
Determining the Proportionality of Ischemic Stroke Risk Factors to Age

Abstract
:1. Introduction
2. Materials and Methods
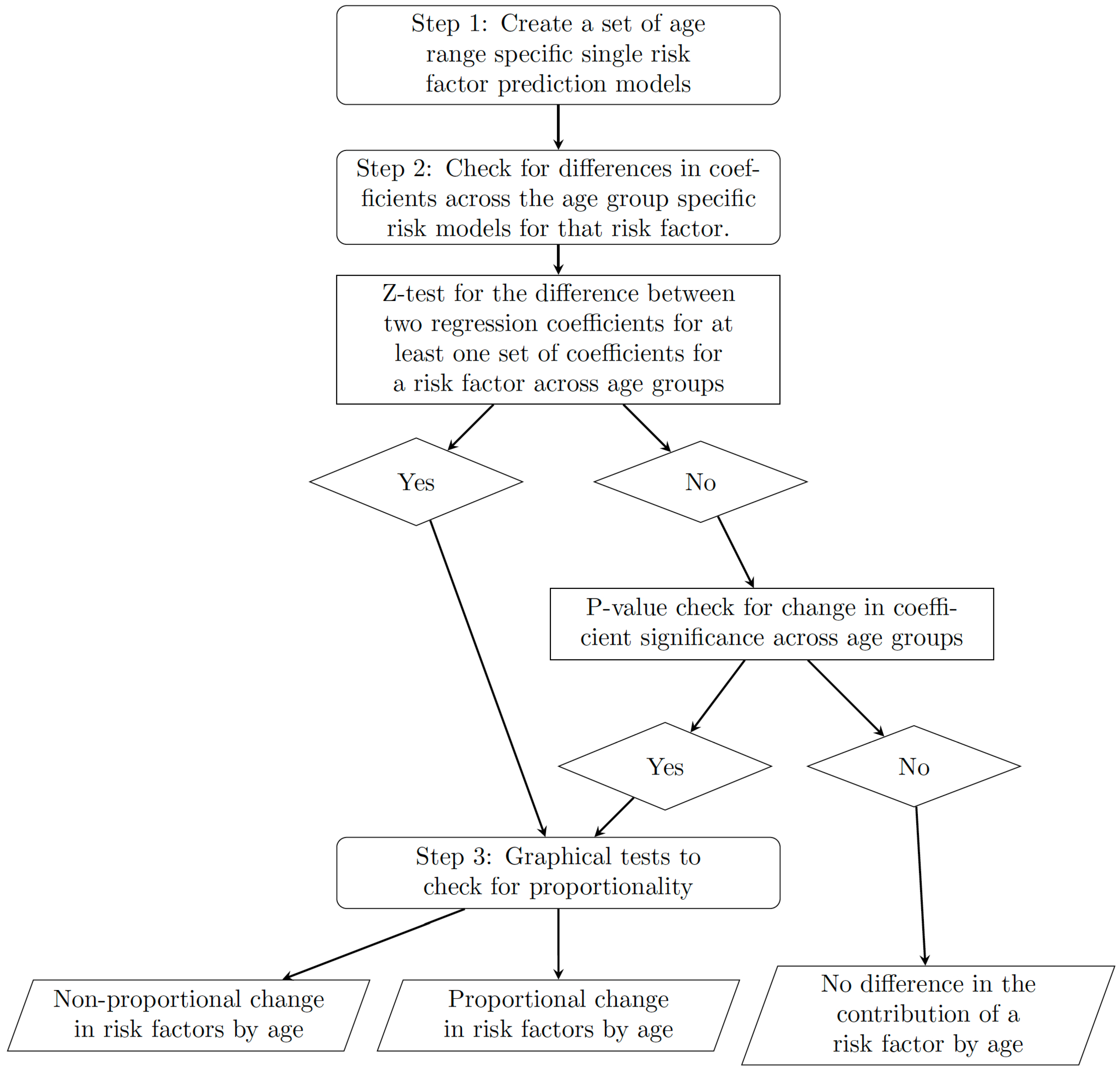
2.1. Framework
- 1.
- Separate the data into a number of different age groups and create separate risk prediction models for each age group for each potential risk factor.
- 2.
- For each risk factor, check for differences in coefficients across the age-group-specific risk models for that risk factor.
- 3.
- If we see differences in coefficients, check for proportionality.
2.1.1. Step 1: Separate Risk Prediction Models by Age Group
2.1.2. Step 2: Difference in Coefficients
2.1.3. Step 3: Proportionality by Age
2.2. Case Study
2.3. Data
3. Results
3.1. Model Results
3.2. Coefficient Magnitude and Significance
3.3. Proportionality
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Owolabi, M.O.; Thrift, A.G.; Mahal, A.; Ishida, M.; Martins, S.; Johnson, W.D.; Pandian, J.; Abd-Allah, F.; Yaria, J.; Phan, H.T.; et al. Primary stroke prevention worldwide: Translating evidence into action. Lancet Public Health 2022, 7, e74–e85. [Google Scholar] [CrossRef] [PubMed]
- Siontis, G.C.M.; Tzoulaki, I.; Siontis, K.C.; Ioannidis, J.P.A. Comparisons of established risk prediction models for cardiovascular disease: Systematic review. BMJ 2012, 344, e3318. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, W.; Huang, J.; Yu, Q.; Yu, H.; Pu, Y.; Shi, Q. A systematic review of the status and methodological considerations for estimating risk of first ever stroke in the general population. Neurol. Sci. 2021, 42, 2235–2247. [Google Scholar] [CrossRef] [PubMed]
- Lloyd-Jones, D.M. Cardiovascular Risk Prediction. Circulation 2010, 121, 1768–1777. [Google Scholar] [CrossRef] [PubMed]
- Wolf, P.A.; D’Agostino, R.B.; Belanger, A.J.; Kannel, W.B. Probability of stroke: A risk profile from the Framingham Study. Stroke 1991, 22, 312–318. [Google Scholar] [CrossRef] [Green Version]
- Conroy, R.M.; Pyörälä, K.; Fitzgerald, A.P.; Sans, S.; Menotti, A.; De Backer, G.; De Bacquer, D.; Ducimetière, P.; Jousilahti, P.; Keil, U.; et al. Estimation of ten-year risk of fatal cardiovascular disease in Europe: The SCORE project. Eur. Heart J. 2003, 24, 987–1003. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.F.; Attia, J.; D’Este, C.; Yu, X.H.; Wu, X.G. A risk score predicted coronary heart disease and stroke in a Chinese cohort. J. Clin. Epidemiol. 2005, 58, 951–958. [Google Scholar] [CrossRef]
- Lip, G.Y.H.; Genaidy, A.; Tran, G.; Marroquin, P.; Estes, C.; Sloop, S. Improving Stroke Risk Prediction in the General Population: A Comparative Assessment of Common Clinical Rules, a New Multimorbid Index, and Machine-Learning-Based Algorithms. Thromb. Haemost. 2022, 122, 142–150. [Google Scholar] [CrossRef]
- Piepoli, M.F.; Hoes, A.W.; Agewall, S.; Albus, C.; Brotons, C.; Catapano, A.L.; Cooney, M.T.; Corrà, U.; Cosyns, B.; Deaton, C.; et al. 2016 European Guidelines on cardiovascular disease prevention in clinical practiceThe Sixth Joint Task Force of the European Society of Cardiology and Other Societies on Cardiovascular Disease Prevention in Clinical Practice (constituted by representatives of 10 societies and by invited experts)Developed with the special contribution of the European Association for Cardiovascular Prevention & Rehabilitation (EACPR). Eur. Heart J. 2016, 37, 2315–2381. [Google Scholar] [CrossRef]
- Choudhury, M.J.H.; Chowdhury, M.T.I.; Nayeem, A.; Jahan, W.A. Modifiable and Non-Modifiable Risk Factors of Stroke: A Review Update. J. Natl. Inst. Neurosci. Bangladesh 2015, 1, 22–26. [Google Scholar] [CrossRef] [Green Version]
- Leening, M.J.; Cook, N.R.; Ridker, P.M. Should we reconsider the role of age in treatment allocation for primary prevention of cardiovascular disease? Eur. Heart J. 2017, 38, 1542–1547. [Google Scholar] [CrossRef] [Green Version]
- Marma, A.K.; Berry, J.D.; Ning, H.; Persell, S.D.; Lloyd-Jones, D.M. Distribution of 10-Year and Lifetime Predicted Risks for Cardiovascular Disease in US Adults. Circ. Cardiovasc. Qual. Outcomes 2010, 3, 8–14. [Google Scholar] [CrossRef] [Green Version]
- Hunter, E.; Kelleher, J.D. Age Specific Models to Capture the Change in Risk Factor Contribution by Age to Short Term Primary Ischemic Stroke Risk. Front. Neurol. 2022, 13, 803749. [Google Scholar] [CrossRef]
- Yousufuddin, M.; Young, N. Aging and ischemic stroke. Aging 2019, 11, 2542–2544. [Google Scholar] [CrossRef]
- Wu, C.Y.; Wu, H.M.; Lee, J.D.; Weng, H.H. Stroke risk factors and subtypes in different age groups: A hospital-based study. Neurol. India 2010, 58, 863. [Google Scholar] [CrossRef]
- Du, X.; Wang, C.; Ni, J.; Gu, H.; Liu, J.; Pan, J.; Tu, J.; Wang, J.; Yang, Q.; Ning, X. Association of Blood Pressure With Stroke Risk, Stratified by Age and Stroke Type, in a Low-Income Population in China: A 27-Year Prospective Cohort Study. Front. Neurol. 2019, 10, 564. [Google Scholar] [CrossRef]
- Reshetnyak, E.; Ntamatungiro, M.; Pinheiro, L.C.; Howard, V.J.; Carson, A.P.; Martin, K.D.; Safford, M.M. Impact of Multiple Social Determinants of Health on Incident Stroke. Stroke 2020, 51, 2445–2453. [Google Scholar] [CrossRef]
- Avendano, M.; Kawachi, I.; Van Lenthe, F.; Boshuizen, H.C.; Mackenbach, J.P.; Van den Bos, G.; Fay, M.E.; Berkman, L.F. Socioeconomic Status and Stroke Incidence in the US Elderly. Stroke 2006, 37, 1368–1373. [Google Scholar] [CrossRef] [Green Version]
- George, M.G. Risk Factors for Ischemic Stroke in Younger Adults. Stroke 2020, 51, 729–735. [Google Scholar] [CrossRef]
- Putaala, J. Ischemic stroke in the young: Current perspectives on incidence, risk factors, and cardiovascular prognosis. Eur. Stroke J. 2016, 1, 28–40. [Google Scholar] [CrossRef] [Green Version]
- Paternoster, R.; Brame, R.; Mazerolle, P.; Piquero, A. Using the Correct Statistical Test for the Equality of Regression Coefficients. Criminology 1998, 36, 859–866. [Google Scholar] [CrossRef]
- Clogg, C.C.; Petkova, E.; Haritou, A. Statistical Methods for Comparing Regression Coefficients Between Models. Am. J. Sociol. 1995, 100, 1261–1293. [Google Scholar] [CrossRef] [Green Version]
- BioLINCC: Framingham Heart Study-Cohort (FHS-Cohort). 2015. Available online: https://biolincc.nhlbi.nih.gov/studies/framcohort/ (accessed on 25 January 2021).
- BioLINCC: Framingham Heart Study (FHS) Offspring (OS) and OMNI 1 Cohorts. 2009. Available online: https://biolincc.nhlbi.nih.gov/studies/framoffspring/ (accessed on 25 January 2021).
- Framingham Heart Study (FHS) Third Generation (Gen III), OMNI 2, and New Offspring (NOS) Cohorts. 2012. Available online: https://biolincc.nhlbi.nih.gov/studies/gen3/ (accessed on 25 January 2021).
- Hunter, E.; Kelleher, J.D. A review of risk concepts and models for predicting the risk of primary stroke. Front. Neuroinform. 2022, 16, 883762. [Google Scholar] [CrossRef] [PubMed]
- Xue, X.; Xie, X.; Gunter, M.; Rohan, T.E.; Wassertheil-Smoller, S.; Ho, G.Y.; Cirillo, D.; Yu, H.; Strickler, H.D. Testing the proportional hazards assumption in case-cohort analysis. BMC Med. Res. Methodol. 2013, 13, 88. [Google Scholar] [CrossRef] [Green Version]
- Kleinbaum, D.G.; Klein, M. Survival Analysis, 3rd ed.; Statistics for Biology and Health; Springer: London, UK, 2012. [Google Scholar]
- Kuitunen, I.; Ponkilainen, V.T.; Uimonen, M.M.; Eskelinen, A.; Reito, A. Testing the proportional hazards assumption in cox regression and dealing with possible non-proportionality in total joint arthroplasty research: Methodological perspectives and review. BMC Musculoskelet. Disord. 2021, 22, 489. [Google Scholar] [CrossRef]
- Herrgårdh, T.; Hunter, E.; Tunedal, K.; Örman, H.; Amann, J.; Navarro, F.A.; Martinez-Costa, C.; Kelleher, J.D.; Cedersund, G. Digital twins and hybrid modelling for simulation of physiological variables and stroke risk. bioRxiv 2022. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Under 50 | 50 to 59 | 60 to 69 | Over 70 | |
|---|---|---|---|---|
| Systolic Blood Pressure | ||||
| Coefficient | 0.70 | 0.54 | 0.50 | 0.17 |
| p-value | 4.52 × 10−6 | 4.00 × 10−11 | <2.00 × 10−16 | 2.27 × 10−6 |
| Standard error | 0.153 | 0.081 | 0.053 | 0.037 |
| Diastolic Blood Pressure | ||||
| Coefficient | 0.55 | 0.55 | 0.39 | 0.24 |
| p-value | 0.0001 | 5.11 × 10−11 | 9.32 × 10−14 | 8.6 × 10−11 |
| Standard error | 0.143 | 0.083 | 0.052 | 0.038 |
| Total Cholesterol | ||||
| Coefficient | 0.36 | 0.16 | 0.17 | 0.07 |
| p-value | 0.01 | 0.08 | 0.006 | 0.19 |
| Standard error | 0.143 | 0.090 | 0.063 | 0.050 |
| BMI | ||||
| Coefficient | 0.32 | 0.32 | 0.06 | 0.06 |
| p-value | 0.02 | 4.03 × 10−5 | 0.27 | 0.12 |
| Standard error | 0.136 | 0.078 | 0.050 | 0.037 |
| Sex (Male as Reference Category) | ||||
| Coefficient | 0.22 | 0.06 | -0.08 | 0.15 |
| p-value | 0.42 | 0.72 | 0.41 | 0.05 |
| Standard error | 0.271 | 0.155 | 0.100 | 0.074 |
| Atrial Fibrillation | ||||
| Coefficient | 0.48 | 1.40 | 1.94 | 2.64 |
| p-value | 0.36 | 0.0002 | 9.59 × 10−16 | <2 × 10−16 |
| Standard error | 0.523 | 0.381 | 0.241 | 0.155 |
| High Blood Pressure Treatment | ||||
| Coefficient | 0.66 | 0.21 | 0.23 | 0.11 |
| p-value | 0.15 | 0.31 | 0.03 | 0.15 |
| Standard error | 0.460 | 0.201 | 0.104 | 0.074 |
| Risk Factor | Age Group 1 | Age Group 2 | Z-Statistics | Significant |
|---|---|---|---|---|
| Systolic Blood Pressure | under 50 (0.70) | 70 plus (0.17) | 3.37 | Yes (5%) |
| Diastolic Blood Pressure | under 50 (0.55) | 70 plus (0.24) | 2.07 | Yes (5%) |
| Total Cholesterol | under 50 (0.36) | 70 plus (0.07) | 1.958 | Yes (10%) |
| BMI | under 50 (0.32) | 70 plus (0.06) | 1.88 | Yes (10%) |
| Sex (Male as Reference Category) | under 50 (0.22) | 60 to 69 (–0.08) | 1.05 | No |
| 60 to 69 (–0.08) | over 70 (0.15) | 1.81 | Yes (10%) | |
| Atrial Fibrillation | under 50 (0.48) | 70 plus (2.64) | 3.97 | Yes (5%) |
| High Blood Pressure Treatment | under 50 (0.66) | over 70 (0.11) | 1.19 | No |
| 60 to 69 (0.23) | over 70 (0.11) | 0.99 | No |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hunter, E.; Kelleher, J.D. Determining the Proportionality of Ischemic Stroke Risk Factors to Age. J. Cardiovasc. Dev. Dis. 2023, 10, 42. https://doi.org/10.3390/jcdd10020042
Hunter E, Kelleher JD. Determining the Proportionality of Ischemic Stroke Risk Factors to Age. Journal of Cardiovascular Development and Disease. 2023; 10(2):42. https://doi.org/10.3390/jcdd10020042
Chicago/Turabian StyleHunter, Elizabeth, and John D. Kelleher. 2023. "Determining the Proportionality of Ischemic Stroke Risk Factors to Age" Journal of Cardiovascular Development and Disease 10, no. 2: 42. https://doi.org/10.3390/jcdd10020042