSE | Root Mean Squared Error |
| RNN | Recurrent Neural Network |
| Seq2Seq | Sequence to Sequence Learning Neural Networks |
| SOGNO | Service-based Open-source Grid Automation Platform for Network Operation of the Future |
| STLF | Short Term Load Forecasting |
| TPE | Tree-Structured Parzen Estimator |
| TSO | Transmission System Operator |
| XGBoost | Extreme Gradient Boosting |
References
- CEDEC; E.DSO; ENTSO-E; EURELECTRIC; GEODE (Eds.) TSO–DSO Report: An Integrated Approach to Active System Management; CEDEC; E.DSO; ENTSO-E; EURELECTRIC; GEODE: Brussels, Belgium, April 2019. [Google Scholar]
- Kloubert, M.L.; Schwippe, J.; Muller, S.C.; Rehtanz, C. Analyzing the impact of forecasting errors on redispatch and control reserve activation in congested transmission networks. In Proceedings of the 2015 IEEE Eindhoven PowerTech, Eindhoven, The Netherlands, 29 June–2 July 2015; pp. 1–6. [Google Scholar]
- Gürses-Tran, G. ProLoaF: V0.2.2. 2021. Available online: https://zenodo.org/record/6408478#.Yo8y4VRBxPY (accessed on 25 May 2022).
- Messner, J.W.; Pinson, P.; Browell, J.; Bjerregård, M.B.; Schicker, I. Evaluation of wind power forecasts—An up-to-date view. Wind. Energy 2020, 23, 1461–1481. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, R.J.; Athanasopoulos, G. (Eds.) Forecasting: Principles and Practice; Otexts: Lexington, Kentucky, May 2018. [Google Scholar]
- Dobschinski, J.; Bessa, R.; Du, P.; Geisler, K.; Haupt, S.E.; Lange, M.; Möhrlen, C.; Nakafuji, D.; de la Torre Rodriguez, M. Uncertainty Forecasting in a Nutshell: Prediction Models Designed to Prevent Significant Errors. IEEE Power Energy Mag. 2017, 15, 40–49. [Google Scholar] [CrossRef] [Green Version]
- Hong, T.; Pinson, P.; Wang, Y.; Weron, R.; Yang, D.; Zareipour, H. Energy Forecasting: A Review and Outlook. IEEE Open Access J. Power Energy 2020, 7, 376–388. [Google Scholar] [CrossRef]
- Murphy, A.H. What Is a Good Forecast? An Essay on the Nature of Goodness in Weather Forecasting. Weather. Forecast. 1993, 8, 281–293. [Google Scholar] [CrossRef] [Green Version]
- Bessa, R.J.; Miranda, V.; Botterud, A.; Wang, J. ‘Good’ or ‘bad’ wind power forecasts: A relative concept. Wind. Energy 2011, 14, 625–636. [Google Scholar] [CrossRef]
- Haupt, S.E.; Casado, M.G.; Davidson, M.; Dobschinski, J.; Du, P.; Lange, M.; Miller, T.; Mohrlen, C.; Motley, A.; Pestana, R.; et al. The Use of Probabilistic Forecasts: Applying Them in Theory and Practice. IEEE Power Energy Mag. 2019, 17, 46–57. [Google Scholar] [CrossRef]
- Bracale, A.; Caramia, P.; Falco, P.D.; Hong, T. Multivariate Quantile Regression for Short-Term Probabilistic Load Forecasting. IEEE Trans. Power Syst. 2020, 35, 628–638. [Google Scholar] [CrossRef]
- Toubeau, J.F.; Bottieau, J.; Vallee, F.; de Greve, Z. Deep Learning-Based Multivariate Probabilistic Forecasting for Short-Term Scheduling in Power Markets. IEEE Trans. Power Syst. 2019, 34, 1203–1215. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: 100,000 time series and 61 forecasting methods. Int. J. Forecast. 2020, 36, 54–74. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. M5 accuracy competition: Results, findings, and conclusions. Int. J. Forecast. 2022, 36, 224–227. [Google Scholar] [CrossRef]
- Farrokhabadi, M.; Browell, J.; Wang, Y.; Makonin, S.; Su, W.; Zareipour, H. Day-Ahead Electricity Demand Forecasting Competition: Post-COVID Paradigm. IEEE Open Access J. Power Energy 2022, 1. [Google Scholar] [CrossRef]
- Gürses-Tran, G.; Flamme, H.; Monti, A. Probabilistic Load Forecasting for Day-Ahead Congestion Mitigation. In Proceedings of the 16th International Conference on Probabilistic Methods Applied to Power Systems, PMAPS 2020, Liege, Belgium, 18–21 August 2020; pp. 1–6. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, V.Q. Sequence to Sequence Learning with Neural Networks. Adv. Neural Inf. Process. Syst. 2014, 27, 5–8. [Google Scholar]
- Bottieau, J.; Hubert, L.; De Greve, Z.; Vallee, F.; Toubeau, J.F. Very-Short-Term Probabilistic Forecasting for a Risk-Aware Participation in the Single Price Imbalance Settlement. IEEE Trans. Power Syst. 2020, 35, 1218–1230. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Seabold, S.; Perktold, J. statsmodels: Econometric and statistical modeling with python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010. [Google Scholar]
- Taylor, S.J.; Letham, B. Forecasting at Scale. Am. Stat. 2018, 72, 37–45. [Google Scholar] [CrossRef]
- Gneiting, T.; Balabdaoui, F.; Raftery, A.E. Probabilistic forecasts, calibration and sharpness. J. R. Stat. Soc. Ser. 2007, 69, 243–268. [Google Scholar] [CrossRef] [Green Version]
- Gneiting, T.; Raftery, A.E. Strictly Proper Scoring Rules, Prediction, and Estimation. J. Am. Stat. Assoc. 2007, 102, 359–378. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef] [Green Version]
- Petropoulos, F.; Apiletti, D.; Assimakopoulos, V.; Babai, M.Z.; Barrow, D.K.; Taieb, S.B.; Bergmeir, C.; Bessa, R.J.; Bijak, J.; Boylan, J.E.; et al. Forecasting: Theory and practice. arXiv 2020, arXiv:2012.03854. [Google Scholar] [CrossRef]
- Barandas, M.; Folgado, D.; Fernandes, L.; Santos, S.; Abreu, M.; Bota, P.; Liu, H.; Schultz, T.; Gamboa, H. TSFEL: Time Series Feature Extraction Library. SoftwareX 2020, 11, 100456. [Google Scholar] [CrossRef]
- Taylor, G.S. pmdarima: ARIMA Estimators for Python. 2017. Available online: http://www.alkaline-ml.com/pmdarima (accessed on 25 May 2022).
- Rimi, N.F.; Bast, H.; Wittwer, C. Comparative Study of Forecasting Algorithms for Energy Data. 2019. Available online: https://ad-publications.informatik.uni-freiburg.de/theses/Master_Nishat_Fariha_Rimi_2019.pdf (accessed on 25 May 2022).
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Ashour Novirdoust, A.; Bichler, M.; Bojung, C.; Buhl, H.; Fridgen, G.; Gretschko, V.; Hanny, L.; Knörr, J.; Maldonado, F.; Neuhoff, K.; et al. Electricity Sport Market Design 2030–2050. In Report, Fraunhofer-Publica; The Institute of Energy Economics at the University of Cologne (EWI): Cologne, Germany, 2021. [Google Scholar] [CrossRef]
- Val Leeuwen, T.; Meinerzhagen, A.K.; Raths, S.; Roether, A. Integration kurativer Maßnahmen in das Engpassmanagement im deutschen Übertragungsnetz. In Symposium Energieinnovation; Amprion: Graz, Austria, 2020. [Google Scholar]
- 50Hertz Transmission GmbH. Daten und Fakten 2019; 50Hertz Transmission GmbH: Berlin, Germany, 2020; Available online: https://www.50hertz.com (accessed on 25 May 2022).
- Böttcher, F.; Deutschländer, T.; Friedrich, A.; Friedrich, K.; Fröhlich, K.; Früh, B.; Ganske, A.; Heinrich, H.; Kreienkamp, F.; Malitz, G.; et al. National Climate Report. In Report, Deutscher Wetterdienst; Deutscher Wetterdienst: Offenbach am Main, Germany, 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- NVIDIA. NVIDIA Data Center Inference Products: Performance Specs. 2022. Available online: https://www.nvidia.com/en-us/deep-learning-ai/solutions/inference-platform/hpc/ (accessed on 25 May 2022).
- Tashman, L.J. Out-of-sample tests of forecasting accuracy: An analysis and review. Int. J. Forecast. 2000, 16, 437–450. [Google Scholar] [CrossRef]
- Rajapaksha, D.; Bergmeir, C.; Hyndman, R.J. LoMEF: A Framework to Produce Local Explanations for Global Model Time Series Forecasts. arXiv 2021, arXiv:2111.07001. [Google Scholar]
- Gürses-Tran, G.; Körner, T.A.; Monti, A. Introducing Explainability in Sequence-to-Sequence Learning for Short-term Load Forecasting. Electr. Power Syst. Res. 2022, in press. [Google Scholar]
- Alliander N.V. OpenSTEF–Automated Machine Learning Pipelines. In Builds the Open Short Term Forecasting Package; Alliander N.V.: Arnhem, The Netherlands, 2022. [Google Scholar]
- Makridakis, S.; Hyndman, R.J.; Petropoulos, F. Forecasting in social settings: The state of the art. Int. J. Forecast. 2020, 36, 15–28. [Google Scholar] [CrossRef]
- Lim, B.; Arık, S.O.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for interpretable multi-horizon time series forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PV | Offshore | Onshore | Other RES | Fossil | Load | |
|---|---|---|---|---|---|---|
| Mean | 1331 | 451 | 3909 | 893 | 8474 | 11,904 |
| Std. Dev. | 2143 | 352 | 3397 | 641 | 2296 | 1977 |
| q(25%) | 0 | 120 | 1258 | 511 | 6878 | 10,973 |
| q(75%) | 1972 | 787 | 5624 | 1056 | 10,136 | 13,359 |
| PV | Offshore | Onshore | Load | |
|---|---|---|---|---|
| Mean | 1327 | 467 | 3930 | 10,397 |
| Std. Dev. | 2110 | 345 | 3322 | 1816 |
| q(25%) | 0 | 142 | 1357 | 8992 |
| q(75%) | 1990 | 794 | 5541 | 12,008 |
| ARIMA | ARIMAX | SARIMA | SARIMAX | |
|---|---|---|---|---|
| Season | - | - | 24 | 24 |
| Exog. | None | Temperature Wind Onshore Wind Offshore PV Conventional Other RES | None | Temperature Wind Onshore Wind Offshore PV Conventional Other RES |
| Lag | 168 | 168 | 168 | 168 |
| Model | (2,1,1)(0,0,0)[0] | (2,1,1)(0,0,0)[0] | (1,1,0)(1,0,2)[24] | (4,1,1)(2,0,2)[24] |
| AIC | −9150.47 | −9152.59 | −10,411.57 | −10,570.10 |
| Parameter | Min | Max | Best ProLoaF RNN |
|---|---|---|---|
| Learning Rate | 1 × 10 | 1 × 10 | 7.47 × 10 |
| Batch Size | 32 | 128 | 64 |
| Linear Layers | 1 | 4 | 3 |
| RNN Layers | 1 | 4 | 4 |
| Data Points | Tesla P40 |
|---|---|
| Single-Precision Performance (FP32) | 12 TFLOPS |
| Integer Operations (INT8) | 47 TOPS |
| GPU Memory | 24GB |
| Memory Bandwidth | 346 GB/s |
| Power | 250 W |
| Metric | auto.arima | Prophet | ProLoaF |
|---|---|---|---|
| RMSE | 0.1047 | 0.0696 | 0.0514 |
| Sharpness | 0.4730 | 0.2156 | 0.1748 |
| PICP | 95.88% | 87.19% | 92.17% |
| MIS | 0.5370 | 0.3299 | 0.075 |
| Prophet | ProLoaF | |
|---|---|---|
| Average in MWh | 907.18 | 666.26 |
| Summed in GWh | 3049.95 | 2437.19 |
| Total Cost C in Mio.€ | 580.96 | 352.72 |
| Metric | ProLoaF RNN | -No Temp. | -No PV | -No Fossil | Enc. Size (24 h × 6 Days = 144 Time Steps Embedded as Encoder Input Size during Training.) |
|---|---|---|---|---|---|
| MSE | 0.002 | 0.002 | 0.003 | 0.002 | 0.002 |
| RMSE | 0.050 | 0.049 | 0.058 | 0.049 | 0.050 |
| Sharpness | 0.197 | 0.220 | 0.185 | 0.219 | 0.202 |
| PICP | 94.63% | 96.92% | 90.19% | 96.86% | 95.36% |
| RAE | 0.235 | 0.228 | 0.272 | 0.231 | 0.237 |
| MAE | 0.038 | 0.037 | 0.044 | 0.037 | 0.038 |
| MIS | 0.075 | 0.073 | 0.087 | 0.073 | 0.075 |
| MASE | 0.960 | 0.933 | 1.116 | 0.944 | 0.973 |
| QS | 0.025 | 0.025 | 0.030 | 0.024 | 0.025 |
| Residuals | 0.002 | 0.005 | 0.019 | 0.010 | 0.009 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gürses-Tran, G.; Monti, A. Advances in Time Series Forecasting Development for Power Systems’ Operation with MLOps. Forecasting 2022, 4, 501-524. https://doi.org/10.3390/forecast4020028
Gürses-Tran G, Monti A. Advances in Time Series Forecasting Development for Power Systems’ Operation with MLOps. Forecasting. 2022; 4(2):501-524. https://doi.org/10.3390/forecast4020028
Chicago/Turabian StyleGürses-Tran, Gonca, and Antonello Monti. 2022. "Advances in Time Series Forecasting Development for Power Systems’ Operation with MLOps" Forecasting 4, no. 2: 501-524. https://doi.org/10.3390/forecast4020028