
Systematic Review of Recommendation Systems for Course Selection

Abstract
:1. Introduction
2. Motivation and Rationale of the Research
3. Research Questions
3.1. Questions about the Used Algorithms
- What preprocessing methods were applied?
- What recommendation system algorithms were used in the paper?
- What are the applied evaluation metrics?
- What are the performance results of applied evaluation metrics?
3.2. Questions about the Used Dataset
- Is the dataset published or accessible?
- How many records are there in the dataset?
- How many unique student records are there in the dataset?
- How many unique course records are there in the dataset?
- How many features are there in the dataset?
- How many features are used from the existing features?
- How many unique majors are there in the dataset?
- How did the authors split the training and testing set?
3.3. Questions about the Research
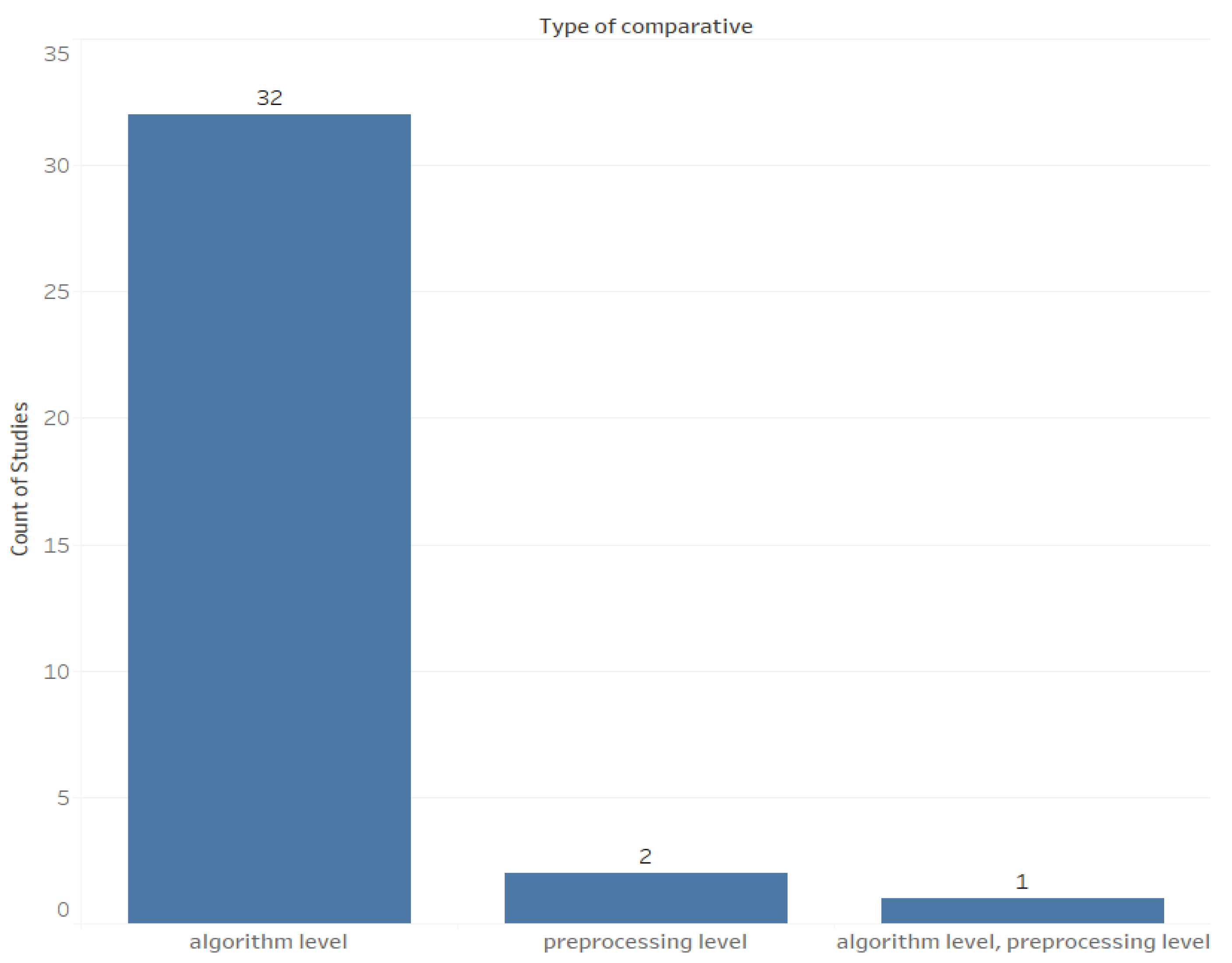
- What is the type of comparative produced in the study (algorithm level, preprocessing level, or data level)?
- What is the main aim of the study?
- What are the strong points of the research?
- What are the weak points of the research?
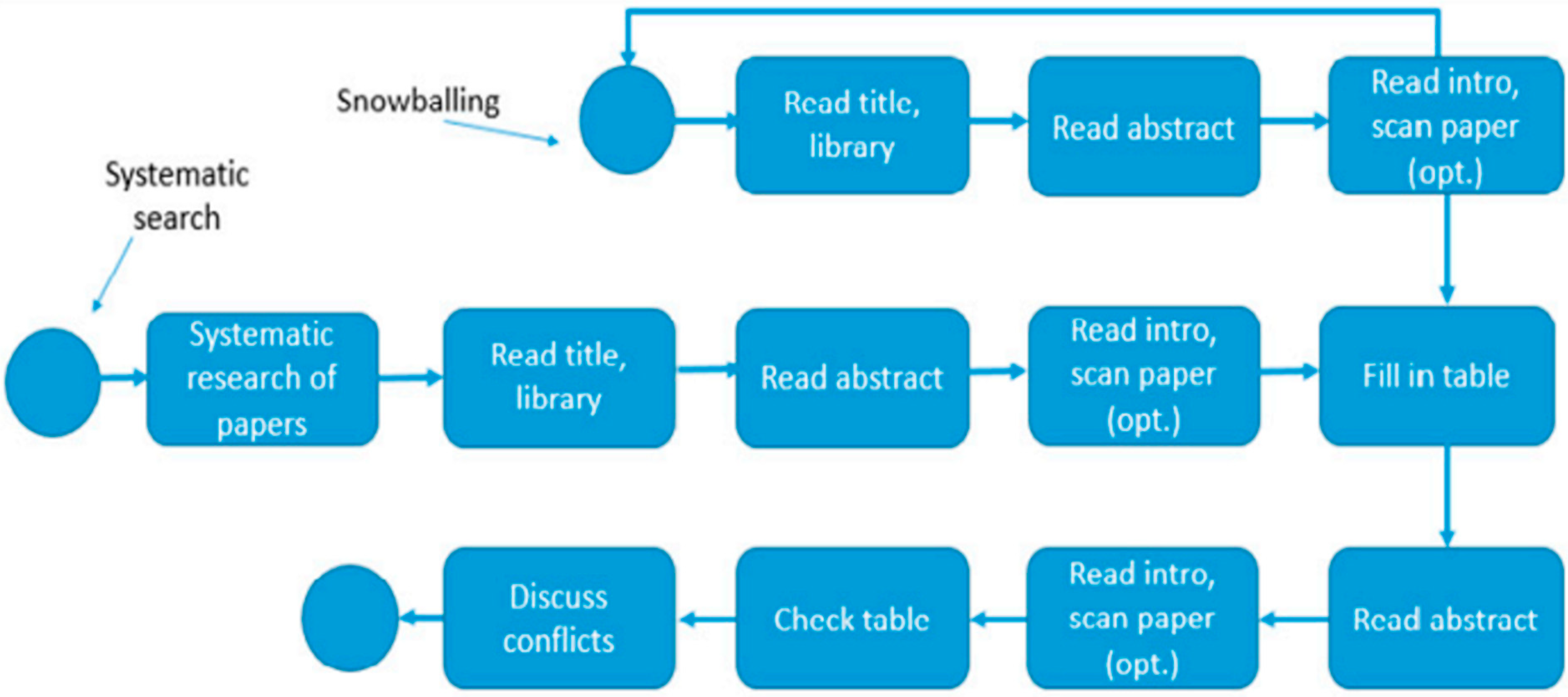
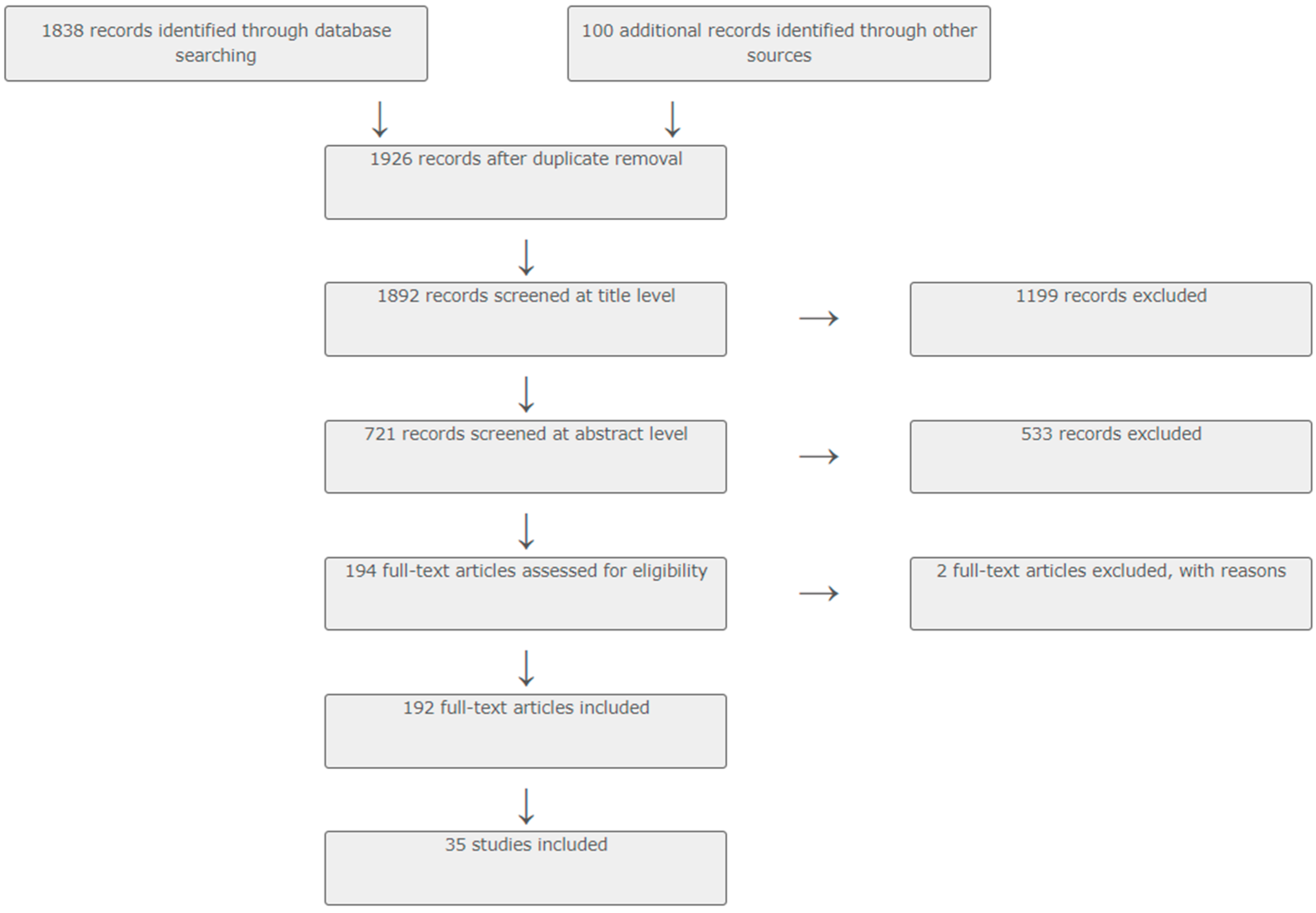
4. Research Methodology
4.1. Title-Level Screening Stage
- The study addresses recommendation systems in the Education sector.
- The study must be primary.
4.2. Abstract-Level Screening Stage
- The study addresses recommendation systems in the Education sector.
- The study must be primary.
4.3. Full-Text Article Scanning Stage
- The study was written in the English language.
- The study implies empirical experiments and provides the experiment’s results.
4.4. Full-Text Article Screening Stage
- Q1: Did the study conduct experiment in the course selection and courses recommendation system?
- Q2: Is there a comparison with other approaches in the conducted study?
- Q3: Were the performance measures fully defined?
- Q4: Was the method used in the study clearly described?
- Q5: Was the dataset and number of training and testing data identified?
4.5. Data Extraction Stage
5. Research Results
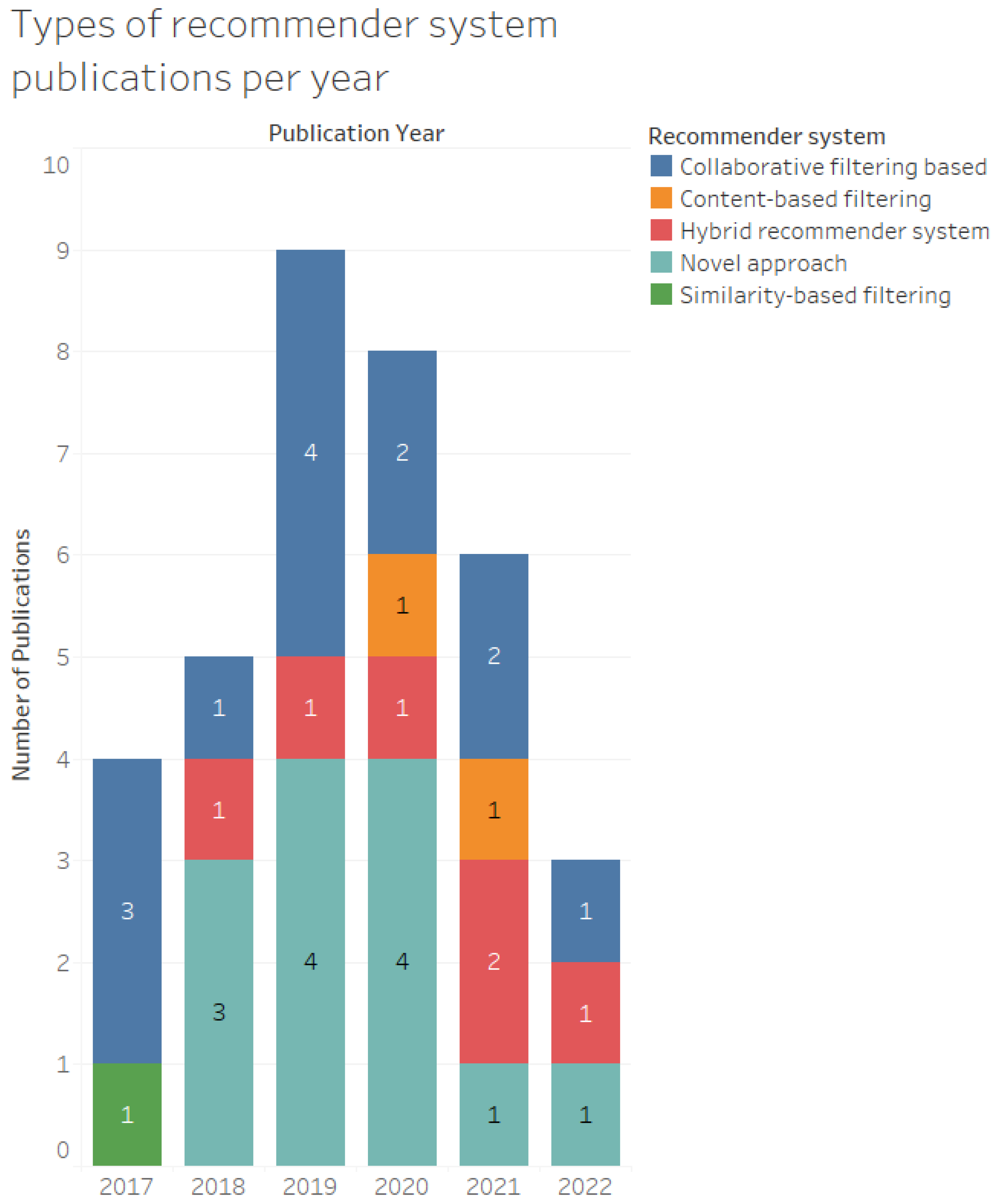
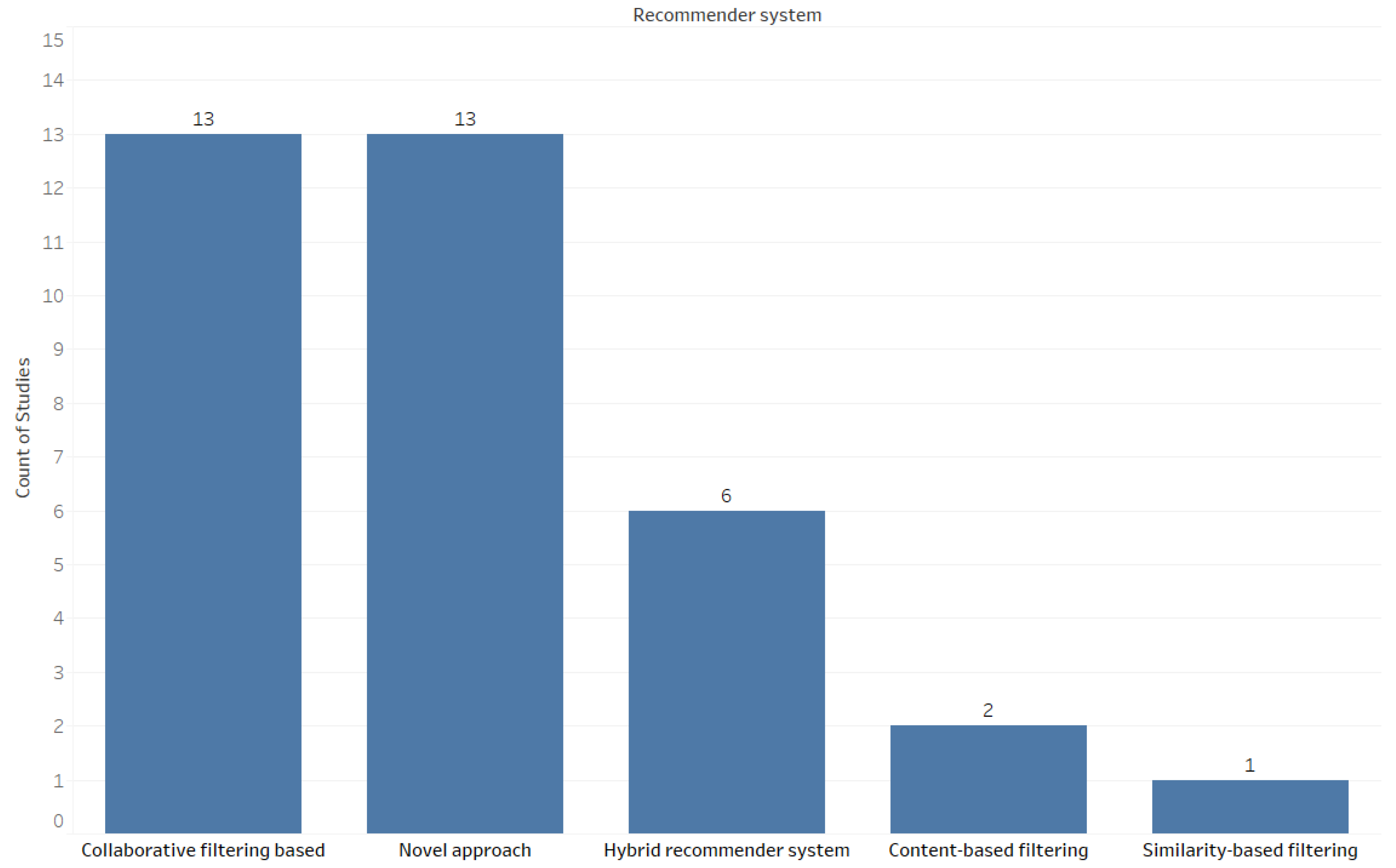
5.1. The Studies Included in the SLR
5.1.1. Collaborative Filtering Studies
5.1.2. Content-Based Filtering Studies
5.1.3. Hybrid Recommender System Studies
5.1.4. Studies Based on Machine Learning
5.1.5. Similarity-Based Study
6. Key Studies Analysis
6.1. Discussion of Aims and Contributions of the Existing Research Works
6.1.1. Aim of Studies That Used Collaborative Filtering
- (1)
- Authors in [26] used ordered weighted average (OWA) to address the problem that most other studies make recommendations based on the student’s previous academic performance. None of the current studies take course repetition into account when calculating student performance; instead, they only look at the most recent grades on the transcript for repeated courses. They made the premise that students’ final grades in a course may not accurately reflect their performance because they may retake a course multiple times to improve their performance. Therefore, using the student’s most recent grades alone may not result in the best suggestions,
- (2)
- Authors in [27] offered a machine-learning strategy to suggest appropriate courses to learners based on their prior performance and learning history,
- (3)
- Authors in [28] enabled the task of course recommendation to be handled using a CF-based model. They list many obstacles to using the current CF models to create a course recommendation engine, such as the absence of ratings and metadata, the uneven distribution of course registrations, and the requirement for course dependency modeling,
- (4)
- The system suggested by Malhorta et al. [29] will assist students in enrolling in the finest optional courses according to their areas of interest. This method groups students into clusters according to their areas of interest, then utilizes the matrix factorization approach to analyze past performance data of students in those areas to forecast the courses that a specific student in the cluster can enroll in,
- (5)
- Authors in [30] proposed the CUDCF (Cross-User-Domain Collaborative Filtering) algorithm, which uses the course score distribution of the most comparable senior students to precisely estimate each student’s score in the optional courses,
- (6)
- The main aim of the authors in [31] was to improve the precision and recall rate of recommendation results by improving the collaborative filtering algorithm,
- (7)
- Students’ grade prediction using user-based collaborative filtering was introduced by authors in [32],
- (8)
- Authors in [9] improved association rule generation and coverage by clustering,
- (9)
- Authors in [33] suggested utilizing big data recommendations in education. According to the student’s grades in other topics, this study uses collaborative filtering-based recommendation approaches to suggest elective courses to them,
- (10)
- To forecast sophomores’ elective course scores, authors in [34] presented the Constrained Matrix Factorization (ConMF) algorithm, which can not only assist students in choosing the appropriate courses but also make the most efficient use of the scarce teaching resources available at universities,
- (11)
- Authors in [35] applied the interestingness measure threshold and association rule of data-mining technology to the course recommendation system,
- (12)
- Authors in [36] improved the accuracy of recommendations by using the improved cosine similarity,
- (13)
- Neural Collaborative Filtering (NCF), a deep learning-based recommender system approach, was presented by authors in [37] to make grade predictions for students enrolled in upcoming courses.
6.1.2. Aim of Studies That Used Content-Based Filtering
- (1)
- Authors in [38] introduce a method that does more than just estimate dropout risk or student performance; it also takes action to support both students and educational institutions, which helps to reverse the dropout problem. The goal is to increase graduation rates by creating a recommender system to help students choose their courses,
- (2)
- Authors in [39] improve the accuracy of recommendations by using weighted cosine similarity instead of traditional cosine similarity.
6.1.3. Aim of Studies That Used Hybrid Recommender Systems
- (1)
- College students were assisted in selecting electives by combining a multi-criteria hybrid recommendation system that utilizes CF and CBF with genetic optimization, which was introduced by authors in [40],
- (2)
- Authors in [41] overcame the performance implications of traditional algorithms by presenting a hybrid approach that includes using association rule-mining and collaborative filtering,
- (3)
- Authors in [42] used data mining and recommendation systems to assist academic advisers and students in creating effective study plans, particularly when a student has failed a few courses,
- (4)
- Authors in [43] overcame the cold-start drawback of collaborative filtering and the domain knowledge requirement of content-based filtering by using a hybrid approach that combines both,
- (5)
- Authors in [44] represented the student learning styles and the learning object profiles using the Felder–Silverman learning styles model, thus improving the overall accuracy of recommendations,
- (6)
- Authors in [45] suggested a Course Recommendation Model in Academic Social Networks Based on Association Rules and Multi-similarity (CRM-ARMS) that is based on academic social networks, a hybrid approach combining an association rules algorithm and an improved multi-similarity algorithm of multi-source information, which can recommend courses by possible relationships between courses and the user’s implicit interests.
6.1.4. Aim of Studies That Used Novel Approaches
- (1)
- Authors in [46] provided a recommendation system based on the Support Vector Machine and K-Nearest Neighbor techniques that suggest the most appealing graduate programs to students,
- (2)
- Authors in [47] helped students prepare for target courses of interest, they created a novel recommendation system based on recurrent neural networks that are tailored to each student’s estimated previous knowledge background and zone of proximal development,
- (3)
- The decision tree’s upgraded algorithm is applied by the authors in [48] to the data on college electives in recent years after the currency rules and C4.5 algorithm are coupled to extract the statute rules from the student elective database,
- (4)
- Authors in [49] built an autonomous course recommender system for undergraduates using five classification models: linear regression, Naive Bayes, Support Vector Machines, K-Nearest Neighbor, and decision tree algorithm,
- (5)
- By applying feature selection and extraction approaches to reduce the dimensionality, early detection of dropout factors is made possible by the authors in [50]. Unbalanced data may occur during feature extraction, which could have an impact on the usefulness of machine-learning approaches. To manage the oversampling of unbalanced data and create a balanced dataset, the Synthetic Minority Oversampling Technique is then used with Principal Compound Analysis,
- (6)
- Students’ academic outcomes prediction using a machine-learning approach that utilizes the Catboost algorithm was proposed in [51],
- (7)
- An effective method has been put out in [52] that makes use of SVM to guarantee academic success in optional courses through its predictions and to maintain student topic preferences for the better attainment of bilateral academic quality learning outcomes,
- (8)
- Authors in [53], to reduce overfitting and misclassification results by imbalanced multi-classification based on oversampling Synthetic Minority Oversampling Technique (SMOTE) using two feature selection methods, suggested a multiclass prediction model. According to the results, the presented model integrates with RF and significantly improves with an f-score of 99.5%,
- (9)
- Research [54] conducted for choosing open elective courses at a prestigious private university is highlighted. The classification techniques KNN and Support Vector Machine with Radial Basis Kernel are reviewed, used, and compared during the data-mining process. Additionally, the article seeks to replace the current heuristic process’s mathematical underpinning with data mining techniques,
- (10)
- Authors in [55] improved the accuracy of course recommendations using a machine-learning approach that utilizes the Naive Bayes algorithm,
- (11)
- Authors in [56] developed a list of suggestions for academics and professionals on the choice, configuration, and application of ML algorithms in predictive analytics in STEM education,
- (12)
- Based on a variety of criteria, authors in [57] mapped their present-day students to their alumni students. Then, in contrast to earlier articles that employed k-means, they used c-means and fuzzy clustering to find a superior way to predict the student’s elective course,
- (13)
- The goals of the study [58] were to determine how KNN and Naive Bayes can be used to suggest the best and most advanced course options for students.
6.1.5. Aim of Studies That Used Similarity-Based Filtering
6.2. Description of Datasets Used in the Studies
6.2.1. Dataset Description of Studies That Used Collaborative Filtering
6.2.2. Dataset Description of Studies That Used Content-Based Filtering
6.2.3. Dataset Description of Studies That Used Hybrid Recommender Systems
6.2.4. Dataset Description of Studies That Used Novel Approaches
- Train-test split.
- K-fold cross-validation.
- Nested time series splits.
6.2.5. Dataset Description of the Study That Used Similarity-Based Filtering
6.3. Research Evaluation
6.3.1. Research Evaluation for Studies That Used Collaborative Filtering
6.3.2. Research Evaluation for Studies That Used Content-Based Filtering
6.3.3. Research Evaluation for Studies That Used Hybrid Recommender Systems
6.3.4. Research Evaluation for Studies That Used Novel Approaches
6.3.5. Research Evaluation for the Study That Used Similarity-Based Filtering
7. Discussion of Findings
8. Gaps, Challenges, Future Directions and Conclusions for (CRS) Selection
8.1. Gap
8.2. Challenges
8.3. Future Directions
9. Conclusions
- Making precise course recommendations that are tailored to each student’s interests, abilities, and long-term professional goals.
- Addressing the issue of “cold starts,” wherein brand-new students without prior course experience might not obtain useful, reliable, and precise advice.
- Ensuring that the system is flexible enough to accommodate various educational contexts, data accessibility, and the unique objectives of the advising system.
- Increasing suggestion recall and precision rates.
- Using preprocessing and data-splitting methods to enhance the predefined performance standards of the CRS overall as well as the predefined and measured quality of recommendations.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Iatrellis, O.; Kameas, A.; Fitsilis, P. Academic advising systems: A systematic literature review of empirical evidence. Educ. Sci. 2017, 7, 90. [Google Scholar] [CrossRef] [Green Version]
- Chang, P.C.; Lin, C.H.; Chen, M.H. A hybrid course recommendation system by integrating collaborative filtering and artificial immune systems. Algorithms 2016, 9, 47. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Xing, T.; Van Der Schaar, M. Personalized course sequence recommendations. IEEE Trans. Signal Process. 2016, 64, 5340–5352. [Google Scholar] [CrossRef] [Green Version]
- Noaman, A.Y.; Ahmed, F.F. A new framework for e academic advising. Procedia Comput. Sci. 2015, 65, 358–367. [Google Scholar] [CrossRef] [Green Version]
- Pizzolato, J.E. Complex partnerships: Self-authorship and provocative academic-advising practices. NACADA J. 2006, 26, 32–45. [Google Scholar] [CrossRef] [Green Version]
- Unelsrød, H.F. Design and Evaluation of a Recommender System for Course Selection. Master’s Thesis, Institutt for Datateknikk og Informasjonsvitenskap, Trondheim, Norway, 2011. [Google Scholar]
- Kuh, G.D.; Kinzie, J.; Schuh, J.H.; Whitt, E.J. Student Success in College: Creating Conditions That Matter; John Wiley & Sons: New York, NY, USA, 2011. [Google Scholar]
- Mostafa, L.; Oately, G.; Khalifa, N.; Rabie, W. A case based reasoning system for academic advising in Egyptian educational institutions. In Proceedings of the 2nd International Conference on Research in Science, Engineering and Technology (ICRSET’2014), Dubai, United Arab Emirates, 21–22 March 2014; pp. 21–22. [Google Scholar]
- Obeidat, R.; Duwairi, R.; Al-Aiad, A. A collaborative recommendation system for online courses recommendations. In Proceedings of the 2019 International Conference on Deep Learning and Machine Learning in Emerging Applications (Deep-ML), Istanbul, Turkey, 26–28 August 2019; pp. 49–54. [Google Scholar]
- Feng, J.; Xia, Z.; Feng, X.; Peng, J. RBPR: A hybrid model for the new user cold start problem in recommender systems. Knowl.-Based Syst. 2021, 214, 106732. [Google Scholar] [CrossRef]
- Kohl, C.; McIntosh, E.J.; Unger, S.; Haddaway, N.R.; Kecke, S.; Schiemann, J.; Wilhelm, R. Online tools supporting the conduct and reporting of systematic reviews and systematic maps: A case study on CADIMA and review of existing tools. Environ. Evid. 2018, 7, 8. [Google Scholar] [CrossRef] [Green Version]
- Shminan, A.S.; Choi, L.J.; Barawi, M.H.; Hashim, W.N.W.; Andy, H. InVesa 1.0: The Conceptual Framework of Interactive Virtual Academic Advisor System based on Psychological Profiles. In Proceedings of the 2021 13th International Conference on Information & Communication Technology and System (ICTS), Surabaya, Indonesia, 20–21 October 2021; pp. 112–117. [Google Scholar]
- Wang, H.; Wei, Z. Research on Personalized Learning Route Model Based on Improved Collaborative Filtering Algorithm. In Proceedings of the 2021 2nd International Conference on Big Data & Artificial Intelligence & Software Engineering (ICBASE), Zhuhai, China, 24–26 September 2021; pp. 120–123. [Google Scholar]
- Shaptala, R.; Kyselova, A.; Kyselov, G. Exploring the vector space model for online courses. In Proceedings of the 2017 IEEE First Ukraine Conference on Electrical and Computer Engineering (UKRCON), Kyiv, Ukraine, 29 May–2 June 2017; pp. 861–864. [Google Scholar]
- Zhao, X.; Liu, B. Application of personalized recommendation technology in MOOC system. In Proceedings of the 2020 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Vientiane, Laos, 11–12 January 2020; pp. 720–723. [Google Scholar]
- Wahyono, I.D.; Asfani, K.; Mohamad, M.M.; Saryono, D.; Putranto, H.; Haruzuan, M.N. Matching User in Online Learning using Artificial Intelligence for Recommendation of Competition. In Proceedings of the 2021 Fourth International Conference on Vocational Education and Electrical Engineering (ICVEE), Surabaya, Indonesia, 2–3 October 2021; pp. 1–4. [Google Scholar]
- Elghomary, K.; Bouzidi, D. Dynamic peer recommendation system based on trust model for sustainable social tutoring in MOOCs. In Proceedings of the 2019 1st International Conference on Smart Systems and Data Science (ICSSD), Rabat, Morocco, 3–4 October 2019; pp. 1–9. [Google Scholar]
- Mufizar, T.; Mulyani, E.D.S.; Wiyono, R.A.; Arifiana, W. A combination of Multi Factor Evaluation Process (MFEP) and the Distance to the Ideal Alternative (DIA) methods for majors selection and scholarship recipients in SMAN 2 Tasikmalaya. In Proceedings of the 2018 6th International Conference on Cyber and IT Service Management (CITSM), Parapat, Indonesia, 7–9 August 2018; pp. 1–7. [Google Scholar]
- Sutrisno, M.; Budiyanto, U. Intelligent System for Recommending Study Level in English Language Course Using CBR Method. In Proceedings of the 2019 6th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Bandung, Indonesia, 18–20 September 2019; pp. 153–158. [Google Scholar]
- Gan, B.; Zhang, C. Research on the Application of Curriculum Knowledge Point Recommendation Algorithm Based on Learning Diagnosis Model. In Proceedings of the 2020 5th International Conference on Electromechanical Control Technology and Transportation (ICECTT), Nanchang, China, 5–17 May 2020; pp. 188–192. [Google Scholar]
- Ivanov, D.A.; Ivanova, I.V. Computer Self-Testing of Students as an Element of Distance Learning Technologies that Increase Interest in the Study of General Physics Course. In Proceedings of the 2018 IV International Conference on Information Technologies in Engineering Education (Inforino), Moscow, Russia, 22–26 October 2018; pp. 1–4. [Google Scholar]
- Anupama, V.; Elayidom, M.S. Course Recommendation System: Collaborative Filtering, Machine Learning and Topic Modelling. In Proceedings of the 2022 8th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 25–26 March 2022; Volume 1, pp. 1459–1462. [Google Scholar]
- Sabnis, V.; Tejaswini, P.D.; Sharvani, G.S. Course recommendations in moocs: Techniques and evaluation. In Proceedings of the 2018 3rd International Conference on Computational Systems and Information Technology for Sustainable Solutions (CSITSS), Bengaluru, India, 20–22 December 2018; pp. 59–66. [Google Scholar]
- Britto, J.; Prabhu, S.; Gawali, A.; Jadhav, Y. A Machine Learning Based Approach for Recommending Courses at Graduate Level. In Proceedings of the 2019 International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 27–29 November 2019; pp. 117–121. [Google Scholar]
- Peng, Y. A Survey on Modern Recommendation System based on Big Data. arXiv 2022, arXiv:2206.02631. [Google Scholar]
- Bozyiğit, A.; Bozyiğit, F.; Kilinç, D.; Nasiboğlu, E. Collaborative filtering based course recommender using OWA operators. In Proceedings of the 2018 International Symposium on Computers in Education (SIIE), Jerez, Spain, 19–21 September 2018; pp. 1–5. [Google Scholar]
- Mondal, B.; Patra, O.; Mishra, S.; Patra, P. A course recommendation system based on grades. In Proceedings of the 2020 International Conference on Computer Science, Engineering and Applications (ICCSEA), Gunupur, India, 13–14 March 2020; pp. 1–5. [Google Scholar]
- Lee, E.L.; Kuo, T.T.; Lin, S.D. A collaborative filtering-based two stage model with item dependency for course recommendation. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 496–503. [Google Scholar]
- Malhotra, I.; Chandra, P.; Lavanya, R. Course Recommendation using Domain-based Cluster Knowledge and Matrix Factorization. In Proceedings of the 2022 9th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, Indi, 23–25 March 2022; pp. 12–18. [Google Scholar]
- Huang, L.; Wang, C.D.; Chao, H.Y.; Lai, J.H.; Philip, S.Y. A score prediction approach for optional course recommendation via cross-user-domain collaborative filtering. IEEE Access 2019, 7, 19550–19563. [Google Scholar] [CrossRef]
- Zhao, L.; Pan, Z. Research on online course recommendation model based on improved collaborative filtering algorithm. In Proceedings of the 2021 IEEE 6th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA), Chengdu, China, 24–26 April 2021; pp. 437–440. [Google Scholar]
- Ceyhan, M.; Okyay, S.; Kartal, Y.; Adar, N. The Prediction of Student Grades Using Collaborative Filtering in a Course Recommender System. In Proceedings of the 2021 5th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 21–23 October 2021; pp. 177–181. [Google Scholar]
- Dwivedi, S.; Roshni, V.K. Recommender system for big data in education. In Proceedings of the 2017 5th National Conference on E-Learning & E-Learning Technologies (ELELTECH), Hyderabad, India, 3–4 August 2017; pp. 1–4. [Google Scholar]
- Zhong, S.T.; Huang, L.; Wang, C.D.; Lai, J.H. Constrained matrix factorization for course score prediction. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 1510–1515. [Google Scholar]
- Chen, Z.; Song, W.; Liu, L. The application of association rules and interestingness in course selection system. In Proceedings of the 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Beijing, China, 10–12 March 2017; pp. 612–616. [Google Scholar]
- Chen, Z.; Liu, X.; Shang, L. Improved course recommendation algorithm based on collaborative filtering. In Proceedings of the 2020 International Conference on Big Data and Informatization Education (ICBDIE), Zhangjiajie, China, 23–25 April 2020; pp. 466–469. [Google Scholar]
- Ren, Z.; Ning, X.; Lan, A.S.; Rangwala, H. Grade prediction with neural collaborative filtering. In Proceedings of the 2019 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Washington, DC, USA, 5–8 October 2019; pp. 1–10. [Google Scholar]
- Fernández-García, A.J.; Rodríguez-Echeverría, R.; Preciado, J.C.; Manzano, J.M.C.; Sánchez-Figueroa, F. Creating a recommender system to support higher education students in the subject enrollment decision. IEEE Access 2020, 8, 189069–189088. [Google Scholar] [CrossRef]
- Adilaksa, Y.; Musdholifah, A. Recommendation System for Elective Courses using Content-based Filtering and Weighted Cosine Similarity. In Proceedings of the 2021 4th International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), Yogyakarta, Indonesia, 16–17 December 2021; pp. 51–55. [Google Scholar]
- Esteban, A.; Zafra, A.; Romero, C. Helping university students to choose elective courses by using a hybrid multi-criteria recommendation system with genetic optimization. Knowl.-Based Syst. 2020, 194, 105385. [Google Scholar] [CrossRef]
- Emon, M.I.; Shahiduzzaman, M.; Rakib, M.R.H.; Shathee, M.S.A.; Saha, S.; Kamran, M.N.; Fahim, J.H. Profile Based Course Recommendation System Using Association Rule Mining and Collaborative Filtering. In Proceedings of the 2021 International Conference on Science & Contemporary Technologies (ICSCT), Dhaka, Bangladesh, 5–7 August 2021; pp. 1–5. [Google Scholar]
- Alghamdi, S.; Sheta, O.; Adrees, M. A Framework of Prompting Intelligent System for Academic Advising Using Recommendation System Based on Association Rules. In Proceedings of the 2022 9th International Conference on Electrical and Electronics Engineering (ICEEE), Alanya, Turkey, 29–31 March 2022; pp. 392–398. [Google Scholar]
- Bharath, G.M.; Indumathy, M. Course Recommendation System in Social Learning Network (SLN) Using Hybrid Filtering. In Proceedings of the 2021 5th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 2–4 December 2021; pp. 1078–1083. [Google Scholar]
- Nafea, S.M.; Siewe, F.; He, Y. On recommendation of learning objects using felder-silverman learning style model. IEEE Access 2019, 7, 163034–163048. [Google Scholar] [CrossRef]
- Huang, X.; Tang, Y.; Qu, R.; Li, C.; Yuan, C.; Sun, S.; Xu, B. Course recommendation model in academic social networks based on association rules and multi-similarity. In Proceedings of the 2018 IEEE 22nd International Conference on Computer Supported Cooperative Work in Design (CSCWD), Nanjing, China, 9–11 May 2018; pp. 277–282. [Google Scholar]
- Baskota, A.; Ng, Y.K. A graduate school recommendation system using the multi-class support vector machine and KNN approaches. In Proceedings of the 2018 IEEE International Conference on Information Reuse and Integration (IRI), Salt Lake City, UT, USA, 6–9 July 2018; pp. 277–284. [Google Scholar]
- Jiang, W.; Pardos, Z.A.; Wei, Q. Goal-based course recommendation. In Proceedings of the 9th International Conference on Learning Analytics & Knowledge, Tempe, AZ, USA, 4–8 March 2019; pp. 36–45. [Google Scholar]
- Liang, Y.; Duan, X.; Ding, Y.; Kou, X.; Huang, J. Data Mining of Students’ Course Selection Based on Currency Rules and Decision Tree. In Proceedings of the 2019 4th International Conference on Big Data and Computing, Guangzhou, China, 10–12 May 2019; pp. 247–252. [Google Scholar]
- Isma’il, M.; Haruna, U.; Aliyu, G.; Abdulmumin, I.; Adamu, S. An autonomous courses recommender system for undergraduate using machine learning techniques. In Proceedings of the 2020 International Conference in Mathematics, Computer Engineering and Computer Science (ICMCECS), Ayobo, Nigeria, 18–21 March 2020; pp. 1–6. [Google Scholar]
- Revathy, M.; Kamalakkannan, S.; Kavitha, P. Machine Learning based Prediction of Dropout Students from the Education University using SMOTE. In Proceedings of the 2022 4th International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 January 2022; pp. 1750–1758. [Google Scholar]
- Oreshin, S.; Filchenkov, A.; Petrusha, P.; Krasheninnikov, E.; Panfilov, A.; Glukhov, I.; Kaliberda, Y.; Masalskiy, D.; Serdyukov, A.; Kazakovtsev, V.; et al. Implementing a Machine Learning Approach to Predicting Students’ Academic Outcomes. In Proceedings of the 2020 International Conference on Control, Robotics and Intelligent System, Xiamen, China, 27–29 October 2020; pp. 78–83. [Google Scholar]
- Verma, R. Applying Predictive Analytics in Elective Course Recommender System while preserving Student Course Preferences. In Proceedings of the 2018 IEEE 6th International Conference on MOOCs, Innovation and Technology in Education (MITE), Hyderabad, India, 29–30 November 2018; pp. 52–59. [Google Scholar]
- Bujang, S.D.A.; Selamat, A.; Ibrahim, R.; Krejcar, O.; Herrera-Viedma, E.; Fujita, H.; Ghani, N.A.M. Multiclass prediction model for student grade prediction using machine learning. IEEE Access 2021, 9, 95608–95621. [Google Scholar] [CrossRef]
- Srivastava, S.; Karigar, S.; Khanna, R.; Agarwal, R. Educational data mining: Classifier comparison for the course selection process. In Proceedings of the 2018 International Conference on Smart Computing and Electronic Enterprise (ICSCEE), Shah Alam, Malaysia, 11–12 July 2018; pp. 1–5. [Google Scholar]
- Abed, T.; Ajoodha, R.; Jadhav, A. A prediction model to improve student placement at a south african higher education institution. In Proceedings of the 2020 International SAUPEC/RobMech/PRASA Conference, Cape Town, South Africa, 29–31 January 2020; pp. 1–6. [Google Scholar]
- Uskov, V.L.; Bakken, J.P.; Byerly, A.; Shah, A. Machine learning-based predictive analytics of student academic performance in STEM education. In Proceedings of the 2019 IEEE Global Engineering Education Conference (EDUCON), Dubai, United Arab Emirates, 8–11 April 2019; pp. 1370–1376. [Google Scholar]
- Sankhe, V.; Shah, J.; Paranjape, T.; Shankarmani, R. Skill Based Course Recommendation System. In Proceedings of the 2020 IEEE International Conference on Computing, Power and Communication Technologies (GUCON), Greater Noida, India, 2–4 October 2020; pp. 573–576. [Google Scholar]
- Kamila, V.Z.; Subastian, E. KNN and Naive Bayes for Optional Advanced Courses Recommendation. In Proceedings of the 2019 International Conference on Electrical, Electronics and Information Engineering (ICEEIE), Denpasar, Indonesia, 3–4 October 2019; Volume 6, pp. 306–309. [Google Scholar]
- Shah, D.; Shah, P.; Banerjee, A. Similarity based regularization for online matrix-factorization problem: An application to course recommender systems. In Proceedings of the TENCON 2017—2017 IEEE Region 10 Conference, Penang, Malaysia, 5–8 November 2017; pp. 1874–1879. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | The Study Addresses Recommendation Systems in the Education Sector | Primary Study |
|---|---|---|
| Shminan et al. [12] | No | Yes |
| Wang et al. [13] | No | Yes |
| Shaptala et al. [14] | No | Yes |
| Zhao et al. [15] | No | Yes |
| ID Wahyono et al. [16] | No | Yes |
| Author | The Study Addresses Recommendation Systems in the Education Sector | Primary Study |
|---|---|---|
| Elghomary et al. [17] | No | Yes |
| Mufizar et al. [18] | No | Yes |
| Sutrisno et al. [19] | No | Yes |
| Gan et al. [20] | No | Yes |
| Ivanov et al. [21] | No | Yes |
| Author | Reason of Exclusion |
|---|---|
| Anupama et al. [22] | Did not imply empirical experiments and did not provide experiments results |
| Sabnis et al. [23] | The full text is not accessible |
| Author | Score | Total Score | Included | ||||
|---|---|---|---|---|---|---|---|
| Q1 | Q2 | Q3 | Q4 | Q5 | |||
| Britto et al. [24] | 1 | 0 | 0.5 | 0.5 | 0.5 | 2.5 | No |
| Obeidat et al. [9] | 0.5 | 1 | 0.5 | 0.5 | 0.5 | 3 | Yes |
| Authors and Year | Algorithms Used | Comparative Type |
|---|---|---|
| A. Bozyiğit et al., 2018 [26] | • Collaborative filtering; | Algorithm level |
| • OWA (ordered weighted average). | ||
| B. Mondal et al., 2020 [27] | • Collaborative filtering. | Algorithm level |
| E. L. Lee et al., 2017 [28] | • Two-stage collaborative filtering; | Algorithm level |
| • Personalized Ranking Matrix Factorization (BPR-MF); | ||
| • Course dependency regularization; | ||
| • Personalized PageRank; | ||
| • Linear RankSVM. | ||
| I. Malhotra et al., 2022 [29] | • Collaborative filtering; | Algorithm level |
| • Domain-based cluster knowledge; | ||
| • Cosine pairwise similarity evaluation; | ||
| • Singular value decomposition ++; | ||
| • Matrix factorization. | ||
| L. Huang et al., 2019 [30] | • Cross-user-domain collaborative filtering. | Algorithm level |
| L. Zhao et al., 2021 [31] | • Improved collaborative filtering; | Algorithm level |
| • Historical preference fusion similarity. | ||
| M. Ceyhan et al., 2021 [32] | • Collaborative filtering; | Algorithm level |
| • Correlation-based similarities: (Pearson correlation coefficient, median-based robust correlation coefficient); | ||
| • Distance-based similarities: Manhattan and Euclidian distance similarities. | ||
| R. Obeidat et al., 2019 [9] | • Collaborative filtering; | Algorithm level |
| • K-means clustering; | ||
| • Association rules (Apriori algorithm, sequential, pattern discovery using equivalence classes algorithm). | ||
| S. Dwivedi et al., 2017 [33] | • Collaborative filtering; | Algorithm level |
| • Similarity log-likelihood. | ||
| S.-T. Zhong et al., 2019 [34] | • Collaborative filtering; | Algorithm level |
| • Constrained matrix factorization. | ||
| Z. Chen et al., 2017 [35] | • Collaborative filtering; | Algorithm level |
| • Association rules (Apriori). | ||
| Z. Chen et al., 2020 [36] | • Collaborative filtering; | Algorithm level |
| • Improved cosine similarity; | ||
| • TF–IDF (term frequency–inverse document frequency). | ||
| Z. Ren et al., 2019 [37] | • Neural Collaborative Filtering (NCF). | Algorithm level |
| Authors and Year | Used Algorithms | Comparative Type |
|---|---|---|
| A. J. Fernández-García et al., 2020 [38] | • Content-based filtering. | Preprocessing level |
| Y. Adilaksa et al., 2021 [39] | • Content-based filtering; | Algorithm level |
| • Weighted cosine similarity; • TF–IDF. |
| Authors and Year | Used Algorithms | Comparative Type |
|---|---|---|
| Esteban, A. et al., 2020 [40] | • Hybrid recommender system; | Algorithm level |
| • Collaborative filtering; | ||
| • Content-based filtering; | ||
| • Genetic algorithm. | ||
| M. I. Emon et al., 2021 [41] | • Hybrid recommender system; | Algorithm level |
| • Collaborative filtering; | ||
| • Association rules (Apriori algorithm). | ||
| S. Alghamdi et al., 2022 [42] | • Hybrid recommender system; | Algorithm level |
| • Content-based filtering; | ||
| • Association rules (Apriori algorithm); | ||
| • Jaccard coefficient. | ||
| S. G. G et al., 2021 [43] | • Hybrid recommender system; | Algorithm level |
| • Collaborative filtering; | ||
| • Content-based filtering; | ||
| • Lasso; | ||
| • KNN; | ||
| • Weighted average. | ||
| S. M. Nafea et al., 2019 [44] | • Hybrid recommender system; | Algorithm level |
| • Felder–Silverman learning styles model; | ||
| • K-means clustering. | ||
| X. Huang et al., 2018 [45] | • Hybrid recommender system; | Algorithm level |
| • Association rules; | ||
| • Improved multi-similarity. |
| Authors and Year | Used Algorithms | Comparative Type |
|---|---|---|
| A. Baskota et al., 2018 [46] | • Forward feature selection; | Algorithm level |
| • K-Nearest Neighbor (KNN); | ||
| • Multi-class Support Vector Machines (MC-SVM). | ||
| Jiang, Weijie et al., 2019 [47] | • Goal-based filtering; | Algorithm level |
| • LSTM recurrent neural network. | ||
| Liang, Yu et al., 2019 [48] | • Currency rules; | Preprocessing level |
| • C4.5 decision tree. | ||
| M. Isma’il et al., 2020 [49] | • Support Vector Machine (SVM). | Algorithm level |
| M. Revathy et al., 2022 [50] | • KNN-SMOTE. | Algorithm level |
| Oreshin et al., 2020 [51] | • Latent Dirichlet Allocation; | Algorithm level |
| • FastTextSocialNetworkModel; | ||
| • Catboost. | ||
| R. Verma et al., 2018 [52] | • Support Vector Machines; | Algorithm level |
| • Artificial Neural Networks (ANN). | ||
| S. D. A. Bujang et al., 2021 [53] | • Random forests. | • Algorithm level |
| • Preprocessing level | ||
| S. Srivastava et al., 2018 [54] | • Support Vector Machines with radial basis kernel; | Algorithm level |
| • KNN. | ||
| T. Abed et al., 2020 [55] | • Naive Bayes. | Algorithm level |
| V. L. Uskov et al., 2019 [56] | • Linear regression. | Algorithm level |
| V. Sankhe et al., 2020 [57] | • Skill-based filtering; | Algorithm level |
| • C-means fuzzy clustering; | ||
| • Weighted mode. | ||
| V. Z. Kamila et al., 2019 [58] | • KNN; | algorithm level |
| • Naive Bayes. |
| Authors and Year | Used Algorithms | Comparative Type |
|---|---|---|
| D. Shah et al., 2017 [59] | • Similarity-based regularization; | Algorithm level |
| • Matrix factorization. |
| Authors and Year | Public | Records | Students | Courses | Majors | Features | Used Features | Preprocessing Steps | Data-Splitting Method |
|---|---|---|---|---|---|---|---|---|---|
| A. Bozyiğit et al., 2018 [26] | No | N/A | 221 | 76 | N/A | N/A | N/A | N/A | Ten-fold cross-validation. |
| B. Mondal et al., 2020 [27] | No | 300 | 300 | N/A | N/A | 48 | 12 | • Data cleaning: lowercase conversion, removing punctuation, striping white spaces. | N/A |
| E. L. Lee et al., 2017 [28] | No | 896,616 | 13,977 | N/A | N/A | N/A | N/A | • Ignore the students whose 4-year registration records are incomplete. | Nested time-series split cross-validation (class 2008, class 2009 as a training set, and class 2010 as a testing set). |
| I. Malhotra et al., 2022 [29] | No | N/A | 1780 | N/A | 9 | N/A | N/A | N/A | N/A |
| L. Huang et al., 2019 [30] | No | 52,311 | 1166 | N/A | 8 | N/A | N/A | N/A | N/A |
| L. Zhao et al., 2021 [31] | No | N/A | 43,916 | 240 | N/A | N/A | N/A | • Group data based on interest data points, • Eliminate noise by filtering the data noise constrained in 0,1, • Normalize all numerical features. | Five-fold cross-validation. |
| M. Ceyhan et al., 2021 [32] | No | N/A | 1506 | 1460 | N/A | N/A | N/A | • The updated grade is taken into consideration if a student retakes any course. | • Nested time-series split cross-validation, • Train = 91.7% (from 2010/11-F to 2019/20-S), • Test = 8.3% (the whole 2020/21-F). |
| R. Obeidat et al., 2019 [9] | Yes | 22,144 | 10,000 | 16 | N/A | N/A | N/A | • Remove incomplete records • Calculate the order of courses sequences events for each student, • Convert grades to a new grade scale, • Cluster students. | N/A |
| S. Dwivedi et al., 2017 [33] | No | N/A | N/A | N/A | N/A | N/A | N/A | • Data cleaning, • Data discretization (converting low-level concept to high-level concept). | N/A |
| S. -T. Zhong et al., 2019 [34] | No | N/A | N/A | N/A | 8 | N/A | N/A | N/A | N/A |
| Z. Chen et al., 2017 [35] | No | N/A | N/A | N/A | N/A | N/A | N/A | Students’ score categorization (A, B, C). | N/A |
| Z. Chen et al., 2020 [36] | No | 18,457 | 2022 | 309 | N/A | N/A | N/A | N/A | K-fold cross-validation. |
| Z. Ren et al., 2019 [37] | No | N/A | 43,099 | N/A | 151 | N/A | N/A | Used different embedding dimensions for students, courses, and course instructors for different majors. | Nested time-series split cross-validation (data from Fall 2009 to Fall 2015 as a training set, and data from Spring 2016 as a testing set). |
| Authors and Year | Public | Records | Students | Courses | Majors | Features | Features Used | Preprocessing Steps | Data-Splitting Method |
|---|---|---|---|---|---|---|---|---|---|
| A. J. Fernández-García et al., 2020 [38] | No | 6948 | 323 | N/A | N/A | 10 | 10 | • Feature deletion, • Class reduction, • One-hot encoding, • Creating new features, • Data scaling: MinMax Scaler, Standard Scaler, Robust Scaler, and Normalizer Scaler, • Data resampling: upsample, downsample, SMOTE. | • Train size = 80%, • Test size = 20%. |
| Y. Adilaksa et al., 2021 [39] | No | N/A | N/A | N/A | N/A | N/A | N/A | • Case folding, • Word tokenization, • Punctuation removal, • Stop words removal. | N/A |
| Authors and Year | Pub | Recs | Students | Courses | Majors | Features | Used Features | Preprocessing Steps | Data-Splitting Method |
|---|---|---|---|---|---|---|---|---|---|
| Esteban, A. et al., 2020 [40] | No | 2500C | 95 | 63 | N/A | N/A | N/A | N/A | Five-fold cross-validation. |
| M. I. Emon et al., 2021 [41] | No | N/A | 250+ | 250+ | 20+ | N/A | N/A | Feature extraction. | N/A |
| S. Alghamdi et al., 2022 [42] | No | 1820 | 38 | 48 | N/A | N/A | 7 | Cluster sets for academic transcript datasets. | Five-fold cross-validation. |
| S. G. G et al., 2021 [43] | No | N/A | ~6000 | ~4000 | 18 | N/A | N/A | N/A | N/A |
| S. M. Nafea et al., 2019 [44] | No | N/A | 80 | N/A | N/A | N/A | N/A | N/A | Student dataset was split into cold-start students, cold-start learning objects, and all students. |
| X. Huang et al., 2018 [45] | Yes | N/A | 56,600 | 860 | N/A | N/A | N/A | N/A | • Train size = 80%, • Test size = 20%. |
| Authors and Year | Public | Records | Students | Courses | Majors | Features | Features Used | Preprocessing Steps | Data-Splitting Method |
|---|---|---|---|---|---|---|---|---|---|
| A. Baskota et al., 2018 [46] | No | 16,000 | N/A | N/A | N/A | N/A | N/A | • Data cleaning, • Data scaling. | • Train size = 14,000, • Test size = 2000. |
| Jiang, Weijie et al., 2019 [47] | No | 4,800,000 | 164,196 | 10,430 | 17 | N/A | N/A | N/A | Nested time-series split cross-validation (data from F’08 to F’15 as a training set, data in Sp’16 as validation set & data in Sp’17 as test set) |
| Liang, Yu et al., 2019 [48] | No | 35,000 | N/A | N/A | N/A | N/A | N/A | Data cleaning. | N/A |
| M. Isma’il et al., 2020 [49] | No | 8700 | N/A | 9 | N/A | N/A | 4 | • Data cleaning, • Data encoding. | N/A |
| M. Revathy et al., 2022 [50] | No | N/A | 1243 | N/A | N/A | N/A | 33 | • One-hot encoding for categorical features, • Principal Component Analysis (PCA). | • Train size = 804, • Test size = 359. |
| Oreshin et al., 2020 [51] | No | N/A | >20,000 | N/A | N/A | N/A | 112 | • One-hot encoding, • Removed samples with unknown values. | Nested time-series split cross-validation. |
| R. Verma et al., 2018 [52] | No | 658 | 658 | N/A | N/A | 13 | 11 | Data categorization. | Ten-fold cross-validation. |
| S. D. A. Bujang et al., 2021 [53] | No | 1282 | 641 | 2 | N/A | 13 | N/A | • Ranked and grouped the students into five categories of grades, • Applied oversampling SMOTE (Synthetic Minority Over-sampling Technique), • Applied two feature selection methods: Wrapper and filter-based. | Ten-fold cross-validation. |
| S. Srivastava et al., 2018 [54] | No | 1988 | 2890 | N/A | N/A | N/A | 14 | Registration number transformation. | • Train = 1312, • Test = 676. |
| T. Abed et al., 2020 [55] | No | N/A | N/A | N/A | N/A | N/A | 18 | Balanced the dataset using under sampling. | Ten-fold cross-validation. |
| V. L. Uskov et al., 2019 [56] | No | 90+ | N/A | N/A | N/A | 16 | N/A | Data cleaning | • Train = 80%, • Test = 20%. |
| V. Sankhe et al., 2020 [57] | No | N/A | 2000 | 15 | 7 | N/A | N/A | N/A | N/A |
| V. Z. Kamila et al., 2019 [58] | No | N/A | N/A | N/A | N/A | N/A | N/A | N/A | • Train size = 75%, • Test size= 25%. |
| Authors and Year | Public | Records | Students | Courses | Majors | Features | Features Used | Preprocessing Steps | Data-Splitting Method |
|---|---|---|---|---|---|---|---|---|---|
| D. Shah et al., 2017 [59] | No | N/A | • Dataset 1 = 300 students • Dataset 2 = 84 students | • Dataset 1 = 10 • Dataset 2 = 26 | N/A | N/A | • Student features = 3 • Course features = 30 | N/A | • Train size = 90% • Test size = 10% |
| Authors and Year | Evaluation Metrics and Values | Strengths | Weaknesses |
|---|---|---|---|
| A. Bozyiğit et al., 2018 [26] | MAE = 0.063. | • Compared the performance of the proposed OWA approach with the performance of other popular approaches. | • The number of features and features used in the dataset is not provided, • The dataset description is not detailed, • Did not use RMSE for evaluation, considered the standard as it’s more accurate, • Mentioned that some preprocessing had been carried out but did not give any details regarding it. |
| B. Mondal et al., 2020 [27] | • MSE = 3.609, • MAE = 1.133, • RMSE = 1.8998089, • Precision, • Recall. | • Used many metrics for evaluation, • The implementation of algorithms is comprehensively explained. | • Did not mention whether they split data for testing or used the training data for testing, • Did not provide the exact measures of precision and recall. |
| E. L. Lee et al., 2017 [28] | AUC = 0.9709. | • Compared the performance of the proposed approach with the performance of other approaches, • Used a very large dataset, • Achieved a very high AUC, • The implementation of algorithms is comprehensively explained. | • Did not provide the percentage of the train-test split, • The number of courses in the dataset is not mentioned (it only mentions course registration records). |
| I. Malhotra et al., 2022 [29] | • MAE = 0.468, • RMSE = 0.781. | • The implementation of algorithms is comprehensively explained with examples, • Used RMSE and MAE for evaluation. | • The dataset description is not detailed, • The method of splitting the training and testing dataset is not provided, • Did not mention whether they have done any preprocessing on the dataset or if it was used as it is, • The proposed approach is not compared to any other approaches in the evaluation section. |
| L. Huang et al., 2019 [30] | • AverHitRate between 0.6538, 1, • AverACC between 0.8347, 1. | • The literature is meticulously discussed, • The implementation is comprehensively explained in detail. | • The method of splitting the training and testing dataset is not provided, • Did not mention whether they have conducted any preprocessing on the dataset or if it was used as it is. |
| L. Zhao et al., 2021 [31] | • Precision, • Recall. | • The implementation is comprehensively explained. | • The exact numbers for the evaluation metrics used in the paper are not provided, • The numbers of features and features used in the dataset are not provided. |
| M. Ceyhan et al., 2021 [32] | • Coverage, • F1-measure, • Precision, • Sensitivity, • Specificity, • MAE, • RMSE, • Binary MAE, • Binary RMSE. | • Used many metrics for evaluation. | • The implemented algorithm and similarities explanation were very brief |
| R. Obeidat et al., 2019 [9] | • Coverage measure (using SPADES | with clustering) = 0.376, 0.28, 0.594, 0.546, • Coverage measure (using Apriori | with clustering) = 0.46, 0.348, 0.582, 0.534. | • Confirmed by experiment that clustering significantly improves the generation and coverage of two association rules: SPADES and Apriori | • The dataset description is not detailed, • The method of splitting the training and testing dataset is not provided, • The implementation is not discussed in detail. |
| S. Dwivedi et al., 2017 [33] | • RMSE = 0.46. | • The proposed system is efficient as it proved to work well with big data, • The implementation of algorithms is comprehensively explained. | • Did not provide any information about the dataset, • The literature review section was very brief. |
| S.-T. Zhong et al., 2019 [34] | • MAE (CS major) = 6.6764 ± 0.0029, • RMSE (CS major) = 4.5320 ± 0.0022. | • Used eight datasets for model training and evaluation, • Dataset description is detailed, • Compared the performance of the proposed approach with the performance of other popular approaches. | • The percentage of train-test splitting is not consistent among the eight datasets. |
| Z. Chen et al., 2017 [35] | • Confidence, • Support. | • The implementation of algorithms is comprehensively explained with examples. | • Did not provide any information about the used dataset, • Did not include any information about the preprocessing of the dataset, • Did not provide useful metrics for evaluation, • The performance of the proposed approach is not compared to other similar approaches. |
| Z. Chen et al., 2020 [36] | • Precision, • Recall, • F1-score. | • Compared the performance of the proposed approach with the performance of other popular approaches: cosine similarity and improved cosine similarity. | • The exact numbers for the evaluation metrics used in the paper are not provided, • The numbers of features and features used in the dataset are not provided. |
| Z. Ren et al., 2019 [37] | • PTA, • MAE. | • Compared the performance of the proposed approach with the performance of other approaches, • The implementation of algorithms is comprehensively explained, • The number of students in the dataset is big. | • The dataset description is not detailed. |
| Authors and Year | Evaluation Metrics and Values | Strengths | Weaknesses |
|---|---|---|---|
| A. J. Fernández-García et al., 2020 [38] | • Accuracy, • Precision, • Recall, • F1-score. | • Included a section that contains the implementation code, • The literature is meticulously discussed and followed by a table for a summary, • Compared the effect of various preprocessing steps on the final measures of different machine-learning approaches and provided full details about these metrics, • The implementation of each preprocessing step is explained in detail. | • N/A |
| Y. Adilaksa et al., 2021 [39] | • The percentage of recommendation diversity = 81.67%, • Accuracy = 64%. | • The preprocessing steps are discussed in detail, • The implementation is comprehensively explained, • Confirmed by the experiment that using the weighted cosine similarity instead of the traditional cosine similarity significantly increased the accuracy of the course recommendations system. | • Did not provide any information about the used dataset, • The method of splitting the training and testing dataset is not provided, • The accuracy measurement is not specified. |
| Authors and Year | Evaluation Metrics and Values | Strengths | Weaknesses |
|---|---|---|---|
| Esteban, A. et al., 2020 [40] | • RMSE = 0.971, • Normalized discount cumulative gain (nDCG) = 0.682, • Reach = 100%, • Time = 3.022s. | • The literature is meticulously discussed and followed by a table for a summary, • The implementation of algorithms is comprehensively explained with examples, • Compared the performance of the proposed hybrid approach with other similar approaches, • Used many useful metrics for evaluation. | • Mentioned that some preprocessing had been carried out but did not give any details regarding it, • The number of students in the dataset is relatively low. |
| M. I. Emon et al., 2021 [41] | • Accuracy, • Precision, • Recall, • F1-score. | • Compared the performance of the proposed hybrid approach with the used standalone algorithms. | • The exact numbers for the evaluation metrics used in the paper are not provided, • The dataset description is not detailed, • The method of splitting the training and testing dataset is not provided. |
| S. Alghamdi et al., 2022 [42] | • MAE = 0.772, • RMSE = 1.215. | • The dataset description is detailed, • The implementation of algorithms is clearly explained. | • Other similar approaches are not stated in the literature, • The number of students in the dataset is relatively low. |
| S. G. G et al., 2021 [43] | RMSE = 0.931. | • EDA of the dataset is included in the paper, • Compared the performance of different approaches against the proposed approach, • The implementation is comprehensively discussed and explained. | • The dataset description is not detailed, • The method of splitting the training and testing dataset is not provided, • Similar approaches are not stated in the literature, • Did not mention whether they conducted any preprocessing on the dataset or if it was used as it is. |
| S. M. Nafea et al., 2019 [44] | • MAE for cold students = 0.162, • RMSE for cold students = 0.26, • MAE for cold Learning Objects (Los) = 0.162, • RMSE for cold LOs = 0.3. | • Achieved higher accuracy than standalone traditional approaches mentioned in the paper: collaborative filtering and content-based recommendations, • The implementation is comprehensively explained with examples. | • Mentioned that some preprocessing had been carried out but did not give any details regarding it, • The dataset description is not detailed, • The number of students in the dataset is relatively low. |
| X. Huang et al., 2018 [45] | • Precision, • Recall, • F1-score. | • The implementation of the proposed approach is comprehensively explained with examples, • Compared the performance of the proposed hybrid approach with other similar approaches through testing. | • The dataset description is not detailed, • Did not mention whether they have done any preprocessing on the dataset or if it was used as it is, • The exact numbers for the evaluation metrics used in the paper are not provided. |
| Authors and Year | Evaluation Metrics and Values | Strengths | Weaknesses |
|---|---|---|---|
| A. Baskota et al., 2018 [46] | • Accuracy = 61.6%, • Precision = 61.2%, • Recall = 62.6%, • F1-score = 61.5%. | • Compared the performance of the proposed approach with the performance of other popular approaches, • Used many evaluation metrics and provided the exact numbers for each metric for the evaluation result. | • The dataset description is not detailed. |
| Jiang, Weijie et al., 2019 [47] | • The A model: accuracy = 75.23%, F-score = 60.24%, • The B model: accuracy = 88.05%, F-score = 42.01%. | • The implementation of algorithms is comprehensively explained with examples, • Included various sets of hyperparameters and carried out extensive testing. | • Did not mention whether they have done any preprocessing on the dataset or if it was used as it is, • Did not mention the number of features in the dataset, • The performance of the proposed approach is not compared to other similar approaches, • Did not mention the exact percentages for splitting data. |
| Liang, Yu et al., 2019 [48] | • Support rate. | • The implementation of algorithms is comprehensively explained. | • The dataset description is not detailed, • A literature review has not been discussed, • The performance of the proposed approach is not compared to other similar approaches, • Did not provide many useful metrics for evaluation and explained that was due to the large number of data sets selected for the experiment. |
| M. Isma’il et al., 2020 [49] | • Accuracy = 99.94%. | • Compared the performance of the proposed machine-learning algorithm with the performance of other algorithms through testing. | • Did not mention the training and test set sizes, • The machine learning algorithms used are not explained, • Only used the accuracy measure for evaluation, • The dataset description is not detailed. |
| M. Revathy et al., 2022 [50] | • Accuracy = 97.59%, • Precision = 97.52%, • Recall = 98.74%, • Sensitivity = 98.74%, • Specificity = 95.56%. | • Used many evaluation metrics and provided the exact numbers for each metric for the evaluation result, • Provided detailed information about the preprocessing steps, • Compared the performance of the proposed approach with the performance of other approaches, • Provided the exact numbers for each metric for the evaluation result. | N/A |
| Oreshin et al., 2020 [51] | • Accuracy = 0.91 ± 0.02, • ROC-AUC = 0.97 ± 0.01, • Recall = 0.83 ± 0.02, • Precision = 0.86 ± 0.03. | • Used many evaluation metrics and provided the exact numbers for each metric for the evaluation result, • Provided detailed information about the preprocessing steps. | • Contains many English grammar and vocabulary errors, • The dataset description is not detailed, • The machine learning algorithms used are not explained, • Did not specify the parameters for the nested time-series split cross-validation. |
| R. Verma et al., 2018 [52] | • Accuracy (SVM) = 88.5%, • Precision, • Recall, • F1-score. | • The implementation of algorithms is comprehensively explained, • Compared the performance of several machine-learning algorithms with the performance of other algorithms through testing and concluded that the best two were SVM and ANN. | • The exact numbers for the evaluation metrics used in the paper are not provided except for the achieved accuracy of SVM. |
| S. D. A. Bujang et al., 2021 [53] | • Accuracy = 99.5%, • Precision 99.5%, • Recall = 99.5%, • F1-score = 99.5%. | • Included all the exact numbers for the evaluation metrics used in the evaluation, • Compared the performance of six machine learning algorithms and concluded that random forests performed the best based on the evaluation metrics, • EDA of the dataset is included in the paper, • The literature is meticulously discussed and followed by a table for a summary, • Provided detailed information about the used dataset. | • The number of courses is very low (only 2). |
| S. Srivastava et al., 2018 [54] | • Accuracy (from 1 cluster to 100) = 99.40%:87.72%. | • Compared the performance of the proposed approach with the performance of other popular approaches, • Provided a confusion matrix for all the used approaches. | • Accuracy is the only metric used for evaluation, • The dataset description is not detailed. |
| T. Abed et al., 2020 [55] | • Accuracy = 69.18%. | • Compared the performance of the proposed approach with the performance of other popular approaches: Random Forest, J48, Naive Bayes, Logistic Regression, Sequential Minimal Optimization, and a Multilayer Perceptron. | • The dataset description is not detailed, • Only used the accuracy measure for evaluation, • Did not include an explanation for the implemented algorithms and why they were initially chosen. |
| V. L. Uskov et al., 2019 [56] | • Average error = 3.70%. | • Through extensive testing of various ML algorithms, they concluded that linear regression was the best candidate for the problem as the data was linear; • The implementation of algorithms is comprehensively explained. | • The dataset description is not detailed, • Only used the accuracy measure for evaluation, • Did not use RMSE for the evaluation of linear regression. |
| V. Sankhe et al., 2020 [57] | • Accuracy = 81.3% | • The implementation of algorithms is comprehensively explained. | • The dataset description is not detailed, • The method of splitting the training and testing dataset is not provided, • Did not mention whether they have conducted any preprocessing on the dataset or if it was used as it is. |
| V. Z. Kamila et al., 2019 [58] | • Accuracy of KNN K = 1:100.00% • Accuracy of Naive Bayes algorithm = 100.00% | • Provided the exact numbers for each metric for the evaluation result. | • The implemented algorithms explanation was very brief, • The performance of the proposed approach is not compared to other similar approaches, • Did not provide any information about the dataset used, • Did not mention whether they have conducted any preprocessing on the dataset or if it was used as it is. |
| Authors and Year | Evaluation Metrics | Strengths | Weaknesses |
|---|---|---|---|
| D. Shah et al., 2017 [59] | • Normalized mean absolute error (NMAE) = 0.0023, • Computational Time Comparison. | • The implementation of the two compared algorithms is comprehensively explained, • Compared the accuracy of recommendations from both algorithms as well as the speed. | • Did not mention whether they have conducted any preprocessing on the dataset or if it was used as it is, • Similar approaches are not stated in the literature, in addition, the literature was very brief, • Did not use RMSE for evaluation, which is considered the standard as its more accurate. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Algarni, S.; Sheldon, F. Systematic Review of Recommendation Systems for Course Selection. Mach. Learn. Knowl. Extr. 2023, 5, 560-596. https://doi.org/10.3390/make5020033
Algarni S, Sheldon F. Systematic Review of Recommendation Systems for Course Selection. Machine Learning and Knowledge Extraction. 2023; 5(2):560-596. https://doi.org/10.3390/make5020033
Chicago/Turabian StyleAlgarni, Shrooq, and Frederick Sheldon. 2023. "Systematic Review of Recommendation Systems for Course Selection" Machine Learning and Knowledge Extraction 5, no. 2: 560-596. https://doi.org/10.3390/make5020033