
RETRACTED: Express Data Processing on FPGA: Network Interface Cards for Streamlined Software Inspection for Packet Processing

 ,
,  , ,
, ,
Abstract
:1. Introduction
- A.
- A compiler for the enhanced hXDP ISA that converts the bytecode of XDP applications;
- B.
- An independent is a block of logic or data that is used in making field programme gateway arrays or is application specific with various low-level optimizations;
- C.
- The tool chain mechanism, which is dynamic at run time, loads a library and communicates for data path programmes, handles the acceleration tasks, and passes to NIC devices for additional processing.
Conception
- It must run compiled XDP programmes without modification and, therefore, must support the provided coverage foundations’ tool chain, providing immense contribution to reloading and user-mode access to maps.
- Performance for processing packets ought to be at least on par with top-tier processing packets.
- It can be utilized only for the small portion of the hardware in the FPGA.
2. Materials and Methods
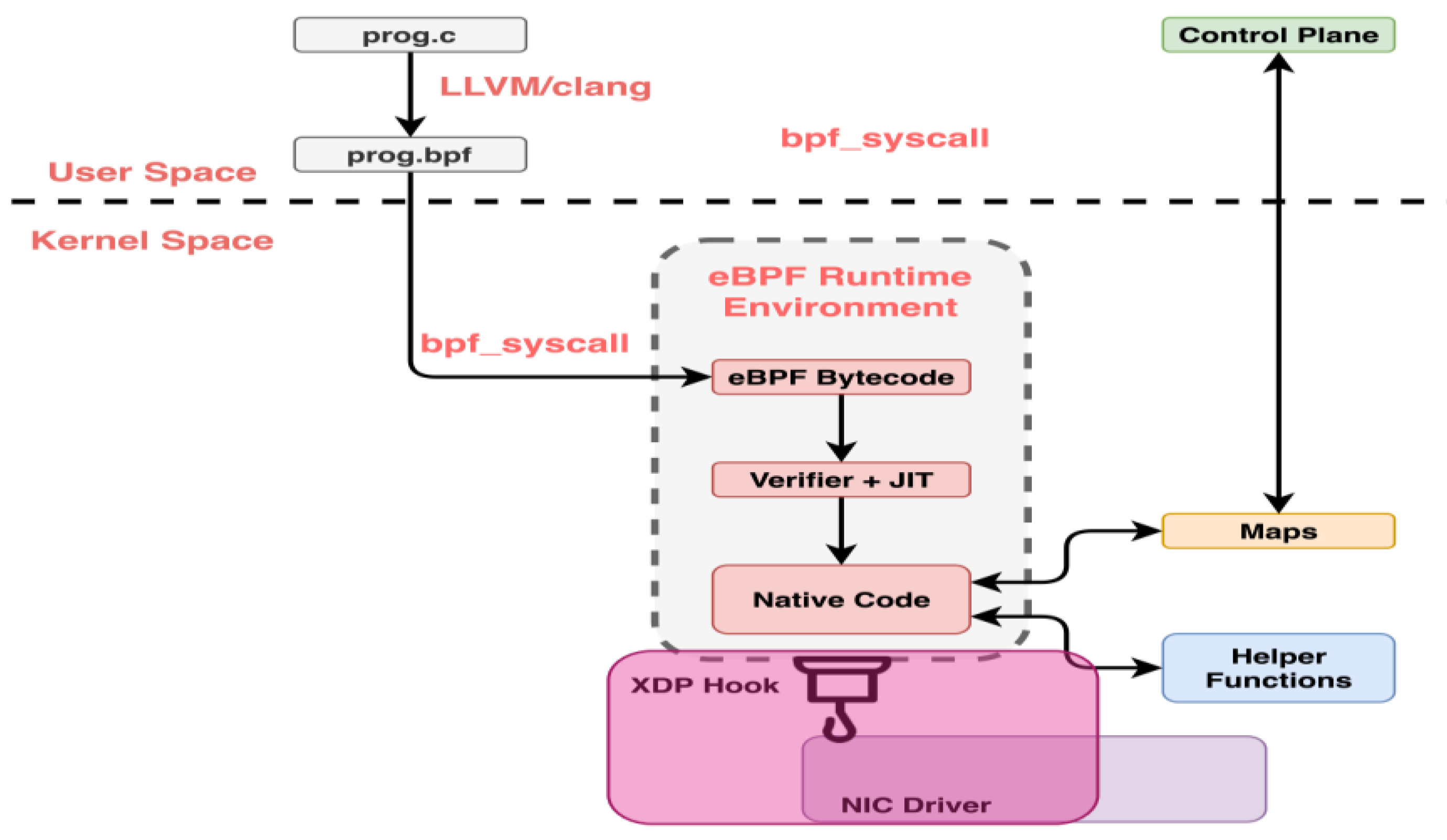
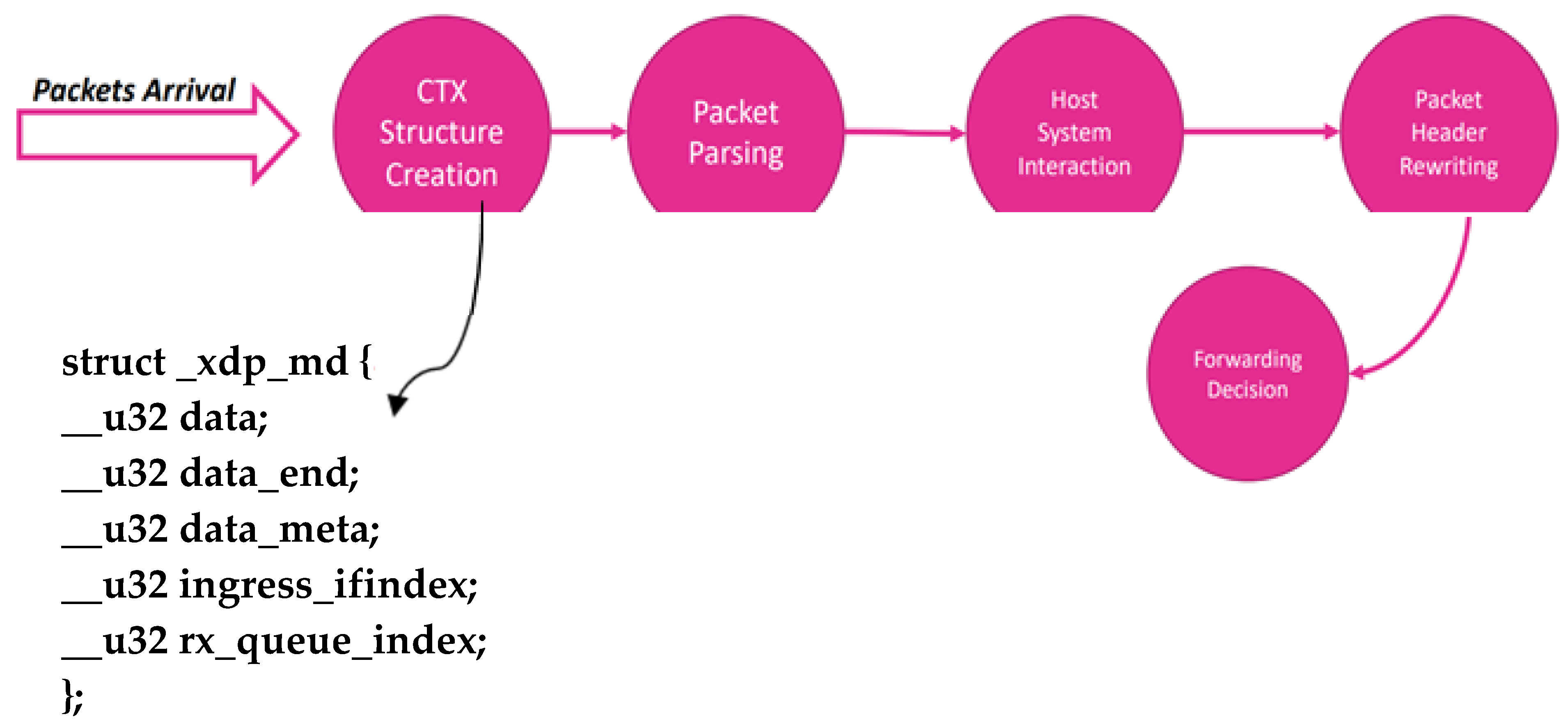
2.1. Xdp
- (a)
- r0 stores the return value from in-kernel programmes.
- (b)
- r1, r2, r3, r4, r5 function as the parameters supplied to in-kernel functions.
- (c)
- Holding address throughout control and arguments at r6, r7, r8, r9.
- (d)
- Accessing the stack using the frame pointer, r10.
- (e)
- The standard instruction set architecture that made over a hundred packed frame lengths is present in the eBPF virtual machine.
2.2. Challenges
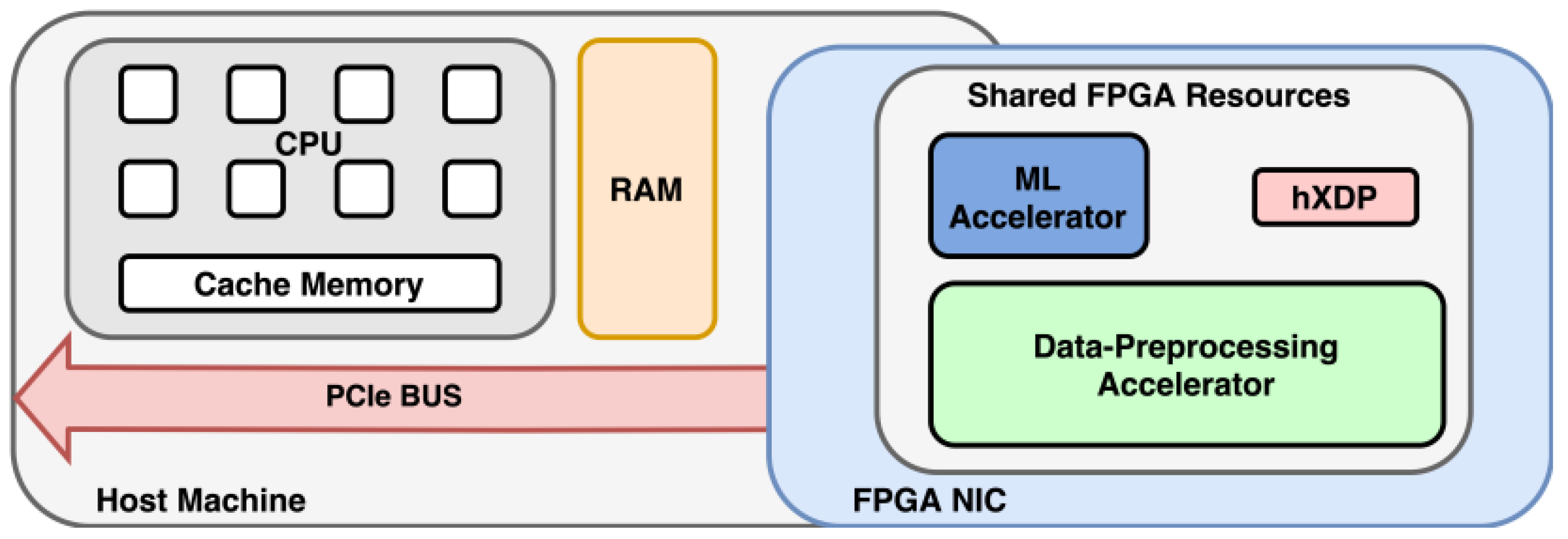
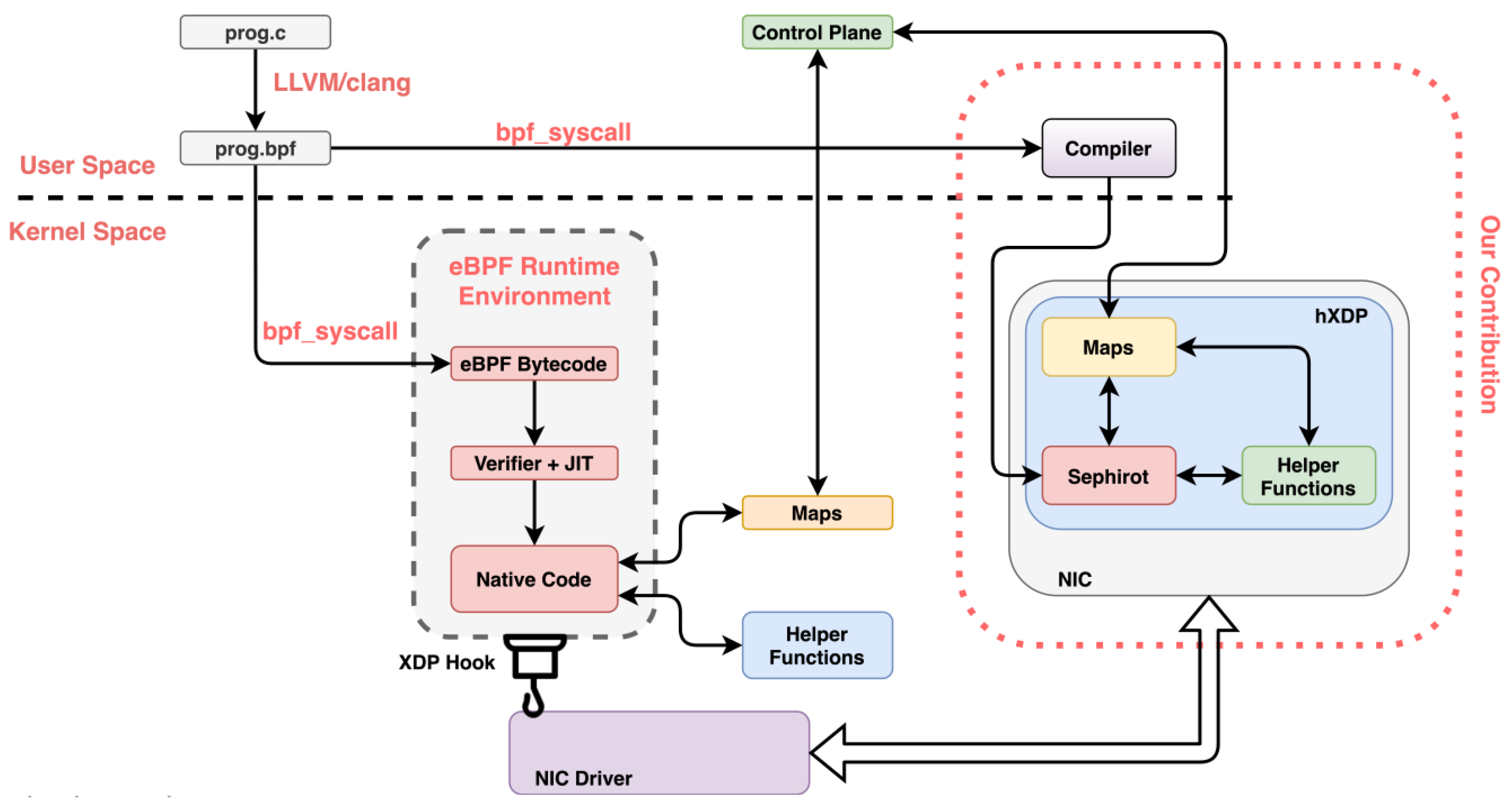
2.3. hXDP Overview
2.4. hXdp Complier
2.5. Hardware Module
- (a)
- Input Queue (PIQ);
- (b)
- eBPF runtime environment;
- (c)
- Embedded packet capture (epc);
- (d)
- Sephirot hardware and software;
- (e)
- Helper functions.
2.6. PIPE LINE
3. Hardware Functionality
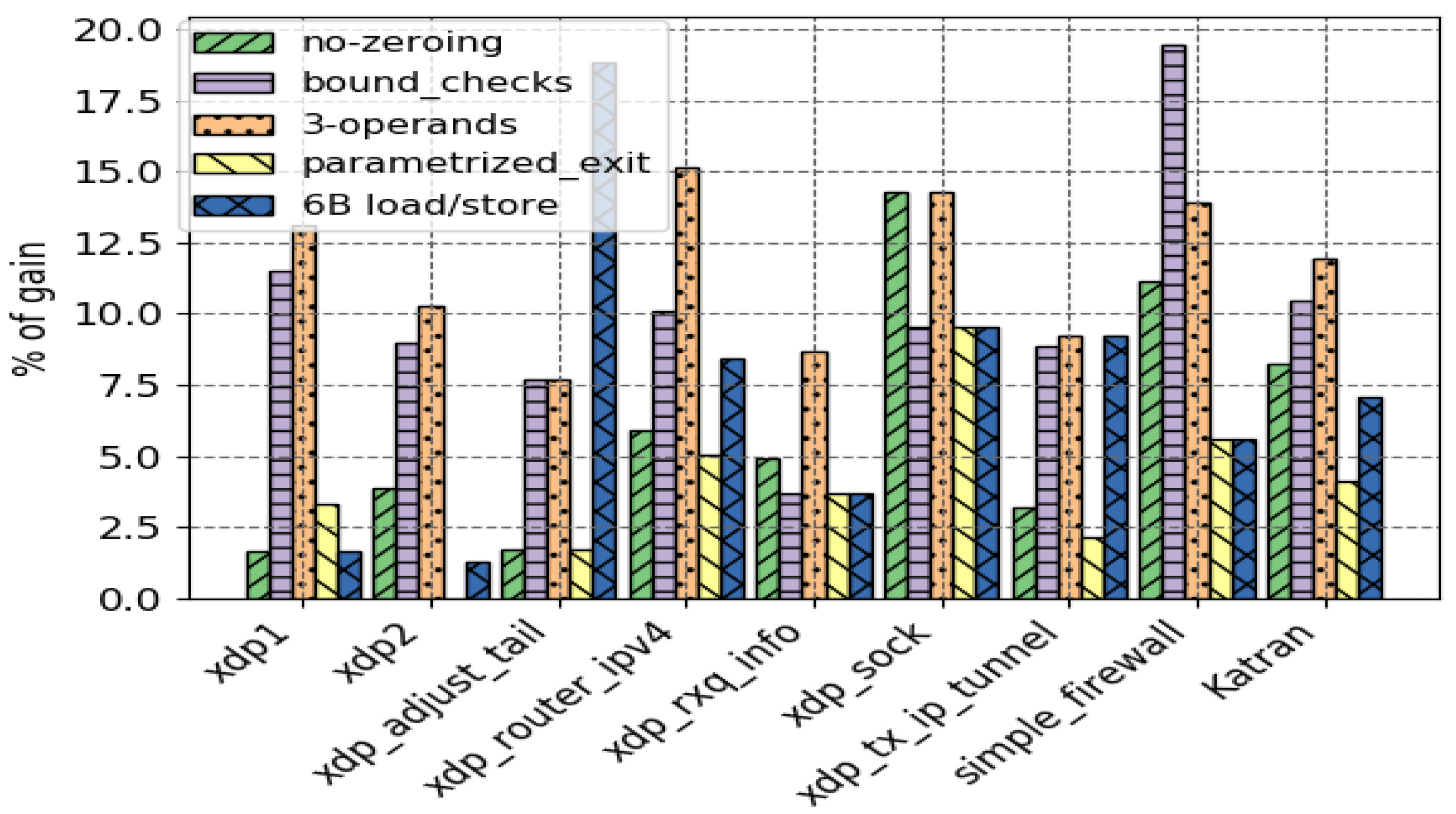
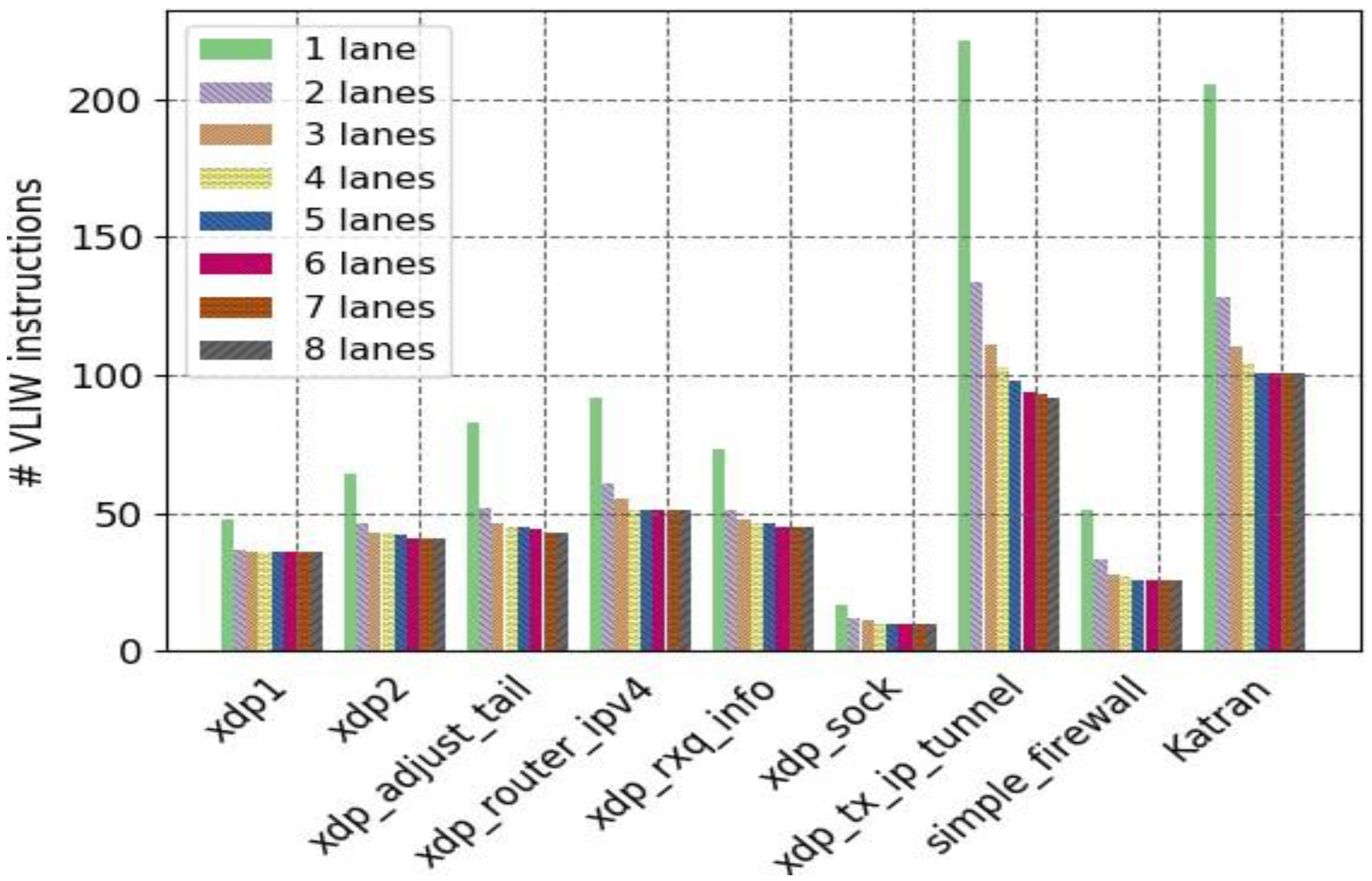
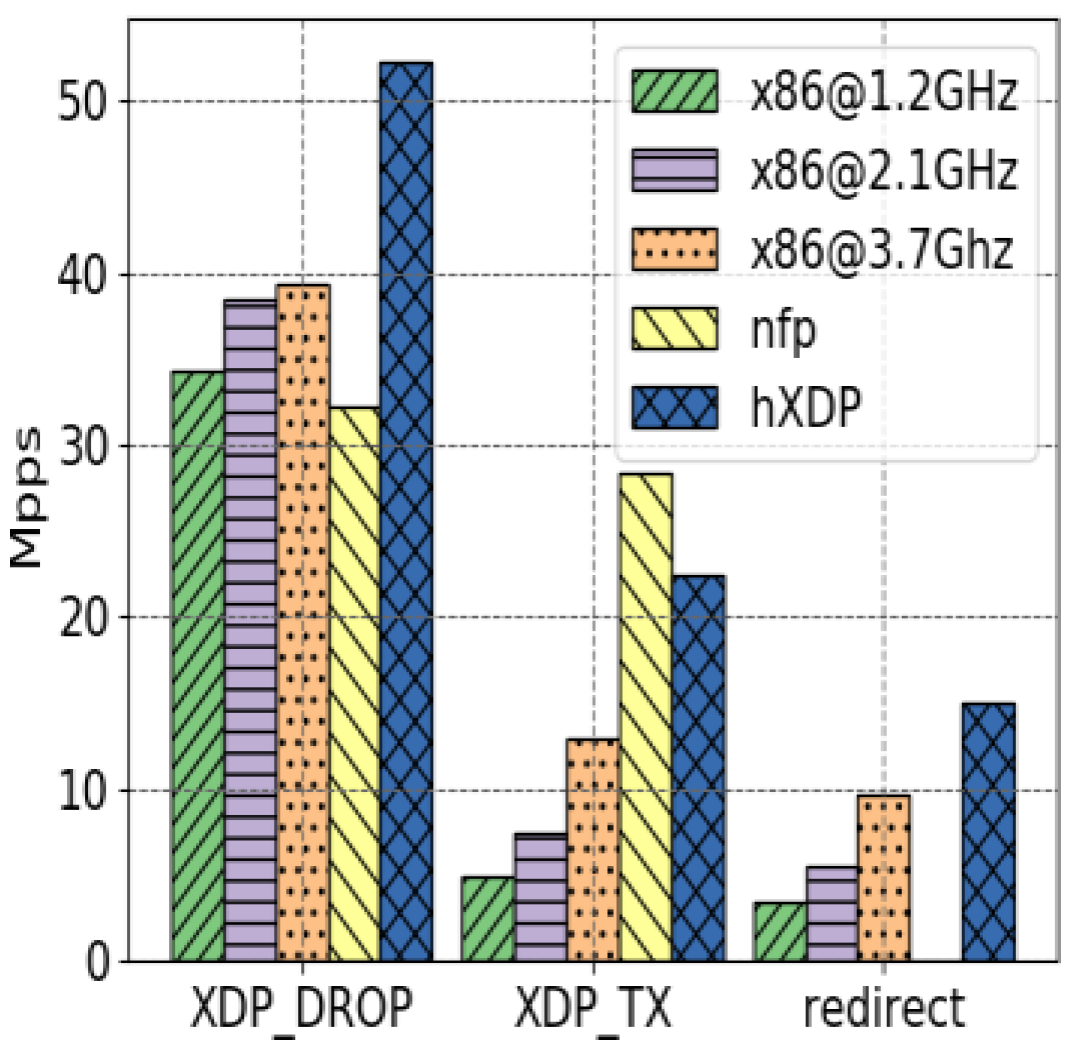
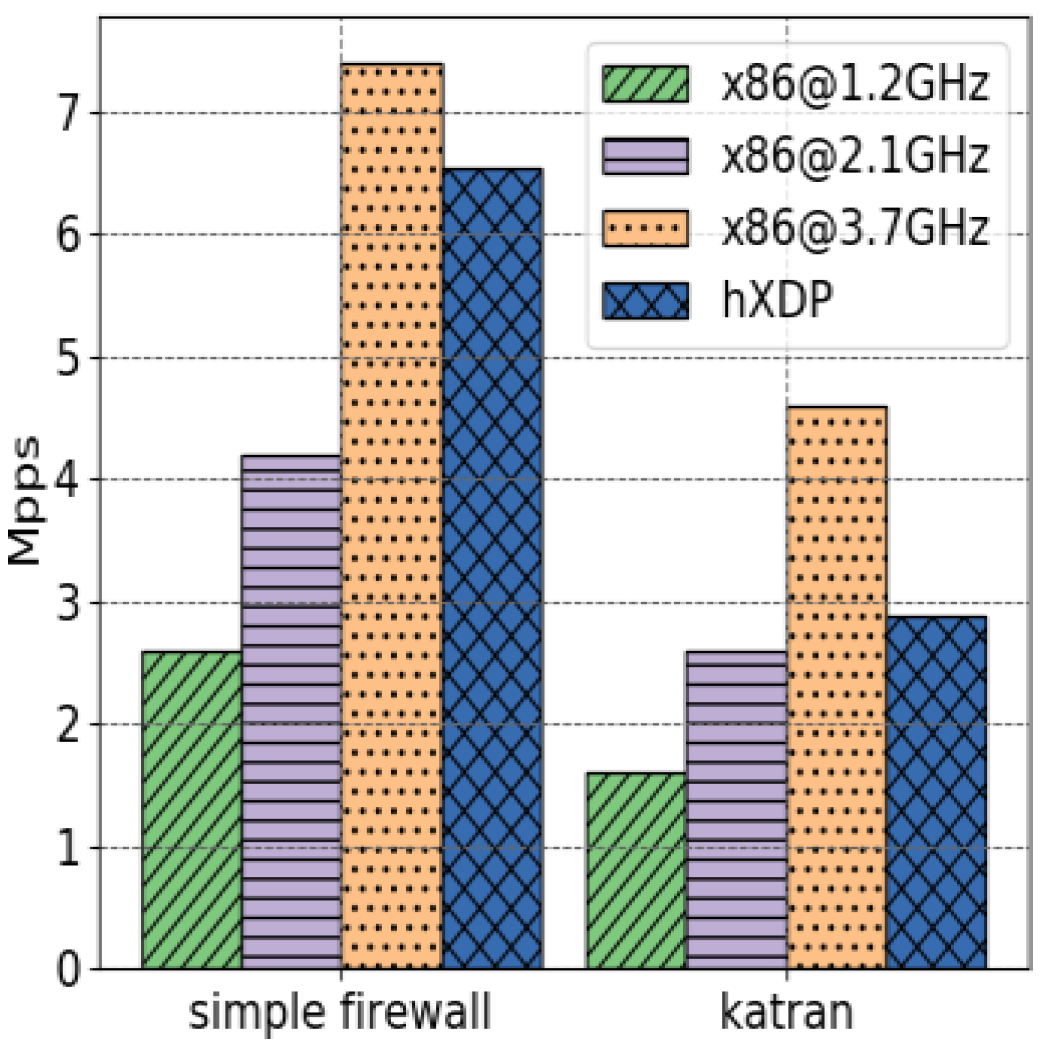
4. Evaluation and Results
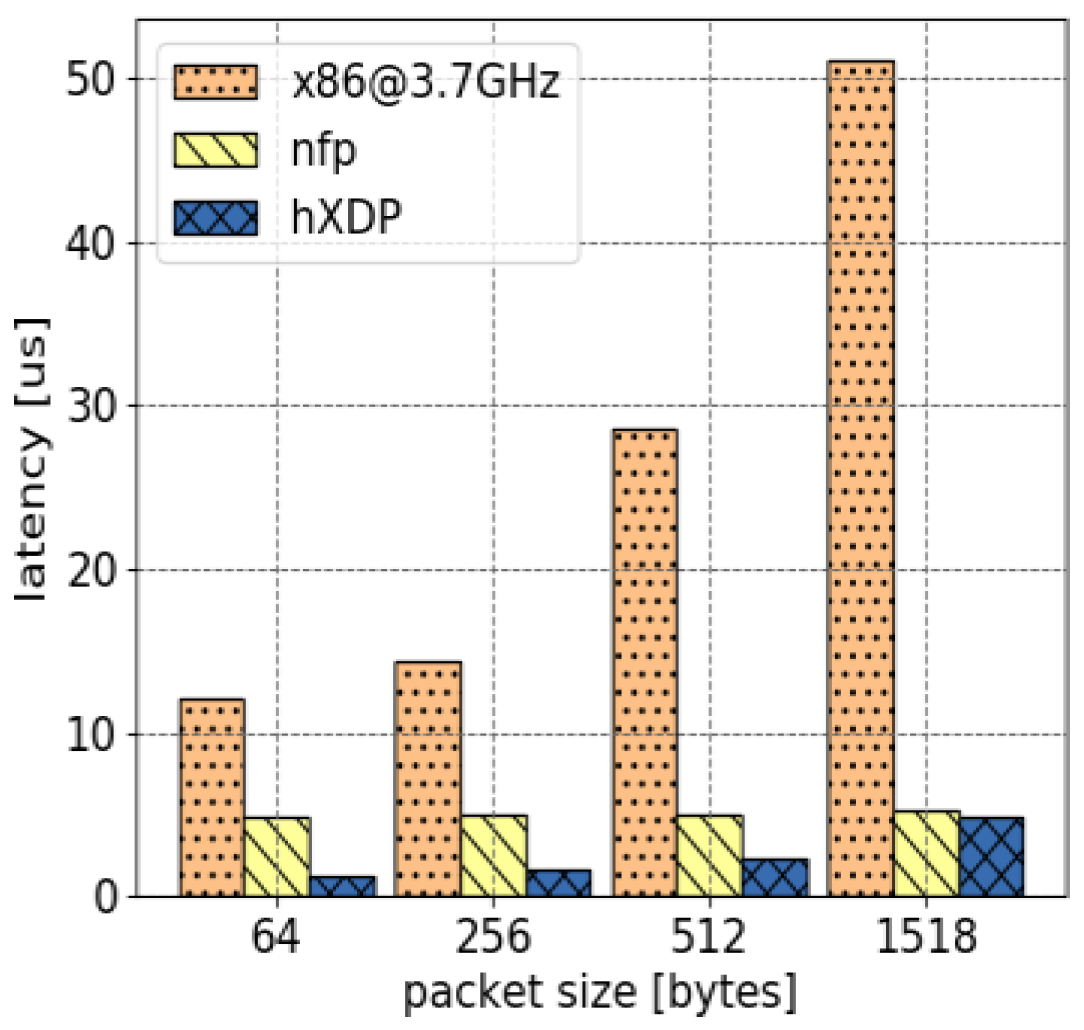
4.1. Test Results
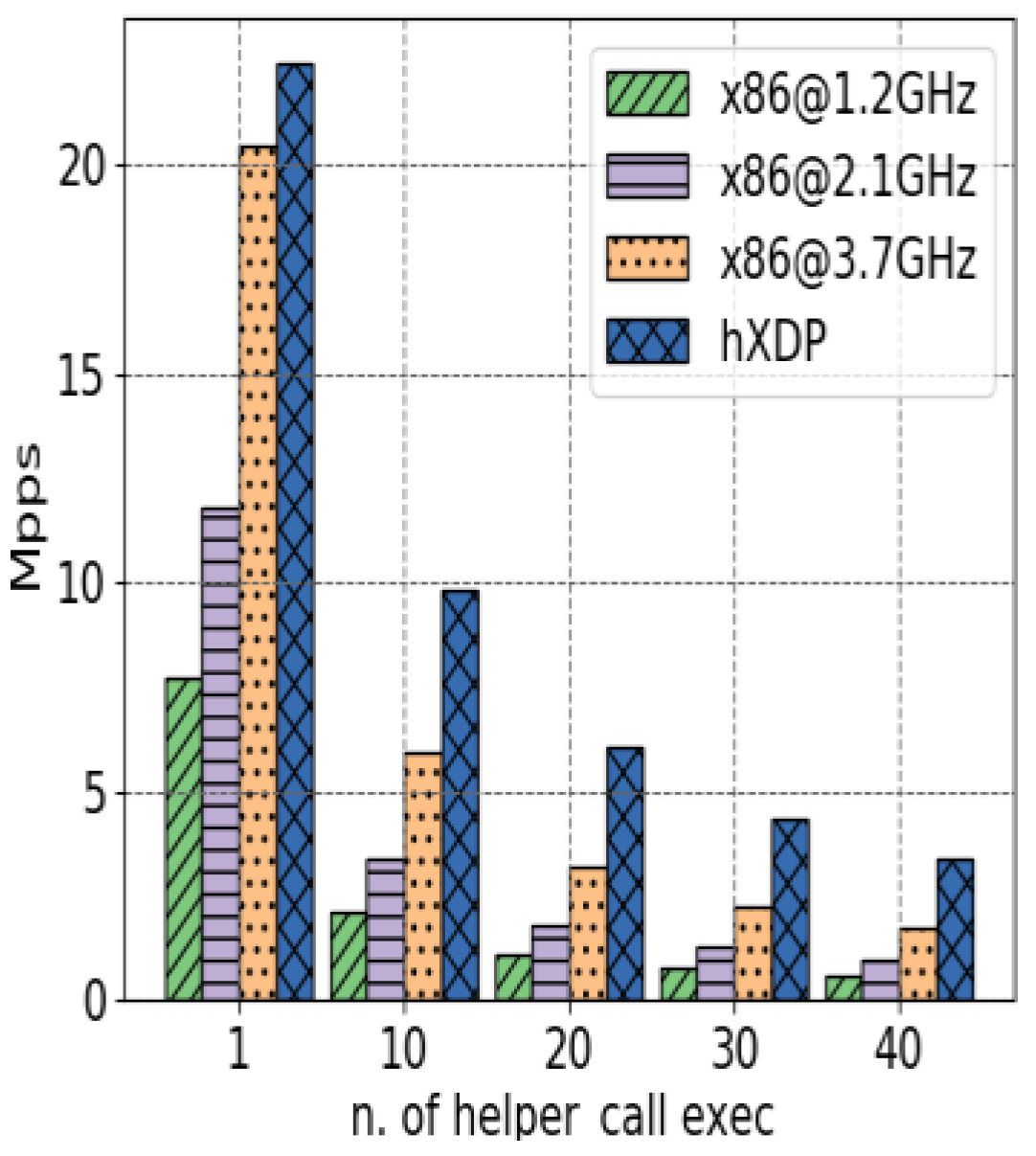
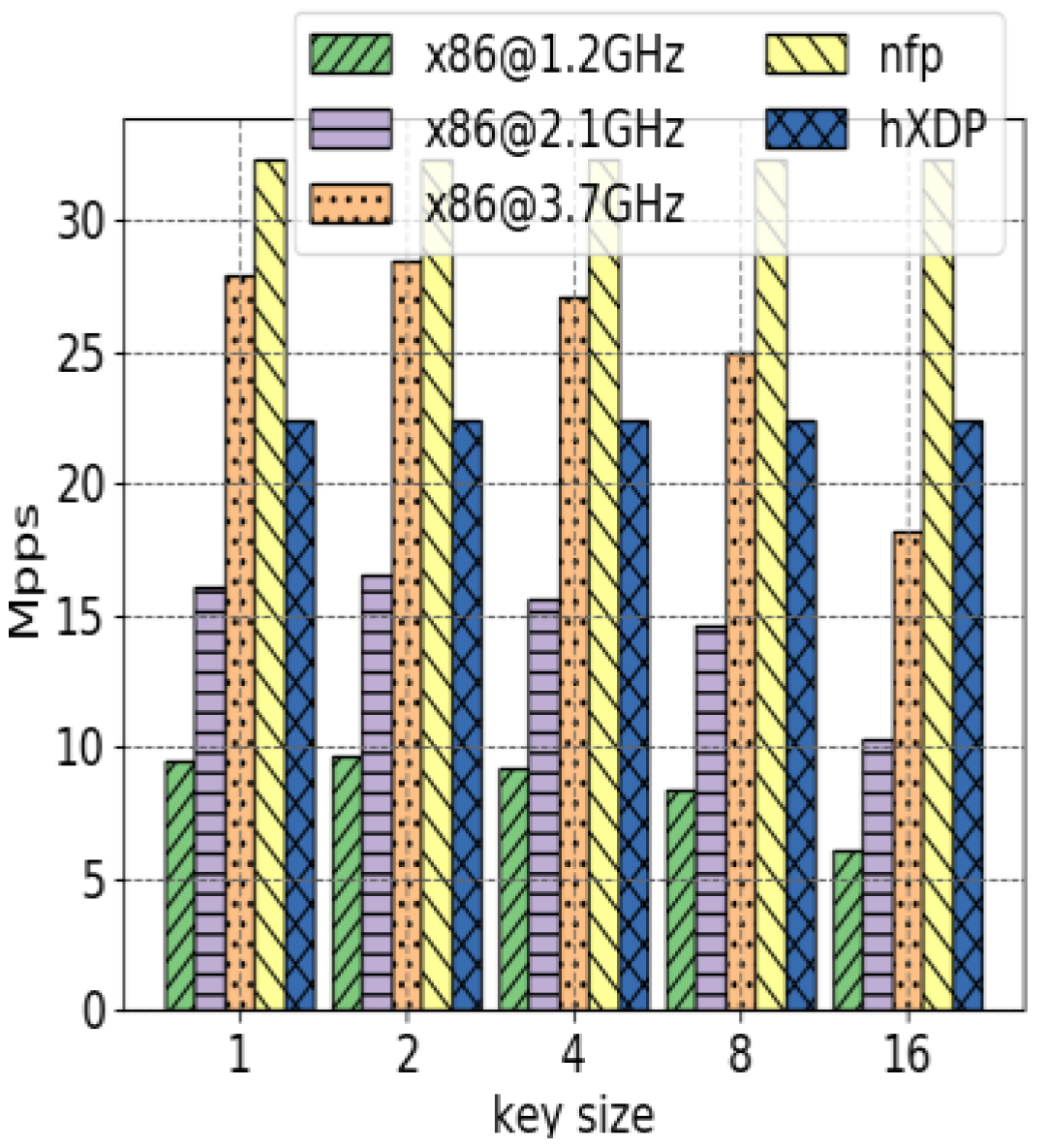
4.2. Application Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| hXdp | Linux Express Data Path |
| XDP | Express Data path |
| FPGA | Filed programmed gateway array |
| NIC | Network Interface Cards |
| VERY LONG INSTRUCTION WORD | Very Long Instruction Word |
| Ebpf | Extended Berkeley Packet Filter |
References
- P4-NetFPGA. Available online: https://github.com/NetFPGA/P4-NetFPGA-public/wiki14-oct-21 (accessed on 25 December 2022).
- Bernstein, A.J. Analysis of programs for parallel processing. IEEE Trans. Electron. Comput. 1966, 15, 757–763. [Google Scholar] [CrossRef]
- Bosshart, P.; Daly, D.; Gibb, G.; Izzard, M.; McKeown, N.; Rexford, J.; Schlesinger, C.; Talayco, D.; Vahdat, A.; Varghese, G.; et al. P4: Programming protocol-independent packet processors. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 87–95. [Google Scholar] [CrossRef]
- Bosshart, P.; Gibb, G.; Kim, H.-S.; Varghese, G.; McKeown, N.; Izzard, M.; Mujica, F.; Horowitz, M. Forwarding metamorphosis: Fast programmable match-action processing in hardware for sdn. In Proceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM, SIGCOMM ’13, Hong Kong, China, 12–16 August 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 99–110. [Google Scholar]
- Brunella, M.S.; Pontarelli, S.; Bonola, M.; Bianchi, G. V-PMP: A VERY LONG INSTRUCTION WORD packet manipulator processor. In Proceedings of the 2018 European Conference on Networks and Communications (EuCNC), Ljubljiana, Slovenia, 18–21 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–9. [Google Scholar]
- Caulfield, A.M.; Chung, E.S.; Putnam, A.; Angepat, H.; Fowers, J.; Haselman, M.; Heil, S.; Humphrey, M.; Kaur, P.; Kim, J.; et al. A cloud-scale acceleration architecture. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–13. [Google Scholar]
- Chen, T.; Moreau, T.; Jiang, Z.; Zheng, L.; Yan, E.; Shen, H.; Cowan, M.; Wang, L.; Hu, Y.; Ceze, L.; et al. TVM: An automated end-to-end optimizing compiler for deep learning. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), Carlsbad, CA, USA, 8–10 October 2018; USENIX Association: Berkeley, CA, USA, 2018; pp. 578–594. [Google Scholar]
- Chiou, D. The microsoft catapult project. In Proceedings of the 2017 IEEE International Symposium on Workload Characterization (IISWC), Seattle, WA, USA, 1–3 October 2017; p. 124. [Google Scholar]
- Dumitru, M.V.; Dumitrescu, D.; Raiciu, C. Can we exploit buggy p4 programs? In Proceedings of the Symposium on SDN Research, SOSR ‘20, San Jose, CA, USA, 3 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 62–68. [Google Scholar]
- Facebook. Katran Source Code Repository. 2018. Available online: https://github.com/facebookincubator/katran (accessed on 25 December 2022).
- Firestone, D.; Putnam, A.; Mundkur, S.; Chiou, D.; Dabagh, A.; Andrewartha, M.; Angepat, H.; Bhanu, V.; Caulfield, A.; Chung, E.; et al. Azure accelerated networking: Smartnics in the public cloud. In Proceedings of the 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), Renton, WA, USA, 9–11 April 2018; USENIX Association: Berkeley, CA, USA, 2018; pp. 51–66. [Google Scholar]
- FlowBlaze. Repository with FlowBlaze Source Code and Additional Material. Available online: http://axbryd.com/FlowBlaze.html (accessed on 25 December 2022).
- Forencich, A.; Snoeren, A.C.; Porter, G.; Papen, G. Corundum: An open-source 100-Gbps NIC. In Proceedings of the 28th IEEE International Symposium on Field-Programmable Custom Computing Machines, Boulder, CO, USA, 29 April–1 May 2020. [Google Scholar]
- Gautschi, M.; Schiavone, P.D.; Traber, A.; Loi, I.; Pullini, A.; Rossi, D.; Flamand, E.; Gürkaynak, F.K.; Benini, L. Near-threshold risc-v core with dsp extensions for scalable iot endpoint devices. IEEE Trans. Very Large Scale Integr. VLSI Syst 2017, 25, 2700–2713. [Google Scholar] [CrossRef]
- Hazelwood, K.; Bird, S.; Brooks, D.; Chintala, S.; Diril, U.; Dzhulgakov, D.; Fawzy, M.; Jia, B.; Jia, Y.; Kalro, A.; et al. Applied machine learning at Facebook: A datacenter infrastructure perspective. In Proceedings of the High Performance Computer Architecture (HPCA), Vienna, Austria, 24–28 February 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Heinz, C.; Lavan, Y.; Hofmann, J.; Koch, A. A catalog and in-hardware evaluation of open-source drop-in compatible risc-v softcore processors. In Proceedings of the 2019 International Conference on ReConFigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 9–11 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Hennessy, J.L.; Patterson, D.A. A new golden age for computer architecture. Commun. ACM 2019, 62, 48–60. [Google Scholar] [CrossRef]
- Hohlfeld, O.; Krude, J.; Reelfs, J.H.; Rüth, J.; Wehrle, K. Demystifying the performance of XDP BPF. In Proceedings of the 2019 IEEE Conference on Network Softwarization (NetSoft), Paris, France, 24–28 June 2019; pp. 208–212. [Google Scholar]
- Høiland-Jørgensen, T.; Brouer, J.D.; Borkmann, D.; Fastabend, J.; Herbert, T.; Ahern, D.; Miller, D. The express data path: Fast programmable packet processing in the operating system kernel. In Proceedings of the 14th International Conference on Emerging Networking EXperiments and Technologies, CoNEXT ’18, Heraklion, Greece, 4–7 December 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 54–66. [Google Scholar]
- Intel. 5G Wireless. 2020. Available online: https://www.intel.com/content/www/us/en/communications/products/programmable/applications/baseband.html (accessed on 25 December 2022).
- Iseli, C.; Sanchez, E. Spyder: A reconfigurable Very Long Instruction Word processor using FPGAs. In Proceedings of the IEEE Workshop on FPGAs for Custom Computing Machines, Napa, CA, USA, 5–7 April 1993; IEEE: Piscataway, NJ, USA, 1993; pp. 17–24. [Google Scholar]
- Jones, A.K.; Hoare, R.; Kusic, D.; Fazekas, J.; Foster, J. An fpga-based Very Long Instruction Word processor with cust om hardware execution. In Proceedings of the 2005 ACM/SIGDA 13th International Symposium on Field-Programmable Gate Arrays, FPGA ’05, Monterey, CA, USA, 20–22 February 2005; Association for Computing Machinery: New York, NY, USA, 2005; pp. 107–117. [Google Scholar]
- Kaufmann, A.; Peter, S.; Anderson, T.; Krishnamurthy, A. Flexnic: Rethinking network DMA. In Proceedings of the 15th Workshop on Hot Topics in Operating Systems (HotOS XV), Kartause Ittingen, Switzerland, 18–20 May 2015; USENIX Association: Berkeley, CA, USA, 2015. [Google Scholar]
- Kicinski, J.; Viljoen, N. eBPF hardware offload to SmartNICs: Cls bpf and XDP. Proc. Netdev 2016, 1, 1–6. [Google Scholar]
- Michel, O.; Bifulco, R.; Rétvári, G.; Schmid, S. The programmable data plane: Abstractions, architectures, algorithms, and applications. ACM Comput. Surv. 2021, 54, 1–36. [Google Scholar] [CrossRef]
- NEC Building an Open vRAN Ecosystem White Paper. 2020. Available online: https://www.nec.com/en/global/solutions/5g/index.html (accessed on 25 December 2022).
- Netronome. AgilioTM CX 2x40GbE Intelligent Server Adapter. Available online: https://www.netronome.com/media/redactor_files/PB_Agilio_CX_2x40GbE.pdf (accessed on 25 December 2022).
- Pontarelli, S.; Bifulco, R.; Bonola, M.; Cascone, C.; Spaziani, M.; Bruschi, V.; Sanvito, D.; Siracusano, G.; Capone, A.; Honda, M.; et al. Flowblaze: Stateful packet processing in hardware. In Proceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19), Boston, MA, USA, 26–28 February 2019; USENIX Association: Berkeley, CA, USA, 2019; pp. 531–548. [Google Scholar]
- Sultana, N.; Galea, S.; Greaves, D.; Wojcik, M.; Shipton, J.; Clegg, R.; Mai, L.; Bressana, P.; Soulé, R.; Mortier, R.; et al. Emu: Rapid prototyping of networking services. In Proceedings of the 2017 USENIX Annual Technical Conference (USENIX ATC 17), Santa Clara, CA, USA, 12–14 July 2017; USENIX Association: Berkeley, CA, USA, 2017; pp. 459–471. [Google Scholar]
- Wang, H.; Soulé, R.; Dang, H.T.; Lee, K.S.; Shrivastav, V.; Foster, N.; Weatherspoon, H. P4fpga: A rapid prototyping framework for p4. In Proceedings of the Symposium on SDN Research, SOSR ’17, Santa Clara, CA, USA, 3–4 April 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 122–135. [Google Scholar]
- Xilinx. 5G Wireless Solutions Powered by Xilinx. 2020. Available online: https://www.xilinx.com/applications/megatrends/5g.html (accessed on 25 December 2022).
- Zilberman, N.; Audzevich, Y.; Covington, G.A.; Moore, A.W. NetFPGA SUME: Toward 100 Gbps as Research Commodity. IEEE Micro 2014, 34, 32–41. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S No. | Abbreviation | Processor | Description |
|---|---|---|---|
| 1 | ASIC s | Application Specific Integrated Circuits | The most efficient devices are those that are specifically designed, like Google’s Tensor Processor Units (TPU). They cannot be changed to suit your changing demands. |
| 2 | GPU s | Graphics Processing Units | A common option for AI calculations. GPUs are faster at rendering images than CPUs because they can perform parallel processing. |
| 3 | CPU s | Central Processing Unit | CPUs are general-purpose processes but have subpar performance for processing graphics and video. |
| 4 | FPGA s | Field-Programmable Gate Arrays | The performance of FPGAs is comparable to that of ASICs, such as those offered on Azure. In order to include new logic, they are also adaptable and re-configurable throughout time. |
| S No. | Type | Model | Processor |
|---|---|---|---|
| 1 | Intel | XL 710 | 2.1 |
| 2 | Intel | I40 e | 3.7 |
| 3 | Xeon | X5670 | 3.6 |
| Program | Description |
|---|---|
| xdp1 | Parse pkt headers up to IP and XDP _DROP |
| Xdp2 | Parse pkt headers up to IP and XDP _TX |
| Xdp_adjust_tail | Receive pkt, modify pkt into ICMP pkt and XDP _TX |
| Router _ipv4 | Parse pkt headers up to IP, look up in routing table and forward (redirect) |
| Rxq_info(drop) | Increment counter and XDP _DROP |
| Rxq_info(tx) | Increment counter and XDP _TX |
| tx_ip_tunnel | Parse pkt up to L4, Encapsulate and XDP_TX |
| Redirect(map) | Output pkt from a specified interface (redirect) |
| S No. | Program | Instruction | X86 | hXdp |
|---|---|---|---|---|
| 1 | Xdp1 | 77 | 2.18 | 1.65 |
| 2 | Xdp 2 | 60 | 2.22 | 1.69 |
| 3 | Xdp tail | 115 | 2.32 | 2.69 |
| 4 | Ipv4 | 117 | 2.31 | 2.31 |
| 5 | rxq info | 80 | 2.74 | 1.75 |
| 6 | Ip | 281 | 2.34 | 2.76 |
| 7 | Katran | 267 | 2.31 | 2.61 |
| 8 | Firewall | 70 | 2.28 | 2.55 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pradeep, S.; Sharma, Y.K.; Verma, C.; Sreeram, G.; Hanumantha Rao, P. RETRACTED: Express Data Processing on FPGA: Network Interface Cards for Streamlined Software Inspection for Packet Processing. Appl. Syst. Innov. 2023, 6, 9. https://doi.org/10.3390/asi6010009
Pradeep S, Sharma YK, Verma C, Sreeram G, Hanumantha Rao P. RETRACTED: Express Data Processing on FPGA: Network Interface Cards for Streamlined Software Inspection for Packet Processing. Applied System Innovation. 2023; 6(1):9. https://doi.org/10.3390/asi6010009
Chicago/Turabian StylePradeep, Sunkari, Yogesh Kumar Sharma, Chaman Verma, Gutha Sreeram, and Panugati Hanumantha Rao. 2023. "RETRACTED: Express Data Processing on FPGA: Network Interface Cards for Streamlined Software Inspection for Packet Processing" Applied System Innovation 6, no. 1: 9. https://doi.org/10.3390/asi6010009