1. Introduction
Deep learning has been effectively used in an extensive range of fields to solve complicated problems, like image segmentation and classification [
1], fraud detection [
2], medical image analysis [
3], plant phenotyping [
4,
5], etc. However, it has also been used to develop applications that can pose a threat to people’s privacy, like deepfakes. Traditionally, digital images were manipulated through vision-based tools like Adobe Photoshop. Manually processed images could be easily distinguished. However, synthetic images are becoming increasingly convincing due to the fast development of deep learning method, which has led to the popularity of deepfakes. Deepfake methods are gaining attention, as they are currently able to manipulate media in a way that another person’s face can replace an original face, while the original facial expressions and actions are retained. The problems of deepfakes arise along with the advances in deep learning. Deepfakes are becoming more and more realistic. It is becoming difficult or even impossible for people to discern if the images and videos are real or fake.
Because the amount of data required for training a deepfake model is enormous, some deepfakes are conspicuous due to the lack of data. Therefore, it is very easy to target celebrities and world leaders who have plenty of images and videos on multiple media platforms, which leads them to being the main targets of seemingly real looking deepfakes. Disinformation could be misleading or even damaging, due to the rapid spread of information on the large-scale platform of the Internet. According to Chesney et al. [
6], deepfakes usually mislead the general public. However, these are a severe problem for national and societal security if they are used for political purposes. For instance, deepfakes of world leaders, like Barack Obama and Donald Trump, have sparked heated debates. Deepfakes created a heated worldwide debate when President Trump shared a deepfake GIF of Joe Biden [
7]. Later, that Tweet was deleted, though its spread was a worldwide concern; deepfakes could be politically dangerous in the near future.
In recent years, it has become very easy to create a deepfake of any object due to the extensive evolution of machine learning apps (like Zao and FaceApp) backed by facial manipulation engines [
8]. TikTok has also been introducing filters that can create very realistic deepfakes. There are a number of social media platforms on which people extensively post realistic looking deepfakes of celebrities.
Recently, Tom Cruise appeared on the TikTok platform and gained 486.2 K followers with 1.4 million likes in a few days. Later, it was revealed that he never had an account on TikTok, and it was an artist who created the account "deeptomcruise” and created these very realistic Tom Cruise deepfakes [
9]. This proved that deepfakes could damage someone’s credibility or help to spread disinformation. Therefore, it is essential to help the audience identify fake media and protect people from deepfakes. Many companies and institutes have launched competitions, such as the Deepfake Detection Challenge (DFDC) [
10], to explore innovative technologies for deepfake detection. Traditional forensics approaches, including signal-level cues, physical-level evidence, or semantic-level consistencies, have not been sufficiently useful or efficient in deepfake detection [
11]. Additionally, these techniques are not robust against changing conditions that are caused by resizing and compression operations [
12]. Thus, deepfake detection methods that are based on deep learning or other machine learning technologies exist, but these approaches also tend to be short lived because the deepfake creation methods are being continuously improved. This research aimed to create a novel deepfake detection method that can deal with emerging deepfake threats and cope with the possible improvements of the deepfake creation methods.
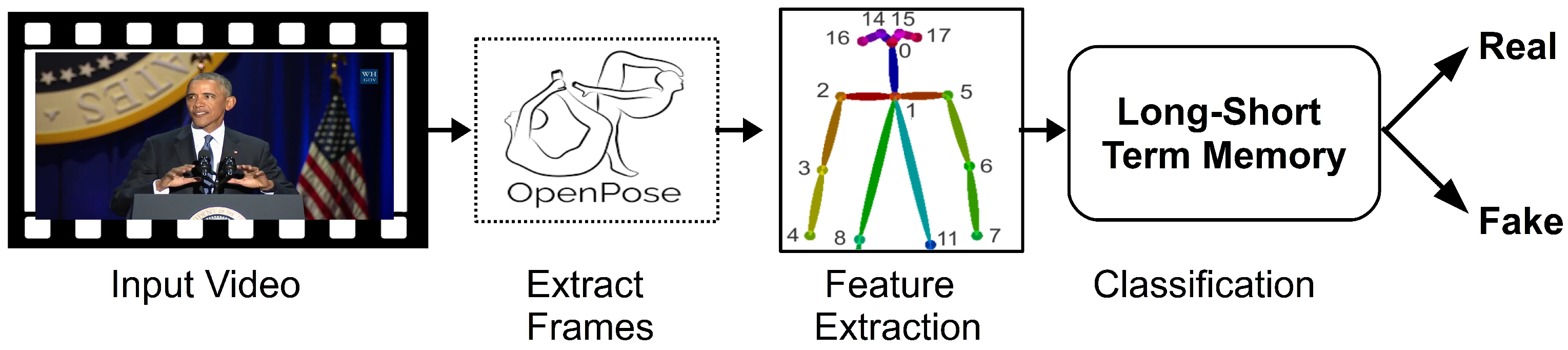
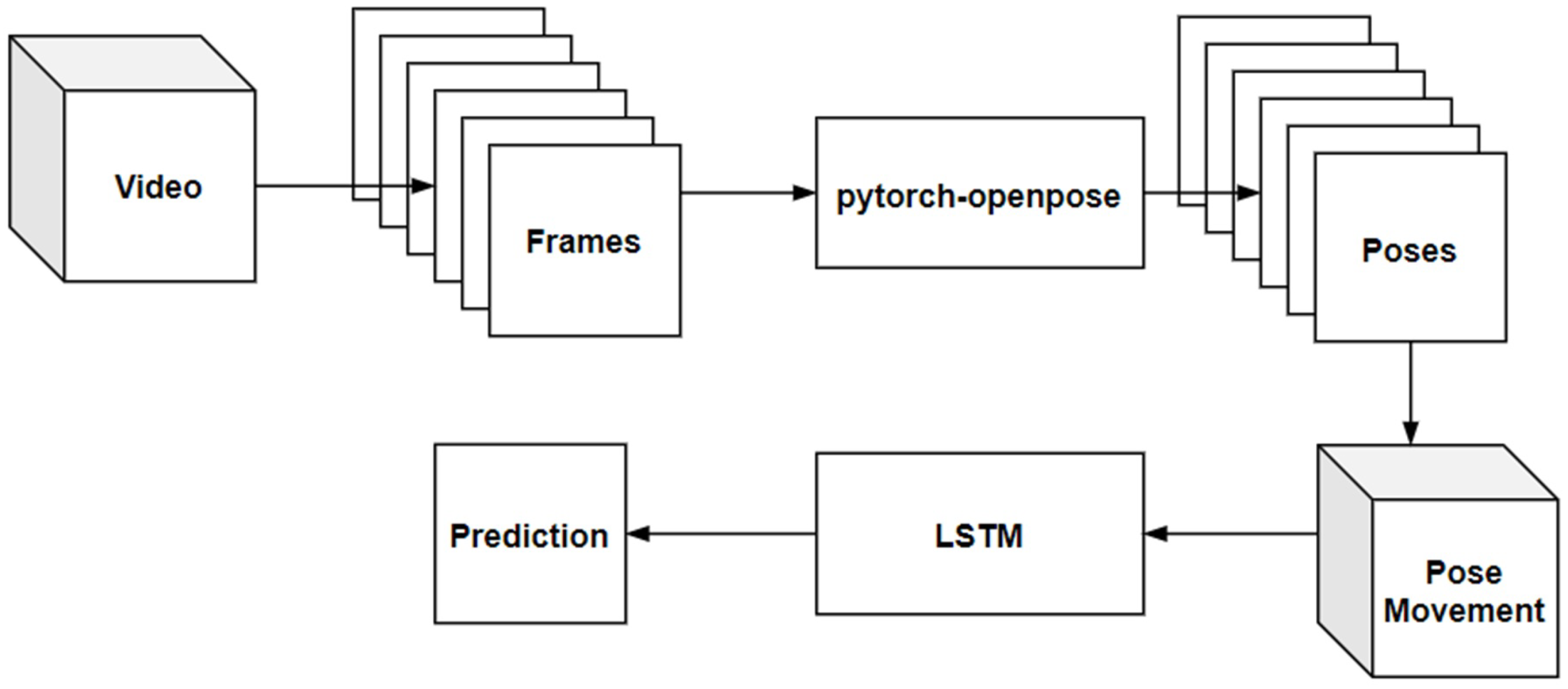
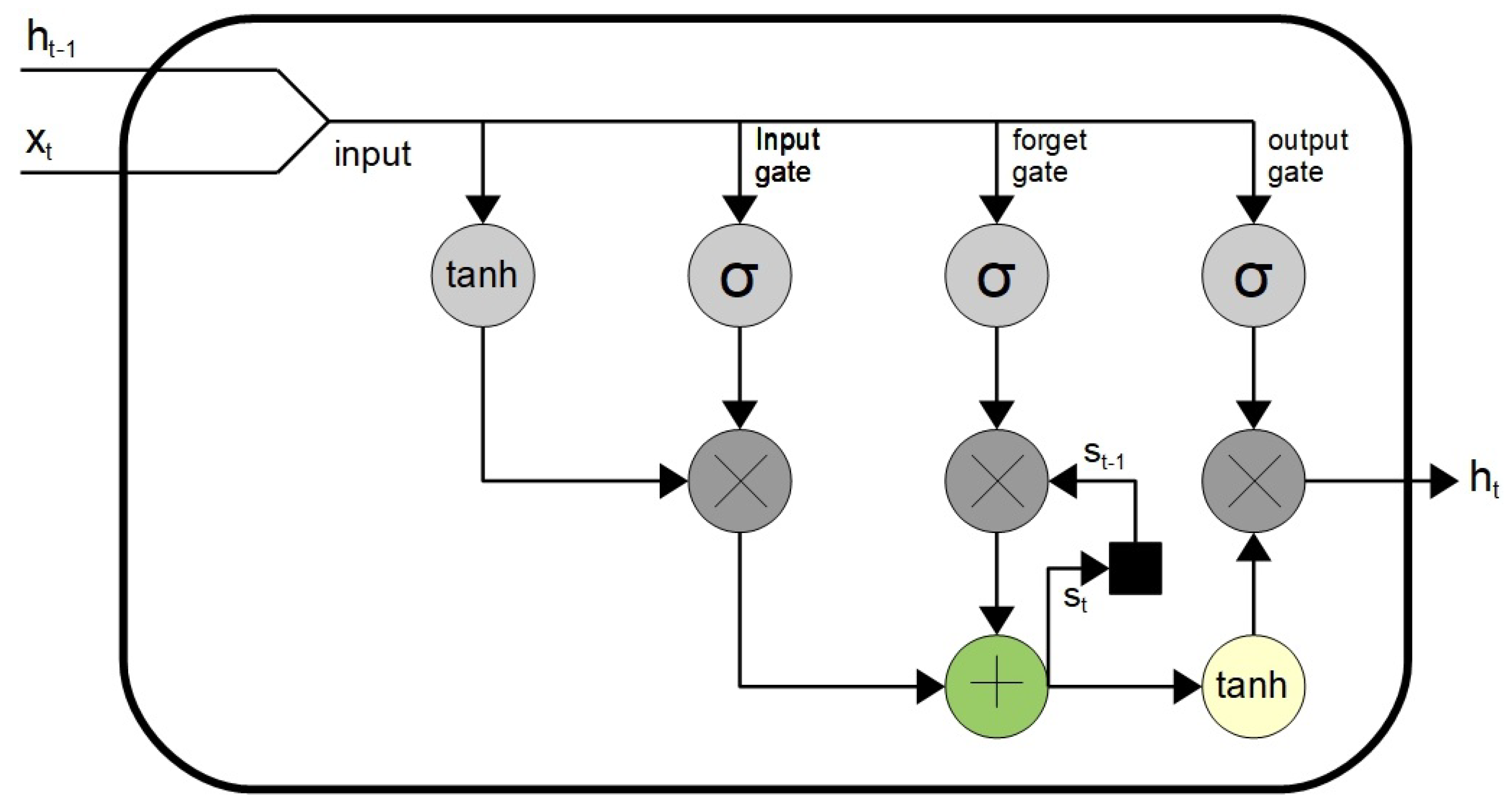
When considering the magnitude of problems caused by fake videos, especially for world leaders, this research focused on automatically protecting world leaders from deepfake videos by using deep learning techniques. The speeches of world leaders can have a significant impact on a country or the world. Most world leaders present debates behind a lectern, thereby only exposing the upper half of the body. We hypothesized that upper body movements are distinct for different individuals, and deep learning networks can utilize upper body language to identify the corresponding people and expose the deepfakes. The upper body pose consists of the keypoints of eyes, nose, neck, shoulders, elbows, and wrists. These keypoints can be used to train a deep neural network to learn someone’s distinct posture and gestures.
Figure 1 presents the proposed design. The key contributions in this work can be described, as follows.
To provide a general literature review of deep learning technologies, deepfake detection, and human pose estimation.
To develop a human pose estimation program to detect upper body keypoints.
To implement a deep learning network to learn the upper body languages of the target world leader.
A comprehensive dataset of world leaders, which could serve as a pre-training arrangement for the smaller dataset (with less real/fake data samples).
To examine the effectiveness of detecting deepfakes through upper-body language analysis.
The introductory section presents the problem of deepfake, the necessity of creating deepfake forensics, and possible outcomes. This research aims to detect deepfake videos of world leaders using upper body language analysis. The goal is achieved through providing a literature review of deepfake in
Section 2.
Section 3 presents the proposed methodology, data collection, and network implementation. The following
Section 4 provides the results and discussion.
2. Literature Review
Human pose estimation refers to a mechanism that locates people’s body parts in digital images or videos. The human pose estimation problem includes the single-person pose estimation problems, 3D skeleton estimation problem, multi-person pose estimation problem, and video pose tracking problem [
13]. MPII [
14] and COCO [
15] are two public-available datasets for 2D pose estimation. The traditional methods for pose estimation are vision-based that are used in two contexts. The first is the feature representation like a histogram of oriented gradients (HOG) and the second is the spatial context. In contrast, deep learning-based methods are widely used these days because of the rapid development capability. Convolutional Pose Machine (CPM) is one of the essential pose estimation methods proposed by Wei et al. [
16]. Jain et al. [
17] used CNN to estimate the single-person skeleton. A CPM consists of a sequence of CNNs, which can learn image features and spatial context simultaneously. Some researchers have applied CPM in their design, for instance, OpenPose, an open-source real-time 2D pose detection system that was released by Cao et al. [
18]. This has applied the CPM refinement and won first place in the COCO-2016 Keypoint Challenge. Cao et al. [
18] created Part Affinity Fields (PAFs), a novel bottom-up representation of association scores, where the location and orientation of limbs are encoded as 2D vector fields. Newell et al. [
19] also proposed a bottom-up method in the COCO 2016 Keypoint Challenge. This approach simultaneously performs detection and grouping by applying associative embedding. Based on CPM development, deepfake creation is considered to be an advanced human pose estimation and manipulation stage.
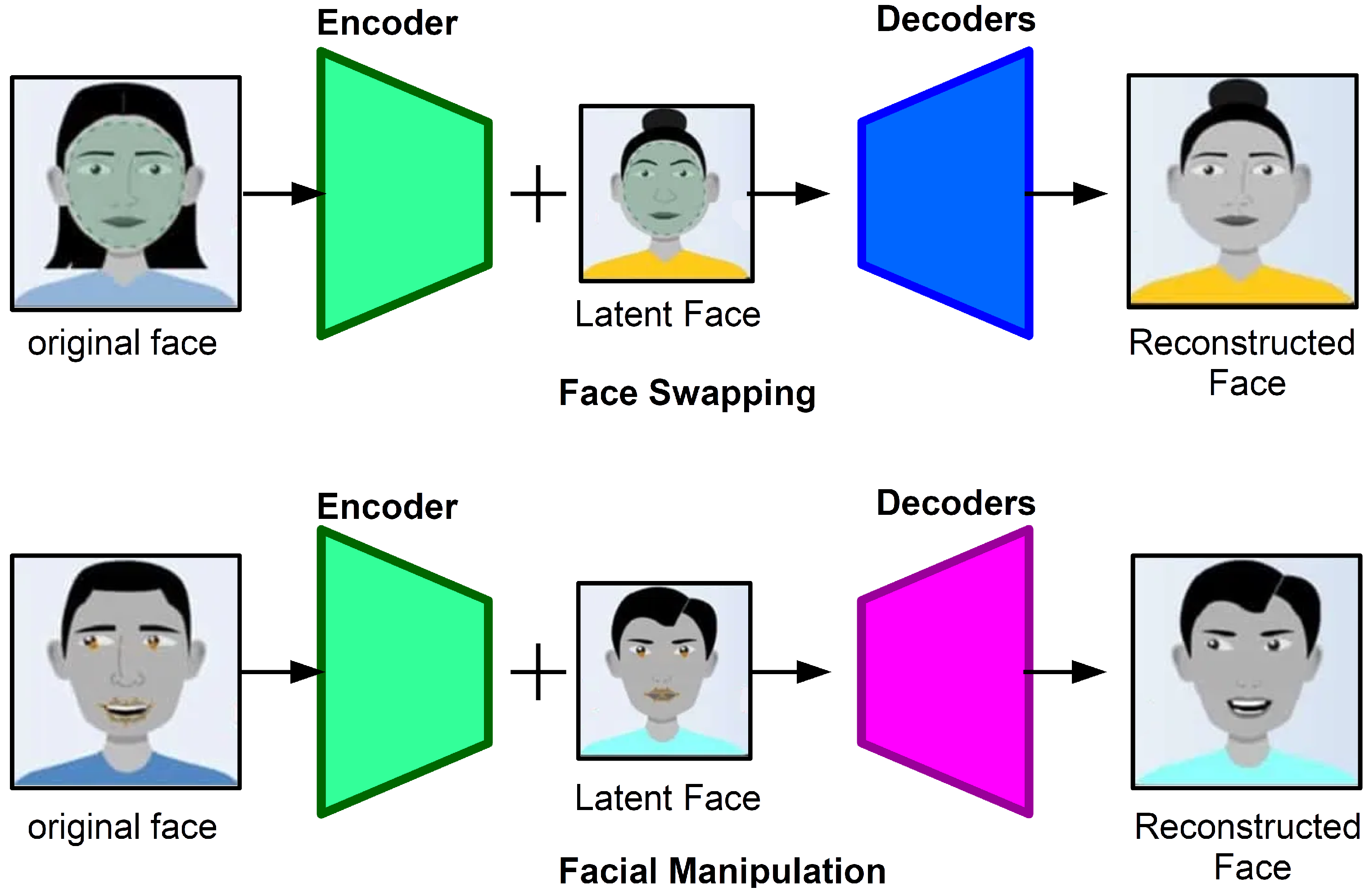
Deepfake creation is a combination of computer vision algorithms and deep learning techniques. The unsupervised image-to-image translation framework, as developed by Liu et al. [
20], is the basis of deepfake generation, which is established on the coupled Generative Adversarial Network (GAN). The networks for deepfake creation use two sets of encoders-decoders, consisting of a standard encoder using shared weights for two network pairs and two different decoders, according to Nguyen et al. [
21]. The encoder aims to learn the similarities between two different faces. Given an image of an aligned face as the input, a fake face can be produced using a standard encoder and decoding.
Figure 2 shows the process of creating a fake face. Deepfake conversion is an essential step in the process of deepfake creation. Li et al. [
22] indicated that the deepfake generation process includes face detection, face landmarks extraction, face alignment, deepfake generation, affine warping, and post-processing, such as boundary smoothing. Meanwhile, advanced deepfake creation methods are also developed; for example, GAN-based deepfake creation adds the adversarial and perceptual losses to the original network [
21]. Additionally, Mirsky et al. [
23] indicate that current deepfake creation uses various combinations of Deep Neural Networks (DNNs), like Convolution Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and GANs. The detection and combating of deepfakes is getting harder because deepfake creation methods are getting sophisticated.
Several deepfake detection methods have recently emerged. These methods/algorithms are fundamentally divided into (a) fake image detection and (b) fake video detection [
21]. AI-based video synthesis is a relatively new technology. Some forensic techniques have successfully addressed general deepfake detection problems that are based on a wide range of different technologies. Besides, a deepfake detection tool using Support Vector Machine (SVM) has been specifically developed for world leaders [
24]. However, these methods tend to be transient, because new deepfakes can fix corresponding imperfections in a shorter time [
25]. Thus, it is necessary to expose new imperfections of deepfakes and develop new detection algorithms or improve existing approaches.
Most research on fake video detection has used deep learning to detect artifacts and inconsistencies of the video. Li et al. [
11] used a CNN and Long-term Recurrent Convolutional Network (LRCN) to detect unnatural blinking patterns in the video. The resultant videos contain irregular blinking frequency because of the lack of images (with closed eyes) for the training and deepfakes generation. However, Korshunov et al. [
26] claimed that the effectiveness of eye blinking detection for exposing GAN-based deepfakes is unclear because the videos being used for training the model were collected from the web. In addition, eye blinking detection is not effective at present, because blinking was quickly incorporated into the new generation of deepfake technique [
25]. Li et al. [
11] proposed another detection method that uses CNNs to detect the resolution inconsistency between facial area and other areas that are caused by the affine wrapping process of deepfake creation. They trained four types of CNN models, including a VGG16 [
27], and three different ResNets [
28]. The results have higher accuracy than earlier benchmark approaches when tested with two public GAN-based deepfake datasets. This approach effectively generated negative data by applying the Gaussian blur to the facial area instead of spending a large amount of time implementing a network and training a model for deepfake generation as other approaches have. Likewise, Güera et al. [
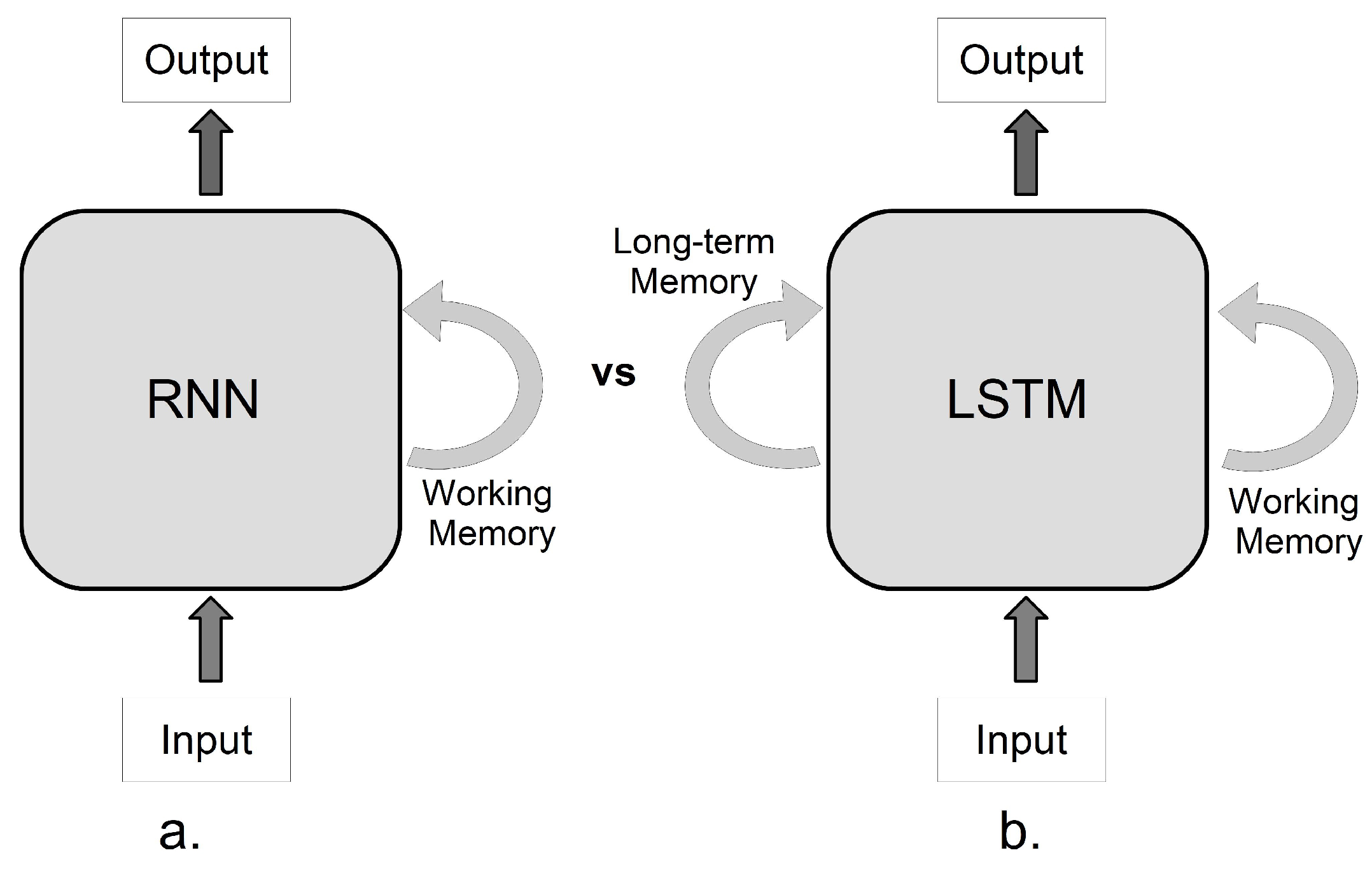
29] indicated intra-frame inconsistency due to the seamed fusion of face and the rest of the frame. They also demonstrated that multiple camera views and various lighting conditions could cause frame-level inconsistency between video segments. Their method uses CNN to extract frame-level features and use Long Short-term Memory (LSTM) to extract features in sequences of frames.
Zhang et al. [
30] proposed a novel method that was based on the GAN simulator. This simulator approach frees developers from accessing the actual GAN model to generate forgery images when training classifiers. They reviewed the artefacts that were caused by GAN’s up-sampling module. The proposed model achieved excellent performance in terms of binary classification of real and fake images.
Another method that was proposed by Jain et al. [
31] detects GANs and retouches based digital alterations. The proposed architecture has three hierarchy levels to broadly classify and distinguish input images as original or altered, followed by subsequent levels in the architecture. The framework can detect retouching and GANs generated images with high accuracy, showing its applicability in real-life scenarios.
Guarnera et al. [
32,
33] proposed a similar approach that extracts deepfake fingerprints from images. Furthermore, the fingerprint extraction method is based on the expectation-maximization algorithm, emphasizing the extraction ability of convolution traces that are embedded by the generative process. In this paper, a random forest classifier is used to determine the pipeline of fakeness detection. The authors highlighted different CNN-based approaches for deepfake detection that are required highly computational power. The proposed technique obtained excellent classification results by only using CPU power. Nevertheless, Agarwal et al. [
24] argued that simple manipulations, like additive noise, recompression, and resizing, could easily eliminate the inconsistencies mentioned in the above two methods.
In addition to deep learning methods, some methods rely on supervised machine learning models (SVMs). For instance, Yang et al. [
34] introduced an SVM classifier to expose deepfakes by inconsistent 3D head poses, and argued that the difference between head poses is a useful feature for deepfake detection. The SVM classifier was evaluated on two datasets using five different features of estimated 3D head poses. However, most of the experimental results achieved an Area Under the Receiver Operating Characteristic (AUROC) of around 0.9, which shows that using these features is insufficient for deepfake detection.
Moreover, Dang et al. [
35] evaluated the inconsistent 3D head pose on Celeb-DF (a new deepfake dataset that was created by the improved deepfake algorithm [
36]) and only obtained an AUROC of 0.548. Almost all of the existing methods are general for various deepfake videos, but Agarwal et al. [
24] created an SVM classifier that was specialized for world leaders, which uses biometric patterns, including facial action units (AU) and head movements. This method is based on the observation that each individual has unique facial expressions and behaviors, so that the manipulations cannot destroy it on videos, such as recompression, as mentioned above. These SVM models only need original videos for training, which saves time. They effectively trained different binary SVM models for five world leaders, and the average results achieved an AUROC of about 0.948. On the other hand, Agarwal et al. [
24] also indicated that their method might fail for an individual speaking in different scenes. Furthermore, it is reported that it would not take a long time for deepfake techniques to overcome these deficiencies [
25].
As deepfake techniques improved aggressively, deepfake detection methods are no longer useful or will be ineffective in time. Additionally, deepfake poses detection challenges, in that there are more datasets released for deepfake forensics with higher quality. As a result, it becomes a cycle that these two opposing techniques continue to learn and reinforce each other. This requires more advanced forensic techniques to protect people from deepfakes. Agarwal et al. [
24] mentioned that body movement could be used to identify the persons of interest, but they used head movements without taking body movements into account. Deepfake techniques only temper with the facial area and manipulate inconsistencies, so the detection methods generally concentrate on facial areas and head poses. Therefore, utilizing upper body languages for deepfake detection is a new and promising research direction.
4. Results
The following chapter will present the results of model training and testing. The final version of the LSTM model was trained through extensive hyper-parameters adjustments. The proposed deepfake detection method was tested through an inference procedure.
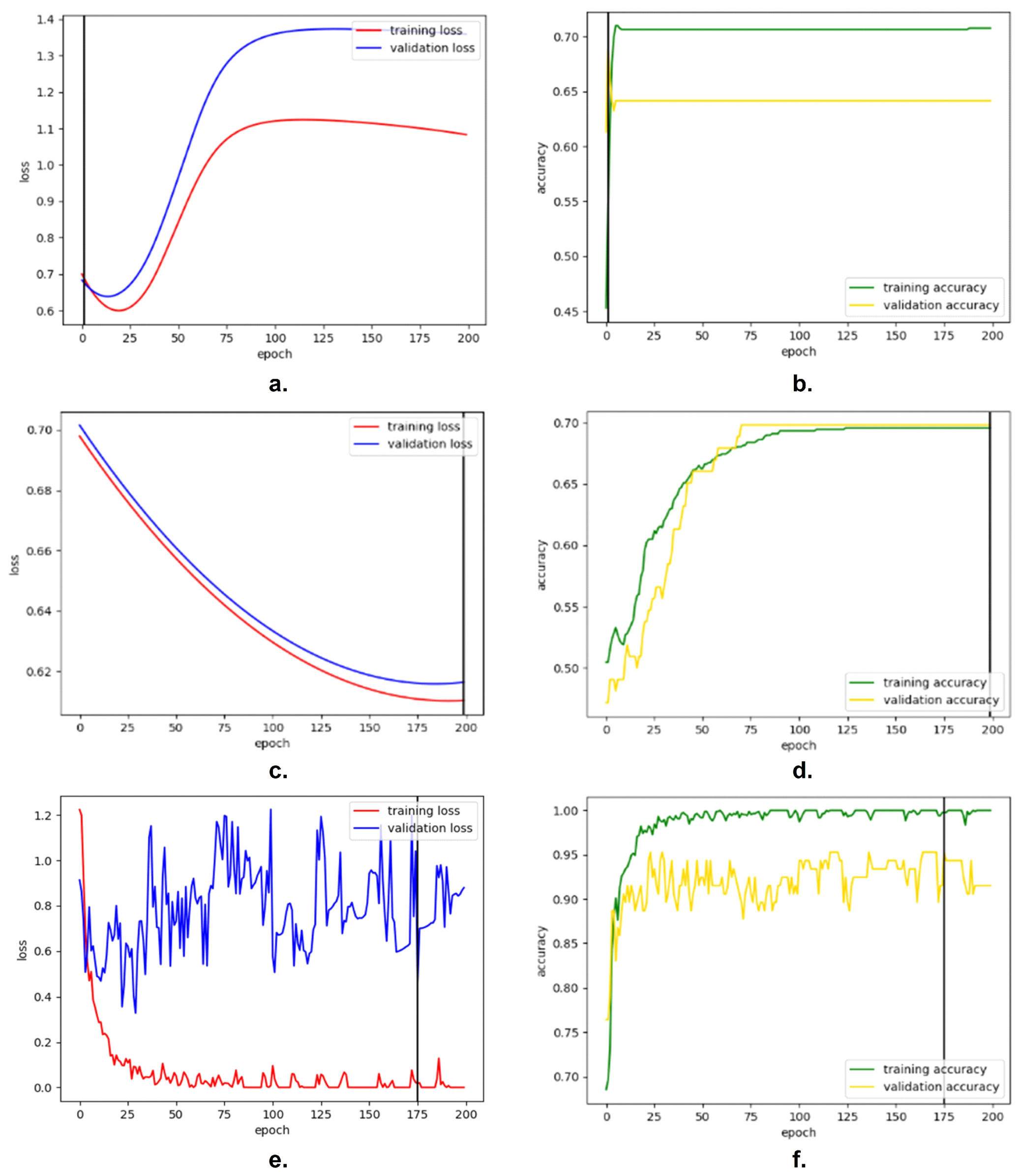
Step one was to determine the appropriate optimizer. For this process, two optimizers, including the SGD and Adam, were tested. We first tried the SGD with a learning rate of
. The results are shown in the subfigures (a) and (b) of
Figure 8. Over time, the training and validation losses implied that the learning rate was too high, so that the model failed to converge. Therefore, we reduced the learning rate to
. The subsequent results are presented in the subfigures (c) and (d) of
Figure 8. The lower learning rate made the loss convergence slow, but the model with an accuracy of about 70% was still underfitted. Subsequently, we used Adam with a learning rate of
; the results are shown in the subfigures (e) and (f) of
Figure 8. The training loss drastically decreased and approached zero, but the validation loss was unstable and getting higher. Thus, the model was overfitted. The above results show that it is hard to adjust the learning rate for the SGD, so Adam is more suitable for this model. Thus, we decided to use Adam to be the final optimizer.
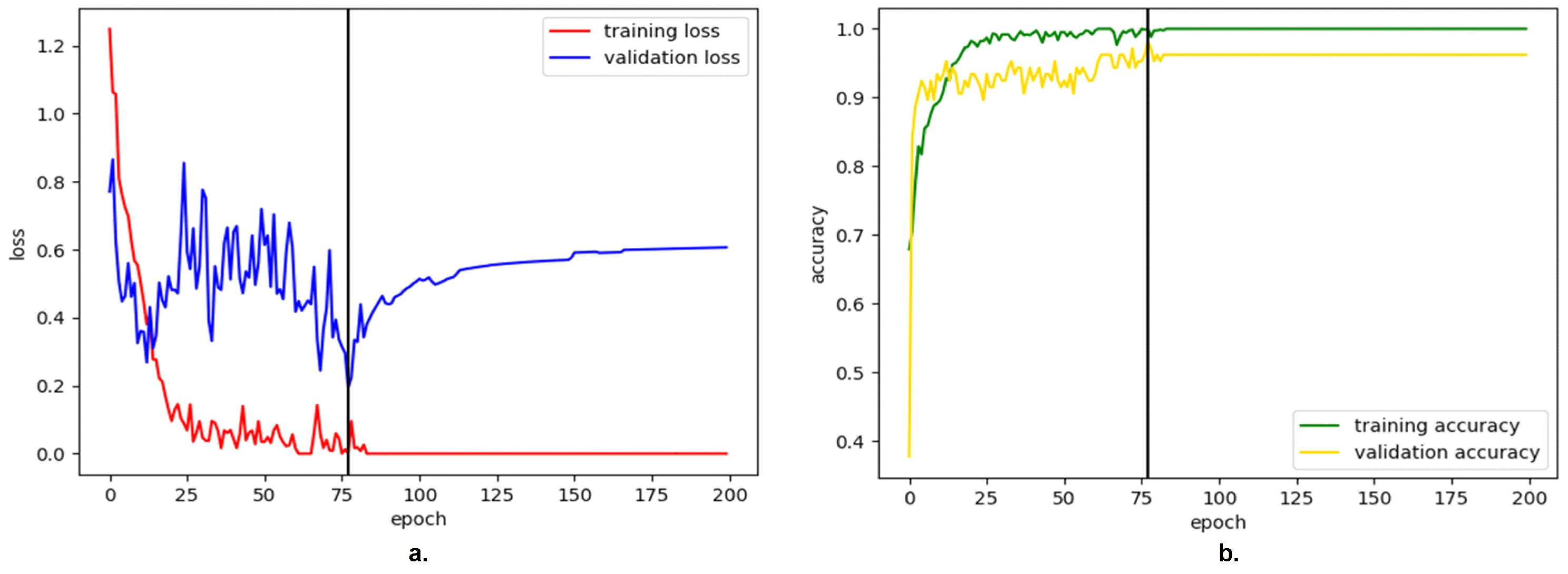
The next step was to solve the overfitting problem. It is assessed that dropout is an effective method for addressing this problem. The dropout for an LSTM model with a single hidden layer is zero. Therefore, we changed the number of hidden layers to 2 and set the dropout probability as 0.5. A stacked LSTM model was the modified model.
Figure 9 shows the results. After the modification, the overfitting problem still existed, but the results revealed that the validation accuracy was more significant than using a single hidden layer. Furthermore, the learning rate also needed to be tuned. A reasonable learning rate should make the loss decrease gradually.
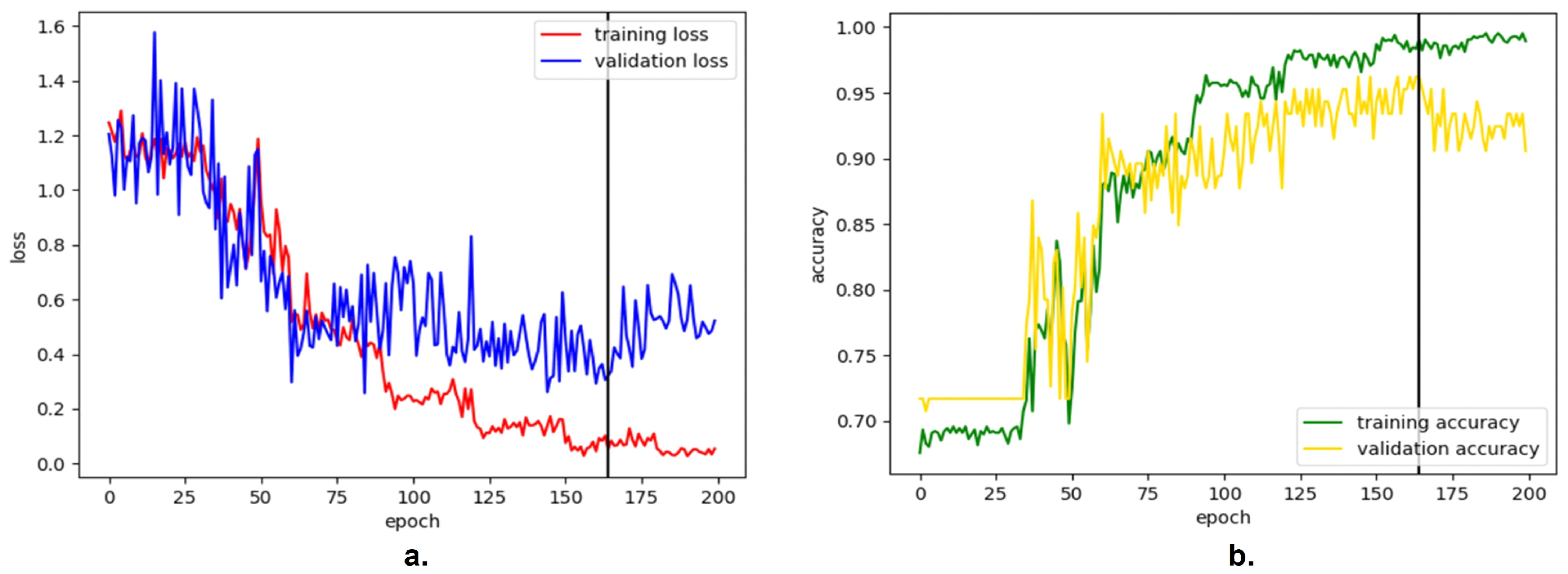
The next step was to solve overfitting and adopt an appropriate learning rate. For this purpose, we applied learning rate decay (0.5 for every 30 epochs) with the initial learning rate of
. Besides, the weight decay with a
coefficient of
was used to prevent overfitting. The results that are presented in
Figure 10 show that both the losses and accuracy remained virtually unchanged during the first 30 epochs, but the values gradually decreased after the first learning rate decay. The best model with the highest validation accuracy was at 165
th epoch.
Table 3 provides the final hyper-parameters.
We trained LSTMs with different neuron depths (hidden states) to assess the most appropriate LSTM arrangement for experiments. It started with 128 neuron depth (number of neurons for LSTM’s hidden state) and kept moving-up till 512 neuron depth. After evaluating the final results, this research identified that LSTMs with 512 neuron depth offered people much better learning capabilities in comparison to less deep neurons LSTMs. Therefore, 512 hidden neuron layers finalized for deepfake detection architecture. Each of these models trained with the given dataset through a single end-to-end trainable design for 200 epochs (500 for initial experiments).
Table 4 presents the quantitative results.
The model was then tested using the testing data. The training, validation, and testing accuracy of the model were 99.06%, 96.23% and 94.39%, respectively, as listed in
Table 5. The model was trained using the final hyper-parameters and a single TitanX GPU for computation.
A detailed benchmark analysis was performed to assess the effectiveness of the proposed method. In this scenario, the proposed LTSM was compared to the well-known deep learning architectures.
Table 5 shows the final results of the overall assessment. The proposed method performed best in terms of high detection accuracy.
Li et al. [
1] used CNNs to detect artifacts, such as face regions and surrounding areas. The use of facial landmarks is the most appropriate way to analyze the proposed method. The proposed dataset also has upper body landmarks, which include facial landmarks. Therefore, we only trained facial landmarks using the CNN architecture, as suggested in the proposed research [
1]. The results in
Table 6 show that our methods offer much better performance when compared to the facial landmarks detection method.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}