The here presented work aims at evaluating the forecasting performance of the proposed hybrid method, composed by a HYPE hydrological model and a ANN method. The model is applied on the power production time series decomposed in trend, residual and seasonality. This approach (Hybrid plus Decomposition) is then compared to three benchmark models: Hybrid, ANN, and ANN plus decomposition.
This section is structured as follows. At first, the available dataset for the proposed method validation is presented and described. In the second part, the error metrics adopted to evaluate the performance of the investigated methods are discussed. Finally, in the last subsection the novel hybrid method for RoR hydroelectric production forecast is detailed.
2.1. Available Dataset
The dataset adopted to validate the proposed method is referred to Slovenia and consists of two parts: flow data and measured electric hydropower production in the period from January 2010 to December 2017.
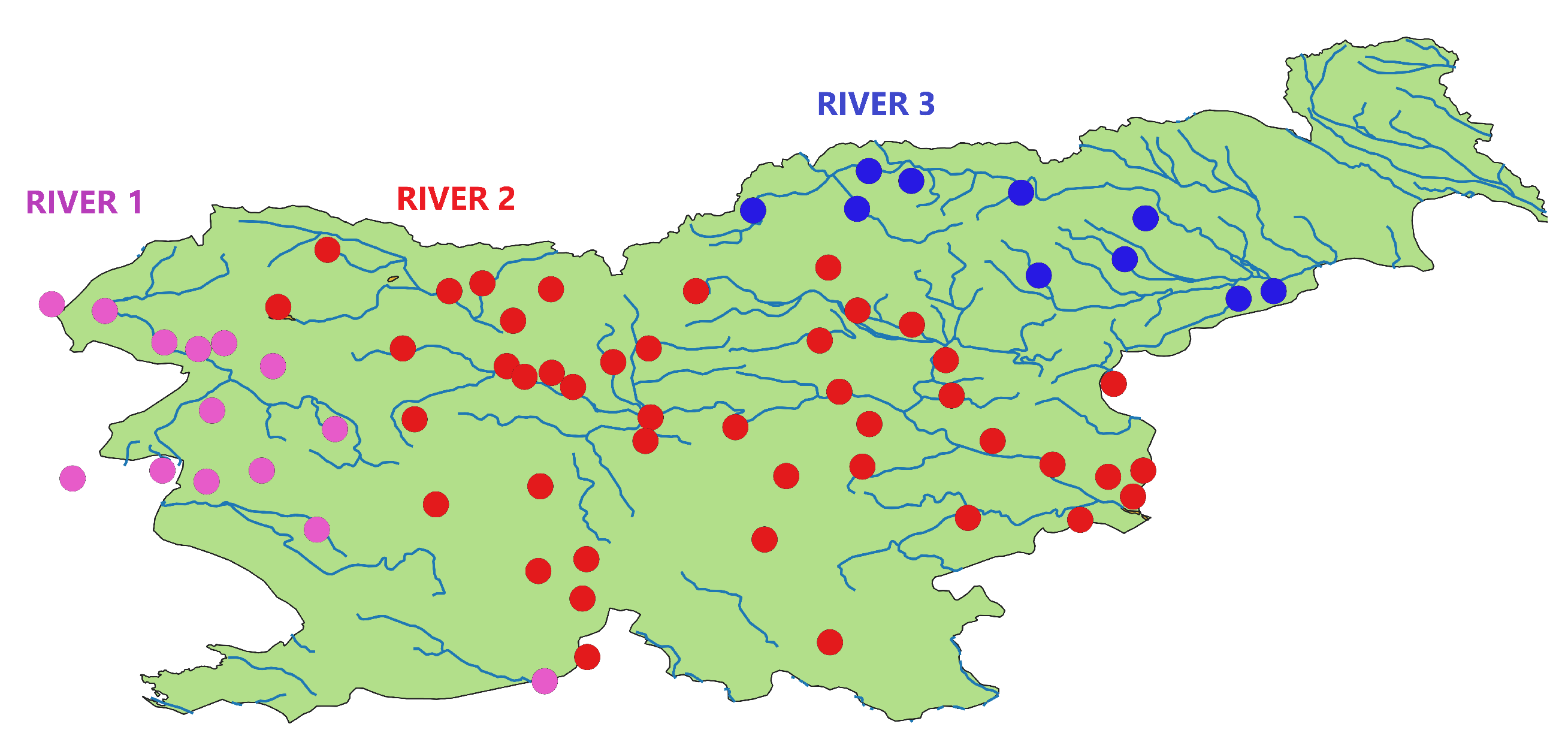
Slovenia is modeled dividing it into 86 different sub-basins. The conditions and geographic features of each sub-basin are exploited by the HYPE model to return the inflow of the drainage basin (an area of land where precipitation collects and drains off into a common outlet, such as river, bay, or other body of water). In our specific case, just precipitations data are provided to the HYPE model, since rain is the main driver in hydropower generation. It has been collected rainfall daily data, measured in [mm], of three Slovenian meteorological stations. Climate data are taken from the “Copernicus Era5” meteorological database and are of public domain. For each sub-basin, geographical data are provided and a basin map based on sequentiality of sub-basins has been drawn: in particular three groups have been identified, and these groups of points represents the river-basin of the three main Slovenian watercourses: River 1, River 2, and River 3, represented in
Figure 1.
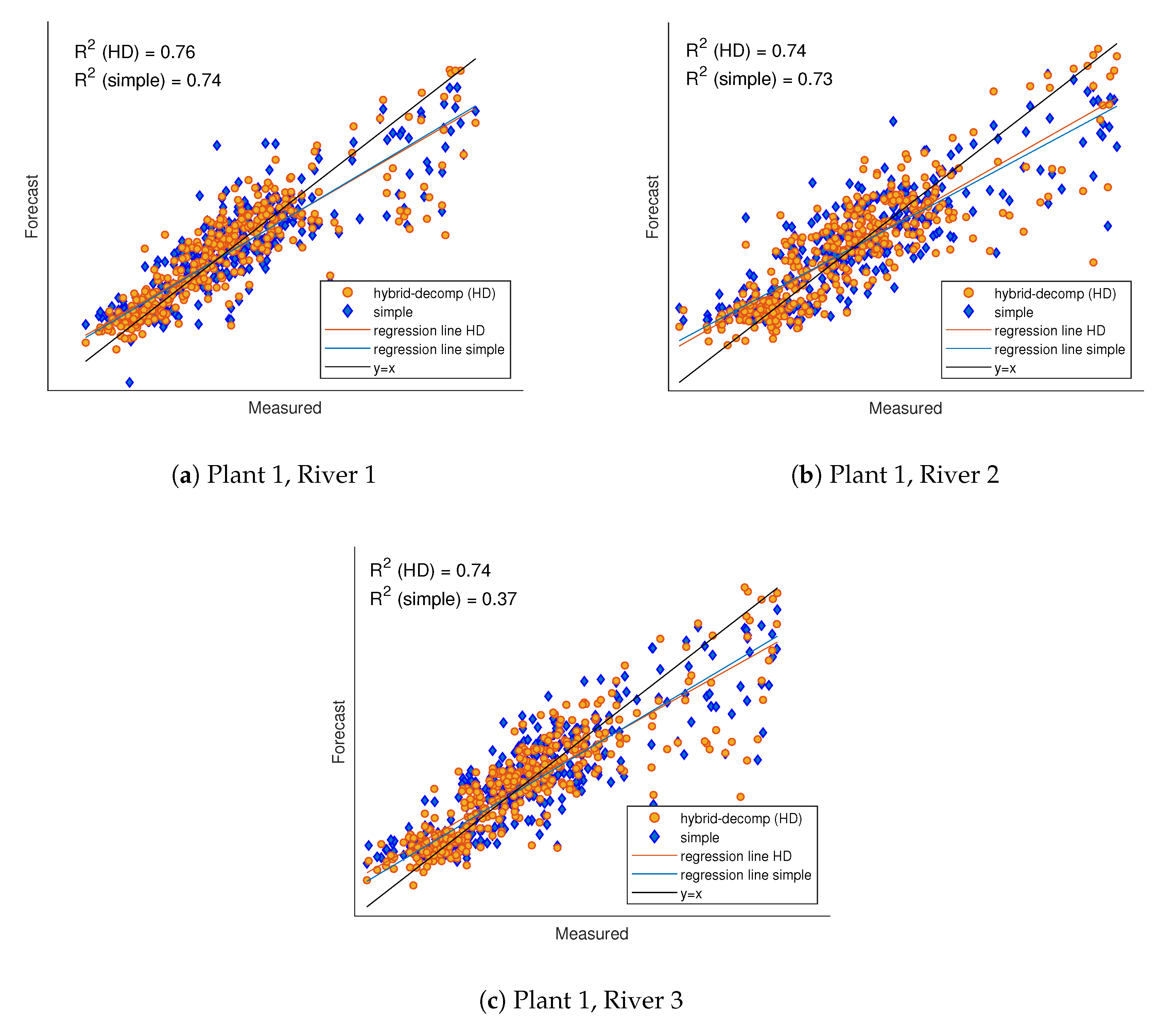
The second part of the dataset is made by the hydroelectric energy produced [MWh] from 2010 to 2017 and Hydro-States, that informs about the status of each plant (working or not). The final purpose of the analysis is to predict the electric production of hydroelectric power plants, and specifically of big power plants (rated power > 20 MW). The dataset is cleaned by discarding those plants characterized by zero-production for a period greater than the 10 % of the total number of samples: three plants have been excluded, for a total of 15 RoR remaining plants, distributed on three rivers: 3 plants on River 1, 5 on River 2, and 7 on River 3. The preprocessing performed on the dataset aimed at testing the proposed method on a significant set of data, with few missing values, to evaluate its performance. The null power production observed in a plant could be due to human regulation rather than a lack of minimal flow in the river, uncoupling in this way the production from the Rainfall/CSB flow forecast. These cases are unpredictable by the algorithm, since they do not derive from a physical process and we have therefore decided to exclude them.
Data are converted on daily basis to have the same time-step of flow data. To validate the proposed method, all the available plants have been studied.
2.3. HYPE model and hybrid forecast method
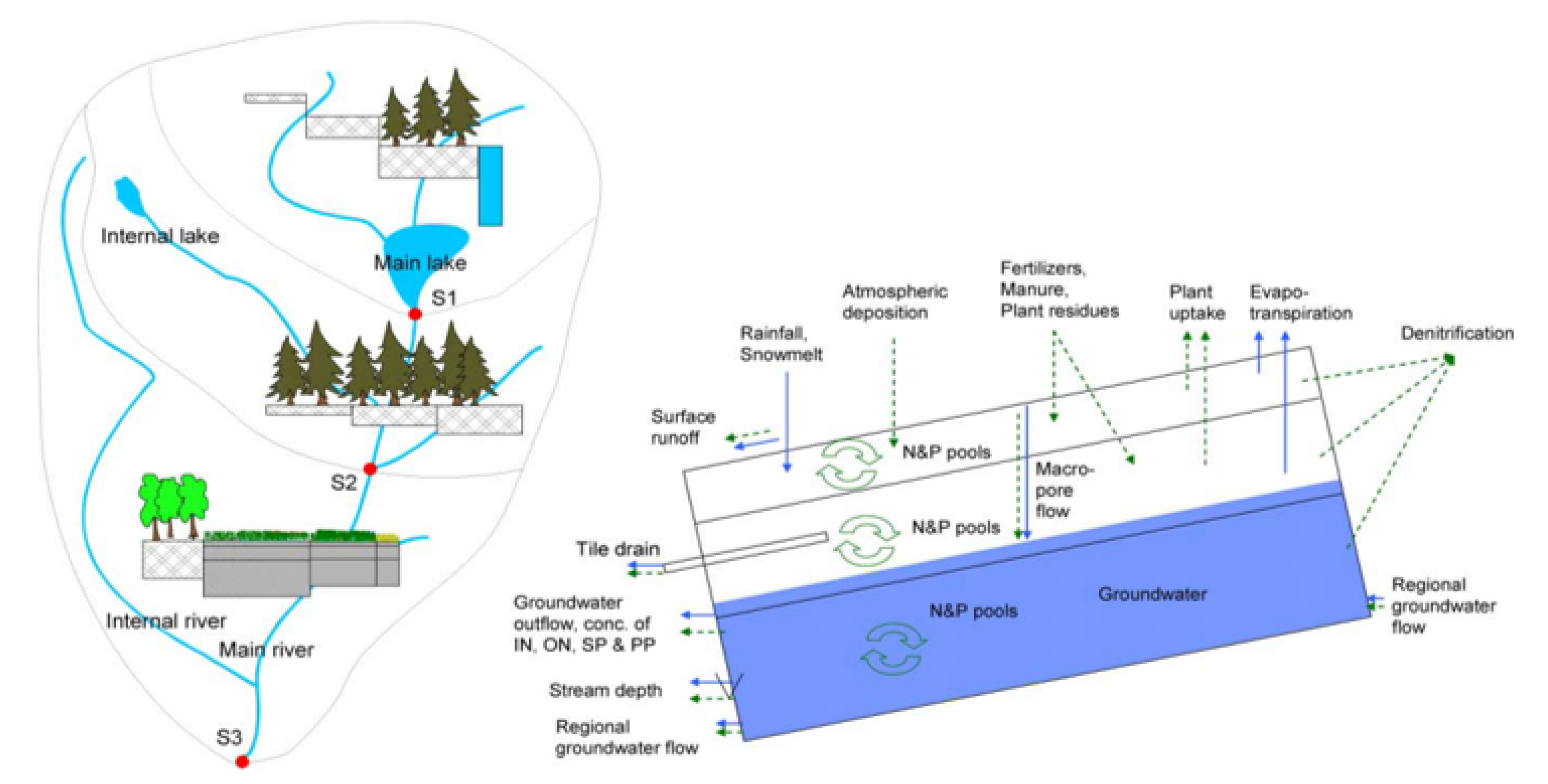
The Hydrological Predictions for the Environment (HYPE) model, is a dynamic, semi-distributed, and process-based model leveraging on well-known hydrological and nutrient transport concepts. It can be used for both small and large scale assessments of water resources and water quality developed at the Swedish Meteorological and Hydrological Institute during the period 2005–2007 [
33]. In the HYPE model applications, which simulates water flows [
34,
35,
36], the model domain may be divided into sub-basins, that can either be independent or connected by rivers and a regional groundwater flow, as exemplified in
Figure 2.
The model receives as input climate variables, rainfall, and ambient temperature among the most important, and returns the sub-basins’ water flow with a daily time step as output. An overview of the typical input data for the HYPE model is provided in [
33], while in [
37] a review of those input parameters that majorly influence performances of the model is presented. The HYPE model is particularly appropriate to simulate ungauged catchments, it is made on simple conceptual and empirical equations, and represents one of the best options for large-scale continental or multi-basins simulations [
9]. Therefore, HYPE model was selected to compose the here presented hybrid method.
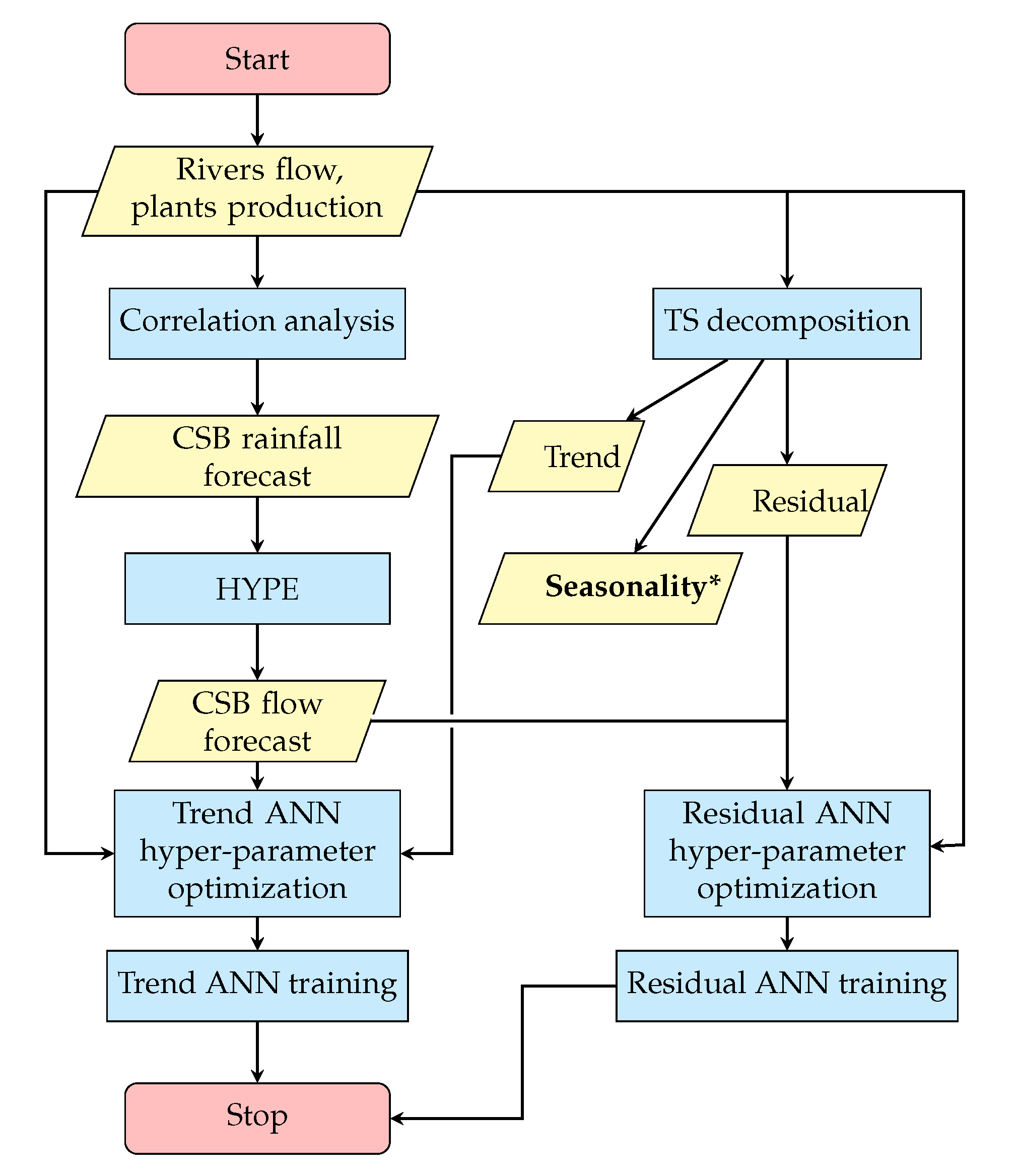
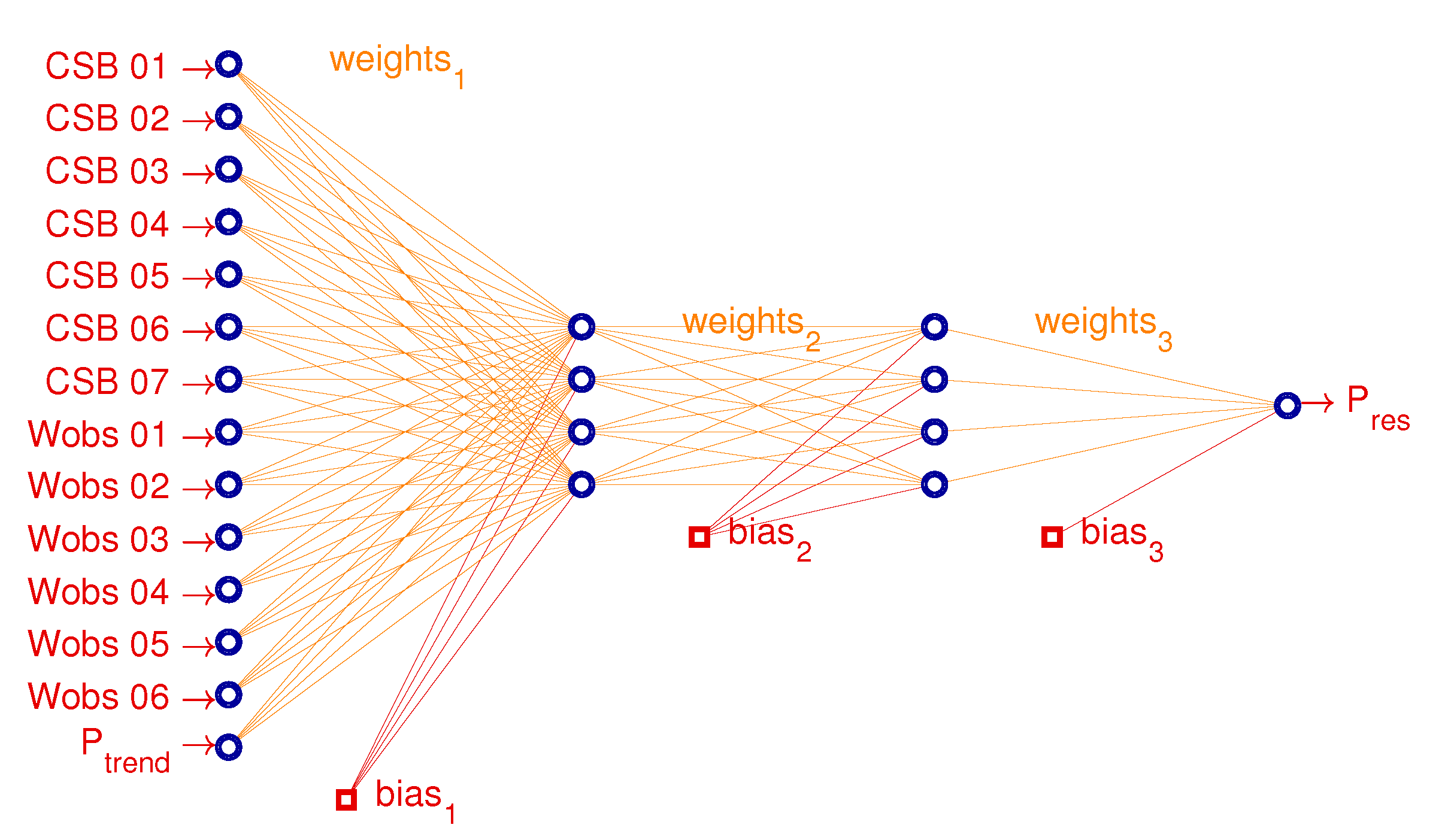
In
Figure 3, the adopted method and the process required to train the hybrid network is displayed. The yellow parallelogram highlights the input/output datasets obtained, while the light blue rectangles highlights the processes performed. At first, it is conducted an analysis to identify the most suitable inputs to be fed into the neural network. A correlation analysis is therefore performed, to select the highly Correlated Sub-Basins (CSB) to the considered plant. The rainfall forecast associated to the identified sub-basins is then fed into the HYPE model, that provides the CSB outflow forecast. In parallel to this analysis, a decomposition of the production time series of the considered plant is performed, identifying the Trend, Seasonality*, and Residual components. The second term will be then used in the forecast process (
Figure 4). Trend and residual components, together with the considered plant past production and the CSB flow forecast, are exploited to perform at first the hyperparameter optimization for the Trend and Residual ANN sizing, respectively, and then for the network training itself.
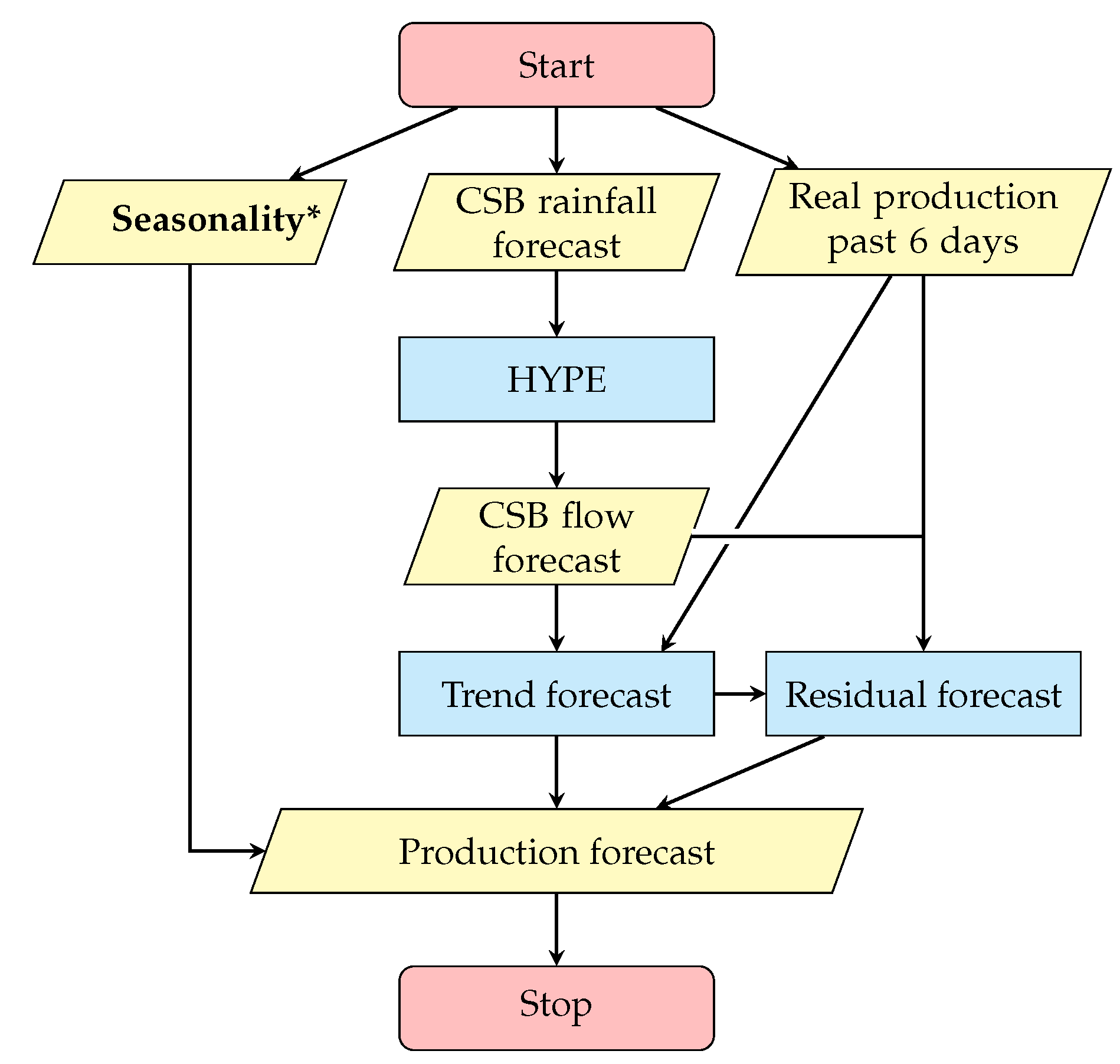
Once the proper network structure is identified, the forecast will be performed, according to the scheme reported in
Figure 4. The CSB flow forecast and the real production of the past six days are exploited to get the trend forecast. This forecast is then fed, together with the previous inputs, into the residual ANN, to get the residual forecast. The obtained production components are then summed up to the seasonality profile to get the production forecast. The obtained results are compared to those coming from the adoption of the ANN (without decomposition), which receives as input the same elements of the HYPE model, i.e., the input weather data from national databases. Additional configurations are considered: Hybrid and ANN with decomposition, to highlight the contributions of decomposition and hybrid network, respectively.
Analyzing the process in detail, at first an analysis on correlation factors is conducted, in order to establish the input–output connection and to identify the proper input layer to feed the ANN. The aim is to understand how the energy production is linked with the discharge flow rate of all basins, in order to find groups of sub-basins which are more relevant for the production; when these groups of basins are estimated, their data values will be exploited to feed a neural network, by exploiting just the highly correlated sub-basins.
The correlation coefficient (
4),
, measures the strength of the linear relationship between two variables x and y. When the value of
is near zero, it indicates the absence of a linear relationship. Generally, we consider the correlation between two variables to be strong when
, weak when
, and moderate otherwise [
38]. The analysis allowed to associate at each power plant a list of sub-basins that majorly contribute, from the correlation point of view, to the hydroelectric generation and to identify the most correlated plants. In particular, it emerges that plants on River 3 have a high correlation with very few sub-basins, which largely correspond to those basins contributing to River 3 from sequentiality point of view. Instead, plants on River 1 and River 2 are both highly correlated to many more sub-basins, and especially they have many correlated sub-basins in common, which do not correspond to those identified from the sequentiality logic.
A decomposition procedure is then introduced to separate the different contributions of the series. Decomposition is used in time series analysis to describe the trend and seasonal factors in a time series. One of the main objectives for a decomposition is to estimate seasonal effects that can be used to create and present seasonally adjusted values [
39]. One of the strengths of the ANNs is their ability to infer nonlinear relationships between the input and the output [
40], as ANN leverage on a nonlinear activation function, therefore a simple correlation analysis and moving average decomposition approach [
41] has been adopted, reported in (
5).
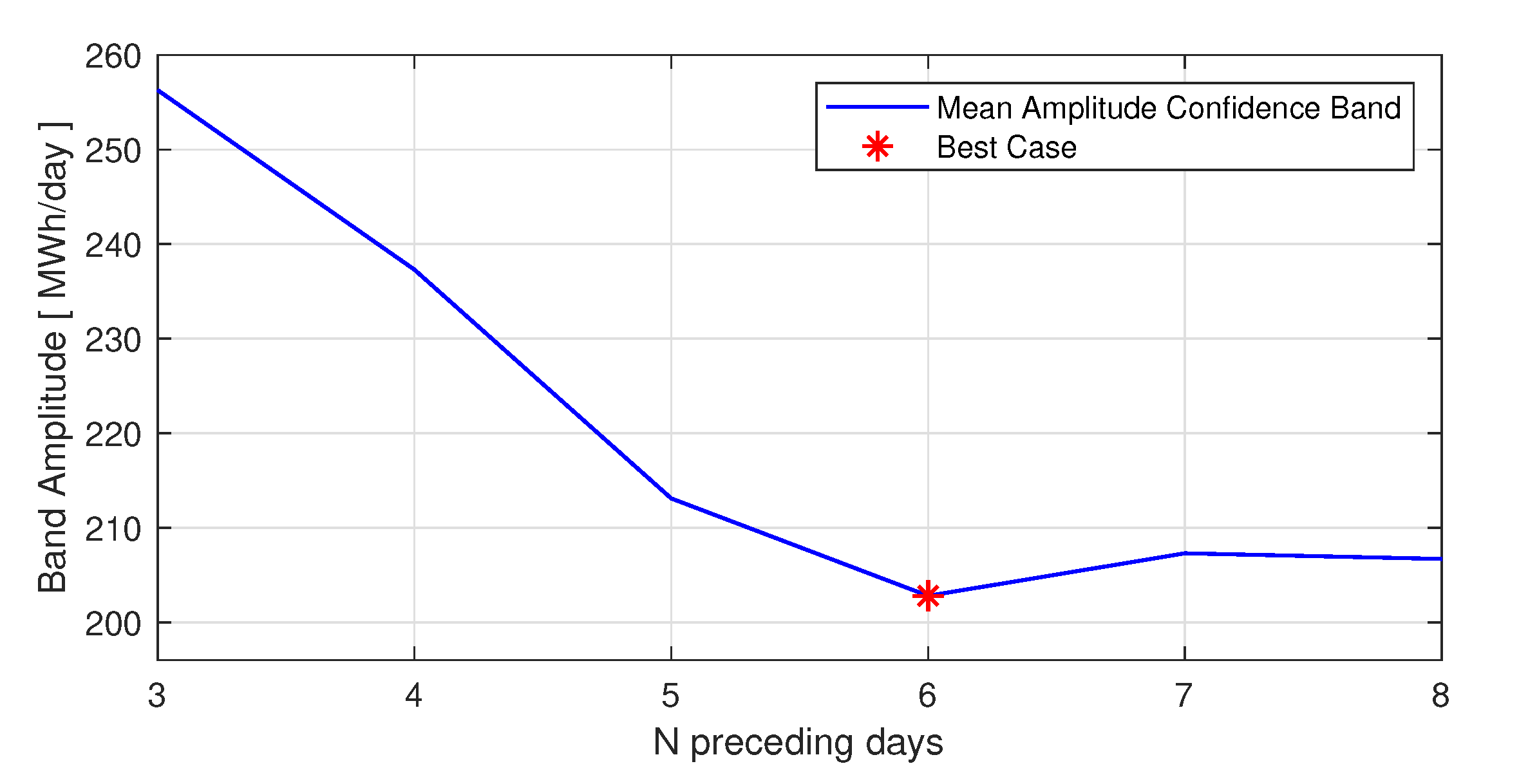
The trend is detected by applying an asymmetrical moving average, with a moving window referred to the past “N” days, thus a methodology that allows to find the best number of past days to apply the moving average is investigated. A statistical approach exploiting confidence interval is adopted. In particular, an adaptive confidence band is implemented, where the band is time-variant and it is computed on the basis of the “N” past days. The objective is to find what is the number such that the 90% of the real data are contained in the confidence band and which of these numbers guarantee the smaller band. At first, it is extracted the trend, applying the mean of the
N past samples, for each day
D of the dataset, where
Observed is the real production dataset and
D is the number of samples (from 1 to 366) (
6). Subsequently it is computed the error, defined as the difference between the real production and the extracted trend, evaluated from the preceding
N days to the day
D (
7). Finally, on the basis of the standard deviation
of the error, proportional to the error committed in the past
N days, it is found the confidence band amplitude.
C is a multiplicative factor to guarantee the inclusion of 90% of real data in the confidence band (
8). For the sake of simplicity the value of “N” preceding days varies from 3 to 8.
The number of samples to be included in the moving average has been set equal to 6 days, according to the sensitivity analysis led (
Figure 5).
The difference between the starting (
) time series and the new trend function (
) is called
Ripple (
9) and it contains the sum of the seasonal and residuals components.
The ripple dataset is then divided in many subsets as the amplitude of the window moving average, 7 in our case (6 previous days plus the day to be forecast), forming 7 datasets containing the ripple component of every day of the week along the whole dataset, as exemplified in (
10).
To obtain the seasonal component, the arithmetic mean of each
subset is performed (
11). The seasonality dataset is made by 7 terms repeated periodically, being the average value of the deviation between the real production and the trend.
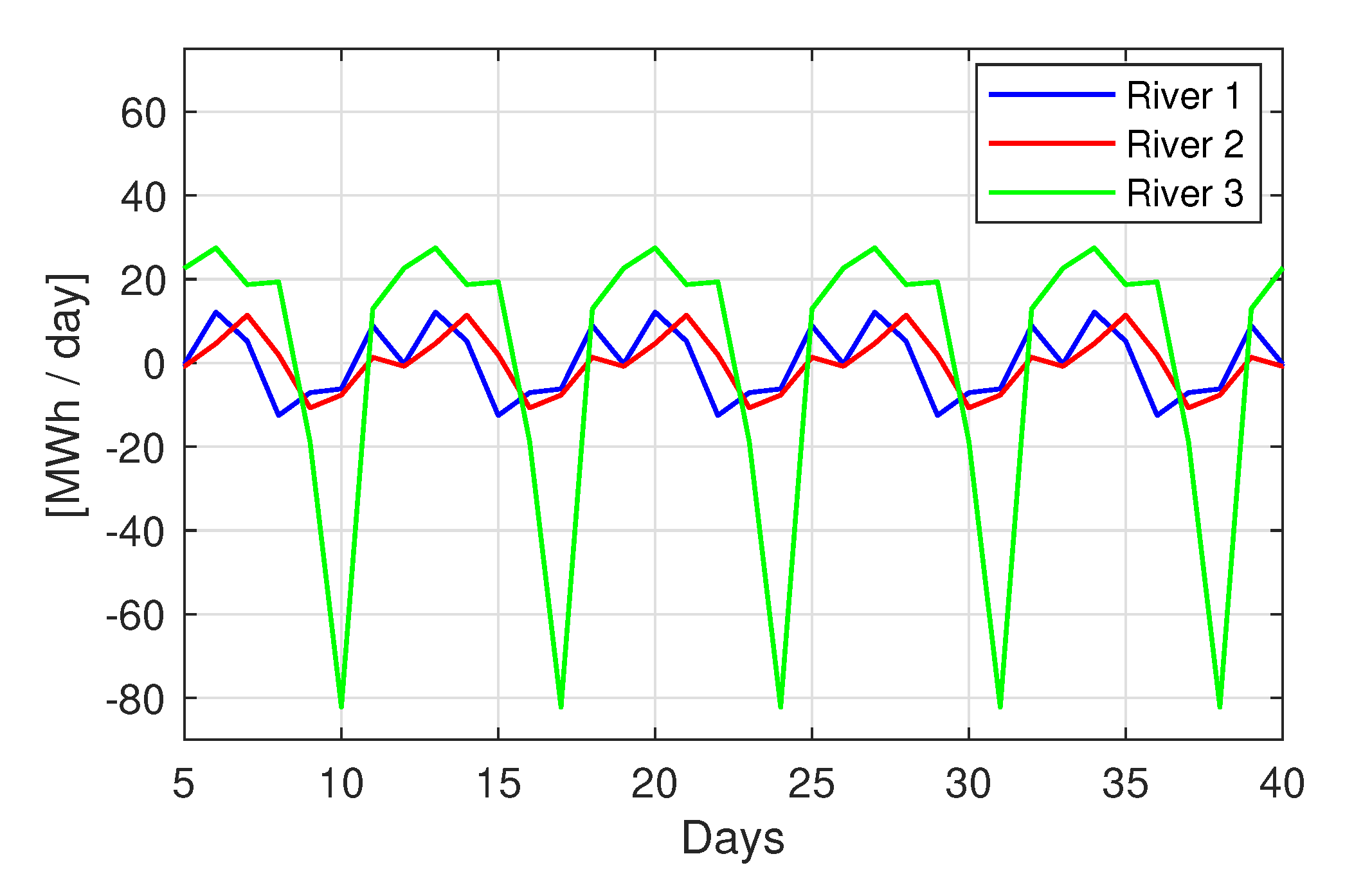
It is important to underline that “seasonal” refers to a “statistical seasonality”. In
Figure 6, the seasonal component of three power plants on the three different rivers is represented. The plant on river 3 is characterized by an amplitude in the seasonality profile more stressed than in the other two, therefore it is reasonable to expect that this plant will benefit more than the other two from a decomposition approach.
The remaining component is the
residual which contains information about the “irregularities” found in the time-series decomposition.
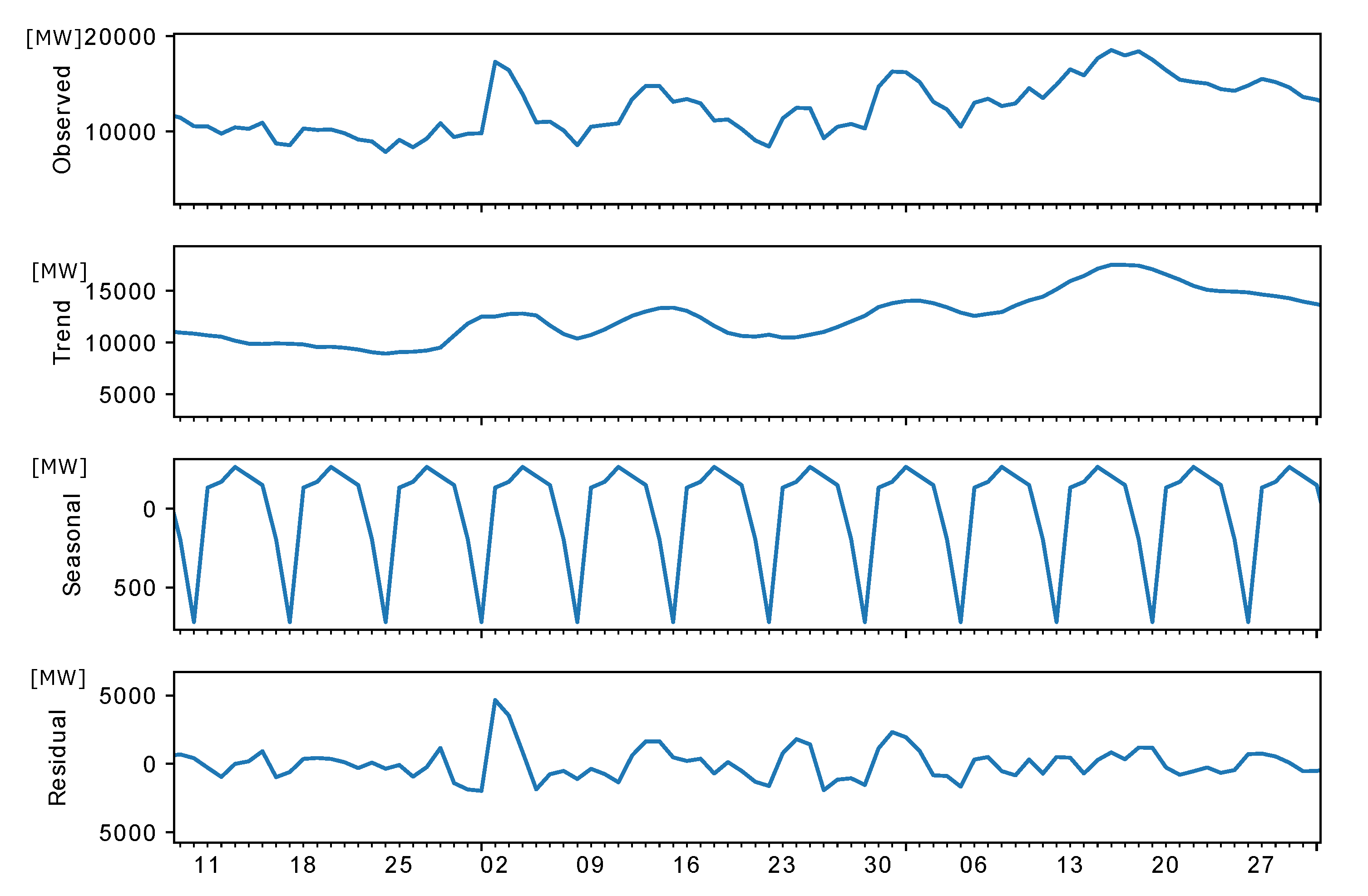
Figure 7 shows graphically the extraction of the three components from the observed production of a selected plant. It is evident how the trend is characterized by a smoother profile, with less noise, while the residual absorbs all the “irregularities”. The seasonal component is used to analyze and understand the dynamics of the electric production and the behavior of the river on which the hydroplant lies. To apply the above described decomposition it is exploited the Python function seasonal-decompose, imported from the “statsmodel” library (which is taken from the “stats” package of R language).
On top of the obtained decomposition, the training of the ANN can be set. The novel hybrid approach proposed is characterized by two ANNs having as output layer the
trend in one case and the
residuals in the other, which will be then summed up to the seasonality component previously extracted to recompose the function, according to (
5).
A preliminary analysis is conducted in order to assess the order of magnitude of the main parameters of the network: the size of the training set, the number of hidden layers, and the number of neurons in each hidden layer [
42,
43]. A hyperparameter optimization is performed varying the training set size and the number of neurons, selecting the combination of parameters that minimizes MAE. The number of neurons is assumed varying in the range [2,40] with step 2.
The three models selected for the comparison undertook themselves a hyper-parameter optimization to properly design their structure.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









