
Social Intelligence Mining: Unlocking Insights from X


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methodology
2.1. Sentiment Analysis: A Brief Mathematical Perspective
2.1.1. Representation of Text
2.1.2. Sentiment Scoring
2.1.3. Classification
2.1.4. Training
2.2. Network Analysis
2.2.1. Graph Definition
- V is a set of nodes (vertices). The total number of nodes is denoted as n where .
- E is a set of edges (links). The total number of edges is denoted as m where .
2.2.2. Adjacency Matrix
2.2.3. Degree of a Node
- In-degree, as the number of edges coming into v.
- Out-degree, as the number of edges going out of v.
2.2.4. Path and Distance
2.2.5. Centrality Measures
- Degree Centrality:
- Betweenness Centrality:
2.2.6. Clustering Coefficient
2.2.7. Modularity
2.3. Lead and Lag Analysis
2.3.1. Univariate Case
2.3.2. Bivariate Case
3. Results
3.1. Data
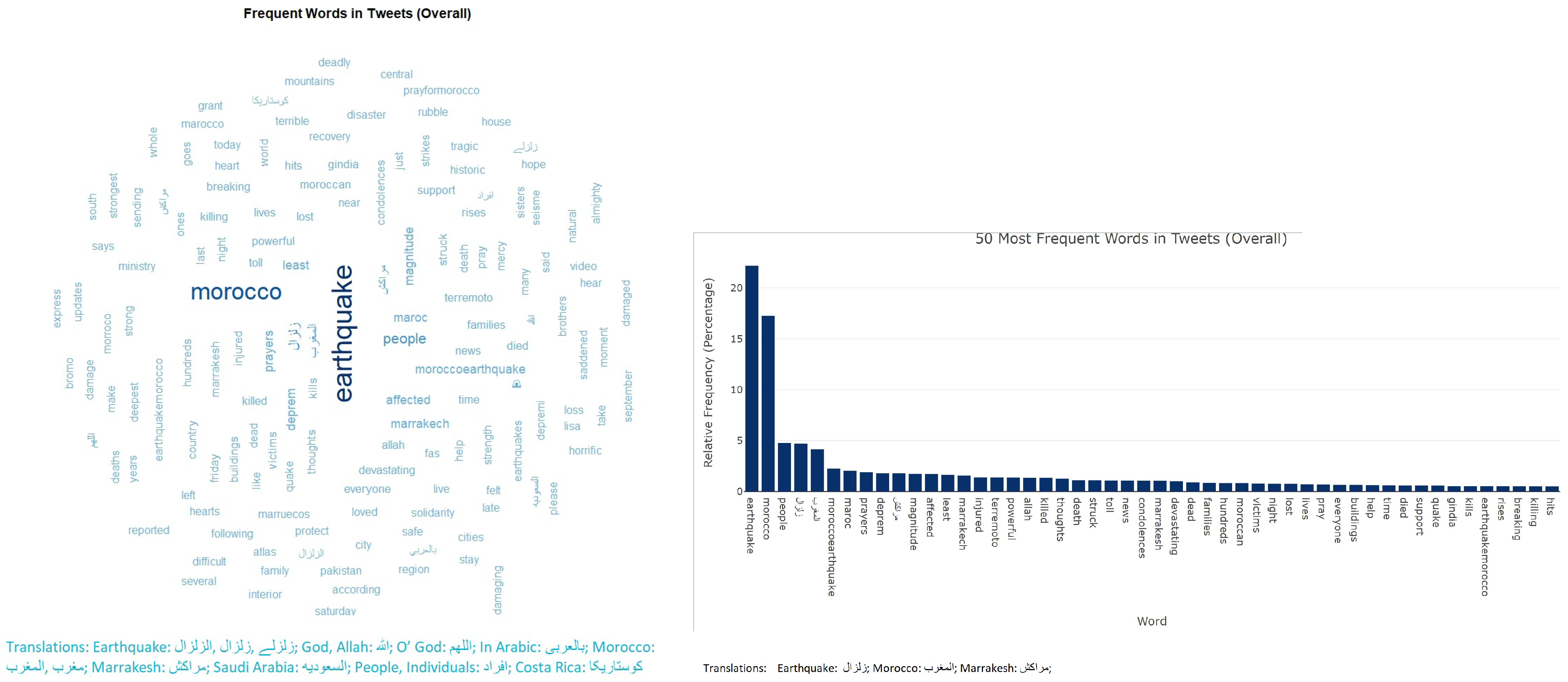
3.2. Sentiment Analysis
3.3. Tweet Trend Index
3.4. Coherence Analysis
- In the top panel:
- In the middle panel:
- In the bottom panel:
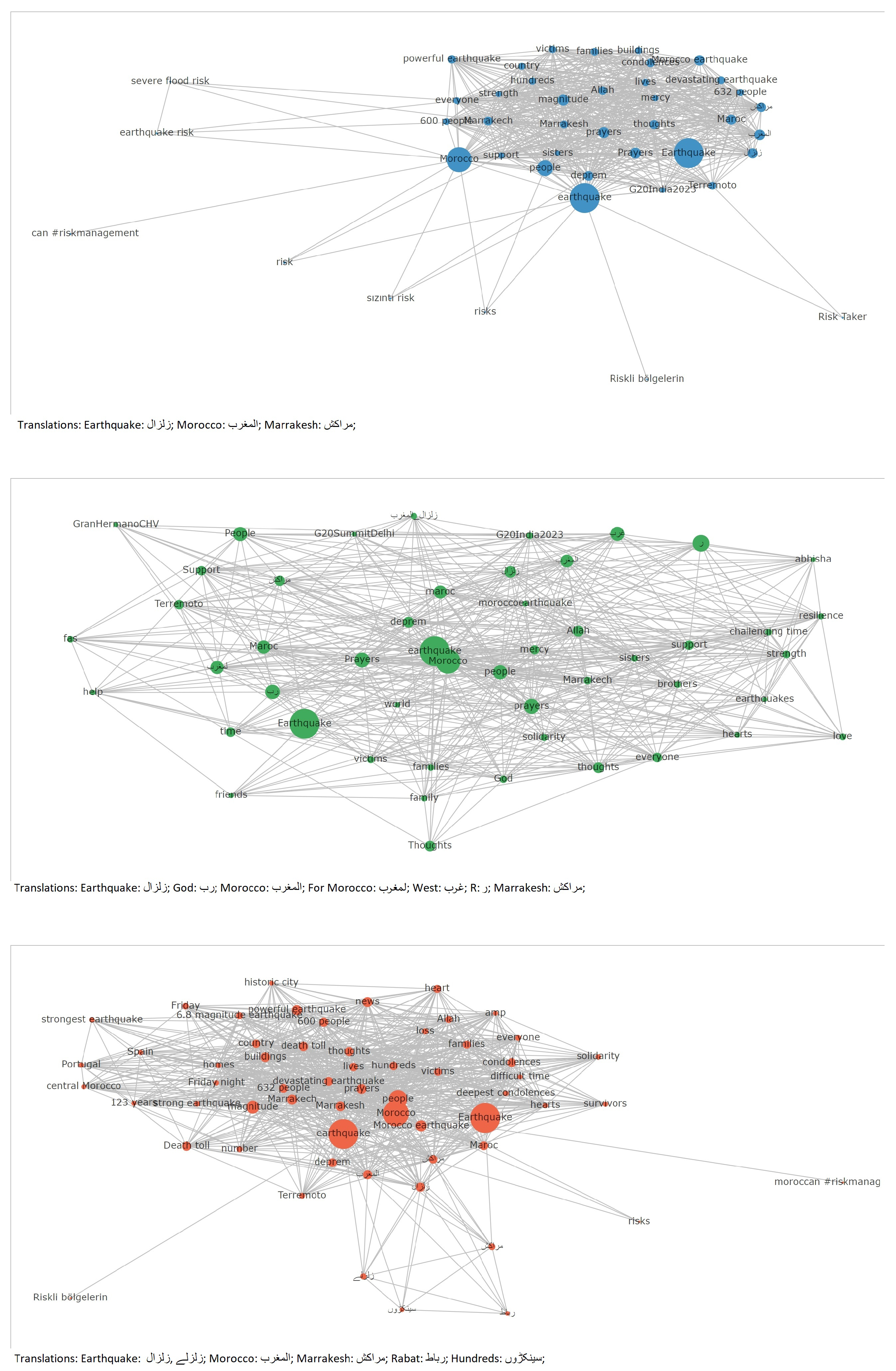
3.5. Network Analysis
4. Discussion
4.1. SentimentAnalysis
4.2. Network Analysis
4.3. Coherence Analysis Using Wavelet Transforms
4.4. Sentiment Analysis for Understanding Public Reaction and Awareness
- (a)
- Sentiment analysis of social media data, especially around the time of an earthquake, can provide real-time insights into public emotions, concerns, and awareness levels.
- (b)
- Identifying shifts in sentiment (e.g., fear, confusion, or relief) can guide emergency services in tailoring their communication and support strategies to address public concerns effectively.
4.5. Network Analysis for Mapping Communication Patterns
- (a)
- Network analysis can identify key influencers, communication hubs, and information dissemination patterns within social networks.
- (b)
- Understanding how information about earthquakes spreads through networks enables authorities to identify misinformation and target outreach efforts more effectively. It also helps in leveraging influential nodes (like popular social media accounts) to disseminate accurate information quickly.
4.6. Coherence Analysis for Temporal Dynamics
- (a)
- Coherence analysis using wavelet transforms can uncover temporal patterns in public discussions and sentiments about earthquakes.
- (b)
- This can help predict when public interest or concern might peak, allowing for timely interventions, like public education campaigns or readiness drills.
4.7. Integrated Application in Disaster Risk Management
- 1.
- Pre-Disaster: By analyzing sentiment and network structures, authorities can assess public preparedness and tailor educational campaigns to improve readiness. Coherence analysis can indicate optimal times for releasing information.
- 2.
- During a Disaster: Real-time sentiment analysis can gauge public mood and needs, guiding immediate response strategies. Network analysis can help manage the flow of information, ensuring accurate and efficient communication.
- 3.
- Post-Disaster: Continued analysis aids in monitoring public morale and the spread of information about aftershocks, relief efforts, and recovery resources. It can also help in understanding community resilience and long-term recovery needs.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Karami, A.; Shah, V.; Mammadov, T. Mining Public Opinion about Economic Issues: Twitter and the U.S. Presidential Election. Int. J. Strateg. Decis. Sci. (IJSDS) 2020, 11, 89–104. [Google Scholar] [CrossRef]
- Silva, E.S.; Hassani, H.; Madsen, D.Ø.; Gee, L. Googling Fashion: Forecasting Fashion Consumer Behaviour Using Google Trends. Soc. Sci. 2019, 8, 111. [Google Scholar] [CrossRef]
- Silva, E.S.; Hassani, H.; Madsen, D.Ø. Big Data in fashion: Transforming the retail sector. J. Bus. Strategy 2020, 41, 21–27. [Google Scholar] [CrossRef]
- Bruns, A.; Stieglitz, S. Towards more systematic Twitter analysis: Metrics for tweeting activities. Int. J. Soc. Res. Methodol. 2013, 16, 91–108. [Google Scholar] [CrossRef]
- Negrón, J.B. EULAR2018: The Annual European Congress of Rheumatology—A Twitter hashtag analysis. Rheumatol. Int. 2019, 39, 893–899. [Google Scholar] [CrossRef] [PubMed]
- Thakur, N. Monkey Pox 2022 Tweets: A Large-Scale Twitter Dataset on the 2022 Monkeypox Outbreak, Findings from Analysis of Tweets, and Open Research Questions. Infect. Dis. Rep. 2022, 14, 855–883. [Google Scholar] [CrossRef] [PubMed]
- Hassani, H.; Komendantova, N.; Rovenskaya, E.; Yeganegi, M.R. Social Trend Mining: Lead or Lag. Big Data Cogn. Comput. 2023, 7, 171. [Google Scholar] [CrossRef]
- Vosen, S.; Schmidt, T. Forecasting private consumption: Survey-based indicators vs. Google trends. J. Forecast. 2011, 30, 565–578. [Google Scholar] [CrossRef]
- He, W.; Zha, S.; Li, L. Social media competitive analysis and text mining: A case study in the pizza industry. Int. J. Inf. Manag. 2013, 33, 464–472. [Google Scholar] [CrossRef]
- Stieglitz, S.; Dang-Xuan, L. Social media and political communication: A social media analytics framework. Soc. Netw. Anal. Min. 2013, 3, 1277–1291. [Google Scholar] [CrossRef]
- Fan, W.; Gordon, M.D. The power of social media analytics. Commun. ACM 2014, 57, 74–81. [Google Scholar] [CrossRef]
- Bastos, M.T.; Travitzki, R.; Raimundo, R. Tweeting Political Dissent: Retweets as Pamphlets in #FreeIran, #FreeVenzuela, #Jan25, #SpanishRevolution and #OccupyWallSt, IPP2012; University of Oxford: Oxford, UK, 2012. [Google Scholar]
- Bastos, M.T.; Travitzki, R.; Puschmann, C. What sticks with whom? Twitter follower- followee networks and news classification. In Proceedings of the 6th International AAAI Conference on Weblogs and Social Media—Workshop on the Potential of Social Media Tools and Data for Journalists in the News Media Industry, Dublin, Ireland, 4–7 June 2012. [Google Scholar]
- Suh, B.; Hong, L.; Pirolli, P.; Chi, E.H. Want to be Retweeted? Large scale analytics on factors impacting Retweet in Twitter network. In Proceedings of the SOCIALCOM’10 Proceedings of the 2010 IEEE Second International Conference on Social Computing, Minneapolis, MN, USA, 20–22 August 2020; pp. 177–184. [Google Scholar]
- Go, A.; Bhayani, R.; Huang, L. Twitter Sentiment Classification Using Distant Supervision; Technical Report, Stanford Digital Library Technologies Project; Stanford University: Stanford, CA, USA, 2009. [Google Scholar]
- Hajibagheri, A.; Sukthankar, G. Political Polarization over Global Warming: Analyzing Twitter Data on Climate Change; Academy of Science and Engineering (ASE): Greensboro, NC, USA, 2014. [Google Scholar]
- Jahanbakhsh, K.; Moon, Y. The predictive power of social media: On the predictability of U.S presidential elections using twitter. arXiv 2014, arXiv:1407.0622. [Google Scholar]
- Japkowicz, N.; Shah, K. (Eds.) Evaluating Learning Algorithms: A Classification Perspective, 1st ed.; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Johnson, C.; Shukla, P.; Shukla, S. On Classifying the Political Sentiment of Tweets. 2012. Available online: https://www.cs.utexas.edu/ (accessed on 25 October 2023).
- Kumar, S.; Morstatter, F.; Liu, H. Twitter Data Analytics; Springer: New York, NY, USA, 2014. [Google Scholar]
- Saif, H.; He, Y.; Alani, H. Semantic sentiment analysis of twitter. In Proceedings of the 11th International Semantic Web Conference—ISWC 2012, Boston, MA, USA, 11–15 November 2012; pp. 508–524. [Google Scholar]
- Ellison, N.B.; Steinfield, C.; Lampe, C. The benefits of Facebook “friends”: Social capital and college students’ use of online social network sites. J. Comput.-Mediat. Commun. 2007, 12, 1143–1168. [Google Scholar] [CrossRef]
- Boyd, D.M.; Ellison, N.B. Social network sites: Definition, history, and scholarship. J. Comput.-Mediat. Commun. 2007, 13, 210–230. [Google Scholar] [CrossRef]
- Haythornthwaite, C. Social networks and Internet connectivity effects. Inf. Commun. Soc. 2005, 8, 125–147. [Google Scholar] [CrossRef]
- Data Portal. Global Digital Overview. Available online: https://datareportal.com/global-digital-overview (accessed on 23 October 2023).
- Kumar, S.; Morstatter, F.; Liu, H. Twitter Data Analytics; Springer: Berlin/Heidelberg, Germany, 2014; ISBN 978-1-4614-9372-3. [Google Scholar]
- Russell, M.A.; Klassen, M. Mining the Social Web: Data Mining Facebook, Twitter, LinkedIn, Instagram, GitHub, and More, 3rd ed.; O’Reilly Media: Sebastopol, CA, USA, 2019; ISBN 978-1491985045. [Google Scholar]
- Liu, B. Sentiment Analysis and Opinion Mining; Morgan and Claypool Publishers: San Rafael, CA, USA, 2012; ISBN 978-1608458844. [Google Scholar]
- Golbeck, J. Analyzing the Social Web; Morgan Kaufmann: Burlington, MA, USA, 2013; ISBN 978-0124055315. [Google Scholar]
- Mejova, Y.; Weber, I.; Macy, M.W. Twitter: A Digital Socioscope; Cambridge University Press: Cambridge, UK, 2015; ISBN 978-1107500076. [Google Scholar]
- Cambria, E.; White, B. Jumping NLP curves: A review of natural language processing research. IEEE Comput. Intell. Mag. 2020, 9, 48–57. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Giachanou, A.; Crestani, F. Like it or not: A survey of Twitter sentiment analysis methods. ACM Comput. Surv. (CSUR) 2016, 49, 1–41. [Google Scholar] [CrossRef]
- Lu, L.; Chen, D.; Ren, X.-L.; Zhang, Q.-M.; Zhang, Y.-C.; Zhou, T. Vital nodes identification in complex networks. Phys. Rep. 2016, 650, 1–63. [Google Scholar] [CrossRef]
- Barabási, A.-L.; Pósfai, M. Network Science; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Boccaletti, S.; Bianconi, G.; Criado, R.; Del Genio, C.I.; Gómez-Gardeñes, J.; Romance, M.; Sendiña-Nadal, I.; Wang, Z.; Zanin, M. The Structure and Dynamics of Multilayer Networks. Phys. Rep. 2014, 544, 1–122. [Google Scholar] [CrossRef]
- Carmona, R.; Hwang, W.L.; Torresani, B. Practical Time Frequency Analysis: Gabor and Wavelet Transforms with an Implementation in S; Academic Press: San Diego, CA, USA, 1998. [Google Scholar]
- Morlet, J.; Arens, G.; Fourgeau, E.; Giard, D. Wave propagation and sampling theory—Part I: Complex signal and scattering in multilayered media. Geophysics 1982, 47, 203–221. [Google Scholar] [CrossRef]
- Torrence, C.; Compo, G.P. A practical guide to wavelet analysis. Bull. Am. Meteorol. Soc. 1998, 79, 61–78. [Google Scholar] [CrossRef]
- Ge, Z. Significance tests for the wavelet power and the wavelet power spectrum. Ann. Geophys 2007, 25, 2259–2269. [Google Scholar] [CrossRef]
- Maraun, D.; Kurths, J. Cross wavelet analysis: Significance testing and pitfalls. Nonlinear Process. Geophys. 2004, 11, 505–514. [Google Scholar] [CrossRef]
- Ge, Z. Significance tests for the wavelet cross spectrum and wavelet linear coherence. Ann. Geophys 2008, 26, 3819–3829. [Google Scholar] [CrossRef]
- Rósch, A.; Schmidbauer, H. WaveletComp 1.1: A Guided Tour through the R Package. 2018. Available online: http://www.hsstat.com/projects/WaveletComp/WaveletComp_guided_tour.pdf (accessed on 23 October 2023).
- Berestycki, H.; Rossi, L.; Rodríguez, N. Periodic cycles of social outbursts of activity. J. Differ. Equ. 2018, 264, 163–196. [Google Scholar] [CrossRef]
- Petz, G.; Karpowicz, M.; Fürschuß, H.; Auinger, A.; Stříteský, V.; Holzinger, A. Computational approaches for mining user’s opinions on the Web 2.0. Inf. Process. Manag. 2014, 50, 899–908. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassani, H.; Komendantova, N.; Rovenskaya, E.; Yeganegi, M.R. Social Intelligence Mining: Unlocking Insights from X. Mach. Learn. Knowl. Extr. 2023, 5, 1921-1936. https://doi.org/10.3390/make5040093
Hassani H, Komendantova N, Rovenskaya E, Yeganegi MR. Social Intelligence Mining: Unlocking Insights from X. Machine Learning and Knowledge Extraction. 2023; 5(4):1921-1936. https://doi.org/10.3390/make5040093
Chicago/Turabian StyleHassani, Hossein, Nadejda Komendantova, Elena Rovenskaya, and Mohammad Reza Yeganegi. 2023. "Social Intelligence Mining: Unlocking Insights from X" Machine Learning and Knowledge Extraction 5, no. 4: 1921-1936. https://doi.org/10.3390/make5040093