
Combination of Deep Cross-Stage Partial Network and Spatial Pyramid Pooling for Automatic Hand Detection



Abstract
:1. Introduction
2. Related Work
2.1. Hand Detection and Recognition
2.2. CNN for Object Detection
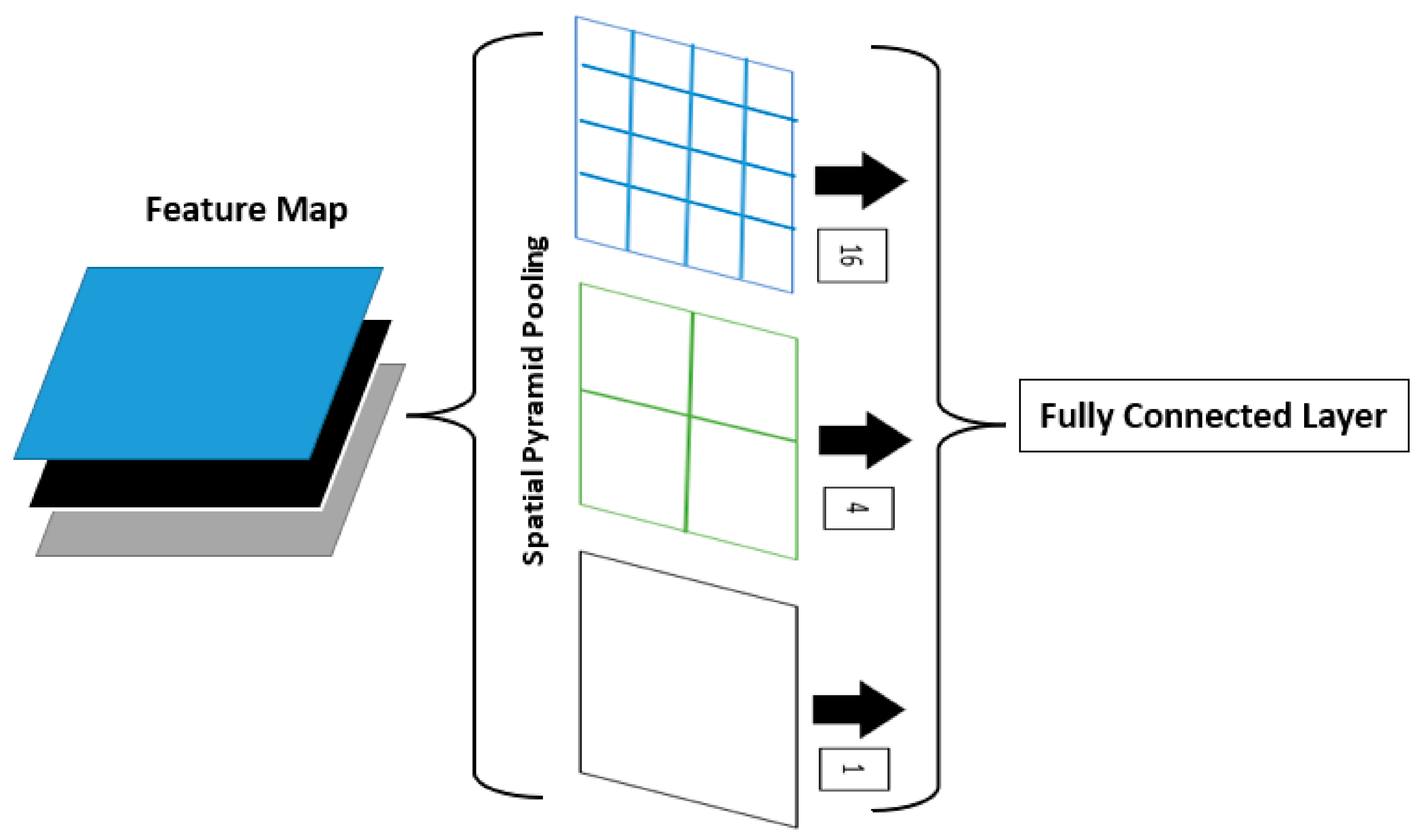
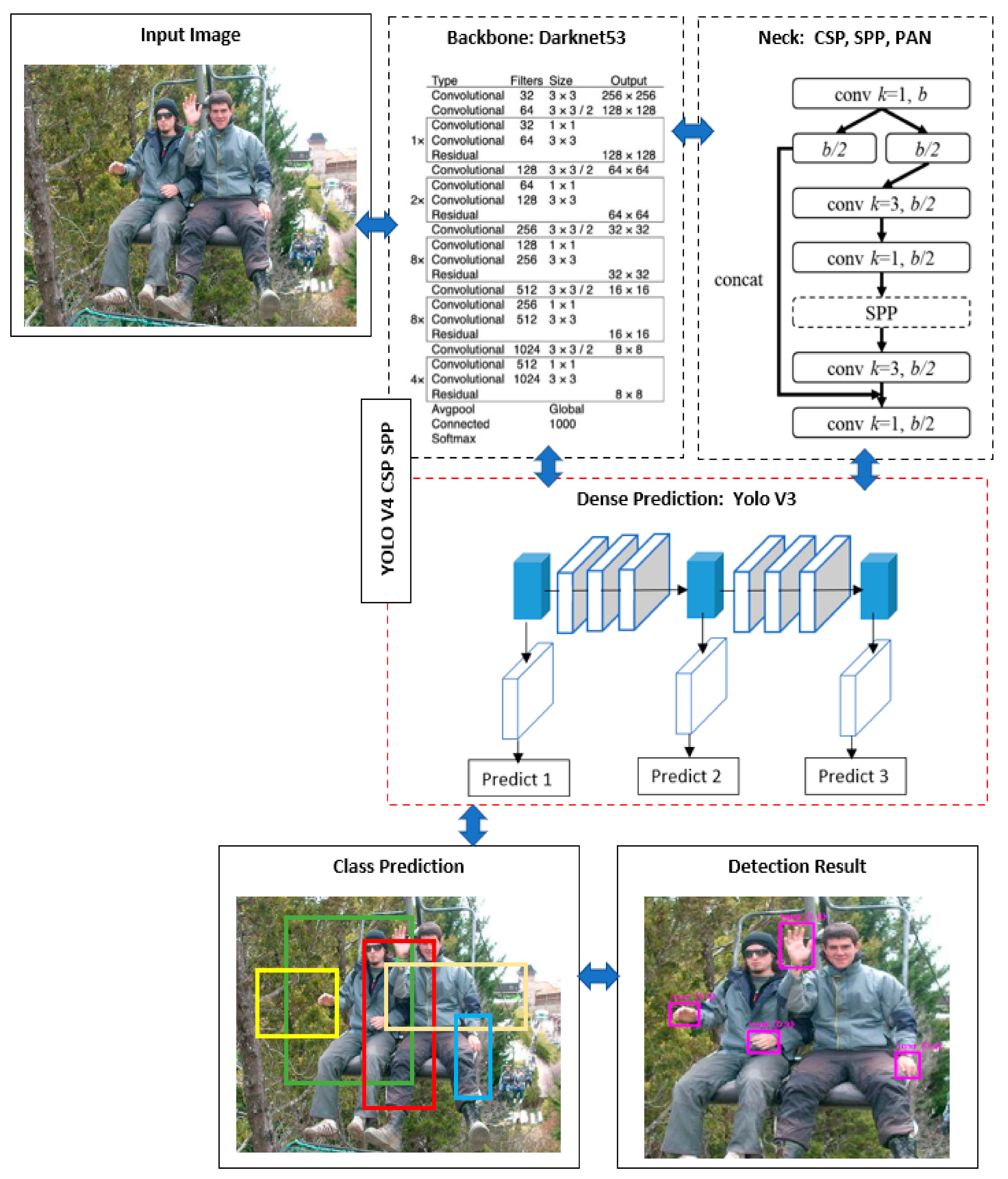
2.3. Cross-Stage Partial (CSP) Network and Spatial Pyramid Pooling (SPP)
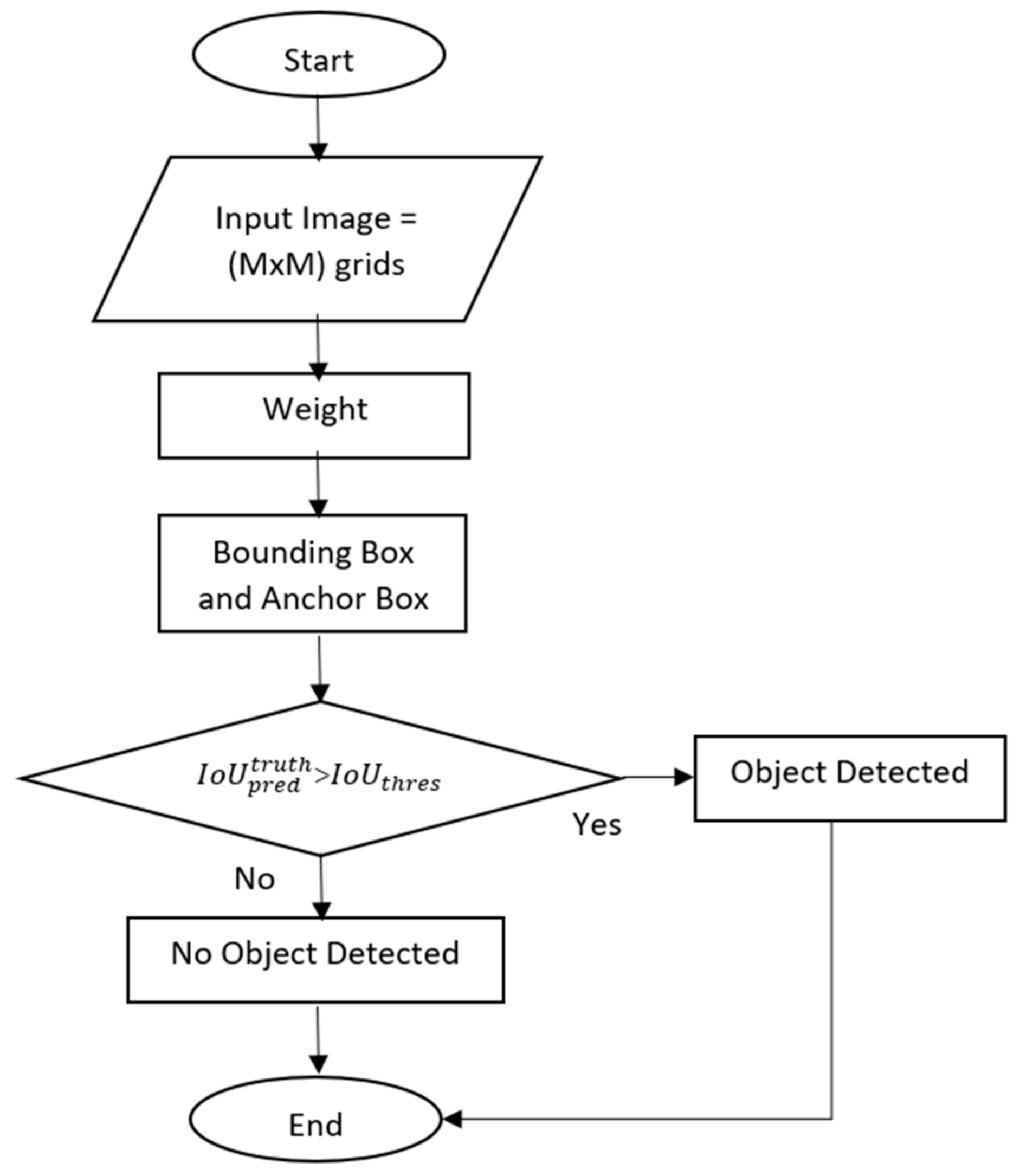
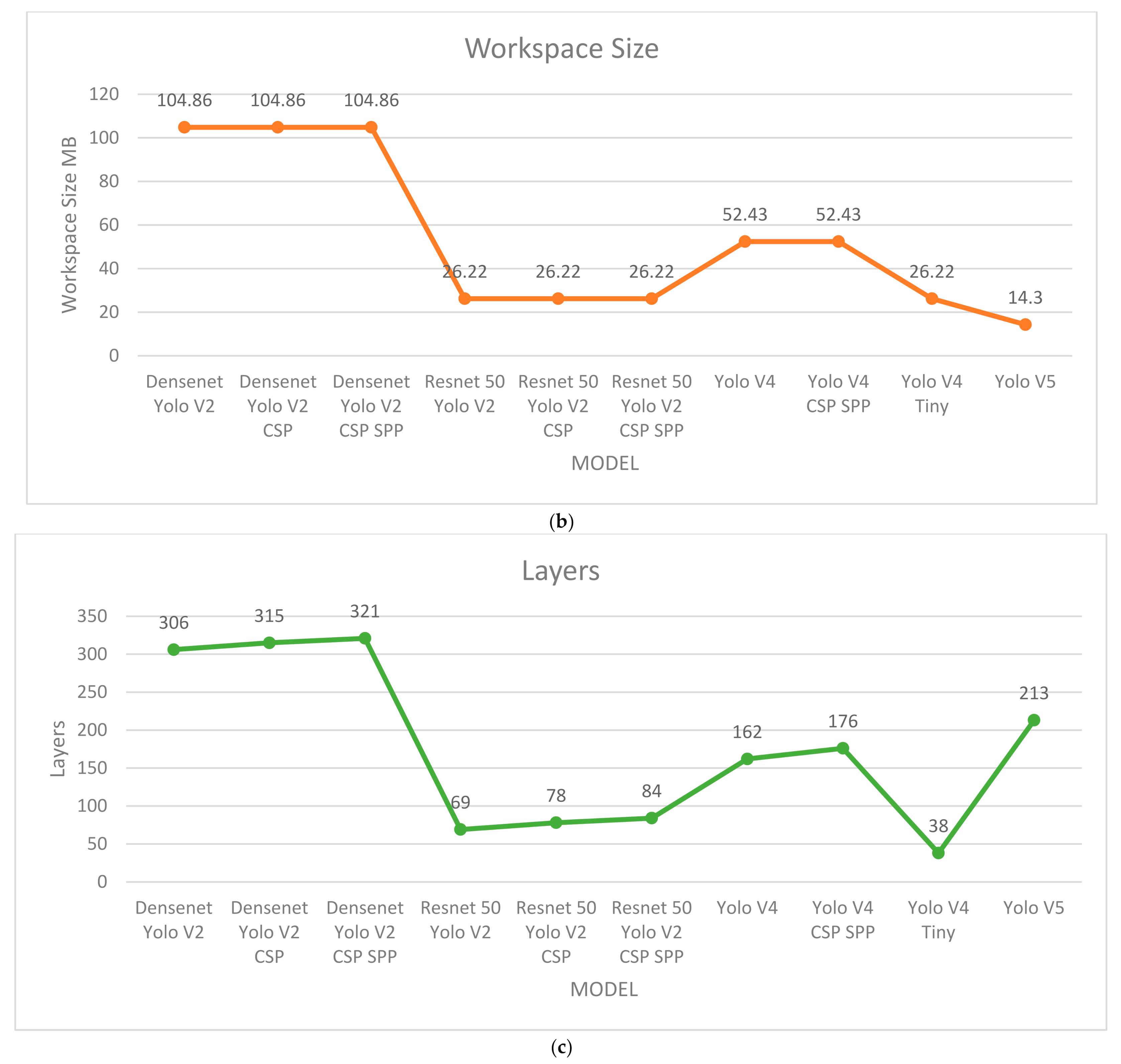
3. Methodology
| Algorithm 1. Yolo V4 CSP SPP hand detection process. |
| 1. Divide the input image data into (M × M) grids. |
| 2. For each grid, create a total of K bounding boxes with an estimate of the anchor boxes in each. |
| 3. Using CNN, extract all of the object characteristics from the image. |
| 4. Predict the and the . |
| 5. Choose the optimum confidence of the K bounding boxes with the threshold . |
| 6. If , it means that the bounding box includes the object. Otherwise, the bounding box does not contain the object. |
| 7. Choose the category that has the highest estimated likelihood of being correct. |
| 8. Non-maximum suppression (NMS) is used in conjunction with a maximum local search in order to eliminate redundant boxes and output. |
| 9. Display the output of the object detection result. |
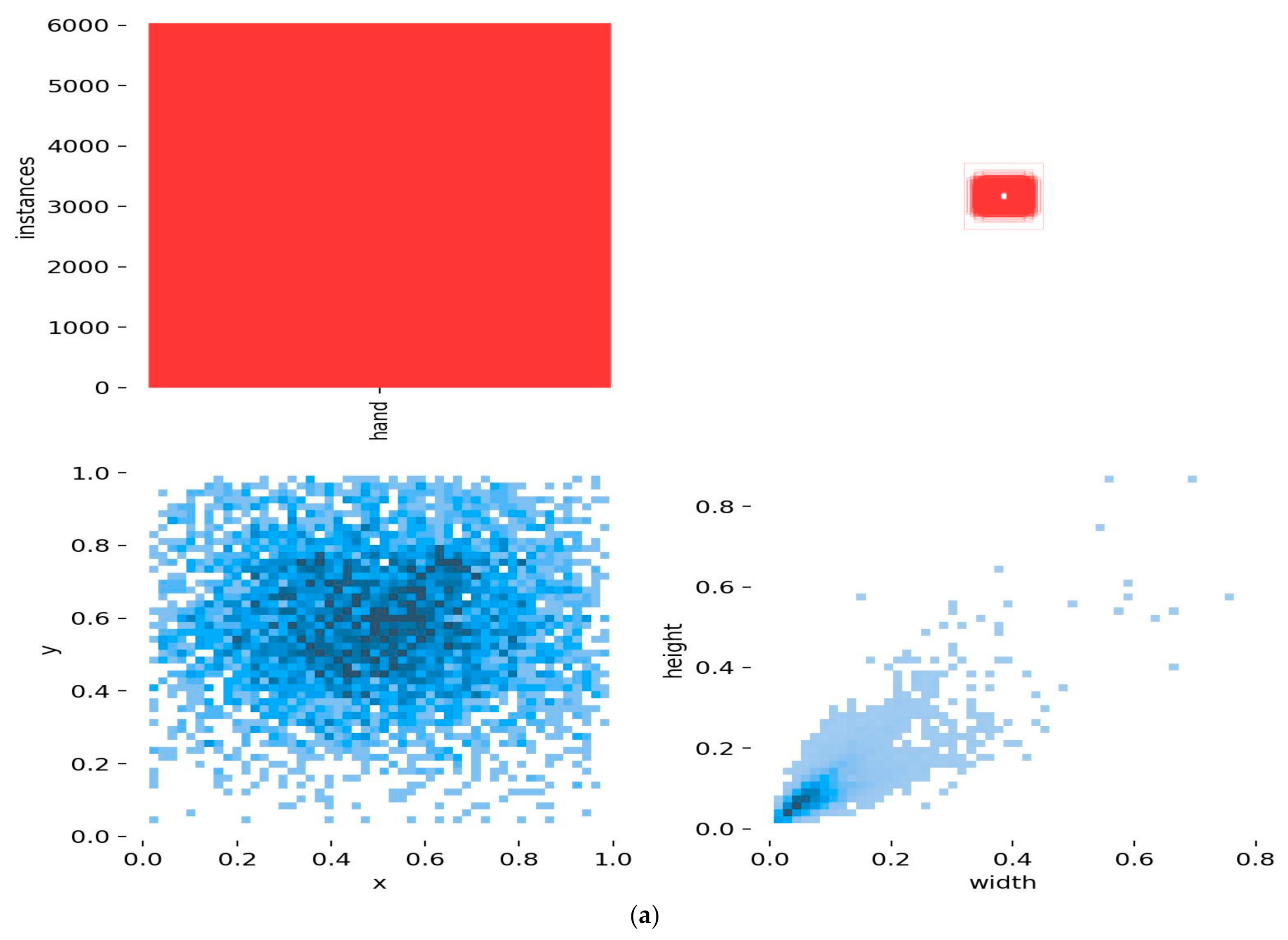
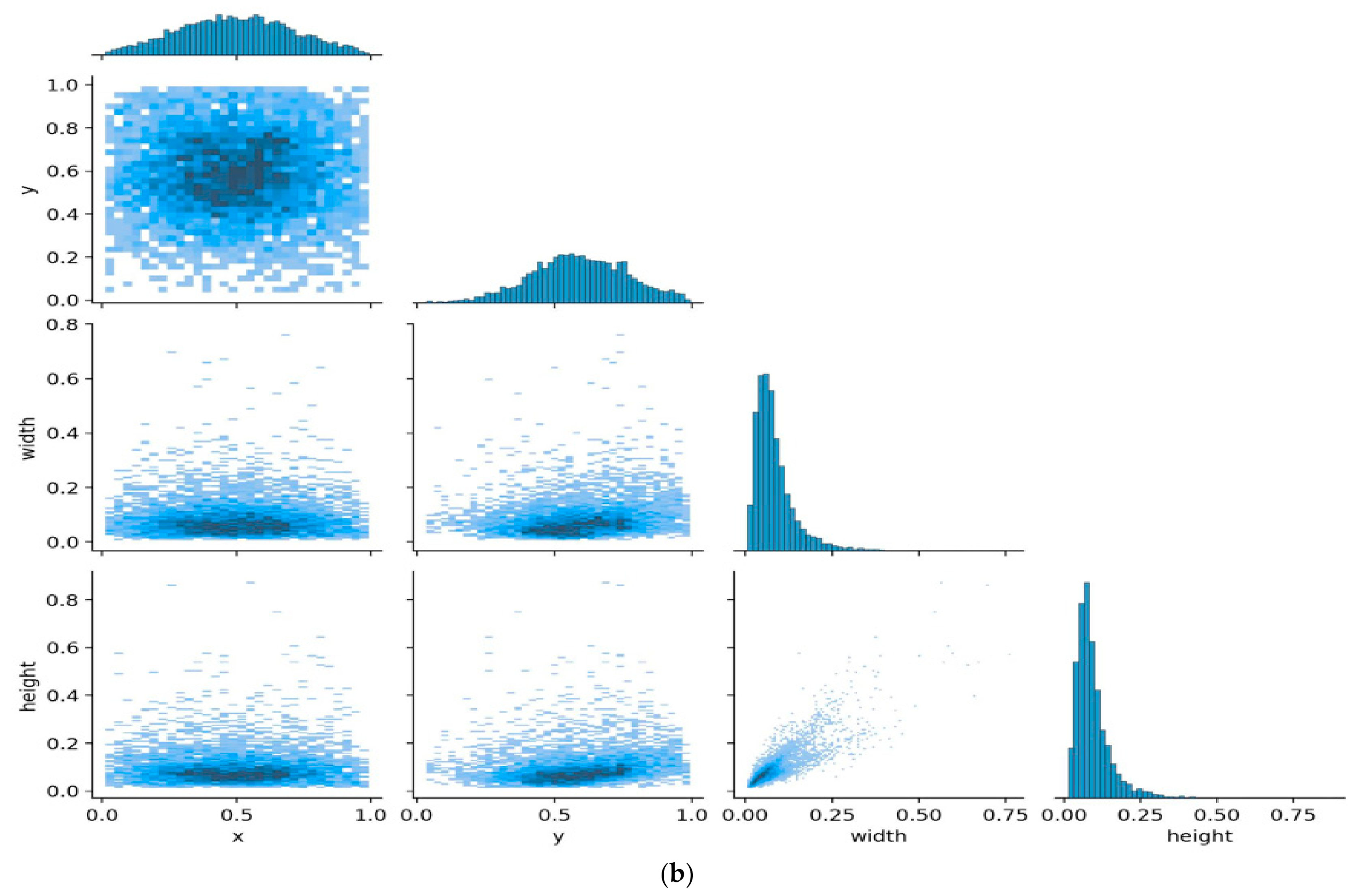
3.1. Oxford Hand Dataset
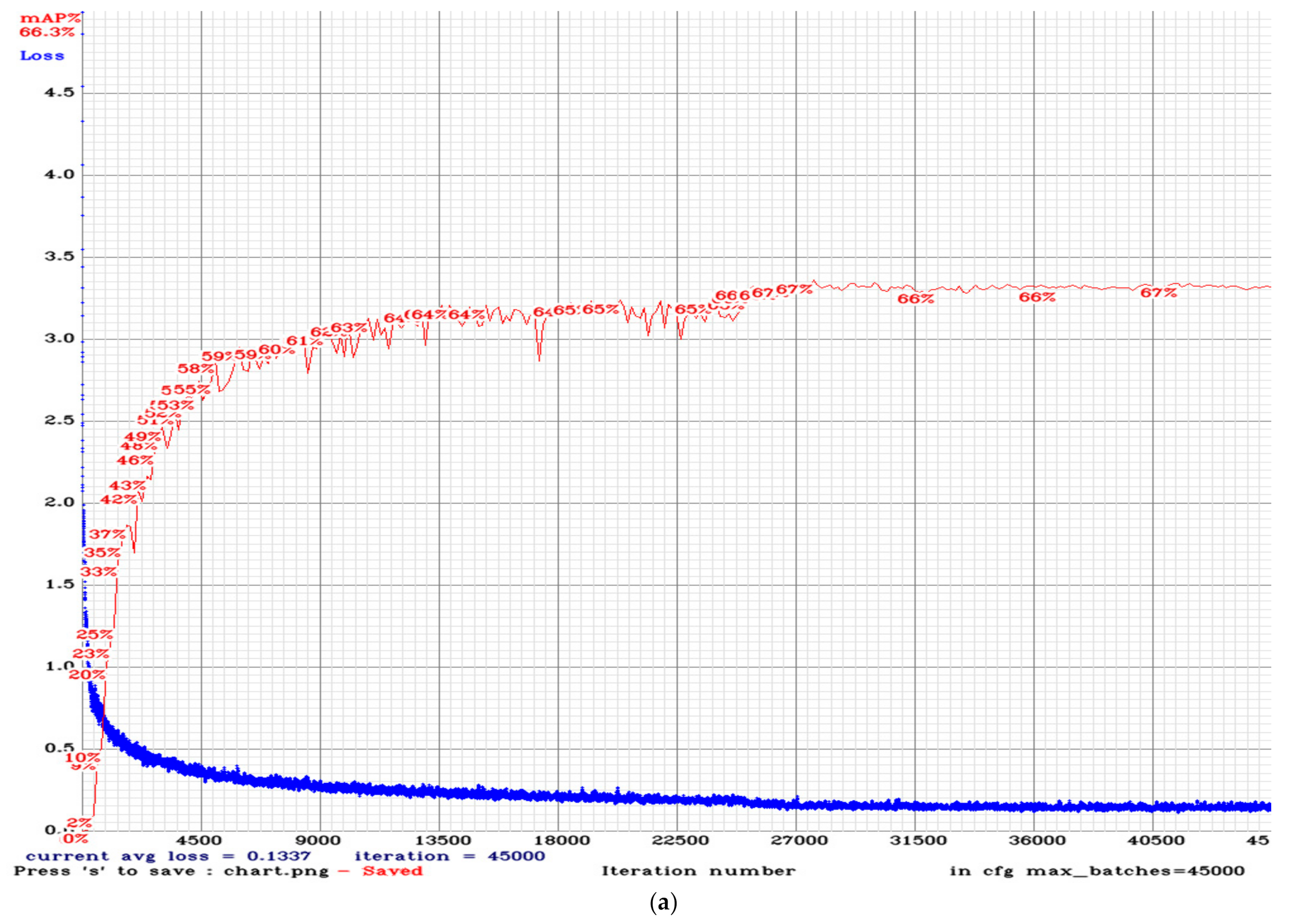
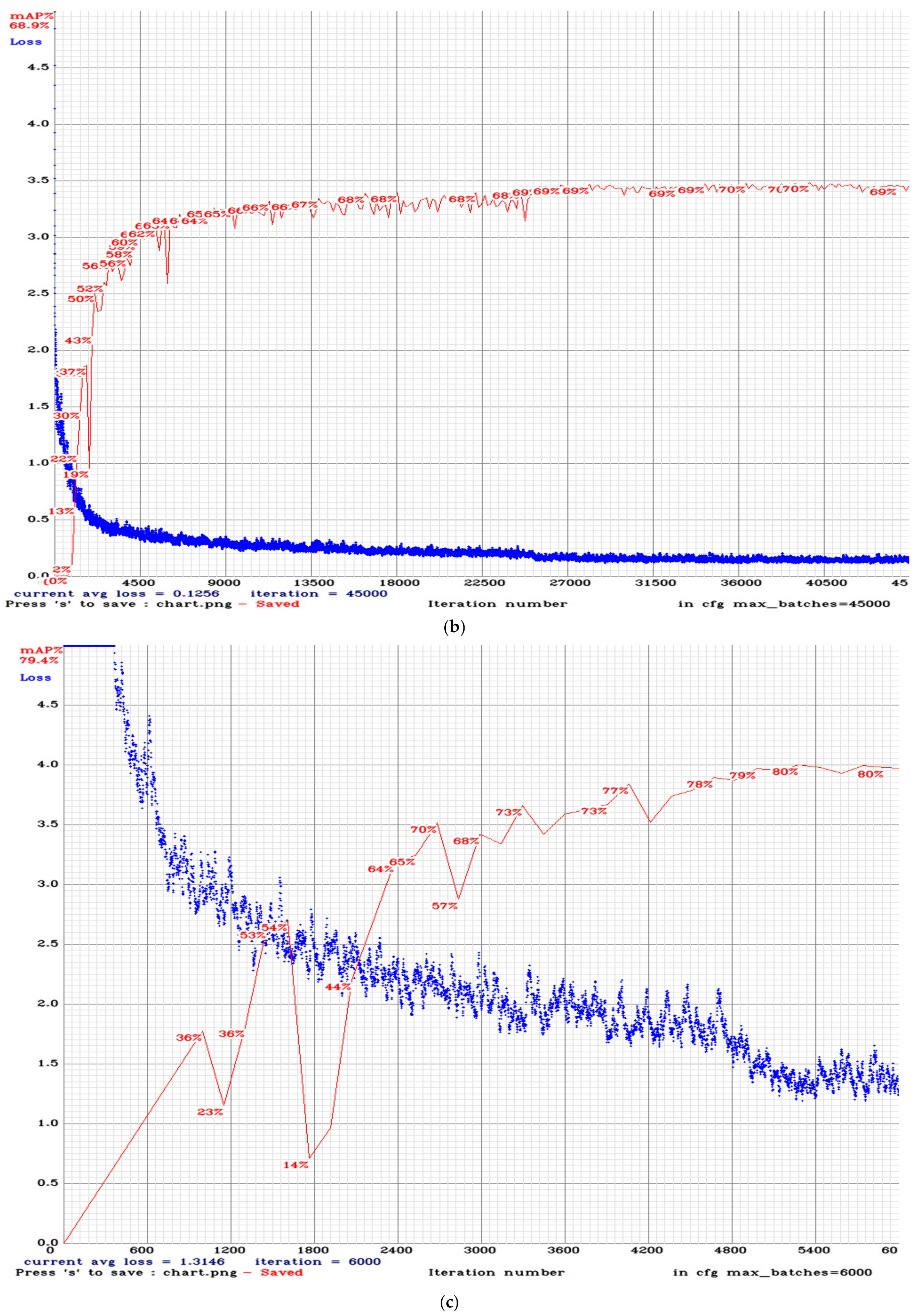
3.2. Training Result
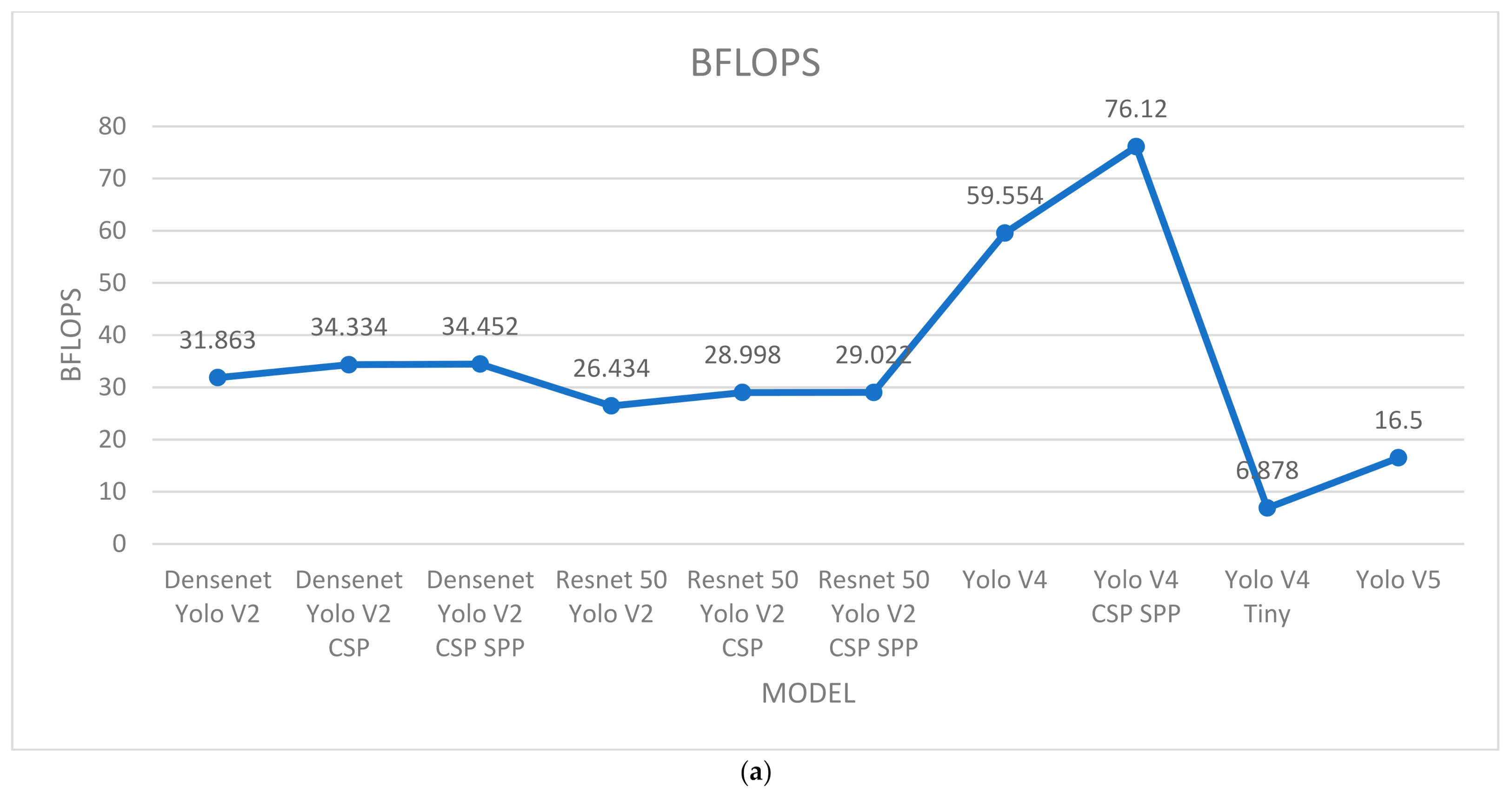
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, C.; Cai, W.; Li, Y.; Zhou, J.; Wei, L. Accurate hand detection from single-color images by reconstructing hand appearances. Sensors 2019, 20, 192. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Narasimhaswamy, S.; Wei, Z.; Wang, Y.; Zhang, J.; Nguyen, M.H. Contextual attention for hand detection in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Mohammed, A.A.Q.; Lv, J.; Islam, S. A deep learning-based end-to-end composite system for hand detection and gesture recognition. Sensors 2019, 19, 5282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adaloglou, N.; Chatzis, T.; Papastratis, I.; Stergioulas, A.; Papadopoulos, G.T.; Zacharopoulou, V.; Xydopoulos, G.J.; Atzakas, K.; Papazachariou, D.; Daras, P. A comprehensive study on deep learning-based methods for sign language recognition. IEEE Trans. Multimed. 2022, 24, 1750–1762. [Google Scholar] [CrossRef]
- Knights, E.; Mansfield, C.; Tonin, D.; Saada, J.; Smith, F.W.; Rossit, S. Hand-selective visual regions represent how to grasp 3D tools: Brain decoding during real actions. J. Neurosci. 2021, 41, 5263–5273. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Dewi, C.; Chen, R.-C.; Yu, H. Weight analysis for various prohibitory sign detection and recognition using deep learning. Multimed. Tools Appl. 2020, 79, 32897–32915. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Liu, W.; Feng, B. Deep attention network for joint hand gesture localization and recognition using static RGB-D images. Inf. Sci. 2018, 441, 66–78. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C.; Jiang, X.; Yu, H. Adjusting eye aspect ratio for strong eye blink detection based on facial landmarks. PeerJ Comput. Sci. 2022, 8, e943. [Google Scholar] [CrossRef]
- Sigal, L.; Sclaroff, S.; Athitsos, V. Skin color-based video segmentation under time-varying illumination. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 862–877. [Google Scholar] [CrossRef] [Green Version]
- Guo, J.; Cheng, J.; Pang, J.; Guo, Y. Real-time hand detection based on multi-stage HOG-SVM classifier. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013; pp. 4108–4111. [Google Scholar] [CrossRef]
- Zhao, L.; Li, S. Object detection algorithm based on improved YOLOv3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef] [Green Version]
- Dewi, C.; Chen, R.-C.; Yu, H.; Jiang, X. Robust detection method for improving small traffic sign recognition based on spatial pyramid pooling. J. Ambient Intell. Humaniz. Comput. 2021, 12, 1–18. [Google Scholar] [CrossRef]
- Mujahid, A.; Awan, M.; Yasin, A.; Mohammed, M.; Damaševičius, R.; Maskeliūnas, R.; Abdulkareem, K. Real-time hand gesture recognition based on deep learning YOLOv3 model. Appl. Sci. 2021, 11, 4164. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.C.; Liu, Y.T. Wasserstein Generative Adversarial Networks for Realistic Traffic Sign Image Generation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2021; Volume 12672, pp. 479–493. [Google Scholar] [CrossRef]
- Dardas, N.H.; Georganas, N.D. Real-time hand gesture detection and recognition using bag-of-features and support vector machine techniques. IEEE Trans. Instrum. Meas. 2011, 60, 3592–3607. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C.; Liu, Y.-T. Synthetic traffic sign image generation applying generative adversarial networks. Vietnam J. Comput. Sci. 2022, 9, 1–12. [Google Scholar] [CrossRef]
- Girondel, V.; Bonnaud, L.; Caplier, A. A human body analysis system. EURASIP J. Adv. Signal Process. 2006, 2006, 061927. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Zisserman, A.; Torr, P. Hand detection using multiple proposals. In Proceedings of the 22nd British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011. [Google Scholar] [CrossRef]
- Karlinsky, L.; Dinerstein, M.; Harari, D.; Ullman, S. The chains model for detecting parts by their context. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 25–32. [Google Scholar] [CrossRef]
- De Feudis, I.; Buongiorno, D.; Grossi, S.; Losito, G.; Brunetti, A.; Longo, N.; Di Stefano, G.; Bevilacqua, V. Evaluation of vision-based hand tool tracking methods for quality assessment and training in human-centered industry 4.0. Appl. Sci. 2022, 12, 1796. [Google Scholar] [CrossRef]
- Keskin, C.; Kiraç, F.; Kara, Y.E.; Akarun, L. Hand pose estimation and hand shape classification using multi-layered randomized decision forests. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2012; Volume 7577. [Google Scholar] [CrossRef]
- Le, T.H.N.; Quach, K.G.; Zhu, C.; Duong, C.N.; Luu, K.; Savvides, M. Robust hand detection and classification in vehicles and in the wild. In Proceedings of the 2017 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Gao, Q.; Liu, J.; Ju, Z. Robust real-time hand detection and localization for space human–robot interaction based on deep learning. Neurocomputing 2019, 390, 198–206. [Google Scholar] [CrossRef]
- Ashiquzzaman, A.; Lee, H.; Kim, K.; Kim, H.-Y.; Park, J.; Kim, J. Compact spatial pyramid pooling deep convolutional neural network based hand gestures decoder. Appl. Sci. 2020, 10, 7898. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C.; Liu, Y.-T.; Yu, H. Various generative adversarial networks model for synthetic prohibitory sign image generation. Appl. Sci. 2021, 11, 2913. [Google Scholar] [CrossRef]
- Huang, L.; Pun, C.M. Audio replay spoof attack detection using segment-based hybrid feature and densenet-lstm network. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 2567–2571. [Google Scholar] [CrossRef]
- Yu, C.; He, X.; Ma, H.; Qi, X.; Lu, J.; Zhao, Y. S-DenseNet: A densenet compression model based on convolution grouping strategy using skyline method. IEEE Access 2019, 7, 183604–183613. [Google Scholar] [CrossRef]
- Zhang, K.; Guo, Y.; Wang, X.; Yuan, J.; Ding, Q. Multiple feature reweight densenet for image classification. IEEE Access 2019, 7, 9872–9880. [Google Scholar] [CrossRef]
- Ghatwary, N.; Ye, X.; Zolgharni, M. Esophageal abnormality detection using densenet based faster r-cnn with gabor features. IEEE Access 2019, 7, 84374–84385. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C. Human activity recognition based on evolution of features selection and random forest. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 2496–2501. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Chander, G.; Markham, B.L.; Helder, D.L. Summary of current radiometric calibration coefficients for Landsat MSS, TM, ETM+, and EO-1 ALI sensors. Remote Sens. Environ. 2009, 113, 893–903. [Google Scholar] [CrossRef]
- Fang, W.; Wang, C.; Chen, X.; Wan, W.; Li, H.; Zhu, S.; Fang, Y.; Liu, B.; Hong, Y. Recognizing global reservoirs from landsat 8 images: A deep learning approach. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3168–3177. [Google Scholar] [CrossRef]
- Sundar, K.V.S.; Bonta, L.R.; Reddy, A.K.B.; Baruah, P.K.; Sankara, S.S. Evaluating training time of Inception-v3 and resnet-50,101 models using TensorFlow across CPU and GPU. In Proceedings of the 2nd International Conference on Electronics, Communication and Aerospace Technology, Coimbatore, India, 29–31 March 2018; pp. 1964–1968. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-J.M. YOLOv4 optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. Available online: https://arxiv.org/abs/2004.10934 (accessed on 8 December 2020).
- Wang, C.; Liao, H.M.; Wu, Y.; Chen, P. CSPNet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR Workshop), Seattle, WA, USA, 14–19 June 2020; p. 2. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. Available online: http://arxiv.org/abs/1804.02767 (accessed on 25 August 2020).
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.086811. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13024–13033. [Google Scholar] [CrossRef]
- van de Sande, K.E.A.; Uijlings, J.R.R.; Gevers, T.; Smeulders, A.W.M. GoogLeNet going deeper with convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C.; Jiang, X.; Yu, H. Deep convolutional neural network for enhancing traffic sign recognition developed on Yolo V4. Multimed. Tools Appl. 2022, 81, 1–25. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C.; Liu, Y.-T.; Jiang, X.; Hartomo, K.D. Yolo V4 for Advanced Traffic Sign Recognition With Synthetic Training Data Generated by Various GAN. IEEE Access 2021, 9, 97228–97242. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C.; Liu, Y.-T.; Tai, S.-K. Synthetic Data generation using DCGAN for improved traffic sign recognition. Neural Comput. Appl. 2021, 33, 1–15. [Google Scholar] [CrossRef]
- Grauman, K.; Darrell, T. The pyramid match kernel: Discriminative classification with sets of image features. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; pp. 1458–1465. [Google Scholar] [CrossRef] [Green Version]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Dewi, C.; Chen, R.-C.; Tai, S.-K. Evaluation of robust spatial pyramid pooling based on convolutional neural network for traffic sign recognition system. Electronics 2020, 9, 889. [Google Scholar] [CrossRef]
- Lu, X.; Wang, B.; Zheng, X. Sound active attention framework for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2019, 58, 1985–2000. [Google Scholar] [CrossRef]
- Bbox Label Tool. Available online: https://github.com/puzzledqs/BBox-Label-Tool (accessed on 10 January 2019).
- Mao, Q.-C.; Sun, H.-M.; Liu, Y.-B.; Jia, R.-S. Mini-YOLOv3: Real-Time Object Detector for Embedded Applications. IEEE Access 2019, 7, 133529–133538. [Google Scholar] [CrossRef]
- Xu, Q.; Lin, R.; Yue, H.; Huang, H.; Yang, Y.; Yao, Z. Research on Small Target Detection in Driving Scenarios Based on Improved Yolo Network. IEEE Access 2020, 8, 27574–27583. [Google Scholar] [CrossRef]
- Wu, F.; Jin, G.; Gao, M.; He, Z.; Yang, Y. Helmet detection based on improved YOLO V3 deep model. In Proceedings of the 2019 IEEE 16th International Conference on Networking, Sensing and Control ICNSC, Banff, AB, Canada, 9–11 May 2019; pp. 363–368. [Google Scholar] [CrossRef]
- Yang, H.; Chen, L.; Chen, M.; Ma, Z.; Deng, F.; Li, M.; Li, X. Tender tea shoots recognition and positioning for picking robot using improved YOLO-V3 model. IEEE Access 2019, 7, 180998–181011. [Google Scholar] [CrossRef]
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting Critical Features for Data Classification Based on Machine Learning Methods. J. Big Data 2020, 7, 1–26. [Google Scholar] [CrossRef]
- Yuan, Y.; Xiong, Z.; Wang, Q. an incremental framework for video-based traffic sign detection, tracking, and recognition. IEEE Trans. Intell. Transp. Syst. 2016, 18, 1918–1929. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Shi, R.; Li, T.; Yamaguchi, Y. An attribution-based pruning method for real-time mango detection with YOLO network. Comput. Electron. Agric. 2020, 169, 105214. [Google Scholar] [CrossRef]
- Kang, H.; Chen, C. Fast implementation of real-time fruit detection in apple orchards using deep learning. Comput. Electron. Agric. 2019, 168, 105108. [Google Scholar] [CrossRef]
- Yang, L.; Qi, Z.; Liu, Z.; Liu, H.; Ling, M.; Shi, L.; Liu, X. An embedded implementation of CNN-based hand detection and orientation estimation algorithm. Mach. Vis. Appl. 2019, 30, 1071–1082. [Google Scholar] [CrossRef]
- Deng, X.; Zhang, Y.; Yang, S.; Tan, P.; Chang, L.; Yuan, Y.; Wang, H. Joint Hand Detection and Rotation Estimation Using CNN. IEEE Trans. Image Process. 2017, 27, 1888–1900. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | CSP | SPP |
|---|---|---|
| Densenet Yolo V2 | ||
| Densenet Yolo V2 CSP | X | |
| Densenet Yolo V2 CSP SPP | X | X |
| Resnet 50 Yolo V2 | ||
| Resnet 50 Yolo V2 CSP | X | |
| Resnet 50 Yolo V2 CSP SPP | X | X |
| Yolo V4 SPP | X | |
| Yolo V4 CSP SPP | X | X |
| Yolo V5 | X | X |
| Model | Precision | Recall | F1-Score | IoU (%) | mAP@0.50 (%) |
|---|---|---|---|---|---|
| Densenet Yolo V2 | 0.68 | 0.68 | 0.68 | 49.16 | 65.65 |
| Densenet Yolo V2 CSP | 0.71 | 0.68 | 0.69 | 50.98 | 66.82 |
| Densenet Yolo V2 CSP SPP | 0.7 | 0.68 | 0.69 | 49.96 | 67.19 |
| Resnet 50 Yolo V2 | 0.68 | 0.57 | 0.62 | 46.62 | 54.4 |
| Resnet 50 Yolo V2 CSP | 0.68 | 0.58 | 0.63 | 47.22 | 56.51 |
| Resnet 50 Yolo V2 CSP SPP | 0.67 | 0.63 | 0.65 | 47.19 | 60.99 |
| Yolo V4 | 0.83 | 0.78 | 0.81 | 62.11 | 81.5 |
| Yolo V4 CSP SPP | 0.82 | 0.76 | 0.79 | 61.36 | 82.13 |
| Yolo V4 Tiny | 0.82 | 0.46 | 0.59 | 59.2 | 56.71 |
| Yolo V5 | 0.84 | 0.74 | 0.79 | 64.85 | 82.7 |
| Model | Precision | Recall | F1-Score | IoU (%) | AP@0.50 (%) |
|---|---|---|---|---|---|
| Densenet Yolo V2 | 0.9 | 0.91 | 0.91 | 70.91 | 90.19 |
| Densenet Yolo V2 CSP | 0.9 | 0.9 | 0.9 | 69.44 | 90.45 |
| Densenet Yolo V2 CSP SPP | 0.91 | 0.91 | 0.91 | 70.86 | 91.27 |
| Resnet 50 Yolo V2 | 0.84 | 0.82 | 0.83 | 59.96 | 82.25 |
| Resnet 50 Yolo V2 CSP | 0.83 | 0.82 | 0.83 | 59.64 | 83.01 |
| Resnet 50 Yolo V2 CSP SPP | 0.84 | 0.86 | 0.85 | 62.49 | 86.53 |
| Yolo V4 | 0.9 | 0.92 | 0.91 | 69.8 | 92.99 |
| Yolo V4 CSP SPP | 0.92 | 0.95 | 0.94 | 72.34 | 96.48 |
| Yolo V4 Tiny | 0.89 | 0.57 | 0.7 | 66.14 | 70.17 |
| Yolo V5 | 0.83 | 0.77 | 0.80 | 66.51 | 84.4 |
| Author | Model | AP@0.50 (%) |
|---|---|---|
| Mittal et al. [19] | Multi Proposal with NMS | 48.2 |
| Deng et al. [62] | RPN and Rotation Estimation | 58.1 |
| Le et al. [23] | MS-RFCN | 75.1 |
| Narasimhaswamy et al. [2] | Hand-CNN | 78.8 |
| Yang et al. [61] | SSD Hand | 83.2 |
| Xu et al. [1] | Hybrid Detection with GAN | 87.6 |
| Our method | Yolo V4 CSP SPP | 96.48 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dewi, C.; Juli Christanto, H. Combination of Deep Cross-Stage Partial Network and Spatial Pyramid Pooling for Automatic Hand Detection. Big Data Cogn. Comput. 2022, 6, 85. https://doi.org/10.3390/bdcc6030085
Dewi C, Juli Christanto H. Combination of Deep Cross-Stage Partial Network and Spatial Pyramid Pooling for Automatic Hand Detection. Big Data and Cognitive Computing. 2022; 6(3):85. https://doi.org/10.3390/bdcc6030085
Chicago/Turabian StyleDewi, Christine, and Henoch Juli Christanto. 2022. "Combination of Deep Cross-Stage Partial Network and Spatial Pyramid Pooling for Automatic Hand Detection" Big Data and Cognitive Computing 6, no. 3: 85. https://doi.org/10.3390/bdcc6030085