


Automatic Medical Face Mask Detection Based on Cross-Stage Partial Network to Combat COVID-19


Abstract
:1. Introduction
- (1)
- An innovative deep learning detector model that automatically identifies and localizes a medically masked face on an image has been developed and demonstrated.
- (2)
- Identification and evaluation of the advantages and disadvantages of using the Yolo V3, Yolo V4, and Yolo V5 facial recognition systems for the detection and recognition of medical face masks.
- (3)
- Our work combined the Cross Stage Partial network (CSP) and Spatial Pyramid Pooling (SPP) with the Yolo model.
- (4)
- This work performs a comparative analysis of the combination of the Yolo V3, Yolo V4, and Yolo V5 models.
2. Related Works
2.1. Medical Face Mask Detection with Deep Learning
2.2. Yolo Algorithm
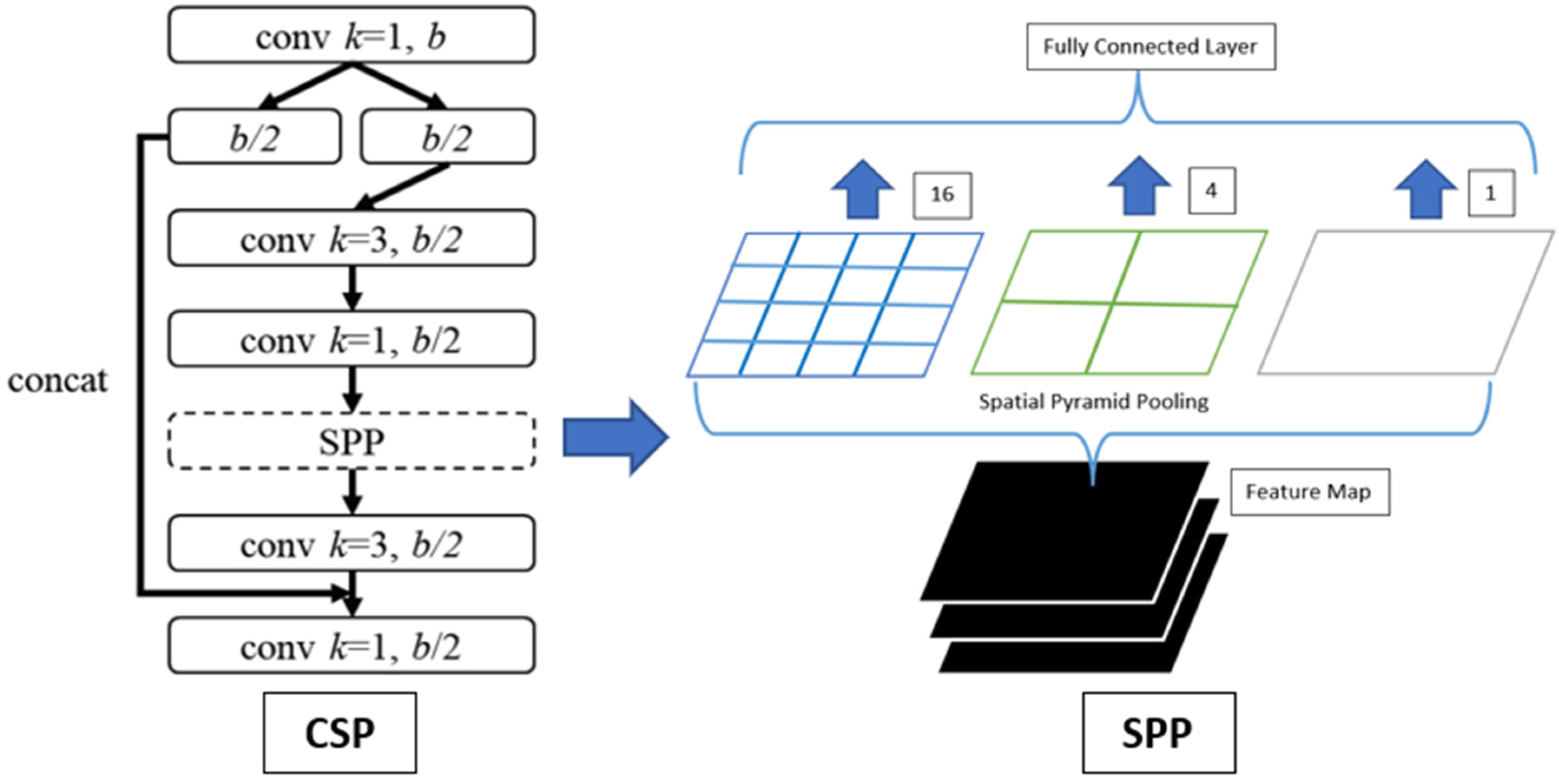
2.3. Cross Stage Partial (CSP) Networks and Spatial Pyramid Pooling (SPP)
3. Methodology
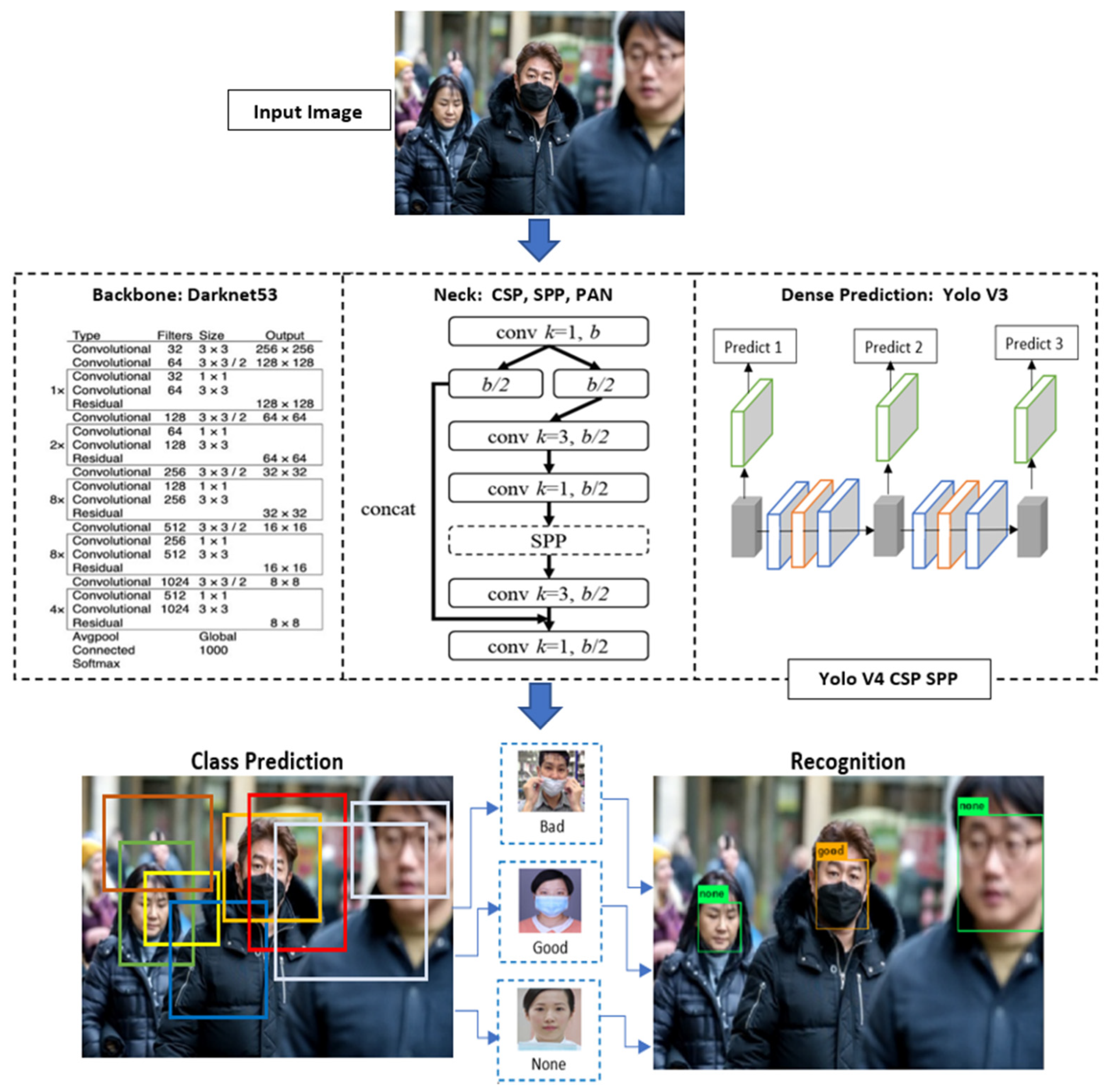
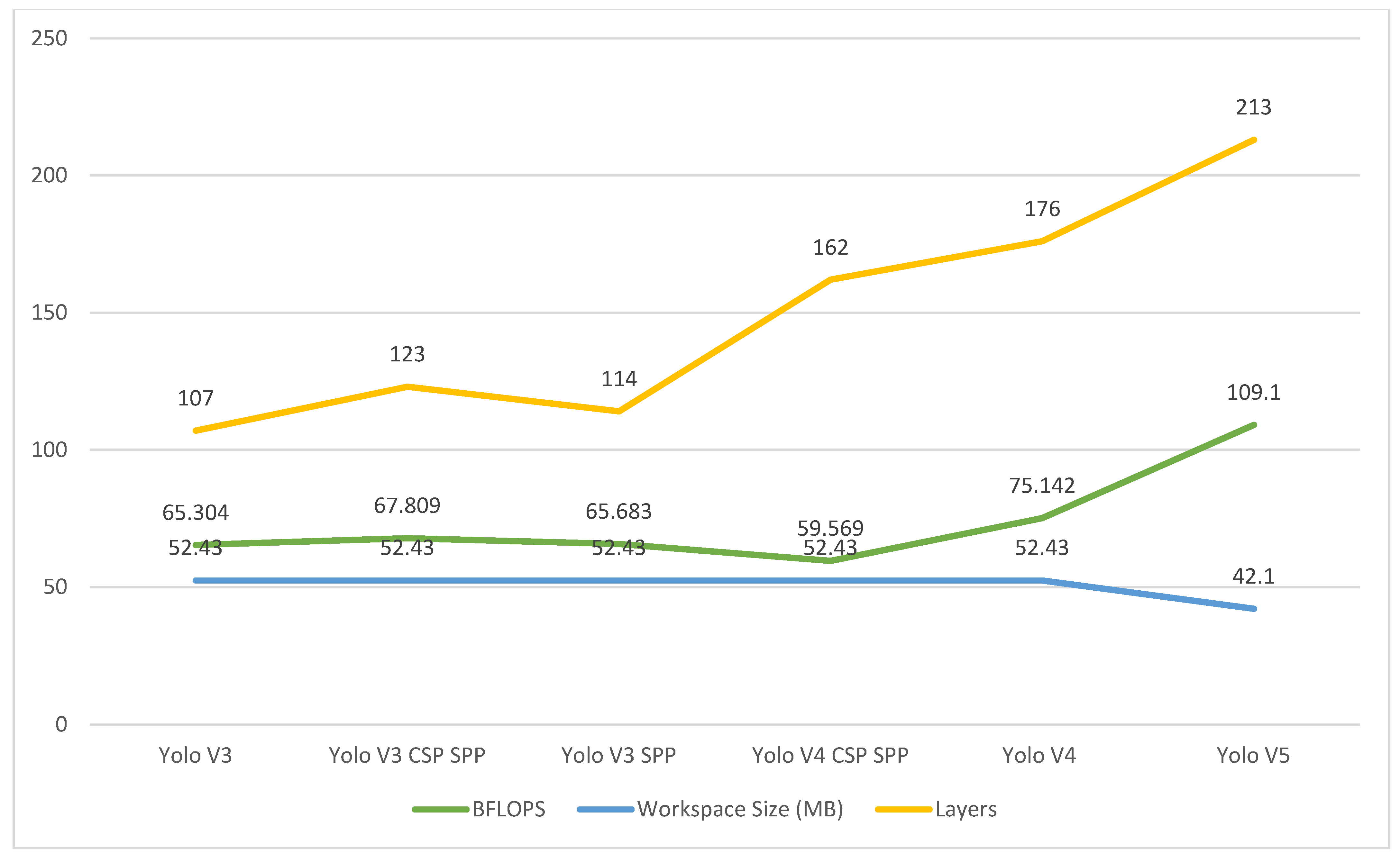
3.1. Yolo V4 CSP SPP
- Organizes the input image into m × m grids, with each grid generating K bounding boxes based on the calculation of the anchor boxes in the previous grid.
- Makes use of the CNN to collect all of the object characteristics from the picture and predict the and the . Given the anchor box of size () at the grid cell with its top left corner at (), the model predicts the offset and the scale (), and the corresponding predicted bounding box b has center () and size (). The confidence score is the sigmoid (σ) of another output .
- Compares the maximum confidence of the K bounding boxes with the threshold .
- If > , this means that the object is contained in the bounding box. If this is not the case, the item is not in the bounding box.
- The object category should be chosen based on the category with the highest anticipated probability.
- The Non-Maximum Suppression (NMS) method is then used to perform an optimum search strategy to suppress duplicate boxes and outcomes, after which the outcomes of object recognition are displayed on the screen.

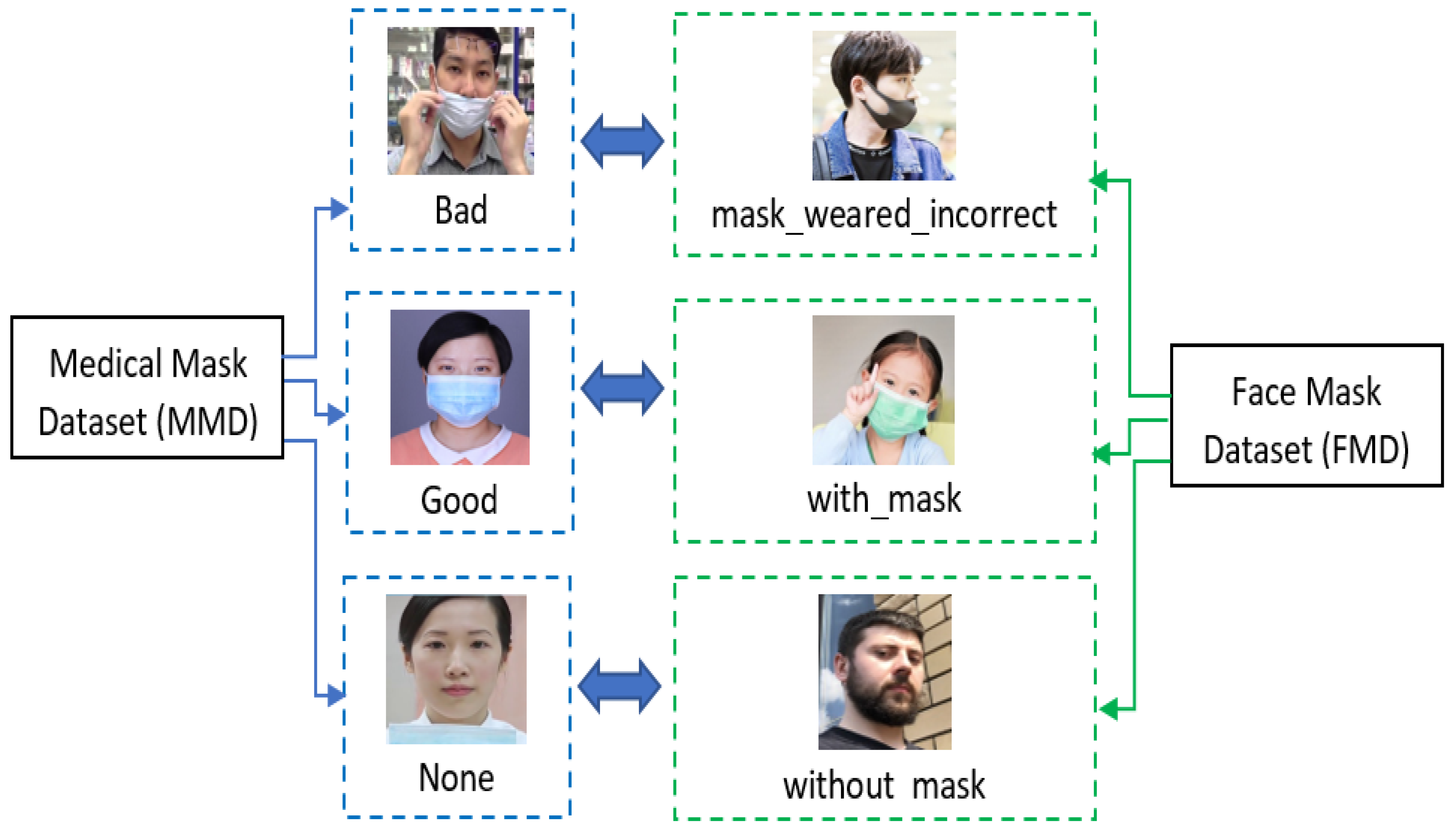
3.2. FMD and MMD Dataset
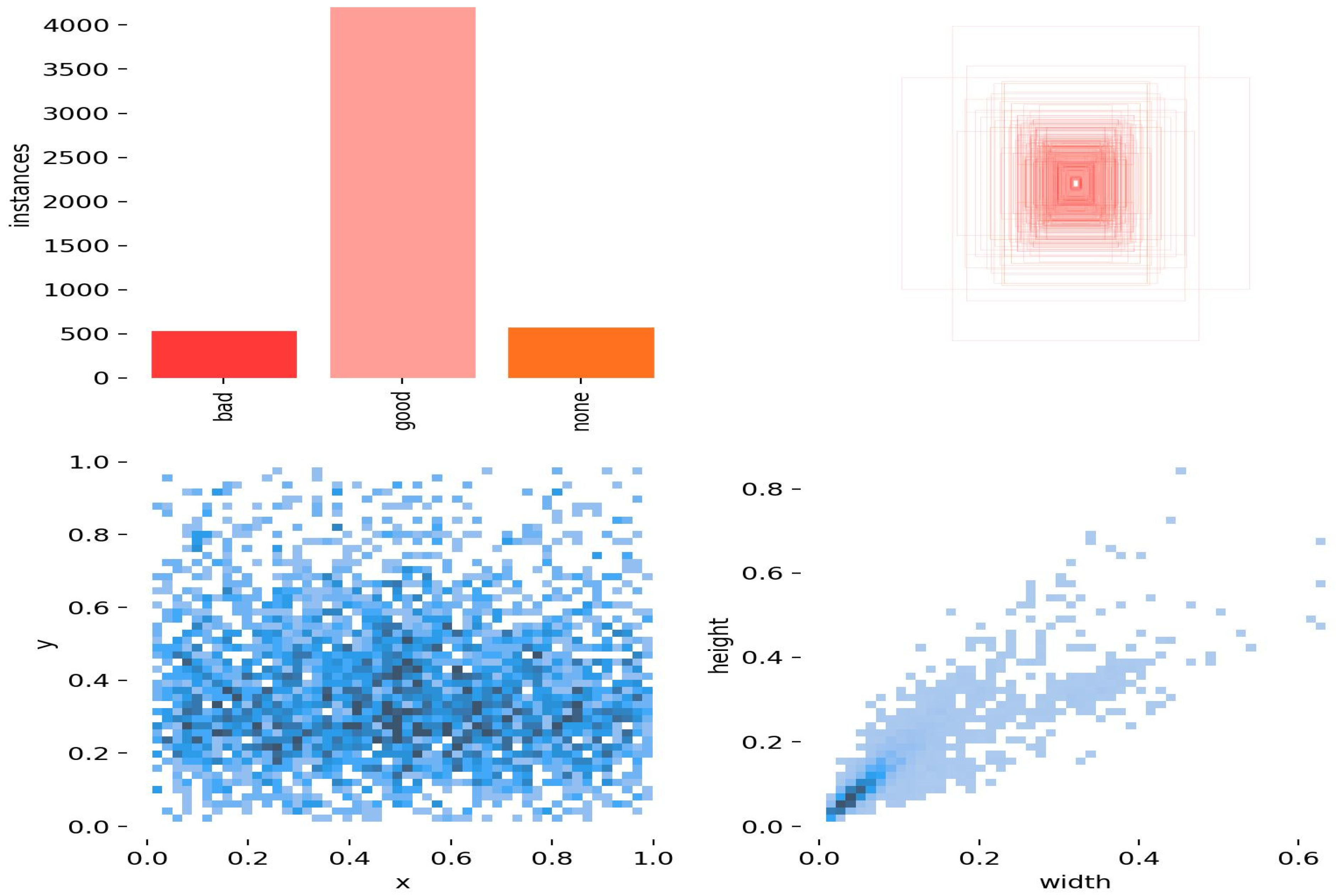
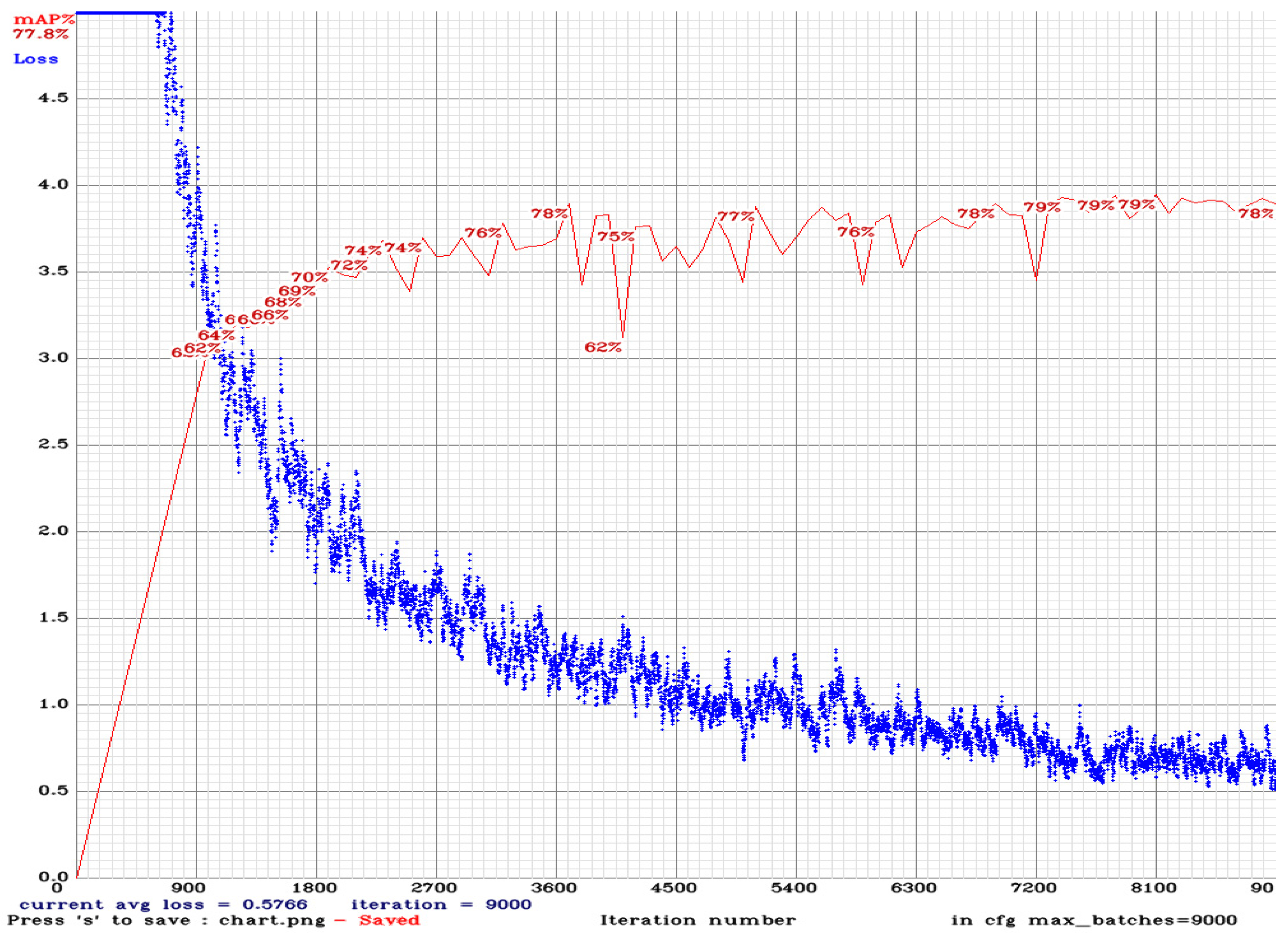
3.3. Training Result
4. Results and Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nowrin, A.; Afroz, S.; Rahman, M.S.; Mahmud, I.; Cho, Y.Z. Comprehensive Review on Facemask Detection Techniques in the Context of COVID-19. IEEE Access 2021, 9, 106839–106864. [Google Scholar] [CrossRef]
- Cao, Z.; Shao, M.; Xu, L.; Mu, S.; Qu, H. Maskhunter: Real-Time Object Detection of Face Masks during the COVID-19 Pandemic. IET Image Process. 2020, 14, 4359–4367. [Google Scholar] [CrossRef]
- Loey, M.; Manogaran, G.; Taha, M.H.N.; Khalifa, N.E.M. Fighting against COVID-19: A Novel Deep Learning Model Based on YOLO-v2 with ResNet-50 for Medical Face Mask Detection. Sustain. Cities Soc. 2021, 65, 102600. [Google Scholar] [CrossRef]
- Feng, S.; Shen, C.; Xia, N.; Song, W.; Fan, M.; Cowling, B.J. Rational Use of Face Masks in the COVID-19 Pandemic. Lancet Respir. Med. 2020, 8, 434–436. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C. Combination of Resnet and Spatial Pyramid Pooling for Musical Instrument Identification. Cybern. Inf. Technol. 2022, 22, 104. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.C.; Yu, H.; Jiang, X. Robust Detection Method for Improving Small Traffic Sign Recognition Based on Spatial Pyramid Pooling. J. Ambient Intell. Humaniz. Comput. 2021, 12, 1–18. [Google Scholar] [CrossRef]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent Advances in Deep Learning for Object Detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef]
- Singh, S.; Ahuja, U.; Kumar, M.; Kumar, K.; Sachdeva, M. Face Mask Detection Using YOLOv3 and Faster R-CNN Models: COVID-19 Environment. Multimed. Tools Appl. 2021, 80, 19753–19768. [Google Scholar] [CrossRef]
- Lemke, M.K.; Apostolopoulos, Y.; Sönmez, S. Syndemic Frameworks to Understand the Effects of COVID-19 on Commercial Driver Stress, Health, and Safety. J. Transp. Health 2020, 18, 100877. [Google Scholar] [CrossRef]
- Dewi, C.; Christanto, J. Henoch Combination of Deep Cross-Stage Partial Network and Spatial Pyramid Pooling for Automatic Hand Detection. Big Data Cogn. Comput. 2022, 6, 85. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-Yolov4: Scaling Cross Stage Partial Network. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE Computer Society: Washington, DC, USA, 2021; pp. 13024–13033. [Google Scholar]
- Said, Y. Pynq-YOLO-Net: An Embedded Quantized Convolutional Neural Network for Face Mask Detection in COVID-19 Pandemic Era. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 100–106. [Google Scholar] [CrossRef]
- Ejaz, M.S.; Islam, M.R.; Sifatullah, M.; Sarker, A. Implementation of Principal Component Analysis on Masked and Non-Masked Face Recognition. In Proceedings of the 1st International Conference on Advances in Science, Engineering and Robotics Technology 2019, ICASERT 2019, Dhaka, Bangladesh, 3–5 May 2019. [Google Scholar]
- Ud Din, N.; Javed, K.; Bae, S.; Yi, J. A Novel GAN-Based Network for Unmasking of Masked Face. IEEE Access 2020, 8, 44276–44287. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.; Liu, Y.; Yu, H. Various Generative Adversarial Networks Model for Synthetic Prohibitory Sign Image Generation. Appl. Sci. 2021, 11, 2913. [Google Scholar] [CrossRef]
- Ge, S.; Li, J.; Ye, Q.; Luo, Z. Detecting Masked Faces in the Wild with LLE-CNNs. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017. Volume 2017-January. [Google Scholar]
- Loey, M.; Manogaran, G.; Taha, M.H.N.; Khalifa, N.E.M. A Hybrid Deep Transfer Learning Model with Machine Learning Methods for Face Mask Detection in the Era of the COVID-19 Pandemic. Meas. J. Int. Meas. Confed. 2021, 167, 108288. [Google Scholar] [CrossRef] [PubMed]
- Nieto-Rodríguez, A.; Mucientes, M.; Brea, V.M. System for Medical Mask Detection in the Operating Room through Facial Attributes. In Pattern Recognition and Image Analysis, Proceedings of the 7th Iberian Conference, IbPRIA 2015, Santiago de Compostela, Spain, 17–19 June 2015; Paredes, R., Cardoso, J.S., Pardo, X.M., Eds.; Springer: Cham, Switzerland, 2015; Volume 9117. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. CoRR 2018, abs/1804.0, 1–6. [Google Scholar]
- Chen, H.; He, Z.; Shi, B.; Zhong, T. Research on Recognition Method of Electrical Components Based on YOLO V3. IEEE Access 2019, 7, 157818–157829. [Google Scholar] [CrossRef]
- Zhao, L.; Li, S. Object Detection Algorithm Based on Improved YOLOv3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Mark Liao, H.-Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.; Liao, H.M.; Wu, Y.; Chen, P. CSPNet: A New Backbone That Can Enhance Learning Capability of Cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR Workshop), Seattle, WA, USA, 14–19 June 2020; p. 2. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Misra, D. Mish: A Self Regularized Non-Monotonic Neural Activation Function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Ren, S.; He, K.; Girshick, R. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 2015 advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Xu, Q.; Lin, R.; Yue, H.; Huang, H.; Yang, Y.; Yao, Z. Research on Small Target Detection in Driving Scenarios Based on Improved Yolo Network. IEEE Access 2020, 8, 27574–27583. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C.; Jiang, X.; Yu, H. Deep Convolutional Neural Network for Enhancing Traffic Sign Recognition Developed on Yolo V4. Multimed. Tools Appl. 2022, 81, 1–25. [Google Scholar] [CrossRef]
- Fang, Y.; Guo, X.; Chen, K.; Zhou, Z.; Ye, Q. Accurate and Automated Detection of Surface Knots on Sawn Timbers Using YOLO-V5 Model. BioResources 2021, 16, 5390–5406. [Google Scholar] [CrossRef]
- Wu, W.; Liu, H.; Li, L.; Long, Y.; Wang, X.; Wang, Z.; Li, J.; Chang, Y. Application of Local Fully Convolutional Neural Network Combined with YOLO v5 Algorithm in Small Target Detection of Remote Sensing Image. PLoS ONE 2021, 16, e0259283. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Wang, B.; Zheng, X. Sound Active Attention Framework for Remote Sensing Image Captioning. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1985–2000. [Google Scholar] [CrossRef]
- Jiang, J.; Fu, X.; Qin, R.; Wang, X.; Ma, Z. High-Speed Lightweight Ship Detection Algorithm Based on YOLO-V4 for Three-Channels RGB SAR Image. Remote Sens. 2021, 13, 1909. [Google Scholar] [CrossRef]
- Grauman, K.; Darrell, T. The Pyramid Match Kernel: Discriminative Classification with Sets of Image Features. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; pp. 1458–1465. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 1–8. [Google Scholar]
- Bbox Label Tool. Available online: https://github.com/puzzledqs/BBox-Label-Tool (accessed on 1 December 2020).
- Larxel Face Mask Detection. Available online: https://www.kaggle.com/datasets/andrewmvd/face-mask-detection (accessed on 13 January 2022).
- Mikolaj Witkowski Medical Mask Dataset. Available online: https://www.kaggle.com/vtech6/medical-masks-dataset (accessed on 24 January 2022).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Yuan, Y.; Xiong, Z.; Wang, Q. An Incremental Framework for Video-Based Traffic Sign Detection, Tracking, and Recognition. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1918–1929. [Google Scholar] [CrossRef]
- Kang, H.; Chen, C. Fast Implementation of Real-Time Fruit Detection in Apple Orchards Using Deep Learning. Comput. Electron. Agric. 2020, 168, 105108. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Class ID | AP | Precision | Recall | F1-Score | IoU (%) | mAP@0.50 (%) |
|---|---|---|---|---|---|---|---|
| Yolo V3 | 0 | 52.18 | 0.82 | 0.78 | 0.8 | 64.83 | 58.86 |
| 1 | 89.33 | ||||||
| 2 | 35.09 | ||||||
| Yolo V3 CSP SPP | 0 | 56.4 | 0.78 | 0.81 | 0.79 | 60.25 | 59.91 |
| 1 | 90.36 | ||||||
| 2 | 32.97 | ||||||
| Yolo V3 SPP | 0 | 59.05 | 0.81 | 0.79 | 0.8 | 61.57 | 59.76 |
| 1 | 91.09 | ||||||
| 2 | 29.16 | ||||||
| Yolo V4 | 0 | 65.67 | 0.78 | 0.93 | 0.85 | 66.8 | 67.9 |
| 1 | 96.47 | ||||||
| 2 | 41.56 | ||||||
| Yolo V4 CSP SPP | 0 | 76.88 | 0.89 | 0.91 | 0.9 | 75.9 | 78.84 |
| 1 | 96.06 | ||||||
| 2 | 63.57 | ||||||
| Yolo V5 | 0 | 47.8 | 0.62 | 0.77 | 0.687 | 52.3 | 63.5 |
| 1 | 94.6 | ||||||
| 2 | 48.1 |
| Model | Class ID | AP | Precision | Recall | F1-Score | IoU (%) | mAP@0.50 (%) |
|---|---|---|---|---|---|---|---|
| Yolo V3 | 0 | 55.6 | 0.84 | 0.86 | 0.85 | 66.32 | 67.11 |
| 1 | 95.65 | ||||||
| 2 | 50.08 | ||||||
| Yolo V3 CSP SPP | 0 | 60.76 | 0.82 | 0.89 | 0.85 | 63.67 | 69.41 |
| 1 | 95.97 | ||||||
| 2 | 51.51 | ||||||
| Yolo V3 SPP | 0 | 58.85 | 0.82 | 0.86 | 0.84 | 62.91 | 66.27 |
| 1 | 95.45 | ||||||
| 2 | 44.5 | ||||||
| Yolo V4 | 0 | 64.92 | 0.81 | 0.99 | 0.89 | 71.04 | 74.26 |
| 1 | 99.53 | ||||||
| 2 | 58.32 | ||||||
| Yolo V4 CSP SPP | 0 | 99.52 | 0.97 | 0.99 | 0.98 | 86.54 | 99.26 |
| 1 | 99.51 | ||||||
| 2 | 98.76 | ||||||
| Yolo V5 | 0 | 0.48 | 0.615 | 0.837 | 0.7 | 0.54 | 65.3 |
| 1 | 95.8 | ||||||
| 2 | 52.2 |
| Reference | Dataset | Methodology | Classification | Detection | Result AP (%) |
|---|---|---|---|---|---|
| (Ejaz et al., 2019) [13] | Our Database of Faces (ORL) | PCA | Yes | No | 70% |
| (Loey et al., 2021a) [17] | Face Mask Dataset (FMD) | Hybrid | Yes | No | 99.64% |
| (Ge et al., 2017) [16] | A Dataset of Masked Faces (MAFA) | LLE-CNNs | Yes | Yes | 76.4% |
| (Loey et al., 2021b) [3] | Face Mask Dataset (FMD) and Medical Mask Dataset (MMD) | Yolo V2 with Resnet | Yes | Yes | 81% |
| Proposed Method | Face Mask Dataset (FMD) and Medical Mask Dataset (MMD) | Yolo V4 CSP SPP | Yes | Yes | 99.26% |
| Model | Class | |||
|---|---|---|---|---|
| None | Good | |||
| Acc (%) | Time (ms) | Acc (%) | Time (ms) | |
| YoloV3 | 50.1 | 16.4 | 71.2 | 16.7 |
| YoloV3 CSP SPP | 61.4 | 18.1 | 76.1 | 18.4 |
| Yolo V3 SPP | 55.7 | 17.4 | 66.0 | 17.6 |
| Yolo V4 | 82.0 | 19.03 | 92.0 | 19.01 |
| Yolo V4 CSP | 83.0 | 19.07 | 97.0 | 19.08 |
| Yolo V5 | 72.7 | 11.13 | 85.7 | 11.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dewi, C.; Chen, R.-C. Automatic Medical Face Mask Detection Based on Cross-Stage Partial Network to Combat COVID-19. Big Data Cogn. Comput. 2022, 6, 106. https://doi.org/10.3390/bdcc6040106
Dewi C, Chen R-C. Automatic Medical Face Mask Detection Based on Cross-Stage Partial Network to Combat COVID-19. Big Data and Cognitive Computing. 2022; 6(4):106. https://doi.org/10.3390/bdcc6040106
Chicago/Turabian StyleDewi, Christine, and Rung-Ching Chen. 2022. "Automatic Medical Face Mask Detection Based on Cross-Stage Partial Network to Combat COVID-19" Big Data and Cognitive Computing 6, no. 4: 106. https://doi.org/10.3390/bdcc6040106