
Mobile User Interface Adaptation Based on Usability Reward Model and Multi-Agent Reinforcement Learning

Abstract
:1. Introduction
2. Related Work
2.1. Improving Usability
2.2. Creating a Reward Model
3. Method
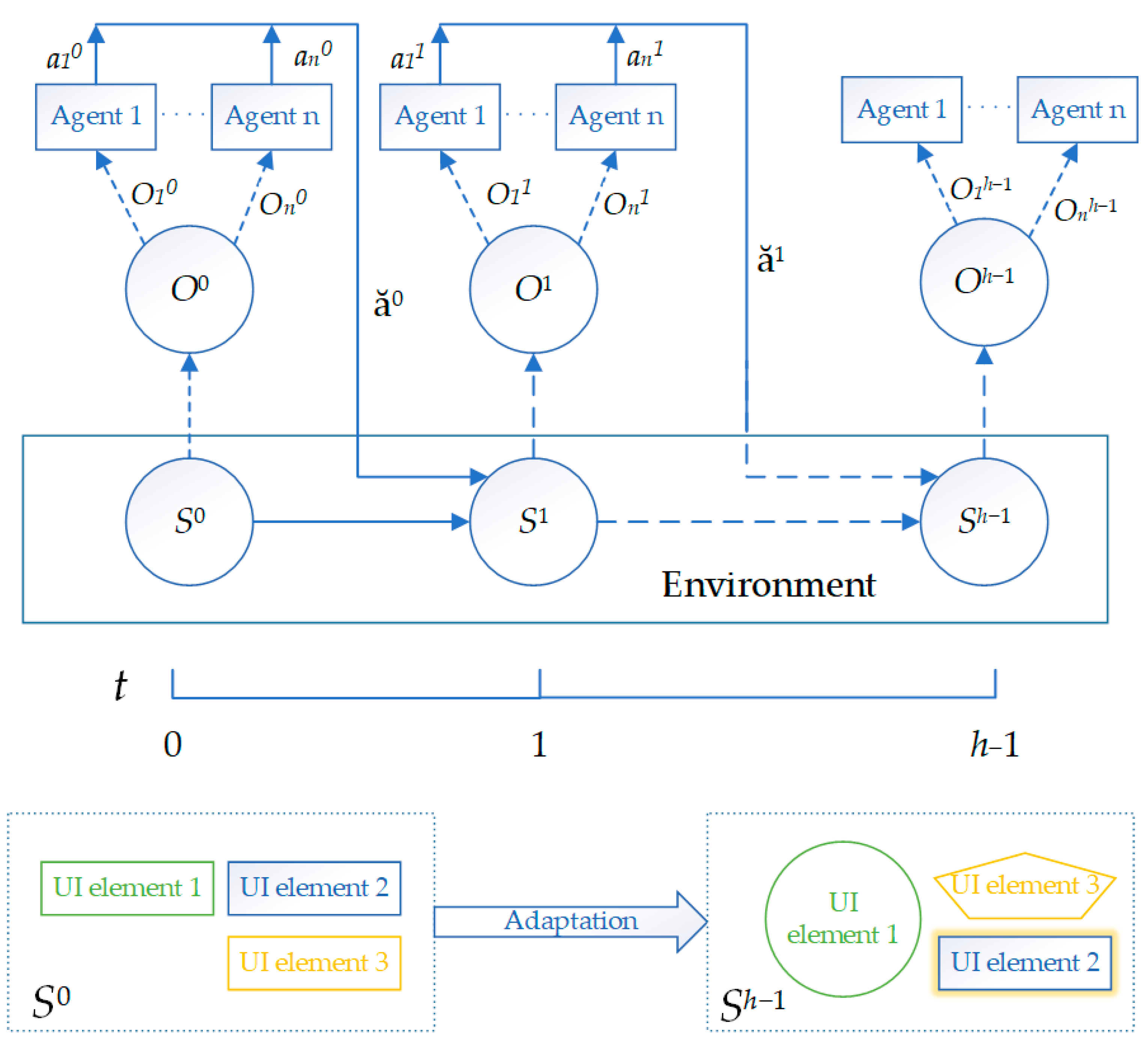
3.1. Decentralized POMDP Model
3.2. Usability Reward Model
3.3. IQL Algorithm
| Algorithm 1 Deep Independent Learning for Agent i Using Fully Connected Neural Network. |
|
4. Experiment
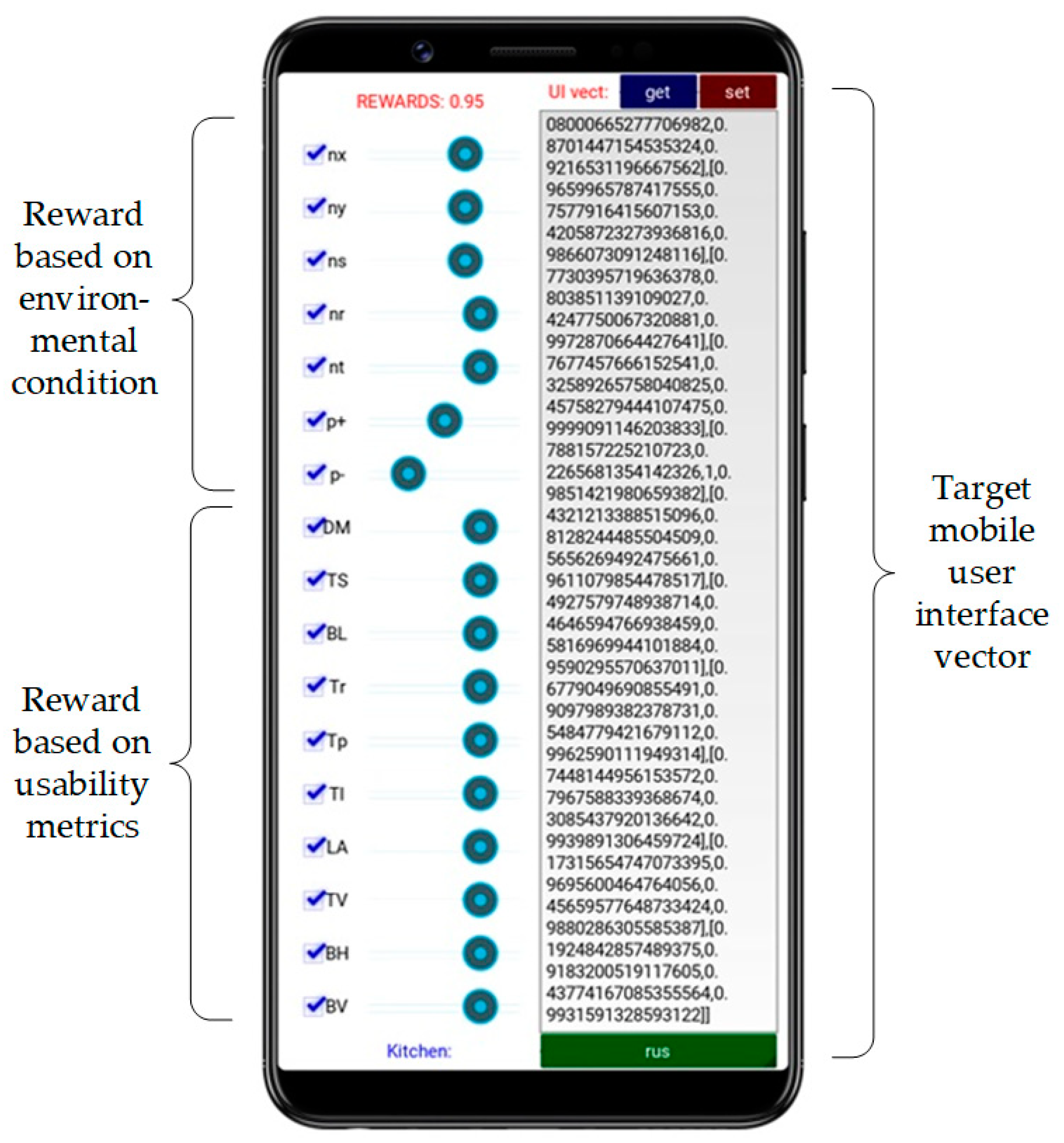
4.1. Multi-Agent Environment
4.2. Use Cases
4.3. Reward Computation
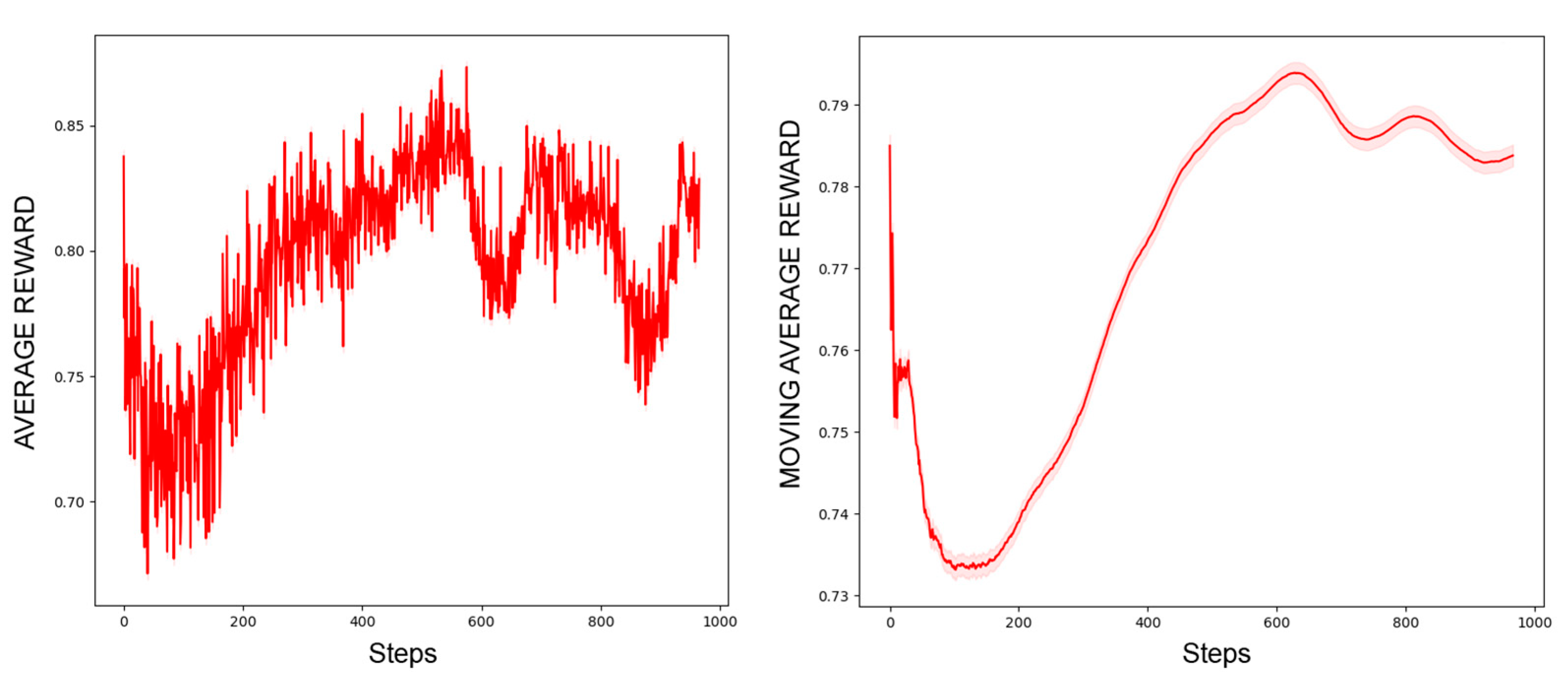
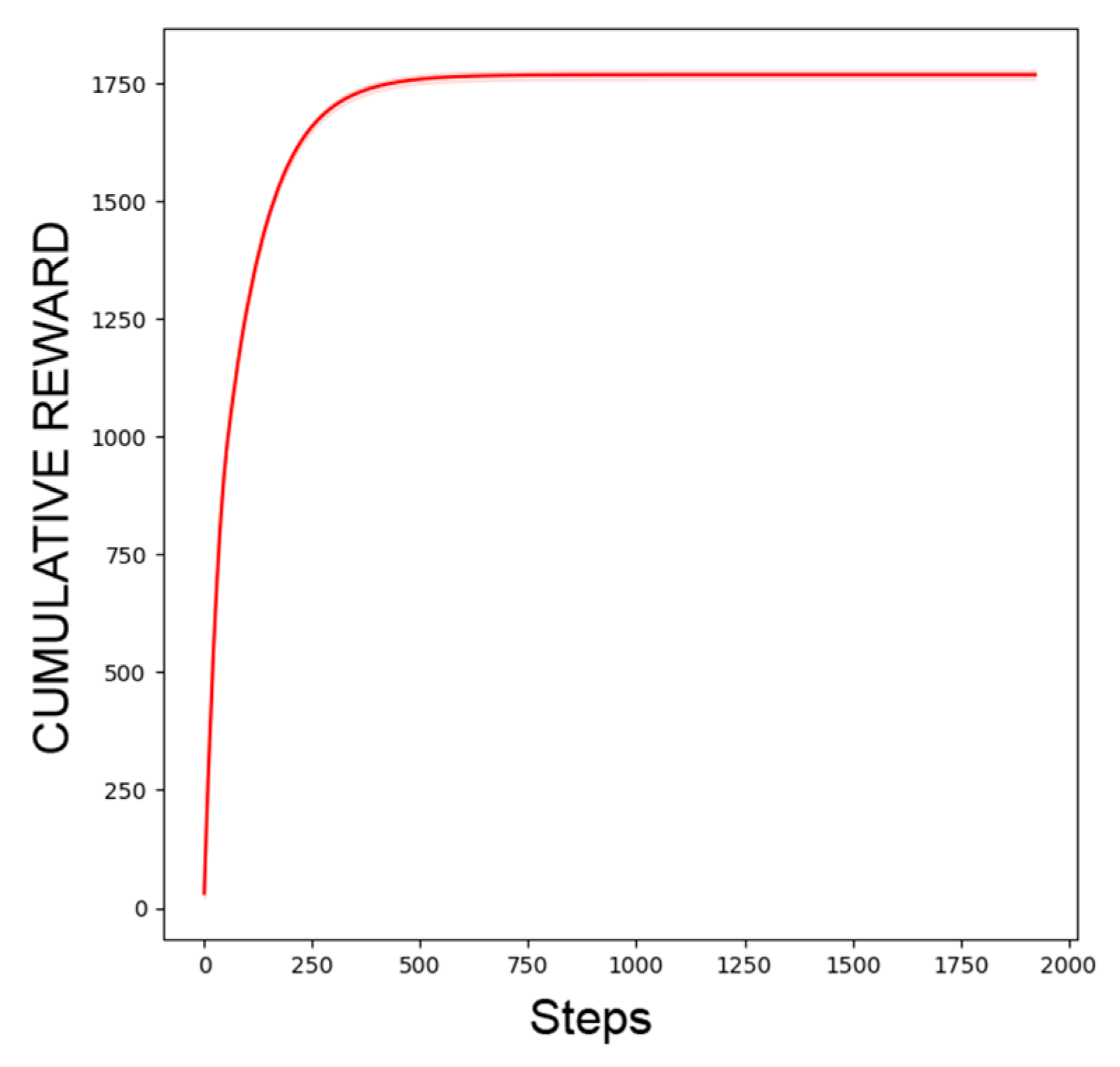
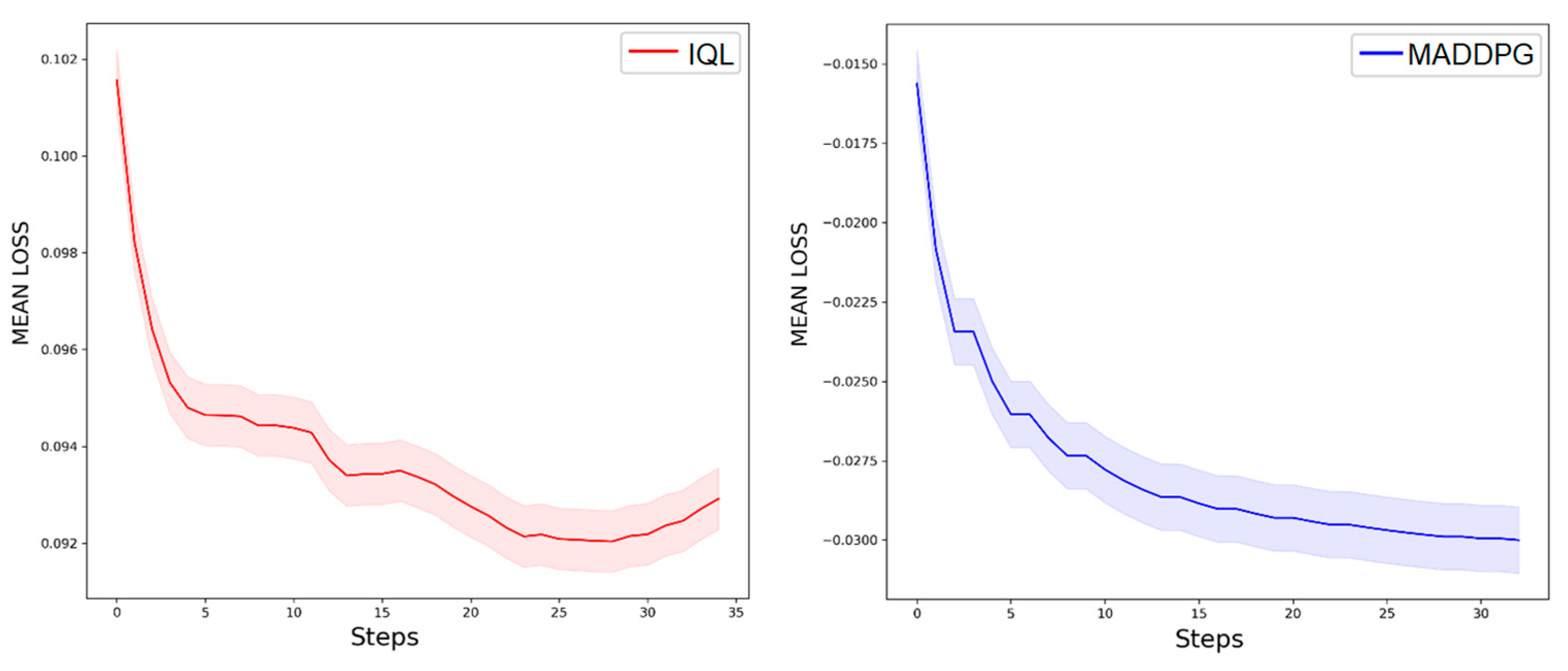
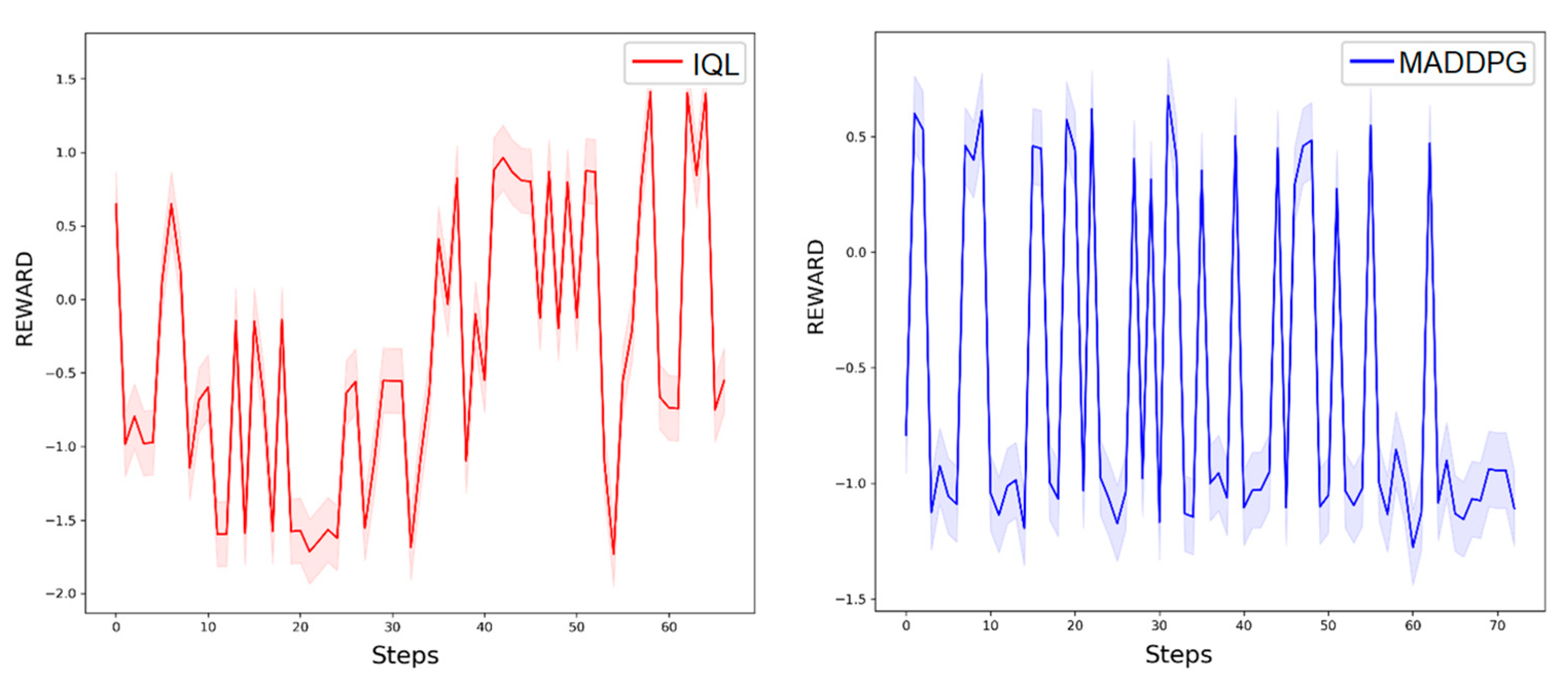
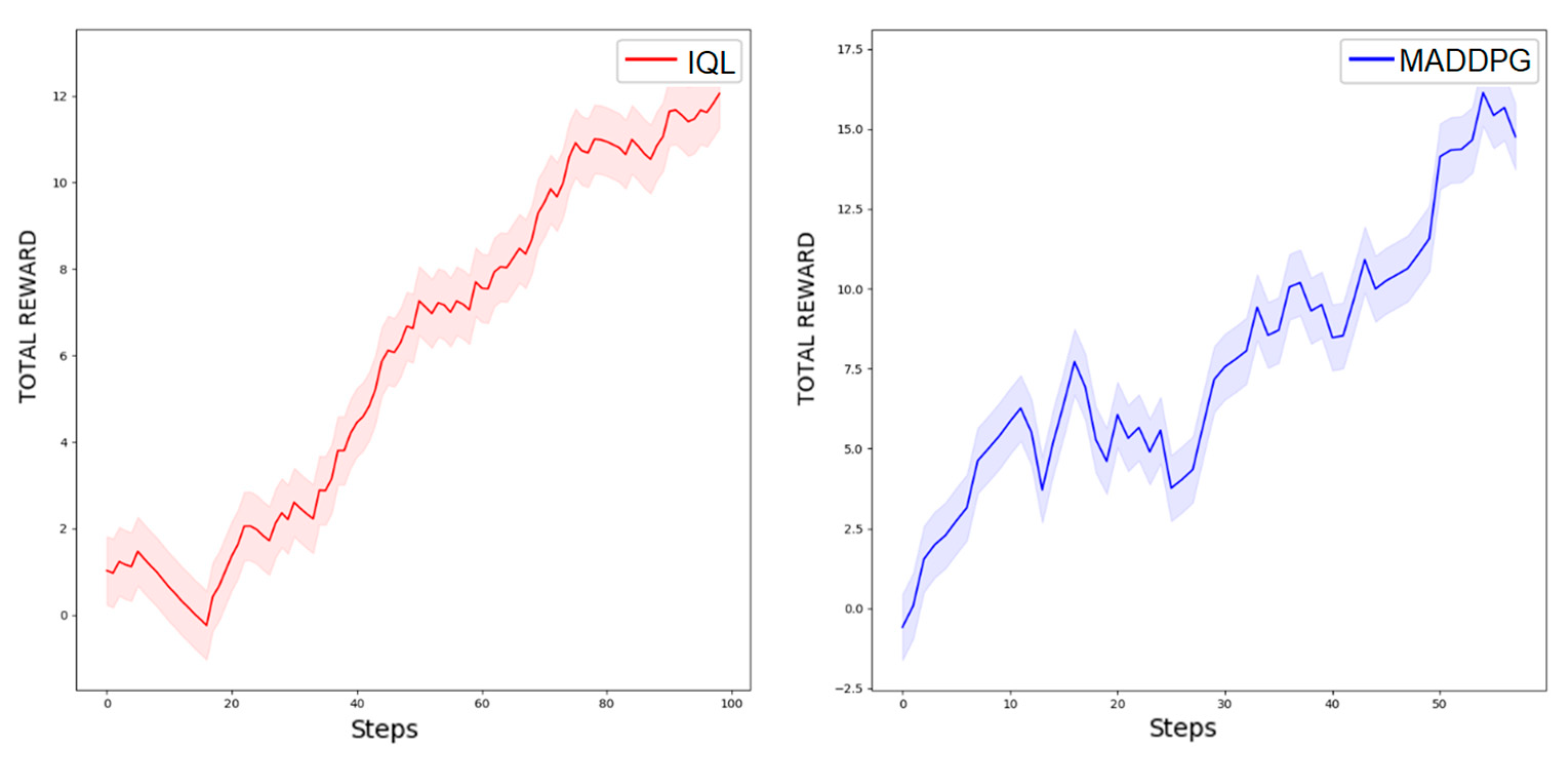
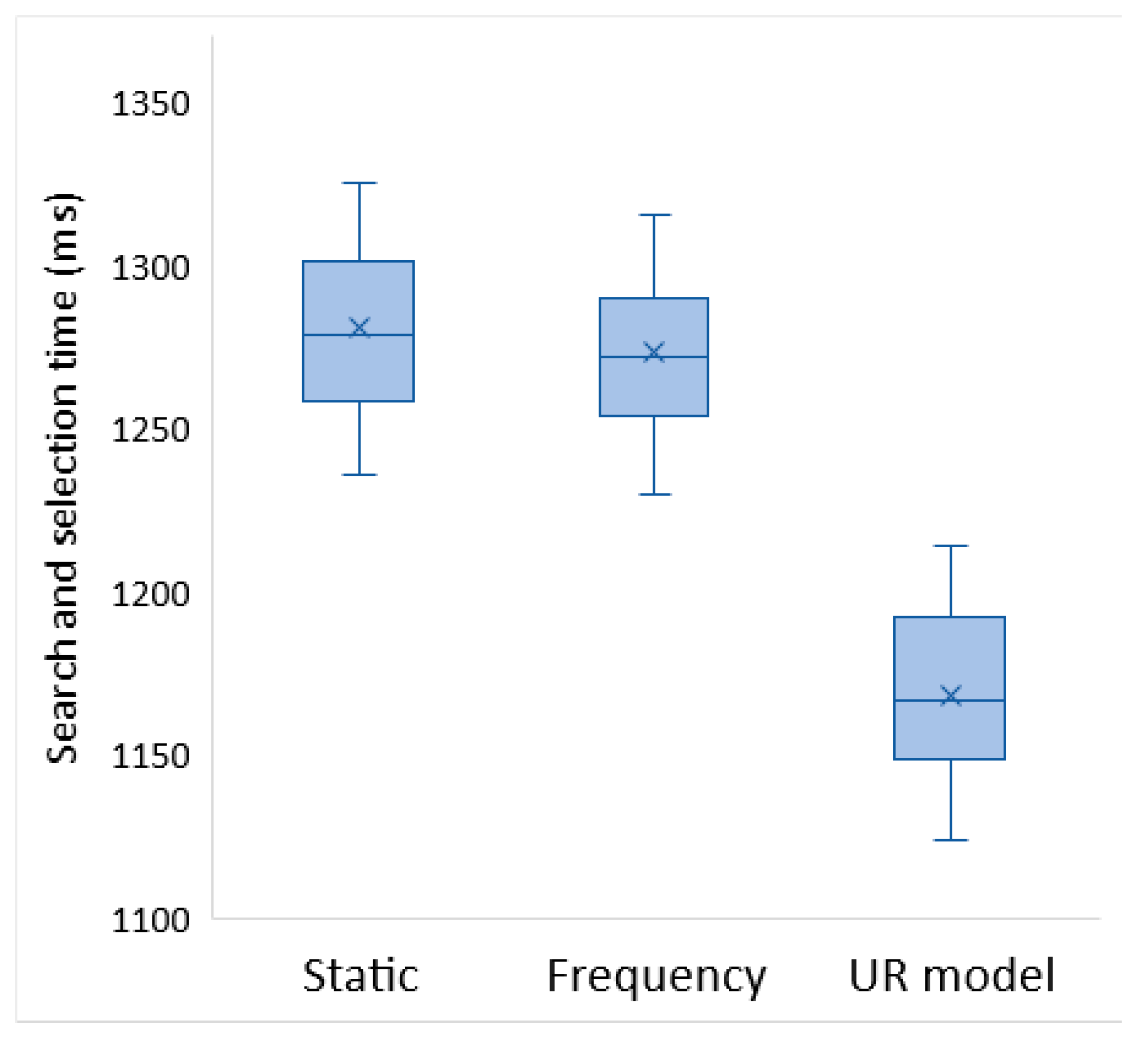
4.4. Experimental Results and Analysis
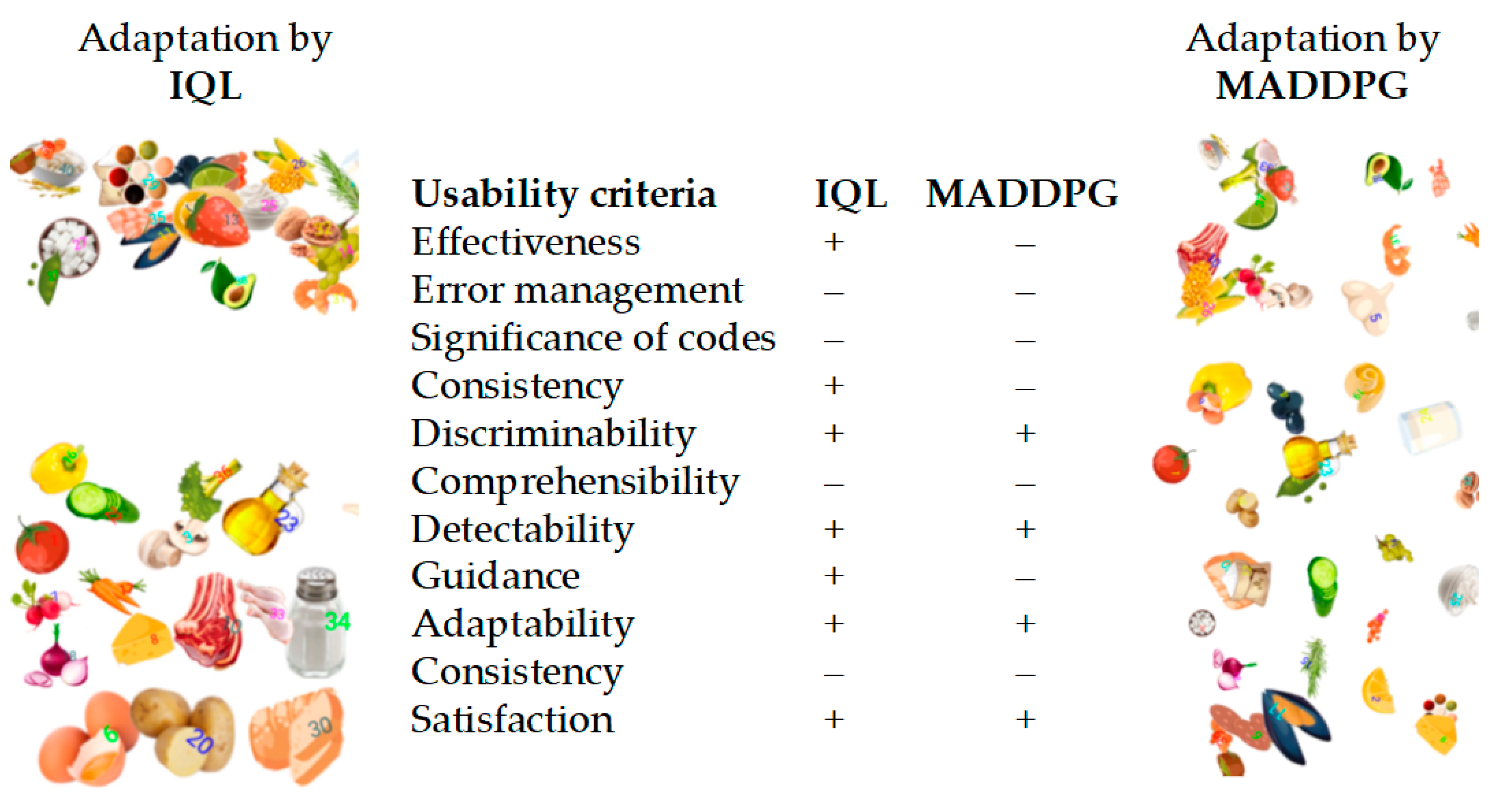
4.5. Model Validation
5. Discussion
5.1. Limitations
- Robustness: The ability of a multi-agent system to continue functioning in the event of failures in individual agents’ operations.
- Efficiency: Parallel data processing in a multi-agent system by autonomous agents accelerates the system’s operation.
- Adaptability: A decentralized multi-agent system is capable of dynamically changing its behavior in response to changes in the environment.
- Encapsulation: A multi-agent system is modular by nature, allowing flexible changes to its structure, abstraction of data, and protection of internal implementations.
- Scalability: In information perception and decision-making, a multi-agent system has no limitations on centralized data control, which enables better handling of increased workloads with added resources.
5.2. Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| UR | Usability Reward |
| MUI | Mobile User Interface |
| HCI | Human–Computer Interaction |
| RL | Reinforcement Learning |
| MARL | Multi-Agent Reinforcement Learning |
| MDP | Markov Decision Processes |
| POMDP | Partially Observable Markov Decision Process |
| DQN | Deep Q-Network |
| MADDPG | Multi-Agent Deep Deterministic Policy Gradient |
| MCTS | Monte Carlo Tree Search |
| PPO | Proximal Policy Optimization |
| IQL | Independent Q-Learning |
| LLM | Large Language Models |
| tinyML | Tiny Machine Learning |
References
- Tao, K.; Edmunds, P. Mobile APPs and Global Markets. Theor. Econ. Lett. 2018, 8, 1510–1524. [Google Scholar] [CrossRef]
- Falloon, G. Mobile Devices and Apps as Scaffolds to Science Learning in the Primary Classroom. J. Sci. Educ. Technol. 2017, 26, 613–628. [Google Scholar] [CrossRef]
- Lee, H. Mobile App Evolution: How the Ecosystem Has Changed. App Annie. Available online: https://www.data.ai/en/insights/market-data/mobile-app-evolution-how-the-ecosystem-has-changed/ (accessed on 20 March 2024).
- Ullah, I.; Boreli, R.; Kanhere, S.S. Privacy in targeted advertising on mobile devices: A survey. Int. J. Inf. Secur. 2022, 22, 647–678. [Google Scholar] [CrossRef] [PubMed]
- Iqbal, M.W.; Ahmad, N.; Shahzad, S.K.; Feroz, I.; Mian, N.A. Towards adaptive user interfaces for mobile-phone in smart world. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 556–565. [Google Scholar] [CrossRef]
- Zhou, J.; Tang, Z.; Zhao, M.; Ge, X.; Zhuang, F.; Zhou, M.; Xiong, H. Intelligent exploration for user interface modules of mobile app with collective learning. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Long Beach, CA, USA, 20 August 2020; KDD 20. Association for Computing Machinery: New York, NY, USA, 2020; pp. 3346–3355. [Google Scholar] [CrossRef]
- Macías-Escrivá, F.D.; Haber, R.; del Toro, R.; Hernandez, V. Self-adaptive systems: A survey of current approaches, research challenges and applications. Expert Syst. Appl. 2013, 40, 7267–7279. [Google Scholar] [CrossRef]
- Todi, K.; Bailly, G.; Leiva, L.; Oulasvirta, A. Adapting user interfaces with model-based reinforcement learning. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–13. [Google Scholar] [CrossRef]
- Gorban, A.N.; Pokidysheva, L.I.; Smirnova, E.V.; Tyukina, T.A. Law of the minimum paradoxes. Bull. Math. Biol. 2011, 73, 2013–2044. [Google Scholar] [CrossRef] [PubMed]
- Gorban, A.N.; Smirnova, E.V.; Tyukina, T.A. General Laws of Adaptation to Environmental Factors: From Ecological Stress to Financial Crisis. Math. Model. Nat. Phenom. 2009, 4, 1–53. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- Croft, W.B. The role of context and adaptation in user interfaces. Int. J. Man Mach. Stud. 1984, 21, 283–292. [Google Scholar] [CrossRef]
- Langerak, T.; Christen, S.; Albaba, M.; Gebhardt, C.; Hilliges, O. MARLUI: Multi-Agent Reinforcement Learning for Goal-Agnostic Adaptive UIs. arXiv 2022, arXiv:2209.12660. [Google Scholar] [CrossRef]
- Abrahão, S.; Insfran, E.; Sluÿters, A.; Vanderdonckt, J. Model-based intelligent user interface adaptation: Challenges and future directions. Softw. Syst. Model. 2021, 20, 1335–1349. [Google Scholar] [CrossRef]
- Figueiredo, D.G. Learning from Interaction: User Interface Adaptation using Reinforcement Learning. arXiv 2023, arXiv:2312.07216. [Google Scholar]
- Singh, S.; Lewis, R.L.; Barto, A.G.; Sorg, J. Intrinsically Motivated Reinforcement Learning: An Evolutionary Perspective. IEEE Trans. Auton. Ment. Dev. 2010, 2, 70–82. [Google Scholar] [CrossRef]
- Gaspar-Figueiredo, D.; Fernández-Diego, M.; Abrahao, S.; Insfran, E. A Comparative Study on Reward Models for UI Adap-tation with Reinforcement Learning. Methods 2023, 13, 14. [Google Scholar]
- Razevicius, G.; Roudaut, A.; Karnik, A. HoberUI: An Exploration of Kinematic Structures as Interactive Input Devices. Multimodal Technol. Interact. 2024, 8, 13. [Google Scholar] [CrossRef]
- Maes, P.; Kozierok, R. Learning interface agents. In Proceedings of the 11th National Conference on Artificial Intelligence, Washington, DC, USA, 11–15 July 1993; pp. 459–465. [Google Scholar]
- Seo, Y.W.; Zhang, B.T. A reinforcement learning agent for personalized information filtering. In Proceedings of the 5th International Conference on Intelligent User Interfaces; IUI ’00, New Orleans, LA, USA, 9–12 January 2000; Association for Computing Machinery: New York, NY, USA, 2000; pp. 248–251. [Google Scholar] [CrossRef]
- Schatzmann, J.; Weilhammer, K.; Stuttle, M.; Young, S. A survey of statistical user simulation techniques for reinforce-ment-learning of dialogue management strategies. Knowl. Eng. Rev. 2006, 21, 97–126. [Google Scholar] [CrossRef]
- Thomaz, A.L.; Breazeal, C. Reinforcement learning with human teachers: Evidence of feedback and guidance with implica-tions for learning performance. In Proceedings of the AAAI-06: Twenty-First Conference on Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; pp. 1000–1005. [Google Scholar]
- Branavan, S.R.; Chen, H.; Zettlemoyer, L.; Barzilay, R. Reinforcement learning for mapping instructions to actions. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 82–90. [Google Scholar]
- Young, S. Cognitive user interfaces. IEEE Signal Process. Mag. 2010, 27, 128–140. [Google Scholar] [CrossRef]
- Glowacka, D.; Ruotsalo, T.; Konuyshkova, K.; Athukorala, K.; Kaski, S.; Jacucci, G. Directing exploratory search: Reinforcement learning from user interactions with keywords. In Proceedings of the 2013 International Conference on Intelligent User Interfaces, Los Angeles, CA, USA, 19–22 March 2013; pp. 117–128. [Google Scholar]
- Littman, M.L. Reinforcement learning improves behaviour from evaluative feedback. Nature 2015, 521, 445–451. [Google Scholar] [CrossRef]
- Debard, Q.; Dibangoye, J.S.; Canu, S.; Wolf, C. Learning 3d navigation protocols on touch interfaces with cooperative mul-ti-agent reinforcement learning. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2019, Würzburg, Germany, 16–20 September 2019; Proceedings, Part III. Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 35–52. [Google Scholar]
- Li, Z.; Zhao, M.; Das, D.; Zhao, H.; Ma, Y.; Liu, W.; Beaudouin-Lafon, M.; Wang, F.; Ramakrishnan, I.; Bi, X. Select or Suggest? Reinforcement Learning-based Method for High-Accuracy Target Selection on Touchscreens. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 30 April–5 May 2022; pp. 1–15. [Google Scholar]
- Bi, X.; Li, Y.; Zhai, S. FFitts law: Modeling finger touch with fitts’ law. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 1363–1372. [Google Scholar]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Gupta, T.; Gori, J. Modeling reciprocal adaptation in HCI: A Multi-Agent Reinforcement Learning Approach. In Proceedings of the Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–6. [Google Scholar]
- Li, Z.; Ko, Y.J.; Putkonen, A.; Feiz, S.; Ashok, V.; Ramakrishnan, I.V.; Oulasvirta, A.; Bi, X. Modeling Touch-based Menu Se-lection Performance of Blind Users via Reinforcement Learning. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–18. [Google Scholar]
- Sheikh, H.U.; Khadka, S.; Miret, S.; Majumdar, S.; Phielipp, M. Learning intrinsic symbolic rewards in reinforcement learning. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; IEEE: New York, NY, USA, 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Amato, C.; Konidaris, G.; Cruz, G.; Maynor, C.A.; How, J.P.; Kaelbling, L.P. Planning for decentralized control of multiple robots under uncertainty. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; IEEE: New York, NY, USA, 2015; pp. 1241–1248. [Google Scholar] [CrossRef]
- Ammar, L.B. A usability model for mobile applications generated with a model-driven approach. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 140–146. [Google Scholar] [CrossRef]
- Seffah, A.; Donyaee, M.; Kline, R.B.; Padda, H.K. Usability measurement and metrics: A consolidated model. Softw. Qual. J. 2006, 14, 159–178. [Google Scholar] [CrossRef]
- Tampuu, A.; Matiisen, T.; Kodelja, D.; Kuzovkin, I.; Korjus, K.; Aru, J.; Aru, J.; Vicente, R. Multiagent cooperation and competition with deep reinforcement learning. PLoS ONE 2017, 12, e0172395. [Google Scholar] [CrossRef] [PubMed]
- Verzynov, S.N.; Bochkarev, I.V.; Khramshin, V.R. Development of Line Locator Software Component for Mobile Operating Systems. In 2020 International Conference on Industrial Engineering, Applications and Manufacturing (ICIEAM), Sochi, Russia, 18–22 May 2020; IEEE: New York, NY, USA, 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Chin, J.P.; Diehl, V.A.; Norman, L.K. Development of an Instrument Measuring User Satisfaction of the Human-Computer Interface. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems—CHI ’88, Washington, DC, USA, 15–19 May 1988. [Google Scholar] [CrossRef]
- Moumane, K.; Idri, A.; Abran, A. Usability evaluation of mobile applications using ISO 9241 and ISO 25062 standards. SpringerPlus 2016, 5, 548. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, J. Usability Engineering; Morgan Kaufmann: Burlington, MA, USA, 1994. [Google Scholar]
- Liu, W.; Bailly, G.; Howes, A. Effects of frequency distribution on linear menu performance. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 1307–1312. [Google Scholar]
- Wong, A.; Bäck, T.; Kononova, A.V.; Plaat, A. Deep multiagent reinforcement learning: Challenges and directions. Artif. Intell. Rev. 2023, 56, 5023–5056. [Google Scholar] [CrossRef]
- Oroojlooy, A.; Hajinezhad, D. A review of cooperative multi-agent deep reinforcement learning. Appl. Intell. 2023, 53, 13677–13722. [Google Scholar] [CrossRef]
- Carta, T.; Romac, C.; Wolf, T.; Lamprier, S.; Sigaud, O.; Oudeyer, P.-Y. Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 3676–3713. [Google Scholar]
- Li, W.; Qiao, D.; Wang, B.; Wang, X.; Jin, B.; Zha, H. Semantically Aligned Task Decomposition in Multi-Agent Reinforcement Learning. arXiv 2023, arXiv:2305.10865. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RL Algorithm | Model | Author, Year, Reference |
|---|---|---|
| Memory-based learning | Closest distance | Maes et al., 1993 [21] |
| Q-Learning | MDP | Seo et al., 2000 [22] |
| Model-based Q-Learning | MDP | Schatzmann et al., 2006 [23] |
| Interactive Q-Learning | MDP | Thomaz et al., 2006 [24] |
| Policy Gradient | MDP | Branavan et al., 2009 [25] |
| Iterative optimization | POMDP | Young, 2010 [26] |
| Q-Learning | MDP | Glowacka et al., 2013 [27] |
| DQN | MDP | Mnih et al., 2015 [11] |
| DQN | MDP | Littman, 2015 [28] |
| DDPG | MDP | Debard et al., 2020 [29] |
| Maxmin DQN | POMDP | Sheikh et al., 2020 [35] |
| MCTS | MDP | Todi et al., 2021 [8] |
| DQN | MDP | Li et al., 2022 [30] |
| PPO | POMDP | Langerak et al., 2022 [15] |
| MADDPG | POMDP | Gupta et al., 2023 [33] |
| DQN | MDP | Li et al., 2023 [34] |
| Name of Usability Metric (Reference) | Definition |
|---|---|
| Structured Text Entry [37] | where Structured_Text_Entry() returns 1 if the input element displays a mask, 0 otherwise; n—the total number of input elements that accept data in an exact format. |
| Essential Efficiency [38] | where Sessential is the number of user steps in the description of the primary (best) use case, and Senacted is the number of steps required to perform the use case with the current user interface design. |
| Built in Icon [37] | where Built_in_Icon() returns 1 if the action element displays a system icon, 0 otherwise; n—the total number of action elements in the interface. |
| Density Measure [37] | where ai and aframe represent the area of object i and the area of the frame, respectively, and n is the number of objects in the frame. |
| Layout Appropriateness [38] | where Pi,j is the transition frequency between visual components i and j, Di, j is the distance between visual components i and j. |
| Default Value [37] | where ai is the input element with a default value, n is the total number of input elements. |
| Task Concordance [38] | where N is the number of tasks to be ranked, D is the inconsistency index, i.e., the number of tasks pairs whose difficulties are arranged correctly minus those pairs whose difficulties are arranged incorrectly. |
| Target Element Size [37] | where ai returns 1 if the area of object i is greater than or equal to 44 pt × 44 pt (or 88 pt × 88 pt), otherwise 0, and n is the number of interactive objects in the interface. |
| Text Size [37] | where FontSizei returns 1 if the font size for text input i is greater than or equal to 16 px, otherwise 0, and n is the number of text inputs in the interface. |
| Task Visibility [38] | where Stotal is the total number of implemented steps to complete the use case, Vi is the visibility of the implemented step i, ranging from 0 to 1. |
| Balance [37] | where BLvert is the vertical balance, and BLhor is the horizontal balance. where L, R, T, and B refer to the left, right, top, and bottom edges, respectively. Wj is the weight of the j-th side of the interface (left, right, top, and bottom). |
| Horizontal (BH) or Vertical Balance (BV) [38] | where W1 is the weight of the first side, W2 is the weight of the second side. The weight of a side (Wi) = the number of pixels used × the distance of the side from the center. The center = halfway between the left edge of the leftmost visual element and the right edge of the rightmost element. |
| Element Readability [8] | where B(il) is the activation of element i at point l, and δ is the constant for careful examination of the element in the absence of activation. |
| Element Selection [8] | where ap and bp are the Fitts’ law constants for estimating the time to select an element (for example, ap = 10.3 and bp = 4.8), for the target element i at point l. |
| Local Search [8] | where Tc is a constant penalty for unexpectedness (element found where it was not expected), δ is the constant cost of careful examination of the element, Nlocal is the number of nearby elements being checked, Ttrail is the constant time for the cursor to follow the gaze of the eye. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vidmanov, D.; Alfimtsev, A. Mobile User Interface Adaptation Based on Usability Reward Model and Multi-Agent Reinforcement Learning. Multimodal Technol. Interact. 2024, 8, 26. https://doi.org/10.3390/mti8040026
Vidmanov D, Alfimtsev A. Mobile User Interface Adaptation Based on Usability Reward Model and Multi-Agent Reinforcement Learning. Multimodal Technologies and Interaction. 2024; 8(4):26. https://doi.org/10.3390/mti8040026
Chicago/Turabian StyleVidmanov, Dmitry, and Alexander Alfimtsev. 2024. "Mobile User Interface Adaptation Based on Usability Reward Model and Multi-Agent Reinforcement Learning" Multimodal Technologies and Interaction 8, no. 4: 26. https://doi.org/10.3390/mti8040026