

Prognostic Modelling Studies of Coronary Heart Disease—A Systematic Review of Conventional and Genetic Risk Factor Studies


Abstract
:1. Introduction
2. Materials and Methods
3. Eligibility Criteria
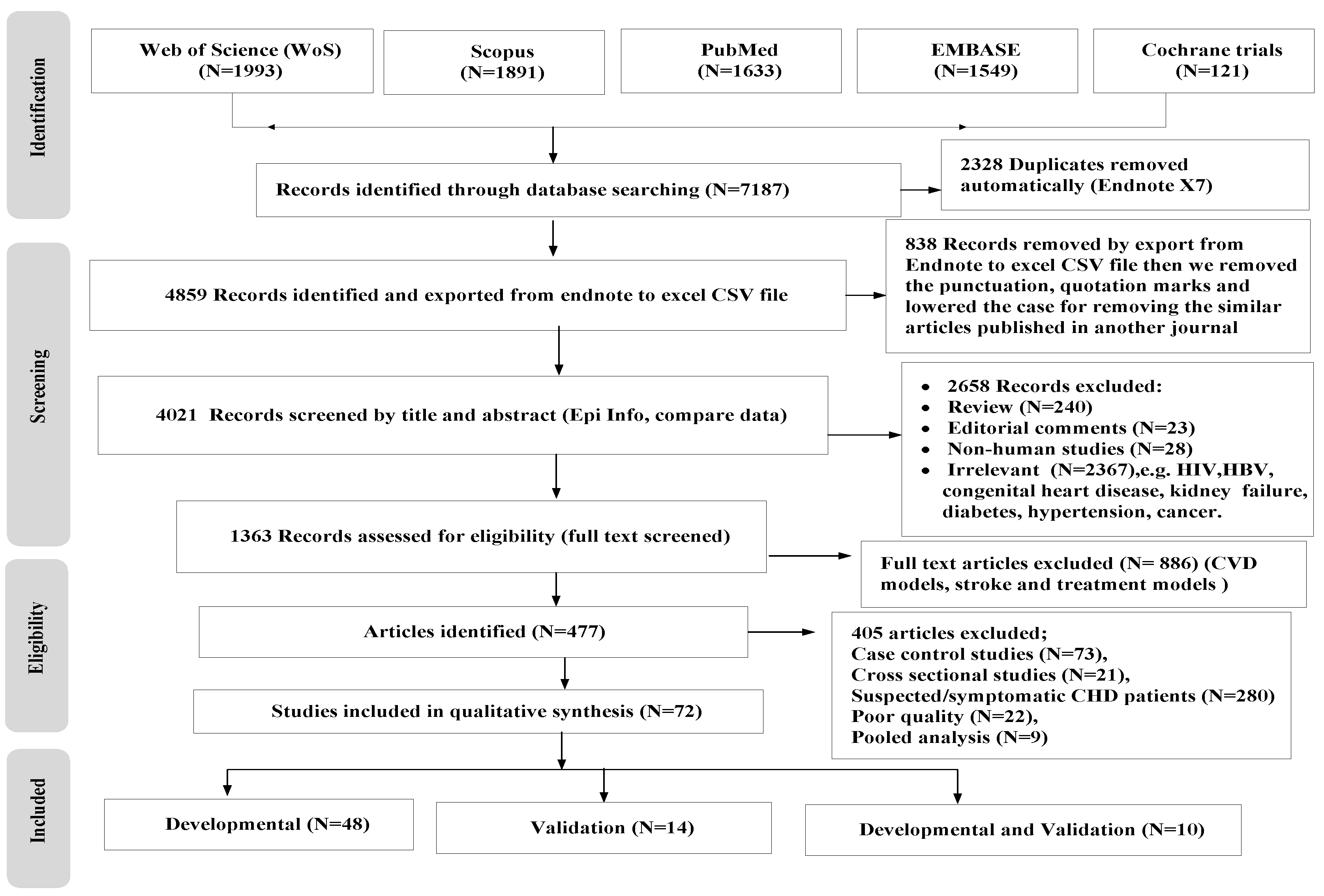
4. Selection Process
5. Data Extraction and Critical Appraisal
6. Results
6.1. Studies Describing the Developmental Type of CHD Prognostic Models
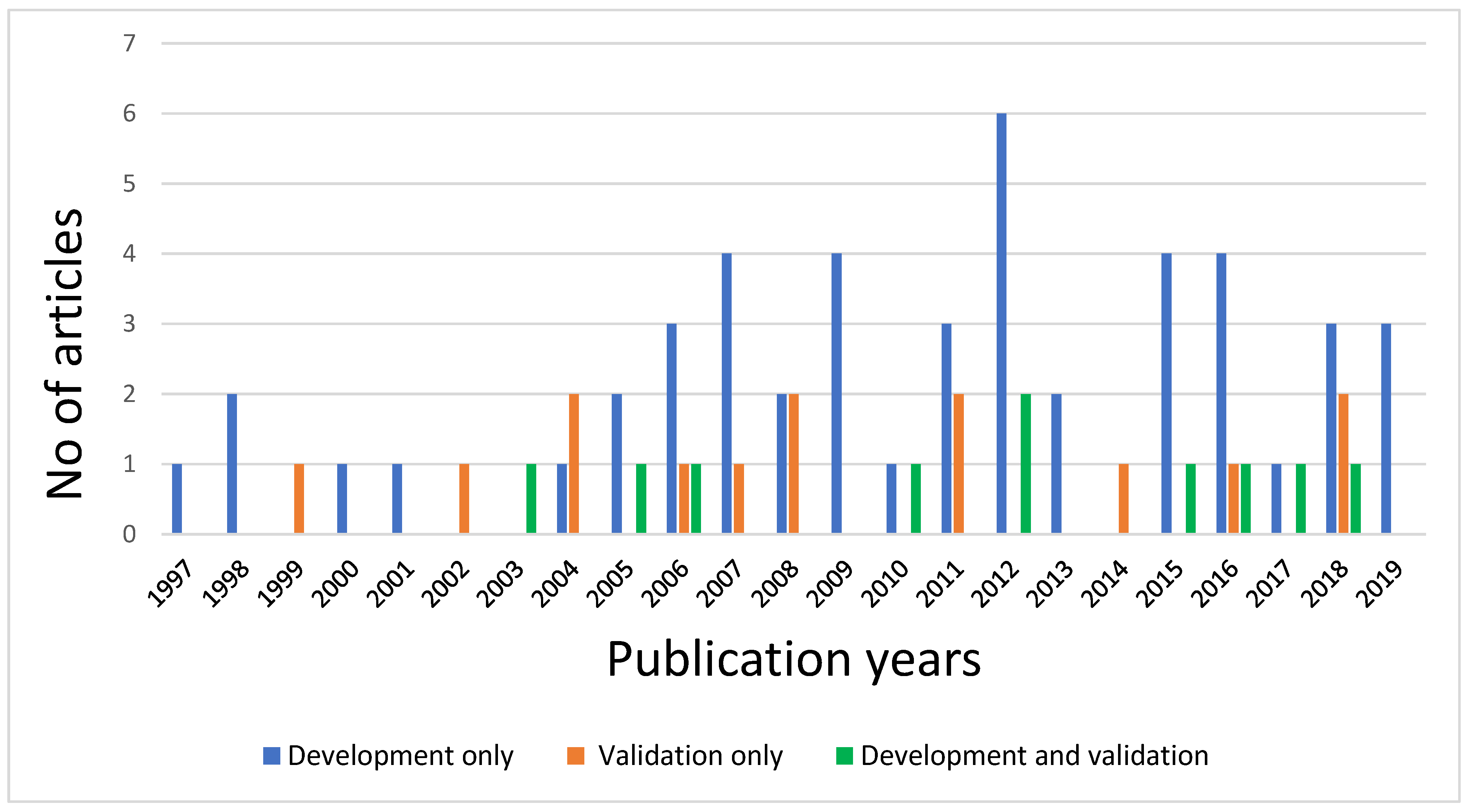
6.1.1. Frequency of Models, Study Designs, and Study Populations
6.1.2. Definition and Method for Measurement of Outcome
6.1.3. Time Span of Prognostic Models
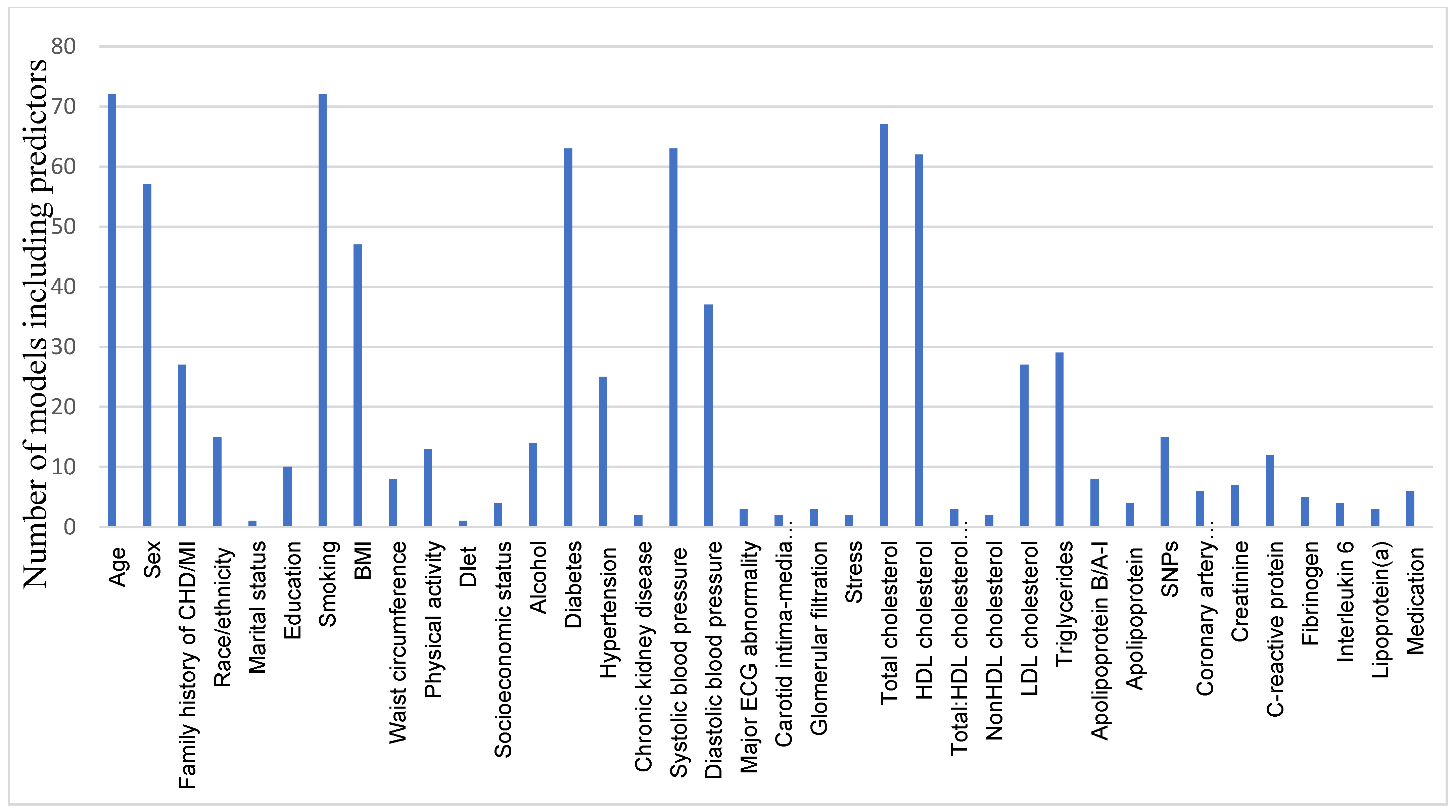
6.1.4. The Candidate Predictors
6.1.5. Sample Size and Number of Outcomes
6.1.6. Missing Data
6.1.7. Modelling Method
6.1.8. Models’ Assumptions and Normality Distribution
6.1.9. Predictive Performance of the Studies
7. Validation Modelling Studies
8. Genetic Risk Prognostic Modelling Studies
9. Discussion
10. Conclusions
11. Strengths and Limitations of This Study
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ATP | Adult Treatment Panel |
| BMI | Body Mass Index |
| WC | Waist Circumference |
| CHD | Coronary Heart Disease |
| CRFs | Conventional Risk Factors |
| CVD | Cardiovascular Diseases |
| DALYs | Disability-Adjusted Life Years |
| DM | Diabetes Mellitus |
| GRS | Genetic Risk Score |
| HDL | High-Density Lipoprotein |
| HTN | Hypertension |
| ICD | International Classification of the Diseases |
| IDI | Integrated Discrimination Improvement |
| LDL | Low-Density Lipoprotein |
| MI | Myocardial Infarction |
| NRI | Net Reclassification Improvement |
| SNPs | Single-Nucleotide Polymorphisms |
| WHO | World Health Organization |
References
- Themistocleous, I.-C.; Stefanakis, M.; Douda, H. Coronary Heart Disease Part I: Pathophysiology and Risk Factors. J. Phys. Act. Nutr. Rehabil. 2017. Available online: https://www.panr.com.cy/?p=1542 (accessed on 30 April 2019).
- Nowbar, A.N.; Gitto, M.; Howard, J.P.; Francis, D.P.; Al-Lamee, R. Mortality from Ischemic Heart Disease. Circ. Cardiovasc. Qual. Outcomes 2019, 12, e005375. [Google Scholar] [CrossRef] [PubMed]
- WHO. Cardiovascular Disease. About Cardiovascular Diseases. Fact Sheet. Available online: https://www.who.int/en/news-room/fact-sheets/detail/cardiovascular-diseases-(cvds) (accessed on 11 June 2021).
- WHF. Secondary Cardiovascular Disease Prevention and Control; A World Heart Federation Report; World Heart Federation: Geneva, Switzerland, 2014. [Google Scholar]
- Sharma, R.; Kumar, P.; Prashanth, S.P.; Belagali, Y. Dual Antiplatelet Therapy in Coronary Artery Disease. Cardiol. Therapy 2020, 9, 349–361. [Google Scholar] [CrossRef] [PubMed]
- Wilson, P.W.F.; D’Agostino, R.B.; Levy, D.; Belanger, A.M.; Silbershatz, H.; Kannel, W.B. Prediction of Coronary Heart Disease Using Risk Factor Categories. Circulation 1998, 97, 1837–1847. [Google Scholar] [CrossRef] [PubMed]
- De Vries, T.I.; Visseren, F.L.J. Cardiovascular risk prediction tools made relevant for GPs and patients. Heart 2020, 107, 332–340. [Google Scholar] [CrossRef]
- Brown, J.C.; Gerhardt, T.E.; Kwon, E. Risk Factors for Coronary Artery Disease. In StatPearls; StatPearls Publishing: Treasure Island, FL, USA, 2020. [Google Scholar]
- Karunathilake, S.P.; Ganegoda, G.U. Secondary Prevention of Cardiovascular Diseases and Application of Technology for Early Diagnosis. BioMed Res. Int. 2018, 2018, 5767864. [Google Scholar] [CrossRef]
- Dent, T.H.S. Predicting the risk of coronary heart disease: I. The use of conventional risk markers. Atherosclerosis 2010, 213, 345–351. [Google Scholar] [CrossRef]
- Hendriksen, J.M.; Geersing, G.J.; Moons, K.G.; de Groot, J.A. Diagnostic and prognostic prediction models. J. Thromb. Haemost. 2013, 11 (Suppl. 1), 129–141. [Google Scholar] [CrossRef]
- Collins, G.S.; de Groot, J.A.; Dutton, S.; Omar, O.; Shanyinde, M.; Tajar, A.; Voysey, M.; Wharton, R.; Yu, L.-M.; Moons, K.G.; et al. External validation of multivariable prediction models: A systematic review of methodological conduct and reporting. BMC Med. Res. Methodol. 2014, 14, 40. [Google Scholar] [CrossRef]
- Moons, K.G.M.; Kengne, A.P.; Grobbee, D.E.; Royston, P.; Vergouwe, Y. Altman, D.G.; Woodward, M. Risk prediction models: II. External validation, model updating, and impact assessment. Heart 2012, 98, 691–698. [Google Scholar] [CrossRef]
- Moons, K.G.M.; Kengne, A.P.; Woodward, M.; Royston, P.; Vergouwe, Y.; Altman, D.G.; Grobbee, D.E. Risk prediction models: I. Development, internal validation, and assessing the incremental value of a new (bio)marker. Heart 2012, 98, 683–690. [Google Scholar] [CrossRef] [Green Version]
- Moons, K.G.; de Groot, J.A.; Bouwmeester, W.; Vergouwe, Y.; Mallett, S.; Altman, D.G.; Reitsma, J.B.; Collins, G.S. Critical appraisal, and data extraction for systematic reviews of prediction modelling studies: The CHARMS checklist. PLoS Med. 2014, 11, e1001744. [Google Scholar] [CrossRef] [PubMed]
- Alba, A.C.; Agoritsas, T.; Walsh, M.; Hanna, S.; Iorio, A.; Devereaux, P.J.; McGinn, T.; Guyatt, G. Discrimination and Calibration of Clinical Prediction Models: Users' Guides to the Medical Literature. JAMA 2017, 318, 1377–1384. [Google Scholar] [CrossRef] [PubMed]
- Steyerberg, E.W.; Moons, K.G.M.; van der Windt, D.A.; Hayden, J.A.; Perel, P.; Schroter, S.; Riley, R.D.; Hemingway, H.; Altman, D.G.; PROGRESS Group. Prognosis Research Strategy (PROGRESS) 3: Prognostic model research. PLoS Med. 2013, 10, e1001381. [Google Scholar]
- Morris, R.W.; A Cooper, J.; Shah, T.; Wong, A.; Drenos, F.; Engmann, J.; McLachlan, S.; Jefferis, B.; Dale, C.; Hardy, R.; et al. Marginal role for 53 common genetic variants in cardiovascular disease prediction. Heart 2016, 102, 1640–1647. [Google Scholar] [CrossRef] [PubMed]
- Dhiman, P.; Kai, J.; Horsfall, L.; Walters, K.; Qureshi, N. Availability and Quality of Coronary Heart Disease Family History in Primary Care Medical Records: Implications for Cardiovascular Risk Assessment. PLoS ONE 2014, 9, e81998. [Google Scholar] [CrossRef]
- Piepoli, M.F.; Hoes, A.W.; Agewall, S.; Albus, C.; Brotons, C.; Catapano, A.L.; Cooney, M.T.; Corrà, U.; Cosyns, B.; Deaton, C.; et al. 2016 European Guidelines on cardiovascular disease prevention in clinical practice: The Sixth Joint Task Force of the European Society of Cardiology and Other Societies on Cardiovascular Disease Prevention in Clinical Practice (constituted by representatives of 10 societies and by invited experts) Developed with the special contribution of the European Association for Cardiovascular Prevention & Rehabilitation (EACPR). Eur. Heart J. 2016, 37, 2315–2381. [Google Scholar]
- Damen, J.A.A.G.; Hooft, L.; Schuit, E.; Debray, T.P.A.; Collins, G.S.; Tzoulaki, I.; Lassale, C.; Siontis, G.C.M.; Chiocchia, V.; Roberts, C.; et al. Prediction models for cardiovascular disease risk in the general population: Systematic review. BMJ 2016, 353, i2416. [Google Scholar] [CrossRef]
- Okwuosa, T.M.; Greenland, P.; Burke, G.L.; Eng, J.; Cushman, M.; Michos, E.D.; Ning, H.; Lloyd-Jones, D.M. Prediction of Coronary Artery Calcium Progression in Individuals With Low Framingham Risk Score: The Multi-Ethnic Study of Atherosclerosis. JACC Cardiovasc. Imaging 2012, 5, 144–153. [Google Scholar] [CrossRef]
- Arima, H.; Kubo, M.; Yonemoto, K.; Doi, Y.; Ninomiya, T.; Tanizaki, Y.; Hata, J.; Matsumura, K.; Iida, M.; Kiyohara, Y. High-sensitivity C-reactive protein and coronary heart disease in a general population of Japanese: The Hisayama study. Arterioscler. Thromb. Vasc. Biol. 2008, 28, 1385–1391. [Google Scholar] [CrossRef]
- Rana, J.S.; Cote, M.; Despres, J.P.; Sandhu, M.S.; Talmud, P.J.; Ninio, E.; Wareham, N.J.; Kastelein, J.J.P.; Zwinderman, A.H.; Khaw, K.-T.; et al. Inflammatory biomarkers and the prediction of coronary events among people at intermediate risk: The EPIC-Norfolk prospective population study. Heart (Br. Card. Soc.) 2009, 95, 1682–1687. [Google Scholar] [CrossRef]
- Auer, R.; Bauer, D.C.; Marques-Vidal, P.; Butler, J.; Min, L.J.; Cornuz, J.; Satterfield, S.; Newman, A.B.; Vittinghoff, E.; Rodondi, N.; et al. Association of major and minor ECG abnormalities with coronary heart disease events. JAMA 2012, 307, 1497–1505. [Google Scholar] [PubMed]
- Cushman, M.; Arnold, A.M.; Psaty, B.M.; Manolio, T.A.; Kuller, L.H.; Burke, G.L.; Polak, J.F.; Tracy, R.P. C-reactive protein and the 10-year incidence of coronary heart disease in older men and women: The cardiovascular health study. Circulation 2005, 112, 25–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nambi, V.; Chambless, L.; Folsom, A.R.; He, M.; Hu, Y.; Mosley, T.; Volcik, K.; Boerwinkle, E.; Ballantyne, C.M. Carotid Intima-Media Thickness and Presence or Absence of Plaque Improves Prediction of Coronary Heart Disease Risk: The ARIC (Atherosclerosis Risk In Communities) Study. J. Am. Coll. Cardiol. 2010, 55, 1600–1607. [Google Scholar] [CrossRef] [PubMed]
- Yeboah, J.; McClelland, R.L.; Polonsky, T.S.; Burke, G.L.; Sibley, C.T.; O'Leary, D.; Carr, J.J.; Goff, D.C.; Greenland, P.; Herrington, D.M. Comparison of novel risk markers for improvement in cardiovascular risk assessment in intermediate-risk individuals. JAMA 2012, 308, 788–795. [Google Scholar] [CrossRef]
- Damen, J.A.; Pajouheshnia, R.; Heus, P.; Moons, K.G.M.; Reitsma, J.B.; Scholten, R.J.P.M.; Hooft, L.; Debray, T.P.A. Performance of the Framingham risk models and pooled cohort equations for predicting 10-year risk of cardiovascular disease: A systematic review and meta-analysis. BMC Med. 2019, 17, 109. [Google Scholar] [CrossRef]
- Singh, M. Framingham equations overestimate risk of coronary heart disease mortality in British males. Evid. -Based Healthc. 2004, 8, 131–132. [Google Scholar]
- Brindle, P.M.; McConnachie, A.; Upton, M.N.; Hart, C.L.; Davey Smith, G.; Watt, G.C. The accuracy of the Framingham risk-score in different socioeconomic groups: A prospective study. Br. J. Gen. Pract. J. R. Coll. Gen. Pract. 2005, 55, 838–845. [Google Scholar]
- Nishimura, K.; Okamura, T.; Watanabe, M.; Nakai, M.; Takegami, M.; Higashiyama, A.; Kokubo, Y.; Okayama, A.; Miyamoto, Y. Correction:Predicting Coronary Heart Disease Using Risk Factor Categories for a Japanese Urban Population, and Comparison with the Framingham Risk Score: The Suita Study. J. Atheroscler. Thromb. 2016, 23, 1138–1139. [Google Scholar] [CrossRef]
- Talmud, P.J. Gene–environment interaction and its impact on coronary heart disease risk. Nutr. Metab. Cardiovasc. Dis. NMCD 2007, 17, 148–1522. [Google Scholar] [CrossRef]
- O'Donnell, C.J.; Nabel, E.G. Genomics of Cardiovascular Disease. N. Engl. J. Med. 2011, 365, 2098–2109. [Google Scholar] [CrossRef]
- Gui, L.; Wu, F.; Han, X.; Dai, X.; Qiu, G.; Li, J.; Wang, J.; Zhang, X.; Wu, T.; He, M. A multilocus genetic risk score predicts coronary heart disease risk in a Chinese Han population. Atherosclerosis 2014, 237, 480–485. [Google Scholar] [CrossRef] [PubMed]
- Sasidhar, M.V.; Reddy, S.; Naik, A.; Naik, S. Genetics of coronary artery disease-a clinician's perspective. Indian Heart J. 2014, 66, 663–671. [Google Scholar] [CrossRef] [PubMed]
- McPherson, R. Genome-Wide Association Studies of Cardiovascular Disease in European and Non-European Populations. Curr. Genet. Med. Rep. 2014, 2, 1–12. [Google Scholar] [CrossRef]
- Zhao, C.; Zhu, P.; Shen, Q.; Jin, L. Prospective association of a genetic risk score with major adverse cardiovascular events in patients with coronary artery disease. Medicine 2017, 96, e9473. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Ding, H.; Zhang, X.; He, M.; Huang, S.; Xu, Y.; Shi, Y.; Cui, G.; Cheng, L.; Wang, Q.K.; et al. Genetic Variants at Newly Identified Lipid Loci Are Associated with Coronary Heart Disease in a Chinese Han Population. PLoS ONE 2011, 6, e27481. [Google Scholar] [CrossRef]
- Tikkanen, E.; Gustafsson, S.; Ingelsson, E. Associations of fitness, physical activity, strength, and genetic risk with cardiovascular disease: Longitudinal analyses in the UK Biobank study. Circulation 2018, 137, 2583–2591. [Google Scholar] [CrossRef]
- Khera, A.V.; Emdin, C.A.; Drake, I. Genetic risk, adherence to a healthy lifestyle, and coronary disease. N. Engl. J. Med. 2016, 375, 2349–2358. [Google Scholar] [CrossRef]
- Robert, R.; Chang, C.; Hadley, T. Genetic Risk Stratification A Paradigm Shift in Prevention of Coronary Artery Disease. JACC Basic Transl. Sci. 2021, 6, 287–304. [Google Scholar] [CrossRef]
- Severino, P.; D'Amato, A.; Netti, L.; Pucci, M.; Mariani, M.V.; Cimino, S.; Birtolo, L.I.; Infusino, F.; De Orchi, P.; Palmirotta, R.; et al. Susceptibility to ischemic heart disease: Focusing on genetic variants for ATP-sensitive potassium channel beyond traditional risk factors. Eur. J. Prev. Cardiol. 2020, 28, 1495–1500. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; PRISMA Group. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef]
- Janssens, A.C.J.; Ioannidis, J.P.; van Duijn, C.M.; Little, J.; Khoury, M.J.; GRIPS Group. Strengthening the reporting of genetic risk prediction studies: The GRIPS statement. Genome Med. 2011, 3, 16. [Google Scholar] [CrossRef] [PubMed]
- Iribarren, C.; Lu, M.; Jorgenson, E.; Martínez, M.; Lluis-Ganella, C.; Subirana, I.; Salas, E.; Elosua, R. Clinical Utility of Multimarker Genetic Risk Scores for Prediction of Incident Coronary Heart Disease: A Cohort Study Among Over 51 000 Individuals of European Ancestry. Circ. Cardiovasc. Genet. 2016, 9, 531–540. [Google Scholar] [CrossRef] [PubMed]
- Hughes, M.F.; Saarela, O.; Stritzke, J.; Kee, F.; Silander, K.; Klopp, N.; Kontto, J.; Karvanen, J.; Willenborg, C.; Salomaa, V.; et al. Genetic markers enhance coronary risk prediction in men: The MORGAM prospective cohorts. PLoS ONE. 2012, 7, e40922. [Google Scholar] [CrossRef] [PubMed]
- Talmud, P.J.; Cooper, J.A.; Palmen, J.; Lovering, R.; Drenos, F.; Hingorani, A.D.; Humphries, S.E. Chromosome 9p21.3 Coronary Heart Disease Locus Genotype and Prospective Risk of CHD in Healthy Middle-Aged Men. Clin. Chem. 2008, 54, 467–474. [Google Scholar] [CrossRef] [Green Version]
- Humphries, S.E.; Cooper, J.A.; Talmud, P.J.; Miller, G.J. Candidate Gene Genotypes, Along with Conventional Risk Factor Assessment, Improve Estimation of Coronary Heart Disease Risk in Healthy UK Men. Clin. Chem. 2007, 53, 8–16. [Google Scholar] [CrossRef]
- Beaney, K.E.; Cooper, J.A.; Drenos, F.; Humphries, S.E. Assessment of the clinical utility of adding common single nucleotide polymorphism genetic scores to classical risk factor algorithms in coronary heart disease risk prediction in UK men. Clin. Chem. Lab. Med. 2017, 55, 1605–1613. [Google Scholar] [CrossRef]
- Antiochos, P.; Marques-Vidal, P.; McDaid, A.; Waeber, G.; Vollenweider, P. Association between parental history and genetic risk scores for coronary heart disease prediction: The population-based CoLaus study. Atherosclerosis 2016, 244, 59–65. [Google Scholar] [CrossRef]
- Brautbar, A.; Pompeii, L.A.; Dehghan, A.; Ngwa, J.S.; Nambi, V.; Virani, S.S.; Rivadeneira, F.; Uitterlinden, A.G.; Hofman, A.; Witteman, J.C.M.; et al. A genetic risk score based on direct associations with coronary heart disease improves coronary heart disease risk prediction in the Atherosclerosis Risk in Communities (ARIC), but not in the Rotterdam and Framingham Offspring, Studies. Atherosclerosis 2012, 223, 421–426. [Google Scholar] [CrossRef]
- Chien, K.L.; Hsu, H.C.; Su, T.C.; Chen, M.F.; Lee, Y.T.; Hu, F.B. Apolipoprotein B and non-high density lipoprotein cholesterol and the risk of coronary heart disease in Chinese. J. Lipid Res. 2007, 48, 2499–2505. [Google Scholar] [CrossRef] [PubMed]
- Simmons, R.K.; Sharp, S.; Boekholdt, S.M.; Sargeant, L.A.; Khaw, K.T.; Wareham, N.J.; Griffin, S.J. Evaluation of the Framingham risk score in the European Prospective Investigation of Cancer-Norfolk cohort: Does adding glycated hemoglobin improve the prediction of coronary heart disease events? Arch. Int. Med. 2008, 168, 1209–1216. [Google Scholar] [CrossRef] [PubMed]
- Macleod, J.; Metcalfe, C.; Smith, G.D.; Hart, C. Does consideration of either psychological or material disadvantage improve coronary risk prediction? Prospective observational study of Scottish men. J. Epidemiol. Community Health 2007, 61, 833–837. [Google Scholar] [CrossRef] [PubMed]
- Ingelsson, E.; Schaefer, E.J.; Contois, J.H.; McNamara, J.R.; Sullivan, L.; Keyes, M.J.; Pencina, M.J.; Schoonmaker, C.; Wilson, P.W.F.; D'Agostino, R.B.; et al. Clinical Utility of Different Lipid Measures for Prediction of Coronary Heart Disease in Men and Women. JAMA 2007, 298, 776–785. [Google Scholar] [CrossRef]
- Cao, J.; Steffen, B.T.; Guan, W.; Remaley, A.T.; McConnell, J.P.; Palamalai, V.; Tsai, M.Y. A comparison of three apolipoprotein B methods and their associations with incident coronary heart disease risk over a 12-year follow-up period: The Multi-Ethnic Study of Atherosclerosis. J. Clin. Lipidol. 2018, 12, 300–304. [Google Scholar] [CrossRef] [PubMed]
- Cooper, J.A.; Miller, G.J.; Humphries, S.E. A comparison of the PROCAM and Framingham point-scoring systems for estimation of individual risk of coronary heart disease in the Second Northwick Park Heart Study. Atherosclerosis 2005, 181, 93–100. [Google Scholar] [CrossRef] [PubMed]
- Orford, J.L.; Sesso, H.D.; Stedman, M.; Gagnon, D.; Vokonas, P.; Gaziano, J.M. A comparison of the Framingham and European society of cardiology coronary heart disease risk prediction models in the normative aging study. Am. Heart J. 2002, 144, 95–100. [Google Scholar] [CrossRef] [PubMed]
- Jee, S.H.; Jang, Y.; Oh, D.J.; Oh, B.-H.; Lee, S.H.; Park, S.-W.; Seung, K.-B.; Mok, Y.; Jung, K.J.; Kimm, H.; et al. A coronary heart disease prediction model: The Korean Heart Study. BMJ Open 2014, 4, e005025. [Google Scholar] [CrossRef]
- Merry, A.H.; Boer, J.M.; Schouten, L.J.; Ambergen, T.; Steyerberg, E.W.; Feskens, E.J.; Verschuren, W.M.M.; Gorgels, A.P.M.; van den Brandt, P.A. Risk prediction of incident coronary heart disease in The Netherlands: Re-estimation and improvement of the SCORE risk function. Eur. J. Prev. Cardiol. 2012, 19, 840–848. [Google Scholar] [CrossRef]
- Khalili, D.; Hadaegh, F.; Fahimfar, N.; Shafiee, G.; Sheikholeslami, F.; Ghanbarian, A.; Azizi, F. Does an electrocardiogram add predictive value to the rose angina questionnaire for future coronary heart disease? 10-year follow-up in a Middle East population. J. Epidemiol. Community Health 2012, 66, 1104–1109. [Google Scholar] [CrossRef]
- Taylor, A.J.; Feuerstein, I.; Wong, H.; Barko, W.; Brazaitis, M.; O'Malley, P.G. Do conventional risk factors predict subclinical coronary artery disease? Results from the Prospective Army Coronary Calcium Project. Am. Heart J. 2001, 141, 463–468. [Google Scholar] [CrossRef]
- Parikh, N.I.; Jeppson, R.P.; Berger, J.S.; Eaton, C.B.; Kroenke, C.H.; LeBlanc, E.S.; Lewis, C.E.; Loucks, E.B.; Parker, D.R.; Rillamas-Sun, E.; et al. Reproductive Risk Factors and Coronary Heart Disease in the Women’s Health Initiative Observational Study. Circulation 2016, 133, 2149–2158. [Google Scholar] [CrossRef]
- De Vries, P.S.; Kavousi, M.; Ligthart, S.; Uitterlinden, A.G.; Hofman, A.; Franco, O.H.; Dehghan, A. Incremental predictive value of 152 single nucleotide polymorphisms in the 10-year risk prediction of incident coronary heart disease: The Rotterdam Study. Int. J. Epidemiol. 2015, 44, 682–688. [Google Scholar] [CrossRef]
- Paynter, N.P.; Crainiceanu, C.M.; Sharrett, A.R.; Chambless, L.E.; Coresh, J. Effect of correcting for long-term variation in major coronary heart disease risk factors: Relative hazard estimation and risk prediction in the Atherosclerosis Risk in Communities Study. Ann. Epidemiol. 2012, 22, 191–197. [Google Scholar] [CrossRef] [PubMed]
- Morrison, A.C.; Bare, L.A.; Chambless, L.E.; Ellis, S.G.; Malloy, M.; Kane, J.P.; Pankow, J.S.; Devlin, J.J.; Willerson, J.T.; Boerwinkle, E.; et al. Prediction of Coronary Heart Disease Risk using a Genetic Risk Score: The Atherosclerosis Risk in Communities Study. Am. J. Epidemiol. 2007, 166, 28–35. [Google Scholar] [CrossRef] [PubMed]
- Folsom, A.R.; Chambless, L.E.; Ballantyne, C.M.; Coresh, J.; Heiss, G.; Wu, K.K.; Wu, K.K.; Boerwinkle, E.; Mosley, T.H., Jr.; Sorlie, P. An assessment of incremental coronary risk prediction using C-reactive protein and other novel risk markers: The atherosclerosis risk in communities study. Arch. Intern. Med. 2006, 166, 1368–1373. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Detrano, R.C.; Wong, N.D.; Doherty, T.M.; Shavelle, R.M.; Tang, W.; Ginzton, L.E.; Budoff, M.J.; Narahara, K.A. Coronary calcium does not accurately predict near-term future coronary events in high-risk adults. Circulation 1999, 99, 2633–2638. [Google Scholar] [CrossRef]
- Tada, H.; Melander, O.; Louie, J.Z.; Catanese, J.J.; Rowland, C.M.; Devlin, J.J.; Kathiresan, S.; Shiffman, D. Risk prediction by genetic risk scores for coronary heart disease is independent of self-reported family history. Eur. Heart J. 2015, 37, 561–567. [Google Scholar] [CrossRef]
- Aekplakorn, W.; Pakpeankitwatana, V.; Lee, C.M.Y.; Woodward, M.; Barzi, F.; Yamwong, S.; Unkurapinun, N.; Sritara, P. Abdominal Obesity and Coronary Heart Disease in Thai Men. Obesity. 2007, 15, 1036–1042. [Google Scholar] [CrossRef]
- Bolton, J.L.; Stewart, M.C.W.; Wilson, J.F.; Anderson, N.; Price, J.F. Improvement in prediction of coronary heart disease risk over conventional risk factors using SNPs identified in genome-wide association studies. PLoS ONE 2013, 8, e57310. [Google Scholar] [CrossRef]
- Lloyd-Jones, D.M.; Wilson, P.W.; Larson, M.G.; Beiser, A.; Leip, E.P.; D'Agostino, R.B.; Levy, D. Framingham risk score and prediction of lifetime risk for coronary heart disease. Am. J. Cardiol. 2004, 94, 20–24. [Google Scholar] [CrossRef]
- Empana, J.P.; Ducimetière, P.; Arveiler, D.; Ferrières, J.; Evans, A.; Ruidavets, J.B.; Haas, B.; Yarnell, J.; Bingham, A.; Amouyel, P.; et al. Are the Framingham and PROCAM coronary heart disease risk functions applicable to different European populations?: The PRIME Study. Eur. Heart J. 2003, 24, 1903–1911. [Google Scholar] [CrossRef]
- Rodondi, N.; Locatelli, I.; Aujesky, D.; Butler, J.; Vittinghoff, E.; Simonsick, E.; Satterfield, S.; Newman, A.B.; Wilson, P.W.F.; Pletcher, M.J.; et al. Framingham Risk Score and Alternatives for Prediction of Coronary Heart Disease in Older Adults. PLoS ONE 2012, 7, e34287. [Google Scholar] [CrossRef] [PubMed]
- McGeechan, K.; Liew, G.; Macaskill, P.; Irwig, L.; Klein, R.; Sharrett, A.R.; Klein, B.E.K.; Wang, J.J.; Chambless, L.E.; Wong, T.Y. Risk Prediction of Coronary Heart Disease Based on Retinal Vascular Caliber (from the Atherosclerosis Risk In Communities [ARIC] Study). Am. J. Cardiol. 2008, 102, 58–63. [Google Scholar] [CrossRef] [PubMed]
- Onat, A.; Dursunoǧlu, D.; Sansoy, V. Relatively high coronary death and event rates in Turkish women: Relation to three major risk factors in five-year follow-up of cohort. Int. J. Cardiol. 1997, 61, 69–77. [Google Scholar] [CrossRef]
- Mainous, A.G.; 3rd Everett, C.J.; Player, M.S.; King, D.E.; Diaz, V.A. Importance of a patient's personal health history on assessments of future risk of coronary heart disease. J. Am. Board Fam. Med. 2008, 21, 408–413. [Google Scholar] [CrossRef]
- Pyörälä, M.; Miettinen, H.; Laakso, M.; Pyörälä, K. Hyperinsulinemia Predicts Coronary Heart Disease Risk in Healthy Middle-aged Men. Circulation 1998, 98, 398–404. [Google Scholar] [CrossRef]
- Thomsen, T.F.; McGee, D.; Davidsen, M.; Jørgensen, T. A cross-validation of risk-scores for coronary heart disease mortality based on data from the Glostrup Population Studies and Framingham Heart Study. Int. J. Epidemiol. 2002, 31, 817–822. [Google Scholar] [CrossRef]
- Bye, A.; Røsjø, H.; Nauman, J.; Silva, G.J.J.; Follestad, T.; Omland, T.; Wisløff, U. Circulating microRNAs predict future fatal myocardial infarction in healthy individuals – The HUNT study. J. Mol. Cell. Cardiol. 2016, 97, 162–168. [Google Scholar] [CrossRef]
- Kavousi, M.; Elias-Smale, S.; Rutten, J.H.W.; Leening, M.J.G.; Vliegenthart, R.; Verwoert, G.C.; Krestin, G.P.; Oudkerk, M.; de Maat, M.P.M.; Leebeek, F.W.G.; et al. Evaluation of newer risk markers for coronary heart disease risk classification: A cohort study. Ann. Intern. Med. 2012, 156, 438–444. [Google Scholar] [CrossRef]
- Ganna, A.; Magnusson, P.K.; Pedersen, N.L.; de Faire, U.; Reilly, M.; Arnlöv, J.; Sundström, J.; Hamsten, A.; Ingelsson, E. Multilocus genetic risk scores for coronary heart disease prediction. Arterioscler. Thromb. Vasc. Biol. 2013, 33, 2267–2272. [Google Scholar] [CrossRef]
- Cooper, J.A.; Miller, G.J.; Bauer, K.A.; Morrissey, J.H.; Meade, T.W.; Howarth, D.J. Comparison of Novel Hemostatic Factors and Conventional Risk Factors for Prediction of Coronary Heart Disease. Circulation 2000, 102, 2816–2822. [Google Scholar] [CrossRef]
- Brautbar, A.; Ballantyne, C.M.; Lawson, K.; Nambi, V.; Chambless, L.; Folsom, A.R.; Willerson, J.T.; Boerwinkle, E. Impact of Adding a Single Allele in the 9p21 Locus to Traditional Risk Factors on Reclassification of Coronary Heart Disease Risk and Implications for Lipid-Modifying Therapy in the Atherosclerosis Risk in Communities Study. Circ. Cardiovasc. Genet. 2009, 2, 279–285. [Google Scholar] [CrossRef] [PubMed]
- St-Pierre, A.C.; Cantin, B.; Dagenais, G.R.; Després, J.-P.; Lamarche, B. Apolipoprotein-B, Low-Density Lipoprotein Cholesterol, and the Long-Term Risk of Coronary Heart Disease in Men. J. Am. Coll. Cardiol. 2006, 97, 997–1001. [Google Scholar] [CrossRef] [PubMed]
- Ryoo, J.-H.; Park, S.K.; Hong, H.P.; Kim, M.-G.; Ha, C.S. Clinical significance of serum apolipoproteins as a predictor of coronary heart disease risk in Korean men. Clin.l Endocrinol. 2016, 84, 63–71. [Google Scholar] [CrossRef] [PubMed]
- Yarnell, J.W.G.; Patterson, C.C.; Sweetnam, P.M.; Lowe, G.D.O. Haemostatic/inflammatory markers predict 10-year risk of IHD at least as well as lipids: The Caerphilly collaborative studies. Eur. Heart J. 2004, 25, 1049–1056. [Google Scholar] [CrossRef] [Green Version]
- Everage, N.J.; Gjelsvik, A.; McGarvey, S.T.; Linkletter, C.D.; Loucks, E.B. Inverse Associations Between Perceived Racism and Coronary Artery Calcification. Ann. Epidemiol. 2012, 22, 183–190. [Google Scholar] [CrossRef]
- Iribarren, C.; Chandra, M.; Rana, J.S.; Hlatky, M.A.; Fortmann, S.P.; Quertermous, T.; Go, A.S. High-sensitivity cardiac troponin I and incident coronary heart disease among asymptomatic older adults. Heart 2016, 102, 1177–1182. [Google Scholar] [CrossRef]
- McClelland, R.L.; Jorgensen, N.W.; Budoff, M.; Blaha, M.J.; Post, W.S.; Kronmal, R.A.; Bild, D.E.; Shea, S.; Liu, K.; Watson, K.E.; et al. 10-Year Coronary Heart Disease Risk Prediction Using Coronary Artery Calcium and Traditional Risk Factors: Derivation in the MESA (Multi-Ethnic Study of Atherosclerosis) With Validation in the HNR (Heinz Nixdorf Recall) Study and the DHS (Dallas Heart Study). J. Am. Coll. Cardiol. 2015, 66, 1643–1653. [Google Scholar]
- Liu, J.; Hong, Y.; D'Agostino, S.; Ralph, B.; Wu, Z.; Wang, W.; Sun, J.; Wilson, P.W.F.; Kannel, W.B.; Zhao, D. Predictive Value for the Chinese Population of the Framingham CHD Risk Assessment Tool Compared with the Chinese Multi-provincial Cohort Study. JAMA 2004, 291, 2591–2599. [Google Scholar] [CrossRef]
- Brant, L.J.; Ferrucci, L.; Sheng, S.L.; Concin, H.; Zonderman, A.B.; Kelleher, C.C.; Longo, D.L.; Ulmer, H.; Strasak, A.M. Gender differences in the accuracy of time-dependent blood pressure indices for predicting coronary heart disease: A random-effects modeling approach. Gend. Med. 2010, 7, 616–627. [Google Scholar] [CrossRef]
- Onat, A.; Can, G.; Hergenç, G.; Uğur, M.; Yüksel, H. Coronary disease risk prediction algorithm warranting incorporation of C-reactive protein in Turkish adults, manifesting sex difference. Nutr. Metab. Cardiovas. 2012, 22, 643–650. [Google Scholar] [CrossRef]
- Cross, D.S.; McCarty, C.A.; Hytopoulos, E.; Beggs, M.; Nolan, N.; Harrington, D.S.; Hastie, T.; Tibshirani, R.; Tracy, R.P.; Psaty, B.M.; et al. Coronary risk assessment among intermediate risk patients using a clinical and biomarker-based algorithm developed and validated in two population cohorts. Curr. Med. Res. Opin. 2012, 28, 1819–1830. [Google Scholar] [CrossRef] [PubMed]
- Hadaegh, F.; Mohebi, R.; Bozorgmanesh, M.; Saadat, N.; Sheikholeslami, F.; Azizi, F. Electrocardiographic abnormalities improve classification of coronary heart disease risk in women: Tehran Lipid and Glucose Study. Atherosclerosis 2012, 222, 110–115. [Google Scholar] [CrossRef] [PubMed]
- Kang, H.M.; Kim, D.-J. Metabolic Syndrome versus Framingham Risk Score for Association of Self-Reported Coronary Heart Disease: The 2005 Korean Health and Nutrition Examination Survey. Diabetes Metab. J. 2012, 36, 237–244. [Google Scholar] [CrossRef] [PubMed]
- Kivimäki, M.; Nyberg, S.T.; Batty, G.D.; Shipley, M.J.; Ferrie, J.E.; Virtanen, M.; Marmot, M.G.; Vahtera, J.; Singh-Manoux, A.; Hamer, M. Does adding information on job strain improve risk prediction for coronary heart disease beyond the standard Framingham risk score? The Whitehall II study. Int. J. Epidemiol. 2011, 40, 1577–1584. [Google Scholar] [CrossRef] [PubMed]
- Gander, J.C.; Sui, X.; Hébert, J.R.; Hazlett, L.J.; Cai, B.; Lavie, C.J.; Blair, S.N. Association of Cardiorespiratory Fitness With Coronary Heart Disease in Asymptomatic Men. Mayo Clin. Proc. 2015, 90, 1372–1379. [Google Scholar] [CrossRef] [Green Version]
- Arad, Y.; Goodman, K.J.; Roth, M.; Newstein, D.; Guerci, A.D. Coronary Calcification, Coronary Disease Risk Factors, C-Reactive Protein, and Atherosclerotic Cardiovascular Disease Events: The St. Francis Heart Study. J. Am. Coll. Cardiol. 2005, 46, 158–165. [Google Scholar] [CrossRef]
- Pischon, T.; Girman, C.J.; Sacks, F.M.; Rifai, N.; Stampfer, M.J.; Rimm, E.B. Non-high-density lipoprotein cholesterol and apolipoprotein B in the prediction of coronary heart disease in men. Circulation 2005, 112, 3375–3383. [Google Scholar] [CrossRef]
- Polak, J.F.; Szklo, M.; O’Leary, D.H. Associations of Coronary Heart Disease with Common Carotid Artery Near and Far Wall Intima-Media Thickness: The Multi-Ethnic Study of Atherosclerosis. J. Am. Soc. Echocardiogr. 2015, 28, 1114–1121. [Google Scholar] [CrossRef]
- Cavus, E.; Karakas, M.; Ojeda, F.M.; Kontto, J.; Veronesi, G.; Ferrario, M.M.; Linneberg, A.; Jørgensen, T.; Meisinger, C.; Thorand, B.; et al. Association of Circulating Metabolites with Risk of Coronary Heart Disease in a European Population: Results From the Biomarkers for Cardiovascular Risk Assessment in Europe (BiomarCaRE) Consortium. JAMA Cardiol. 2019, 4, 1270–1279. [Google Scholar] [CrossRef]
- Subirana, I.; Fitó, M.; Diaz, O.; Vila, J.; Francés, A.; Delpon, E.; Sanchis, J.; Elosua, R.; Muñoz-Aguayo, D.; Dégano, I.R.; et al. Prediction of coronary disease incidence by biomarkers of inflammation, oxidation, and metabolism. Sci. Rep. 2018, 8, 3191. [Google Scholar] [CrossRef]
- Hindy, G.; Wiberg, F.; Almgren, P.; Melander, O.; Orho-Melander, M. Polygenic Risk Score for Coronary Heart Disease Modifies the Elevated Risk by Cigarette Smoking for Disease Incidence. Circ.-Genom. Precis. Me. 2018, 11, e001856. [Google Scholar] [CrossRef] [PubMed]
- Chien, K.L.; Lin, H.J.; Su, T.C.; Chen, Y.Y.; Chen, P.C. Comparing the Consistency and Performance of Various Coronary Heart Disease Prediction Models for Primary Prevention Using a National Representative Cohort in Taiwan. Circ. J. 2018, 82, 1805–1812. [Google Scholar] [CrossRef] [PubMed]
- Iribarren, C.; Lu, M.; Jorgenson, E.; Martínez, M.; Lluis-Ganella, C.; Subirana, I.; Salas, E.; Elosua, R. Weighted Multi-marker Genetic Risk Scores for Incident Coronary Heart Disease among Individuals of African, Latino and East-Asian Ancestry. Sci. Rep. 2018, 8, 6853. [Google Scholar] [CrossRef] [PubMed]
- Can, G.; Onat, A.; Sayılı, U.; Hayıroğlu, M.; Ademoglu, E.; Yurtseven, E. Optimal anthropometric measures to predict incidence of coronary heart disease in adults in Turkey. Natl. Med. J. India 2019, 32, 334–341. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Zhu, C.; Nambi, V.; Morrison, A.C.; Folsom, A.R.; Ballantyne, C.M.; Boerwinkle, E.; Yu, B. Metabolomic Pattern Predicts Incident Coronary Heart Disease. Arterioscler. Thromb. Vasc. Biol. 2019, 39, 1475–1482. [Google Scholar] [CrossRef]
- Fiatal, S.; Ádány, R. Application of Single-Nucleotide Polymorphism-Related Risk Estimates in Identification of Increased Genetic Susceptibility to Cardiovascular Diseases: A Literature Review. Front. Public Health 2017, 5, 358. [Google Scholar] [CrossRef]
- Kaptoge, S.; Pennells, L.; De Bacquer, D.; Cooney, M.T.; Kavousi, M.; Stevens, G.; Riley, L.M.; Savin, S.; Khan, T.; Altay, S.; et al. World Health Organization cardiovascular disease risk charts: Revised models to estimate risk in 21 global regions. Lancet Glob. Health 2019, 7, e1332–e1345. [Google Scholar] [CrossRef]
- Beyene, J.; Atenafu, E.G.; Hamid, J.S.; To, T.; Sung, L. Determining relative importance of variables in developing and validating predictive models. BMC Med. Res. Methodol. 2009, 9, 64. [Google Scholar] [CrossRef]
- Vogenberg, F.R. Predictive and prognostic models: Implications for healthcare decision-making in a modern recession. Am. Health Drug Benefits 2009, 2, 218–222. [Google Scholar]
- Shipe, M.E.; Deppen, S.A.; Farjah, F.; Grogan, E.L. Developing prediction models for clinical use using logistic regression: An overview. J. Thorac. Dis. 2019, 11, S574–S584. [Google Scholar] [CrossRef]
- Walsh, C.G.; Sharman, K.; Hripcsak, G. Beyond discrimination: A comparison of calibration methods and clinical usefulness of predictive models of readmission risk. J. Biomed. Inform. 2017, 76, 9–18. [Google Scholar] [CrossRef] [PubMed]
- Jousilahti, P.; Vartiainen, E.; Tuomilehto, J.; Puska, P. Sex, Age, Cardiovascular Risk Factors, and Coronary Heart Disease. Circulation 1999, 99, 1165–1172. [Google Scholar] [CrossRef] [PubMed]
- Mpye, K.; Matimba, A.; Dzobo, K.; Chirikure, S.; Wonkam, A.; Dandara, C. Disease burden and the role of pharmacogenomics in African populations. J. Health Epidemiol. Genom. 2017, 2, e1. [Google Scholar] [CrossRef] [PubMed]
- Altman, D.G.; Royston, P. What do we mean by validating a prognostic model? Stat. Med. 2000, 19, 453–473. [Google Scholar] [CrossRef]
- Dai, X.; Wiernek, S.; Evans, J.P.; Runge, M.S. Genetics of coronary artery disease and myocardial infarction. World J. of Cardiol. 2016, 8, 1–23. [Google Scholar] [CrossRef] [PubMed]
- Cook, N.R.; Paynter, N.P. Comments on1 ‘Extensions of net reclassification improvement calculations to measure usefulness of new biomarkers’ by M. J. Pencina, R.B.; D'Agostino, Sr. and E. W. Steyerberg. Stat. Med. 2012, 31, 93–95. [Google Scholar] [CrossRef]
- Pavlou, M.; Ambler, G.; Seaman, S.R.; Guttmann, O.; Elliott, P.; King, M.; Omar, R.Z. How to develop a more accurate risk prediction model when there are few events. BMJ-Brit. Med. J. 2015, 351, h3868. [Google Scholar] [CrossRef] [PubMed]
- Virani, S.S.; Alonso, A.; Benjamin, E.J.; Bittencourt, M.S.; Callaway, C.W.; Carson, A.P.; Chamberlain, A.M.; Chang, A.R.; Cheng, S.; Delling, F.N.; et al. Heart Disease and Stroke Statistics—2020 Update: A Report From the American Heart Association. Circulation 2020, 141, e139–e596. [Google Scholar] [CrossRef]
- Van Calster, B.; Nieboer, D.; Vergouwe, Y.; De Cock, B.; Pencina, M.J.; Steyerberg, E.W. A calibration hierarchy for risk models was defined: From utopia to empirical data. J. Clin. Epidemiol. 2016, 74, 167–176. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| No | Name of the Models | Frequency of the Models | ||
|---|---|---|---|---|
| Developmental | Validation | Total | ||
| 1 | Framingham–Wilson–D’Agostino, 1998 | 11 | 9 | 20 |
| 2 | SCORE 2003 | 5 | 2 | 7 |
| 3 | Framingham–ATP III, 2002 | 6 | 0 | 6 |
| 4 | Framingham–Anderson, 1991 | 2 | 3 | 5 |
| 5 | Framingham–Kannel, 1979 | 2 | 3 | 5 |
| 6 | Framingham–Wilson, 1998 | 4 | 1 | 5 |
| 7 | Framingham–ATP III, 2001 | 1 | 2 | 3 |
| 8 | PROCAM–Assmann, 2002 | 3 | 1 | 4 |
| 9 | Framingham–D’Agostino, 2008 | 3 | 0 | 3 |
| 10 | QRISK2–Hippisley-Cox, 2008 | 0 | 2 | 2 |
| 11 | PROCAM–Assmann, 2007 | 0 | 1 | 1 |
| 12 | Framingham–Splansky, 2007 | 0 | 1 | 1 |
| 13 | Framingham–Kannel, 1959 | 0 | 1 | 1 |
| 14 | Framingham–Kannel, 1986 | 1 | 0 | 1 |
| 15 | Framingham–Polak, 2011 | 1 | 0 | 1 |
| 16 | Framingham–Wilson, 1991 | 1 | 0 | 1 |
| 17 | Framingham–Wang, 2006 | 1 | 0 | 1 |
| 18 | Framingham–Wilson, 2005 | 0 | 1 | 1 |
| 19 | Framingham–Ridker, 2002 | 1 | 0 | 1 |
| 20 | Framingham–Franklin | 1 | 1 | 2 |
| 21 | Framingham–ARIC, 2003 | 1 | 0 | 1 |
| 22 | Framingham–Rotterdam | 2 | 0 | 2 |
| 23 | Framingham–MESA, 2002 | 1 | 1 | 2 |
| 24 | Framingham–Lee, 2016 | 1 | 0 | 1 |
| Framingham (not specified) | 19 | 4 | 23 | |
| Total | 67 | 33 | 100 | |
| No | Discrimination Measures | Developmental | Validation | Total |
|---|---|---|---|---|
| 1 | C statistic/AUC | 54 | 9 | 63 |
| 2 | D statistic | 2 | 1 | 3 |
| 3 | Log rank | 0 | 1 | 1 |
| 4 | Lifetime risks for CHD | 3 | 2 | 5 |
| Calibration measures: | ||||
| 5 | Calibration slope and intercept | 0 | 3 | 3 |
| 6 | Calibration plot | 0 | 2 | 2 |
| 7 | Hosmer–Lemeshow test | 11 | 9 | 20 |
| 8 | Grønnesby–Borgan χ2 test | 4 | 1 | 5 |
| Classification measures: | ||||
| 9 | Sensitivity, specificity | 14 | 10 | 24 |
| Predictive value | 5 | 2 | 7 | |
| 10 | Net reclassification improvement (NRI) | 19 | 9 | 28 |
| 11 | Integrated discrimination improvement (IDI) | 10 | 6 | 16 |
| 12 | Clinical NRI | 0 | 3 | 3 |
| Others: | ||||
| 13 | R2 | 2 | 0 | 2 |
| 14 | Kaplan–Meier estimates | 11 | 5 | 16 |
| 15 | Bootstrap resampling | 16 | 5 | 21 |
| 16 | Cross-validation | 2 | 2 | 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nasr, N.; Soltész, B.; Sándor, J.; Adány, R.; Fiatal, S. Prognostic Modelling Studies of Coronary Heart Disease—A Systematic Review of Conventional and Genetic Risk Factor Studies. J. Cardiovasc. Dev. Dis. 2022, 9, 295. https://doi.org/10.3390/jcdd9090295
Nasr N, Soltész B, Sándor J, Adány R, Fiatal S. Prognostic Modelling Studies of Coronary Heart Disease—A Systematic Review of Conventional and Genetic Risk Factor Studies. Journal of Cardiovascular Development and Disease. 2022; 9(9):295. https://doi.org/10.3390/jcdd9090295
Chicago/Turabian StyleNasr, Nayla, Beáta Soltész, János Sándor, Róza Adány, and Szilvia Fiatal. 2022. "Prognostic Modelling Studies of Coronary Heart Disease—A Systematic Review of Conventional and Genetic Risk Factor Studies" Journal of Cardiovascular Development and Disease 9, no. 9: 295. https://doi.org/10.3390/jcdd9090295