1. Introduction
Brain–computer interfaces (BCIs) are an emerging field of technology that combines and allows the connection between the brain and a computer or other external devices. BCIs have the potential to revolutionize the way humans interact with machines, opening countless possibilities both in medical and nonmedical domains. In the medical field, it can help people suffering from locked-in syndrome to communicate [
1]. Moreover, brain–computer interfaces (BCIs) are displaying potential in the realm of neuroprosthetics, offering the prospect for individuals with limb amputations or paralysis to command robotic limbs or exoskeletons through their brain signals [
2]. In epilepsy management, BCIs are researched for real-time seizure detection and intervention, potentially mitigating the impacts of seizures [
3]. In the nonmedical domain, an EEG BCI has applications in areas such as gaming where players can play a game using only their thoughts [
4] and in fields such as entertainment where users can control drones or other robotic devices [
5].
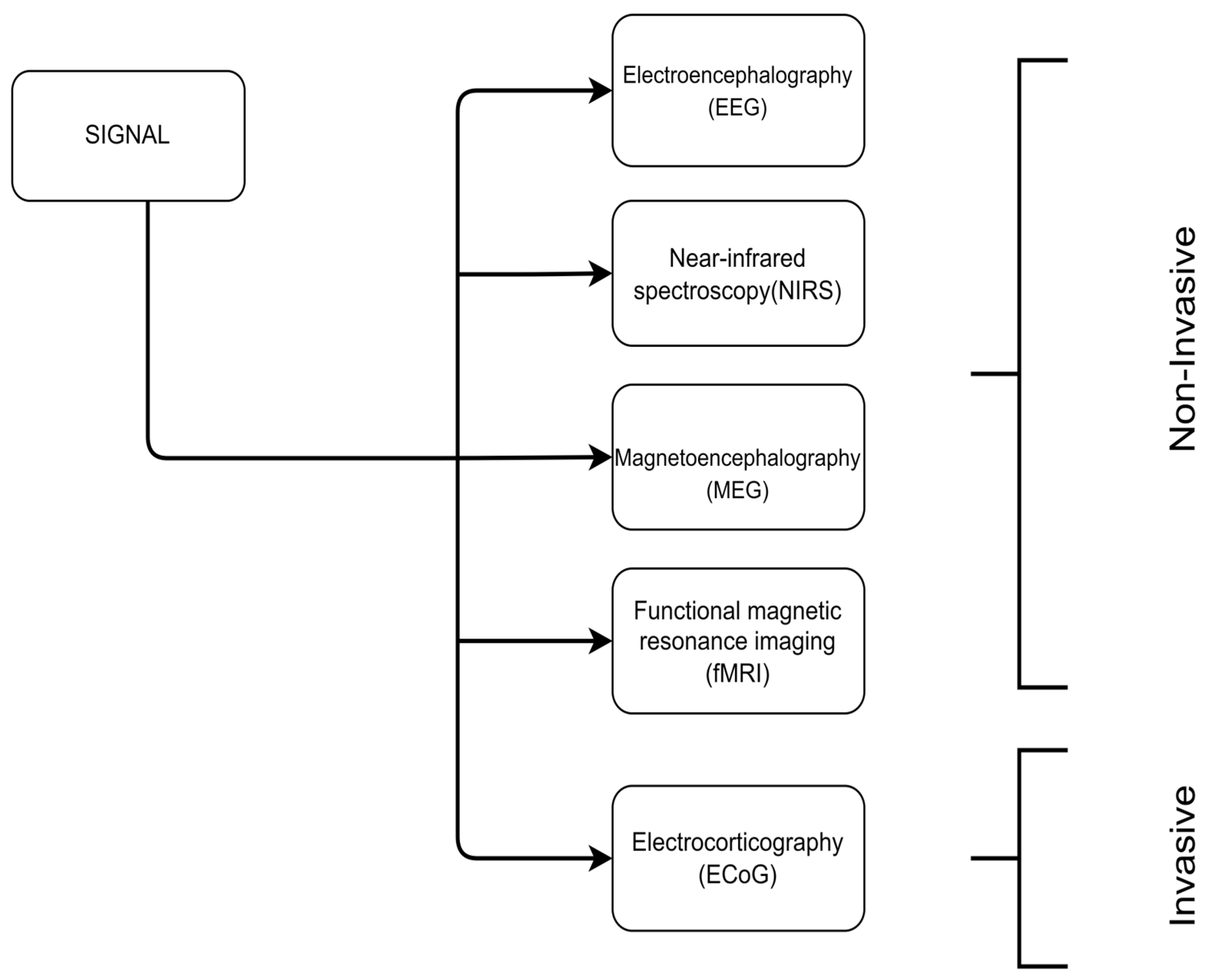
There are several methods and techniques used in BCI research (
Figure 1). These methods can be categorized based on their degree of invasiveness as invasive and noninvasive. Invasive methods require physical access to the brain and include ECoG (electrocorticography) [
6], which is the process of recording electrical activity in the brain by placing electrodes in direct contact with the cerebral cortex or surface of the brain. Noninvasive techniques do not require any type of surgical operation and can be further discriminated into (a) fMRI (functional magnetic resonance imaging), which measures the brain activity by detecting changes associated with the blood flow [
7], (b) MEG (magnetoencephalography) [
8], which is the measurement of the magnetic field generated by the electrical activity of neurons, (c) NIRS (near-infrared spectroscopy) [
9], a brain imaging method that measures light absorbance to calculate oxyhemoglobin (oxy-HB) and deoxyhemoglobin (deoxy-HB), which provides an indirect measure of brain activity, particularly in the frontal cortex, and (d) electroencephalography (EEG), [
6] which is this paper’s subject and refers to the measurement of the electrical activity produced by the brain by placing electrodes to the subject’s scalp.
Although there are disadvantages in EEG-based BCIs compared to other techniques [
10], such as a low signal-to-noise ratio, a low spatial resolution, and variability in the signal quality due to artifacts, their portability, cost-effectiveness, noninvasiveness and high temporal resolution make them the most spread method for BCI applications.
There are a lot of approaches to further categorize EEG BCIs. Authors in [
11,
12] further categorize BCIs based on the user’s activity during the signal acquisition as passive/active. Other approaches are based on the stimuli needed for the activation of the BCI [
13], which group noninvasive BCIs into evoked (also referred as exogenous) or spontaneous (also referred as endogenous). Another work [
10] categorizes BCIs based on the ability of the system to respond on a specific time-window called synchronous or asynchronous.
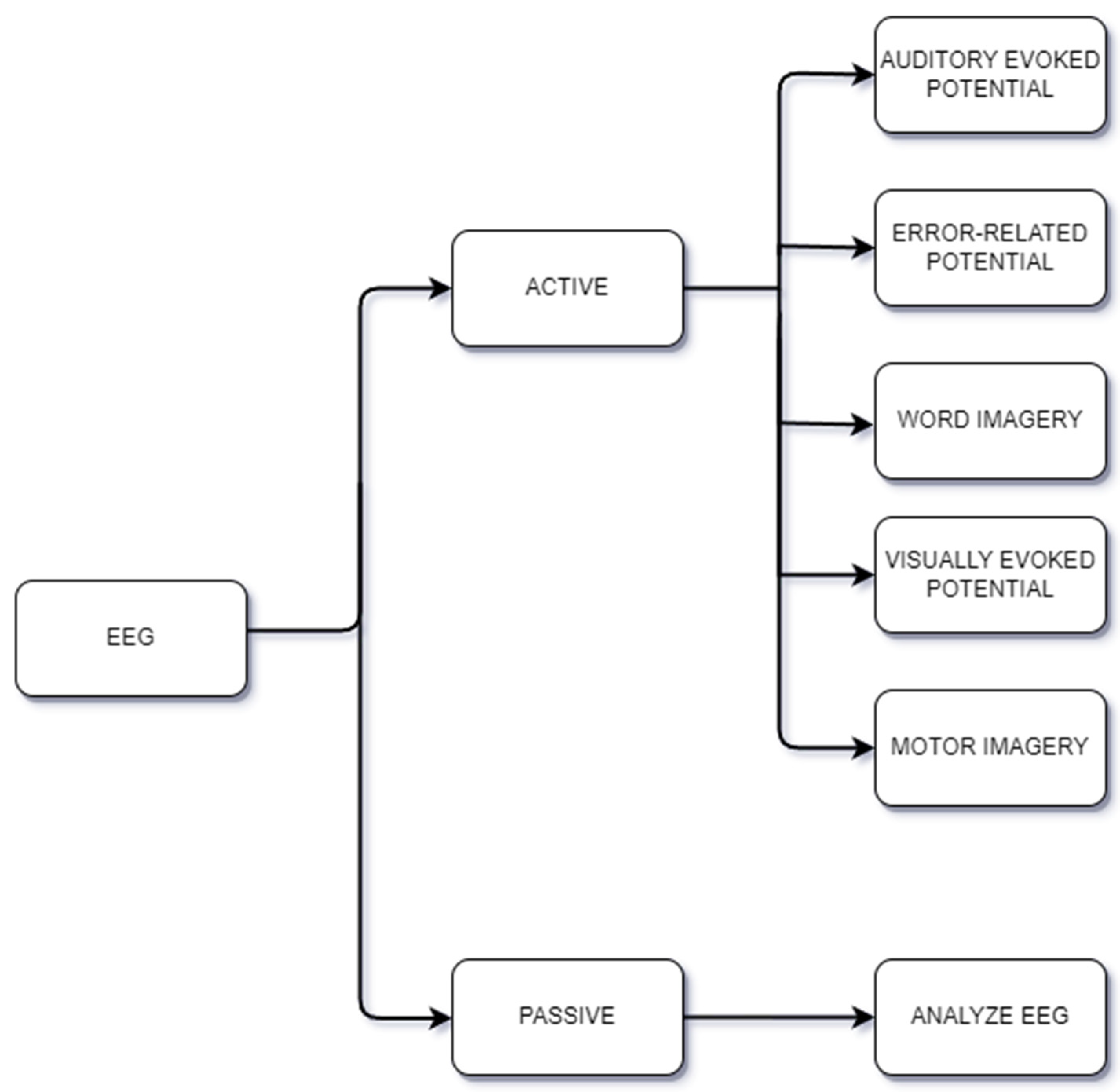
In the active/passive approach (
Figure 2), the term “Passive” refers to situations where the user is either at rest or involved in a task, and brain activity is being measured. The term “Active” refers to the situation where brain activity is measured while the user is carrying out specific tasks or actions. For example, in motor imagery, the user thinks about performing physical movement without actually performing the movement. On the contrary, in the word imagery paradigm also referred to as imagined speech, the user is required to think about certain words, while visually, auditory, and vibrotactile evoked-potential paradigms involve the measurement of brain activity in response to an external visual, auditory, and vibrotactile stimuli, respectively. Some applications of passive EEG BCIs are measuring the subject’s emotion [
14], cognitive load [
15], and attention [
16], while active EEG BCIs have been used to control a cursor on a computer screen [
17], moving a robotic arm [
18], or even helping patient rehabilitation after a stroke [
19].
A typical pipeline for an EEG motor imagery (MI) BCI application involves several stages (
Figure 3). The first stage concerns the signal acquisition, whereas the subject is instructed to imagine a motor movement while their brain activity is measured using EEG. The next stage is signal preprocessing, where several different techniques are used to filter and enhance the quality of the signal. Afterwards, feature extraction is performed, where the processed signal is further analyzed to extract relevant features. These features are then subjected to feature selection, where the most relevant features for the application are identified. Finally, classification is performed using machine learning algorithms to classify the data into different categories, such as left- or right-hand movement, and turn these categories into machine instructions, such as moving a cursor in a 2D space, etc.
The success of this pipeline depends not only on the optimal selection of signal processing techniques, feature extraction methods, feature selection algorithms, and classification models, but also on the user’s ability to consistently generate distinguishable brain patterns [
20].
Electroencephalogram (EEG) signals, captured noninvasively through electrodes on the scalp, are electrical patterns reflecting the synchronized firing of neurons in the brain. This technique has high temporal resolution, enabling researchers and clinicians to monitor real-time brain activity with millisecond precision. Although EEG signals are considered 1D-signal EEG recordings, they yield time series data, where the x-axis represents time, while the y-axis represents the electrical activity observed at each electrode. Time series data can undergo different transformations to be reshaped into 2D or 3D formats, with one common approach involving the creation of 2D images by incorporating time–frequency information.
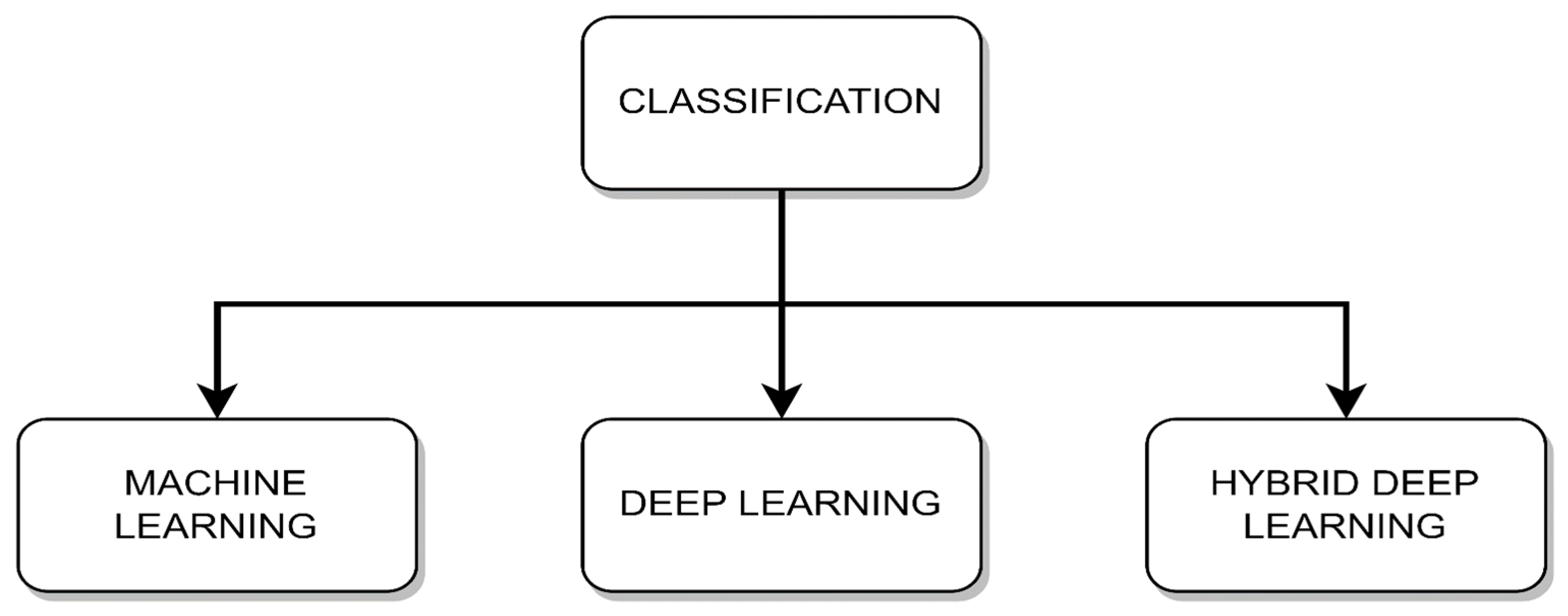
Data classification typically involves one of the following three categories: machine learning, deep learning, and hybrid deep learning as shown in
Figure 4. Machine learning provides strong statistical methods for smaller datasets, while deep learning uses neural networks for complex patterns in larger datasets. Hybrid deep learning merges the two previously mentioned methods, extracting benefits from each method to solve problems more effectively.
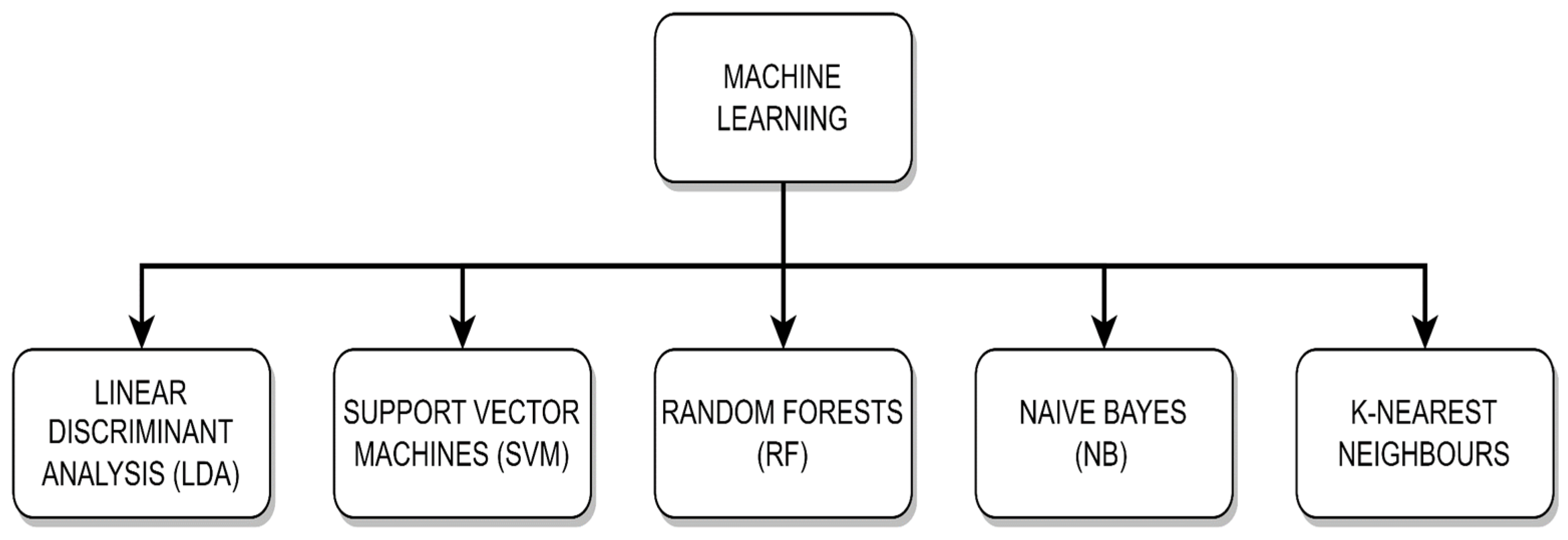
Traditional machine learning is a subfield of artificial intelligence that involves the development of algorithms which can learn from and make predictions or decisions based on data. Unlike deep learning, which requires large datasets and focuses on artificial neural networks, traditional machine learning techniques often work well with smaller datasets and include methods, as shown in
Figure 5, such as decision trees, support vector machines, and linear discriminant analysis. These algorithms build models by analyzing input data features and finding patterns or statistical relationships, which can then be used to make predictions on new, unseen data.
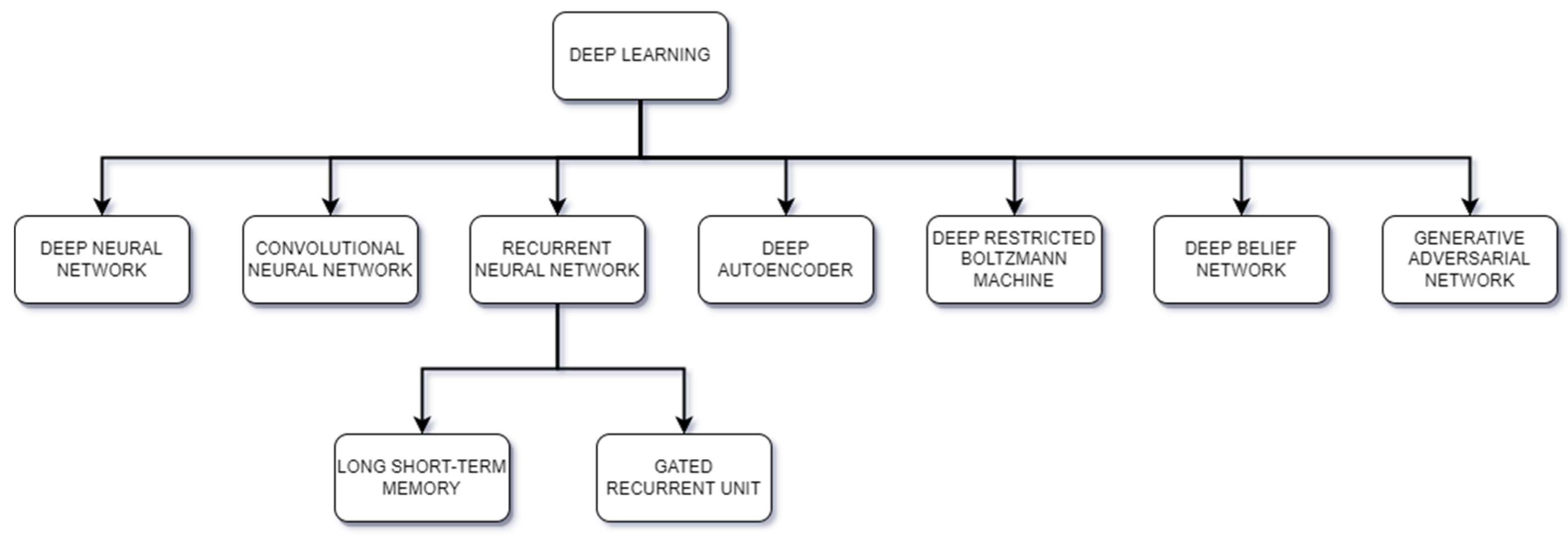
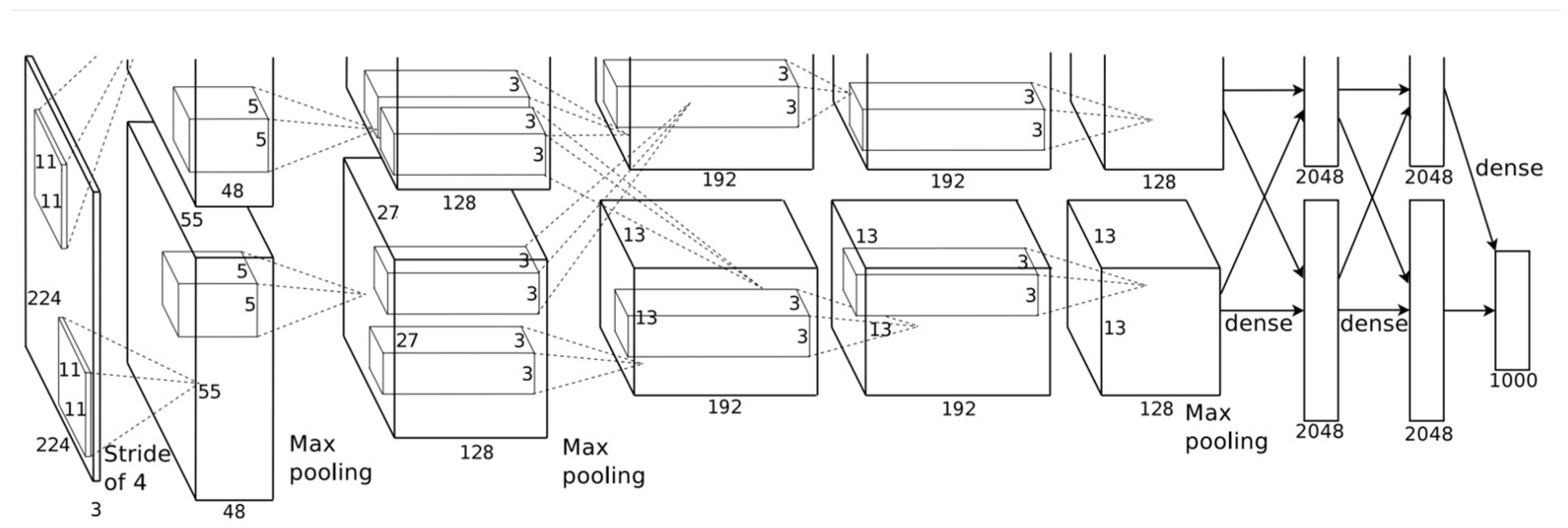
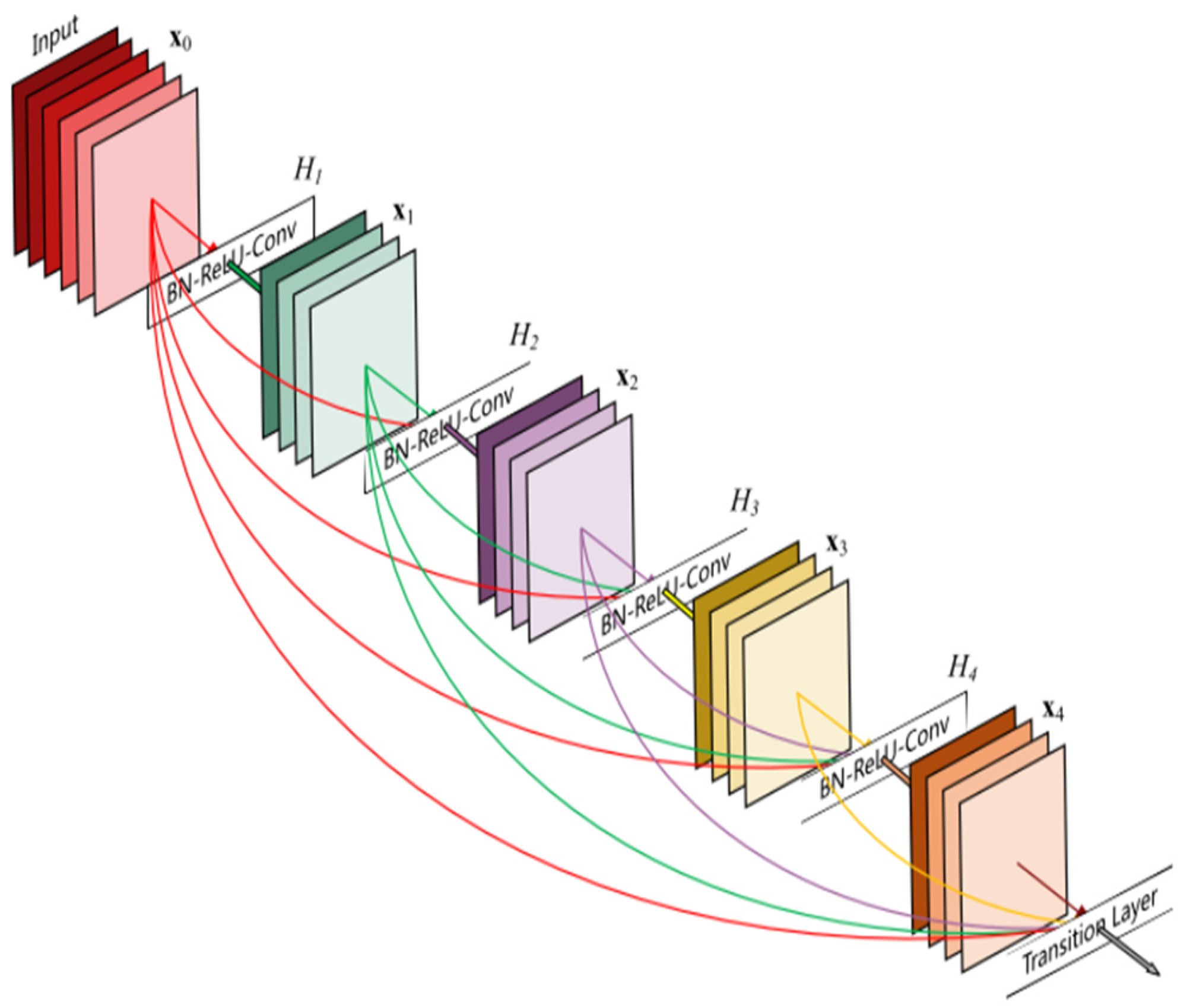
Deep learning has recently become a key component in the development of numerous industries, from healthcare [
21] to computer security [
22,
23,
24,
25,
26]. Deep learning, a subfield of machine learning, excels at managing high-dimensional and complex datasets. Its capacity to represent complex patterns using neural networks with numerous layers has revolutionized a variety of applications, including image recognition [
27], natural language processing [
28], and the diagnosis of medical conditions [
21]. Deep learning has the ability to learn representations directly from the input data, without relying heavily on feature engineering, which is often required in traditional machine learning. Through multiple layers of artificial neural networks, deep learning algorithms can automatically learn hierarchical representations, where initial layers often capture low-level features and deeper layers capture more complex and abstract features. This capability to automatically extract and learn features from raw data is a major reason why deep learning has been successful in numerous fields. Deep learning can be categorized into two main groups, deep learning and hybrid deep learning; deep learning includes models such as transfer learning, convolutional neural networks, and recurrent neural networks, as shown in
Figure 6.
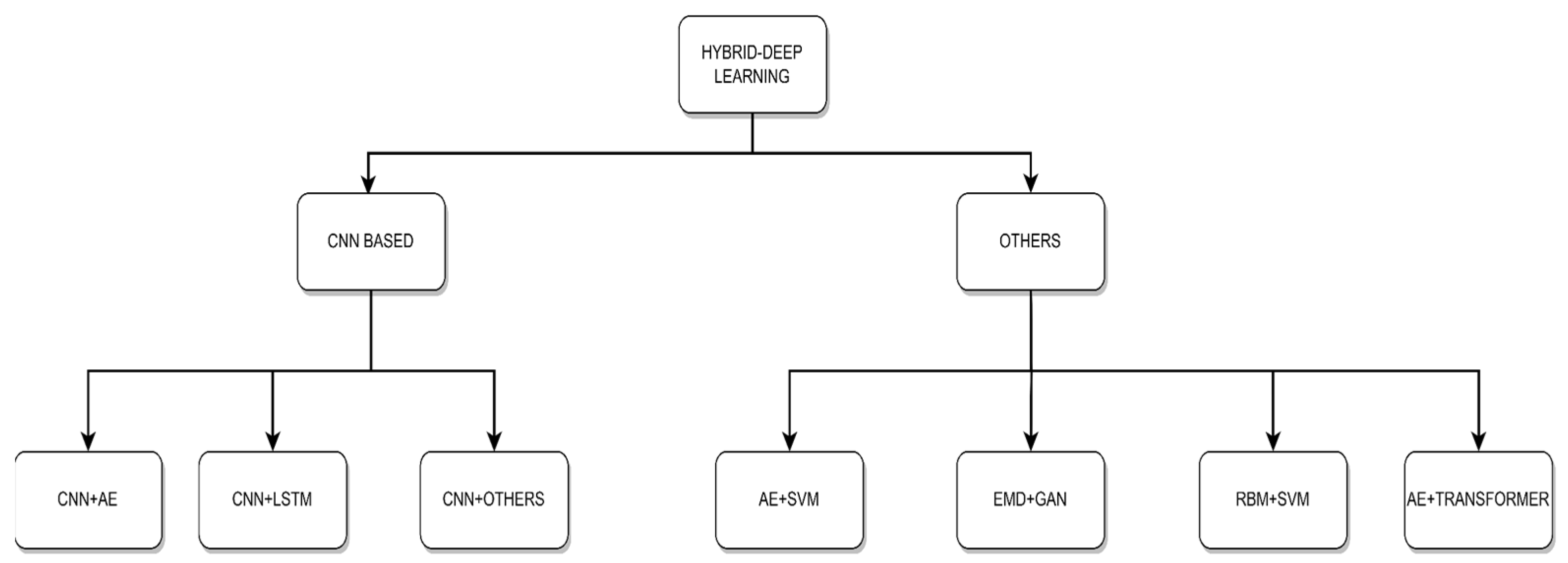
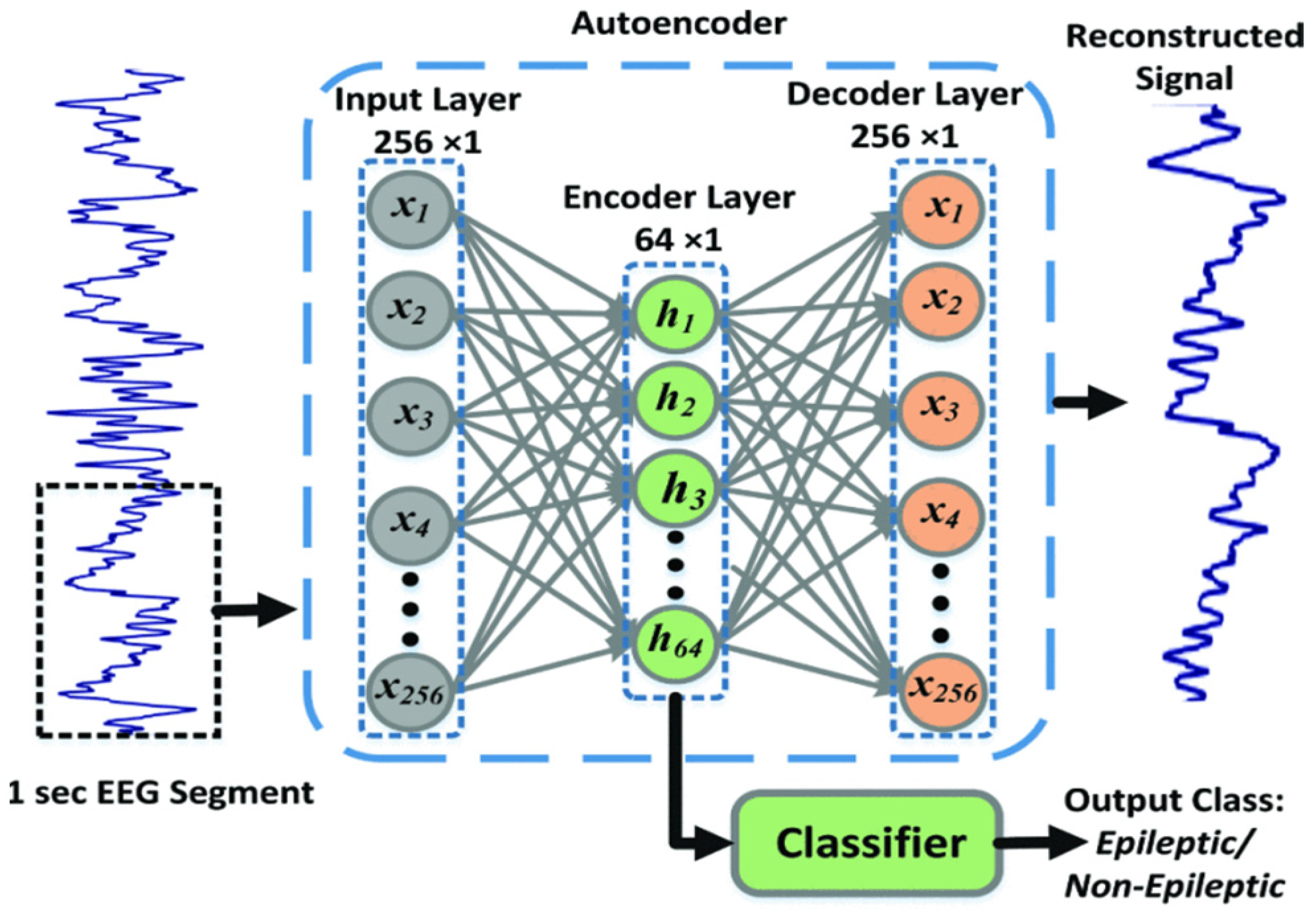
Recent advancements have led to the fusion of deep learning and machine learning techniques, the so-called hybrid deep learning, as shown in
Figure 7. Deep learning techniques such as convolutional neural networks typically serve as a feature extractor from raw data, while machine learning methods techniques serves as a classifier. This hybrid approach leverages the strengths of both methods, creating more effective and interpretable models.
Several review papers have been published on the subject of EEG BCIs, but they are either outdated [
13,
29,
30,
31] or focus on specific methods [
32,
33,
34,
35,
36,
37,
38]. For example, the authors in [
33,
34,
35] provide a significant review but they do not explore the current trends such as deep learning methods. In [
36,
37], the authors focus only on deep learning methods and in [
38], Habashi et al. examine only the proposed methods that involve generative adversarial networks (GANs). Finally, Rajwal et al. [
32] focus on the state-of-the-art methods that deploy CNNs.
While some of the aforementioned review papers report state-of-the-art deep learning methods, they overlook the current research trend, i.e., hybrid deep learning techniques. This could be attributed to the fact that both the field itself and the application of deep learning within it are relatively new and rapidly evolving. In this review, our aim is to address this gap. We provide a comprehensive survey of the entire EEG BCI motor imagery system pipeline, focusing on deep learning methods and placing a particular emphasis on these emerging hybrid deep learning methodologies. Furthermore, we present an in-depth evaluation of the most commonly implemented algorithms in the field, assessing their accuracy and computational efficiency. By doing this, we offer an up-to-date and detailed perspective on this exciting and fast-growing area of research.
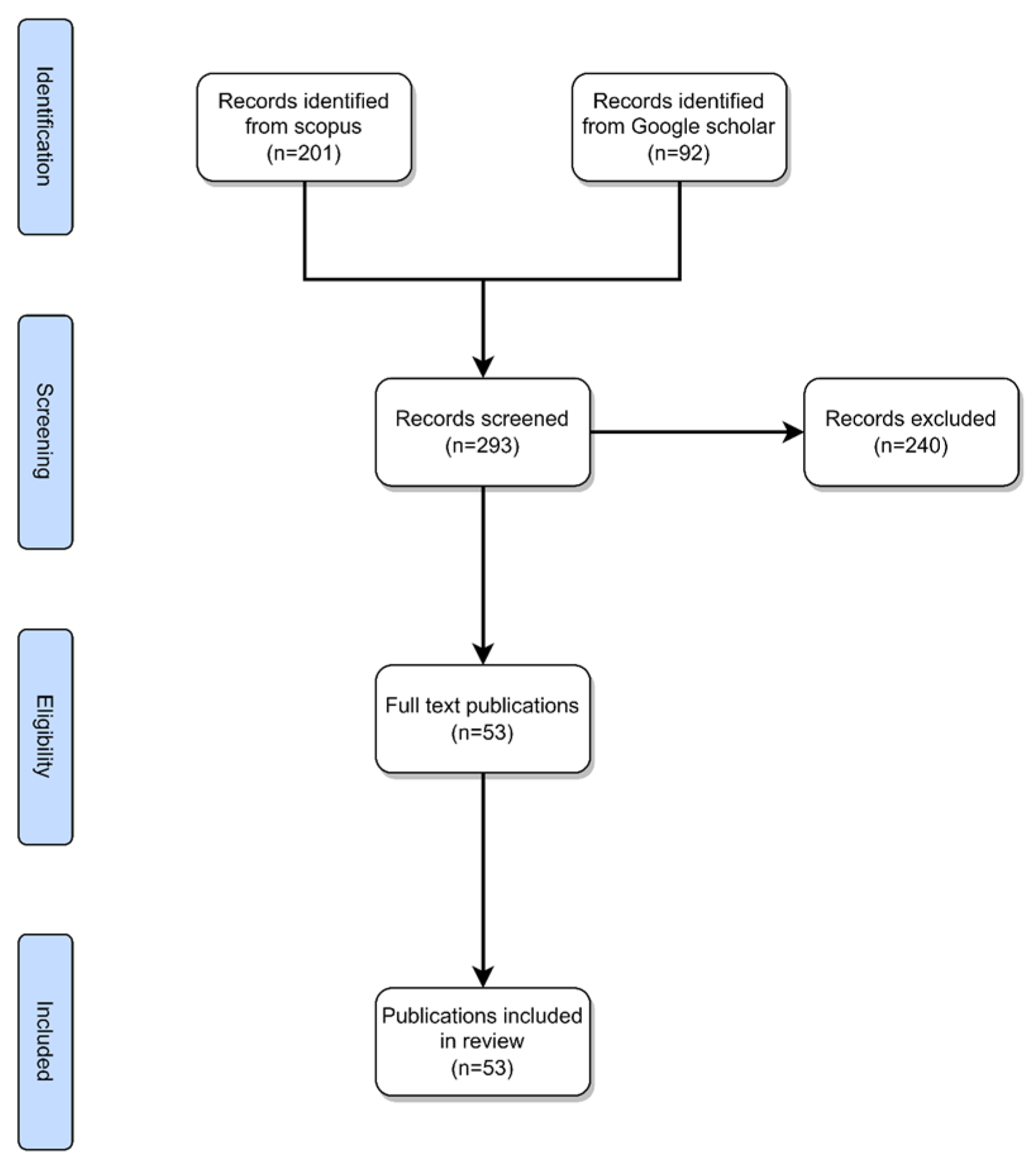
Scopus and Google Scholar were utilized as the electronic databases to retrieve the articles. This review includes articles related to the following keywords: (1) “EEG” or “Electroencephalogram” or “electroencephalography”, (2) “MI” or “Motor Imagery”, (3) “DL” or “Deep learning”. The Scopus database returned 201 results while Google Scholar returned 92 results adding up to a total of 293 results. From the returned results, we excluded duplicate papers and papers that were not relevant to the review, such as papers that included hybrid methods of signal acquisition, papers that did not utilize deep learning architectures, and papers with similar architectures, methods, and accuracies. After these filters were applied, the number of screened papers was 53 as shown in
Figure 8.
The rest of this paper is organized as follows, in
Section 2, “Datasets”, we present all the publicly available datasets that contains motor imagery tasks and relevant information about the datasets.
Section 3, “Deep learning”, includes the deep learning architectures used in the literature for motor imagery brain–computer interfaces. In
Section 4, “Hybrid deep learning”, we review the hybrid architectures that contain a combination of machine learning and deep learning architectures to tackle the problem. In
Section 5, “Discussion”, we provide our conclusions and insights from the reviewed papers, and we provide directions for further research.
5. Discussion
This literature review provides a comprehensive overview of the flourishing research landscape within the realm of brain–computer interfaces (BCIs) utilizing electroencephalograms (EEGs), with a specific focus on the motor imagery paradigm. Notably, the integration of deep learning methodologies, particularly convolutional neural networks (CNNs), has emerged as a prominent and successful approach, yielding notable improvement in terms of accuracy rates when applied to relevant datasets. It is imperative to acknowledge that the efficacy of deep learning and hybrid deep learning, comes hand in hand with the substantial computational power it demands, thereby signifying a notable cost implication. The complex nature of CNN algorithms necessitates a substantial volume of training patterns, ranging from tens of thousands to even millions in certain instances, to facilitate an optimal performance and robust generalization. Complex algorithms benefit from extensive and robust datasets, with the BCI competition IV-2a dataset serving as a key reference point for researchers. However, the EEG-based BCI field urgently requires more comprehensive and larger public datasets to propel progress and innovation. While combining datasets may seem like a viable solution to enhance dataset size, the diverse sampling rates, electrode configurations, and motor imagery tasks across different datasets present integration challenges. To address this, some researchers turn to data augmentation techniques, such as utilizing GANs, to artificially expand dataset size. This not only helps prevent overfitting but also enhances model resilience, particularly in the presence of real-world environmental noise, resulting in more robust and practical EEG-based BCI models. Besides the requirement for large datasets, these complex algorithms also require a vast amount of computational power and time to train. For this reason, some authors such as Zhang et al. [
61] have addressed this problem by using techniques such as pruning, to reduce the amount of time needed to train the network. As the field advances, it becomes imperative to not only address the computational demands of these intricate architectures but also to simultaneously enhance their efficiency and real-world applicability.
Within the realm of brain–computer interface (BCI) research, a consistent pattern emerges: the notable increases in accuracy can predominantly be attributed to the initial stages of preprocessing and the extraction of relevant features. This encompasses activities such as enhancing signals and exploring the time–frequency domain. This pivotal preparatory phase, which involves refining raw signals and extracting informative features, stands as a pivotal factor in achieving substantial progress in accuracy across various algorithmic approaches, which can be seen in Korhan et al.’s paper [
64], which compares the same network architecture with different feature inputs.
The concept of “BCI illiteracy” [
20] holds some significance. BCI illiteracy refers to the challenge that some individuals may face in effectively modulating their brain activity to produce distinguishable patterns during motor imagery tasks. This phenomenon can stem from various factors, such as a lack of familiarity with the task, insufficient cognitive engagement, or physiological variations that affect EEG signals. Addressing MI illiteracy is essential in designing inclusive and accessible BCIs, necessitating personalized training protocols, task adaptations, and innovative algorithms to accommodate users with varying levels of proficiency in generating discernible MI-related EEG patterns.
In the realm of motor imagery (MI), the number of commands that can be reliably extracted is inherently limited, as can be observed by the dataset’s distinct classes. This limitation arises due to the finite nature of distinct motor imagery tasks that users can effectively perform and differentiate in their mental simulations. The challenge lies in striking a balance between expanding the range of commands for diverse applications and maintaining a manageable set of tasks that users can consistently generate through mental imagery. This constraint underscores the importance of thoughtful task selection and user-centric design in the development of effective systems within the MI paradigm.
Finally,
Table 10 offers a comparative analysis of the aforementioned algorithms, showcasing their respective strengths, weaknesses, and prospects for future research.
6. Future Research Directions
The consideration of computational time in real-time applications is crucial when evaluating machine learning and deep learning techniques. While deep learning indeed achieves elevated accuracy rates, the question of whether the benefits outweigh the computational burden becomes paramount. Although the inference of DL is quite fast and can be considered as real time, DL intricate architectures demand significant computational resources. That is, very powerful computers (in terms of processing power, memory, GPUs) are needed to train DL models, typically in a significant time. Balancing the pursuit of accuracy with the deployment of DL models that need less resources and less time to train remains a pivotal challenge.
The transition from a controlled lab environment with stable patients to a real-time application in a dynamic real-world setting introduces a notable shift in challenges. In the real environment, various types of noise can infiltrate the EEG signal, factors such as environmental interference, movement artifacts, and physiological variations. These noise sources can significantly degrade signal quality, making accurate interpretation and classification more difficult. Therefore, addressing the complexities of the real-world research field necessitates increased attention and consideration.
The dataset’s diversity and quality are crucial aspects, encompassing a range of characteristics specific to each dataset. Nevertheless, the absence of a standard benchmark dataset presents a notable constraint. This gap could potentially be mitigated through augmentation methods, including artificial augmentation. By layering additional variations onto existing data, these techniques aim to expand the dataset’s horizon, simulating diverse real-world scenarios. However, it is crucial to recognize that artificial augmentation might fall short in fully replicating the complexities of human experiences and interactions. Moreover, uncertainties persist regarding the exact conditions under which the experiments are conducted, adding an additional layer of complexity to the datasets.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}