2.1. Dynamic Model of the Quadrotor Drone
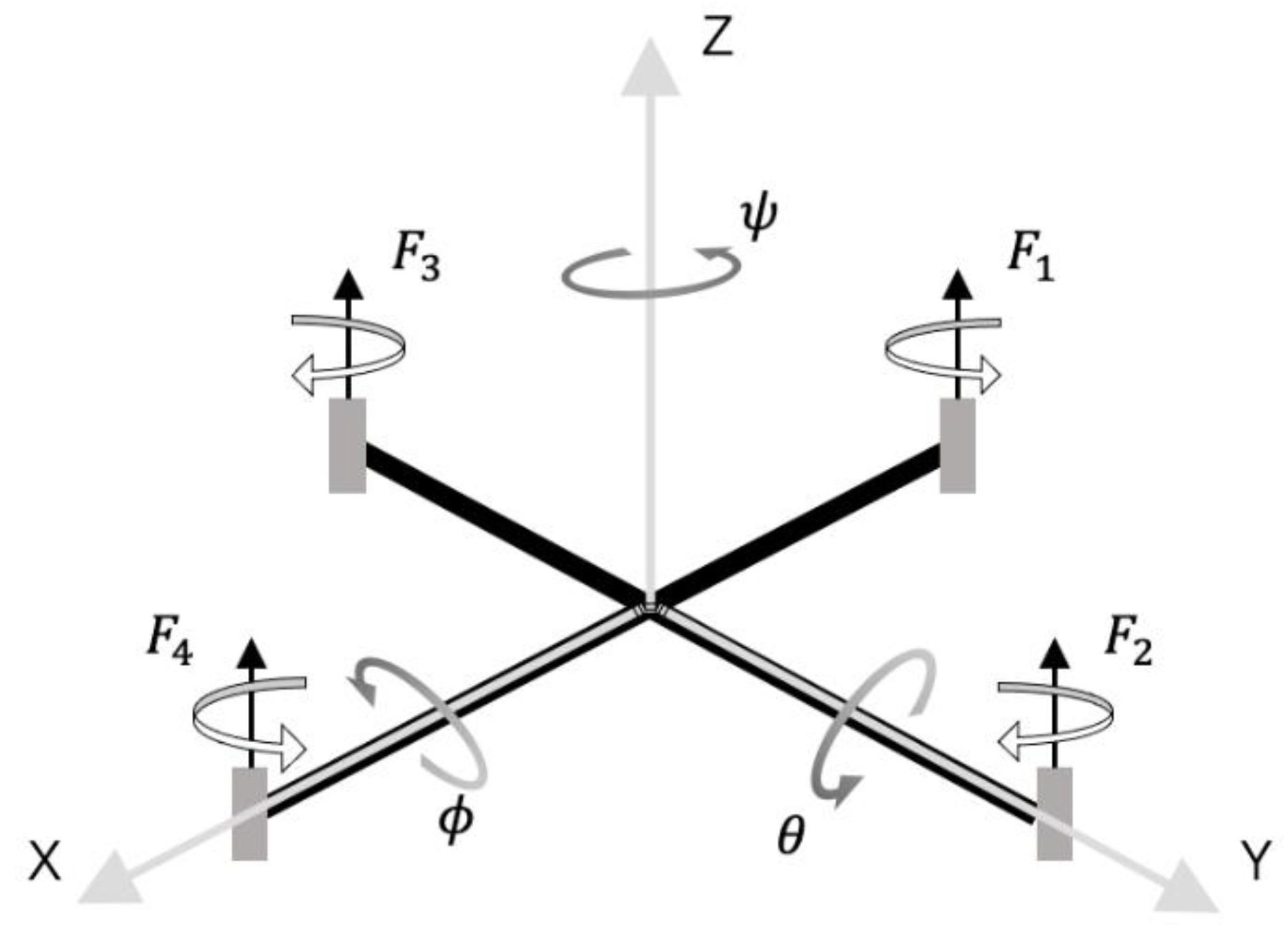
Referring to the Newton–Euler formalism, an intact structure of the quadrotor drone and its body-fixed frame is illustrated in
Figure 1. We defined an earth-fixed frame on earth and a body-fixed frame at the center of the drone to demonstrate the translation and rotation of the quadrotor drone [
23], respectively. Notably, the two coordinate systems were coincident initially; however, during the flight, they diverged. In this process, the earth-fixed frame remained unchanged, but the body-fixed frame moved and rotated. The translation from the earth-fixed frame to the body-fixed frame was assumed to be the position of the drone defined by
. Its first and second derivatives
and
indicated the speed and dynamic acceleration of the drone, respectively. In the body-fixed frame, a set of Euler angles
,
, and
denoted the rotation about the x-, y-, and z-axes of the drone, respectively.
As illustrated in
Figure 1, four rotors were fixed on the four ends of the cruciform frame of the quadrotor. L gives the half distance between the rotors on the diagonals. When viewed from above, the rotors in front (No. 4) and back (No. 1) spun counterclockwise, while those on the left (No. 2) and right (No. 3) spun clockwise. We controlled the rotation speeds of the four rotors individually by transmitting pulse-width modulation (PWM) signals to an electronic speed controller (ESC) separately. Furthermore, the rotation speed was almost proportional to the duty cycle of the PWM signal:
where
is the thrust generated by the rotors,
K is the speed gain of the PWM signal, and
repesents the normalized controller’s output, which ranged between 0 and 1 depending on the ratio of the rotation speed to the maximum speed. From a dynamic perspective, the difference in thrust between the propellers produced a rotational motion of the drone, and the total thrust of the four rotors and the attitude angle of the drone produced a translation motion. We analyzed the dynamic characteristics and applied Euler’s rotation equations to the body-fixed frame; the equation of the model of the quadrotor drone is:
where
indicates the angular rate about the x-, y-, and z-axes of the body-fixed frame, respectively.
is the drone’s diagonal form of an inertial matrix.
M is the sum of the thrusts generated by the rotors.
is the rotational moment due to the differences between the lift thrusts:
In the body-fixed frame, and are the torques about the x- and y-axes, respectively. is the control torque about the z-axis in the body-fixed frame, which was generally generated by the anti-torque force when the propellers rotated in the air. This torque was the lowest among the three torques; therefore, the rotational motion about the z-axis was the slowest. The reverse torque value was almost proportional to the lift thrust and is denoted by . The spinning rotors produced a gyroscope effect, represented by , where is the disturbance effect of the propellers and is the moment of inertia. The rotational dynamic-drag torques are represented by , where , , and are the rotational drag factors along the three axes, respectively.
In the earth-fixed coordinate frame, the translational motion model can be obtained from Newton’s second law:
where G is the gravitational force,
is the aerodynamic drag, and
indicates the resultant force of all external force vectors.
denotes the sum of the thrusts generated by the rotors, where
, with
denoting the thrust generated by the four rotors, respectively. According to the standard motor installation method, the motor shaft should be parallel to the z-axis of the body-fixed coordinate. Therefore, the directions of the thrusts should always be same as the positive z-axis. Meanwhile, the velocity and position coordinates of the quadrotor are defined on the earth-fixed frame. We also introduce the transformation matrix R to transform the thrusts and torques from the body-fixed frame to the earth-fixed frame:
where
indicates sin (
), and
indicates cos (
).
,
, and
are the drag coefficients, and
g is the acceleration due to gravity. Then, the aerodynamic drag will be
, and the gravitational force of drone
.
denotes the resultant thrust from the four rotors. Finally, we obtained the nonlinear differential equations to express the quadrotor dynamics as follows:
Due to the complexity of air dynamics and quadrotor components, some parameters of the model were unavailable to be measured directly. We had to utilize the model identification method to acquire the mathematical model, which was built and verified as described in
Section 3.
2.2. Policy Gradient Method of Reinforcement Learning
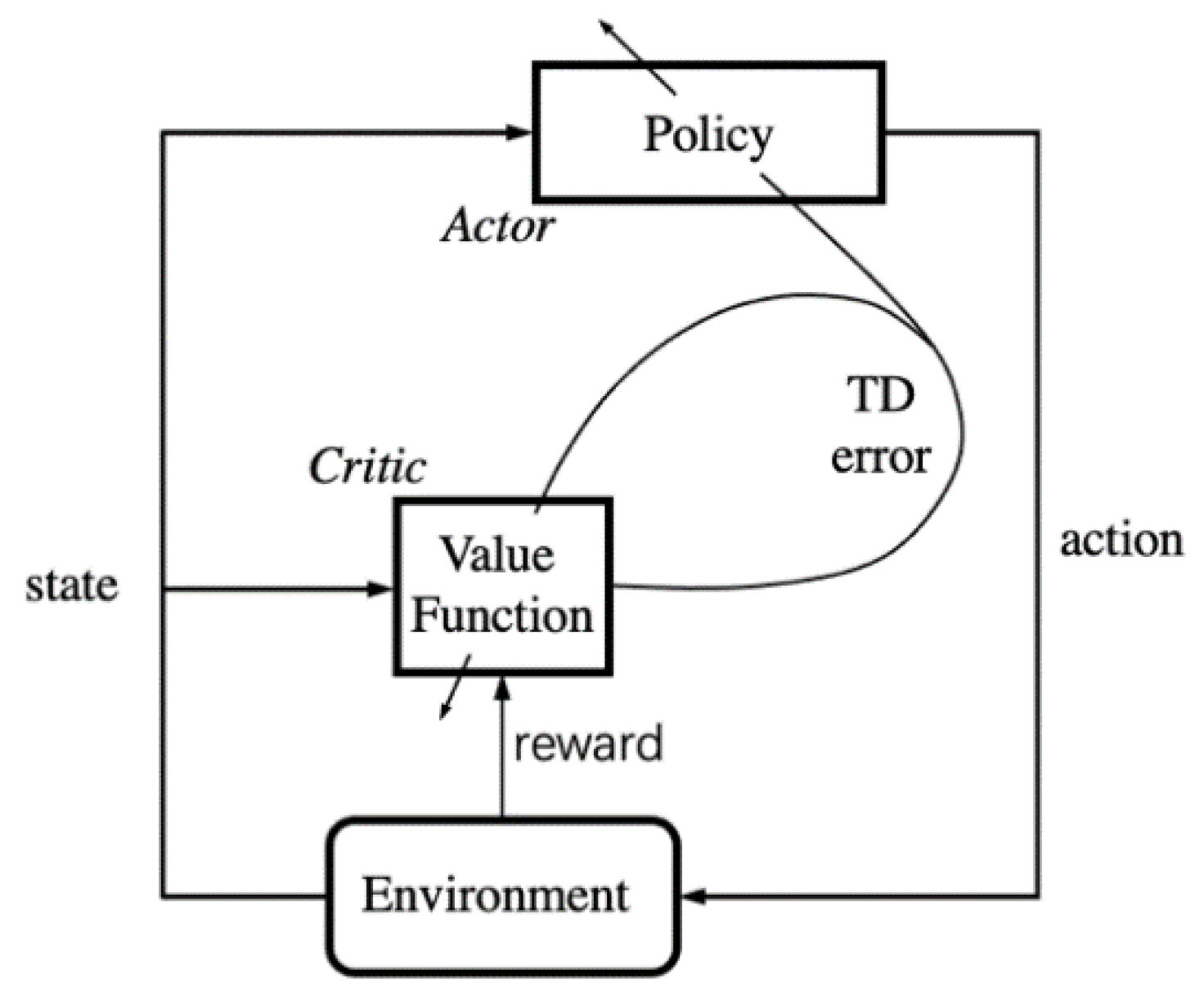
Figure 2 illustrates an agent–environment cyclic process. The agent, also called policy, can directly map situations to actions. The RL algorithm aims to optimize the policy by maximizing the accumulated rewards over the entire trajectory. Considering the formal framework of Markov decision processes (MDPs), with S as the set of states or observer of the system, in the proposed system, the states of the drone can be measured by sensors. Hence, this was a fully observable MDP. A represents the actions the agent can perform; they are real numbers in the quadrotor control problem. P denotes the state transition probability function, which depends on the quadrotor model and environment. R represents the reward function of the environment. Finally, the cyclic process can be formalized by a four-tuple (
).
If we suppose that the environment is in the state
at any timestep t, and it selects an action
according to the policy
, then the environment consequently transits to a new state
with a conditional probability
, simultaneously outputting a reward
to the agent. As an MDP problem, the transitions must follow a stationary transition dynamic distribution with a conditional probability
for each trajectory
in the state–action space. For any timestep
t, we defined the total discounted reward as the return
, and the discount factor
as a hyperparameter to control the weight of future rewards. For a trajectory starting from the timestep
t, the expected return can be generally denoted as
. The central optimization problem can then be expressed by
, where
is the optimal policy. The action–value function
denotes the expected return that the agent starts in state
, takes an arbitrary action
(which may not have been obtained from the policy), and then infinitely executes actions following the policy
. It has been proven that all action–value functions obey the particularly consistent equation known as the Bellman expectation equation:
Over the years, several practicable RL methods have been developed to optimize the policy, such as a policy gradient [
24].
The main objective of the drone control problem is to find an optimal control policy, which can be used to drive the quadrotor in a fast and stable manner to the desired state. The policy gradient algorithm is an efficient way to solve this problem, as it can deal with continuous states and actions. In an environment with a state transition probability
, a parameterized stochastic policy
can generate the control actions directly. Action
a is executed with parameter
while state
s is given. Next, intuitively, the parameters can be adjusted by finding the gradient of the performance measurement
. The gradient descent method can easily improve the policy. The principle of the policy gradient theorem is given as follows:
The policy gradient method demonstrates excellent performance in dealing with complex continuous problems. However, it suffers from two problems that severely limit its capabilities. The first problem is data efficiency. The full policy gradient can only be calculated after completing a trajectory. Once the parameters of the policy are optimized according to the calculated gradient, the trajectory data collected with the old policy will become useless. Then, the new policy can only be used to interact with the environment to generate trajectories and calculate the policy gradient. This reduces the efficiency of data utilization and extends the convergence time of the algorithm indefinitely. A more serious problem is that the stochastic policy generates actions through random sampling, which is impossible to predict and can be dangerous to actual drone control. Researchers have employed deterministic policies to improve this method, and these were used as the foundation of this study.
2.3. RM–DDPG Algorithm
The RM–DDPG algorithm was proposed based on the classical DDPG algorithm, which uses a deterministic policy to approximate the actor function instead of the stochastic policy in the original policy gradient method. In fact, the DDPG theory is a limiting case of the stochastic policy gradient theory.
The policy gradient method is perhaps the most advanced algorithm to deal with continuous-action problems using an RL algorithm. The basic idea of this algorithm is to use an actor function
to present the policy with the parameter
, and then continually optimize the parameters
along the direction of the performance gradient, given by:
where
is the action–value function. Notably, the distribution of state
depends on the parameters of the policy, and the policy gradient does not depend on the gradient of the state distribution.
The next issue to be solved is: how to estimate and evaluate the action–value function
? The actor–critic architecture has been widely used to solve this problem. In this architecture, the action–value function
is replaced by another action–value function
with parameter vector w, and a critic uses an appropriate policy evaluation method to estimate the action–value function
. The off-policy deterministic actor–critic method is applied to update the parameters of the actor and critic function iteratively:
This is a parameter “soft” update method, where
is the updating rate, which can constrain the target values to change gradually, improving the learning stability. We also introduced a critic network to approximate the action–value function.
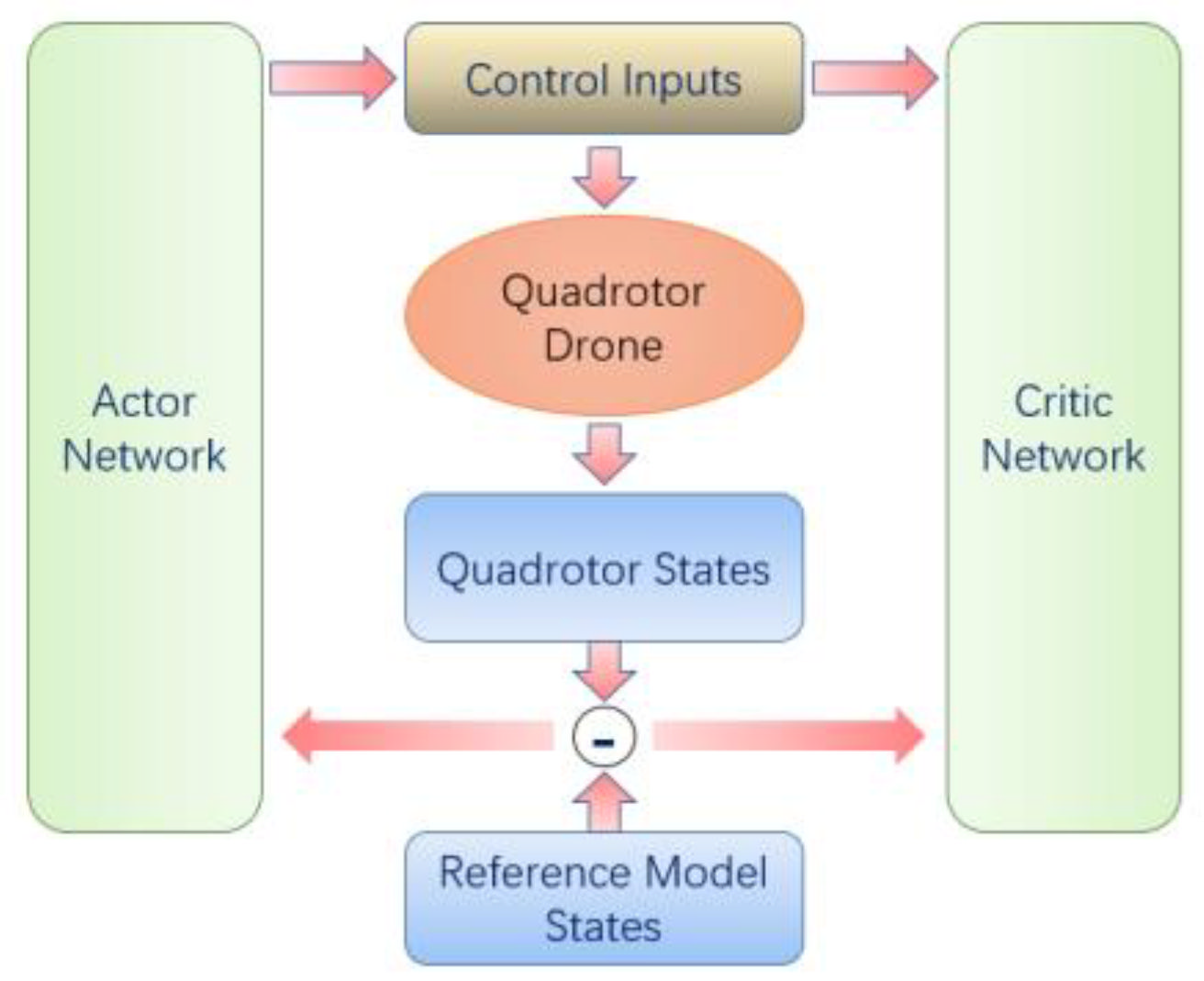
Figure 3 illustrates this structure [
20].
Using the Bellman equation, we improved the accuracy of the critic function by minimizing the difference between its two sides. Here, we define a temporal difference error (TD error):
The simple deterministic gradient decent policy to minimize the TD error is given by:
As the quadrotor drone control is a complex nonlinear problem, the action and state spaces can be very large and continuous. It is generally difficult to estimate the actor function and action–value function (or critic function). Inspired by the DDPG algorithm, we used neural networks to approximate the policy and action–value function. Moreover, experience data replay [
25] and target network methods were applied to improve the efficiency and stability of training.
Most optimization algorithms frequently assume that the samples of experimental data are independent and identically distributed; RL with neural networks is no exception. However, this assumption no longer holds true when samples are obtained during the continuous exploration of an environment. To address this issue, we used an M-sized replay buffer
to store the samples, where
denotes the transition experience data tuple of each timestep. The buffer works like a queue: its length is curtailed, and the oldest samples are dropped when the buffer becomes full. At each training episode, a miniature data batch is randomly sampled to update the actor and critic neural networks. Through this method, the associations between experimental data samples can be significantly reduced to satisfy the assumptions of independence and identical distribution. The efficiency of data and stabilization of training are improved. To further improve the learning stability, we designed target networks for both the actor and critic networks, similar to the target network used in [
26]. However, we modified the networks for the actor–critic pair and only used a “soft” target update instead of directly copying the weights. Before the learning process commenced, the target network was created with parameters identical to those of the critic network. In each learning iteration, the weights of the target network were optimized first and then synchronized with the critic network through the “soft” update method, with an update rate
:
, where
, and
denotes the target critic network and
the weight of the network. As the changes in the target parameters are updated gradually, the learning process becomes more stable. This method moves the problem of learning the action–value function closer to supervised learning, such that a robust solution exists.
Next, we rewrote the updated equations of the target critic network using the experience replay method. During training, a batch of experience data tuples
were randomly sampled from the replay buffer. We minimized the loss function to update the critic network as follows:
where
is the output of the target critic network with the reward of action. The gradient decent method to update the critic network parameters is given as follows:
Meanwhile, we also updated the actor network parameters following the DDPG algorithm:
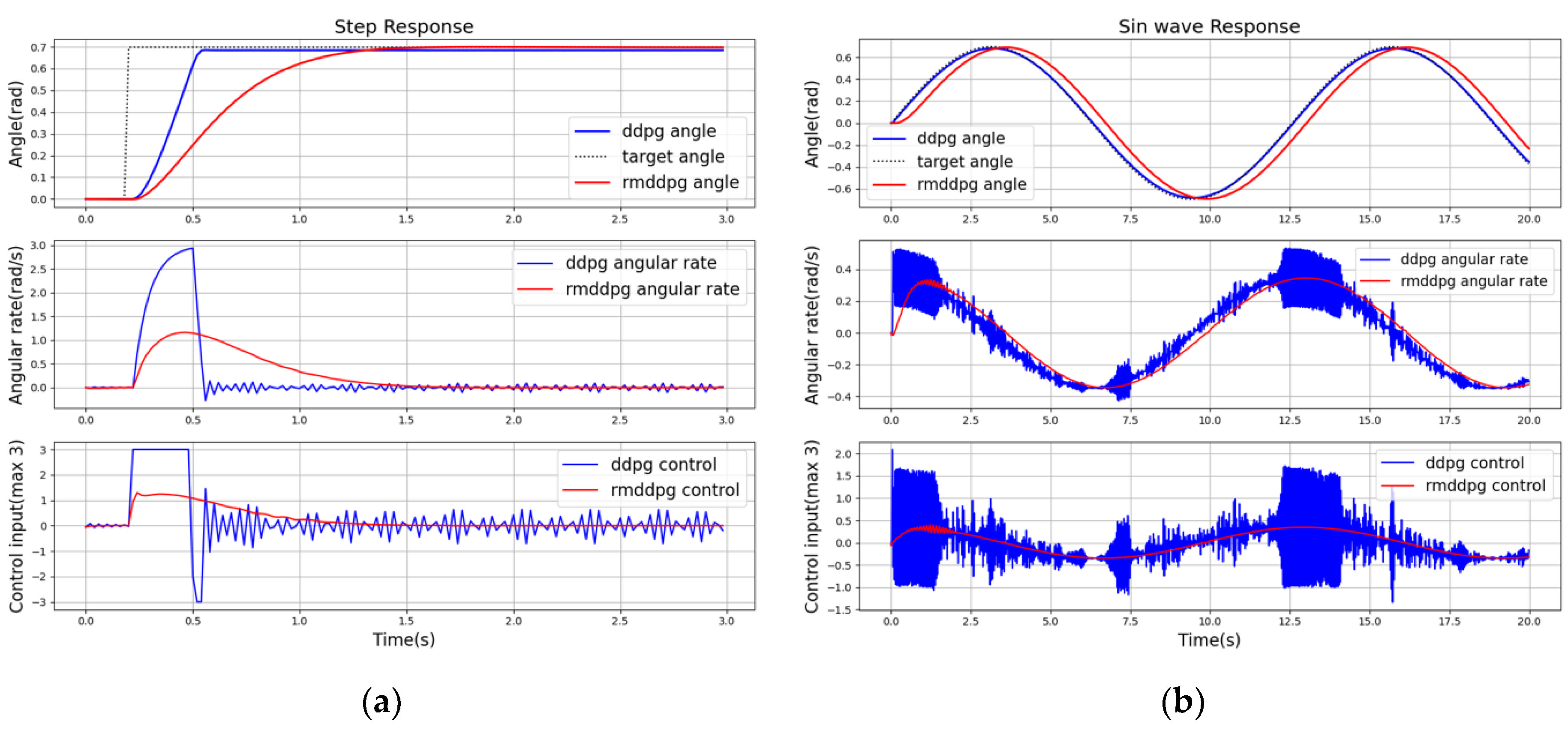
The DDPG algorithm has been proven to be an effective method to learn a stable and fast-responding policy for simulated control tasks in classic control and multi-joint dynamics with contact or MuJoCo environments of the open-source gym library. However, according to the results of the extensive experiments in this study, control saturation and steady-state error were two glaring challenges in the application of the DDPG algorithm with the neural network for quadrotor control.
Control saturation is a common problem among control algorithms for quadrotor control or any other motion control. Preferably, the controlled object must be able to respond to the target value at the earliest. This may fetch good results in simulation experiments; however, in practical application scenarios, a rapid response requires the support of strong hardware, which is generally unavailable. We examined this problem and marked reward as the key reason, according to Equations (18) and (19). While updating the critic network by minimizing the loss function, the reward was an important basis for each iteration. The reward obtained by the current TD error algorithm is a simple scalar quantity, such as attitude control of the quadrotor drone, which is the error between the target and feedback attitude angles. This strategy of receiving a reward may work well for simple control problems, such as CartPole. However, for complex tasks such as quadrotor drone control, the controlled object has several significant state quantities, such as the angle, angular velocity, and angular acceleration. The control goal of this study was not merely to track the attitude angle of the target at the earliest, but also to stabilize and safeguard the system. After introducing the reference model, we improved the reward function in the following manner:
where
n represents the n-dimensional state variables in the controlled system,
denotes the reference states,
is the state variable, and
is the weight set according to experience.
Regarding the steady-state error, the results of the experiments demonstrated that the learned controller in most scenarios cannot eliminate the tracking error, regardless of the time, type of training strategy, or a number of iterations provided to the controller. We offer two plausible reasons for this. As implied in [
13], one reason can be inaccurate function estimation value. Owing to limited sampling, accurate values of the actions could not be obtained. The accurate estimation becomes more difficult for complex problems such as quadrotor drone control. The most important reason is that the policy, which was trained by the DDPG algorithm, is the optimal controller. It is not a servo system, as it does not consider the error integral; for systems with damping and external disturbances, a steady-state error cannot be eliminated by this method.
To design a control system for a quadrotor drone with excellent stability and dynamic performance, we designed a reference model to generate the reference signals according to the target and reanalyzed the quadrotor drone model. We formed the quadrotor drone model by selecting the angle, angular velocity, angular acceleration, and angle error integral as the state variables. The specified reference model, where the state variables directly correspond to the identified model, was constructed as:
Here,
is the reference input. If
and
, the state variable error dynamics can be determined as follows:
To eliminate the steady-state error, a novel state
was introduced:
The expansion system is given as follows:
In the end, we obtained a three-order reference model with the state variables of angular acceleration, angular velocity, and angle reference. The quadrotor model state variables were angular acceleration, angular velocity, integral of angle error, and angle. This standard servo system can remain stable and provide a rapid response.
2.4. Neural Network Structure
Contrary to the stochastic policy, the deterministic policy requires additional strategies instead of naturally exploring the state–action space. As presented in the previous section, we added Gaussian noise to the output actions to construct the exploration policy
:
Figure 4 illustrates the structure of the RM–DDPG algorithm. The green module on the left is the actor network, which used the state
and the reference model state
as the input.
Next, we considered the symmetry of the structure of the quadrotor drone. We used the same controller to control its roll and pitch. This network was designed following the procedure in [
27], and the goal was to continuously approximate to an actor function that had the best control performance and stability. We also considered that the output of the actor network should be smooth. Hence, we designed it with two 128-dim fully connected hidden layers and a tanh activation function. The actor network triggered an action command that was relayed to the motor. In the control problem of a drone, the action command is also the action space of the RL algorithm. In practical applications, it is a continuous quantity in an interval and is limited to [−3 rad/s, 3 rad/s] by the mechanical properties of the drone. For practical purposes, to limit the control signals within a reasonable range, we also applied the tanh function to the output layer. The critic network is depicted on the right-hand side of
Figure 4; the inputs were the quadrotor and reference model states, and the control inputs were generated by the actor network. Similar to the actor network, the output network also had two hidden layers and activation functions. However, the activation function was changed to a linear function to better approximate the action–value function. The center of
Figure 4 illustrates the quadrotor drone model, which is given in Equation (28), and the steady-state error was introduced into the system as a state variable. The objective of this method was to ensure that the actor network considered the steady-state error when generating the control input, and more importantly, that the critic network considered the quadrotor state, the reference model state, and the steady-state error of the quadrotor states. While optimizing the critic network, the gradient policy changed this objective to keep the quadrotor states close to the reference model states, instead of fast-tracking to the target angle, which can lead to control saturation and the elimination of the steady-state error.
Next, we designed an algorithm in the episodic style. First, we created a target critic network with parameters identical to those of the critic network and generated the initial states within the prop range for each episode, following which the actor network relayed control commands to the quadrotor drone model. For each step, the transition of model states was temporarily stored in the replay buffer, and the training commenced if adequate samples were provided. Finally, the offline RL is summarized in Algorithm 1.
| Algorithm 1 Offline training algorithm of RM–DDPG. |
Initialize:
Randomly initialize the weights of the actor network and critic network
Copy parameters from the actor network and critic network to the target actor network and target critic network , respectively
Create an empty replay buffer D with length M
Load the quadrotor drone model and the reference model as the environment
Create a noise distribution N(0, ) for exploration
For episode = 1, M do
Randomly reset quadrotor states and target states
Initialize the reference model states by copying quadrotor states
Observe initial states
For t = 1, T do
If length of replay buffer D is bigger than mini-batch size, then
Choose action based on state and noise
Else
Choose an arbitrary action from the action space
End if
Perform control command in the environment
Calculate reward and new state
Store transition tuple (, , , ) to replay buffer D
If the length of replay buffer D is bigger than mini-batch size, then
Randomly sample a data batch from D
Calculate the gradient and update the critic network following (20) (21)
According to the output of the critic network, update the actor network -following (22) (23)
Soft update the target network parameters following (18)
End if
If exceed the safe range then
break
End If
End For
End For
Save model or evaluate |
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}