
An Overview on the Challenges and Limitations Using Cloud Computing in Healthcare Corporations


Abstract
:1. Introduction
2. Cloud Computing
2.1. Service Models of Cloud Computing
- Software as a Service (SaaS) [12] allows the use of the provider’s applications running on remote architectures. The applications are obtainable through client applications, such as a web browser or an Application Program Interface (API). Users cannot control or manage the beneath Cloud infrastructure components such as network, servers, operating systems, storage, or individual application capabilities, excluding determinate user-specific application configuration settings.
- Platform as a Service (PaaS) [13] enables users to develop in the Cloud environment the users’ applications created using libraries, services, and APIs compatible with the Cloud provider. Users cannot directly manage or control the infrastructure beneath the Cloud, including network, servers, operating systems, or storage, but retain the deployed applications and particular configuration settings for the application-hosting domain.
- Infrastructure as a Service (IaaS) [14] facilitates the user in provision processing, storage, networks, and other essential computing resources where the user can deploy and run the software, including operating systems and apps. Users cannot manage or control the beneath-Cloud infrastructure, whereas having control of the operating systems, storage, deployed applications, and limited control on some select networking components, e.g., host firewalls or bridges.
- Business Process as a Service (BPaaS) [15] exploits the Cloud to automate and drive down the costs of business processes carried out by organizations.
- Data as a Service (DaaS) [16] offers Cloud-based Big Data cleaning, filtering, and enrichment schemes to produce data sets suitable for predictive or prescriptive analyses.
- Connectivity as a Service (CaaS) [17] provides Voice-Over-IP (VOIP), video-conferencing, and Instant Messaging (IM) functions as Cloud-based subscription services for commercial institutions.
- Identity as a Service (IDaaS) [18] provides Cloud-based centralized authentication and Single-Sign-On (SSO) services on heterogeneous or federated Cloud schemes.
2.2. Deployment Models of Cloud Computing
- Public Cloud infrastructure is ideal for organizations needing quick access to computing resources without significant capital expenditure. Public Cloud infrastructure allows organizations to purchase virtualized computing services through the Internet. Since Public Cloud services are furnished as pay-per-use, no initial investments are required because new resources can be purchased when needed. Public Cloud services are ideal for healthcare organizations that cannot afford an investment in particular hardware and maintenance.
- Private Cloud infrastructure is intended for exclusive use by a single organization. The Private Cloud lets organizations complete control over how data are shared and stored, an optimal solution if security is the primary concern, e.g., in the healthcare domain, ensuring compliance with any ethical regulations and protecting the subject’s sensitive data. Additionally, the Private Cloud provides on-demand data availability, guaranteeing trustworthiness and support for mission-critical tasks.
- Hybrid Cloud infrastructure combines Public and Private Cloud infrastructures by allowing data and applications to be moved between them. Cloud infrastructures are unique entities linked by standardized or proprietary technologies, enabling the portability of data and applications. Hence, Hybrid Cloud provides a unique integrated environment combining locally Private and Public Cloud services. Healthcare organizations using Hybrid Cloud could enhance the standard of security. In this regard, data and services that do not affect sensitive information can be available through the Public Cloud. In contrast, sensitive information held in the Private Cloud are under the institution’s absolute control.
- Multicloud infrastructure handles several Cloud services by different providers, including organizations’ Private Cloud resources and private computational assets, to accomplish various requirements and demands in a single heterogeneous Cloud environment. Multicloud gives more flexibility regarding service and computational capabilities, improving performance and increasing resource availability and redundancy, letting organizations and final users to use all available resources efficiently.
- Federated Cloud infrastructure is a heterogeneous Cloud environment connecting diverse providers through a partnership mechanism, e.g., a standard policy to share, access, and control infrastructure and services. Federated Cloud commonly combines multiple Private and Public Clouds. Federation members remain independent in resource sharing and access control, comprising federated identity management. Thus, the Federated Cloud increases reliability and, simultaneously, the scaling up of resources.
- Intercloud is a general model of Cloud infrastructures that incorporates heterogeneous Clouds from various providers and typically includes non-cloud resources. Intercloud models may use the Federated Cloud standard as the basis for creating or implementing more specific but customized control and management functions.
3. Background
- Cloud BioLinux [19] provides a platform for developing bioinformatics infrastructures on the Cloud. Cloud BioLinux is a publicly accessible Virtual Machine (VM) to create on-demand frameworks for high-performance bioinformatics computing using Cloud architectures. Cloud BioLinux preconfigured command line and graphical software applications are available through the Amazon EC2 Cloud. Cloud BioLinux is distributed under the MIT Licence, including different Cloud BioLinux VMs, whereas source code and user guides are available at http://www.cloudbiolinux.org (accessed on 21 March 2023).
- Cloud4SNP [20] is a Cloud-based framework for the parallel preprocessing and statistical analysis of pharmacogenomics SNP DMET microarray data sets. Cloud4SNP extends the DMET-Analyzer [21] engine to be implemented as a Cloud Computing service through the Data Mining Cloud Framework [22]. Data Mining Cloud Framework is a software framework for creating and implementing knowledge discovery workflows on the Cloud [23]. Cloud4SNP performs massive statistical tests of SNPs relevance in case-control studies using the well-known Fisher test. Cloud4SNP exploits data parallelism and employs an optimized filtering technique to bypass the execution of ineffective Fisher tests by removing rows, e.g., probes with similar SNPs distributions.
- CloudBurst [24] is a parallel read-mapping algorithm optimized for mapping Next-Generation Sequence (NGS) data from several organisms, including homo sapiens, SNPs discovery, genotyping, and personal genomics. CloudBurst runs the short Read-Mapping Program (RMAP) linearly since running time decreases linearly with the number of reads mapped, reaching a linear speedup increasing the number of processors. These results are obtained by implementing Hadoop MapReduce [25] to parallelize execution using multiple computing nodes. In this way, CloudBurst improves performance by decreasing the running time to minutes for mapping millions of short reads to the human genome. CloudBurst is available as an open-source Java project for Amazon EC2 at https://sourceforge.net/projects/cloudburst-bio/ (accessed on 21 March 2023).
- CloudMan [26] is a Cloud manager that directs all of the steps required to create and control a complete data analysis environment on a Cloud infrastructure using a web browser. CloudMan provides an NGS analysis technique integrated with the Galaxy applications. CloudMan comes with a graphical interface to enable an easy access to Cloud Computing services. CloudMan is currently available for Amazon Web Services (AWS) Cloud infrastructure as part of the Galaxy Cloud [27] and CloudBioLinux [28].
- Crossbow [29] is a scalable, portable, and automatic Cloud service for identifying SNPs from high-coverage short-read resequencing data. Crossbow implements the MapReduce framework [25] distributed from Apache Hadoop. Alignment and variant calling in Crossbow are performed using the Bowtie [29] and SOAPsnp [30] software tools.
- Eoulsan [31] is a Cloud service implementing the Hadoop MapReduce approach devoted to HT sequencing RNA-seq data analysis. The Eoulsan differential analysis of transcript expression workflow comprises six steps: (i) quality control filtering; (ii) reads mapping; (iii) alignments filtering; (iv) transcript expression calculation. (v) normalization; (vi) detection of significant differential expression. Eoulsan is available as standalone, local cluster, or Cloud Computing on Amazon Elastic MapReduce (EMR).
- Eoulsan 2 [32] is the update of Eoulsan initially developed for analyzing RNA-seq data. Eoulsan 2 introduces the following updates to handling long-read RNA-seq and scRNA-seq data: (i) enhances the workflow manager; (ii) facilitates the development of new modules; (iii) expands its applications to long-read RNA-seq and scRNA-seq. Eoulsan 2 is implemented in Java, available only for Linux systems, and distributed under the LGPL and CeCILL-C licenses at http://outils.genomique.biologie.ens.fr/eoulsan/ (accessed on 21 March 2023). The source code and sample workflows are available on GitHub https://github.com/GenomicParisCentre/eoulsan (accessed on 21 March 2023).
- HealtheDataLab [33] is a Cloud Computing platform for analyzing Electronic Medical Records (EMRs) data with computing capability for analyzing Big Data. HealtheDataLab enables the building of statistical and machine learning models flexibly through the use of Amazon Web Services (AWS), allows for scalability and high-performance computing system, and complaints with the Health Insurance Portability and Accountability Act (HIPAA) standard. HealtheDataLab is available upon request made directly to Cerner Corporation.
- iMage Cloud [34] allows the analysis of medical images integrated with EMRs, enabling the sharing of images, EMRs, and merged images via the Internet. iMage uses Hybrid Cloud to deliver more convenient and secure services, allowing high-performance image processing and virtual applications to be delivered securely, conveniently, and efficiently. iMage provides a graphical user interface with which it is possible to share images after being combined with EMRs.
- PeakRanger [35] is a software package that resolves closely spaced peaks obtained from Chromatin Immunoprecipitation (ChIP) coupled with massively parallel short-read sequencing (seq) ChIP-seq datasets. PeakRanger provides high performance on extensive data sets by taking advantage of the MapReduce parallel environment. PeakRanger improves recognition of extremely closely-spaced peaks improving spatial accuracy in identifying the exact location of binding events and improving the run time by exploiting the parallel environment provided by a Cloud Computing architecture. PeakRanger is written in C++ and can be deployed on Linux, macOS, and Windows.
- STORMSeq (Scalable Tools for Open-source Read Mapping) [36] is a software pipeline for whole-genome and exome sequence data sets. STORMSeq is implemented as AWS Cloud service. STORMSeq presents an intuitive user interface for dealing with reading mapping and variant calling using genomic data.
- VAT (Variant Annotation Tool) [37] is a software package to annotate variants from multiple individual genomes at the transcript level and obtain descriptive statistics across genes and individuals. VAT visualizes different variants, integrating allele frequencies and genotype data, simplifying comparative analysis between distinct groups of individuals. VAT is implemented in C and PHP and it is available as a command-line tool or as a web application. Moreover, VAT can be run as a virtual machine in the AWS Cloud environment. VAT documentation and user guide are available at http://www.vat.gersteinlab.org (accessed on 21 March 2023).
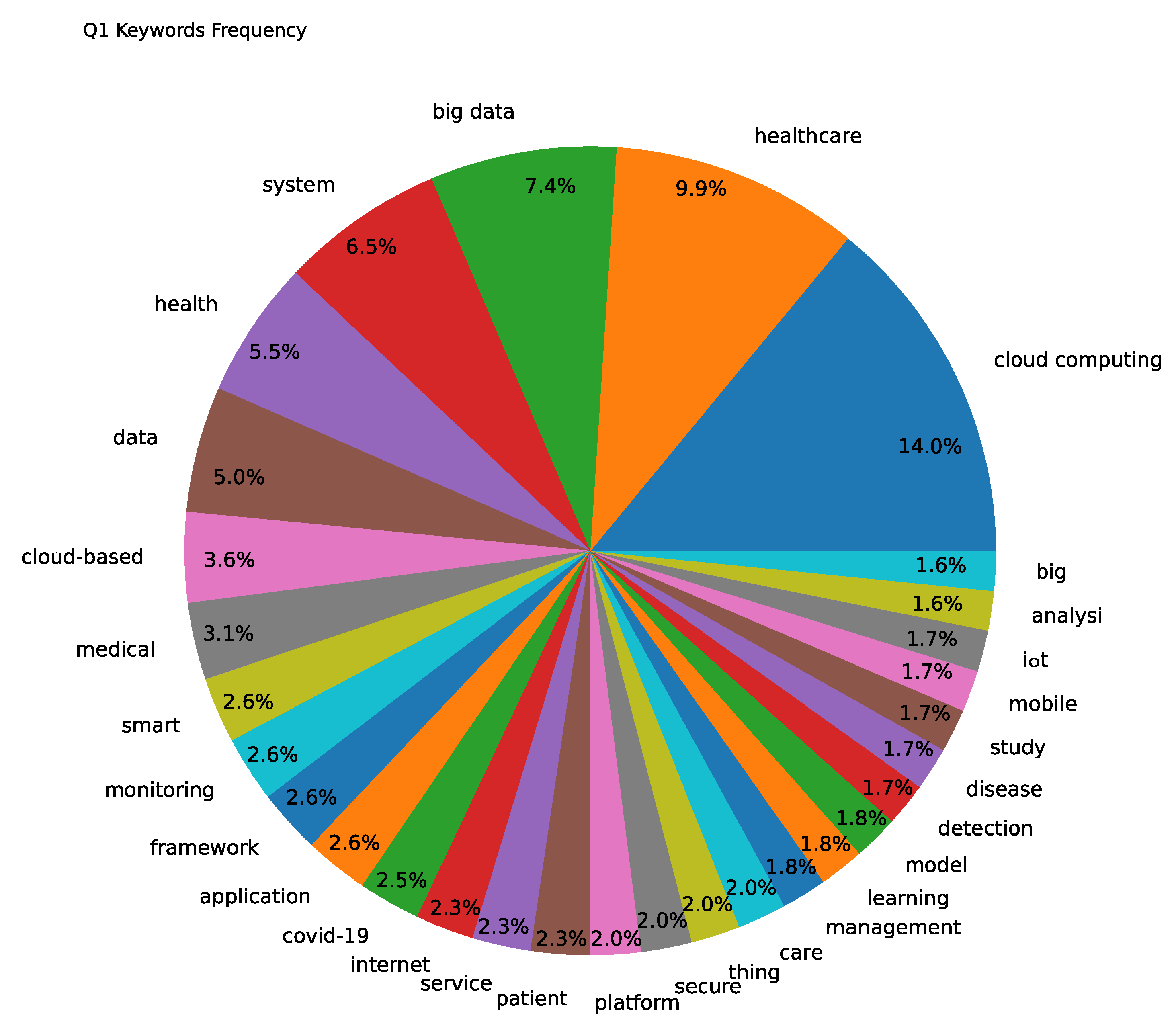
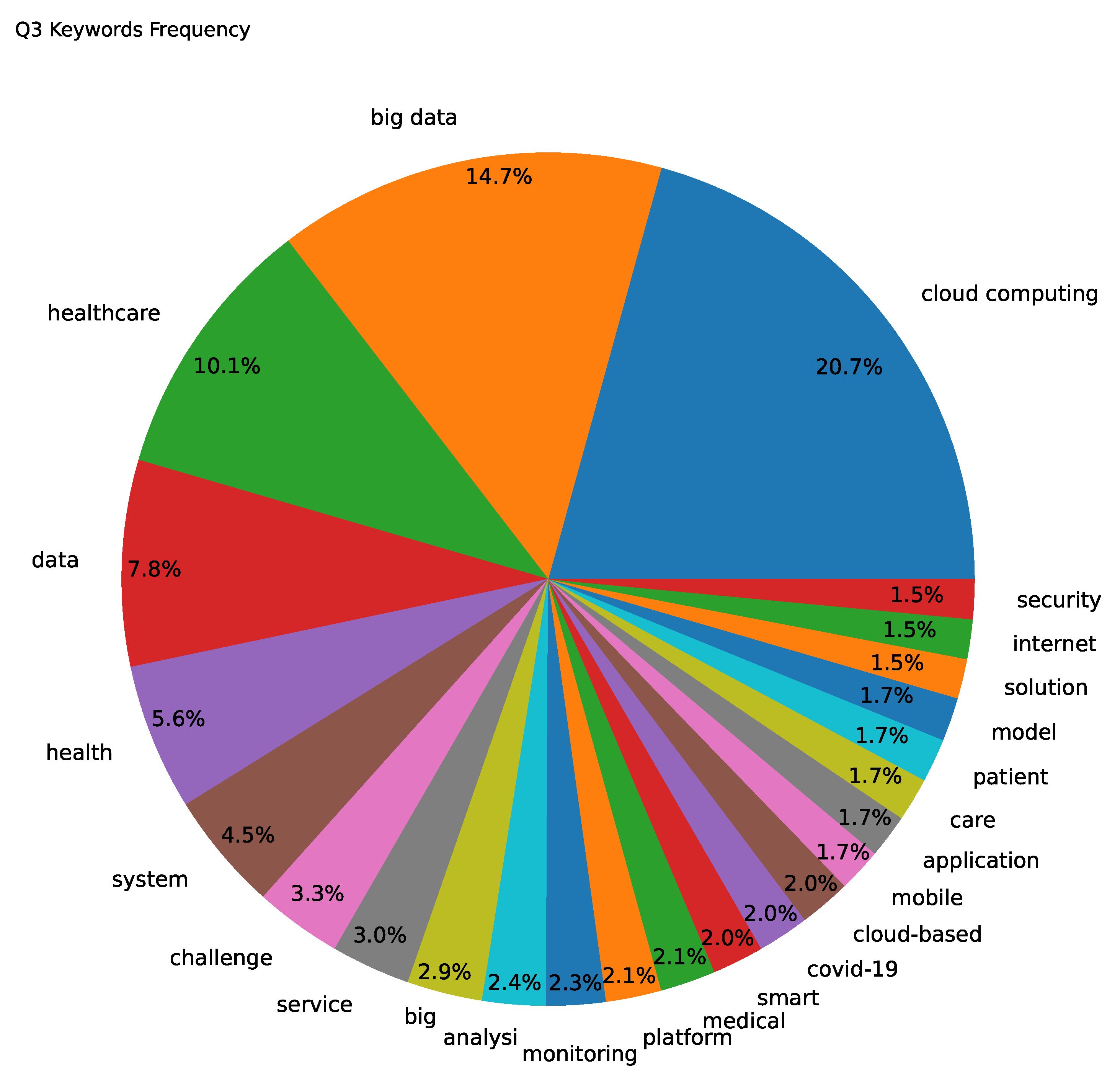
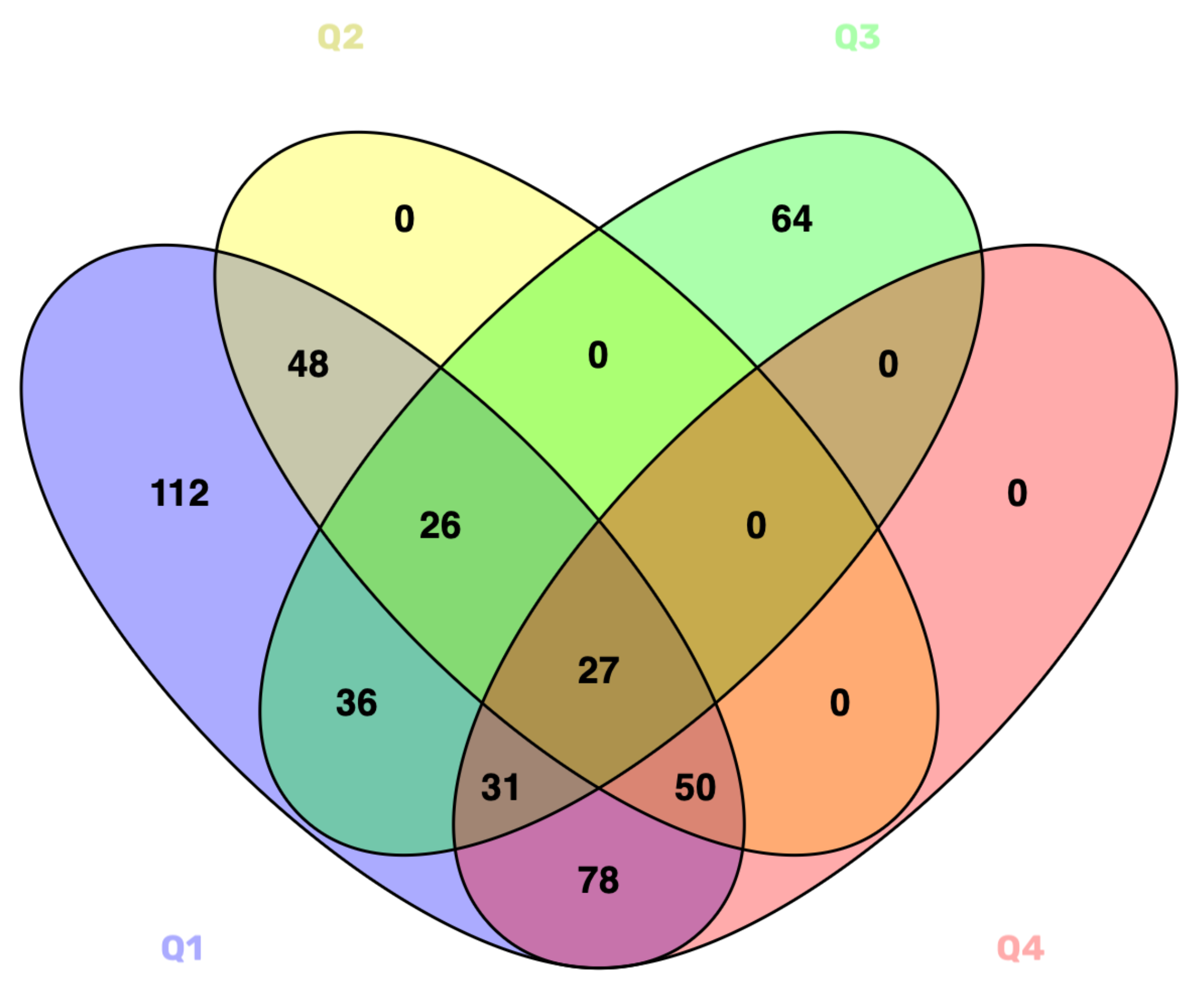
4. Materials and Methods
5. Discussion
6. Tips to Effectively Use Cloud Computing in Healthcare
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MC | Molecular Biology |
| HT | High-throughput |
| AWS | Amazon Web Services |
| BPaaS | Business Process as a Service |
| CaaS | Connectivity as a Service |
| ChIP | Chromatin immunoprecipitation |
| ChiPseq | Short read sequencing |
| DaaS | Data as a Service |
| DNA | DeoxyriboNucleic Acid |
| EMR | Elastic MapReduce |
| EMR | Hectronic medical record |
| GPU | raphics processing units |
| HIPAA | Health Insurance Portability and Accountability Act |
| HPC | High-Performance Computing |
| IaaS | Infrastructure as a Service |
| IDaaS | Identity as a Service |
| IT | Information Technology |
| MPI | Message-Passing Interface |
| NGS | Next-Generation Sequence |
| PaaS | Platform as a Service |
| RMAP | short read-mapping program |
| RNA-seq | RNA sequence |
| SaaS | Software as a Service |
| scRNA-seq | Single-cell RNA-sequence |
| SNP | Single Nucleotide Polymorphism |
| STORMSeq | Scalable Tools for Open-source Read Mapping |
| VAT | Variant Annotation Tool |
| VM | Virtual machines |
References
- Ahn, A.C.; Tewari, M.; Poon, C.S.; Phillips, R.S. The limits of reductionism in medicine: Could systems biology offer an alternative? PLoS Med. 2006, 3, e208. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Loscalzo, J.; Barabasi, A.L. Systems biology and the future of medicine. Wiley Interdiscip. Rev. Syst. Biol. Med. 2011, 3, 619–627. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vailati-Riboni, M.; Palombo, V.; Loor, J.J. What are omics sciences? In Periparturient Diseases of Dairy Cows; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–7. [Google Scholar]
- Mardis, E.R. Next-generation DNA sequencing methods. Annu. Rev. Genom. Hum. Genet. 2008, 9, 387–402. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shendure, J.; Balasubramanian, S.; Church, G.M.; Gilbert, W.; Rogers, J.; Schloss, J.A.; Waterston, R.H. DNA sequencing at 40: Past, present and future. Nature 2017, 550, 345–353. [Google Scholar] [CrossRef]
- D’Adamo, G.L.; Widdop, J.T.; Giles, E.M. The future is now? Clinical and translational aspects of “Omics” technologies. Immunol. Cell Biol. 2021, 99, 168–176. [Google Scholar] [CrossRef]
- Schneider, M.V.; Orchard, S. Omics technologies, data and bioinformatics principles. Bioinform. Omics Data 2011, 719, 3–30. [Google Scholar]
- Clarke, L.; Glendinning, I.; Hempel, R. The MPI message passing interface standard. In Programming Environments for Massively Parallel Distributed Systems; Springer: Berlin/Heidelberg, Germany, 1994; pp. 213–218. [Google Scholar]
- Kim, W. Cloud computing: Today and tomorrow. J. Object Technol. 2009, 8, 65–72. [Google Scholar] [CrossRef] [Green Version]
- Dillon, T.; Wu, C.; Chang, E. Cloud computing: Issues and challenges. In Proceedings of the 2010 24th IEEE International Conference on Advanced Information Networking and Applications, Perth, WA, Australia, 20–23 April 2010; pp. 27–33. [Google Scholar]
- Pautasso, C.; Wilde, E. RESTful web services: Principles, patterns, emerging technologies. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 1359–1360. [Google Scholar]
- Cusumano, M. Cloud computing and SaaS as new computing platforms. Commun. ACM 2010, 53, 27–29. [Google Scholar] [CrossRef]
- Pahl, C. Containerization and the paas cloud. IEEE Cloud Comput. 2015, 2, 24–31. [Google Scholar] [CrossRef]
- Bhardwaj, S.; Jain, L.; Jain, S. Cloud computing: A study of infrastructure as a service (IAAS). Int. J. Eng. Inf. Technol. 2010, 2, 60–63. [Google Scholar]
- Woitsch, R.; Utz, W. Business process as a service (BPaaS). In Proceedings of the Conference on e-Business, e-Services and e-Society, Delft, The Netherlands, 13–15 October 2015; pp. 435–440. [Google Scholar]
- Rajesh, S.; Swapna, S.; Reddy, P.S. Data as a service (daas) in cloud computing. Glob. J. Comput. Sci. Technol. 2012, 12, 25–29. [Google Scholar]
- Ni, Y.; Xing, C.L.; Zhang, K. Connectivity as a service: Outsourcing Enterprise connectivity over cloud computing environment. In Proceedings of the 2011 International Conference on Computer and Management (CAMAN), Wuhan, China, 19–21 May 2011; pp. 1–7. [Google Scholar]
- Ducatel, G. Identity as a service: A cloud based common capability. In Proceedings of the 2015 IEEE Conference on Communications and Network Security (CNS), Florence, Italy, 28–30 September 2015; pp. 675–679. [Google Scholar]
- Krampis, K.; Booth, T.; Chapman, B.; Tiwari, B.; Bicak, M.; Field, D.; Nelson, K.E. Cloud BioLinux: Pre-configured and on-demand bioinformatics computing for the genomics community. BMC Bioinform. 2012, 13, 42. [Google Scholar] [CrossRef] [Green Version]
- Agapito, G.; Cannataro, M.; Guzzi, P.H.; Marozzo, F.; Talia, D.; Trunfio, P. Cloud4SNP: Distributed analysis of SNP microarray data on the cloud. In Proceedings of the International Conference on Bioinformatics, Computational Biology and Biomedical Informatics, Washington, DC, USA, 22–25 September 2013; pp. 468–475. [Google Scholar]
- Guzzi, P.H.; Agapito, G.; Di Martino, M.T.; Arbitrio, M.; Tassone, P.; Tagliaferri, P.; Cannataro, M. DMET-analyzer: Automatic analysis of Affymetrix DMET data. BMC Bioinform. 2012, 13, 258. [Google Scholar] [CrossRef] [Green Version]
- Marozzo, F.; Talia, D.; Trunfio, P. A Cloud Framework for Big Data Analytics Workflows on Azure. In Proceedings of the Post-Proceedings of the High Performance Computing Workshop 2012; Catlett, C., Gentzsch, W., Grandinetti, L., Joubert, G., Vazquez-Poletti, J.L., Eds.; IOS Press: Cetraro, Italy, 2013; Volume 23, pp. 182–191. ISBN 978-1-61499-321-6. [Google Scholar]
- Marozzo, F.; Talia, D.; Trunfio, P. Using clouds for scalable knowledge discovery applications. In Proceedings of the European Conference on Parallel Processing, Aachen, Germany, 26–30 August 2013; pp. 220–227. [Google Scholar]
- Schatz, M.C. CloudBurst: Highly sensitive read mapping with MapReduce. Bioinformatics 2009, 25, 1363–1369. [Google Scholar] [CrossRef] [Green Version]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Afgan, E.; Chapman, B.; Taylor, J. CloudMan as a platform for tool, data, and analysis distribution. BMC Bioinform. 2012, 13, 315. [Google Scholar] [CrossRef] [Green Version]
- Afgan, E.; Lonie, A.; Taylor, J.; Goonasekera, N. CloudLaunch: Discover and deploy cloud applications. Future Gener. Comput. Syst. 2019, 94, 802–810. [Google Scholar] [CrossRef] [Green Version]
- Afgan, E.; Baker, D.; Coraor, N.; Chapman, B.; Nekrutenko, A.; Taylor, J. Galaxy CloudMan: Delivering cloud compute clusters. In Proceedings of the BMC Bioinformatics, Boston, MA, USA, 9–10 July 2010; Volume 11, pp. 1–6. [Google Scholar]
- Langmead, B.; Schatz, M.; Lin, J.; Pop, M.; Salzberg, S. Searching for snps with cloud computing. Genome Biol. 2009, 10, R134. [Google Scholar] [CrossRef] [Green Version]
- Li, R.; Li, Y.; Fang, X.; Yang, H.; Wang, J.; Kristiansen, K.; Wang, J. SNP detection for massively parallel whole-genome resequencing. Genome Res. 2009, 19, 1124–1132. [Google Scholar] [CrossRef] [Green Version]
- Jourdren, L.; Bernard, M.; Dillies, M.A.; Le Crom, S. Eoulsan: A cloud computing-based framework facilitating high throughput sequencing analyses. Bioinformatics 2012, 28, 1542–1543. [Google Scholar] [CrossRef] [Green Version]
- Lehmann, N.; Perrin, S.; Wallon, C.; Bauquet, X.; Deshaies, V.; Firmo, C.; Du, R.; Berthelier, C.; Hernandez, C.; Michaud, C.; et al. Eoulsan 2: An efficient workflow manager for reproducible bulk, long-read and single-cell transcriptomics analyses. bioRxiv 2021. [Google Scholar] [CrossRef]
- Ehwerhemuepha, L.; Gasperino, G.; Bischoff, N.; Taraman, S.; Chang, A.; Feaster, W. HealtheDataLab—A cloud computing solution for data science and advanced analytics in healthcare with application to predicting multi-center pediatric readmissions. BMC Med. Informatics Decis. Mak. 2020, 20, 115. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Chen, W.; Nie, M.; Zhang, F.; Wang, Y.; He, A.; Wang, X.; Yan, G. iMAGE cloud: Medical image processing as a service for regional healthcare in a hybrid cloud environment. Environ. Health Prev. Med. 2016, 21, 563–571. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Grossman, R.; Stein, L. PeakRanger: A cloud-enabled peak caller for ChIP-seq data. BMC Bioinform. 2011, 12, 139. [Google Scholar] [CrossRef] [Green Version]
- Karczewski, K.J.; Fernald, G.H.; Martin, A.R.; Snyder, M.; Tatonetti, N.P.; Dudley, J.T. STORMSeq: An open-source, user-friendly pipeline for processing personal genomics data in the cloud. PloS ONE 2014, 9, e84860. [Google Scholar] [CrossRef] [Green Version]
- Habegger, L.; Balasubramanian, S.; Chen, D.Z.; Khurana, E.; Sboner, A.; Harmanci, A.; Rozowsky, J.; Clarke, D.; Snyder, M.; Gerstein, M. VAT: A computational framework to functionally annotate variants in personal genomes within a cloud-computing environment. Bioinformatics 2012, 28, 2267–2269. [Google Scholar] [CrossRef] [Green Version]
- Roberts, R.J. PubMed Central: The GenBank of the published literature. Proc. Natl. Acad. Sci. USA 2001, 98, 381–382. [Google Scholar] [CrossRef] [Green Version]
- Oliveros, J.C. VENNY. An Interactive Tool for Comparing Lists with Venn Diagrams. 2007. Available online: http://bioinfogp.cnb.csic.es/tools/venny/index.html (accessed on 15 March 2023).
- Calabrese, B.; Cannataro, M. Cloud computing in healthcare and biomedicine. Scalable Comput. Pract. Exp. 2015, 16, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Pezoulas, V.C.; Goules, A.; Kalatzis, F.; Chatzis, L.; Kourou, K.D.; Venetsanopoulou, A.; Exarchos, T.P.; Gandolfo, S.; Votis, K.; Zampeli, E.; et al. Addressing the clinical unmet needs in primary Sjögren’s Syndrome through the sharing, harmonization and federated analysis of 21 European cohorts. Comput. Struct. Biotechnol. J. 2022, 20, 471–484. [Google Scholar] [CrossRef]
- Bukowski, M.; Farkas, R.; Beyan, O.; Moll, L.; Hahn, H.; Kiessling, F.; Schmitz-Rode, T. Implementation of eHealth and AI integrated diagnostics with multidisciplinary digitized data: Are we ready from an international perspective? Eur. Radiol. 2020, 30, 5510–5524. [Google Scholar] [CrossRef]
- Shneiderman, B. Human-centered artificial intelligence: Reliable, safe & trustworthy. Int. J. Hum. Comput. Interact. 2020, 36, 495–504. [Google Scholar]
- Wu, Z.; Xuan, S.; Xie, J.; Lin, C.; Lu, C. How to ensure the confidentiality of electronic medical records on the cloud: A technical perspective. Comput. Biol. Med. 2022, 147, 105726. [Google Scholar] [CrossRef]
- Gkoulalas-Divanis, A.; Loukides, G. Anonymization of Electronic Medical Records to Support Clinical Analysis; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Majeed, A.; Lee, S. Anonymization techniques for privacy preserving data publishing: A comprehensive survey. IEEE Access 2020, 9, 8512–8545. [Google Scholar] [CrossRef]
- Ayoub, F.; Singh, K. Cryptographic techniques and network security. In Proceedings of the IEE Proceedings F-Communications, Radar and Signal Processing; IEEE: Piscataway, NJ, USA, 1984; Volume 7, pp. 684–694. [Google Scholar]
- Hassan, J.; Shehzad, D.; Habib, U.; Aftab, M.U.; Ahmad, M.; Kuleev, R.; Mazzara, M. The Rise of Cloud Computing: Data Protection, Privacy, and Open Research Challenges—A Systematic Literature Review (SLR). Comput. Intell. Neurosci. 2022, 2022, 8303504. [Google Scholar] [CrossRef]
- Forouzan, B.A.; Mukhopadhyay, D. Cryptography and Network Security; Mc Graw Hill Education Private Limited: New York, NY, USA, 2015; Volume 12. [Google Scholar]
- Abood, O.G.; Guirguis, S.K. A survey on cryptography algorithms. Int. J. Sci. Res. Publ. 2018, 8, 495–516. [Google Scholar] [CrossRef] [Green Version]
- Gordon, A.D.; Jeffrey, A. Types and effects for asymmetric cryptographic protocols. J. Comput. Secur. 2004, 12, 435–483. [Google Scholar] [CrossRef]
- Biryukov, A.; Perrin, L. State of the art in lightweight symmetric cryptography. Cryptol. ePrint Arch. 2017. Available online: https://eprint.iacr.org/2017/511 (accessed on 15 March 2023).
- Rahmani, M.K.I.; Shuaib, M.; Alam, S.; Siddiqui, S.T.; Ahmad, S.; Bhatia, S.; Mashat, A. Blockchain-Based Trust Management Framework for Cloud Computing-Based Internet of Medical Things (IoMT): A Systematic Review. Comput. Intell. Neurosci. 2022, 2022, 9766844. [Google Scholar] [CrossRef]
- Ismail, L.; Materwala, H.; Hennebelle, A. A scoping review of integrated blockchain-cloud (BcC) architecture for healthcare: Applications, challenges and solutions. Sensors 2021, 21, 3753. [Google Scholar] [CrossRef]
- Metcalf, D.; Milliard, S.T.; Gomez, M.; Schwartz, M. Wearables and the Internet of Things for Health: Wearable, Interconnected Devices Promise More Efficient and Comprehensive Health Care. IEEE Pulse 2016, 7, 35–39. [Google Scholar] [CrossRef]
- Kibiwott, K.P.; Zhao, Y.; Kogo, J.; Zhang, F. Verifiable fully outsourced attribute-based signcryption system for IoT eHealth big data in cloud computing. Math. Biosci. Eng. 2019, 16, 3561–3594. [Google Scholar] [CrossRef]
- Barillaro, L.; Agapito, G.; Cannataro, M. Edge-based Deep Learning in Medicine: Classification of ECG signals. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–8 December 2022; pp. 2169–2174. [Google Scholar]
- Crespo-Cepeda, R.; Agapito, G.; Vazquez-Poletti, J.L.; Cannataro, M. Challenges and Opportunities of Amazon Serverless Lambda Services in Bioinformatics. In Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, Niagara Falls, NY, USA, 7–10 September 2019; pp. 663–668. [Google Scholar] [CrossRef]
- Aloi, G.; Fortino, G.; Gravina, R.; Pace, P.; Savaglio, C. Simulation-driven platform for Edge-based AAL systems. IEEE J. Sel. Areas Commun. 2020, 39, 446–462. [Google Scholar] [CrossRef]
- Casadei, R.; Fortino, G.; Pianini, D.; Placuzzi, A.; Savaglio, C.; Viroli, M. A methodology and simulation-based toolchain for estimating deployment performance of smart collective services at the edge. IEEE Internet Things J. 2022, 9, 20136–20148. [Google Scholar] [CrossRef]
- Barillaro, L.; Agapito, G.; Cannataro, M. Scalable Deep Learning for Healthcare: Methods and Applications. In Proceedings of the 13th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, Northbrook, IL, USA, 7–10 August 2022. [Google Scholar] [CrossRef]
- Savaglio, C.; Fortino, G. A simulation-driven methodology for IoT data mining based on edge computing. ACM Trans. Internet Technol. (TOIT) 2021, 21, 1–22. [Google Scholar] [CrossRef]
- Bertuccio, S.; Tardiolo, G.; Giambò, F.M.; Giuffrè, G.; Muratore, R.; Settimo, C.; Raffa, A.; Rigano, S.; Bramanti, A.; Muscarà, N.; et al. ReportFlow: An application for EEG visualization and reporting using cloud platform. BMC Med. Inform. Decis. Mak. 2021, 21, 7. [Google Scholar] [CrossRef] [PubMed]
- Mehrtak, M.; SeyedAlinaghi, S.; MohsseniPour, M.; Noori, T.; Karimi, A.; Shamsabadi, A.; Heydari, M.; Barzegary, A.; Mirzapour, P.; Soleymanzadeh, M.; et al. Security challenges and solutions using healthcare cloud computing. J. Med. Life 2021, 14, 448. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DM | CP | S | AS | AP | ToJ | HS | C | EU | T |
|---|---|---|---|---|---|---|---|---|---|
| Public | √ | × | √ | × | sj | × | × | × | × |
| Private | √ | √ | √ | × | cj | × | √ | √ | √ |
| Federate | × | √ | √ | × | cj | √ | √ | √ | √ |
| Hybrid | × | × | × | √ | gj | √ | √ | × | × |
| Multicloud | √ | × | √ | × | gj | √ | √ | × | × |
| Intercloud | × | √ | × | × | gj | √ | √ | √ | √ |
| QueryID | Query | Publication Years Range |
|---|---|---|
| cloud computing & healthcare | 2009–2022 | |
| cloud computing & healthcare & security | 2009–2022 | |
| cloud computing & healthcare & challenges | 2009–2022 | |
| cloud computing & healthcare & applications | 2009–2022 |
| QueryID | TotManuscripts | TotFreeFullText |
|---|---|---|
| 668 | 408 | |
| 237 | 151 | |
| 184 | 120 | |
| 273 | 186 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Agapito, G.; Cannataro, M. An Overview on the Challenges and Limitations Using Cloud Computing in Healthcare Corporations. Big Data Cogn. Comput. 2023, 7, 68. https://doi.org/10.3390/bdcc7020068
Agapito G, Cannataro M. An Overview on the Challenges and Limitations Using Cloud Computing in Healthcare Corporations. Big Data and Cognitive Computing. 2023; 7(2):68. https://doi.org/10.3390/bdcc7020068
Chicago/Turabian StyleAgapito, Giuseppe, and Mario Cannataro. 2023. "An Overview on the Challenges and Limitations Using Cloud Computing in Healthcare Corporations" Big Data and Cognitive Computing 7, no. 2: 68. https://doi.org/10.3390/bdcc7020068