1. Introduction
The pursuit–evasion game is a classic issue in robotics, in which one or more “pursuers” attempt to capture one or more “evaders” in different environments [
1,
2,
3,
4]. The traditional pursuit–evasion algorithms used differential game formulation for the modeling and analysis of the pursuer and evader [
5,
6,
7]. As the number of agents involved in the pursuit–evasion game increases, the complexity of the problem increases. Tian et al. [
8] proposed a distributed cooperative pursuit strategy for an evader in an obstacle-cluttered environment. Cheng and Yuan [
9] proposed a parameter-adaptive method to update the pursuit and evasion strategies when considering collision avoidance in the multiplayer. Sani et al. [
10] considered a pursuit–evasion game based on the nonlinear model predictive control in static obstacle environments, where the pursuer and the evader are nonholonomic mobile robots. The pursuit–evasion problem has a wide range of applications, including navigation [
11], surveillance [
12,
13], human–robot cooperation [
14] and robotic foraging behaviors [
15].
The problem of multiple evaders against a single pursuer requires the pursuer to capture multiple evaders in a finite amount of time. Therefore, the pursuer typically has some advantages over the evaders, such as faster speed, greater maneuverability, or more information about the environment [
16]. The main challenge for the evaders is to increase the survival time. One approach that has been developed to guide multiple evaders is to formulate them as a group moving together and following a single leader [
17]. Scott and Leonard [
18] analyzed a dynamic model of multiple heterogeneous evaders against a faster pursuer and presented pursuit and evasion strategies considering global or local detection. However, their study only considered collision-free obstacle environment. The LoS (line-of-sight) guidance principle has been widely used in the pursuit–evasion game due to its simplicity, intuition, and low computational burden [
19]. However, a singular escape direction may lead the evader to a local minimum constituted by obstacles in complex environments. Scott and Leonard [
20] proposed a strategy for evaders not initially targeted to avoid capture and considered the limited sensing condition through a local risk reduction strategy. However, they only considered that multiple evaders work in collision-free obstacle environments. Some studies focused on the influence of the obstacle in the pursuit-evasion game. The traditional methods impose some limitations to the physical states for both pursuers and evaders to formulate the game in a bounded area or obstacle environment. Fisac and Sastry [
21] proposed a two-player game where the obstacle is able to delay or avoid capture from the pursuer. Oyler [
22] considered the effect of asymmetric obstacles, where the obstacle has different influences on each player. Bhadauria and Isler [
23] considered a bounded environment with some static obstacles. When considering the effect of the obstacle, the visibility may not be full for the pursuer and evader. Wu et al. [
24] proposed a flock control algorithm that can guide swarming aerial vehicles with obstacle avoidance in a dynamic and unknown 3D environment. Dong et al. [
25] incorporated the artificial potential field method to design a collision-free evasion model. Oyler et al. [
22] proposed dominance regions to generate the evasion path considering the presence of obstacles. However, these studies often rely on assumptions about the behavior of the pursuer. These assumptions may not always hold in practice, which makes it difficult to develop strategies for unpredictable pursuit behavior.
Recently, the neural network approach has become a hot research topic [
26,
27]. Many studies considered using neural networks to deal with the pursuit–evasion problem. Qi et al. [
28] proposed a deep Q-network approach to guide the evader to escape from the pursuer based on a self-play mechanism. Qu et al. [
29] proposed a deep reinforcement learning approach to generate pursuit and evasion trajectories for unmanned surface vehicles. The proposed approach considered multi-obstacle influences in the water surface environment. Guo et al. [
30] proposed a neural network-based control method to ensure that the velocities of the pursuer and the evader converge to their desired values with unknown dynamics. However, pursuit–evasion games that use learning-based neural network approaches are not efficient and computationally expensive, especially in their initial learning.
This paper aims to provide a novel approach that approximates a general pursuit–evasion game from a neurodynamic perspective instead of formulating the problem as a differential game. In this paper, the neurodynamics-based approach aims to overcome the limitations of the traditional approach and improve the performance of evaders in dynamic and uncertain environments. A bio-inspired neural network (BINN) is applied to guide robots to evade a single faster pursuer in the presence of dynamic obstacles. Compared with existing research, the contributions of this paper are summarized as follows:
- (1)
The concept of a pursuit–evasion game with sudden environmental changes is proposed for the first time.
- (2)
A novel neurodynamic-based approach is proposed to approximate the pursuit–evasion game instead of formulating the problem as a differential game.
- (3)
A novel real-time evasion strategy is proposed based on the landscape of the neural activity without any learning procedures.
This paper is organized as follows.
Section 2 offers the preliminaries and a description of the problem.
Section 3 describes the proposed approaches to evasion.
Section 4 shows the simulation and experimental results involving different scenarios. In
Section 5, the results of this research are briefly summarized.
2. Problem Statement
For a group of m evader robots, their time-varying location in the workspace, W, can be uniquely determined by the spatial position, , . The time-varying position of the faster pursuer can be denoted by . Suppose the pursuer has full knowledge of the environment. However, the pursuer has no knowledge about the evasion strategy of evaders and their evasion directions. It is the same for the evader, which has full knowledge of the environment but has no information on the direction of the move and the pursuit strategy of the pursuer. Because the moving directions and strategies of the pursuer and evader are unknown to each other, the trajectories of the evader and pursuer are not able to predict depending on their kinematics model. Thus, the kinematics model of the pursuer and evader is not considered in this paper. In the workspace, W, there is a sequence of i obstacles, and their position can be denoted by , . The speed of moving obstacles can be denoted by . The boundary of the workspace is assumed to be a sequence of static obstacles. If the evader reaches the environmental limit, the evader is considered a collision with obstacles.
The speed of the pursuer is denoted by
, whereas the speed of the evader is denoted by
. Suppose that both the evader and the faster pursuer move with constant speeds. In the workspace,
W, assume that the pursuer captures the evader at position
f in limit time
T. The position of
f can be denoted by
. Position
f satisfies the following condition:
where
is the speed ratio of evader and the pursuer. The speed ratio plays an important role in the evasion task [
31]. If speed ratio
is very large, it means the evader can be easily captured by the pursuer. In this paper, the pursuer is faster than the evaders. Thus,
in all considerations. The purpose of evasion is to increase the total survival time
of evaders. Since the pursuer has full knowledge of the environment and the pursuer and the evader move with constant speed, the strategy of the pursuer is equivalent to a multi-target path planning problem [
22]. The number of evaders is greater than that of the pursuers; at each instant of time, the pursuer captures evaders based on the following sequence:
where
is the evader assigned for the pursuer to capture at the instant of time
t; and
is the Euclidean distance between the pursuer and each evader. The pursuer captures the nearest robot until all the robots are captured. If two evaders are equidistant from the pursuer, a random evader is chosen for one of them.
Therefore, the problem studied in this paper can be described as follows: for a group of m evaders and one faster-moving pursuer, given the initial positions of evaders with and with , the collision-free trajectories of robots are generated to increase survival time for the group of evaders. The evader is captured by a faster pursuer when the distance between the purser and the evader is smaller than capture distance .
Since several movable and sudden change obstacles exist in the workspace, the evaders should not only escape the pursuer, but also guarantee the evasion trajectories are real-time collision-free to obstacles. Note that the term “real-time” means that the response of the robot trajectory generator is instant to the dynamic environmental changes.
3. Proposed Approach
In the proposed approach, the environment is represented one to one by a neural network with only local connections. The evasion strategy is analyzed and designed from a neurodynamic perspective. The real-time collision-free evasion trajectories are generated through dynamics of neural activity.
3.1. Environment Representation via Bio-Inspired Neural Network
In this study, the fundamental idea is to construct a topologically organized neural network architecture in which the dynamic landscape of neural activity represents the dynamic environment. By properly defining the external inputs from the dynamic environment and internal neural connections, the pursuer and obstacles are guaranteed to stay at the peak and valley of the activity landscape of the neural network, respectively. The architecture of the proposed neural network is illustrated in
Figure 1a. The proposed neural network is characterized by its local connectivity structure in which the neuron is only connected to other neurons within a small region
. The neighboring neurons are defined as those whose distance between the
kth neuron and the
jth neuron is smaller than
. The environment is assigned one to one to the neural network, as illustrated in
Figure 1a. The black squares represent the position of the obstacles and the gray circles represent the corresponding neurons that map to the obstacles. The red square represents the position of the pursuer, and the blue square represents the position of the evader.
Hodgkin and Huxley [
32] proposed an electrical circuit for modeling the membrane potential in a biological neuron system. Using the state equation technique, the dynamics of membrane
can be obtained as
where
is the capacitance of the membrane;
and
are the equilibrium potentials of potassium and sodium ions, respectively;
is the potentials of passive leak current due to chloride and other ions;
and
are the ionic conductances of the potassium and sodium, respectively;
is conductances of chloride and other ions. Grossberg [
33] developed a shunting neurodynamics model that establishes
and substitutes
,
,
,
,
, and
in (
3). Therefore, the shunting equation can be written as
where
denotes the neural activity of the
kth neuron;
and
are the excitatory and inhibitory inputs to the neuron, respectively;
A is the passive decay rate;
B and
D are the upper and lower bounds of the neural activity, respectively. The neural activity is bounded in the area of
. Several robotic navigation and control algorithms have been developed depending on the neurodynamic shunting model [
34,
35,
36].
Based on (
4), the excitatory input
is derived from the pursuer and its neighboring neurons, while the inhibitory input
is derived from obstacles. Therefore, the neural activity for the
kth neuron is written as
where
represents the neural activity of neighboring neurons to the
kth neuron;
n represents the amount of neighboring neurons to the
kth neuron;
is defined as
; and
is defined as
. Connection weight
is defined as
where
is a positive constant and
represents the Euclidean distance between the
kth neuron and the
lth neuron. The neural activity is bounded in the area of
as shown in
Figure 1b. The parameters of the shunting model have been discussed in previous work [
37]. The shunting model exhibits low sensitivity to both parameters and the neural connection weight function, which allows for a broad selection range of parameters. For the pursuit–evasion game, only two parameters
A and
are important factors. The neural network is very easy to saturate when parameter
> 1. Thus, the value of
is normally selected in the interval of
. When choosing a small
A value, the small transient response makes the past influence of external inputs (pursuer or obstacle) disappear slowly. When choosing a big
A value, the propagation from the current pursuer position becomes the domain contribution to the neuron activities.
Theorem 1. The steady-state neural activity is bounded in the area of .
Proof of Theorem 1. The shunting Equation (
4) can be rewritten as
where
is linearly related to
and this relationship can be categorized into three distinct scenarios. Firstly, when considering the absence of any inputs (
), the relationship can be described as
When
,
is negative and its magnitude increases as
increases. In contrast, when
,
is positive and its magnitude increases with decreasing
. As a result, at steady state (
), the value of
converges to 0. Secondly, when only the presence of excitatory input is considered (
and
), the relationship can be described as
when
is at the steady state (
), the value of
can be given as
where
A is a positive constant. Then,
; thus,
converges to
. Finally, when only the presence of inhibitory input is considered (
and
), the relationship can be described as
when
is at the steady state (
), the value of
can be given as
where
; thus,
converges to
. Therefore, neural activity
is bounded within an interval of
. □
3.2. Evasion Strategy Based on Neurodynamics
The directions and strategies of the pursuer and the evader are unknown to each other. Therefore, the evasion strategy cannot be guaranteed to be optimal because the strategy considers only the current locations of the players and not their locations at future times. The external input
to the
kth neuron is defined as
where
E is a positive constant. If the corresponding position of the neuron is the pursuer, the external input becomes a large positive value. If the corresponding position is the obstacle, the external input becomes a large negative value. As the directions and strategies of the pursuer and evader are not mutually known, each evader assumes that the pursuer is pursuing itself specifically. The evasion strategy for each evader can be given as
where
represents the next position of the evader robot and
represents the neural activity of the command neuron. From (
5), there are two components in the excitatory term
. The
term depends on the corresponding position of the pursuer, and the
term enables the propagation of positive activity to the whole neural network. The inhibitory term
only consists of
, which depends only on the corresponding position of the obstacle. Therefore, the pursuer has global effects throughout the neural network, while the obstacle effect is local without propagation. As shown in
Figure 1b, the neuron with the pursuer position has maximum neural activity and propagates the positive neural activity to its neighborhoods. The neurons of obstacles have negative neural activity without propagating.
Theorem 2. The trajectory of the evader is collision-free with the obstacles.
Proof of Theorem 2. The neural activity of obstacle
at the steady state can be written as
Since the evader only chooses the positive neural activity for the next position according to the evasion strategy (
14), the obstacle neuron will not be chosen as the next position. □
Theorem 3. The proposed neural network has a real-time response to the obstacle.
Proof of Theorem 3. Suppose that the
kth neuron is not an obstacle at time instant
. Assume that one obstacle moves to the
kth neuron at the instant of time
. The neural activity of the
kth neuron at time instant
can be written as
Thus, for any time instant
t, if the position of the neuron becomes the obstacle, the neural activity of this neuron changes to a very large negative value. Based on the evasion strategy (
14), the evader would not choose the neuron with negative neural activity. Therefore, the trajectories of the pursuer and evader are collision-free in real time to the obstacle in any time instant. □
4. Results
To evaluate the performance of the proposed approach, simulations are performed with three types of obstacles. The positions of the pursuer, obstacles, and robots are randomly distributed in the workspace. The simulation studies are tested in MATLAB 2021a. The simulation parameters are listed as , , , , , , , and . The speed of obstacle is equal to that of the evader robot. The workspace is represented by a neural network that has neurons.
4.1. Evasion with Static Obstacles
In the initial simulation, the proposed approach to avoid static obstacles was tested using one pursuer and three evader robots. The initial positions of the robots and the pursuer were as follows: the robots are located at (20, 23), (16, 10), and (30, 14), and the pursuer is located at (40, 40). The pursuer captured the closest robot, Robot 1, at the 12th step, as shown in
Figure 2a. Subsequently, the pursuer captured Robot 2 at the 18th step, as shown in
Figure 2b. At the beginning of the evasion, Robot 2 kept the same direction as Robot 1 but was later impeded by an obstacle. Lastly, Robot 3 was captured by the pursuer at the 24th step, as shown in
Figure 2c. During the evasion process, both Robots 2 and 3 altered their evasion direction at the 9th and 15th steps, respectively. When close to the boundary of the workspace, the robots changed direction to avoid collision.
4.2. Evasion with Moving Obstacles
In the next simulation, a more complex scenario was considered in which obstacles were moving within the workspace. In the simulation scenario, the velocity of the obstacles is equivalent to the evader robots. The gray lines represent the past trajectory of the obstacles. As shown in
Figure 3a, Robot 1 was captured at the 11th step. An obstacle moving upward hindered the pursuit of Robot 1, leading it to move upward to evade the pursuer. Robot 2 was captured at the 16th step, as shown in
Figure 3b. In contrast to the previous simulation, the obstacle started moving upward, providing enough space for Robot 2 to move toward the past position of the obstacle. Finally, Robot 3 was captured at the 29th step, as shown in
Figure 3c. Initially, Robot 3 moved to the left as the obstacle blocked its evasion direction. However, as the pursuer closed in on Robot 1, Robot 3 reversed its direction and moved toward the right.
4.3. Evasion with Sudden Change Obstacles
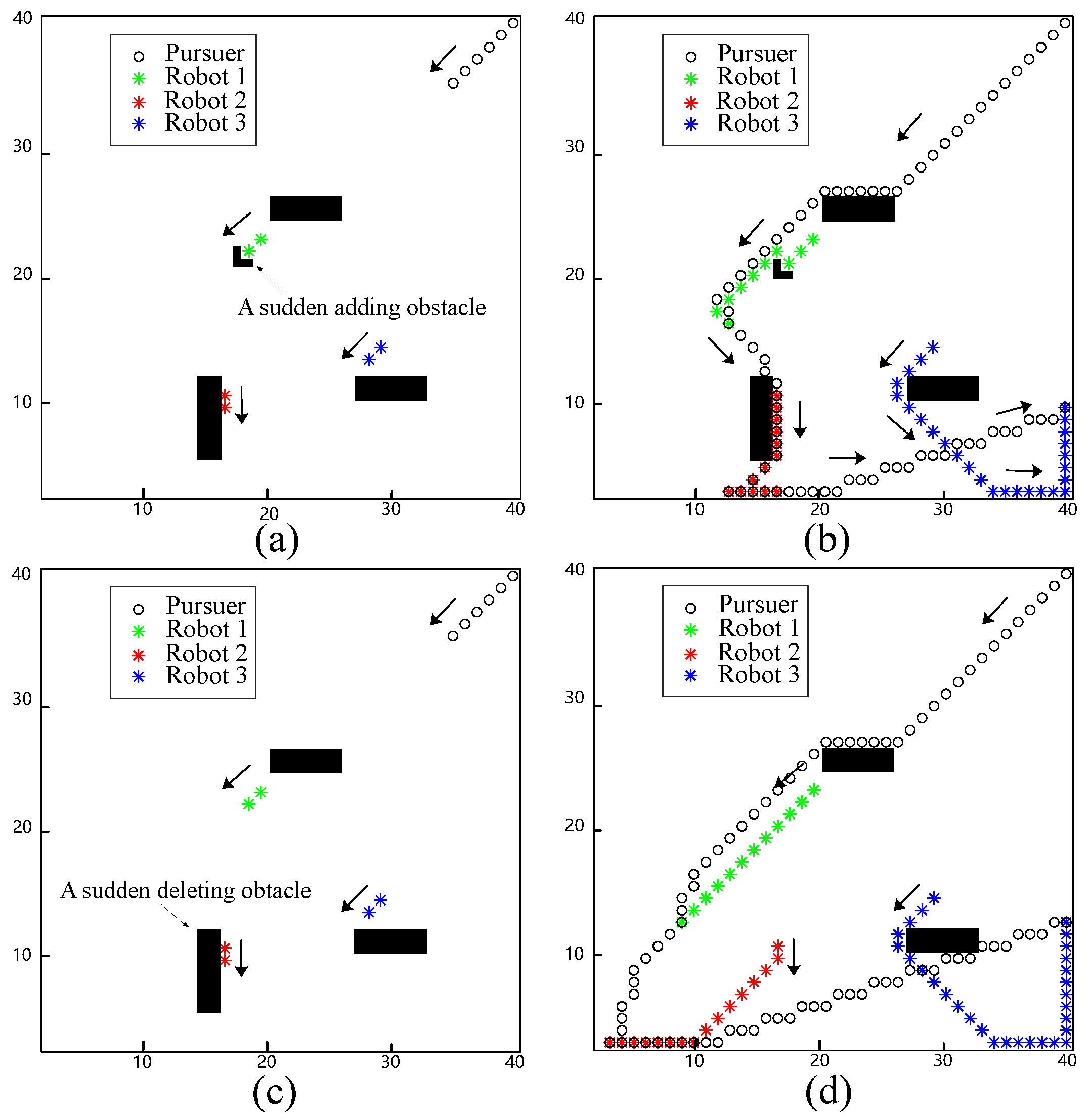
In this simulation, a case of sudden addition and removal of obstacles is tested to indicate the real-time response of the proposed approach.
Figure 4a shows an L-shaped obstacle suddenly placed in front of Robot 1. Robot 1 is not able to move forward due to a sudden obstacle. The neural activity of the L-shaped obstacle immediately becomes a large negative value. Thus, Robot 1 moves to its right side and passes around obstacles, as shown in
Figure 4b. Compared to the results shown in
Figure 3b and
Figure 4b, it can be observed that Robot 2 chose a different direction for evasion. This is because the sudden addition of the obstacle hindered the evasion of Robot 1, resulting in its early capture. As a result, the relative position of Robot 2 and the pursuer was greater than in the previous simulation, leading Robot 2 to move to the left to evade rather than to the right. Another scenario considered was the sudden removal of an obstacle. As shown in
Figure 4c, an obstacle near Robot 2 was removed. After that, Robot 2 moved to the right, which increased the distance between the pursuers, as shown in
Figure 4d.
4.4. Comparison Studies
In comparison studies, several experiments are tested in various scenarios to evaluate the performance of the proposed approach. The proposed approach and the compared approach are tested 30 times for different scenarios when . As mentioned in the literature review, the following approaches are compared with the proposed method:
CM: a collective moving approach is to form multiple evaders as a group moves together with others following a single leader. In this comparison study, a self-adaptive collective moving approach is used to guide evaders to move in the opposite direction of the pursuer [
38].
LoS-PF: a potential field-based approach that generates attractive and repulsive forces to guide the evader [
25]. The attractive force is based on the virtual target which is the line-of-sight direction of the pursuer, whereas the repulsive force is based on the position of obstacles.
RL: a reinforcement learning algorithm based on a self-play mechanism to guide the evader to escape from the pursuer and avoid collisions with obstacles [
28]. The reward function of the evader is defined as follows:
where
c is a small constant;
is the reward value of the evader in self-play training, and
is the distance between the pursuer and the evader at time
t.
As shown in
Table 1, the comparison results indicate that the proposed method obtains a longer survival time in dynamic scenarios, including moving, adding, and deleting environments, while the RL method outperforms other methods only in static scenarios. It is important to note the limitation of the RL method in terms of training time. Due to the position changes of the pursuer and the obstacle, the training process is restarted at every step. Therefore, the training time is significantly extended with an increasing number of evaders or environmental changes, which might pose significant challenges in real-world applications, where computational resources, time constraints, and the need for rapid deployment can limit the feasibility of the methods. However, the training process is not necessary in the proposed approach. The next evasive movement is based on the dynamic change in neural activity. It is unnecessary to incorporate a learning mechanism to determine optimal neural weights, which would lead to greater complexity of the algorithm and increased computational costs. Compared to the LoS-PF method, the evasion of the proposed method is based on the propagation of neural activity, which is not limited to a specific evasive direction. In contrast, the LoS-PF method is a direction-selective evasion strategy, where the chosen direction is the opposite of the pursuer. The opposite direction of the pursuer is the optimal direction for the evader in a collision-free environment. However, in environments with obstacles, a singular escape direction may lead the evader to a local minimum constituted by obstacles, which leads the evader to be trapped at the current location. This limitation is also present in the CM approach that involves multiple evaders moving as a group with a single leader, which can lead to a group of evaders in a single direction.
4.5. Real-World Experiments on Mobile Robots
To validate the proposed neurodynamic-based evasion method for mobile robots, three robot operating systems (ROSs) were built for experimental tests, as shown in
Figure 5. Each robot was equipped with a 1080p camera and an RPLIDAR A1 laser scanner and both were integrated into an Ubuntu system. For control, environment detection, and localization tasks, the robots used Raspberry Pi 4 Model B and STM32F405 computing boards. The proposed evasion strategy can be considered as a virtual target path planning for robots. When the pursuit–evasion game begins, the command position of the evader
is sent to mobile robots according to the environment and the current position of the pursuer. Evader robots set the command position as the current virtual target for path planning. The experimental results are in reasonable agreement with the simulation results.
5. Conclusions
This paper presents a novel neurodynamics-based approach that addresses the general pursuit–evasion game from a neurodynamic perspective instead of formulating it as a differential game. A specific evasion task considered the case in which one single pursuer moves faster than the evader robots. The approach utilizes a BINN with only local connections, which is topologically organized to represent the environment. The pursuer has global effects on the whole neural network, whereas the obstacles only have local effects to guarantee evader robots avoid collisions. The proposed approach is capable of generating collision-free evasion trajectories and has a real-time response to the changing environment through dynamic neural activity. The simulation and experimental results demonstrate that the proposed approach is effective and efficient in complex and dynamic environments. The limitation of the proposed method can be summarized as follows. Firstly, the evasion direction in the proposed method is constrained to eight fixed directions, whereas the evasive direction of the real robot can be finely adjusted. Secondly, the proposed method assumes that the robots are point robots, which ignores the dynamics of actual robotic systems. This limits the applicability and effectiveness of the method in practical settings. Future work will aim to incorporate continuous adjustment of the direction of evasion and integrate realistic robotic models to improve applicability and effectiveness in real-world robotic evasion scenarios.
Author Contributions
Conceptualization, J.L. and S.X.Y.; methodology, J.L. and S.X.Y.; software, J.L.; validation, J.L. and S.X.Y.; formal analysis, J.L. and S.X.Y.; investigation, J.L. and S.X.Y.; resources, J.L. and S.X.Y.; data curation, J.L.; writing—original draft preparation, J.L.; writing—review and editing, S.X.Y.; visualization, J.L.; supervision, S.X.Y.; project administration, S.X.Y.; funding acquisition, S.X.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Natural Sciences and Engineering Research Council (NSERC) of Canada.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Jagat, A.; Sinclair, A.J. Nonlinear control for spacecraft pursuit-evasion game using the state-dependent Riccati equation method. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 3032–3042. [Google Scholar] [CrossRef]
- Makkapati, V.R.; Sun, W.; Tsiotras, P. Optimal evading strategies for two-pursuer/one-evader problems. J. Guid. Control Dyn. 2018, 41, 851–862. [Google Scholar] [CrossRef]
- Makkapati, V.R.; Tsiotras, P. Optimal evading strategies and task allocation in multi-player pursuit–evasion problems. Dyn. Games Appl. 2019, 9, 1168–1187. [Google Scholar] [CrossRef]
- Li, J.; Yang, S.X. Intelligent escape of robotic systems: A survey of methodologies, applications, and challenges. J. Intell. Robot. Syst. 2023, 109, 55. [Google Scholar] [CrossRef]
- Lopez, V.G.; Lewis, F.L.; Wan, Y.; Sanchez, E.N.; Fan, L. Solutions for multiagent pursuit-evasion games on communication graphs: Finite-time capture and asymptotic behaviors. IEEE Trans. Autom. Control 2020, 65, 1911–1923. [Google Scholar] [CrossRef]
- Zhou, P.; Chen, B.M. Distributed Optimal Solutions for Multiagent Pursuit-Evasion Games for Capture and Formation Control. IEEE Trans. Ind. Electron. 2023, 71, 5224–5234. [Google Scholar] [CrossRef]
- Rivera, P.; Kobilarov, M.; Diaz-Mercado, Y. Pursuer Coordination Against a Fast Evader via Coverage Control. IEEE Trans. Autom. Control 2023, 69, 1119–1124. [Google Scholar] [CrossRef]
- Tian, B.; Li, P.; Lu, H.; Zong, Q.; He, L. Distributed pursuit of an evader with collision and obstacle avoidance. IEEE Trans. Cybern. 2021, 52, 13512–13520. [Google Scholar] [CrossRef] [PubMed]
- Cheng, L.; Yuan, Y. Multiplayer obstacle avoidance pursuit-evasion games with adaptive parameter estimation. IEEE Trans. Ind. Electron. 2022, 70, 5171–5181. [Google Scholar] [CrossRef]
- Sani, M.; Robu, B.; Hably, A. Pursuit-evasion Game for Nonholonomic Mobile Robots with Obstacle Avoidance using NMPC. In Proceedings of the Mediterranean Conference on Control and Automation, Saint-Rapha, France, 15–18 September 2020; pp. 978–983. [Google Scholar]
- Yang, X.; Shu, L.; Liu, Y.; Hancke, G.P.; Ferrag, M.A.; Huang, K. Physical security and safety of IoT equipment: A survey of recent advances and opportunities. IEEE Trans. Ind. Inform. 2022, 18, 4319–4330. [Google Scholar] [CrossRef]
- Huang, H.; Savkin, A.V. An algorithm of reactive collision free 3-D deployment of networked unmanned aerial vehicles for surveillance and monitoring. IEEE Trans. Ind. Inform. 2019, 16, 132–140. [Google Scholar] [CrossRef]
- Yun, W.J.; Park, S.; Kim, J.; Shin, M.; Jung, S.; Mohaisen, D.A.; Kim, J.H. Cooperative multiagent deep reinforcement learning for reliable surveillance via autonomous multi-UAV control. IEEE Trans. Ind. Inform. 2022, 18, 7086–7096. [Google Scholar] [CrossRef]
- Sawadwuthikul, G.; Tothong, T.; Lodkaew, T.; Soisudarat, P.; Nutanong, S.; Manoonpong, P.; Dilokthanakul, N. Visual goal human-robot communication framework with few-shot learning: A case study in robot waiter system. IEEE Trans. Ind. Inform. 2021, 18, 1883–1891. [Google Scholar] [CrossRef]
- Li, J.; Yang, S.X. Intelligent Fish-Inspired Foraging of Swarm Robots with Sub-Group Behaviors Based on Neurodynamic Models. Biomimetics 2024, 9, 16. [Google Scholar] [CrossRef]
- Weintraub, I.E.; Pachter, M.; Garcia, E. An introduction to pursuit-evasion differential games. In Proceedings of the 2020 American Control Conference (ACC), Denver, CO, USA, 1–3 July 2020; pp. 1049–1066. [Google Scholar]
- Liu, S.Y.; Zhou, Z.; Tomlin, C.; Hedrick, K. Evasion as a team against a faster pursuer. In Proceedings of the 2013 American Control Conference, Washington, DC, USA, 17–19 June 2013; pp. 5368–5373. [Google Scholar]
- Scott, W.; Leonard, N.E. Dynamics of pursuit and evasion in a heterogeneous herd. In Proceedings of the 53rd IEEE Conference on Decision and Control, IEEE, Los Angeles, CA, USA, 15–17 December 2014; pp. 2920–2925. [Google Scholar]
- Jiang, Y.; Peng, Z.; Wang, D.; Chen, C.P. Line-of-sight target enclosing of an underactuated autonomous surface vehicle with experiment results. IEEE Trans. Ind. Inform. 2019, 16, 832–841. [Google Scholar] [CrossRef]
- Scott, W.L.; Leonard, N.E. Optimal evasive strategies for multiple interacting agents with motion constraints. Automatica 2018, 94, 26–34. [Google Scholar] [CrossRef]
- Fisac, J.F.; Sastry, S.S. The pursuit-evasion-defense differential game in dynamic constrained environments. In Proceedings of the 2015 54th IEEE Conference on Decision and Control (CDC), Osaka, Japan, 15–18 December 2015; pp. 4549–4556. [Google Scholar]
- Oyler, D.W.; Kabamba, P.T.; Girard, A.R. Pursuit–evasion games in the presence of obstacles. Automatica 2016, 65, 1–11. [Google Scholar] [CrossRef]
- Bhadauria, D.; Isler, V. Capturing an evader in a polygonal environment with obstacles. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Catalonia, Spain, 16–22 July 2011. [Google Scholar]
- Wu, W.; Zhang, X.; Miao, Y. Starling-behavior-inspired flocking control of fixed-wing unmanned aerial vehicle swarm in complex environments with dynamic obstacles. Biomimetics 2022, 7, 214. [Google Scholar] [CrossRef] [PubMed]
- Dong, J.; Zhang, X.; Jia, X. Strategies of pursuit-evasion game based on improved potential field and differential game theory for mobile robots. In Proceedings of the International Conference on Instrumentation, Measurement, Computer, Communication and Control, Harbin, China, 8–10 December 2012; pp. 1452–1456. [Google Scholar]
- Zhang, W.; Li, Z.; Li, G.; Zhuang, P.; Hou, G.; Zhang, Q.; Li, C. GACNet: Generate adversarial-driven cross-aware network for hyperspectral wheat variety identification. IEEE Trans. Geosci. Remote. Sens. 2023, 62, 5503314. [Google Scholar] [CrossRef]
- Zhang, W.; Zhao, W.; Li, J.; Zhuang, P.; Sun, H.; Xu, Y.; Li, C. CVANet: Cascaded visual attention network for single image super-resolution. Neural Netw. 2024, 170, 622–634. [Google Scholar] [CrossRef] [PubMed]
- Qi, Q.; Zhang, X.; Guo, X. A Deep Reinforcement Learning Approach for the Pursuit Evasion Game in the Presence of Obstacles. In Proceedings of the IEEE International Conference on Real-Time Computing and Robotics, Asahikawa, Japan, 28–29 September 2020; pp. 68–73. [Google Scholar]
- Qu, X.; Gan, W.; Song, D.; Zhou, L. Pursuit-evasion game strategy of USV based on deep reinforcement learning in complex multi-obstacle environment. Ocean Eng. 2023, 273, 114016. [Google Scholar] [CrossRef]
- Guo, X.; Cui, R.; Yan, W. Pursuit-Evasion Games of Marine Surface Vessels Using Neural Network-Based Control. IEEE Trans. Syst. Man Cybern. Syst. 2024. [Google Scholar] [CrossRef]
- Fang, X.; Wang, C.; Xie, L.; Chen, J. Cooperative pursuit with multi-pursuer and one faster free-moving evader. IEEE Trans. Cybern. 2020, 52, 1405–1414. [Google Scholar] [CrossRef] [PubMed]
- Hodgkin, A.L.; Huxley, A.F. A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 1952, 117, 500–544. [Google Scholar] [CrossRef] [PubMed]
- Grossberg, S. Nonlinear neural networks: Principles, mechanisms, and architectures. Neural Netw. 1988, 1, 17–61. [Google Scholar] [CrossRef]
- Li, J.; Yang, S.X. Intelligent Collective Escape of Swarm Robots Based on a Novel Fish-Inspired Self-Adaptive Approach with Neurodynamic Models. IEEE Trans. Ind. Electron. 2024. [Google Scholar] [CrossRef]
- Zhu, D.; Cao, X.; Sun, B.; Luo, C. Biologically inspired self-organizing map applied to task assignment and path planning of an AUV system. IEEE Trans. Cogn. Dev. Syst. 2017, 10, 304–313. [Google Scholar] [CrossRef]
- Li, J.; Yang, S.X. A Novel Feature Learning-based Bio-inspired Neural Network for Real-Time Collision-free Rescue of Multi-Robot Systems. IEEE Trans. Ind. Electron. 2024. [Google Scholar] [CrossRef]
- Li, J.; Xu, Z.; Zhu, D.; Dong, K.; Yan, T.; Zeng, Z.; Yang, S.X. Bio-inspired intelligence with applications to robotics: A survey. Intell. Robot. 2021, 1, 58–83. [Google Scholar] [CrossRef]
- Zhao, H.; Liu, H.; Leung, Y.W.; Chu, X. Self-adaptive collective motion of swarm robots. IEEE Trans. Autom. Sci. Eng. 2018, 15, 1533–1545. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}