1. Introduction
Arbitrary dissimilar stimuli can be trained to be functionally related via conditional discrimination. Based on this idea, Sidman [
1] carried out arbitrary Matching-To-Sample (MTS) experiments and found that functional properties can be transferred to other stimuli without explicit training; these emergent responses of reflexivity, symmetry, and transitivity are known as equivalence relations [
2,
3,
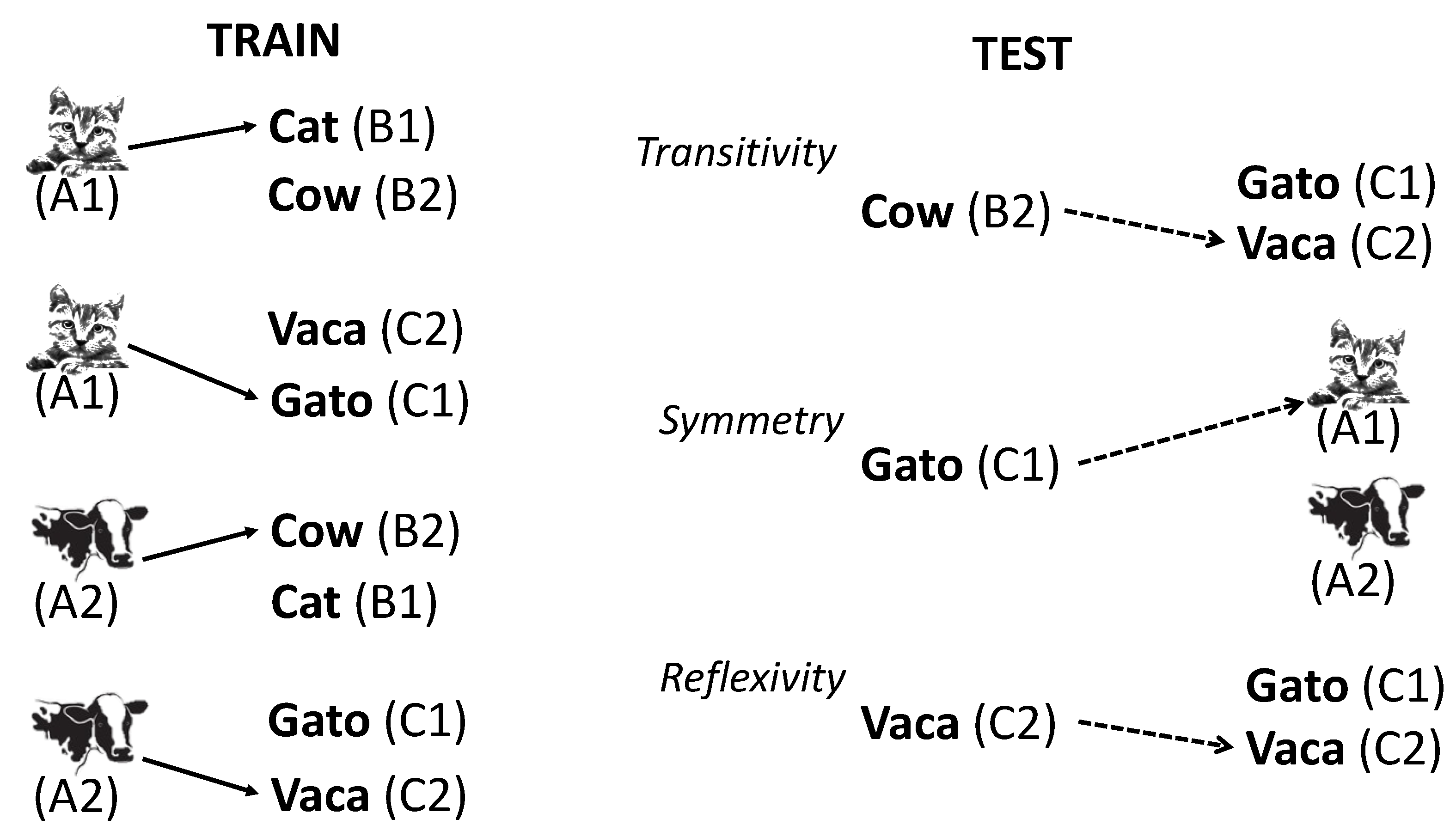
4]. For example, during the training phase, a participant is rewarded when: an image of a cow is presented and the word “cow” is selected; an image of a cow is presented and the equivalent word in Spanish “vaca” is selected; an image of a cat is presented and the word “cat” is selected; an image of a cat is presented and its equivalent in Spanish “gato” is selected. After training, without reward, in the test phase, the word “cow” is presented, and the participant selects the word “vaca”; the word “gato” is presented, and the participant selects the image of a cat; the word “vaca” is presented, and the participant selects the word “vaca”, as shown in
Figure 1. In this example, six stimuli were trained to form two classes (1 and 2) with three members (A, B, and C) each, in an MTS procedure. Stimulus Class 1 consists of the image of a cat (A1), the word cat (B1), and the Spanish word “gato” (C1), while Stimulus Class 2 consists of the image of a cow (A2), the word “cow” (B2), and the Spanish word “vaca” (C2). The two classes were formed by training the A1–B1, A1–C1, A2–B2, and A2–C2 relations. The test phase showed emergent relations between the stimuli within the class members without explicit training: transitivity (B2–C2), symmetry (C1–A1), and reflexivity (C2–C2). In the example, the creation of a class corresponding to a picture and a written word relates it to reading comprehension, meaning, and understanding. Furthermore, the relation established between the words of two languages illustrates the applicability of SE in foreign language acquisition. SE provides a framework in the experimental analysis of behaviour to study language, symbolic behaviour, and cognition, in a form of learning characterised as creative or generative. SE is also a common topic for interdisciplinary research linking behaviour analysis with linguistics and neuroscience [
5,
6,
7].
A context of analytical units and stimulus control is required to understand the behavioural phenomenon of SE from the perspective of experimental behaviour analysis [
8]. The behaviour of organisms can be analysed as environmental events linked by contingencies, if–then statements describing events that are true only under certain conditions [
3]. Contingencies allow units of analysis to be formed according to the number of terms involved. The two-term unit, called operant reinforcement, is composed by the terms response–reinforcer: only a defined response (rsp1) produces a defined reinforcer (rf1) and not otherwise. In the three-term unit, called simple discrimination, a two-term unit is under the control of a discriminative stimulus: a response (rsp1) produces its reinforcer (rf1) only in the presence of a particular discriminative stimulus (B1). In the four-term unit, called conditional discrimination, a three-term unit is under the control of a conditional stimulus: a response (rsp1) produces its reinforcer (rf1) in the presence of a particular discriminative stimulus (B1) only if a conditional stimulus (A1) is present. The MTS procedure is also known as conditional discrimination training in which the conditional stimuli are called samples and the discriminative stimuli are called comparisons [
1,
2,
3,
4]. In the example in
Figure 1, a trained conditional discrimination unit is: selecting option “X” produces its reinforcer (rf) in the presence of the word “cow” (B1) if the image of a cow (A1) is presented and is labelled as the A1–B1 relation. The A1–B1, A1–C1, A2–B2, and A2–C2 relations are conditional discrimination units explicitly formed in the training phase. However, the test phase showed that new conditional discrimination units were formed. One of these new untrained units is the B2–C2 relation: selecting option “X” produces its reinforcer (rf) in the presence of the word “vaca” (C2) if the word “cow” (B2) is presented. This means that a stimulus that was trained as a conditional stimulus can form new units that have not been previously trained, in which it can either control other three-term units or in which its role changes to a discriminative stimulus under the control of other stimuli. If a stimulus controls one member of the class, it affects all members of an equivalent stimulus class [
4]. Stimulus classes can be formed from any unrelated stimulus, arbitrarily assigned and functionally related regardless of its physical properties [
2].
Sidman [
2] affirmed that Stimulus Equivalence (SE) experiments provide an opportunity to study a type of stimulus generalisation in which participants functionally match dissimilar stimuli that have never been directly related. Understanding and correctly reproducing the conditions under which these emergent relations manifest themselves are fundamental knowledge for empirical, theoretical, and applied inquiry. Arntzen [
5] presented a set of procedural variables of relevance for methodological considerations in SE research. The Training Structure (TS) [
9,
10,
11,
12] describes the method of selecting which stimulus pairs will be related by training in the MTS procedure [
2,
10,
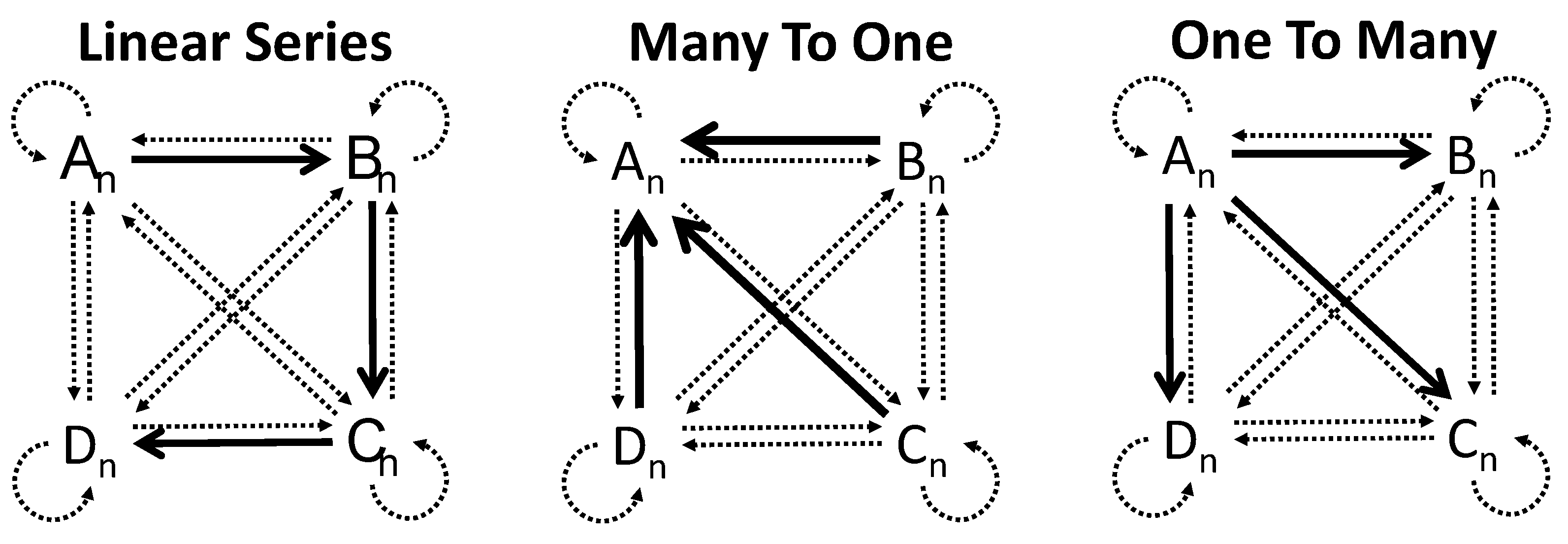
11] and which pairs will be in the test for emergent relations. TSs can be Linear Series (LSs), Many-To-One (MTO), and One-To-Many (OTM). In establishing an (
) equivalent class with four (
) members: A, B, C, and D, it is necessary to train
pairs and evaluate
emergent relations of transitivity and symmetry. In MTO, sample stimuli (B, C, and D) are trained with one comparison stimulus (A), so the training pairs are BA, CA, and DA. In OTM, one sample stimulus (A) is trained with many comparisons (B, C, and D), corresponding to training pairs AB, AC, and AD. In an LS training structure, a sample stimulus is shifted as a comparison to a sample of another pair. The pairs in the LS are AB, BC, and CD. In the AB pair, A is the sample and B is the comparison; then, B is the sample and C is the comparison in the BC pair, and C is the sample and D is the comparison for the CD pair [
5,
9,
11].
Figure 2 shows the trained relations: AB, BC, and CD for the LS; AB, AC, and AD for OTM; BA, CA, and DA for MTO, and the emergent relations evaluated: reflexivity, transitivity, and symmetry.
Fifty years of research on stimulus equivalence have covered a wide range of topics from basic to applied, both in humans and non-human animals [
4,
6], and also in computational simulations often involving an Artificial Neural Network (ANN) to replicate SE in computational agents [
7]. The ANN is a bio-inspired algorithm based on a simplification of the functioning of neurons and their relationship to information flow and processing. A single artificial neuron is called a perceptron, and interconnected, layered artificial neurons that learn simultaneously through the backpropagation of errors [
13] can perform a wide variety of complex tasks [
14,
15,
16,
17]. Deep Learning (DL) is the field of Machine Learning (ML) related to the research and development of those complex ANNs [
14]. As a part of computer science, ML seeks to develop algorithms that can improve their performance on a specific task, without the need for programming their execution, by mapping functional relations between variables in datasets. ML algorithms are classified according to the type of feedback signal available into three categories: supervised learning, unsupervised learning, or Reinforcement Learning (RL) [
15,
18,
19]. In supervised learning, there is a dataset for which the expected outcome is known; the algorithm is expected to infer a function from the labelled training data that maps an input to an output; if the target variable is continuous, the algorithms perform a regression task [
20], and if it is categorical, it is called a classification task [
21]. Unsupervised learning algorithms are not given an expected outcome value, so they identify underlying patterns in the data; tasks may consist of identifying relations between elements in the set, as in clustering tasks, where categories are assigned based on the properties of the elements or dimensional reduction may also be performed to find a way to represent the data more compactly [
15,
16]. In RL, an agent embedded in an environment performs an action in a given time step (
) that changes the state of the environment (
). This new state (
) and a reward signal (
) are returned as the input to the agent, which performs a new action. The agent must learn how to map situations to actions in order to maximise the reward signal [
14,
17,
22].
Computational models of psychological phenomena contribute to the advancement of both theory and research in psychology. The simulation of SE is an opportunity to explore experimental conditions that are difficult to achieve in real conditions with participants due to limitations such as costs, time, experimental control, ethical implications, or practicality. Experimenting and testing various configurations of variables in a short period of time can provide significant contributions, with particular emphasis on parameters for establishing stimulus equivalence [
5,
23,
24]. The aim of this paper was to analyse the effect of different TSs on class formation in a simulation with ANNs as the computational agents performing a classification task.
3. Results
The F1-score averages of the stimulus pairs, grouped by evaluation sets, are presented in
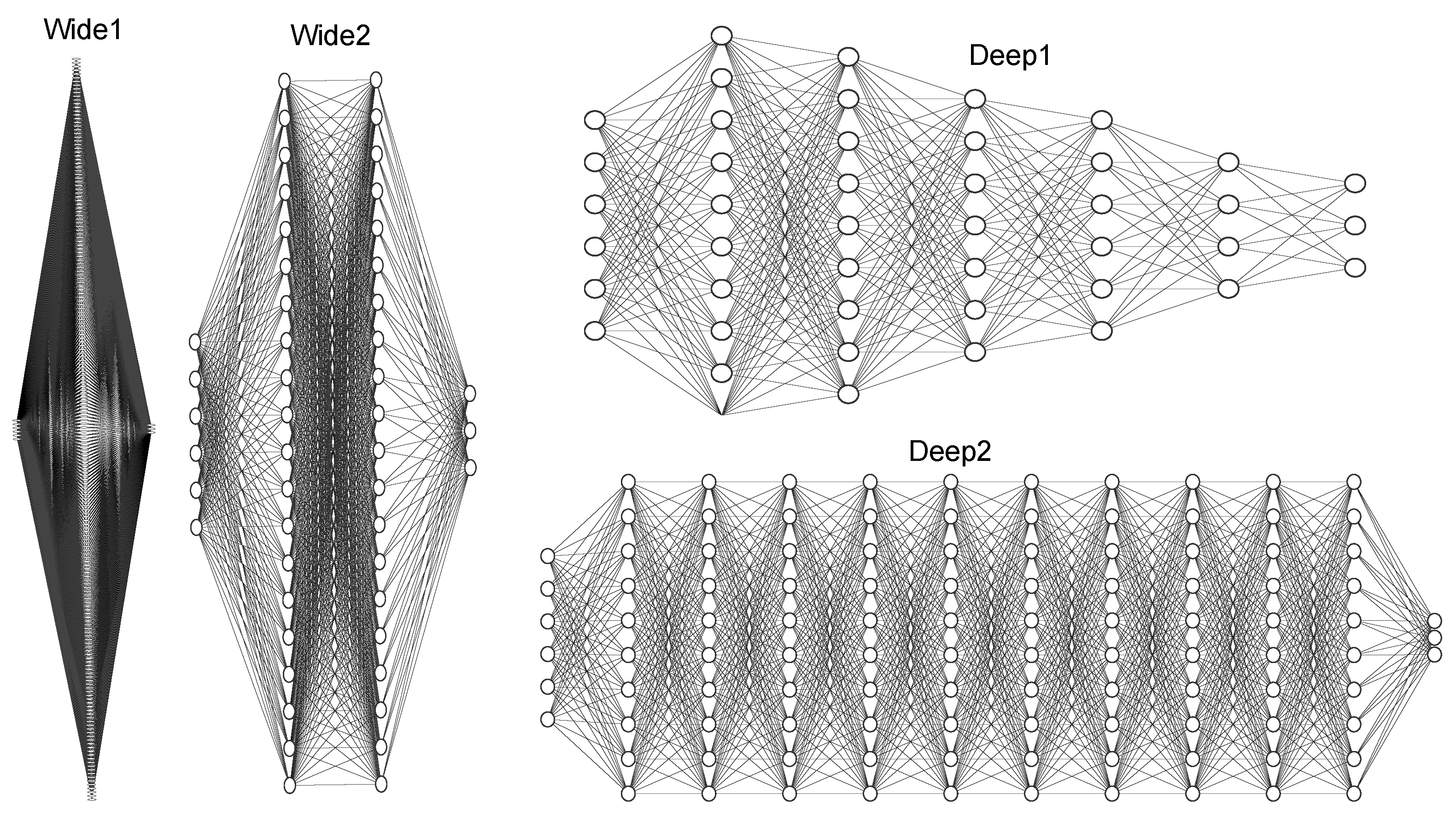
Table 3 for each agent. The four ANN architectures were used as a different agent for each of the three TSs. The Wide1, Wide2, and Deep1 architectures scored highest in the training phase in all TSs. The reflexivity pairs in the LS reached around 50%, while it was above 90% in transitivity for Wide1, Wide2, and Deep1 architectures. The OTM and MTO test pairs performed the lowest, in contrast to the LS.
There was a performance difference for both reflexivity and transitivity in the LS, which was superior to MTO and OTM. An exploration of the evaluation for stimulus-separated reflexivity pairs is presented in
Table 4 and shows that the performance was different for Stimulus Member B in all four classes of the reflexivity evaluation. In the Wide1 and Wide2 architectures, the performance was 100%; in Deep1, it was lower; in Deep2, it was 0%. For the transitivity pairs,
Table 5 shows the performance separated by pairs. Wide1 and Wide2 achieved transitivity for AC pairs, but not for CA pairs. Deep1 achieved partial performance on transitivity for different classes, and Deep2 did not perform on transitivity.
The data suggested differences according to the type of TS. In MTO and OTM, there was no evidence of the emergent relations of reflexivity or symmetry, in contrast to the LS in the Wide1 and Wide2 agents. As described by Arntzen [
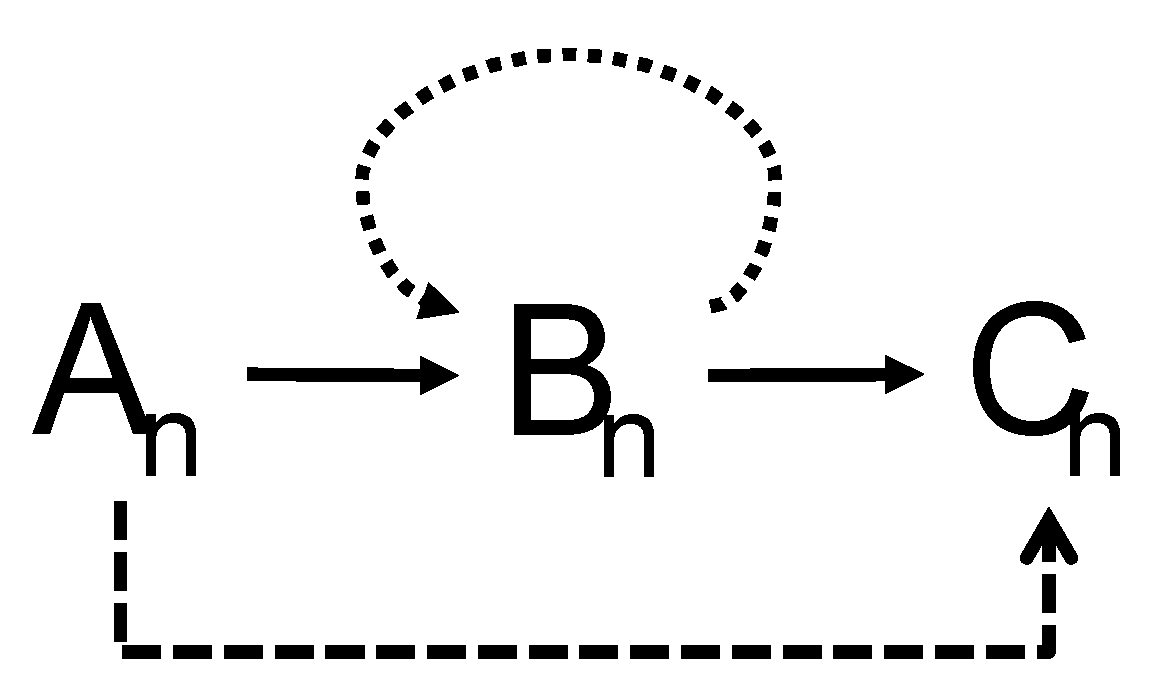
5], the B member stimulus in LS training trials acts as a comparison in the pair AB and as a sample in the pair BC. This change of position during training could be mapped as an abstract feature by the ANN, which allows it to establish the emergent relation of reflexivity (B–B) and transitivity (A–C), as shown in
Figure 4. It is said that an equivalence class has been established when the emergent relations of reflexivity, symmetry, and transitivity are manifested [
4], independent of the TS. However, the evaluation of the whole set of emergent relations in our ANN agents showed that these requirements were not fulfilled, despite partially manifesting the emergent relations of reflexivity and transitivity.








{kind=link}
{kind=link}
{kind=link}
{kind=link}