
Analyzing Pile-Up Crash Severity: Insights from Real-Time Traffic and Environmental Factors Using Ensemble Machine Learning and Shapley Additive Explanations Method


Abstract
:1. Introduction
1.1. Definition and Background of PU Crash
1.2. Importance of Real-Time Traffic Characteristics in Safety
1.3. Application of Machine Learning and Interpretation Methods
1.4. Aims
- Exploring the interacting effects of real-time traffic parameters and environmental conditions on the severity of PU crashes to address these rare and complex aspects of traffic incidents.
- Utilizing ML models and the SHAP method, proficient in identifying complex patterns and interpreting influence and interactions, in order to present results that are easily interpretable for policymakers.
2. Data
2.1. Real-Time Traffic Characteristics
2.2. Crash Characteristics
2.3. Environmental Factors
3. Methodology
3.1. Categorical Boosting Method (CatBoost)
3.2. Resampling
3.3. Hyperparameter Tuning
3.4. Model Evaluation
3.5. Model Interpretation
4. Results and Discussion
4.1. Model Fitting and Evaluation Results
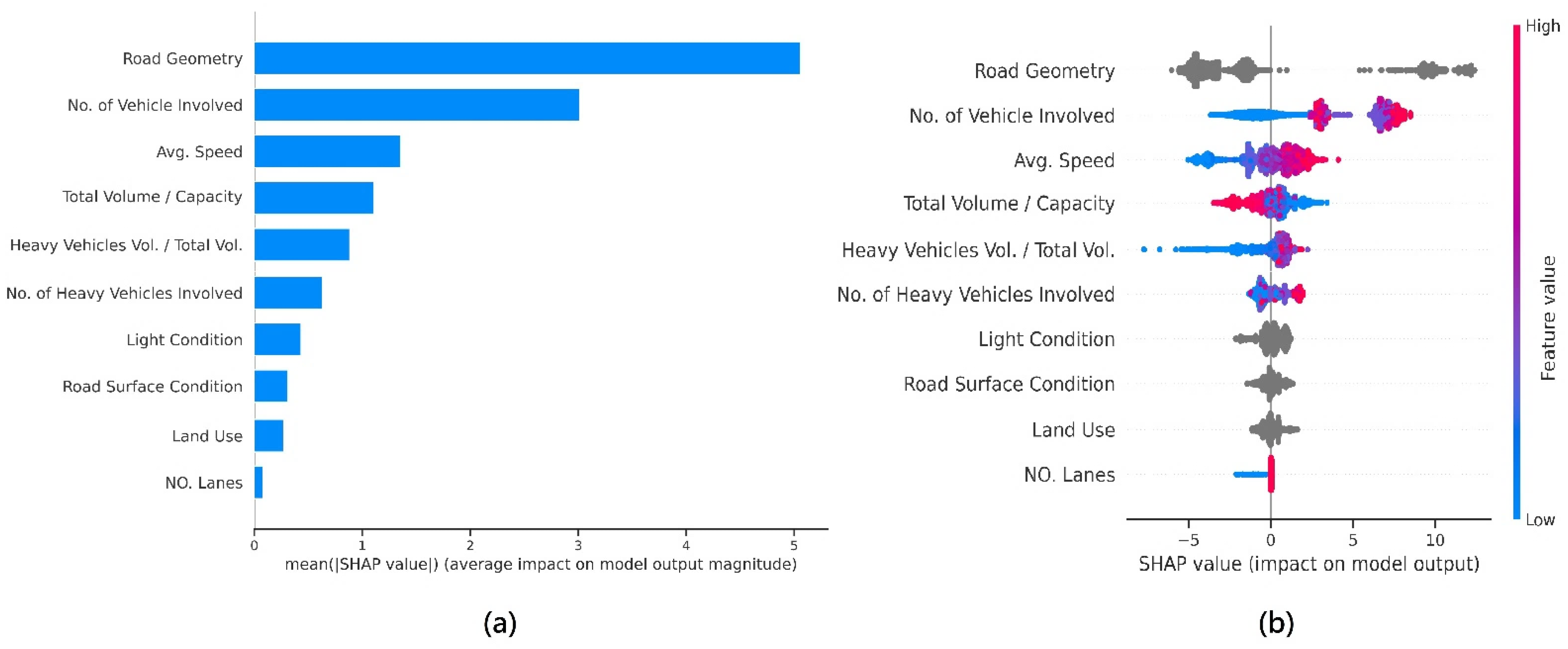
4.2. Importance and Global Interpretation of Risk Factors
4.3. Main and Interacting Effects of Risk Factors
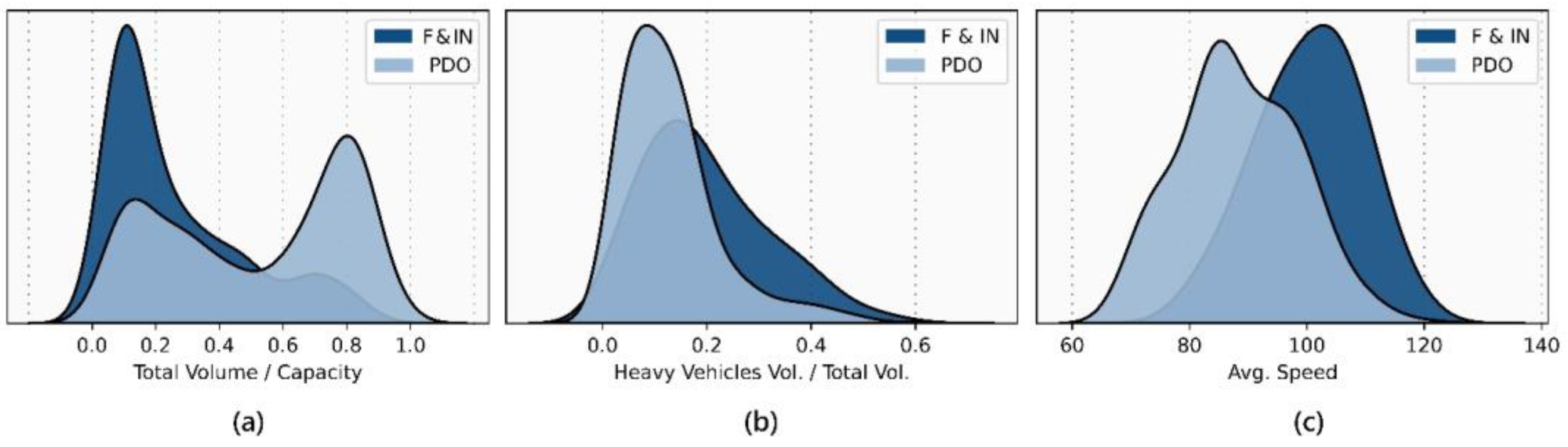
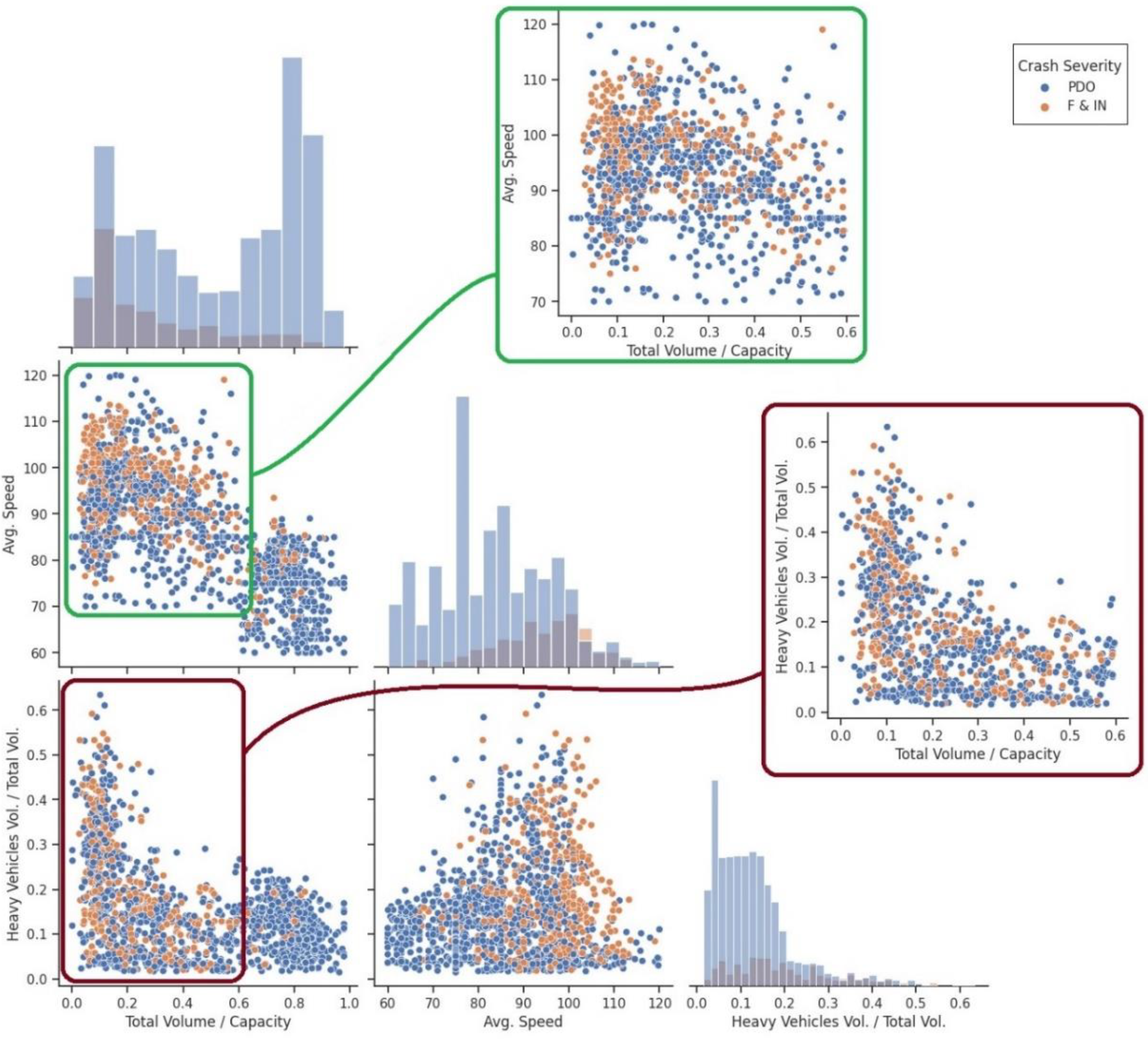
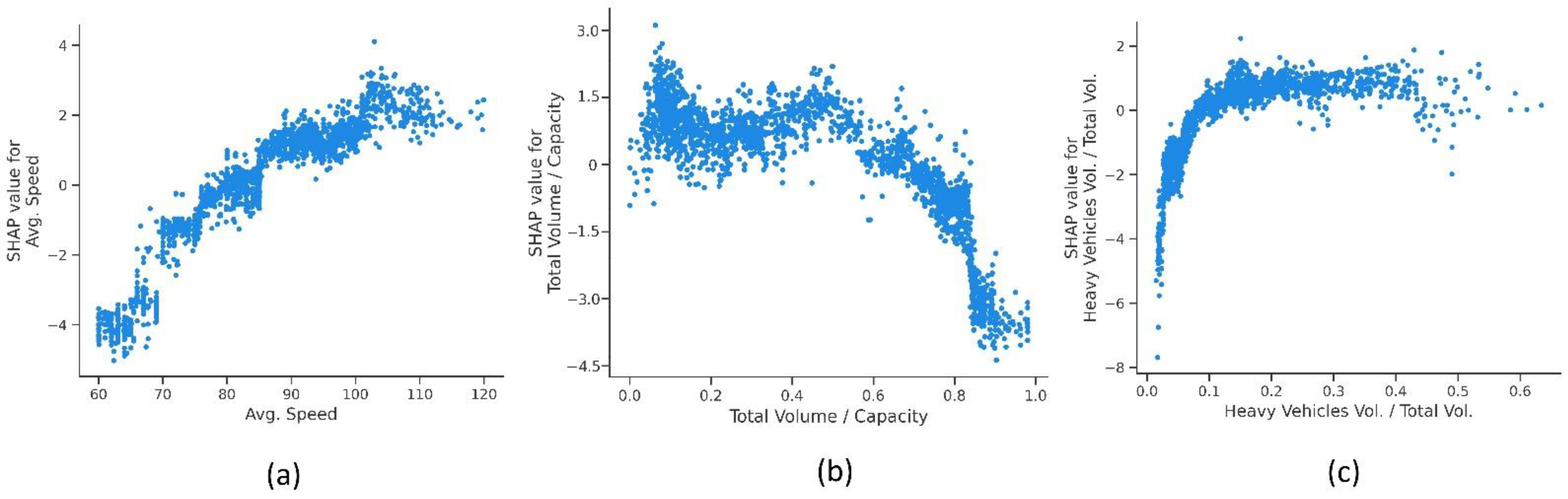
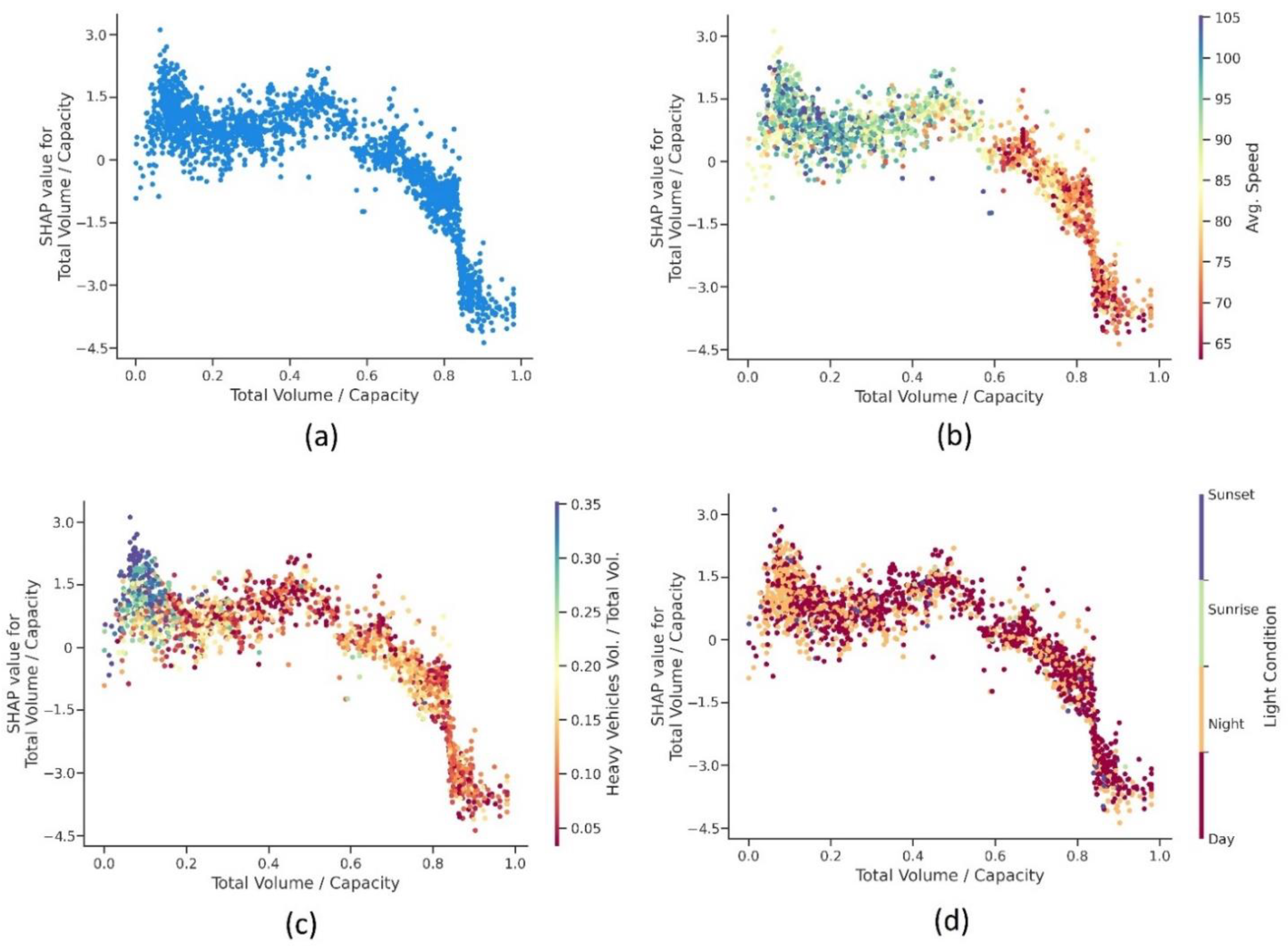
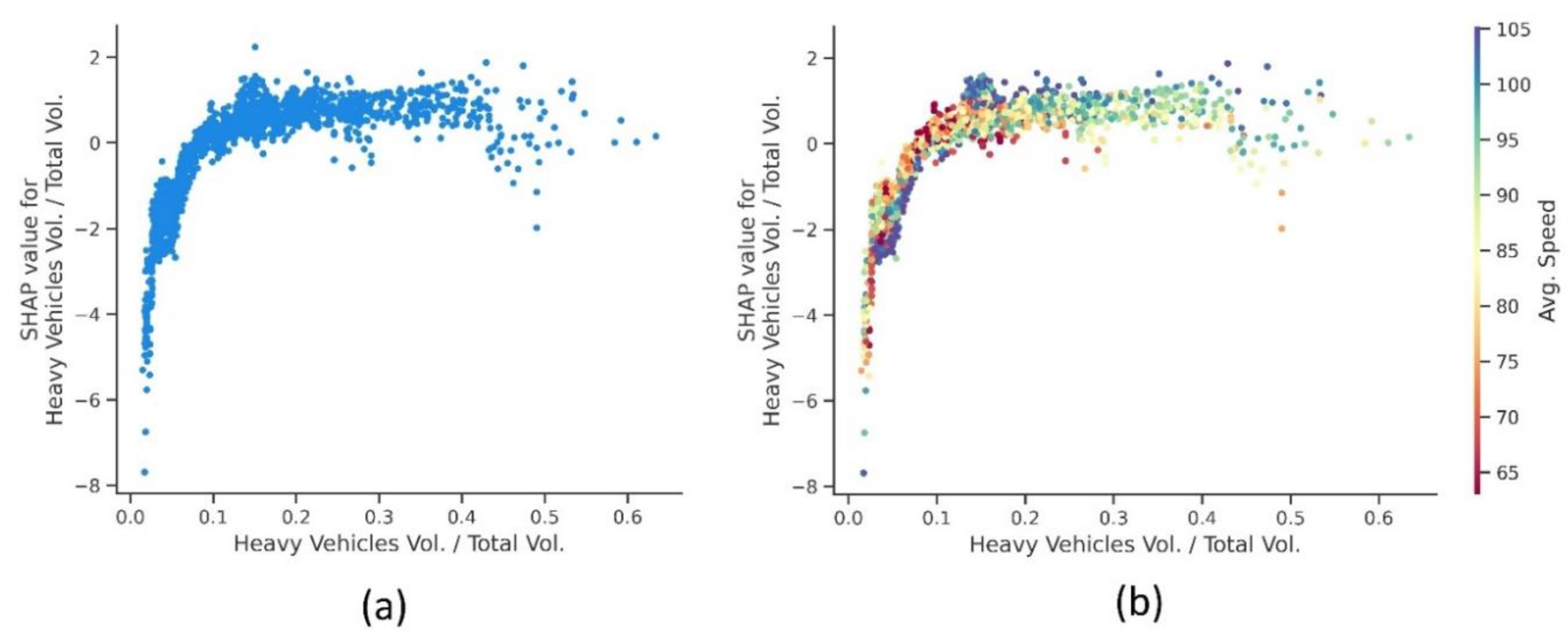
4.3.1. Real-Time Traffic Factors
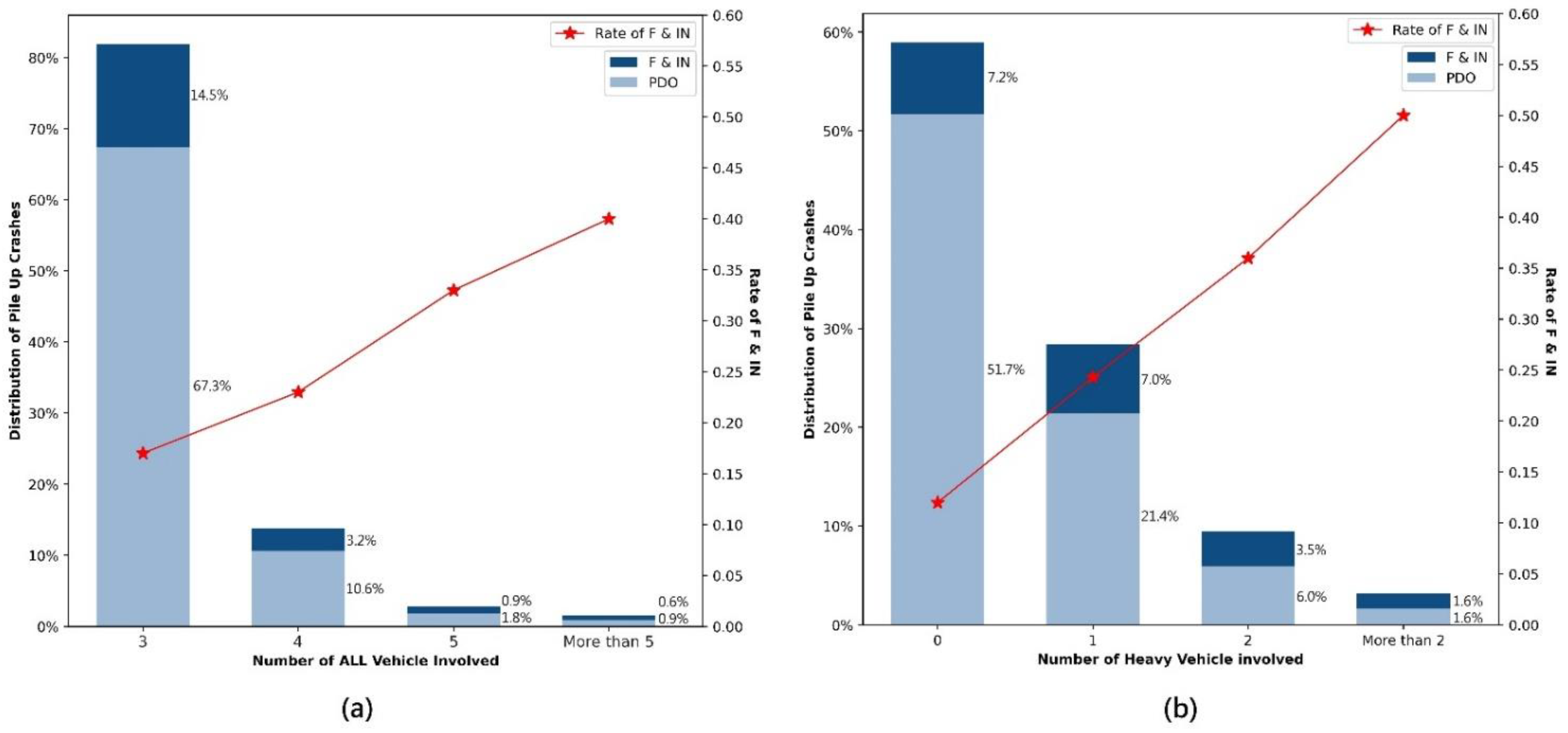
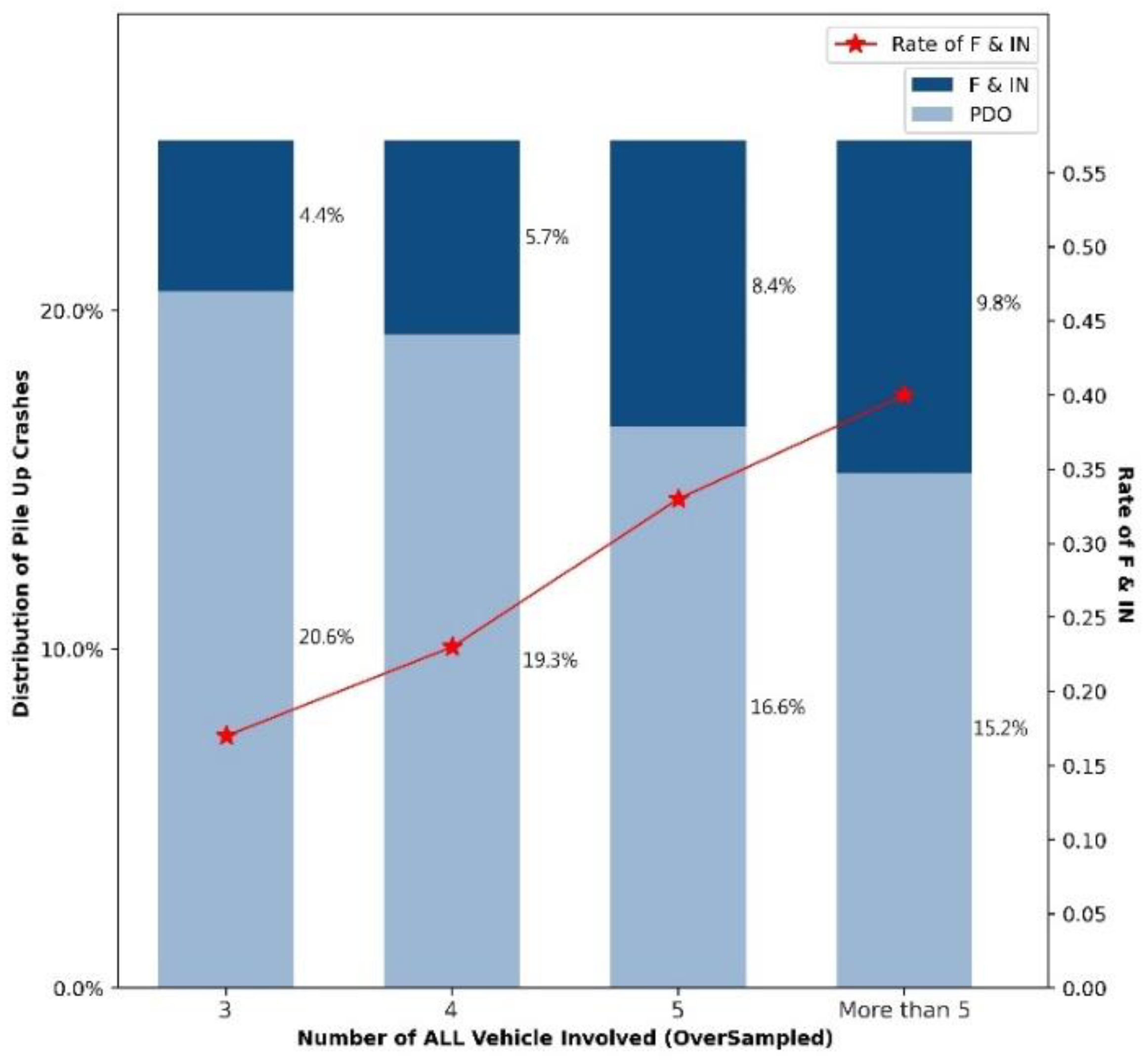
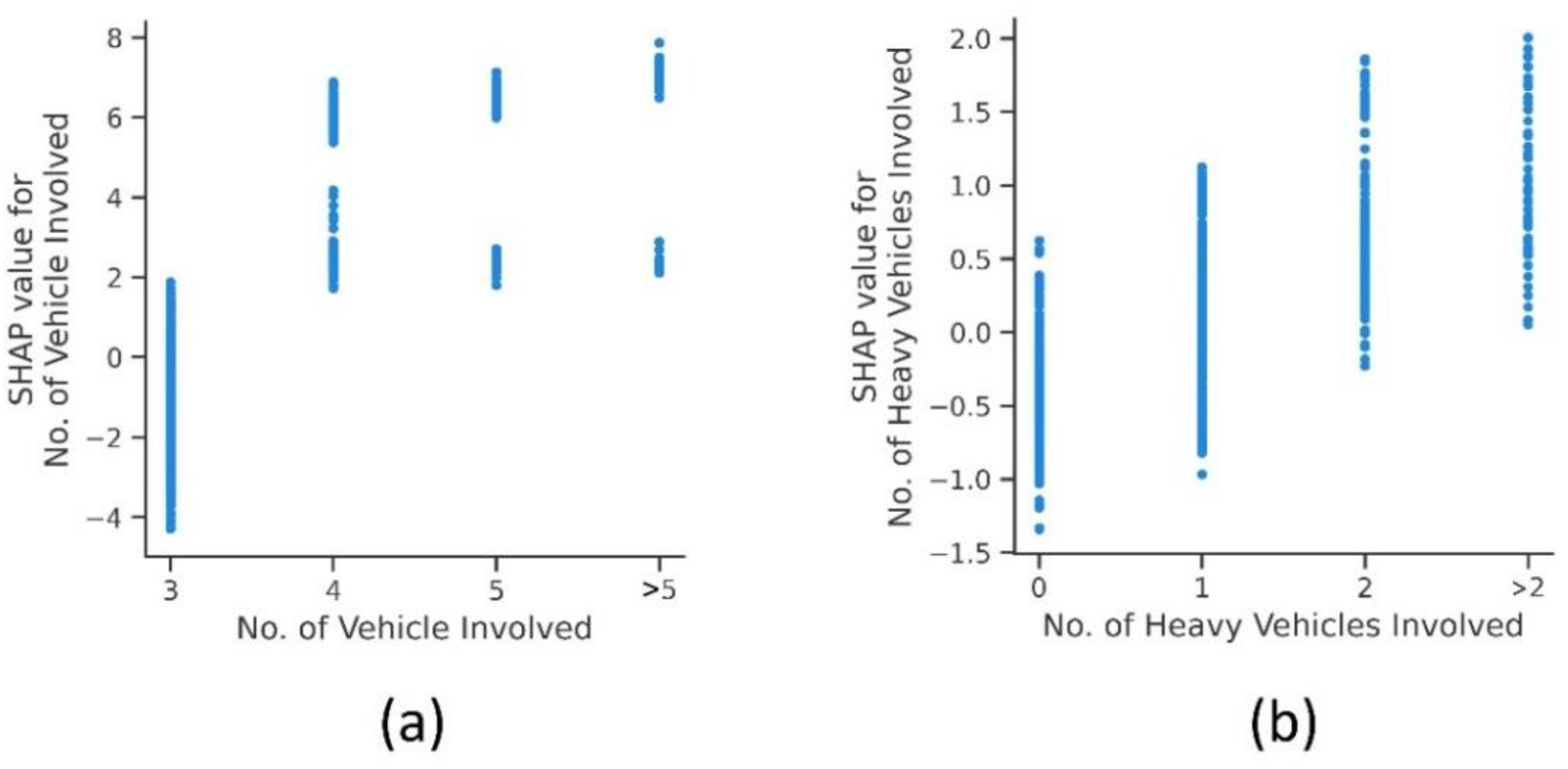
4.3.2. Crash Characteristics
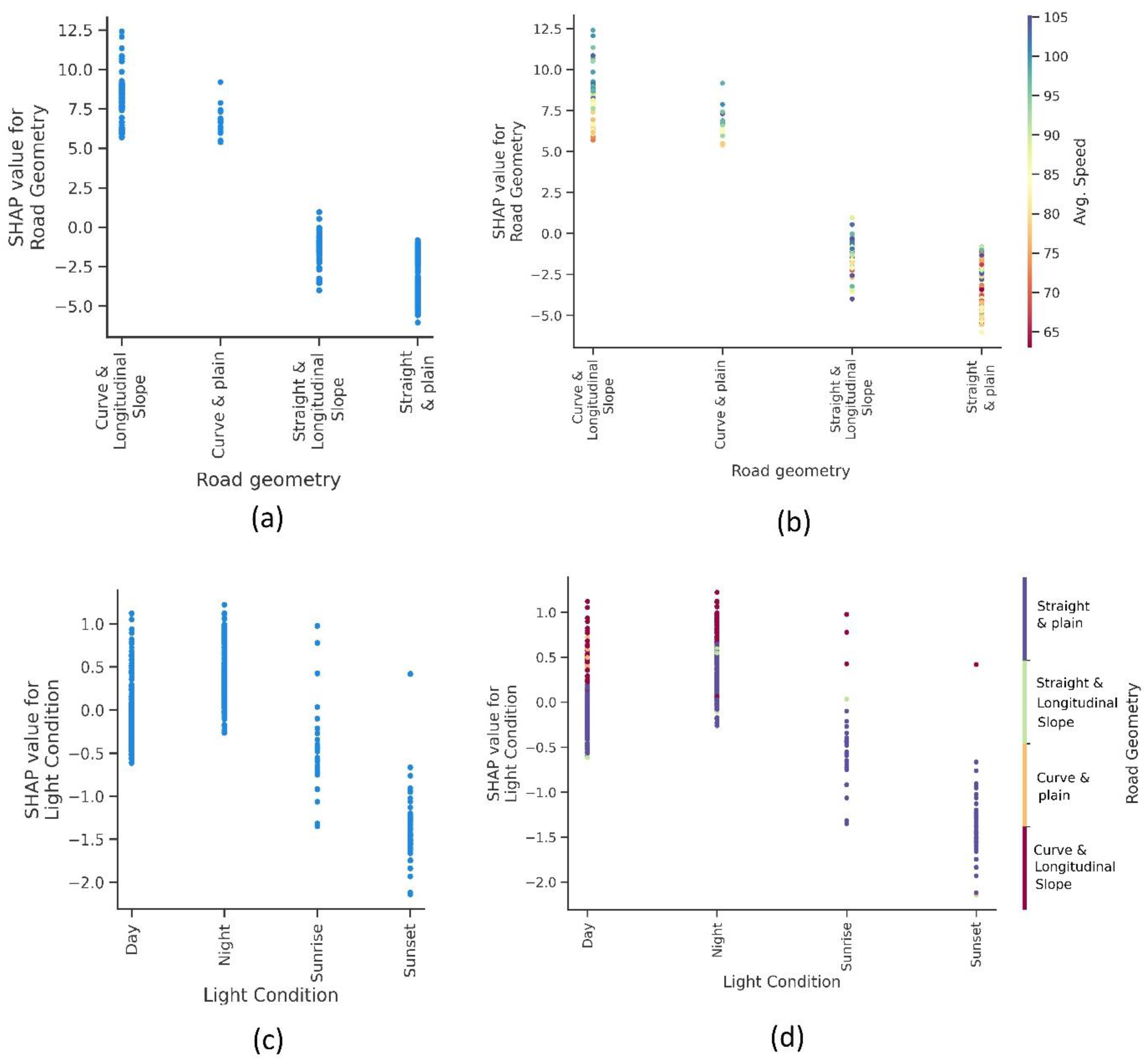
4.3.3. Environmental Factors
5. Conclusions
6. Limitations and Future Direction
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lord, D.; Washington, S. Safe Mobility: Challenges, Methodology and Solutions; Emerald Publishing Bingley: West Yorkshire, UK, 2018. [Google Scholar]
- WHO—World Health Organization. Global Status Report on Road Safety 2023; World Health Organization, WHO Press: Geneva, Switzerland, 2023. [Google Scholar]
- Bakhtiyari, M.; Delpisheh, A.; Monfared, A.B.; Kazemi-Galougahi, M.H.; Mehmandar, M.R.; Riahi, M.; Salehi, M.; Mansournia, M.A. The road traffic crashes as a neglected public health concern; an observational study from Iranian population. Traffic Inj. Prev. 2015, 16, 36–41. [Google Scholar] [CrossRef]
- Hosseinzadeh, A.; Moeinaddini, A.; Ghasemzadeh, A. Investigating factors affecting severity of large truck-involved crashes: Comparison of the SVM and random parameter logit model. J. Saf. Res. 2021, 77, 151–160. [Google Scholar] [CrossRef]
- Meng, F.; Xu, P.; Song, C.; Gao, K.; Zhou, Z.; Yang, L. Influential factors associated with consecutive crash severity: A two-level logistic modeling approach. Int. J. Environ. Res. Public Health 2020, 17, 5623. [Google Scholar] [CrossRef]
- Feng, M.; Wang, X.; Li, Y. Analyzing single-vehicle and multi-vehicle freeway crashes with unobserved heterogeneity. J. Transp. Saf. Secur. 2023, 15, 59–81. [Google Scholar] [CrossRef]
- Geedipally, S.R.; Lord, D. Investigating the effect of modeling single-vehicle and multi-vehicle crashes separately on confidence intervals of Poisson–gamma models. Accid. Anal. Prev. 2010, 42, 1273–1282. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Ren, G.; Li, H.; Wang, S.; Yu, J. Characterizing the differences of injury severity between single-vehicle and multi-vehicle crashes in China. J. Transp. Saf. Secur. 2023, 15, 314–334. [Google Scholar] [CrossRef]
- Wu, Q.; Chen, F.; Zhang, G.; Liu, X.C.; Wang, H.; Bogus, S.M. Mixed logit model-based driver injury severity investigations in single- and multi-vehicle crashes on rural two-lane highways. Accid. Anal. Prev. 2014, 72, 105–115. [Google Scholar] [CrossRef]
- Zichu, Z.; Fanyu, M.; Cancan, S.; Richard, T.; Zhongyin, G.; Lili, Y.; Weili, W. Factors associated with consecutive and non-consecutive crashes on freeways: A two-level logistic modeling approach. Accid. Anal. Prev. 2021, 154, 106054. [Google Scholar] [CrossRef] [PubMed]
- Nagatani, T.; Yonekura, S. Multiple-vehicle collision induced by lane changing in traffic flow. Phys. A Stat. Mech. Appl. 2014, 404, 171–179. [Google Scholar] [CrossRef]
- Nagatani, T. Chain-reaction crash in traffic flow controlled by taillights. Phys. A Stat. Mech. Appl. 2015, 419, 1–6. [Google Scholar] [CrossRef]
- Xu, C.; Liu, P.; Yang, B.; Wang, W. Real-time estimation of secondary crash likelihood on freeways using high-resolution loop detector data. Transp. Res. Part C Emerg. Technol. 2016, 71, 406–418. [Google Scholar] [CrossRef]
- Li, J.; Guo, J.; Wijnands, J.S.; Yu, R.; Xu, C.; Stevenson, M. Assessing injury severity of secondary incidents using support vector machines. J. Transp. Saf. Secur. 2022, 14, 197–216. [Google Scholar] [CrossRef]
- Huang, H.; Ding, X.; Yuan, C.; Liu, X.; Tang, J. Jointly analyzing freeway primary and secondary crash severity using a copula-based approach. Accid. Anal. Prev. 2023, 180, 106911. [Google Scholar] [CrossRef] [PubMed]
- Mishra, S.; Golias, M.; Sarker, A.; Naimi, A. Effect of Primary and Secondary Crashes: Identification, Visualization, and Prediction; National Center for Freight & Infrastructure Research & Education: Madison, WI, USA, 2016. [Google Scholar]
- Zhang, H.; Khattak, A. What is the role of multiple secondary incidents in traffic operations? J. Transp. Eng. 2010, 136, 986–997. [Google Scholar] [CrossRef]
- Høye, A.K.; Hesjevoll, I.S. Traffic volume and crashes and how crash and road characteristics affect their relationship—A meta-analysis. Accid. Anal. Prev. 2020, 145, 105668. [Google Scholar] [CrossRef]
- Kitali, A.E.; Alluri, P.; Sando, T.; Haule, H.; Kidando, E.; Lentz, R. Likelihood estimation of secondary crashes using Bayesian complementary log-log model. Accid. Anal. Prev. 2018, 119, 58–67. [Google Scholar] [CrossRef]
- Park, H.; Haghani, A.; Samuel, S.; Knodler, M.A. Real-time prediction and avoidance of secondary crashes under unexpected traffic congestion. Accid. Anal. Prev. 2018, 112, 39–49. [Google Scholar] [CrossRef]
- Li, P.; Abdel-Aty, M. A hybrid machine learning model for predicting Real-Time secondary crash likelihood. Accid. Anal. Prev. 2022, 165, 106504. [Google Scholar] [CrossRef]
- Yu, R.; Abdel-Aty, M. Analyzing crash injury severity for a mountainous freeway incorporating real-time traffic and weather data. Saf. Sci. 2014, 63, 50–56. [Google Scholar] [CrossRef]
- Yu, R.; Abdel-Aty, M. Using hierarchical Bayesian binary probit models to analyze crash injury severity on high speed facilities with real-time traffic data. Accid. Anal. Prev. 2014, 62, 161–167. [Google Scholar] [CrossRef] [PubMed]
- Lord, D.; Manar, A.; Vizioli, A. Modeling crash-flow-density and crash-flow-V/C ratio relationships for rural and urban freeway segments. Accid. Anal. Prev. 2005, 37, 185–199. [Google Scholar] [CrossRef]
- Quddus, M.A.; Wang, C.; Ison, S.G. Road traffic congestion and crash severity: Econometric analysis using ordered response models. J. Transp. Eng. 2010, 136, 424–435. [Google Scholar] [CrossRef]
- Wang, C.; Quddus, M.; Ison, S. A spatio-temporal analysis of the impact of congestion on traffic safety on major roads in the UK. Transp. A Transp. Sci. 2013, 9, 124–148. [Google Scholar] [CrossRef]
- Apley, D.W.; Zhu, J. Visualizing the effects of predictor variables in black box supervised learning models. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2020, 82, 1059–1086. [Google Scholar] [CrossRef]
- Silva, P.B.; Andrade, M.; Ferreira, S. Machine learning applied to road safety modeling: A systematic literature review. J. Traffic Transp. Eng. (Engl. Ed.) 2020, 7, 775–790. [Google Scholar] [CrossRef]
- Prati, G.; Pietrantoni, L.; Fraboni, F. Using data mining techniques to predict the severity of bicycle crashes. Accid. Anal. Prev. 2017, 101, 44–54. [Google Scholar] [CrossRef] [PubMed]
- López, G.; Abellán, J.; Montella, A.; de Oña, J. Patterns of Single-Vehicle Crashes on Two-Lane Rural Highways in Granada Province, Spain: In-Depth Analysis through Decision Rules. Transp. Res. Rec. 2014, 2432, 133–141. [Google Scholar] [CrossRef]
- Montella, A.; Aria, M.; D’Ambrosio, A.; Mauriello, F. Data-Mining Techniques for Exploratory Analysis of Pedestrian Crashes. Transp. Res. Rec. 2011, 2237, 107–116. [Google Scholar] [CrossRef]
- Montella, A.; de Oña, R.; Mauriello, F.; Rella Riccardi, M.; Silvestro, G. A data mining approach to investigate patterns of pow-ered two-wheeler crashes in Spain. Accid. Anal. Prev. 2020, 134, 105251. [Google Scholar] [CrossRef] [PubMed]
- Montella, A.; Mauriello, F.; Pernetti, M.; Rella Riccardi, M. Rule discovery to identify patterns contributing to overrepresentation and severity of run-off-the-road crashes. Accid. Anal. Prev. 2021, 155, 106119. [Google Scholar] [CrossRef] [PubMed]
- Moral-Garcia, S.; Castellano, J.G.; Mantas, J.G.; Montella, A.; Abellan, J. Decision tree ensemble method for analyzing traffic accidents of novice drivers in urban areas. Entropy 2019, 21, 360. [Google Scholar] [CrossRef]
- Rella Riccardi, M.; Galante, F.; Scarano, A.; Montella, A. Econometric and machine learning methods to identify pedestrian crash patterns. Sustainability 2022, 14, 15471. [Google Scholar] [CrossRef]
- Rella Riccardi, M.; Mauriello, F.; Scarano, A.; Montella, A. Analysis of contributory factors of fatal pedestrian crashes by mixed logit model and association rules. Int. J. Inj. Control Saf. Promot. 2023, 30, 195–209. [Google Scholar] [CrossRef]
- Iranitalab, A.; Khattak, A. Comparison of four statistical and machine learning methods for crash severity prediction. Accid. Anal. Prev. 2017, 108, 27–36. [Google Scholar] [CrossRef]
- Santos, K.; Dias, J.P.; Amado, C. A literature review of machine learning algorithms for crash injury severity prediction. J. Saf. Res. 2021, 80, 254–269. [Google Scholar] [CrossRef]
- Rella Riccardi, M.; Mauriello, F.; Sarkar, S.; Galante, F.; Scarano, A.; Montella, A. Parametric and Non-Parametric Analyses for Pedestrian Crash Severity Prediction in Great Britain. Sustainability 2022, 14, 3188. [Google Scholar] [CrossRef]
- Scarano, A.; Rella Riccardi, M.; Mauriello, F.; D’Agostino, C.; Pasquino, N.; Montella, A. Injury severity prediction of cyclist crashes using random forests and random parameters logit models. Accid. Anal. Prev. 2023, 192, 107275. [Google Scholar] [CrossRef] [PubMed]
- Zhu, S. Analysis of the severity of vehicle-bicycle crashes with data mining techniques. J. Saf. Res. 2021, 76, 218–227. [Google Scholar] [CrossRef]
- Scarano, A.; Aria, M.; Mauriello, F.; Rella Riccardi, M.; Montella, A. Systematic literature review of 10 years of cyclist safety research. Accid. Anal. Prev. 2023, 184, 106996. [Google Scholar] [CrossRef]
- Dong, S.; Khattak, A.; Ullah, I.; Zhou, J.; Hussain, A. Predicting and analyzing road traffic injury severity using boosting-based ensemble learning models with SHAPley Additive exPlanations. Int. J. Environ. Res. Public Health 2022, 19, 2925. [Google Scholar] [CrossRef] [PubMed]
- Hasan, A.S.; Jalayer, M.; Das, S.; Kabir, M.A.B. Application of Machine Learning Models and SHAP to Examine Crashes Involving Young Drivers in New Jersey. Int. J. Transp. Sci. Technol. 2023; in press. [Google Scholar]
- Lin, C.; Wu, D.; Liu, H.; Xia, X.; Bhattarai, N. Factor identification and prediction for teen driver crash severity using machine learning: A case study. Appl. Sci. 2020, 10, 1675. [Google Scholar] [CrossRef]
- Ma, Z.; Mei, G.; Cuomo, S. An analytic framework using deep learning for prediction of traffic accident injury severity based on contributing factors. Accid. Anal. Prev. 2021, 160, 106322. [Google Scholar] [CrossRef]
- Wen, X.; Xie, Y.; Wu, L.; Jiang, L. Quantifying and comparing the effects of key risk factors on various types of roadway segment crashes with LightGBM and SHAP. Accid. Anal. Prev. 2021, 159, 106261. [Google Scholar] [CrossRef]
- Xu, G.; Duong, T.D.; Li, Q.; Liu, S.; Wang, X. Causality learning: A new perspective for interpretable machine learning. arXiv 2020, arXiv:2006.16789. [Google Scholar]
- Mussone, L.; Bassani, M.; Masci, P. Analysis of factors affecting the severity of crashes in urban road intersections. Accid. Anal. Prev. 2017, 103, 112–122. [Google Scholar] [CrossRef] [PubMed]
- Tang, J.; Liang, J.; Han, C.; Li, Z.; Huang, H. Crash injury severity analysis using a two-layer Stacking framework. Accid. Anal. Prev. 2019, 122, 226–238. [Google Scholar] [CrossRef]
- Wang, X.; Kim, S.H. Prediction and factor identification for crash severity: Comparison of discrete choice and tree-based models. Transp. Res. Rec. 2019, 2673, 640–653. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Toran Pour, A.; Moridpour, S.; Tay, R.; Rajabifard, A. Modelling pedestrian crash severity at mid-blocks. Transp. A Transp. Sci. 2017, 13, 273–297. [Google Scholar] [CrossRef]
- Masís, S. Interpretable Machine Learning with Python: Learn to Build Interpretable High-Performance Models with Hands-On Real-World Examples; Packt Publishing Ltd.: Birmingham, UK, 2021. [Google Scholar]
- Molnar, C. Interpretable Machine Learning; Lulu. com: Raleigh, NC, USA, 2020. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems, Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017; NeurIPS: Long Beach, CA, USA, 2017; Volume 30. [Google Scholar]
- Parsa, A.B.; Movahedi, A.; Taghipour, H.; Derrible, S.; Mohammadian, A.K. Toward safer highways, application of XGBoost and SHAP for real-time accident detection and feature analysis. Accid. Anal. Prev. 2020, 136, 105405. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Chen, M.; Yuan, Q. The application of XGBoost and SHAP to examining the factors in freight truck-related crashes: An exploratory analysis. Accid. Anal. Prev. 2021, 158, 106153. [Google Scholar] [CrossRef]
- IRMTO—Iran Road Maintenance and Transportation Organization; Minestry of Roads and Urban Development. 2023. Available online: https://rmto.ir/en/ (accessed on 15 July 2023).
- Theofilatos, A. Incorporating real-time traffic and weather data to explore road accident likelihood and severity in urban arterials. J. Saf. Res. 2017, 61, 9–21. [Google Scholar] [CrossRef] [PubMed]
- Theofilatos, A.; Ziakopoulos, A. Traffic Flow Volume and Safety. In International Encyclopedia of Transportation; Vickerman, R., Ed.; Elsevier: Oxford, UK, 2021; pp. 692–698. [Google Scholar]
- Elvik, R.; Vadeby, A.; Hels, T.; van Schagen, I. Updated estimates of the relationship between speed and road safety at the aggregate and individual levels. Accid. Anal. Prev. 2019, 123, 114–122. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Hancock, J.T.; Khoshgoftaar, T.M. CatBoost for big data: An interdisciplinary review. J. Big Data 2020, 7, 94. [Google Scholar] [CrossRef] [PubMed]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems, Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017; NeurIPS: Long Beach, CA, USA, 2017; Volume 30. [Google Scholar]
- Wang, F.; Jiang, D.; Wen, H.; Song, H. Adaboost-based security level classification of mobile intelligent terminals. J. Supercomput. 2019, 75, 7460–7478. [Google Scholar] [CrossRef]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Hussain, S.; Mustafa, M.W.; Jumani, T.A.; Baloch, S.K.; Alotaibi, H.; Khan, I.; Khan, A. A novel feature engineered-CatBoost-based supervised machine learning framework for electricity theft detection. Energy Rep. 2021, 7, 4425–4436. [Google Scholar] [CrossRef]
- Morris, C.; Yang, J.J. Effectiveness of resampling methods in coping with imbalanced crash data: Crash type analysis and predictive modeling. Accid. Anal. Prev. 2021, 159, 106240. [Google Scholar] [CrossRef]
- Ying, X. An overview of overfitting and its solutions. Proc. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Štrumbelj, E.; Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 2014, 41, 647–665. [Google Scholar] [CrossRef]
- Lundberg, S.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Ahmed, S.S.; Alnawmasi, N.; Anastasopoulos, P.C.; Mannering, F. The effect of higher speed limits on crash-injury severity rates: A correlated random parameters bivariate tobit approach. Anal. Methods Accid. Res. 2022, 34, 100213. [Google Scholar] [CrossRef]
- Alnawmasi, N.; Mannering, F. The impact of higher speed limits on the frequency and severity of freeway crashes: Accounting for temporal shifts and unobserved heterogeneity. Anal. Methods Accid. Res. 2022, 34, 100205. [Google Scholar] [CrossRef]
- Hasan, A.S.; Orvin, M.M.; Jalayer, M.; Heitmann, E.; Weiss, J. Analysis of distracted driving crashes in New Jersey using mixed logit model. J. Saf. Res. 2022, 81, 166–174. [Google Scholar] [CrossRef] [PubMed]
- Khan, G.; Bill, A.R.; Noyce, D.A. Exploring the feasibility of classification trees versus ordinal discrete choice models for analyzing crash severity. Transp. Res. Part C Emerg. Technol. 2015, 50, 86–96. [Google Scholar] [CrossRef]
- Mohanty, M.; Panda, B.; Dey, P.P. Quantification of surrogate safety measure to predict severity of road crashes at median openings. IATSS Res. 2021, 45, 153–159. [Google Scholar] [CrossRef]
- Xu, C.; Tarko, A.P.; Wang, W.; Liu, P. Predicting crash likelihood and severity on freeways with real-time loop detector data. Accid. Anal. Prev. 2013, 57, 30–39. [Google Scholar] [CrossRef]
- Harwood, D.W.; Bauer, K.M.; Potts, I.B. Development of Relationships between Safety and Congestion for Urban Freeways. Transp. Res. Rec. 2013, 2398, 28–36. [Google Scholar] [CrossRef]
- Jo, Y.; Oh, C.; Kim, S. Estimation of heavy vehicle-involved rear-end crash potential using WIM data. Accid. Anal. Prev. 2019, 128, 103–113. [Google Scholar] [CrossRef]
- Hyun, K.; Jeong, K.; Tok, A.; Ritchie, S.G. Assessing crash risk considering vehicle interactions with trucks using point detector data. Accid. Anal. Prev. 2019, 130, 75–83. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Rasouli, S.; Zhao, J.; Qian, Y.; Cheng, L. Large truck fatal crash severity segmentation and analysis incorporating all parties involved: A Bayesian network approach. Travel Behav. Soc. 2023, 30, 135–147. [Google Scholar] [CrossRef]
- Zhu, X.; Srinivasan, S. A comprehensive analysis of factors influencing the injury severity of large-truck crashes. Accid. Anal. Prev. 2011, 43, 49–57. [Google Scholar] [CrossRef]
- Rakotonirainy, A.; Chen, S.; Scott-Parker, B.; Loke, S.W.; Krishnaswamy, S. A novel approach to assessing road-curve crash severity. J. Transp. Saf. Secur. 2015, 7, 358–375. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, W. Analysis of Roadway and Environmental Factors Affecting Traffic Crash Severities. Transp. Res. Procedia 2017, 25, 2119–2125. [Google Scholar] [CrossRef]
- Rusli, R.; Haque, M.M.; Saifuzzaman, M.; King, M. Crash severity along rural mountainous highways in Malaysia: An application of a combined decision tree and logistic regression model. Traffic Inj. Prev. 2018, 19, 741–748. [Google Scholar] [CrossRef] [PubMed]
- Wen, H.; Ma, Z.; Chen, Z.; Luo, C. Analyzing the impact of curve and slope on multi-vehicle truck crash severity on mountainous freeways. Accid. Anal. Prev. 2023, 181, 106951. [Google Scholar] [CrossRef]
- Abegaz, T.; Berhane, Y.; Worku, A.; Assrat, A.; Assefa, A. Effects of excessive speeding and falling asleep while driving on crash injury severity in Ethiopia: A generalized ordered logit model analysis. Accid. Anal. Prev. 2014, 71, 15–21. [Google Scholar] [CrossRef]
- Ackaah, W.; Apuseyine, B.A.; Afukaar, F.K. Road traffic crashes at night-time: Characteristics and risk factors. Int. J. Inj. Control Saf. Promot. 2020, 27, 392–399. [Google Scholar] [CrossRef]
- Yannis, G.; Athanasios, T.; George, P. Investigation of road accident severity per vehicle type. Transp. Res. Procedia 2017, 25, 2076–2083. [Google Scholar] [CrossRef]
- Yasmin, S.; Eluru, N.; Haque, M.M. Addressing endogeneity in modeling speed enforcement, crash risk and crash severity simultaneously. Anal. Methods Accid. Res. 2022, 36, 100242. [Google Scholar] [CrossRef]
- Montella, A.; Persaud, B.; D’Apuzzo, M.; Imbriani, L.L. Safety Evaluation of an Automated Section Speed Enforcement System. Transp. Res. Rec. 2012, 2281, 16–25. [Google Scholar] [CrossRef]
- Montella, A.; Imbriani, L.L.; Marzano, V.; Mauriello, F. Effects on speed and safety of point-to-point speed enforcement systems: Evaluation on the urban motorway A56 Tangenziale di Napoli. Accid. Anal. Prev. 2015, 75, 164–178. [Google Scholar] [CrossRef] [PubMed]
- Montella, A.; Punzo, V.; Chiaradonna, S.; Mauriello, F.; Montanino, M. Point-to-point speed enforcement systems: Speed limits design criteria and analysis of drivers’ compliance. Transp. Res. Part C Emerg. Technol. 2015, 53, 1–18. [Google Scholar] [CrossRef]
- Soole, D.W.; Watson, B.C.; Fleiter, J.J. Effects of average speed enforcement on speed compliance and crashes: A review of the literature. Accid. Anal. Prev. 2013, 54, 46–56. [Google Scholar] [CrossRef]
- Ahmed, F.; Hawas, Y.E. An integrated real-time traffic signal system for transit signal priority, incident detection and congestion management. Transp. Res. Part C Emerg. Technol. 2015, 60, 52–76. [Google Scholar] [CrossRef]
- Nadi, A.; Sharma, S.; Snelder, M.; Bakri, T.; van Lint, H.; Tavasszy, L. Short-term prediction of outbound truck traffic from the exchange of information in logistics hubs: A case study for the port of Rotterdam. Transp. Res. Part C Emerg. Technol. 2021, 127, 103111. [Google Scholar] [CrossRef]
- Chen, S.; Fu, H.; Wu, N.; Wang, Y.; Qiao, Y. Passenger-oriented traffic management integrating perimeter control and regional bus service frequency setting using 3D-pMFD. Transp. Res. Part C Emerg. Technol. 2022, 135, 103529. [Google Scholar] [CrossRef]
- Islam, M.; Hosseini, P.; Jalayer, M. An analysis of single-vehicle truck crashes on rural curved segments accounting for unobserved heterogeneity. J. Saf. Res. 2022, 80, 148–159. [Google Scholar] [CrossRef]
- Cafiso, S.; Montella, A.; D’Agostino, C.; Mauriello, F.; Galante, F. Crash modification functions for pavement surface condition and geometric design indicators. Accid. Anal. Prev. 2021, 149, 105887. [Google Scholar] [CrossRef]
- Liu, Q.; Shen, H.; Wu, Y.; Xia, Z.; Fang, J.; Li, Q. Crash responses under multiple impacts and residual properties of CFRP and aluminum tubes. Compos. Struct. 2018, 194, 87–103. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | PDO | F & IN | Total | Mean | Std. Dev | Min | Max |
|---|---|---|---|---|---|---|---|---|
| Real-Time Traffic Variables | ||||||||
| TV/C | 0.469 | 0.297 | 0.005 | 0.98 | ||||
| Avg.speed | 84.70 | 12.77 | 60 | 120 | ||||
| HVV/TV | 0.143 | 0.102 | 0.014 | 0.634 | ||||
| Crash Characteristics | ||||||||
| No. of vehicles involved | 3.24 | 0.574 | 3 | 12 | ||||
| No. of heavy vehicles involved | 0.57 | 0.791 | 0 | 3 | ||||
| No. of injuries | 0.15 | 0.537 | 0 | 6 | ||||
| No. of fatalities | 0.02 | 0.203 | 0 | 5 | ||||
| Environmental Characteristics | ||||||||
| NO. Lanes | 2 | 24 (23.07%) | 80 (76.92%) | 104 (4.80%) | ||||
| 3 | 393 (19.06%) | 1668 (80.93%) | 2061 (95.1%) | |||||
| Light Condition | Day | 191 (14.81%) | 1098 (85.18%) | 1289 (59.5%) | ||||
| Night | 213 (27.41%) | 564 (72.58%) | 777 (35.8%) | |||||
| Sunrise | 7 (23.33%) | 23 (76.66%) | 30 (1.38%) | |||||
| Sunset | 6 (8.695%) | 63 (91.30%) | 69 (3.18%) | |||||
| Road Surface Condition | Dry | 321 (18.03%) | 1459 (81.96%) | 1780 (82.2%) | ||||
| Ice and snow | 15 (24.19%) | 47 (75.80%) | 62 (2.86%) | |||||
| Wet | 81 (25.07%) | 242 (74.92%) | 323 (14.9%) | |||||
| Land Use | Agriculture | 96 (39.18%) | 149 (60.81%) | 245 (11.3%) | ||||
| Industrial | 9 (21.42%) | 33 (78.57%) | 42 (1.93%) | |||||
| Other | 305 (16.38%) | 1556 (83.61%) | 1861 (85.9%) | |||||
| Residential | 7 (41.17%) | 10 (58.82%) | 17 (0.78%) | |||||
| Weather Condition | Cloudy and foggy and dusty | 15 (33.33%) | 30 (66.66%) | 45 (2.07%) | ||||
| Rainy | 73 (24.74%) | 222 (75.25%) | 295 (13.6%) | |||||
| Smooth | 309 (17.60%) | 1446 (82.39%) | 1755 (81.0%) | |||||
| Snow | 19 (27.53%) | 50 (72.46%) | 69 (3.18%) | |||||
| Storm | 1 (100%) | 0 (0%) | 1 (0.04%) | |||||
| Road Geometry | Curve and longitudinal slope | 101 (95.28%) | 5 (4.716%) | 106 (4.89%) | ||||
| Curve and plain | 21 (95.45%) | 1 (4.545%) | 22 (1.01%) | |||||
| Straight and longitudinal slope | 19 (22.35%) | 66 (77.64%) | 85 (3.92%) | |||||
| Straight and plain | 276 (14.13%) | 1676 (85.86%) | 1952 (90.1%) | |||||
| Predicted | ||
|---|---|---|
| Observed | Positive | Negative |
| Positive | TP | FN |
| Negative | FP | TN |
| Total | P | N |
| Model (Oversampled Data) | Accuracy | Recall | Precision | F1 Score | ROC-AUC |
|---|---|---|---|---|---|
| CART | 73.1% | 0.0% | 0.0% | 0.0% | 50.0% |
| RF | 95.0% | 87.1% | 93.8% | 90.3% | 92.5% |
| CatBoost | 95.6% | 87.6% | 95.6% | 91.4% | 93.1% |
| XGBoost | 95.3% | 85.7% | 96.3% | 90.7% | 92.2% |
| LightGBM | 95.3% | 86.7% | 95.2% | 90.8% | 92.6% |
| AdaBoost | 95.3% | 86.0% | 96.3% | 90.9% | 92.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samerei, S.A.; Aghabayk, K.; Montella, A. Analyzing Pile-Up Crash Severity: Insights from Real-Time Traffic and Environmental Factors Using Ensemble Machine Learning and Shapley Additive Explanations Method. Safety 2024, 10, 22. https://doi.org/10.3390/safety10010022
Samerei SA, Aghabayk K, Montella A. Analyzing Pile-Up Crash Severity: Insights from Real-Time Traffic and Environmental Factors Using Ensemble Machine Learning and Shapley Additive Explanations Method. Safety. 2024; 10(1):22. https://doi.org/10.3390/safety10010022
Chicago/Turabian StyleSamerei, Seyed Alireza, Kayvan Aghabayk, and Alfonso Montella. 2024. "Analyzing Pile-Up Crash Severity: Insights from Real-Time Traffic and Environmental Factors Using Ensemble Machine Learning and Shapley Additive Explanations Method" Safety 10, no. 1: 22. https://doi.org/10.3390/safety10010022