1. Introduction
Urbanization is one of the greatest challenges faced by humanity in the coming years. As of 2007, more than half of the world’s population lives in cities, and this proportion is expected to increase even further in the future [
1]. In particular, cities in the Global South (Africa, Asia, and South America) are characterized by a rapidly increasing number of inhabitants, creating considerable problems for the infrastructure in the respective cities [
2]. These problems are particularly evident in so-called “slums”, in literature often referred to as “informal settlements”. There are many discussions in the literature about these terms and the transferability of definitions to different regions (cf. Hofmann et al. [
3]). In this context, we generally speak of settlements of the urban poor [
4,
5]. According to the United Nations (UN), “a slum household is defined as a group of individuals living under the same roof lacking one or more of the following conditions: access to improved water, access to improved sanitation, sufficient living area, and durability of housing” [
1]. In this paper, we investigate “slums” (according to the definition of the UN), knowing that the morphology and structure of these settlements can be very different worldwide [
6]. The UN estimates that about one billion people worldwide currently live in slums. This number is expected to double or even triple by 2050 [
7]. These settlements are often undersupplied in terms of water, energy, and sanitation, which leads, among other things, to an increased mortality rate among children, as well as negative consequences for the mental and physical health of the residents [
8,
9,
10]. Therefore, it is very important to improve the living conditions of these people. This objective has consequently been included in the UN’s global goals for sustainable development. For this purpose, it is important that we gain an understanding of slums and their development. Slums have been studied in the literature in many ways. In different qualitative studies, aspects of the life of the residents such as health [
11], sexual behavior [
12], living situations [
13], and their connections [
14] have been examined in different ways. It is necessary to collect information about slums and to analyze possible reasons for slum development to identify future scenarios and create holistic solution strategies [
15,
16] to solve the problems related with these settlements. Identifying factors that correlate with strong slum growth can help us to understand the underlying processes of slum growth better.
In the literature, many different factors have been described which were identified as leading to slum development. Mahabir et al. [
17] mention four factors influencing the growth of slums. These are (i) location choice factors; (ii) rural-to-urban migration; (iii) poor urban governance; and (iv) ill-designed policies. Roy et al. [
18] define the following seven factors: population dynamics, economic growth, housing market dynamics, informal economy, local topography, street pattern, and the politics of slums. While some of these previously mentioned factors primarily relate to local conditions (e.g., streets or local topography), others have economic and demographic roots. Current methods of slum modeling follow a bottom-up approach. They are mostly agent-based or work with geographic information systems, like the
informal settlement growth model [
19] or
slumulation [
20]. A detailed review of these models can be found in Roy et al. [
18].
In contrast, this work attempts to investigate slum development based on country-level information [
21]. We use data mining methods to analyze to what extent economic, demographic, and other factors correlate with slum development, and how the development can be validated quantitatively. Thus, we address the following research question in this paper:
RQ:Which national indicators correlate with a high growth of urban slum population?
To answer this question, we apply commonly used data mining methods to data taken from the
World Development Indicators (WDIs ) of the World Bank [
22], which has been collecting a large number of indicators annually from various sources.
Data mining methods have been frequently used in slum research in the context of remote sensing, as shown by detailed reviews [
23,
24]. Several studies have also investigated the correlation between the proportion of the urban population living in slums with other factors, such as infant mortality [
25] or CO
2-emissions [
26]. The World Development Indicators provided by the World Bank have often been used as a database in these studies [
22]. However, no study is known to examine the World Bank data set as a whole using data mining methods to investigate relationships between the growing number of slum dwellers and other factors.
The procedure to address the research question is as follows: After introducing the used data set (
Section 2.1), we briefly describe the framework applied within this work (
Section 2.2), then present the methods of machine learning and evaluation used for the survey (
Section 2.3). After presenting the results of the study (
Section 3), we finally discuss these results (
Section 4) and close with an outlook on possible future work (
Section 5).
3. Results
We describe the results of our study in the following section. We first present two models for a timestep of 10 years, followed by the evaluation results for the three investigated classification methods. Furthermore, we describe the main findings of the learned models. Afterwards, we show indicators with a high correlation to slum development based on the three different approaches to attribute evaluation.
3.1. Classification Models for Slum Development for a Timestep of 10 Years
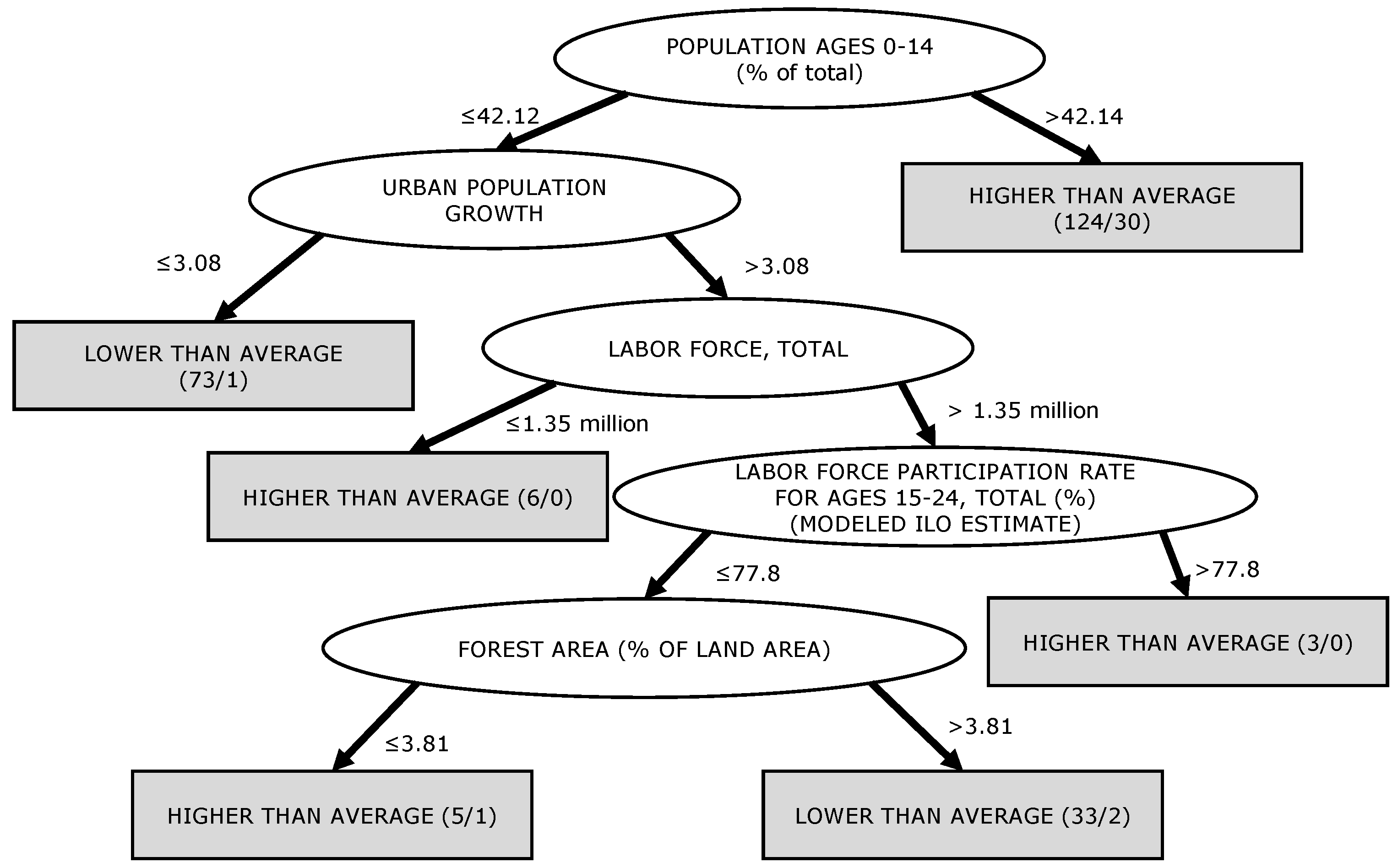
When looking at the model found with J48 for a timestep of 10 years (
Figure 2), the first and second nodes contained demographic aspects, like the proportion of the population with ages between 0–14 and the total urban population. A high proportion of young people (more than 41.43 percent) correlated with a slum growth higher than average. If the proportion of young people was below the threshold mentioned above, the next node was to use the total urban populations as a decision criterion. The last two nodes were economic indicators. The import value index “is the current value of imports (c.i.f.) converted to U.S. dollars and expressed as a percentage of the average for the base period (2000)” [
22]. If this value was below 238.6, the slum growth was classified as lower than average. If it was above, the last decision criterion was the value of the adjusted net savings. For detailed information on the indicators, please see [
22].
In comparison to this J48 model, the model found with JRip was quite simple (cf. Decision Rule 1). The only decision criterion was the “Fertility rate”. If it was higher than 5.15, the slum development was higher than average, if it was below this value, the slum development was lower than average. Even though this did not yield a perfect discrimination yet, additional factors were not considered to deliver further improvements in the prediction quality of the found rules.
| Decision Rule 1: Result for JRip for 10 year timestep. |
![Urbansci 02 00081 i001]() |
3.2. Analysis of Slum Development
Table 3 shows information about the data set as well as the results of the attribute evaluation. The number of available instances decreased with increasing timesteps. It can also be seen that the total number of slum dwellers within a country almost doubled within 20 years.
The results showed that the prediction accuracy of the different algorithms, measured as the share of instances classified correctly, varied between 68% and 84%. All learned models were clearly better than guessing of the largest class, which would have yielded only about 55% prediction accuracy, since the larger class had 55% of all instances (the exact values for each data set can be found in the fourth row of the table). We can also see that the random forest algorithm yielded the best results for all timesteps and both evaluation methods.
Comparing the evaluations in
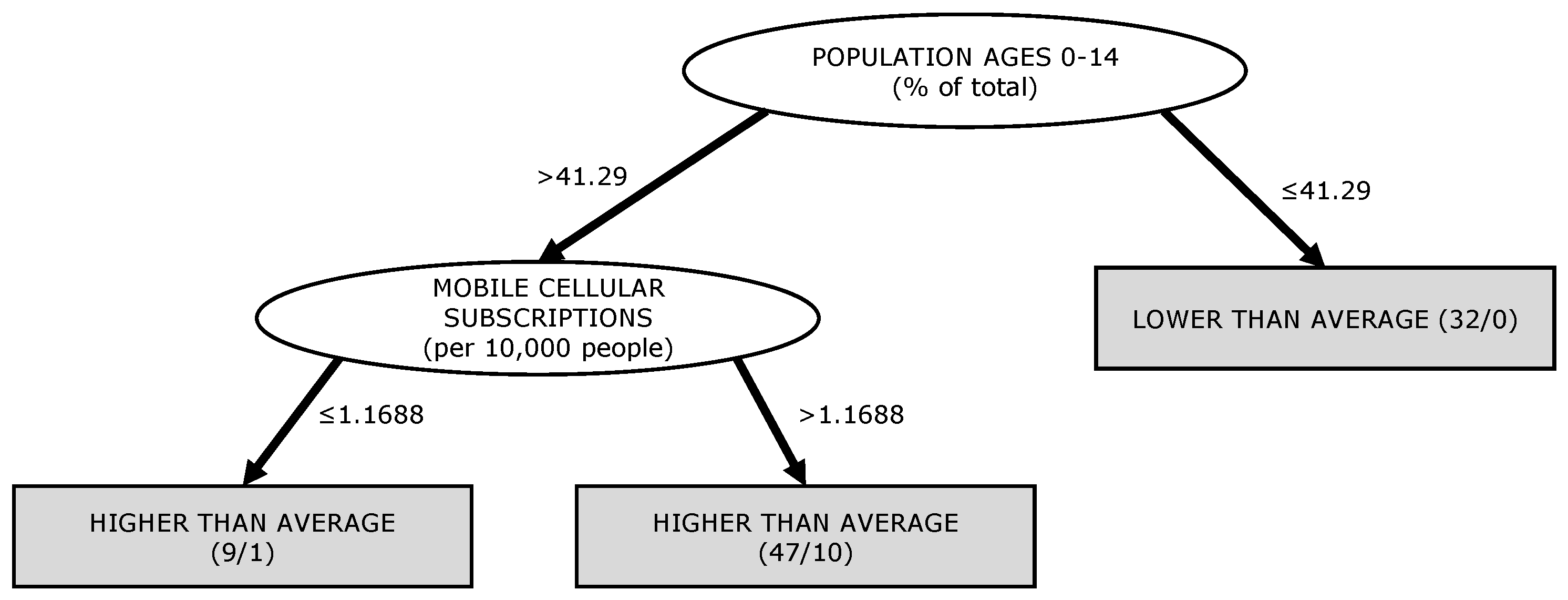
Table 3 for the different models, the prediction accuracy differed only minimally for the different timesteps. It was equally possible to determine whether a slum will grow at an above-average rate in 5 years or at an above-average rate in 20 years. However, the prediction models tended to become simpler, which became visible in various parameters that characterize the complexity of the learned models, such as the number of rules, the average number of conditions per rule, the number of nodes in a decision tree, or the maximum depth of the tree. The learned models for the timesteps of 5 and 20 years can be found in
Appendix A.
While the prediction for the five years has to distinguish many cases (several long rules or a larger number of nodes), in the long run (10 and 20 years) only a few factors are decisive for slum growth. This corresponds with few, short rules or a small number of nodes in the trees. Examining the determining attributes of the models (
Section 3.1 and
Appendix A), we find strong similarities. The largest groups were demographic attributes such as “Population ages 0–14”, “Urban population growth”, “Fertility rate”, etc. All three trees had the attribute “Population ages 0–14” as root nodes, and used this first query to assign a class directly to a subset (i.e., on one side the tree ended with a leaf and its related classification directly below the root). The thresholds of the decision variables were also similar and just over 40 percent. The rule set (JRip) for 10 years even consisted of only one rule with the attribute “Fertility rate”. There were also economic and agricultural factors, such as the “Crop Production Index”, “Import Value Index” and “Final Consumption Expenditure”, which often form a rule with demographic attributes or occur in subtrees caused by them. In addition, health problems (e.g., “Lifetime risk of maternal death”) occured as a factor.
3.3. Indicators with High Correlation to Slum Development
While the models shown above (
Section 3.1) give plausible explanations for slum growth and the opportunity to interpret the emergence of certain attributes, they do not provide a complete overview of the correlation ratio between each individual attribute and the target attribute. For this reason, we used the attribute evaluation algorithms presented in
Section 2.3.3 to evaluate the attributes according to their influence on certain questions.
In addition to information gain ratio, we also examined the correlation with the target attribute “slum development above or below average within 5 years” using the evaluation functions ReliefF and random forest evaluation.
3.3.1. Information Gain Ratio
The results for the information gain ratio evaluation are shown in
Table 4.
For all three timesteps—5, 10, and 20 years—the top five attributes were almost exclusively related to demographic characteristics. It can be seen that the composition of the population from different age groups had a very large influence on whether the slum development was above or below average. Even if the information gain ratio values did not give us a formula for the type of influence, we can see from the models shown in the
Appendix A how the attributes influenced the slum development. Thus, we see that “Population ages 0–14” above approx. 41% led to a classification for a slum development “higher than average” in all three decision trees. In addition, the information gain ratio increased by up to 50%, but at least by 30%, when jumping from 10 to 20 years. This explains why our models were able to keep the prediction accuracy at 80% with fewer rules/nodes. This increase was also visible in the prediction accuracy of the root nodes (
Appendix A). For the timesteps 5 and 10 years, the classification was successful in 75.81% and 70.69% of cases, respectively, due to “Population ages 0–14”. At 20 years, all classifications based on this attribute were correct, and the threshold was very similar each time.
3.3.2. ReliefF
Applying the ReliefF method to the described data set offers new aspects about slum development, reaching beyond the two areas of demography and health that dominated the previous analyses. As shown in
Table 5, only three of the top 10 ReliefF attributes related to these two areas, whereas economic and infrastructural aspects made up the remaining 70%. These included indicators regarding tourism, patent and trademark applications, workforce structure, energy sources, and improved sanitation facilities. The reason for these strongly differentiating results lies in the criteria by which ReliefF rated attributes: attributes got a high ReliefF value if their values were similar for similar instances within the same class and were clearly different for similar instances in other classes. Since this property was not directly evaluated or used in learning rule and tree-based models, these attributes were rare in the models presented in
Section 3.1.
3.3.3. Random Forest
The Random Forest evaluation shown in
Table 6 is not as dependent on the data set as the other two evaluations since the attributes were evaluated for different subsets of the instances. Therefore, the instances listed here have a high information gain ratio for various subsets and generally correlated well with the target attribute. Again, we see some demographic and health issues, but also the nature of the country (“Forest area” and “Arable Land”) and absolute values like “Labor force, total”. However, the fact that the frequency of an attribute’s use in different models was counted also gives an indication of how well an attribute performed in context instead of in isolation. For example, the variable ”Forest area” is only ranked 369 in the information gain ratio table with an information gain of 0, whereas it appeares as the third most important variable here. This means that the attribute by itself does not correlate with the slum development, but it may often be helpful for discriminating between different slum types in certain areas of the instance space.
3.4. Comparison of Slum and Urban Development
With the high amount of demographic attributes correlating with above-average slum growth, the question arises as to what extent slum growth correlates with general urban growth. Even the models presented above (
Section 3.1) used demographic attributes to predict the current proportion of the population living in slums.
At the beginning, we also showed the relative city growth of the instances for which we calculated slum growth values. Now, we can judge whether the urban population is growing faster or slower than the average for individual countries. The considered timestep was 5 years. The average city growth in the observed countries was 18.63% (for slums: 12.90%), the average deviation was 6.45% (for slums: 13.72%). This means that on average the urban population is developing more strongly and more consistently than the slum population.
In
Table 7 we can see that urban and slum growth developed in a similar way in almost 80% of the countries. In just 20% of the cases, slum and urban development developed in different directions. In quantitative terms, this supports the statements that are frequently found in the literature [
23,
24]: looking at the development of slums in isolation from the development of the cities and countries in which they are located is insufficient. Most cases of above-average slum growth were accompanied by above-average growth of the urban population, and vice versa.
4. Discussion
Different reasons for the growth of slums are mentioned in the literature. The various factors are often discussed in qualitative terms. The results presented in this paper, which were determined using data mining methods, help to quantitatively describe these factors. The results show that demographic factors in particular correlated with above-average slum growth. Population dynamics are described in the paper by Roy et al. [
18] as the interplay of birth rate, mortality rate, and migration rate. This thesis can be confirmed and specified: especially the birth rate is part of many models, and has a very high information gain ratio. “Birth rate” was among the top 5 in the three investigated time spans (
Table 4). The top 5 included “Death rate”, “Life Expectancy at Birth”, “Fertility Rate”, and “Population Growth”. Both the “Birth rate” and the “Population ages 0–14” correlated very strongly with above-average slum growth, as shown in
Table 4. Since all decision trees had the same root nodes “Population ages 0–14” with a nearly identical threshold of around 40%, this can be used as a criterion to identify countries with a slum growth higher than average.
If this decision criterion is applied to all countries for the year 2016 (most recent data), 39 countries have a proportion of “Population ages 0–14” of 40% or more. Niger has the maximum with over 50%. Apart from Afghanistan, Iraq, and Yemen, all other 36 of these countries are located in Sub-Saharan Africa. This statement confirms forecasts that a large proportion of the slum population, especially in Africa, will grow at an above-average rate in the coming years [
43].
When analyzing the results of the model for J48 for a timestep of 10 years, we see that high population dynamic coupled with a growing economy (represented by the Import value index) led to an above average slum development. It is also interesting to note that the model of the classification algorithm was based on only one decision variable for a period of 10 years. Countries with a high “Fertility rate” (>5.15 births per woman) were classified here as countries with a high potential for above-average slum development. Although this statement also permits misclassification, it is related to the decision-variable “Population ages 0–14”, since a high “Fertility rate” usually leads to a high number of children, provided that infant mortality is not very high. If this classification (“Fertility rate” > 5.15 births per woman) is applied to the latest data, 13 countries with above-average slum growth are classified. Again, all classified countries can be found in Sub-Saharan Africa.
An analysis of “Fertility rate”, “Birth rate”, and “Population ages 0–14” depending on the regions mentioned above (
Table 1) confirm these results in
Table 8. All three parameters were significantly (at least 50%) higher than the values of the other regions in Sub-Saharan Africa. The second highest value was always found in the Middle East and North Africa, and the third highest in South Asia. A comparison of these values with the results of the slum growth models presented in
Section 3.1 shows that high slum growth is to be expected, especially in the latter regions. Thus, our models confirmed previous studies, such as those of Jorgenson and Rice [
25]. The corresponding values in North America, Europe, and East Asia were much lower and, according to the models presented, led to below-average slum growth, if slums existed at all.
The connection between “Fertility rate” and slum growth confirmed statements made before in other studies [
11]. As mentioned above, we cannot make any statements about causal relations, but only hypotheses about them. The high “Fertility rate” could be a consequence of poorer sexual education [
14] as well as a cause for the strong growth of slums. Both are probably correct at the same time. However, this is very likely not only the case for this example, but also with regard to other factors. There are complex interactions between the various factors and slum development.
Besides population dynamics, Roy et al. [
18] define economic growth as an important indicator for slum growth. Although there are no data on the ratio of economic performance in the cities compared to the whole country, we found individual indicators—mainly from agriculture or economy—having a high correlation with slum development. These includex “Cereal Yield” (rank 19, 13, 9), “Agriculture, value added” (rank 18, 38, 50), “Imports of goods and services” (rank 20, 15, 32), and “Merchandise imports” (rank 15, 12, 14). The here-specified information can be seen in the information gain ratio lists presented in
Table 4 for the specified rank for the timesteps 5, 10, and 20 years.
According to Roy et al. [
18] and Ezeh et al. [
8], informal economy is also a factor leading to slum growth. Information on this is included in the data set as the attribute “Informal Employment”, but does not appear in the models and is poorly evaluated by all three evaluation algorithms. This can be explained by the low number of data points related to this indicator in the dataset.
A limitation of the study presented is that relatively simple models were used. We were able to quantify thresholds within factors related to above-average slum growth, but could not quantify this further. This lack of an ability to identify causalities must be mentioned as another limitation of the study presented here. Although we found very detailed limits for the factors related to above-average slum growth (e.g., “Fertility rate” >5.15 births per woman), we could not make detailed statements about the magnitude of slum growth with the models used.
It should be emphasized that the connections presented here only show correlations and no causalities between slum development and other attributes. Further analysis from different fields (e.g., social science) is required to derive causalities from the identified correlations.
A disadvantage of the dataset used in this paper is the data availability at the country level. The indicators can therefore only be regarded at the national level and no city-specific statements can be made. Intranational differences that may occur in countries with a large number of cities (e.g., India, China, or Brazil) are lost through averaging. Hence, it would be interesting to expand this research at the city level and investigate data sets for different cities.
Despite these statements, the methods and results presented here can provide another element for identifying and quantifying processes and interrelationships in urban development. In the context of digitalization, more and more data are being generated which implicitly contain knowledge about the processes of urban development. In order to make this knowledge explicitly accessible, the data mining methods presented here are ideally suitable.
5. Conclusions and Outlook
The emergence of slums correlates with different factors. The presented work gives an interesting insight into how a country’s slum development can be predicted on the basis of certain attributes. In addition, the models analyzed are based on actual information about slum development at the country level, and thus have a statistical basis. In accordance with common literature, this study shows that demographic indicators are strongly linked with slum development. High population dynamics and a large proportion of young people correlate with a high slum development. According to our methods, the results showed that demographic aspects had the highest impact on slum development. It is an interesting finding that, more than birth or death rates, the proportion of children with ages 0–14 in the overall population correlated with slum development the most. The most recent data of the World Bank show that most of the countries fulfilling the conditions for slum growth above average are located in Sub-Saharian Africa. The composition of the population could be a more important factor than previously assumed. Furthermore, slum and urban growth are strongly linked, and need to be viewed as conditionally dependent on one another. This has to be considered in the development of slum models.
The methodology shown here is a proposal to obtain information about the current status of slums and to uncover correlations from the large amount of data about cities which are available to us today. This can result in recommendations for action to develop solution concepts for todays central tasks and challenges like the development of infrastructures for the urban poor.
In future research further data mining methods could be used to specify the findings presented here in order to determine the influence of the factors on slum growth in more detail and to better classify the magnitude of slum growth. In addition, the factors identified in this study can be used to make future data collection or surveys in the context of slum research more specific (cf. [
44]). Furthermore, they also could help in the design of better slum development models and to refine or improve current models (e.g., Patel et al. [
20], Roy et al. [
45]). Above all, however, it is appropriate to examine the presented connections together with other disciplines, such as the social sciences, in order to better understand the causes and effects of slum growth.








{kind=link}
{kind=link}
{kind=link}
{kind=link}

