1. Introduction
Facial expressions are direct and fundamental social signals in human communication [
1,
2]. Along with other gestures, they convey important nonverbal emotional cues in interpersonal relations. More importantly, vision-based facial expression recognition has become a powerful sentiment analysis tool in a wide spectrum of practical applications. For example, counseling psychologists assess a patient’s condition and consider treatment plans by constantly observing facial expressions [
3]. In retail sales, a customer’s facial expression data are used to determine whether a human sales assistant is needed [
4]. Other significant application areas include social robots, e-learning, and facial expression synthesis.
Facial expression recognition (FER) is a technology that uses computers to automatically recognize facial expressions. As this research area matures, a number of large-scale facial expression datasets have emerged. In an early seminal work [
5], six prototypical emotional displays are postulated: angry (AN), disgust (DI), fear (FE), happy (HA), sad (SA), and surprise (SU), which are often referred to in the literature as
basic emotions. Recent FER datasets regard neutral (NE) or contempt (CO) as additional expression categories, expanding the number of facial expression categories to seven or eight.
In contrast to generic image classification, there are strong common features among different categories of facial expressions. Indeed, multiple expressions share inherently similar underlying facial appearance, and their differences could be less distinguishable. In computer vision, a common strategy to address this issue involves adopting a variant of the center loss [
6]. In this work, a Feature Clustering Network (FCN) is proposed, which includes a simple and straightforward extension to the center loss, and it works well for optimizing both intra-class and inter-class variations. Unlike existing methods [
7,
8,
9], our method does not involve additional computations other than the variation of the cluster centers, and it only requires a few hyper-parameters.
In addition, one unique aspect of FER lies in the delicate contention between capturing the subtle local variations and obtaining a unified holistic representation. To attend to local details, some recent studies focus on attention mechanisms [
7,
10,
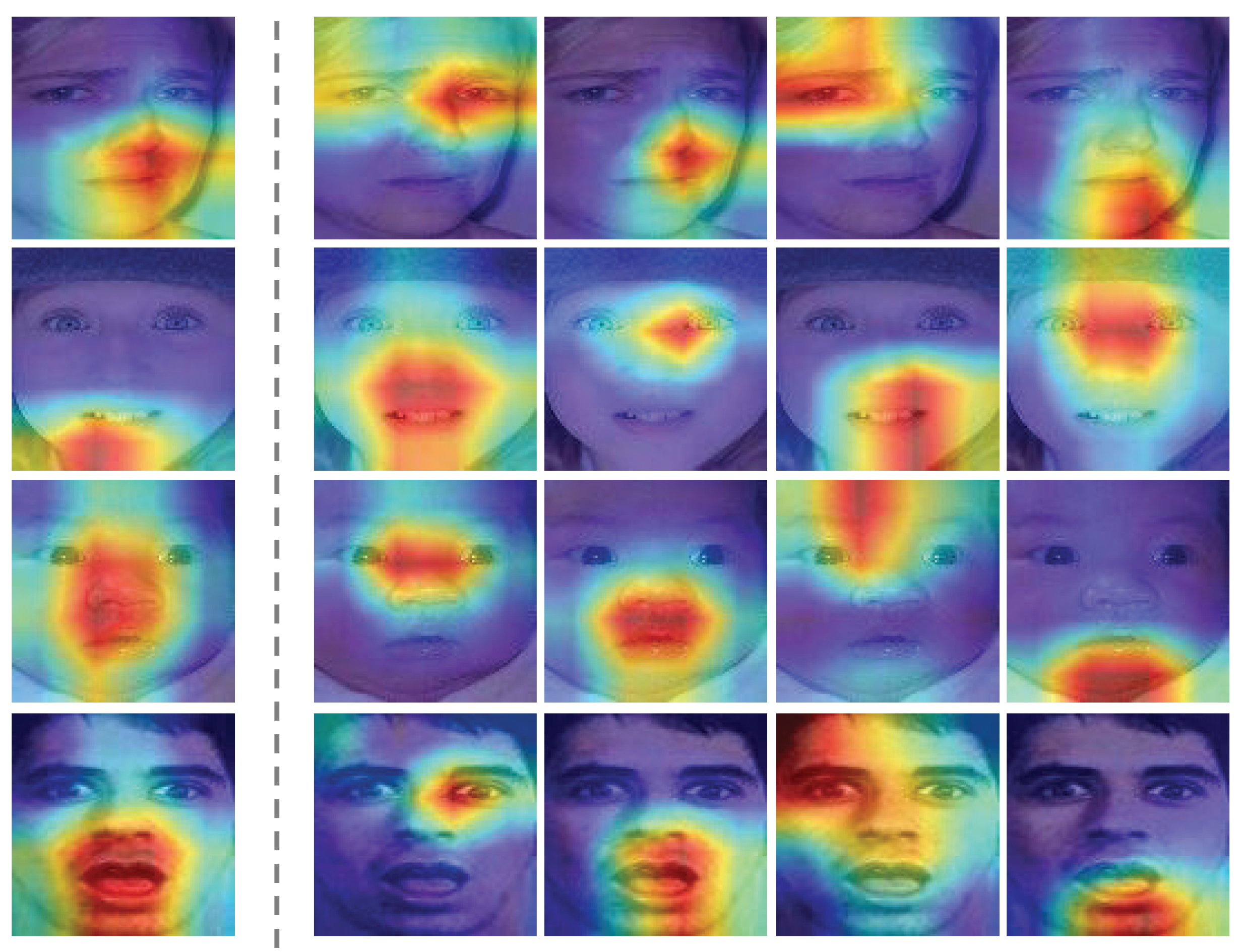
11], achieving promising results. Nonetheless, as shown in
Figure 1, it is difficult for a model with only a single attention head to concentrate on various parts of the face at the same time. In fact, it is our belief that facial expression is simultaneously manifested in multiple parts of the face, such as eyebrows, eyes, nose, mouth, chin, etc. Therefore, this paper proposes a Multi-head Attention Network (MAN) inspired by biological visual perception that instantiates a number of attention heads to attend to multiple facial areas. Our attention module implements both spatial and channel attentions, which allows for capturing higher-order interactions among local features while maintaining a manageable computational budget. Furthermore, this paper proposes an Attention Fusion Network (AFN) that ensures attention is drawn to multiple locations before their fusion into a comprehensive feature vector for downstream classification.
By integrating the above ideas, a novel facial expression recognition network, called Distract your Attention Network (DAN), is presented in this paper. Our method implements multiple attention heads and ensures that they capture useful aspects of the facial expressions without overlapping. Concretely, our work proposes three sub-networks, including a Feature Clustering Network (FCN), a Multi-head Attention Network (MAN), and an Attention Fusion Network (AFN). More specifically, our method first extracts and clusters the backbone feature embedding with FCN, where an affinity loss is applied to increase the inter-class distances while decreasing the intra-class distances. After that, an MAN is built to attend to multiple facial regions concurrently, where multiple attention heads that each include a spatial attention unit and a channel attention unit are adopted. Finally, the output feature vectors from MAN are fed to an AFN to output class scores. Specifically, this work designs a partition loss in AFN to force attention maps from the MAN to focus on different facial locations. As shown in
Figure 1, a single attention module could only concentrate on one coarser image region, missing other important facial locations. On the contrary, our proposed DAN manages to simultaneously capture several vital facial regions.
The main contributions of our work are summarized as follows:
To maximize class separability, this work proposes a simple yet effective feature clustering strategy in FCN to simultaneously optimize intra-class variations and inter-class margins.
Our work demonstrates that a single attention module cannot sufficiently capture all the subtle and complex appearance variations across different expressions. To address this issue, MAN and AFN are proposed to capture multiple non-overlapping local attentions and fuse them to encode higher-order interactions among local features.
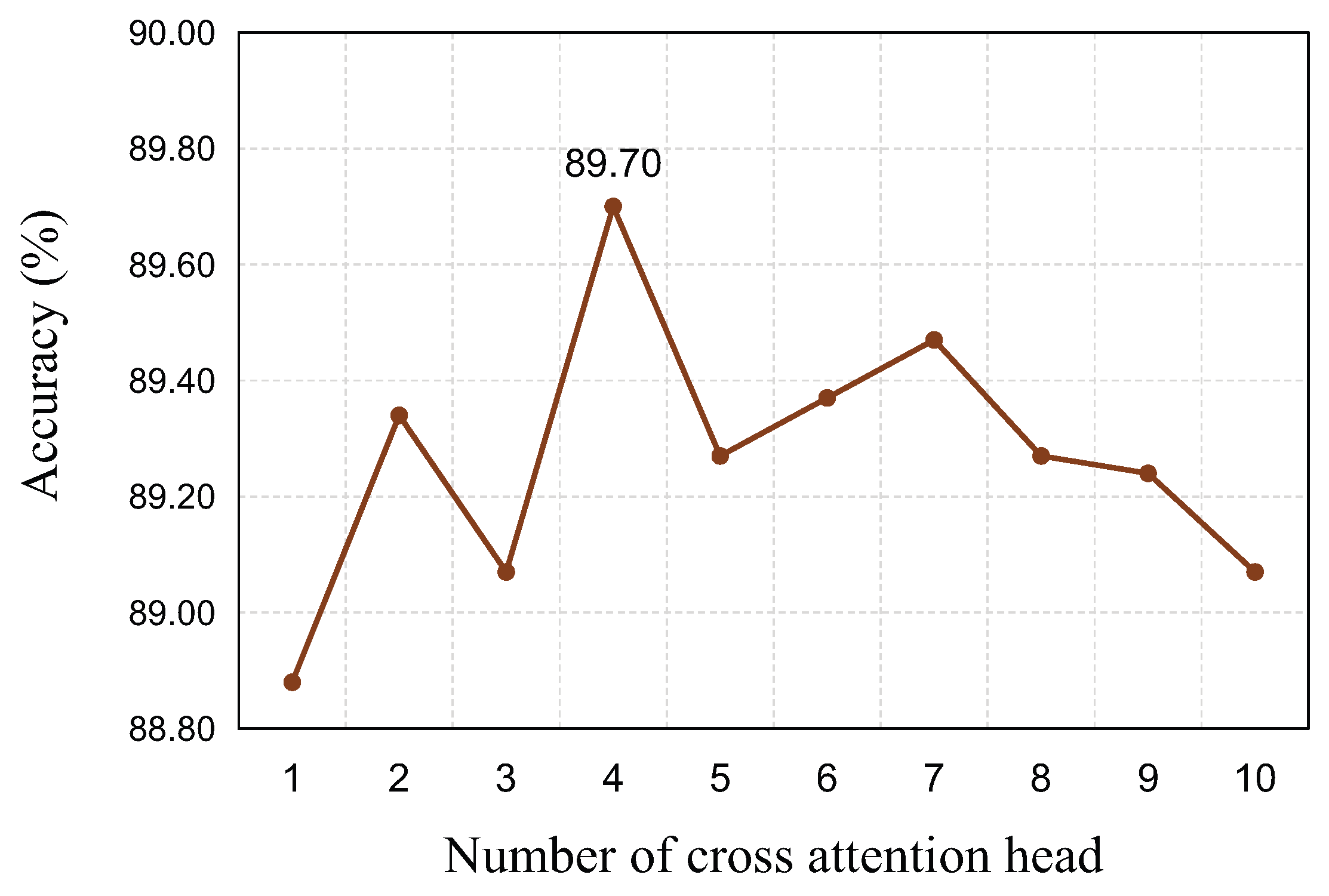
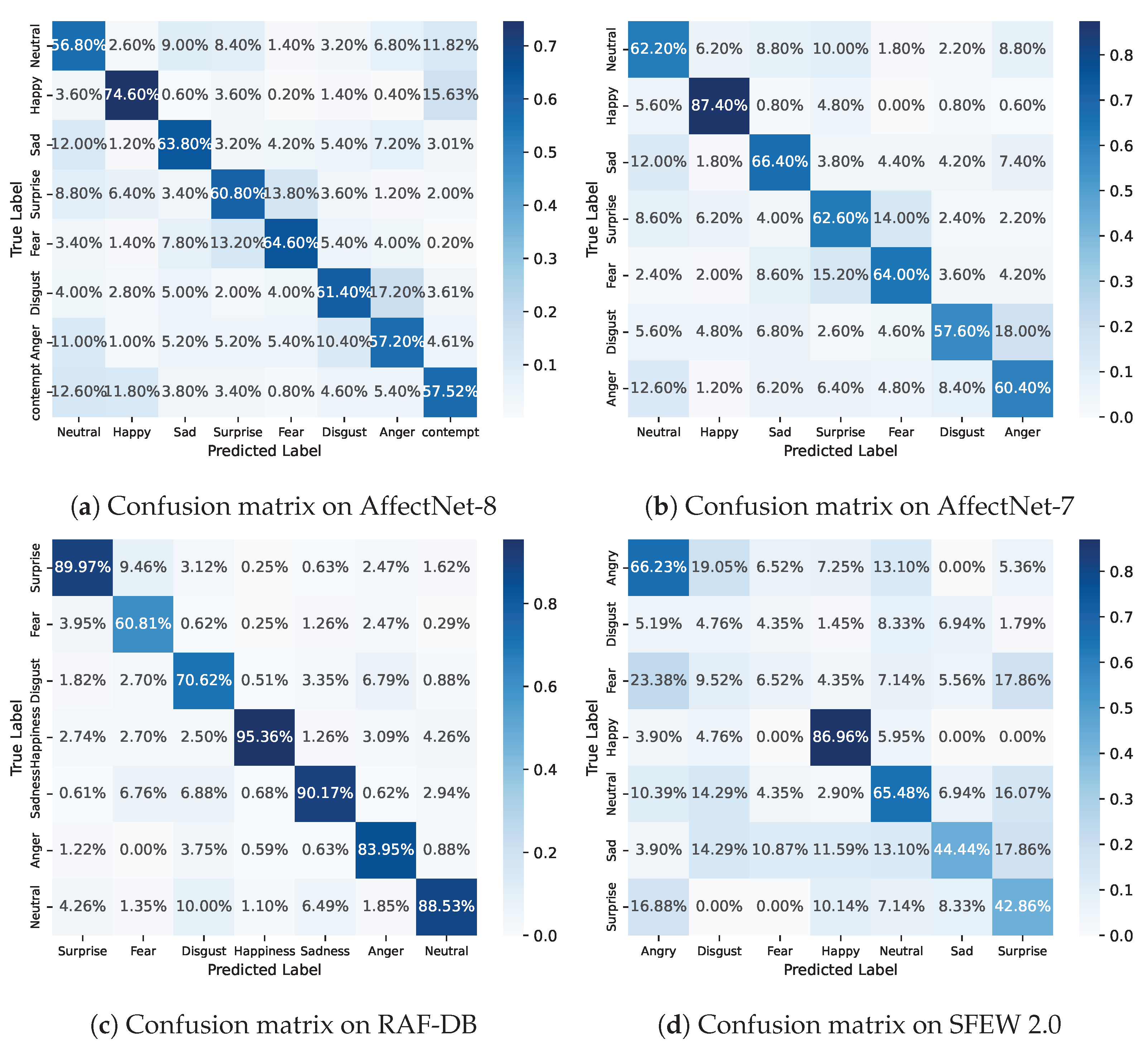
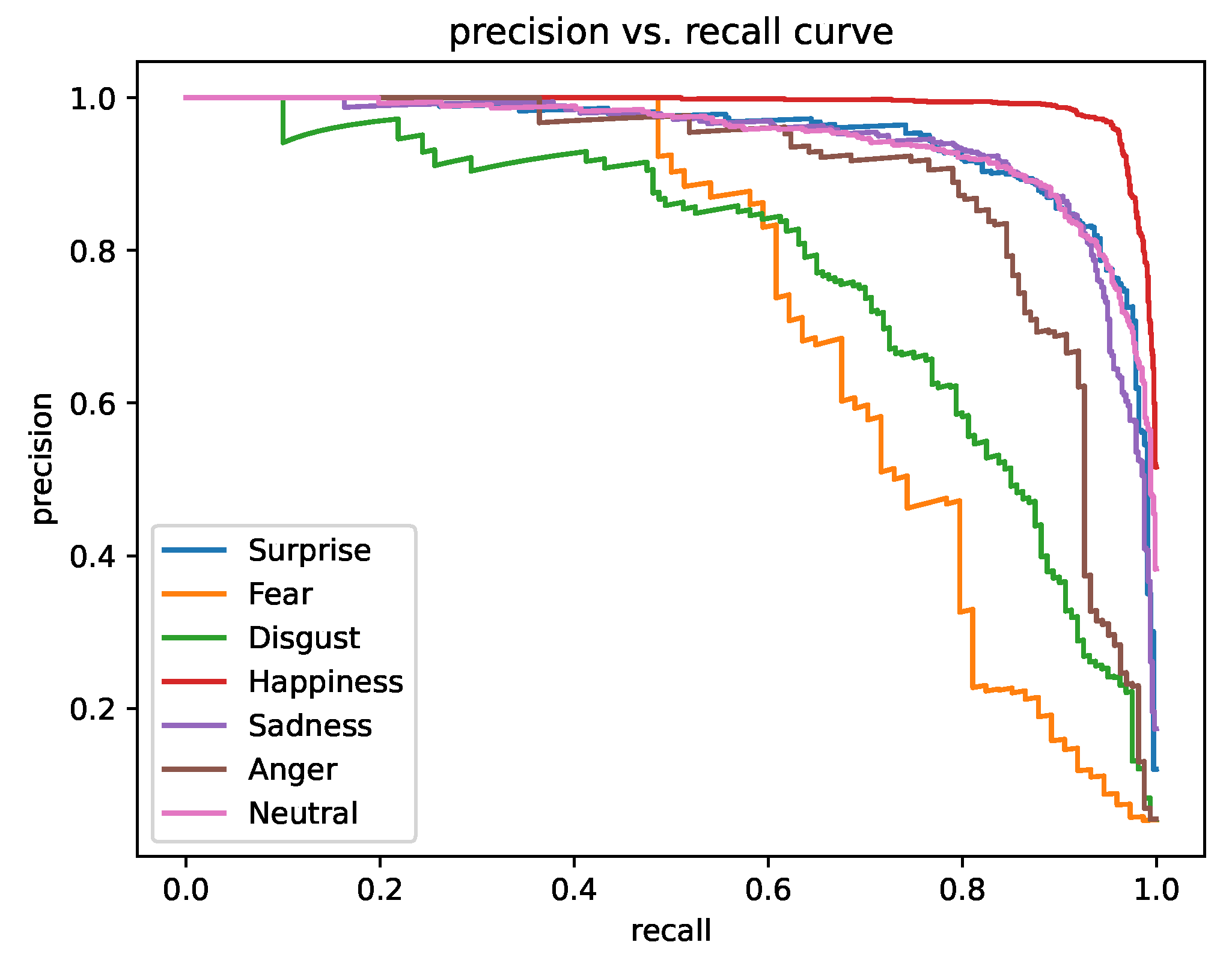
The experimental results show that the proposed DAN method achieves an accuracy of 62.09% on AffectNet-8, 65.69% on AffectNet-7, 89.70% on RAF-DB, and 53.18% on SFEW 2.0, respectively, which represent the state of the art in facial expression recognition performance.
The rest of the paper is organized as follows.
Section 2 reviews related literature in facial expression recognition with a particular focus on the attention mechanism and discriminative loss functions.
Section 3 describes the proposed method in detail.
Section 4 then presents the experimental evaluation results followed by closing remarks in
Section 5.
2. Related Work
Facial expression recognition is an image classification task involving accurately identifying the emotional state of humans. The earliest study on FER dates back to 1872, when Darwin first proposed the argument of consistency in expressions [
2]. In 1971, Ekman and Friesen presented the six basic emotions [
5]. Later, the first facial expression recognition system [
12] was proposed in 1991, which was based on optical flow. After that, the FER system has gradually matured and, in general, can be divided into three sub-processes: face detection, feature extraction, and expression classification [
13]. Recently, FER systems are benefiting from the rapid development of deep learning, and a unified neural network can be used to perform both feature extraction and expression classification.
One of the most significant applications of FER is in human–computer interaction. By analyzing users’ facial expressions, computers can interpret human emotions and respond accordingly, providing more natural and intuitive user interfaces. This technology has already been implemented in various areas, such as gaming, virtual reality, and video conferencing. In the healthcare industry, facial expression recognition can be used to detect and diagnose various mental health disorders. It can also be used to monitor patients’ emotions and provide personalized treatment options. For example, Ref. [
14] take advantage of FER instead of medical devices to detect a people’s health state. FER also has important applications in artistic research, Ref. [
15] use FER to recognize facial expressions in opera performance scenes to help teams assess user satisfaction and use it to make adjustments. Very recently, Ref. [
16] propose a method for synthesizing recognizable face line portraits with controllable expression and high recognizability based on a triangle coordinate system.
Attention mechanism. Attention mechanism plays an important role in visual perception [
17,
18]. In particular, attention enables human beings to actively seek more valuable information in a complex scene. In recent years, there have been a plethora of studies attempting to introduce attention mechanisms into deep Convolutional Neural Network (CNN) with success. For example, Ref. [
19] focus on the channel relationship of network features and propose a squeeze-and-excitation block to retain the most valuable channel information. Ref. [
20] introduce frequency analysis to attention mechanism and present a new method termed FcaNet to compress information loss in scalar-based channel representations. Ref. [
21] present a group-wise spatial attention module (SGE) where the spatial-wise features are divided into multiple groups to learn a potential spatial connection. By leveraging the complementary nature between channel-wise and spatial-wise features, Ref. [
22] propose the Convolutional Block Attention Module (CBAM) that sequentially connects a channel attention and spatial attention to obtain rich attention features. Ref. [
23] propose a coordinate attention that embeds positional information into channel attention to generate spatially selective attention maps. Ref. [
24] propose a new triplet attention that captures cross-dimensional interaction to efficiently build inter-dimensional dependencies. Likewise, Ref. [
25] use a position attention module and a channel attention module in parallel to share the local-wise and global-wise features for scene segmentation task. Very recently, seminal works based on self-attention mechanisms have emerged, such as Swin-Transformer [
26], DAB-DETR [
27], DaViT [
28], and QFormer [
29]. These models have indeed demonstrated superior performance, but they also bring with them a huge number of model parameters and an expensive computational cost, which are unsuitable for lightweight applications. Inspired by these efforts, our method includes design of an attention head that sequentially cascades a spatial attention and a channel attention unit, which is both efficient and effective.
There are a few papers that introduce the above progress into FER. For example, Ref. [
30] apply region attention on the CNN backbone to enhance its power of capturing local information. Ref. [
31] construct a bottom-up and top-down architecture to obtain low resolution attention features. In these papers, only a single attention head is used, which would generally lead to attention on a rough area of the face. In our work, however, multiple non-overlapping attention regions could be simultaneously activated to capture information from different local regions. This is particularly useful for FER, as we need to simultaneously attend to multiple regions (e.g., eyes, nose, mouth, forehead, and chin) to capture the subtle differences among emotion classes.
Attention mechanisms have found applications in a wide range of areas in computer vision. For example, Ref. [
32] propose a joint weak saliency and attention-aware model for person re-identification, in which saliency features are weakened to obtain more complete global features and diversified saliency features via attention diversity. Ref. [
33] propose a reconstruction method based on attention mechanism to address the issue of low-frequency and high-frequency components being treated equally in image super-resolution. Ref. [
34] propose a multi-head self-attention approach for multi-label mRNA subcellular localization prediction and achieve excellent results.
Discriminative loss. A discriminative loss function can strongly regulate the distribution of deep features. For example, Ref. [
35] propose contrastive loss, which is an efficient loss function that maximizes class separability. In detail, a general Euclidean metric is used for features from the same class, but for diverse classes, the loss values will get close to a maximum margin. In addition, Ref. [
6] present the center loss to learn a center distribution of each class and penalize the distances between deep features and their corresponding class centers. Differently, Ref. [
36] propose using an angle as a distance measure and introduce an angular softmax loss. That work is followed by a number of methods [
37,
38,
39] that improve the angular loss function.
In recent years, several studies demonstrate that discriminative loss functions could be well adapted to the FER task. Ref. [
40] combine the advantages of center loss and softmax loss and propose a discriminative distribution-agnostic loss function. Concretely, a center loss aggregates the features of the same class into a cluster, and a softmax loss separates the adjacent classes. Similarly, Ref. [
8] introduce a cosine metric based on center loss to increase the inter-class distance among different categories. Furthermore, Ref. [
7] propose an attentive center loss, which advocates learning the relationship of each class center for the center loss. However, all these loss functions bring in auxiliary parameters and computations. On the contrary, the affinity loss proposed in this paper is more simple and uses the internal relationship among class centers to increase the inter-class distance.
3. Our Approach
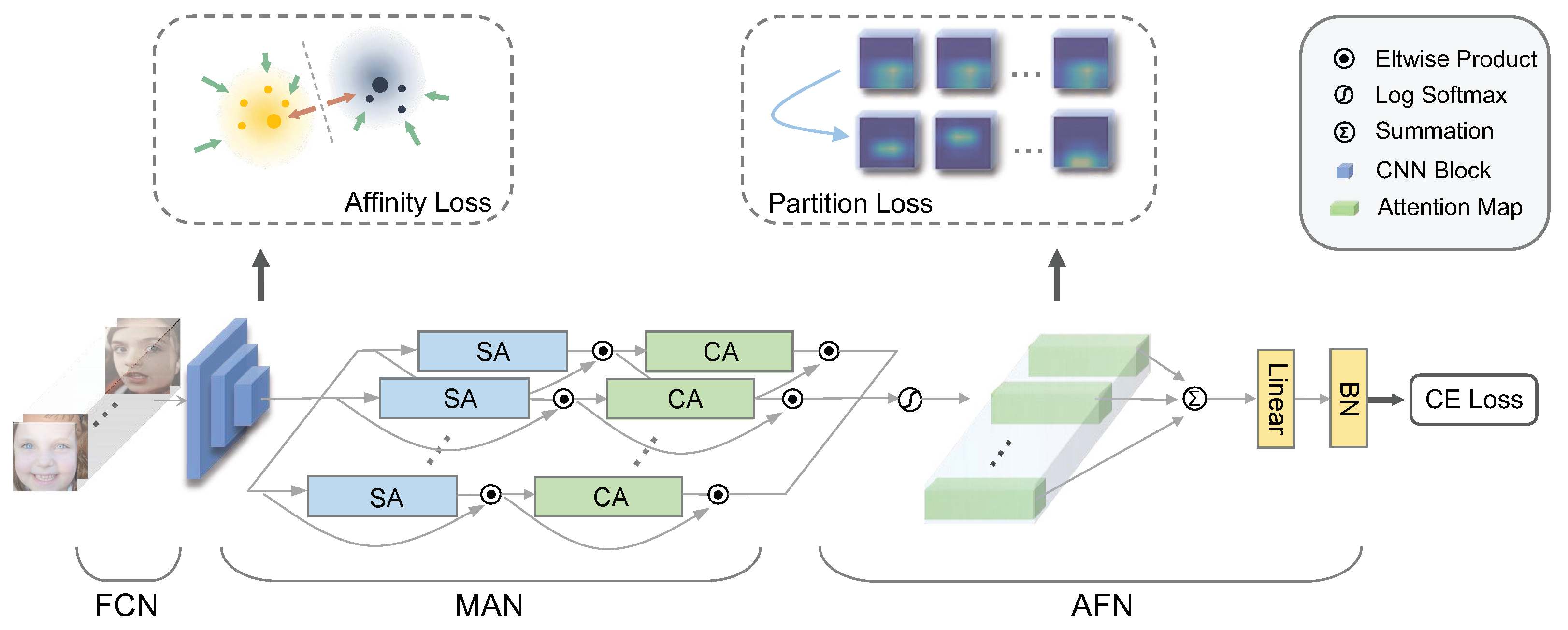
This section describes the proposed DAN model in detail. In order to learn high-quality attentive features, our DAN is divided into three components: Feature Clustering Network (FCN), Multi-head Attention Network (MAN), and Attention Fusion Network (AFN). Firstly, the FCN accepts a batch of face images and outputs basic feature embedding with class discrimination abilities. Afterwards, the MAN is employed to learn diverse attention maps that capture several sectional facial expression regions. Then, these attention maps are explicitly trained to focus on different areas by the AFN. Finally, the AFN fuses features coming from all attention heads and gives a prediction for the expression category of the input images.
In particular, the presented MAN contains a series of lightweight but effective attention heads. An attention head composes of a spatial attention unit and a channel attention unit in sequential order. Distinctively, the spatial attention unit involves convolution kernels of various sizes. A channel attention unit is connected to the end of the spatial attention unit to reinforce the attention maps by simulating an encoder–decoder structure. Both the spatial attention and the channel attention units are integrated back into the input features. The overall process of the proposed DAN is shown in
Figure 2.
3.1. Feature Clustering Network (FCN)
Let us begin by introducing the FCN. Considering both performance and the number of parameters in our model, our method employs a residual network [
41] as the backbone. As discussed earlier, different facial expressions may share similar underlying facial appearance. Therefore, this paper proposes a discriminative loss function, named affinity loss, to maximize class margins. Concretely, in each training step, our method encourages features to move closer to the class center to which they belong. At the same time, our method pushes centers of different classes apart in order to maintain good separability.
More formally, suppose we have the
i-th input image feature
with a class label
during training, where
is the input feature space and
is the label space. Here,
where
M is the number of images in the training set. For the sake of simplicity, the output features of our backbone can be written as:
where
represents the backbone network and
denotes the network parameters of
.
Affinity loss. The affinity loss is proposed to maximize the inter-class distance while minimizing the intra-class variation. By virtue of the affinity loss, the backbone network can accurately cluster various features of facial expressions toward their respective class centers. Compared to the standard center loss [
6], our affinity loss advocates that it makes sense to expand the distance between class centers, because a larger distance between class centers further prevents overlap among classes. Formally, given the class center matrix
wherein each column corresponds to the center of a specific class, the affinity loss function can be written as follows:
where
N is the number of images in a training batch,
D is the dimension of class centers,
is the column vector in
c that corresponds to the ground-truth class of the
i-th image, and
indicates the standard deviation among class centers. One might notice that
is not necessarily a feature vector and could instead be a feature map of higher dimensions. In practice, following [
6], a global average pooling is performed on
, and any singleton dimensions are then removed before applying Equation (
2), and we note that similar operations to flatten the feature maps may also work.
Despite its simplicity, our affinity loss is more effective than the standard center loss, as it encourages wider margins among classes as a result of pushing class centers further away from each other. This arguably completes the other half of the puzzle missing in the center loss, as the standard center loss only enforces tightness within classes but not sparsity among different classes. In particular,
can be readily available during training, as class centers have already been computed, and no additional hyper-parameters are needed for our affinity loss.
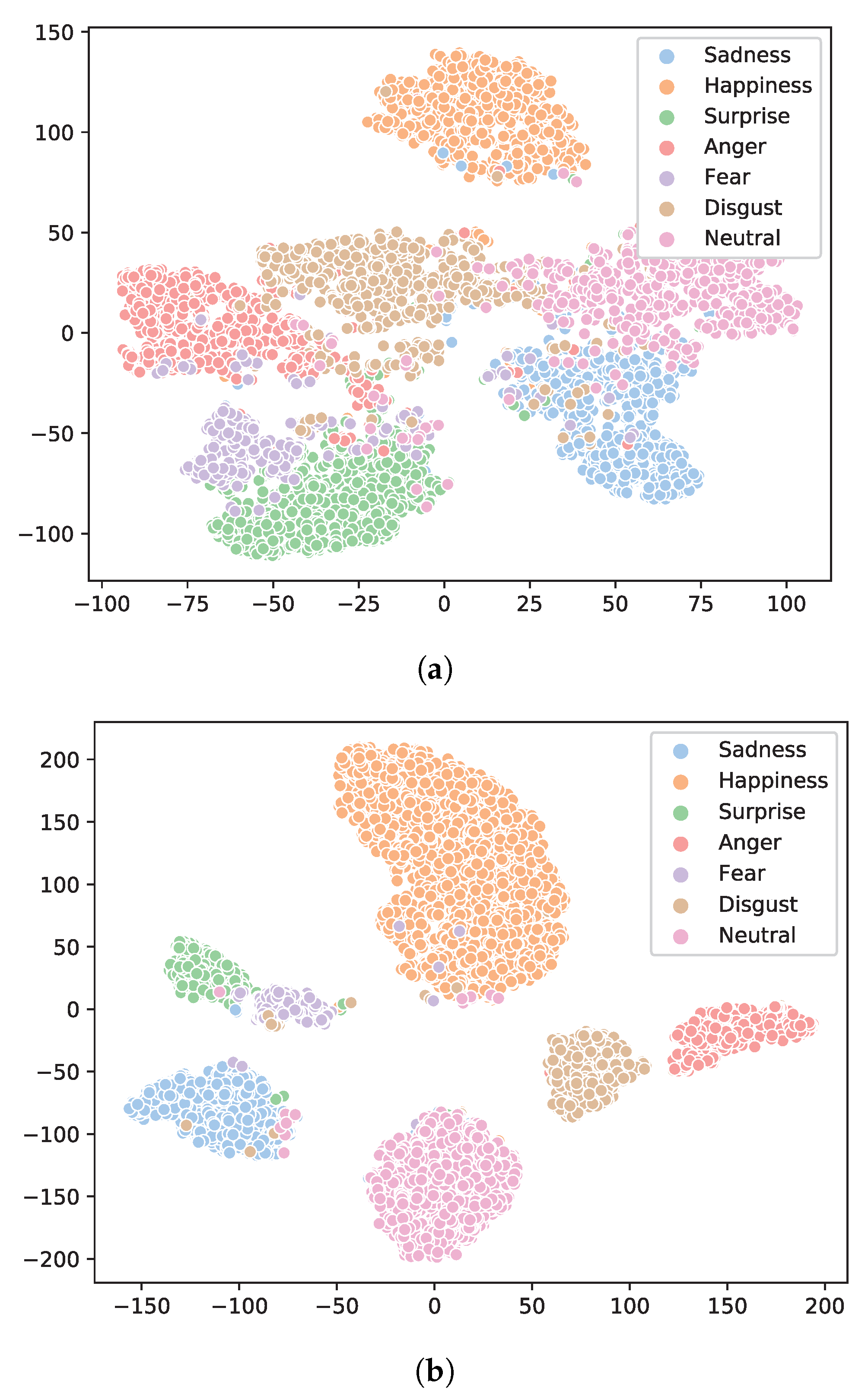
Figure 3 presents the t-SNE visualization of the features obtained by FCN with center loss and affinity loss, respectively. It is clear that by integrating the affinity loss, our FCN learns feature clusters of better quality, and the class margins are clearly wider among different classes.
3.2. Multi-Head Attention Network (MAN)
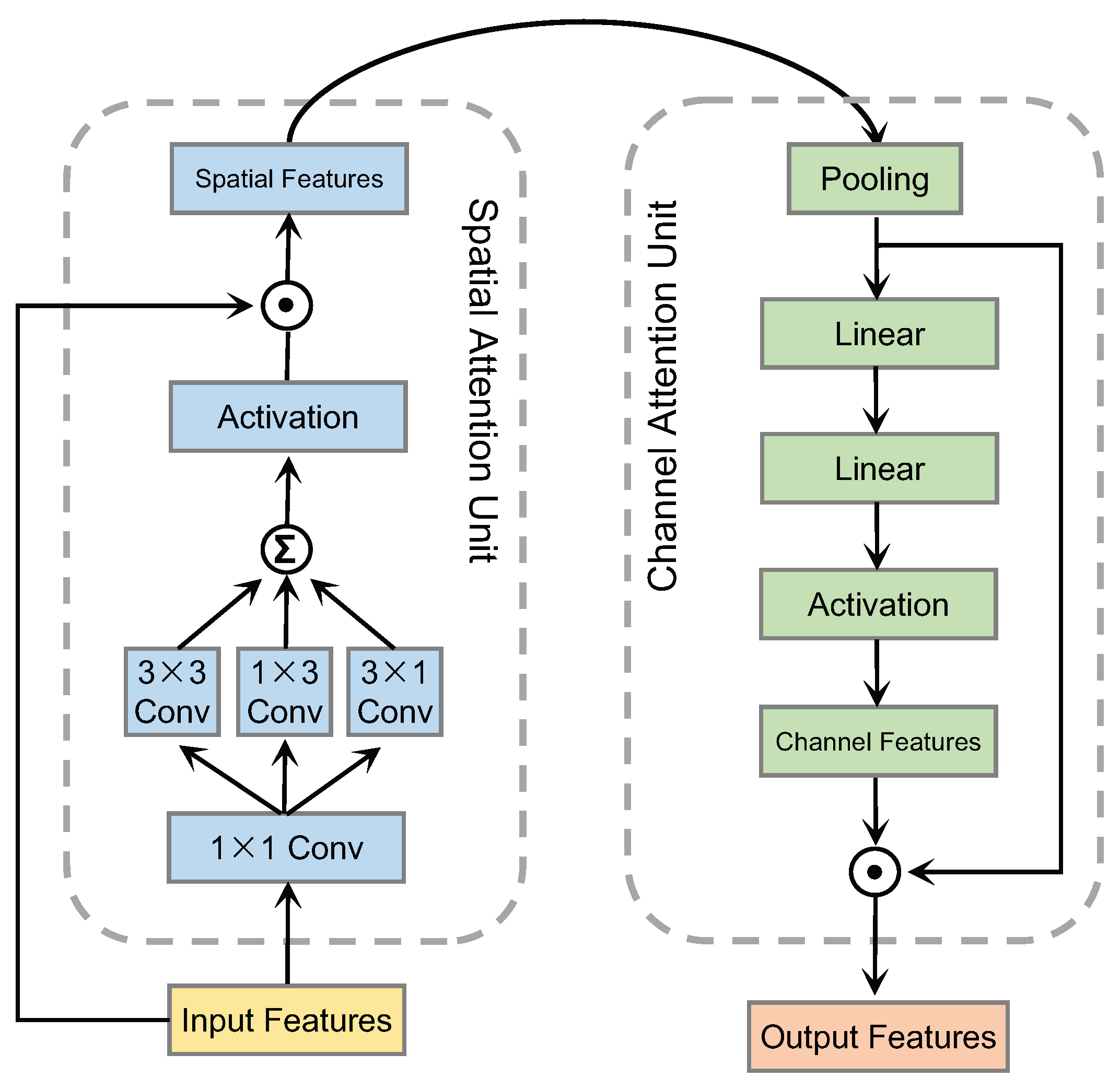
As discussed earlier, a single attention head may be insufficient for effective FER, and the joint reasoning of multiple local regions is necessary. In this regard, our MAN contains a few parallel heads, which remain independent of each other. As shown in
Figure 4, an attention head is a combination of a spatial attention unit and a channel attention unit. The spatial attention unit receives the input features from the FCN and extracts the spatial features. Then, the channel attention unit accepts the spatial features as the input feature and extracts the channel features. Features from the two above dimensions are then combined into an attention vector. In particular, it should be noted that all parallel heads are identical in terms of their sizes, differing only in parameter values.
More concretely, the left section of
Figure 4 illustrates the spatial attention unit, which consists of four convolutional layers and one activation function. In particular, our method constructs the
and
convolution kernels to capture local features at multiple scales. The channel attention unit shown in the right part consists of a global average pooling layer, two linear layers, and one activation function. In particular, our method takes advantage of having two linear layers to encode the channel information.
Figure 3.
The t-SNE visualization of features obtained with standard center loss (a) and the proposed affinity loss (b) on the RAF-DB dataset with our FCN, color-coded according to their class membership. It is clear that our affinity loss provides much better class separability by optimizing both the inter-class margins and the intra-class variations.
Figure 3.
The t-SNE visualization of features obtained with standard center loss (a) and the proposed affinity loss (b) on the RAF-DB dataset with our FCN, color-coded according to their class membership. It is clear that our affinity loss provides much better class separability by optimizing both the inter-class margins and the intra-class variations.
Formally, let
be the spatial attention heads and
be the output spatial attention maps, where
K is the number of attention heads. Given the output features of our backbone
(the subscript
i is omitted for notation brevity), the output of the
j-th spatial attention unit can then be written as:
where
are the network parameters of
, and ⊙ is the Hadamard product.
Similarly, assume
are the channel attention heads and
are the final attention feature vectors of MAN. The
j-th output
can be written as:
where
are the network parameters of
.
The key benefits of the proposed MAN are two-fold. Firstly, our method incorporates spatial attention and channel attention sequentially for each attention head, so as to efficiently capture high-order interactions among features. More importantly, our method instantiates multiple attention heads so that the model can attend to different facial regions at the same time, which is not possible with a single attention head.
Figure 4.
The structure of the proposed attention head, which consists of a spatial attention unit and a channel attention unit. The spatial attention unit and the channel attention unit work together to enable the attention head to selectively focus on relevant spatial locations and channel features.
Figure 4.
The structure of the proposed attention head, which consists of a spatial attention unit and a channel attention unit. The spatial attention unit and the channel attention unit work together to enable the attention head to selectively focus on relevant spatial locations and channel features.
3.3. Attention Fusion Network (AFN)
Furthermore, to guide the MAN in learning attention maps in an orchestrated fashion, this work proposes the AFN to further enhance the features learned by MAN. Firstly, AFN scales the attention feature vectors by applying a log-softmax function to emphasize the most interesting region. After that, a partition loss is proposed to instruct the attention heads to focus on different crucial regions and avoid overlapping attentions. This would ensure the efficacy of multiple attention heads, making them attend to non-overlapping local regions. Lastly, the normalized attention feature vectors are merged into one, and we can then compute class confidence with a linear layer.
Feature scaling. The final attention feature vectors
are firstly scaled using a log-softmax function along the dimension corresponding to the attention heads, so as to obtain a common metric for the features from different heads. More specifically, the output of MAN from
Section 3.2 gives the attention feature vectors
, and we assume that any of these vectors, e.g., the
j-th vector
, is
L-dimensional (e.g.,
in our experiments). In this case, the feature scaling result
for
can be given by:
where
is the
l-th element of
, and
is the
l-th element of
. After scaling, the features from different heads are further added up for the final classification, as shown in
Figure 2.
Partition loss. This paper proposes a partition loss to direct the attention heads to focus on different facial feature regions so they will not collapse into a single attention. As visualized in the right part of
Figure 1, our partition loss successfully controls the heads of MAN to follow different facial areas without additional interventions. More specifically, we do so by maximizing the variance among attention vectors. In particular, our method considers
K, the number of attention heads, as a parameter to adaptively adjust the descent speed of loss values. The MAN with a larger quantity of attention heads may generate more subtle areas of attention. Overall, we write our partition loss as follows:
where
N is the number of images in the current batch,
L is the dimension of the attention feature vector in each head,
denotes the variance of
where
when the
i-th image and the
l-th dimension are given.
3.4. Model Learning
As shown above, our DAN model is comprised of three components: FCN, MAN, and AFN. In order to train this model, one has to consider the losses from all components (i.e., the affinity loss from FCN, the partition loss from AFN, and the cross-entropy loss for image classification) within a unified framework. Following the standard practice in deep learning, our method learns a final loss function by integrating all these loss functions:
where
,
are the weighting hyper-parameters for
and
.
denotes the cross-entropy loss in image classification. In our experiments, we empirically set both
and
to
and note that the consistent performance gains we observe are not particularly sensitive to their values.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




