3.3.1. Natural Language Processing
The first experiment concerned natural language processing (NLP) as NLP techniques were useful for the data pre-processing phase. The Spam Classification for Basic NLP dataset from Kaggle [
27] was used for the NLP experiment. This dataset contained spam messages which included useful features such as IP addresses and URLs, and it was a text-based dataset so various NLP techniques could be experimented with.
There were three Python libraries considered for ascertaining the most suitable library for this research problem: NLTK, Spacy and Gensim. As accuracy and precision could not be used as performance metrics for the NLP experiment, two factors were considered when electing the most suitable Python library for NLP-based tasks. The first factor was how many of the chosen NLP techniques each Python library could complete, and the second factor was how quickly the techniques could be applied to the dataset.
In a similar approach to Banu et al. [
2] and Alhogail and Alsabih [
12], this research used tokenization as its main NLP technique. Tokenization was used to split the dataset into tokens, which made it easier to observe whether words synonymous with phishing and spam emails were present in the dataset. Bountakas, Koutroumpouchos and Xenakis [
6] identified POS tagging as a task that facilitated lemmatization, which was considered the core of the pre-processing task whereas Banu et al. [
2] and Verma Shashidhar and Hossain [
18] used stemming to process text in emails. Removing stopwords has been widely used as a technique in phishing and spam detection research but Egozi and Verma [
7] highlight that they keep stopwords in their research as they consider them a fundamental part of an email. Therefore, stopwords and uppercase text have been kept in this research as they provide context in emails and Bagui et al. [
32] highlight that context can be essential for phishing detection. Tokenization, stemming, lemmatization and POS tagging were the techniques used to determine the most suitable Python library.
As NLTK was able to quickly conduct all the NLP techniques used during the experiment, NLTK was to be used for the NLP-related tasks in this research.
3.3.2. Deep Learning
The aim of the second experiment was to establish whether Keras or PyTorch was the most suitable Python library for deep learning. The UCI Spambase dataset [
22] was used as it provided a dataset ideal for binary classification.
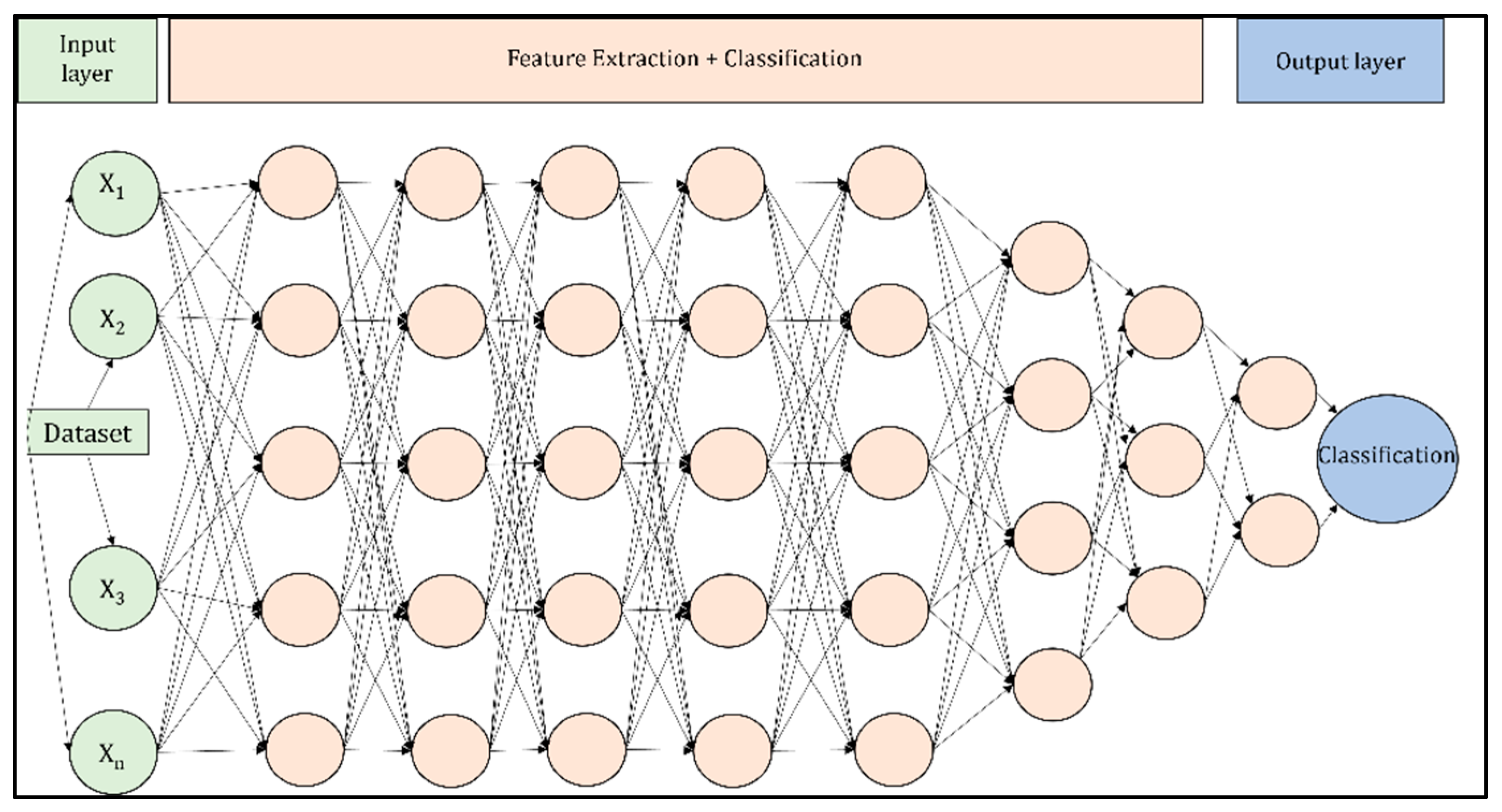
Figure 2 outlines a basic design of the deep learning model that was used for the deep learning experiment.
To establish whether Keras or PyTorch was the more suitable deep learning library, accuracy and precision were the performance metrics considered (see
Table 4).
The opportunity to identify the optimal parameters for this research arose when experimenting with Keras (see
Figure 3).
Binary_crossentropy was the loss function used because Teja, Sasank and Reddy [
33] state that it works best for binary classification problems such as phishing detection.
Figure 4 outlines various optimizers which produced accuracies higher than 90%. It was expected that the
nadam optimizer would be used as Pavan Kumar, Jaya and Rajendran [
34] achieve a high accuracy with this optimizer; however, during the Keras experiment, the nadam optimizer achieved the highest accuracy. Kewei et al. [
35] in their research into fraud detection (a binary classification problem) used the
nadam optimizer.
Relu and sigmoid were the activation functions considered, as when combined with the optimizers illustrated in
Figure 3, high accuracies on average were achieved (see
Table 5 below).
Bagui et al. [
32] found that relu was the most effective activation function but they used sigmoid for the end Dense layer as it performs well for binary classification. Although Butt et al. [
36] achieved 92% for classifying phishing URLs when using relu for the input and hidden layers and sigmoid for the output layer, these results were not replicated in this research. Using the relu activation function for the input and hidden layers produced a 60% accuracy which is not suitable for phishing detection. Therefore, the green row in
Table 3 illustrates the optimal parameters for the model used during the experimentation phase of this research.
After choosing the activation functions, the batch size was tested. Do et al. [
37] illustrate that a batch size of 32 is optimal for all deep learning algorithms, hence a batch size of 32 was used. However, to clarify that this batch size was optimal, a batch size of 10 and 64 were also tested as Shabudin et al. [
38] and Xiao et al. [
30] both used a batch size of 10 for classifying phishing websites. Over five runs, a batch size of 32 produced an average accuracy of 93.78%, whereas a batch size of 64, although faster, achieved an average accuracy of 92.93%. Therefore, a batch size of 32 alongside 100 epochs was used for the rest of the deep learning experiment.
Once the optimal parameters in
Figure 5 had been chosen, these parameters were tested on another dataset.
Despite the Kaggle dataset by Akashsurya156 and Kul [
24] taking longer to classify due to its size, an accuracy of 98% and a precision of 0.98 was achieved, which suggested that the speed of the detection solution depended on the dataset being used.
The optimal model parameters were used for the PyTorch experiment, along with the model in
Figure 2.
Despite both Keras and PyTorch being able to produce high accuracies and precisions, PyTorch produced lower accuracies than Keras (see
Figure 6); therefore, it was determined that Keras would be used in the overall detection solution.
For determining the most suitable deep learning algorithms, each dataset was split into a training and testing dataset. Using a similar approach as Bagui et al. [
32], 70% of each dataset collated was used for training (and validation) and 30% for testing; however, each dataset was kept separate so they could be treated as variables for the detection solution.
Table 6 highlights that the quantity of benign and phishing/spam values was balanced within the training and testing datasets as Bountakas, Koutroumpouchos and Xenakis [
6] draw attention to using balanced datasets.
Overall, the training datasets were used for determining the most suitable deep learning algorithms.
A comparison of algorithms to determine the most suitable algorithm for this research problem was conducted (see
Table 7).
Existing research tends to opt for a combination of algorithms for spam and phishing detection. Ghourabi, Mahmood and Alzubi [
39] used both CNN and LSTM, achieving 98% accuracy, whereas Sriram et al. [
40] demonstrate that CNN, when used for image classification, can achieve up to 99% accuracy. Although CNN is known for image classification, McGinley and Monroy [
41] demonstrated that their CNN model was able to classify real-world phishing emails, achieving an accuracy of 98%. However, CNN was disregarded as an algorithm that could be used to classify numerical-based datasets as it did not work well with the datasets used.
MLP was one of the algorithms tested during the experimentation phase.
Figure 7 displays all the instances used to test the suitability of MLP for this research problem and the green rows outline the highest accuracies achieved.
It was found that with 50 epochs and using all the optimal parameters in
Figure 7, MLP on average achieved a relatively high accuracy, although not when using the dataset from Kaggle by Akashsurya156 and Kul [
24] which only achieved a 50% accuracy.
As Lee et al. [
42] claim that RNN along with LSTM are some of the most widely used deep-learning techniques in recent classification studies, both Simple RNN and LSTM were tested. Accuracy using Simple RNN was seen to be temperamental using the UCI Spambase dataset by Hopkins et al. [
22] as an accuracy of 75% and 10% was achieved across the five runs. When using the Phishing Email Collection dataset from Kaggle [
24], the accuracy also differed. For phishing and spam detection, these accuracies are not good enough and as a result, this algorithm was disregarded.
The same varied accuracies were also produced when using LSTM. The implications of achieving varied accuracies in phishing detection are that an undetected phishing or spam email could severely impact organisations. Combining LSTM and Simple RNN did not see high accuracies either; however, accuracies above 70% were achieved more consistently.
Overall, MLP was found to be the most suitable algorithm for numerical-based datasets as accuracies of above 90% were achieved.
As Das et al. [
43] consider Simple RNN and LSTM in their effectiveness for classifying URLs as malicious or benign, both algorithms were also tested for classifying text-based datasets. The Spam Classification dataset from Kaggle [
27] was used for this part of the experimentation phase because NLP techniques and deep learning algorithms could be applied.
Using a similar approach to Gualberto et al. [
44] and Bountakas, Koutroumpouchos and Xenakis [
6], TF-IDF was used because it is a popular technique for classifying phishing emails. In the case of Bountakas, Koutroumpouchos and Xenakis [
6], a high accuracy was achieved when using TF-IDF alongside machine learning algorithms; therefore text-based datasets were converted into numerical form using TF-IDF prior to using the deep learning model.
As previously highlighted, RNN algorithms have solely been tested for classifying the text-based datasets as Vinayakumar et al. [
45] state that RNN has obtained good performance in artificial intelligence tasks including natural language processing. LSTM was the first RNN-based algorithm that was tested, producing an accuracy of 98% and precision of 0.98 consistently throughout the five runs. Even when the model was changed to resemble the number of layers defined in
Figure 2, the accuracy and precision remained the same. Likewise, Simple RNN achieved an accuracy of 98% and a precision of 0.98. As both algorithms produced high accuracies and precisions, another text-based dataset was used to determine the reliability of the results. The Spam Email dataset from Kaggle by Qureshi [
26] was split into a training and testing dataset and then the training dataset was used. As this second dataset was larger, only 5 epochs were used but both Simple RNN and LSTM still achieved an accuracy of 99.89% and a precision of 0.998883. Both algorithms were combined to understand their value together, but high accuracies and precisions were still achieved. As LSTM has appeared more in similar research, this algorithm was chosen for classifying text-based datasets.
It was observed from the experiments that NLTK and Keras were the most suitable Python libraries for this phishing and spam detection solution. MLP and LSTM were chosen to classify numerical-based datasets and text-based datasets, respectively. All these elements have been combined in the development of a phishing and spam detection solution.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}