1. Introduction
Twitter (
http://twitter.com, accessed on 23 May 2022) is one of the most popular social media sites in the world, with approximately 330 million monthly active users [
1] and over 500 million daily tweets [
2]. Twitter provides an application programming interface (API)
https://developer.twitter.com/en/docs/twitter-api (accessed on 17 May 2022) enables the collection of data from the site using its web service. With the help of Twitter API, tweet data can be analyzed for various tasks and applications, including sentiment and stance analysis [
3,
4,
5,
6,
7,
8], hate speech and misinformation detection [
9,
10,
11,
12,
13,
14], traffic monitoring [
15,
16,
17], disaster management [
18,
19,
20], and disease outbreak control [
21,
22].
In many applications, extracting information from tweet contents needs to be complemented with location analysis. For example, with user geolocation data, the government can detect the location where fake news [
23] or disease outbreak [
24] spreads. Location-based sentiment analysis can predict election results at regional-level granularity [
25,
26] or learn the demographics of candidate supporters to support political campaigns in Presidential elections [
27].
Despite the necessity of such location data, the majority of Twitter users do not provide geolocation information in their profiles or tweets. Even when a user includes location information in their profile, it may not be accurate as they can fill it in arbitrarily. In a random sampling of over one million Twitter users, Cheng et al. [
28] found that only 26% included location data in their profile, and only 0.42% of tweets in the sample were geotagged. Therefore, other information in users’ profiles and tweets is necessary to infer their location.
Geolocation prediction has mainly been performed for English-language tweets. As far as we know, the study of geolocation prediction using Indonesian tweets is still relatively rare. Cheng et al. [
28] made geolocation predictions in 2010 by sampling about one million Twitter users in the US. Roller et al. [
29] used US Twitter data from 450,000 users for geolocation prediction for North America in 2012. Han et al. [
30] provided Twitter-world (a dataset of around 12 million English tweets from users around the world. There are 10,000 each for development and testing, and users are geotagged with the center of the closest city to their tweets) geolocation prediction data for 1.3 million users, specifically for English-language tweets, in various cities worldwide. At the 2016 Workshop on Noisy User-Generated Text (WNUT), Han et al. [
31] provided data for tweets specifically in English for one million users in 3362 cities in different countries, including Indonesia.
Indonesia is expected to have around 17.55 million Twitter users by 2022 [
32]. This places Indonesia in the sixth place among countries with the highest number of Twitter users. Although Indonesian-language Twitter resources are plentiful, only limited work has explored location analysis of Indonesian Twitter users. Han et al. [
33] applied geolocation prediction for multilingual environments, including Indonesian tweets, in the WORLD+ML dataset. They used the information gain ratio method and machine learning to measure the entropy of local words in a city. Izbicki et al. [
34] also applied a multilingual setting that included tweets in Indonesian. They proposed a deep learning model, unicodeCNN, to predict geolocation. In contrast to these previous studies, in our work, we performed location prediction using tweets written by users in Indonesia; therefore, our study is generally specific to Indonesian-language tweets. We then implemented a pretrained bidirectional encoder representations from transformers (BERT) language model to predict geolocation, adopting an approach used by Qian et al. [
35] for Chinese tweets and Scherrer et al. [
36] for Helsinki–Ljubljana tweets.
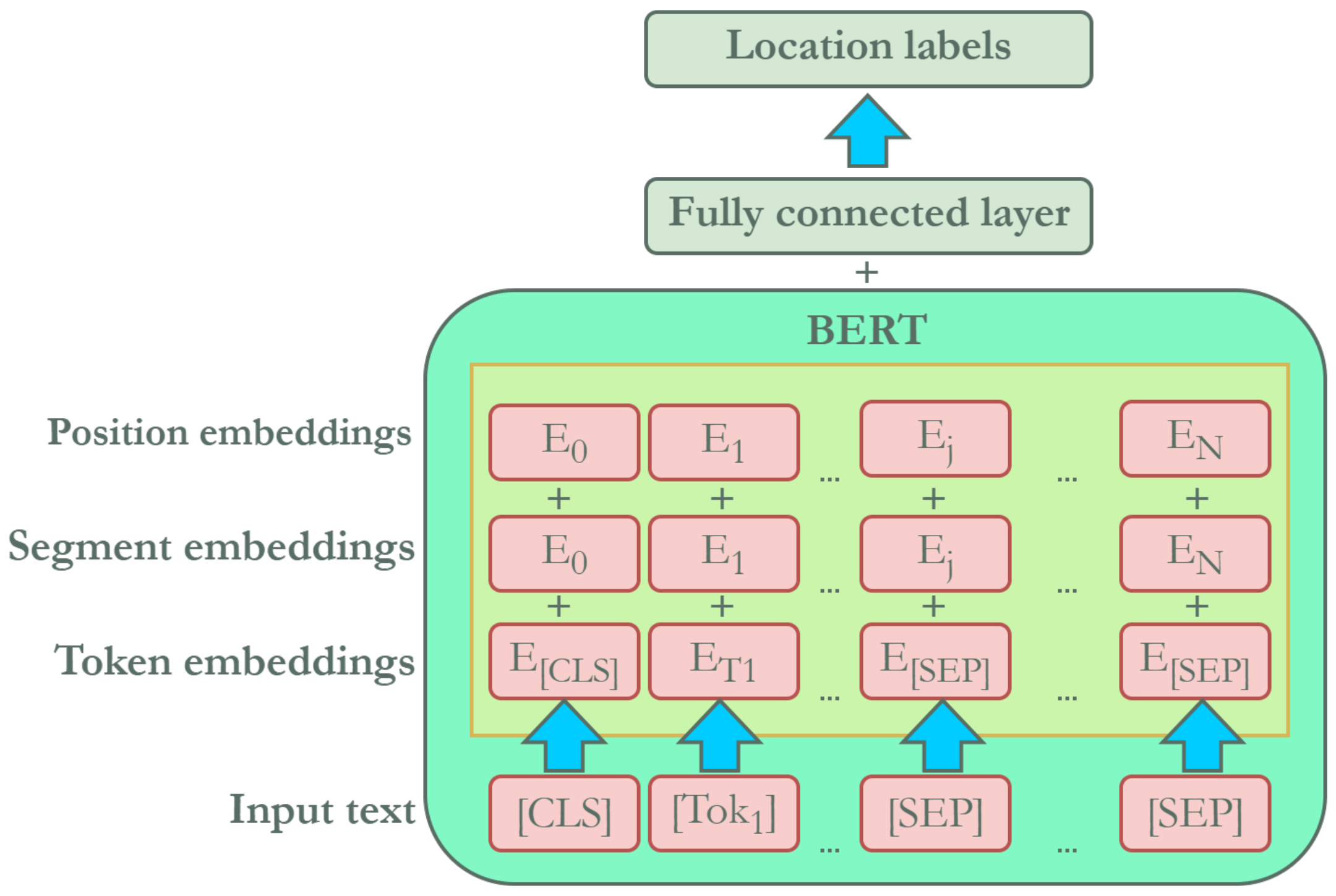
This study examined text in user profiles and tweets to predict users’ locations using a transformer-based language model, i.e., BERT. Hence, we formulate this task as text classification, as in [
33,
37]. BERT is the current state-of-the-art for many natural language processing (NLP) tasks. The fine-tuning of pretrained BERT, with its capability to model bidirectional contexts and attention mechanisms, achieves better performance for many downstream NLP tasks, including text classifications, as shown by Devlin et al. [
38]. Willie et al. [
39] and Koto et al. [
40] trained two different versions of BERT on Indonesian corpus, called IndoBERT, specifically for Indonesian language. IndoBERT by Willie et al. was trained on around 4 billion Indonesian corpora (Indo 4B) collected from 12 publicly available corpora covering formal and colloquial languages. IndoBERT by Koto et al. was trained on 219M Indonesian words from Wikipedia, news articles, and the Web Corpus. Both studies showed state-of-the-art performance of IndoBERT with various Indonesian-language NLP tasks such as morpho-syntax and sequence labeling, semantic tasks, text classification, and discourse analysis. Continuing their work, Koto et al. also trained BERT specifically for Indonesian-language Twitter data with a total of 409 million tokens, called IndoBERTweet [
41].
Our study makes the following contributions: (1) we predict the location of Twitter users specific to Indonesian regions using pretrained BERT language models; and (2) our empirical results show that the BERT model is more accurate in location prediction than some machine learning models and another deep learning model. We release the code and model at
https://github.com/ir-nlp-csui/indotwitterlocation (accessed on 17 May 2022).
2. Related Work
In recent years, many researchers have studied the problem of location prediction, especially with Twitter data. Cheng et al. [
28] applied the content-based user location estimation algorithm to estimate a user’s city location based on their tweets as a baseline. They succeeded in obtaining an accuracy of 0.51 in predicting home location at the city level by adding a local-word-filtering method and performing neighborhood smoothing on word probabilities. Hecht et al. [
42] used naïve Bayes to identify a user’s home country and home state. For each tweet in the corpus, they used the Calgari algorithm to calculate the weighted terms associated with the location. Their experiment gained an accuracy of 0.89 for the country level and 0.31 for the US state level.
Rahimi et al. [
43] used a bag of word unigrams and term frequency, inverse document frequency (TF-IDF) weighting for both words and mentions, followed by l2-normalization of each tweet. They then used logistic regression to classify the data and obtained an accuracy of 0.64 on the Twitter-world data. Indira et al. [
37] extracted more than 1000 tweets containing geolocation to predict the user’s location in three different cities. This information was combined with the user’s name, screen name, and the mentioned locations in the tweet to make predictions using naïve Bayes, support vector machine, and decision tree techniques. They found that the decision tree algorithm could obtain an accuracy of 99.96.
In addition to using machine learning, several researchers have used deep learning techniques to predict location. Rahimi et al. [
44] used a multilayer perceptron with one hidden layer to classify user location. They did not consider @-mentions, words with a document frequency of less than 10, or stop words. The use of k-means discretization of the real-valued coordinates of the training location as the output provided an accuracy of 0.36 for the Twitter-world data. Miura et al. [
45] trained a neural network to predict city-level geolocations on WNUT Twitter data. They employed pretrained word embeddings that used text, location, and description fields with a skip-gram algorithm and obtained an accuracy of 0.47 with a median error distance of 16.13 km in user-level prediction. Continuing their previous work, they proposed a more sophisticated model by sorting user messages chronologically and applying an RNN sequential model to encode the tweets, profile description, and time zone [
46]. The combination of the three features was then passed to the softmax layer to predict the home location at the city level.
Similar to Rahimi et al. [
43], we also use word unigram and TF-IDF to predict each tweet location using machine learning. However, unlike their study, which used text and network context, this study used only text information, i.e., tweets, display name, and user description, to predict user location. Indira et al. [
37] predicted location at the tweet level; they stored only tweets that mentioned location. In contrast, in this study, we predicted the location at the user level and stored tweets even if they did not mention the location to obtain real-world conditions. In contrast to the work of Hecht et al. [
42] that used the Calgari algorithm to weight terms related to location, our study used named-entity recognition (NER) to assign weights to each tweet. Each entity (such as a person, organization, or location), which could be associated with a particular location, extracted from each tweet was duplicated and used as a feature in the inference process. To our knowledge, we are first to apply BERT fine-tuning to infer the location of Twitter users in Indonesia.
3. Problem Formulation
According to Zheng et al. [
47], the location of Twitter users can be categorized into home location, tweet location, and mentioned location, as illustrated in
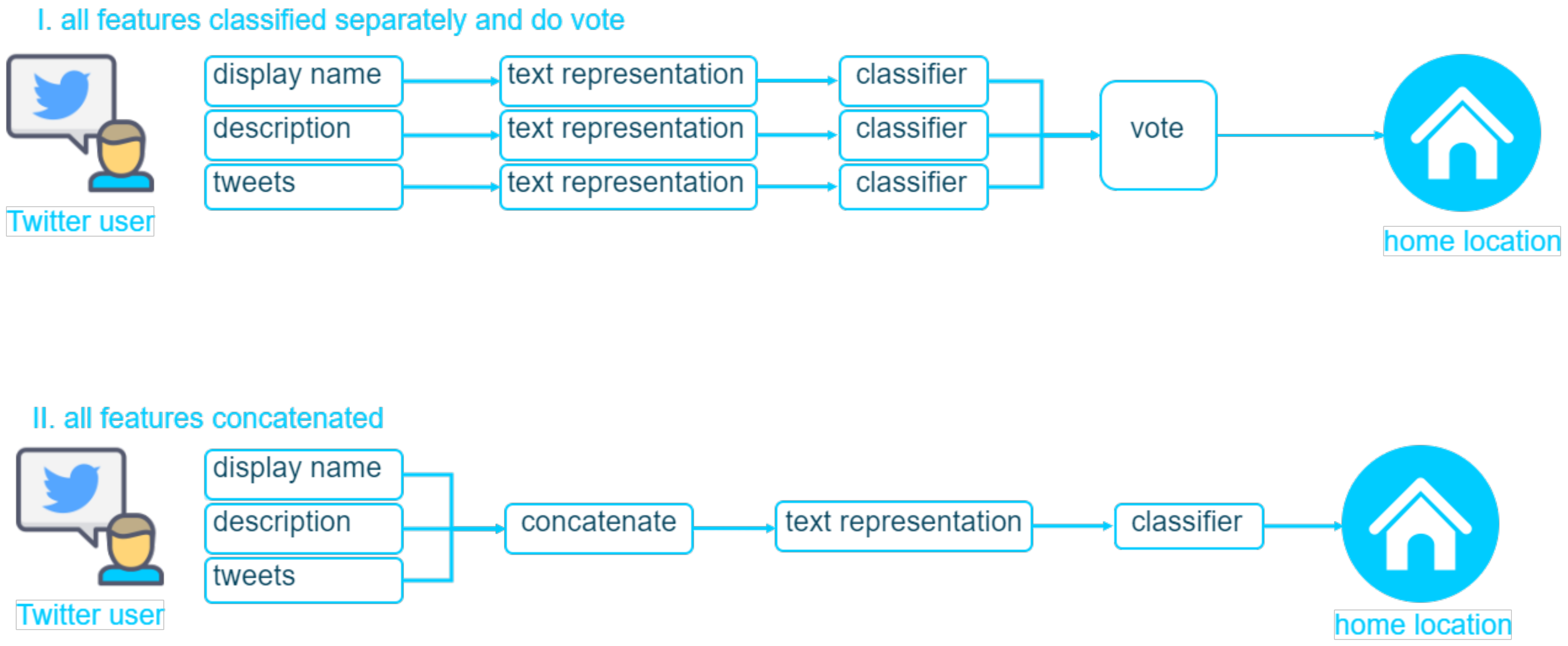
Figure 1. The aim of this study was to predict the home location of Twitter users with the aid of text attributes in their profiles and tweets (
Figure 2). The text attributes we used were limited to the display name, user description, and their tweets. The display name is the name given by the user to their profile and is limited to 1–50 characters. It can be any name; it does not have to be the user’s real name. The user description is the string that the user defines to describe their account. It has a maximum length of 160 characters and can simply be omitted. Tweets are messages posted by users on their timeline and can be in the form of text, photos, gifs, and videos. The maximum length of a tweet is 280 characters.
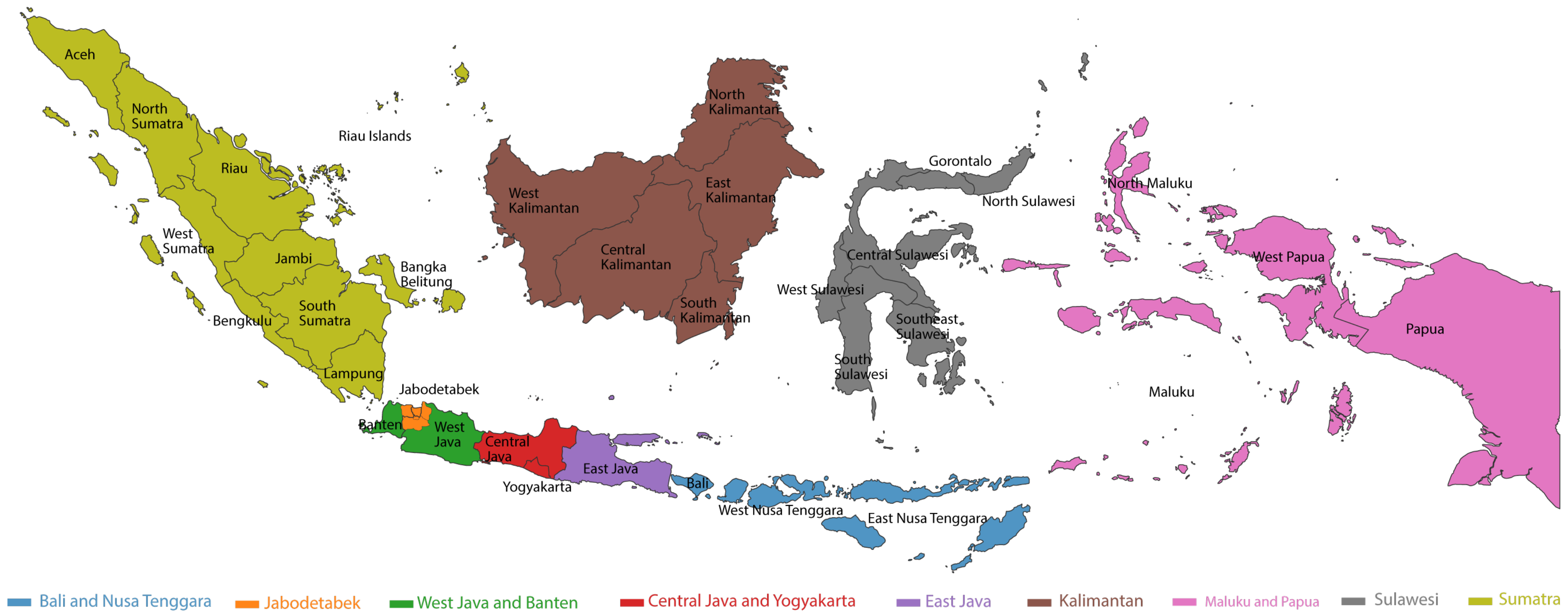
We grouped the home locations of all users into nine regions based on the geographical characteristics of Indonesia. Indonesia has five large islands: Java, Kalimantan, Sumatra, Sulawesi, and Papua. Almost all Indonesian provinces are located on these islands, except for a few geographically separated provinces. The island of Sumatra has two separate provinces. However, there are no differences between these provinces and the main islands in geography and time zone. To the east of Java island are the Nusa Tenggara islands, which comprise the provinces of Bali, West Nusa Tenggara, and East Nusa Tenggara. Geographically and in terms of time zone, these islands have unique characteristics compared to the island of Java. Therefore, we grouped these islands into one distinct region. To the west of the island of Papua are the provinces of Maluku and North Maluku, which are also islands separate from the five big islands. However, we grouped the Maluku islands with the Maluku and Papua region because these islands do not differ from Papua in terms of geography and time zone. Consequently, at this stage, there were six categories of region.
Java is the most populous island in Indonesia. Although in area it is only about seven percent of the entire territory of Indonesia, Java is inhabited by 151.59 million people, or 56.10 percent of Indonesia’s population [
48]. It has six provinces, i.e., West Java, Banten, DKI Jakarta, Central Java, Yogyakarta, and East Java. DKI Jakarta, which includes the capital city of Indonesia and several cities in the province of West Java and Banten, forms a megalopolitan area and Indonesia’s business and economic center. Consequently, we considered it to be a distinct region. We then combined all regions in West Java and Banten not included in this megalopolitan area into one separate region. Technically, Yogyakarta Province is a city with about 10 percent of the total population of Central Java [
48], and geographically, it is only bordered by Central Java Province; therefore, we combined Central Java and Yogyakarta into a separate region. Thus, the four regional categories of this island were Jabodetabek (Jakarta, Bogor, Depok, Tangerang, and Bekasi), West Java and Banten, Central Java and Yogyakarta, and East Java.
We finally obtained a total of nine regional categories for our predictions: West Java and Banten (except Bogor and Tangerang); Jabodetabek (Jakarta, Bogor, Depok, Tangerang, and Bekasi); East Java; Central Java and Yogyakarta; Kalimantan; Maluku and Papua; Bali and Nusa Tenggara; Sulawesi; and Sumatra (
Figure 3).
This task was formulated as a text classification problem as it only used text features to make predictions. Because each user was assigned to a single location class based on information in their profile and tweets, this task was also formulated as a multiclass classification problem. A user typically has more than one tweet, and each tweet could be predicted in a different class. Thus, two approach scenarios were used, i.e., majority vote and tweet aggregation as one, which will be explained in
Section 5.
6. Results
6.1. Results Using Only Display Name
In this experiment, logistic regression obtained the best results, with an accuracy of 0.41 and an F1 score of 0.43. The use of the display name alone showed high accuracy, averaging 0.39 across all three machine learning algorithms. This may be because the share of organizational accounts in the dataset was quite large, at 50%, and such accounts tend to mention location entities in their display names. An example is regional government organizations, such as Pemerintah Provinsi Sulawesi Selatan (South Sulawesi Provincial Government).
Table 1 presents the results for accuracy of prediction using display name and user description.
6.2. Results Using Only User Description
As in the previous result with display name, logistic regression showed the best results with an accuracy of 0.39. The accuracy of logistic regression, naïve Bayes, and support vector machine was generally less than in
Section 6.1. This might have been caused by the requirement to fill in the user description attribute itself. A user can leave the user description blank, while they have to provide a display name for their account. Data on test results that went through the cleaning process showed that 8.5 percent of user descriptions were empty. This was eleven times more than in the case of display name, which had just 0.8 percent empty data. Therefore, more blank data led to lower prediction accuracy.
6.3. Results Using Only User Tweets
In this section, we discuss two scenarios. The first scenario predicted the location of each tweet separately and then determined the user’s location by majority vote. In the second scenario, we aggregated all user tweets into one text for each user and then made user-level predictions.
6.3.1. Majority Vote
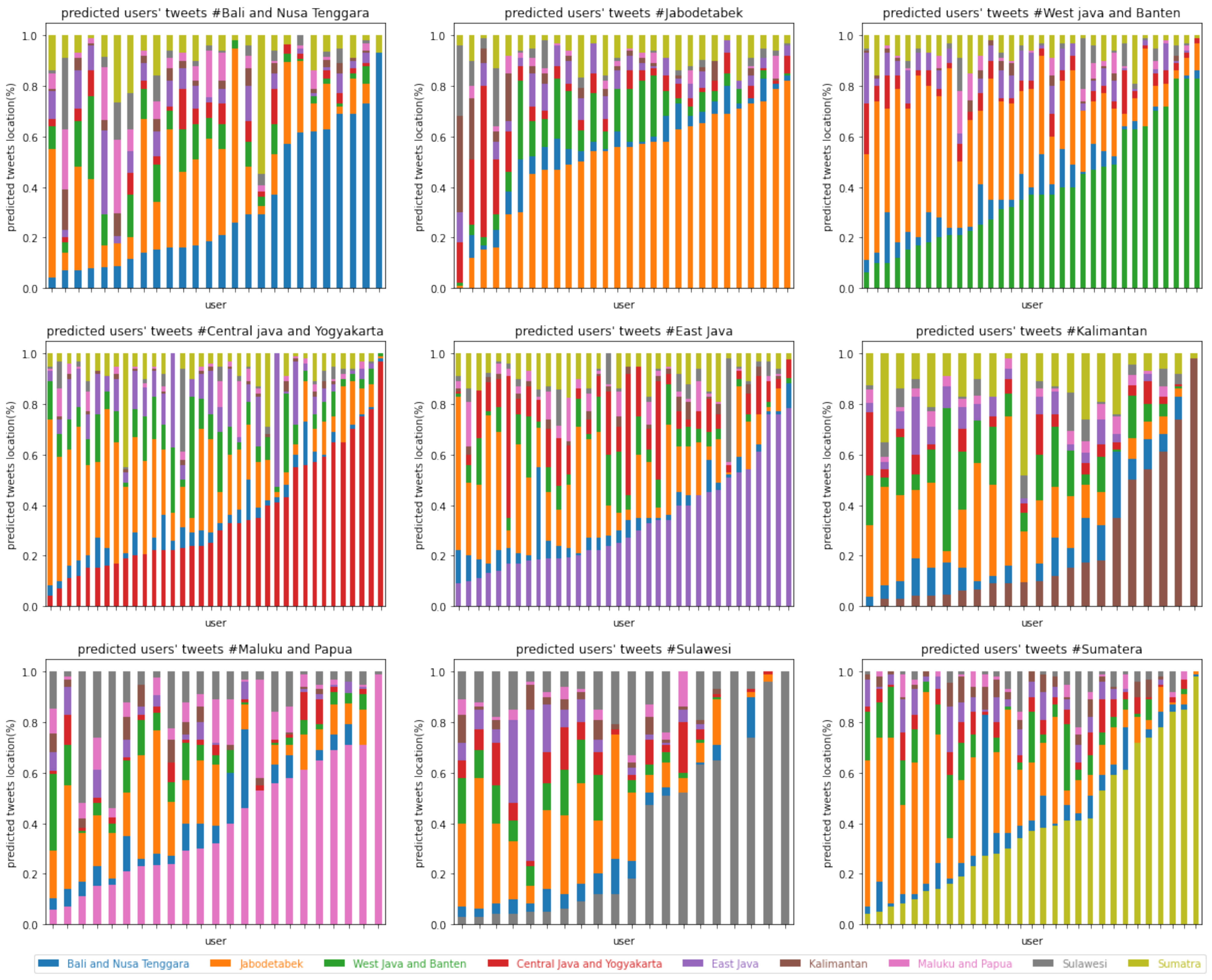
Using the majority vote scenario, i.e., choosing the most frequent location prediction result for a user’s tweets, the best result was obtained by logistic regression, followed by IndoBERTweet and IndoBERT. IndoBERTweet obtained an accuracy of 0.56 and an F1 score of 0.58, an increase of 7 percent from IndoBERT with an F1 score of 0.51. Prediction results using IndoBERTweet are shown in
Figure 8. In general, the classification results for each user’s tweets were highly variable. Consequently, the use of majority vote may not work in some cases, even though some tweets are successfully classified in the correct class. For example, in every class, all users always had tweets that were correctly classified. However, when a majority vote was conducted, the number of users classified in this class was reduced. This may be caused by the tweet topic, which tends to be quite varied. It may even be unrelated to the area where the user lives.
6.3.2. Tweet Aggregation into One Text
By merging all tweets of a user into one text, the best outcome was obtained by IndoBERT, followed by logistic regression and support vector machine. There was a significant 17 percent increase in accuracy of IndoBERT under this scenario compared the the best result in the majority voting scenario (
Table 2). In contrast to IndoBERT, the performance of LSTM and IndoBERTweet decreased significantly under the tweet aggregation scenario (
Table 3), which suggests that this scenario is not suitable for the two models for this task.
6.4. Results Using Display Name, User Description, and User Tweets
Overall, in the predict and vote experiment, combining the best results from display names, user descriptions, and user tweets did not result in increased accuracy compared to using user tweets alone. Under the majority voting scenario for user tweets, the best accuracy dropped slightly from 0.58 to 0.50 when combined with the display name and user description prediction results; in addition, the best accuracy of the aggregate tweet scenario dropped from 0.75 to 0.58.
Table 4 shows the results.
In contrast, in the concatenate and predict experiment, there was an increase in accuracy in both the majority and aggregation voting scenarios. When using majority voting with combined text, there was a 4% increase in accuracy compared to using only tweets. Meanwhile, the accuracy of combining display names, descriptions, and tweet aggregation techniques increased by 2% compared to tweet aggregation alone.
After we combined the display name, description, and tweet, the resulting accuracy showed a slight increase. This was because tweets contain more contextual information about the user than display names and descriptions. The display name attribute is limited to 50 characters and the description is limited to 160 characters, as specified in the problem formulation. A tweet, on the other hand, can be up to 280 characters long. In this study, a maximum of 100 tweets were used to predict the user’s location. As a result, tweets could undoubtedly provide the most detailed information, compared to display names and descriptions, to identify the user’s location.
6.5. Results with NER
The named entities in each attribute in
Section 6.1,
Section 6.2 and
Section 6.3 were extracted using IndoBERTweet. We then performed separate classifications, as in
Section 6.1,
Section 6.2,
Section 6.3 and
Section 6.4. However, the highest accuracy we achieved was 0.71 using IndoBERT under tweet aggregation scenario. This method was no better without named entities extraction, which can reach an accuracy of 0.75 with IndoBERT under the same scenario.
6.6. Cross-Testing Results
Cross-testing was performed with IndoBERT because it produced the best results in the previous stage.
Table 5 shows the results of the cross-testing experiment.
Nonperson had an accuracy of 0.84 when tested on
nonperson. However, accuracy decreased to 0.54 and 0.60 when tested on
person and
all, respectively. While
person had a low accuracy when tested on
person, when we tested it on
nonperson and
all, accuracy increased to 0.60 and 0.68, respectively.
The dataset should not have a high proportion of data on organizational users, as this will lead to overfitting. At the same time, the lack of organizational user categories in training data can reduce accuracy. Therefore, we conclude that the composition of the dataset, i.e., the number of individual and organizational categories in the dataset, can affect the prediction results.
7. Discussion
In general, when using machine learning algorithms, logistic regression can provide the best results compared to naïve Bayes and support vector machine. Compared to TF-IDF representation and classification using logistic regression, the use of BERT for word representation resulted in better accuracy and F1 scores.
Table 6 shows some examples of predicting the location of tweets using IndoBERTweet in the majority vote scenario. We found that tweets containing specific terms and entities tended to be associated with specific locations. Tweets containing location entities, such as “Bali”, “Lombok”, and “Nusa Tenggara”, and specific terms, such as “Galungan” and “Kuningan” (“Galungan” and “Kuningan” are Hindu holidays; Bali is the only province in Indonesia where the majority of population is Hindu [
70]), were always predicted in Bali and Nusa Tenggara. However, this association may result in misclassification. The third row was predicted in the Jabodetabek class because it mentioned entities related to Jabodetabek, i.e., “Jakarta”. Similarly, the fourth and fifth rows were also misclassified in Bali and Nusa Tenggara because the tweets mentioned entities and terms related to Bali and Nusa Tenggara. Considering that individuals tend to mention local entities and events in their area more often than in other areas, more tweets are necessary to infer a more accurate user location in the majority vote scenario.
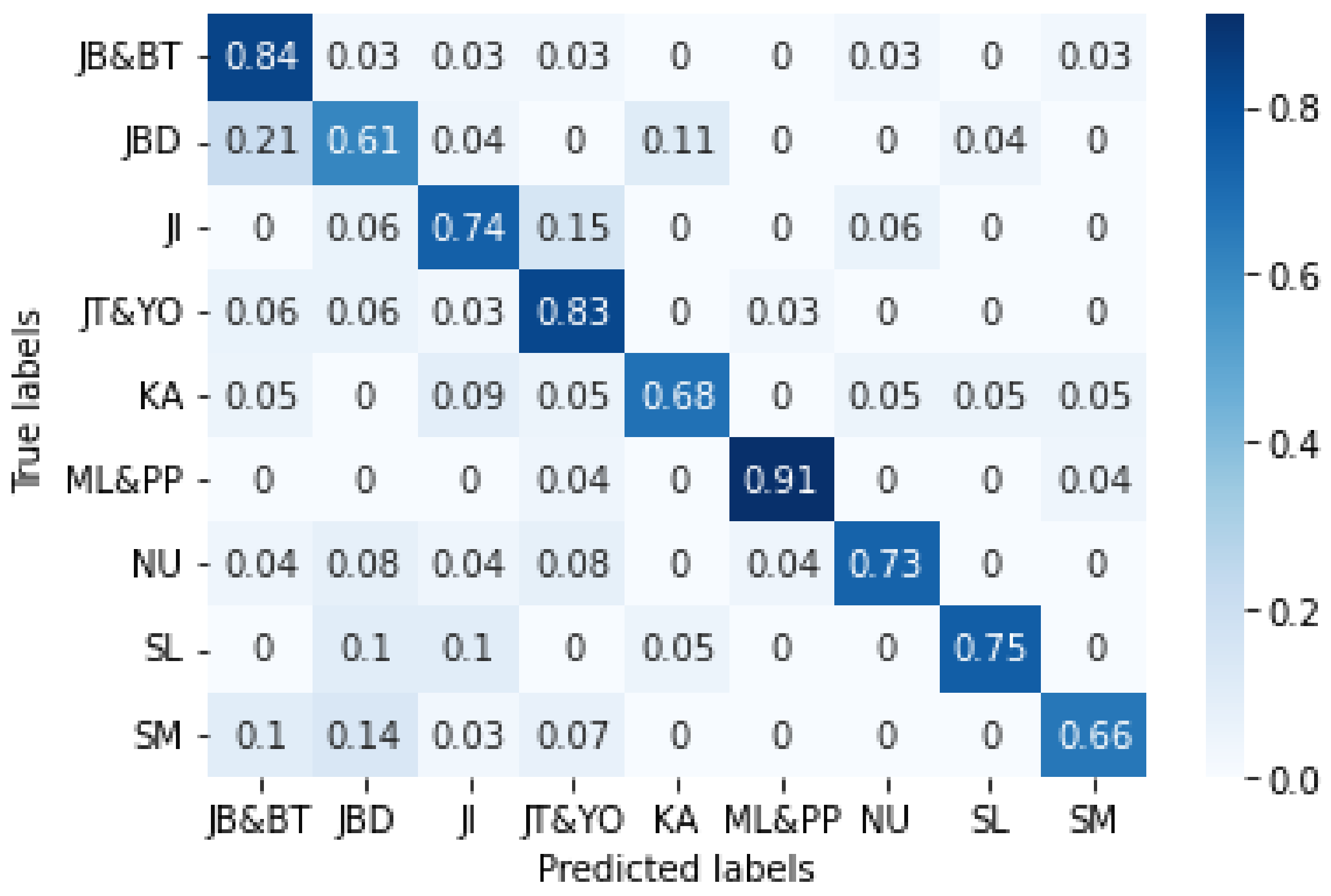
The experimental results for aggregated tweets showed increased accuracy. The normalized confusion matrix obtained with IndoBERT with aggregated tweets can be seen in
Figure 9. Pairs of labels and names for these regions are as follows: JB&BT: West Java and Banten, JBD: Jabodetabek, JI: East Java, JT&YO: Central Java and Yogyakarta, KA: Kalimantan, ML&PP: Maluku and Papua, NU: Bali and Nusa Tenggara, SL: Sulawesi, and SM: Sumatra [
71].
Figure 9 shows that the Maluku and Papua class had the highest percentage of correct predictions at 0.91, followed by the West Java and Banten class at 0.84 correct predictions. The classes with the lowest percentages of correct predictions were from Jabodetabek (Jakarta, Bogor, Tangerang, Depok, and Bekasi). This is remarkable considering that the cities of Bogor, Depok, and Bekasi are administratively part of West Java Province and Tangerang City is part of Banten Province, so the characteristics of the tweets in the two classes may show similarities.
Figure 9 shows that up to 21 percent of the tweets in West Java and Banten class are expected to belong to the Jabodetabek class.
Our results show that IndoBERT, which is a BERT model that has been trained on the Indonesian dataset [
39,
41], can generally outperform machine learning algorithms in generating location predictions. However, using IndoBERT does not produce accurate results in some cases, as shown in
Table 6. The table lists some cases where the IndoBERT model failed to predict the home locations for the given tweets. The actual home locations for the last three tweets in the table are “Bali and Nusa Tenggara”, but the model makes incorrect predictions for all these tweets.
From the table, we can see some limitations of the IndoBERT model when predicting the user home location. The model could not predict correctly when the tweet texts show locations which do not reflect the home location of the user. The fourth tweet contains terms “Bali” and “Lombok” (i.e., Lombok is located in Nusa Tenggara), while the fifth tweet contains terms “Galungan” (i.e., a Balinese holiday), which causes the model to predict the location of these tweets as “Bali and Nusa Tenggara”. However, the actual home locations of the users for these tweets are “Jabodetabek” and “Maluku and Papua”, respectively. Therefore, in this case, using tweet text only with the IndoBERT model is not enough to make accurate prediction. We may need extra information that can guide the model to the actual home locations, such as using time zone information [
46] and friend networks [
43,
46].
The model could not predict correctly for certain locations which are not that popular, so they probably do not appear frequently in the dataset used for training the IndoBERT. Although the sixth tweet contain term “Bakunase” and the seventh tweet contain terms “Pagar Panjang” and “Danau Ina” that clearly show the home location of the user (i.e., Bakunase, Pagar Panjang, and Danau Ina are places in Nusa Tenggara Timur), the model could not make accurate predictions for these tweets.
Finally, the model could not predict correctly for tweets that contain ambiguous words which actually denote the location. The term “Seroja” in the eighth tweet actually indicates the “Badai Seroja” (Cyclone Seroja) which happened in Nusa Tenggara Timur during 3–12 April 2021, but the IndoBERT seemingly could not capture this meaning, probably because “Seroja” has a more general meaning as a certain kind of flower.
In general, this research has some limitations that could be improved in future work. The dataset we used does not cover all provinces in Indonesia, i.e., 34 provinces. As a result, we cannot estimate a user’s location down to province and city level. It would be better if this research can be applied to a larger scope and a more detailed user location level (e.g., province level). For this purpose, we may need to create a bigger dataset which contains more complete annotations for all provinces in Indonesia. However, adding datasets will be proportional to the many costs involved, especially in the data annotation process. Hence, we need another method that is automated to reduce the cost in the annotation process, and therefore it is aimed for future work.
This research only focuses on Indonesian-language tweets. Therefore, it cannot be concluded that the methods used in this research are also effective for tweets in other languages or in code-mixed languages [
72,
73]. Further studies are needed to test the effectiveness of the methods in other languages. Finally, the features used in this study are limited to text features: user name, user description, and user tweets. In our experiments, the combination of the three gave the best results. In future work, it is also necessary to consider cross-feature to see the interaction between features. In addition, several other features could be incorporated, such as time zone information [
46] and friend networks [
43,
46]. In addition, deep learning methods using attention mechanism may also be explored to combine features directly in a single model [
74].
8. Conclusions
In this study, we collected Indonesian-language Twitter data to identify the home location of Twitter users. Home location was divided into nine regions according to the geographical characteristics of Indonesia. We used three user attributes, i.e., display name, user description, and user tweets, and performed location prediction experiments using some machine learning algorithms and deep learning models. Two scenarios were applied to predict user’s home location using tweet attributes: majority vote and tweet aggregation into one text. We also concatenated display name, description, and tweets and performed the same scenario, namely, majority voting and text aggregation in one. The results of our analysis show that fine-tuning IndoBERT on concatenated display names, descriptions, and aggregate tweet can produce the highest accuracy of 0.77 with an F1 score of 0.78, compared to IndoBERTweet with an accuracy of 0.62 and an F1 score of 0.63, on the majority vote scenario. IndoBERT can show good results compared to machine learning algorithms and LSTM. The best result of machine learning was 0.58 for logistic regression and the best result of LSTM was 0.46, each under the majority vote scenario on tweet. In future research, we recommend using larger datasets to make location predictions for a wider area and at a more detailed level.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}