

Sign-to-Text Translation from Panamanian Sign Language to Spanish in Continuous Capture Mode with Deep Neural Networks
 , , and
, , and
Abstract
:1. Introduction
2. Related Work
2.1. SLR Using Deep Learning Methods
2.2. SLR with Traditional Analysis Methods
2.3. SLR for Other Languages (Beyond ASL)
2.4. SLR with Varying Capturing Methods
2.5. Development in Panamanian Sign Languages
3. Methods
3.1. Image Collection and Preprocessing
3.2. Development of the Dynamic Sign Module
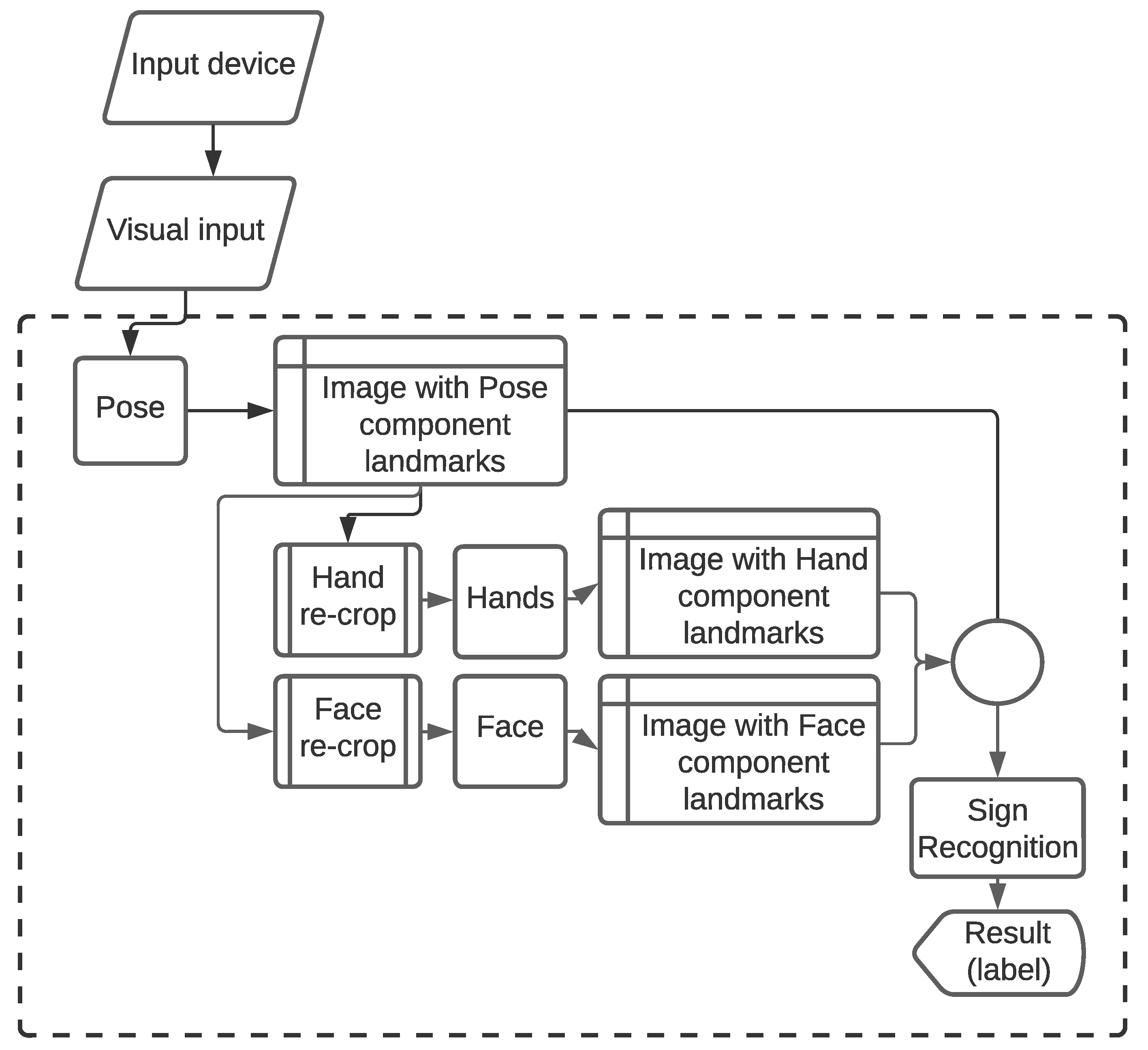
3.2.1. Keypoint/Landmark Detection Using Mediapipe Holistic
3.2.2. Capturing and Processing Images and Keypoints
3.2.3. Keypoint Value Collection for Training and Testing
3.2.4. Sequence Preprocessing and Creation of Labels and Features
3.3. Model Definition
3.4. Experimental Setting
3.5. Experiment Overview
- Experiment #1: the objective of this experiment was to train a model that was able to translate dynamic signs with the deep neural network model. For this task, 5 signs were tested (Hola—Hello, Buenos días—Good morning, Estoy Bien—I am fine, Gracias—Thanks, ¿Cómo estás?—How are you?).For this experiment, a data set consisting of 625 videos (30 frames for each one) corresponding to the 5 classes (signs) were collected. Each sign was then captured 125 times, of which 20% (around 25 images per class) were used for validation.
- Experiment #2: the objective was to be able to assess the performance with a lesser number of classes. For this task, 3 signs were tested (Hola—Hello, Estoy Bien—I am fine, Gracias—Thanks).For this experiment, a reduced data set was considered. This data set consists of 375 videos (30 frames for each one) corresponding to the 3 classes (signs) remaining. Each sign was then captured 125 times, of which 15 images per class (12%) were used for validation.The hypothesis behind this experiment is that the model could have a much better performance in execution if the number of options to be considered is shortened, given that there is a shared probability between all the elements (possible options). Given this hypothesis, we aimed to improve performance by considering fewer classes.
Evaluation Metrics
4. Results
4.1. Image Acquisition
4.2. Detection Experiments
4.3. Individual Class Performances for Experiment #1
4.4. Individual Class Performances for Experiment #2
4.5. Real-Time Execution
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fatmi, R.; Rashad, S.; Integlia, R. Comparing ANN, SVM, and HMM based Machine Learning Methods for American Sign Language Recognition using Wearable Motion Sensors. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019; pp. 0290–0297. [Google Scholar] [CrossRef]
- Sharma, S.; Kumar, K. ASL-3DCNN: American sign language recognition technique using 3-D convolutional neural networks. Multimed. Tools Appl. 2021, 80, 26319–26331. [Google Scholar] [CrossRef]
- Rahman, M.M.; Islam, M.S.; Rahman, M.H.; Sassi, R.; Rivolta, M.W.; Aktaruzzaman, M. A New Benchmark on American Sign Language Recognition using Convolutional Neural Network. In Proceedings of the 2019 International Conference on Sustainable Technologies for Industry 4.0 (STI), Dhaka, Bangladesh, 24–25 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Jing, L.; Vahdani, E.; Huenerfauth, M.; Tian, Y. Recognizing American Sign Language Manual Signs from RGB-D Videos. arXiv 2019, arXiv:1906.02851. [Google Scholar]
- Kannoth, A.; Yang, C.; Guanipa Larice, M.A. Hand Gesture Recognition Using CNN & Publication of World’s Largest ASL Database. In Proceedings of the 2021 IEEE Symposium on Computers and Communications (ISCC), Athens, Greece, 5–8 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Perdana, I.P.; Putra, I.K.G.D.; Dharmaadi, I.P.A. Classification of Sign Language Numbers Using the CNN Method. JITTER J. Ilm. Teknol. Dan Komput. 2021, 2, 485–493. [Google Scholar] [CrossRef]
- Marjusalinah, A.D.; Samsuryadi, S.; Buchari, M.A. Classification of finger spelling American sign language using convolutional neural network. Comput. Eng. Appl. J. 2021, 10, 93–103. [Google Scholar] [CrossRef]
- Ariesta, M.C.; Wiryana, F.; Suharjito; Zahra, A. Sentence level Indonesian sign language recognition using 3D convolutional neural network and bidirectional recurrent neural network. In Proceedings of the 2018 Indonesian Association for Pattern Recognition International Conference (INAPR), Jakarta, Indonesia, 7–8 September 2018; pp. 16–22. [Google Scholar]
- Ibrahim, N.B.; Zayed, H.H.; Selim, M.M. Advances, challenges and opportunities in continuous sign language recognition. J. Eng. Appl. Sci. 2020, 15, 1205–1227. [Google Scholar] [CrossRef]
- Rastgoo, R.; Kiani, K.; Escalera, S. Sign language recognition: A deep survey. Expert Syst. Appl. 2021, 164, 113794. [Google Scholar] [CrossRef]
- Basiri, M.E.; Nemati, S.; Abdar, M.; Cambria, E.; Acharya, U.R. ABCDM: An attention-based bidirectional CNN-RNN deep model for sentiment analysis. Future Gener. Comput. Syst. 2021, 115, 279–294. [Google Scholar] [CrossRef]
- Yu, W.; Kim, I.Y.; Mechefske, C. Analysis of different RNN autoencoder variants for time series classification and machine prognostics. Mech. Syst. Signal Process. 2021, 149, 107322. [Google Scholar] [CrossRef]
- Metaxas, D.; Dilsizian, M.; Neidle, C. Scalable ASL Sign Recognition using Model-based Machine Learning and Linguistically Annotated Corpora. In 8th Workshop on the Representation & Processing of Sign Languages: Involving the Language Community, Language Resources and Evaluation Conference 2018; European Language Resources Association (ELRA): Luxembourg, 2018. [Google Scholar]
- Rahman, M.M.; Malaia, E.A.; Gurbuz, A.C.; Griffin, D.J.; Crawford, C.; Gurbuz, S.Z. Effect of Kinematics and Fluency in Adversarial Synthetic Data Generation for ASL Recognition With RF Sensors. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 2732–2745. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, W.; Xie, C.; Pu, J.; Li, H. Chinese sign language recognition with adaptive HMM. In Proceedings of the 2016 IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Agrawal, S.C.; Jalal, A.S.; Tripathi, R.K. A survey on manual and non-manual sign language recognition for isolated and continuous sign. Int. J. Appl. Pattern Recognit. 2016, 3, 99–134. [Google Scholar] [CrossRef]
- Katoch, S.; Singh, V.; Tiwary, U.S. Indian Sign Language recognition system using SURF with SVM and CNN. Array 2022, 14, 100141. [Google Scholar] [CrossRef]
- Koller, O.; Zargaran, O.; Ney, H.; Bowden, R. Deep sign: Hybrid CNN-HMM for continuous sign language recognition. In Proceedings of the British Machine Vision Conference 2016, York, UK, 19–22 September 2016. [Google Scholar]
- Koller, O.; Zargaran, S.; Ney, H.; Bowden, R. Deep sign: Enabling robust statistical continuous sign language recognition via hybrid CNN-HMMs. Int. J. Comput. Vis. 2018, 126, 1311–1325. [Google Scholar] [CrossRef]
- Buttar, A.M.; Ahmad, U.; Gumaei, A.H.; Assiri, A.; Akbar, M.A.; Alkhamees, B.F. Deep Learning in Sign Language Recognition: A Hybrid Approach for the Recognition of Static and Dynamic Signs. Mathematics 2023, 11, 3729. [Google Scholar] [CrossRef]
- Elsayed, E.K.; Fathy, D.R. Sign language semantic translation system using ontology and deep learning. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 141–147. [Google Scholar] [CrossRef]
- Abedin, T.; Prottoy, K.S.S.; Moshruba, A.; Hakim, S.B. Bangla sign language recognition using concatenated BdSL network. arXiv 2021, arXiv:2107.11818. [Google Scholar]
- Fink, J.; Frénay, B.; Meurant, L.; Cleve, A. LSFB-CONT and LSFB-ISOL: Two New Datasets for Vision-Based Sign Language Recognition. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Calado, A.; Errico, V.; Saggio, G. Toward the Minimum Number of Wearables to Recognize Signer-Independent Italian Sign Language With Machine-Learning Algorithms. IEEE Trans. Instrum. Meas. 2021, 70, 1–9. [Google Scholar] [CrossRef]
- Wei, F.; Chen, Y. Improving continuous sign language recognition with cross-lingual signs. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; p. 23612. [Google Scholar]
- Yin, A.; Zhao, Z.; Jin, W.; Zhang, M.; Zeng, X.; He, X. Mlslt: Towards multilingual sign language translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5109–5119. [Google Scholar]
- Tornay, S.; Razavi, M.; Doss, M.M. Towards multilingual sign language recognition. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6309–6313. [Google Scholar]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. Real-time 3D hand pose estimation with 3D convolutional neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 956–970. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Lu, W.; Gan, W.; Hou, W. A contactless method to measure real-time finger motion using depth-based pose estimation. Comput. Biol. Med. 2021, 131, 104282. [Google Scholar] [CrossRef]
- Huang, J.; Zhou, W.; Zhang, Q.; Li, H.; Li, W. Video-based sign language recognition without temporal segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Pimentel, D.; Walker, R.; Fajardo, M. Lengua de Señas Panameñas; Editora Panamá América: Panama, Panama, 2018. [Google Scholar]
- Pimentel Araúz, M.I. Sitio Web Para el Aprendizaje de Lengua de Señas Panameñas. Ph.D. Thesis, Universidad de Panamá, Vicerrectoría de Investigación y Postgrado, Panama City, Panama, 2018. [Google Scholar]
- Flores, A.; González, E.; Pan, J.Z.; Villarreal, V.; Muñoz, L. Sistema de aprendizaje de Lengua de Señas Panameña (LSP) a través de un brazo robótico articulado con reconocimiento de gestos. In Proceedings of the Memorias de Congresos UTP, Pereira, Colombia, 11–13 September 2019; pp. 168–173. [Google Scholar]
- Gestión Empresarial 3000. IPHE Inclusivo. 2018. Mobile App. Available online: https://play.google.com/store/apps/details?id=ca.costari.apps.ipheinclusivo&pli=1 (accessed on 15 September 2023).
- Rodríguez-Fuentes, A.; Alaín-Botaccio, L.; García-García, F. Presentation and evaluation of a digital tool for sign language (Presentación y evaluación de una herramienta digital para la lengua de signos). Cult. Educ. 2022, 34, 658–688. [Google Scholar] [CrossRef]
- Fuentes, A.R.; Alain, L.; García, F.G. EnSenias: Technological tool to learn, teach, improve and use Panamanian Sign Language. Íkala 2020, 25, 663–678. [Google Scholar]
- Alaín Botacio, L. Desarrollo y Validación de una Aplicación web y cd Educativa Inclusiva Para el Aprendizaje de la Lengua de señas Panameña. Ph.D. Thesis, Universidad de Granada, Granada, Spain, 2019. [Google Scholar]
- Bodmer, R.; Liu, L.; Liu, W.; Rangel, J.C. Sign language recognition with machine learning for elementary school children. Rev. Iniciación Científica Edición Espec. 2020, 6. [Google Scholar] [CrossRef]
- Teran-Quezada, A.; Lopez-Cabrera, V.; Rangel, J.C.; Sanchez-Galan, J.E. Hand Gesture Recognition with ConvNets for School-Aged Children to Learn Basic Arithmetic Operations. In Proceedings of the 2022 IEEE 40th Central America and Panama Convention (CONCAPAN), Panama City, Panama, 9–12 November 2022; pp. 1–6. [Google Scholar]
- Bazarevsky, V.; Grishchenko, I. MediaPipe Holistic—Simultaneous Face, Hand and Pose Prediction, on Device. 2020. Available online: https://ai.googleblog.com/2020/12/mediapipe-holistic-simultaneous-face.html (accessed on 15 September 2023).
- Bazarevsky, V.; Zhang, F. On-Device, Real-Time Hand Tracking with MediaPipe. arXiv 2019, arXiv:2006.10214. [Google Scholar]
- Ablavatski, A.; Grishchenko, I. Real-Time AR Self-Expression with Machine Learning. 2019. Available online: https://blog.research.google/2019/03/real-time-ar-self-expression-with.html (accessed on 20 February 2024).
- Bazarevsky, V.; Grishchenko, I. On-Device, Real-Time Body Pose Tracking with MediaPipe BlazePose. 2020. Available online: https://blog.research.google/2020/08/on-device-real-time-body-pose-tracking.html (accessed on 15 September 2023).
- Zhang, F.; Bazarevsky, V.; Vakunov, A.; Tkachenka, A.; Sung, G.; Chang, C.L.; Grundmann, M. MediaPipe Hands: On-device Real-time Hand Tracking. arXiv 2006, arXiv:2006.10214. [Google Scholar]
- Bazarevsky, V.; Kartynnik, Y.; Vakunov, A.; Raveendran, K.; Grundmann, M. BlazeFace: Sub-Millisecond Neural Face Detection on Mobile GPUs. arXiv 2019, arXiv:1907.05047. [Google Scholar] [CrossRef]
- Bazarevsky, V.; Grishchenko, I.; Raveendran, K.; Zhu, T.; Zhang, F.; Grundmann, M. BlazePose: On-device Real-time Body Pose tracking. arXiv 2020, arXiv:2006.10204. [Google Scholar]
- Teran-Quezada, A.A.; Lopez-Cabrera, V.; Rangel, J.C.; Sanchez-Galan, J.E. A Collection of Basic Greetings in Panamanian Sign Language (PSL). Mendeley Data, V1. 2024. Available online: https://data.mendeley.com/datasets/3d4wggwh5g/1 (accessed on 20 February 2024). (In Spanish).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Simao, M.; Neto, P.; Gibaru, O. Improving novelty detection with generative adversarial networks on hand gesture data. Neurocomputing 2019, 358, 437–445. [Google Scholar] [CrossRef]
- Shen, J.; Dudley, J.; Kristensson, P.O. The imaginative generative adversarial network: Automatic data augmentation for dynamic skeleton-based hand gesture and human action recognition. In Proceedings of the 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jodhpur, India, 15–18 December 2021; pp. 1–8. [Google Scholar]
- Liu, Y.; De Nadai, M.; Zen, G.; Sebe, N.; Lepri, B. Gesture-to-gesture translation in the wild via category-independent conditional maps. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1916–1924. [Google Scholar]
- Núñez-Marcos, A.; Perez-de Viñaspre, O.; Labaka, G. A survey on Sign Language machine translation. Expert Syst. Appl. 2022, 213, 118993. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Z.; Zhang, Y.; Bao, J.; Zhang, Y.; Deng, H. Human activity recognition based on motion sensor using u-net. IEEE Access 2019, 7, 75213–75226. [Google Scholar] [CrossRef]
- Al-Qurishi, M.; Khalid, T.; Souissi, R. Deep learning for sign language recognition: Current techniques, benchmarks, and open issues. IEEE Access 2021, 9, 126917–126951. [Google Scholar] [CrossRef]
- Nogales, R.E.; Benalcázar, M.E. Hand Gesture Recognition Using Automatic Feature Extraction and Deep Learning Algorithms with Memory. Big Data Cogn. Comput. 2023, 7, 102. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Class | |||
|---|---|---|---|
| True | False | ||
| Observed Class | Positive | TP | FN |
| Negative | FP | TN | |
| Metric | Experiment #1 | Experiment #2 |
|---|---|---|
| Accuracy (global) | 0.958 | 0.988 |
| Accuracy (best class) | 1.00 | 1.00 |
| Accuracy (worst class) | 0.96 | 1.00 |
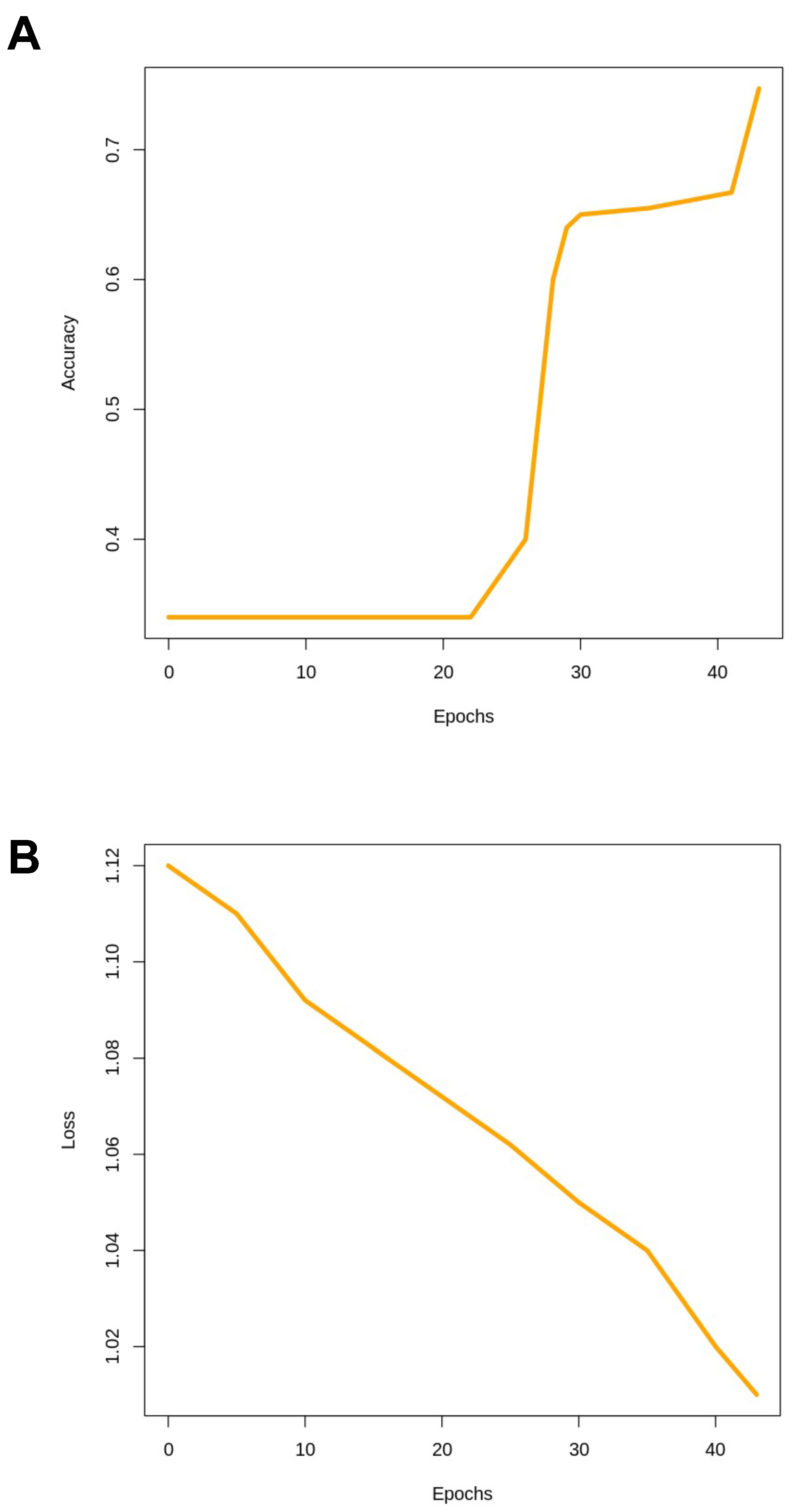
| Final Loss | 0.222 | 0.995 |
| Epochs | 160 | 46 |
| Training time (s) | 196.6 | 38.88 |
| Predicted | |||
|---|---|---|---|
| True | False | ||
| Class “Hello” | Positive | 22–88% | 0–0% |
| Negative | 0–0% | 3–12% | |
| Predicted | |||
|---|---|---|---|
| True | False | ||
| Class “Good morning” | Positive | 20–80% | 1–4% |
| Negative | 0–0% | 4–16% | |
| Predicted | |||
|---|---|---|---|
| True | False | ||
| Class “Hello” | Positive | 7–46.67% | 0–0% |
| Negative | 0–0% | 8–53.33% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Teran-Quezada, A.A.; Lopez-Cabrera, V.; Rangel, J.C.; Sanchez-Galan, J.E. Sign-to-Text Translation from Panamanian Sign Language to Spanish in Continuous Capture Mode with Deep Neural Networks. Big Data Cogn. Comput. 2024, 8, 25. https://doi.org/10.3390/bdcc8030025
Teran-Quezada AA, Lopez-Cabrera V, Rangel JC, Sanchez-Galan JE. Sign-to-Text Translation from Panamanian Sign Language to Spanish in Continuous Capture Mode with Deep Neural Networks. Big Data and Cognitive Computing. 2024; 8(3):25. https://doi.org/10.3390/bdcc8030025
Chicago/Turabian StyleTeran-Quezada, Alvaro A., Victor Lopez-Cabrera, Jose Carlos Rangel, and Javier E. Sanchez-Galan. 2024. "Sign-to-Text Translation from Panamanian Sign Language to Spanish in Continuous Capture Mode with Deep Neural Networks" Big Data and Cognitive Computing 8, no. 3: 25. https://doi.org/10.3390/bdcc8030025