
Partially Observable Mean Field Multi-Agent Reinforcement Learning Based on Graph Attention Network for UAV Swarms


Abstract
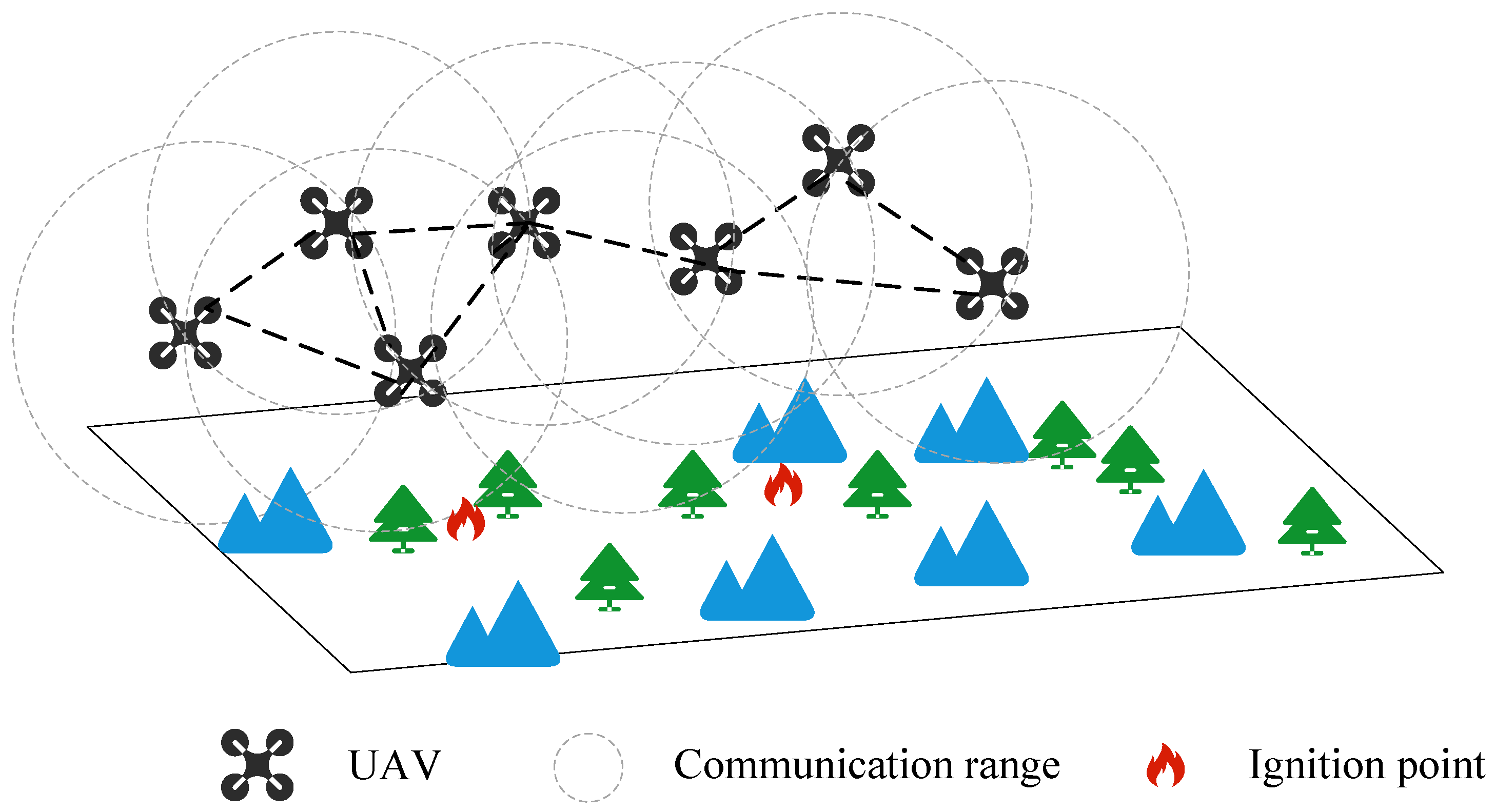
:1. Introduction
- We propose a Graph attention network supported Partially observable Mean Field Multi-agent reinforcement learning (GPMF) algorithm, which can learn a decentralized agent policy from an environment without requiring global information of an environment. This is particularly valuable in scenarios with large-scale agents and limited observability, where existing methods lack sufficient judgment of the importance of neighbor agents.
- We provide theoretical evidence that the settings of the GPMF algorithm approach Nash equilibrium, showcasing its sound theoretical foundation.
- Experiments on three challenging game tasks in the MAgents framework show that GPMF outperforms two baseline algorithms as well as the state-of-the-art partially observable mean field reinforcement learning algorithms. These results validate the effectiveness of GPMF in solving dynamic cooperation problems in multi-UAV scenarios and facilitating collaboration among UAVs.
2. Related Work
2.1. Multi-UAV System Based on Multi-Agent Reinforcement Learning
2.2. Large-Scale Partially Observable Multi-Agent Reinforcement Learning
2.3. Graph Neural Networks (GNNs)
3. Motivation and Preliminaries
3.1. Partially Observable Markov Decision Process
3.2. Partially Observable Mean Field Q-Learning
3.3. Graph Attention Network
4. Approach
4.1. Graph Attention Module
4.2. Mean Field Module
4.3. Theoretical Proof
4.4. Algorithm
| Algorithm 1 Partially Observable Mean Field MARL Based on Graph Attention Network |
|
5. Experiments
5.1. Environment and Tasks
- Multibattle game: There are two groups of UAVs participating in the competition scenario, each consisting of 25 UAVs. UAV gets −0.005 points for each movement, −0.1 points for attacking open space, 200 points for collision causing enemy UAV to fall, and 0.2 points for successful collision. Each UAV has a size of 2 × 2, a maximum health of 10 units, and a speed of 2 units. At the end of the mission, the team with the most surviving UAVs wins. If two teams have the same number of surviving UAVs, the team with the highest reward wins. Each team’s reward is the sum of the rewards of the individual UAVs in the team.
- Battle-Gathering game: The distribution of resources in the environment is uniform, and each UAV can observe the location of all resources. In addition to rewards for shooting down enemy UAVs, each UAV can also occupy resources to obtain rewards. UAVs get 5 points for collides enemy UAVs, and the rest of the reward settings are the same as the Multibattle environment.
- Predator-Prey game: There are 40 predators (big UAVs) and 20 preys (small UAVs), respectively simulating two groups of UAVs. Each large UAV is a square with a size of 2 × 2, with a maximum health of 10 units and a speed of 2 units. The small UAV is a 1 × 1 square with a maximum health of 2 units and a speed of 2.5 units. In order to complete the task, the large UAV must collide with more small UAVs, and the small UAVs must try to evade. In addition, large UAVs and small UAVs have different reward functions. Specifically, large UAVs get −0.3 points for attacking spaces, 1 point for successful collisions with small UAVs, 100 points for shooting down small UAVs, −1 point for collisions with small UAVs, and large UAV drops earn 0.5 points. Unlike the Multibattle environment, when the round ends for a fairer duel, if the two teams have the same number of surviving UAVs, it is judged as a draw.
5.2. Evaluation
5.3. Hyperparameters
6. Results and Discussion
6.1. Reward
6.2. ELO Calculation
6.3. Results
6.4. Visualization
6.5. Ablation Study
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MARL | Multi-agent reinforcement learning |
| GAN | graph attention network |
| POMF | partially observable mean field |
| MAS | multi-agent system |
| POMDP | partially observable Markov decision process |
References
- Frattolillo, F.; Brunori, D.; Iocchi, L. Scalable and Cooperative Deep Reinforcement Learning Approaches for Multi-UAV Systems: A Systematic Review. Drones 2023, 7, 236. [Google Scholar] [CrossRef]
- Wang, J.; Han, L.; Dong, X.; Li, Q.; Ren, Z. Distributed sliding mode control for time-varying formation tracking of multi-UAV system with a dynamic leader. Aerosp. Sci. Technol. 2021, 111, 106549. [Google Scholar] [CrossRef]
- Shi, H.; Liu, G.; Zhang, K.; Zhou, Z.; Wang, J. MARL Sim2real Transfer: Merging Physical Reality With Digital Virtuality in Metaverse. IEEE Trans. Syst. Man Cybern. Syst. 2022, 53, 2107–2117. [Google Scholar] [CrossRef]
- Weng, Q.L.; Liu, G.J.; Zhou, P.; Shi, H.R.; Zhang, K.W. Co-TS: Design and Implementation of a 2-UAV Cooperative Transportation System. Int. J. Micro Air Veh. 2023, 15, 17568293231158443. [Google Scholar] [CrossRef]
- Zhou, P.; Liu, G.; Wang, J.; Weng, Q.; Zhang, K.; Zhou, Z. Lightweight unmanned aerial vehicle video object detection based on spatial-temporal correlation. Int. J. Commun. Syst. 2022, 35, e5334. [Google Scholar] [CrossRef]
- Uhrmacher, A.M.; Weyns, D. Multi-Agent Systems: SIMULATION and Applications; CRC press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Cui, Y.; Luo, B.; Feng, Z.; Huang, T.; Gong, X. Resilient state containment of multi-agent systems against composite attacks via output feedback: A sampled-based event-triggered hierarchical approach. Inf. Sci. 2023, 629, 77–95. [Google Scholar] [CrossRef]
- Zhou, Z.; Liu, G.; Tang, Y. Multi-Agent Reinforcement Learning: Methods, Applications, Visionary Prospects, and Challenges. arXiv 2023, arXiv:2305.10091. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- Zhou, Z.; Liu, G.; Zhou, M. A Robust Mean-Field Actor-Critic Reinforcement Learning Against Adversarial Perturbations on Agent States. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–12. [Google Scholar] [CrossRef]
- Zhou, Z.; Liu, G. Robustness Testing for Multi-Agent Reinforcement Learning: State Perturbations on Critical Agents. arXiv 2023, arXiv:2306.06136. [Google Scholar]
- Guo, X.; Bi, Z.; Wang, J.; Qin, S.; Liu, S.; Qi, L. Reinforcement learning for disassembly system optimization problems: A survey. Int. J. Netw. Dyn. Intell. 2023, 2, 1–14. [Google Scholar] [CrossRef]
- Gu, J.; Wang, J.; Guo, X.; Liu, G.; Qin, S.; Bi, Z. A Metaverse-Based Teaching Building Evacuation Training System With Deep Reinforcement Learning. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 2209–2219. [Google Scholar] [CrossRef]
- Zhang, K.; Yang, Z.; Başar, T. Multi-agent reinforcement learning: A selective overview of theories and algorithms. In Handbook of Reinforcement Learning and Control; Springer: Berlin/Heidelberg, Germany, 2021; pp. 321–384. [Google Scholar]
- Schmidt, L.M.; Brosig, J.; Plinge, A.; Eskofier, B.M.; Mutschler, C. An Introduction to Multi-Agent Reinforcement Learning and Review of its Application to Autonomous Mobility. arXiv 2022, arXiv:2203.07676. [Google Scholar]
- Zhang, Z.; Liu, J.; Liu, G.; Wang, J.; Zhang, J. Robustness verification of swish neural networks embedded in autonomous driving systems. IEEE Trans. Comput. Soc. Syst. 2022, 1–10. [Google Scholar] [CrossRef]
- Liu, B.; Wang, S.; Li, Q.; Zhao, X.; Pan, Y.; Wang, C. Task Assignment of UAV Swarms Based on Deep Reinforcement Learning. Drones 2023, 7, 297. [Google Scholar] [CrossRef]
- Hernandez-Leal, P.; Kartal, B.; Taylor, M.E. A survey and critique of multiagent deep reinforcement learning. Auton. Agents Multi-Agent Syst. 2019, 6, 750–797. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Luo, R.; Li, M.; Zhou, M.; Zhang, W.; Wang, J. Mean Field Multi-Agent Reinforcement Learning. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 5567–5576. [Google Scholar]
- Xie, Q.; Yang, Z.; Wang, Z.; Minca, A. Learning while playing in mean-field games: Convergence and optimality. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 18–24 July 2021; pp. 11436–11447. [Google Scholar]
- Laurière, M.; Perrin, S.; Geist, M.; Pietquin, O. Learning Mean Field Games: A Survey. arXiv 2022, arXiv:2205.12944. [Google Scholar]
- Cai, Q.; Yang, Z.; Wang, Z. Reinforcement learning from partial observation: Linear function approximation with provable sample efficiency. In Proceedings of the International Conference on Machine Learning. PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 2485–2522. [Google Scholar]
- Zhang, T.; Ye, Q.; Bian, J.; Xie, G.; Liu, T. MFVFD: A Multi-Agent Q-Learning Approach to Cooperative and Non-Cooperative Tasks. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event/ Montreal, QC, Canada, 19–27 August 2021; pp. 500–506. [CrossRef]
- Gu, H.; Guo, X.; Wei, X.; Xu, R. Mean-field multi-agent reinforcement learning: A decentralized network approach. arXiv 2021, arXiv:2108.02731. [Google Scholar] [CrossRef]
- Fang, B.; Wu, B.; Wang, Z.; Wang, H. Large-Scale Multi-agent Reinforcement Learning Based on Weighted Mean Field. In Proceedings of the Cognitive Systems and Signal Processing—5th International Conference, ICCSIP 2020, Zhuhai, China, 25–27 December 2020; Volume 1397, pp. 309–316. [Google Scholar]
- Zhou, S.; Ren, W.; Ren, X.; Yi, X. Multi-Agent Mean Field Predict Reinforcement Learning. In Proceedings of the 2020 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 25–27 August 2020; pp. 625–629. [Google Scholar]
- Subramanian, S.G.; Taylor, M.E.; Crowley, M.; Poupart, P. Partially Observable Mean Field Reinforcement Learning. In Proceedings of the AAMAS ’21: 20th International Conference on Autonomous Agents and Multiagent Systems, Virtual Event, 3–7 May 2021; pp. 537–545. [Google Scholar]
- Wu, T.; Li, W.; Jin, B.; Zhang, W.; Wang, X. Weighted Mean-Field Multi-Agent Reinforcement Learning via Reward Attribution Decomposition. In Proceedings of the International Conference on Database Systems for Advanced Applications, Virtual Event, 11–14 April 2022; pp. 301–316. [Google Scholar]
- Hao, Q. Very Large Scale Multi-Agent Reinforcement Learning with Graph Attention Mean Field. 2023. Available online: https://openreview.net/forum?id=MdiVU9lMmVS (accessed on 5 March 2023).
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [Green Version]
- Fan, S.; Liu, G.; Li, J. A heterogeneous graph neural network with attribute enhancement and structure-aware attention. IEEE Trans. Comput. Soc. Syst. 2023. [Google Scholar] [CrossRef]
- Lou, X.; Liu, G.; Li, J. ASIAM-HGNN: Automatic Selection and Interpretable Aggregation of Meta-Path Instances for Heterogeneous Graph Neural Network. Comput. Inform. 2023, 42, 257–279. [Google Scholar] [CrossRef]
- Qie, H.; Shi, D.; Shen, T.; Xu, X.; Li, Y.; Wang, L. Joint optimization of multi-UAV target assignment and path planning based on multi-agent reinforcement learning. IEEE Access 2019, 7, 146264–146272. [Google Scholar] [CrossRef]
- Azzam, R.; Boiko, I.; Zweiri, Y. Swarm Cooperative Navigation Using Centralized Training and Decentralized Execution. Drones 2023, 7, 193. [Google Scholar] [CrossRef]
- Wang, B.; Li, S.; Gao, X.; Xie, T. Weighted mean field reinforcement learning for large-scale UAV swarm confrontation. Appl. Intell. 2023, 53, 5274–5289. [Google Scholar] [CrossRef]
- Zhang, H.; Cheng, J.; Zhang, L.; Li, Y.; Zhang, W. H2GNN: Hierarchical-Hops Graph Neural Networks for Multi-Robot Exploration in Unknown Environments. IEEE Robot. Autom. Lett. 2022, 7, 3435–3442. [Google Scholar] [CrossRef]
- Boehmer, W.; Kurin, V.; Whiteson, S. Deep Coordination Graphs. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Virtual Event, 13–18 July 2020; Volume 119, pp. 980–991. [Google Scholar]
- Li, S.; Gupta, J.K.; Morales, P.; Allen, R.E.; Kochenderfer, M.J. Deep Implicit Coordination Graphs for Multi-agent Reinforcement Learning. In Proceedings of the AAMAS ’21: 20th International Conference on Autonomous Agents and Multiagent Systems, Virtual Event, 3–7 May 2021; pp. 764–772. [Google Scholar]
- Ruan, J.; Du, Y.; Xiong, X.; Xing, D.; Li, X.; Meng, L.; Zhang, H.; Wang, J.; Xu, B. GCS: Graph-based Coordination Strategy for Multi-Agent Reinforcement Learning. arXiv 2022, arXiv:2201.06257. [Google Scholar]
- Niu, Y.; Paleja, R.R.; Gombolay, M.C. Multi-Agent Graph-Attention Communication and Teaming. In Proceedings of the AAMAS ’21: 20th International Conference on Autonomous Agents and Multiagent Systems, Virtual Event, 3–7 May 2021; pp. 964–973. [Google Scholar]
- Littman, M.L. Markov games as a framework for multi-agent reinforcement learning. In Machine Learning Proceedings 1994; Elsevier: Amsterdam, The Netherlands, 1994; pp. 157–163. [Google Scholar]
- Oliehoek, F.A.; Amato, C. A Concise Introduction to Decentralized POMDPS; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Zhang, Y.; Yang, Q.; An, D.; Zhang, C. Coordination Between Individual Agents in Multi-Agent Reinforcement Learning. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; pp. 11387–11394. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2017, 1050, 20. [Google Scholar]
- Fan, J.; Wang, Z.; Xie, Y.; Yang, Z. A theoretical analysis of deep Q-learning. In Proceedings of the Learning for Dynamics and Control, Online Event, 10–11 June 2020; pp. 486–489. [Google Scholar]
- Tsitsiklis, J.N. Asynchronous stochastic approximation and Q-learning. Mach. Learn. 1994, 16, 185–202. [Google Scholar] [CrossRef] [Green Version]
- Zheng, L.; Yang, J.; Cai, H.; Zhou, M.; Zhang, W.; Wang, J.; Yu, Y. MAgent: A Many-Agent Reinforcement Learning Platform for Artificial Collective Intelligence. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 8222–8223. [Google Scholar]
- Jaderberg, M.; Czarnecki, W.M.; Dunning, I.; Marris, L.; Lever, G.; Castañeda, A.G.; Beattie, C.; Rabinowitz, N.C.; Morcos, A.S.; Ruderman, A.; et al. Human-level performance in first-person multiplayer games with population-based deep reinforcement learning. arXiv 2018, arXiv:abs/1807.01281. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Description |
|---|---|---|
| learning rate | ||
| decays linearly from 1 to 0 | exploration rate | |
| 0.95 | discount rate | |
| B | 1024 | replay buffer |
| h | 64 | the hidden layer size in GAT |
| K | 64 | mini-batch |
| 0.1 | the soft-max layer temperature of the actor in MFAC |
| Algorithm 1 | Algorithm 2 | ELO Score 1 | ELO Score 2 |
|---|---|---|---|
| GPMF-1 | POMFQ(FOR)-2 | 3579 | 820 |
| GPMF-2 | POMFQ(FOR)-1 | 2696 | 2838 |
| GPMF-1 | MFQ-2 | 2098 | 1508 |
| GPMF-2 | MFQ-1 | 2535 | 1695 |
| GPMF-1 | MFAC-2 | 1350 | −49 |
| GPMF-2 | MFAC-1 | −856 | −78 |
| POMFQ(FOR)-1 | MFQ-2 | 3145 | 2577 |
| POMFQ(FOR)-2 | MFQ-1 | 2569 | 2857 |
| POMFQ(FOR)-1 | MFAC-2 | −205 | −64 |
| POMFQ(FOR)-2 | MFAC-1 | 826 | −42 |
| MFQ-1 | MFAC-2 | −142 | −49 |
| MFQ-2 | MFAC-1 | 610 | −46 |
| Algorithm 1 | Algorithm 2 | ELO Score 1 | ELO Score 2 |
|---|---|---|---|
| GPMF-1 | POMFQ(FOR)-2 | 7770 | 8931 |
| GPMF-2 | POMFQ(FOR)-1 | 8293 | 9310 |
| GPMF-1 | MFQ-2 | 6374 | 10,870 |
| GPMF-2 | MFQ-1 | 8510 | 8313 |
| GPMF-1 | MFAC-2 | 5525 | 10 |
| GPMF-2 | MFAC-1 | 10,751 | −31 |
| POMFQ(FOR)-1 | MFQ-2 | 8526 | 8760 |
| POMFQ(FOR)-2 | MFQ-1 | 8632 | 8227 |
| POMFQ(FOR)-1 | MFAC-2 | 12,722 | 0 |
| POMFQ(FOR)-2 | MFAC-1 | 12,171 | −88 |
| MFQ-1 | MFAC-2 | 12,649 | 49 |
| MFQ-2 | MFAC-1 | 13,788 | −48 |
| Algorithm 1 | Algorithm 2 | ELO Score 1 | ELO Score 2 |
|---|---|---|---|
| GPMF-1 | POMFQ(FOR)-2 | 421 | −32 |
| GPMF-2 | POMFQ(FOR)-1 | 16 | 7 |
| GPMF-1 | MFQ-2 | 714 | −27 |
| GPMF-2 | MFQ-1 | −15 | −94 |
| GPMF-2 | MFAC-1 | 16 | 16 |
| POMFQ(FOR)-1 | MFQ-2 | 66 | 18 |
| POMFQ(FOR)-2 | MFQ-1 | 13 | 24 |
| POMFQ(FOR)-1 | MFAC-2 | 16 | −16 |
| POMFQ(FOR)-2 | MFAC-1 | 47 | 16 |
| MFQ-1 | MFAC-2 | 16 | −16 |
| MFQ-2 | MFAC-1 | 174 | 17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, M.; Liu, G.; Zhou, Z.; Wang, J. Partially Observable Mean Field Multi-Agent Reinforcement Learning Based on Graph Attention Network for UAV Swarms. Drones 2023, 7, 476. https://doi.org/10.3390/drones7070476
Yang M, Liu G, Zhou Z, Wang J. Partially Observable Mean Field Multi-Agent Reinforcement Learning Based on Graph Attention Network for UAV Swarms. Drones. 2023; 7(7):476. https://doi.org/10.3390/drones7070476
Chicago/Turabian StyleYang, Min, Guanjun Liu, Ziyuan Zhou, and Jiacun Wang. 2023. "Partially Observable Mean Field Multi-Agent Reinforcement Learning Based on Graph Attention Network for UAV Swarms" Drones 7, no. 7: 476. https://doi.org/10.3390/drones7070476