

Development of a Machine Learning-Based Model to Predict Timed-Up-and-Go Test in Older Adults
 , , , , and
, , , , and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Patient Recruitment
2.2. General Data Assessment
2.3. Data Collection
2.4. Timed-Up-and-Go Test
2.5. Clinical Laboratory Data
2.6. Machine Learning Model Construction
2.7. Statistical Analysis
3. Results
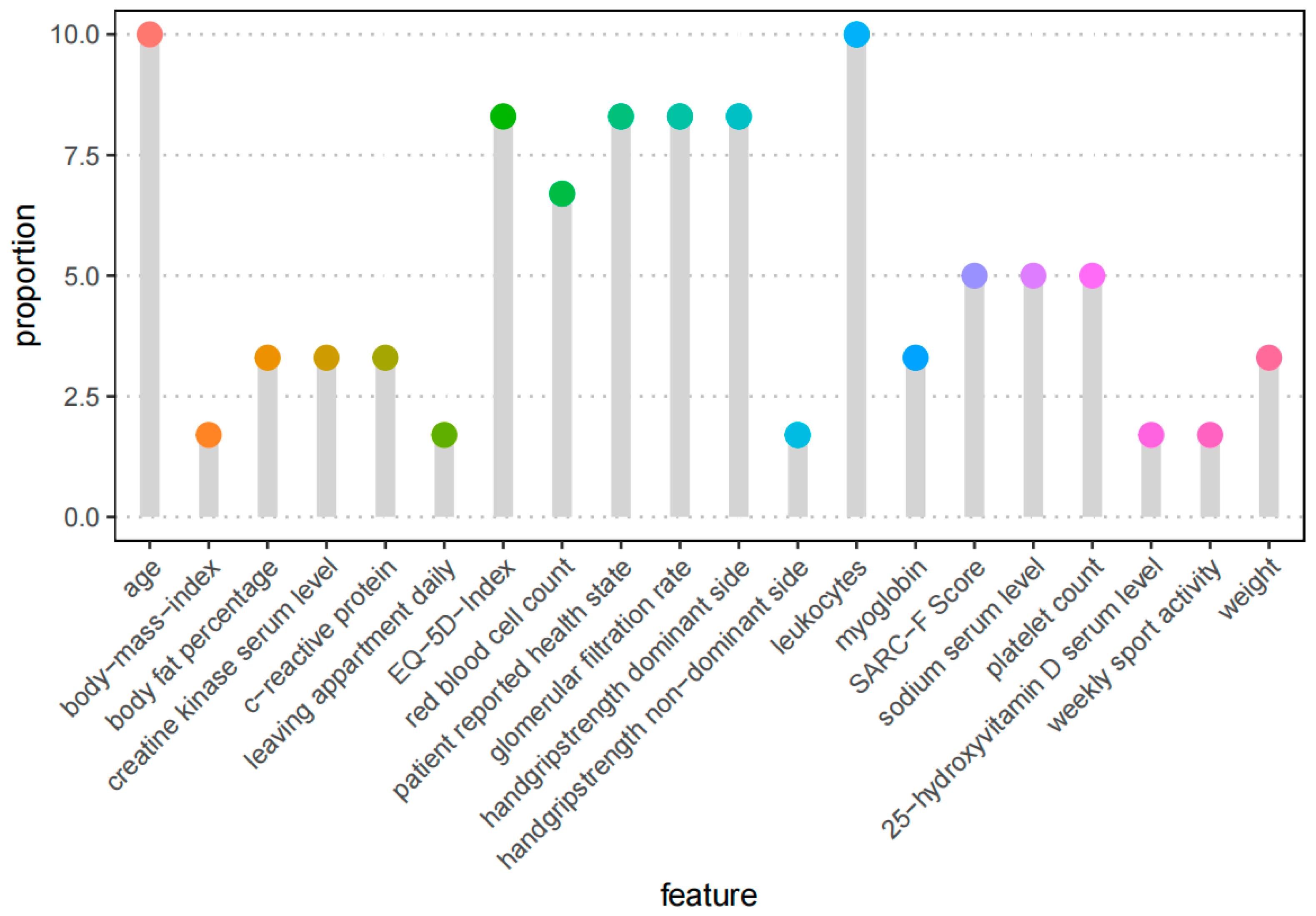
3.1. Feature Selection Process
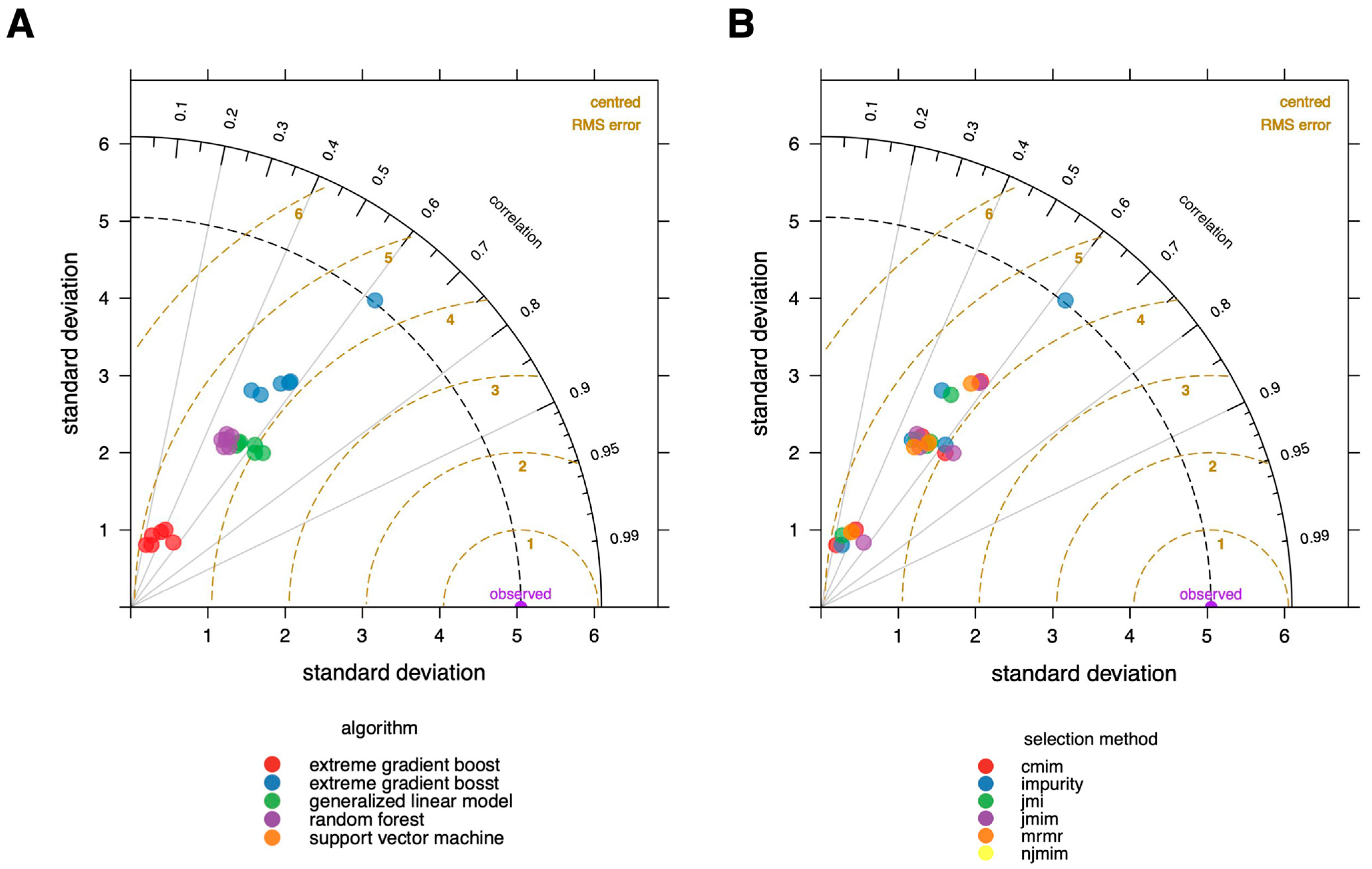
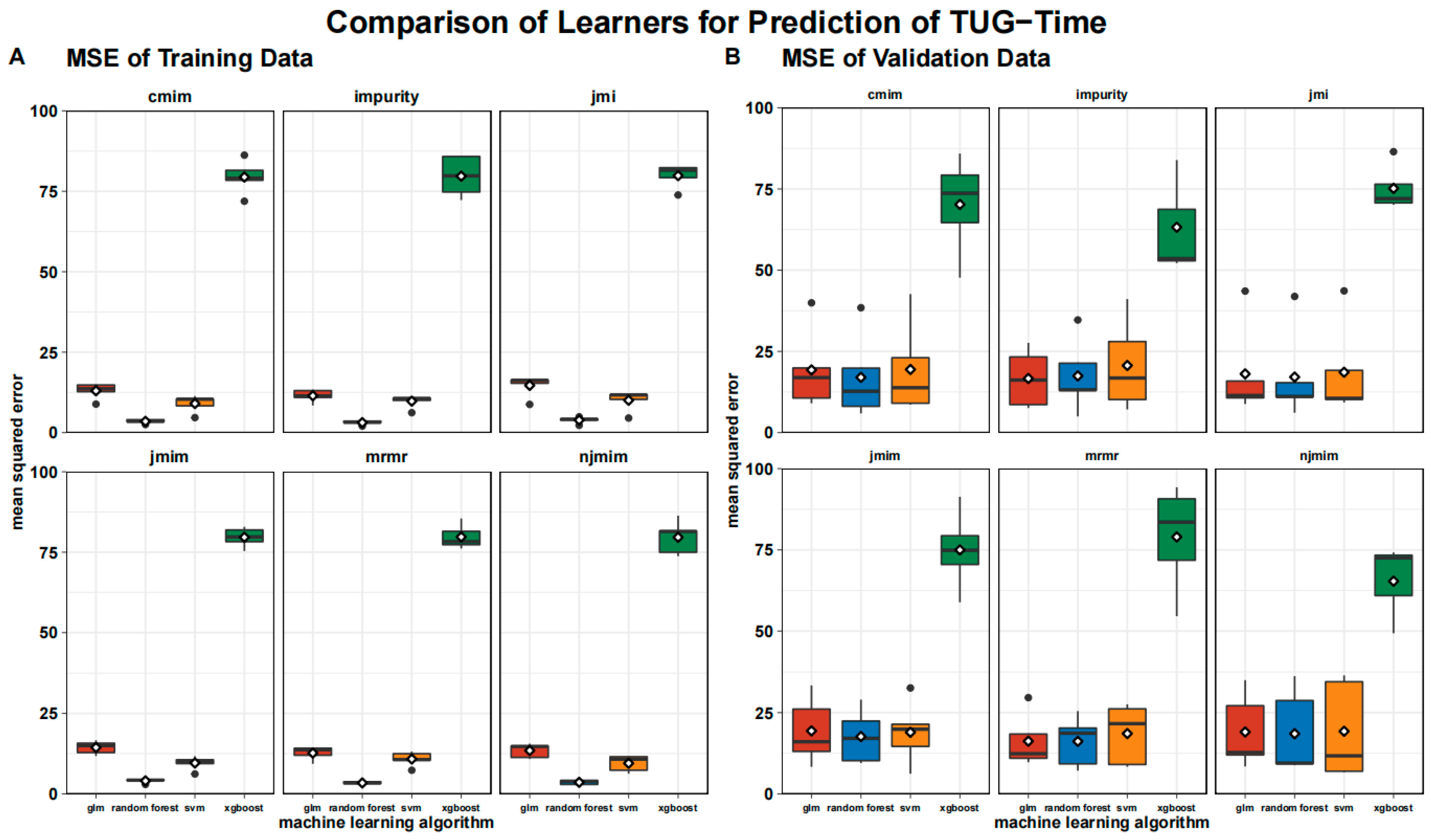
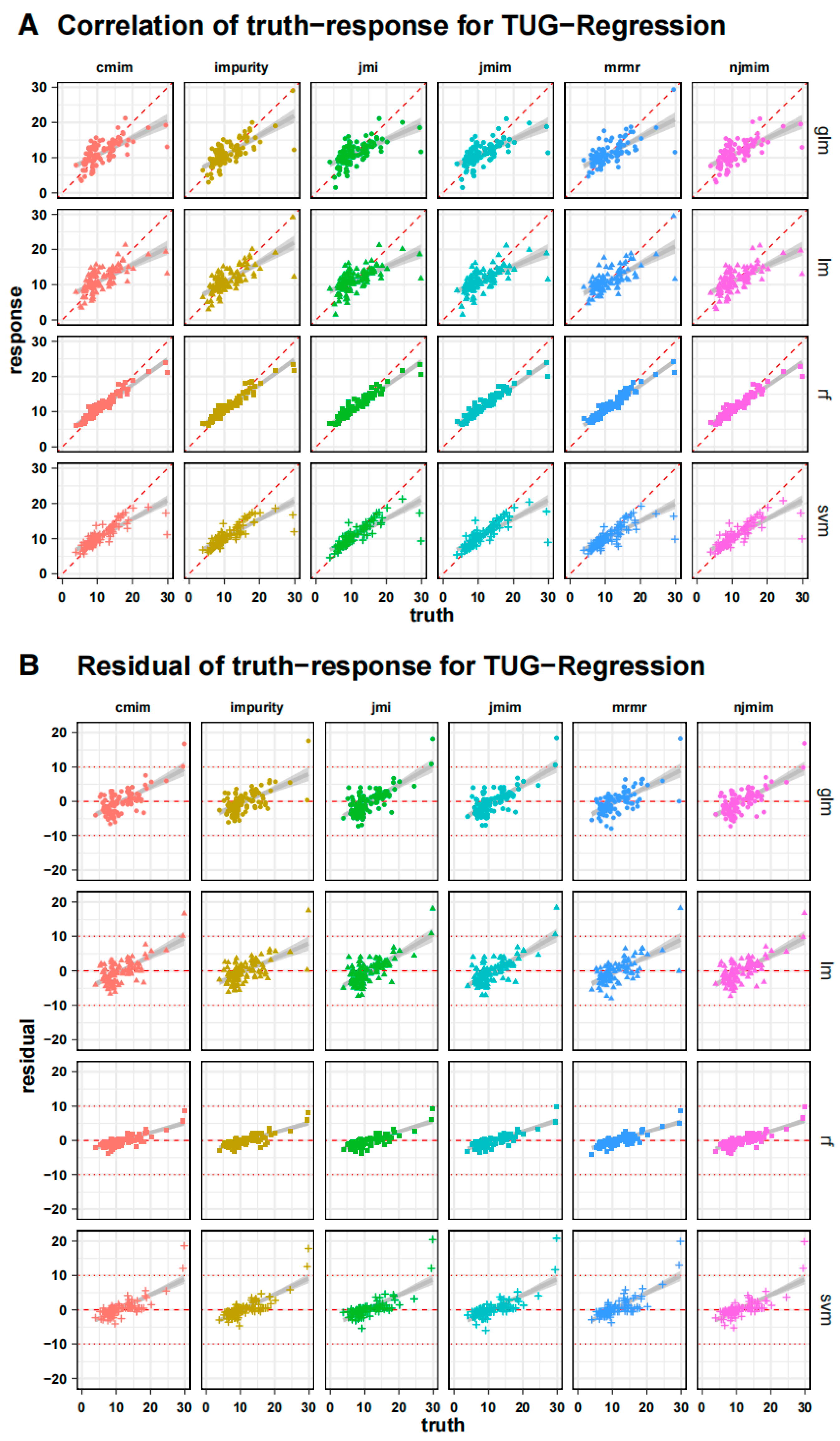
3.2. Validation of the Model
4. Discussion
5. Summary
- Multifactorial non-mobility data from over 100 patients enabled the development of reliable machine learning models for predicting TUG (Time-Up-and-Go) test times in bedridden patients.
- The choice of feature selection techniques minimally impacted the final model performance.
- Age and inflammatory parameters, particularly leukocyte count, emerged as crucial factors in TUG estimation, indicative of systemic inflammation and mortality risk.
- Biological age, incorporating factors such as CRP and hemoglobin levels, correlated with the TUG outcomes.
- Variables such as self-assessed health, GFR, EQ-5D index, and handgrip strength were identified as influential, aligning with existing frailty assessment tools.
- The random forest algorithm outperformed the other ML algorithms in TUG estimation
- The study achieved a mean absolute error of 2.7 s in TUG estimation, though limitations existed for TUG test times over 20 s, potentially due to limited extreme data and uncollected factors such as motivation.
- Estimating mobility from non-mobility data involves complex relationships, posing challenges.
- The impurity filter combined with the random forest algorithm showed the best performance, although overfitting risk and lower validation errors were noted.
6. Limitations
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- CDC. STEADI Assessment Timed Up & Go (TUG). Available online: https://www.cdc.gov/steadi/pdf/TUG_Test-print.pdf (accessed on 28 July 2023).
- Martin, P.; Keppler, A.M.; Alberton, P.; Neuerburg, C.; Drey, M.; Böcker, W.; Kammerlander, C.; Saller, M.M. Self-Assessment of Mobility of People over 65 Years of Age. Medicina 2021, 57, 980. [Google Scholar] [CrossRef] [PubMed]
- van Walree, I.C.; Scheepers, E.R.M.; van den Bos, F.; van Huis-Tanja, L.H.; Emmelot-Vonk, M.H.; Hamaker, M.E. Clinical Judgment versus Geriatric Assessment for Frailty in Older Patients with Cancer. J. Geriatr. Oncol. 2020, 11, 1138–1144. [Google Scholar] [CrossRef] [PubMed]
- Beaudart, C.; Rolland, Y.; Cruz-Jentoft, A.J.; Bauer, J.M.; Sieber, C.; Cooper, C.; Al-Daghri, N.; Araujo de Carvalho, I.; Bautmans, I.; Bernabei, R.; et al. Assessment of Muscle Function and Physical Performance in Daily Clinical Practice: A Position Paper Endorsed by the European Society for Clinical and Economic Aspects of Osteoporosis, Osteoarthritis and Musculoskeletal Diseases (ESCEO). Calcif. Tissue Int. 2019, 105, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Mahoney, F.I.; Barthel, D.W. Functional Evaluation: The Barthel Index. MD State Med. J. 1965, 14, 61–65. [Google Scholar] [PubMed]
- de Morton, N.A.; Davidson, M.; Keating, J.L. The de Morton Mobility Index (DEMMI): An Essential Health Index for an Ageing World. Health Qual. Life Outcomes 2008, 6, 63. [Google Scholar] [CrossRef] [PubMed]
- Hax, V.; Do Espirito Santo, R.C.; Dos Santos, L.P.; Farinon, M.; De Oliveira, M.S.; Três, G.L.; Gasparin, A.A.; De Andrade, N.P.B.; Bredemeier, M.; Xavier, R.M.H.; et al. Practical Screening Tools for Sarcopenia in Patients with Systemic Sclerosis. PLoS ONE 2021, 16, e0245683. [Google Scholar] [CrossRef] [PubMed]
- Usmani, S.; Saboor, A.; Haris, M.; Khan, M.A.; Park, H. Latest Research Trends in Fall Detection and Prevention Using Machine Learning: A Systematic Review. Sensors 2021, 21, 5134. [Google Scholar] [CrossRef]
- Parsons, R.; Blythe, R.D.; Cramb, S.M.; McPhail, S.M. Inpatient Fall Prediction Models: A Scoping Review. Gerontology 2023, 69, 14–29. [Google Scholar] [CrossRef]
- Lippi, L.; D’Abrosca, F.; Folli, A.; Dal Molin, A.; Moalli, S.; Maconi, A.; Ammendolia, A.; de Sire, A.; Invernizzi, M. Closing the Gap between Inpatient and Outpatient Settings: Integrating Pulmonary Rehabilitation and Technological Advances in the Comprehensive Management of Frail Patients. Int. J. Environ. Res. Public Health 2022, 19, 9150. [Google Scholar] [CrossRef]
- Teixeira, E.; Bohn, L.; Guimarães, J.P.; Marques-Aleixo, I. Portable Digital Monitoring System for Sarcopenia Screening and Diagnosis. Geriatrics 2022, 7, 121. [Google Scholar] [CrossRef]
- Petretto, D.R.; Gaviano, L.; Carrogu, G.P.; Berti, R.; Pinna, M.; Pili, R. Telemedicine: Issues in the Analysis of Its Use in Elderly People and in People with Disabilities, According to the Perspective of the Clinical Psychology of Disability. Geriatrics 2022, 8, 5. [Google Scholar] [CrossRef]
- Chen, L.P.; Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning, Second Edition. Stat. Pap. 2019, 60, 1793–1795. [Google Scholar] [CrossRef]
- Ludwig, K.; von der Schulenburg, J.-M.G.; Greiner, W. German Value Set for the EQ-5D-5L. Pharmacoeconomics 2018, 36, 663–674. [Google Scholar] [CrossRef]
- Bahat, G.; Ozkok, S.; Kilic, C.; Karan, M.A. SARC-F Questionnaire Detects Frailty in Older Adults. J. Nutr. Health Aging 2021, 25, 448–453. [Google Scholar] [CrossRef]
- Dachverband Osteologie e.V. Prophylaxe, Diagnostik Und Therapie Der OSTEOPOROSE. Available online: https://www.dv-osteologie.org/uploads/Leitlinie%202017/Finale%20Version%20Leitlinie%20Osteoporose%202017_end.pdf (accessed on 28 July 2023).
- Kraus, M. TUG Regression Pipeline. Available online: https://github.com/KrausMoritz/KI_Workstation/blob/main/TUG_Regression.Rmd (accessed on 25 May 2022).
- Lang, M.; Binder, M.; Richter, J.; Schratz, P.; Pfisterer, F.; Coors, S.; Au, Q.; Casalicchio, G.; Kotthoff, L.; Bischl, B. Mlr3: A Modern Object-Oriented Machine Learning Framework in R. J. Open Source Softw. 2019, 4, 1903. [Google Scholar] [CrossRef]
- Kursa, M.B. Praznik: High Performance Information-Based Feature Selection. SoftwareX 2021, 16, 100819. [Google Scholar] [CrossRef]
- Li, K.; Yu, M.; Liu, L.; Li, T.; Zhai, J. Feature Selection Method Based on Weighted Mutual Information for Imbalanced Data. Int. J. Softw. Eng. Knowl. Eng. 2018, 28, 1177–1194. [Google Scholar] [CrossRef]
- Chormunge, S.; Jena, S. Correlation Based Feature Selection with Clustering for High Dimensional Data. J. Electr. Syst. Inf. Technol. 2018, 5, 542–549. [Google Scholar] [CrossRef]
- Yang, H.; Moody, J. Data Visualization and Feature Selection: New Algorithms for Nongaussian Data. Adv. Neural Inf. Process. Syst. 1999, 12, 687–693. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature Selection Based on Mutual Information Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Fleuret, F. Fast Binary Feature Selection with Conditional Mutual Information. J. Mach. Learn. Res. 2004, 5, 1531–1555. [Google Scholar]
- Sechidis, K.; Azzimonti, L.; Pocock, A.; Corani, G.; Weatherall, J.; Brown, G. Efficient Feature Selection Using Shrinkage Estimators. Mach. Learn. 2019, 108, 1261–1286. [Google Scholar] [CrossRef]
- Bennasar, M.; Hicks, Y.; Setchi, R. Feature Selection Using Joint Mutual Information Maximisation. Expert Syst. Appl. 2015, 42, 8520–8532. [Google Scholar] [CrossRef]
- Wright, M.N.; Ziegler, A. Ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef]
- Wang, M.; Tian, G.L. Adaptive Group Lasso for High-Dimensional Generalized Linear Models. Stat. Pap. 2019, 60, 1469–1486. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Chai, T.; Draxler, R.R. Root Mean Square Error (RMSE) or Mean Absolute Error (MAE)?—Arguments against Avoiding RMSE in the Literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Taylor, K.E. Summarizing Multiple Aspects of Model Performance in a Single Diagram. J. Geophys. Res. Atmos. 2001, 106, 7183–7192. [Google Scholar] [CrossRef]
- Leng, S.; Chen, X.; Mao, G. Frailty Syndrome: An Overview. Clin. Interv. Aging 2014, 2014, 433–441. [Google Scholar] [CrossRef]
- Obermeyer, Z.; Emanuel, E.J. Predicting the Future—Big Data, Machine Learning, and Clinical Medicine. N. Engl. J. Med. 2016, 375, 1216–1219. [Google Scholar] [CrossRef]
- Larsson, B.A.M.; Johansson, L.; Johansson, H.; Axelsson, K.F.; Harvey, N.; Vandenput, L.; Magnusson, P.; McCloskey, E.; Liu, E.; Kanis, J.A.; et al. The Timed up and Go Test Predicts Fracture Risk in Older Women Independently of Clinical Risk Factors and Bone Mineral Density. Osteoporos. Int. 2021, 32, 75–84. [Google Scholar] [CrossRef] [PubMed]
- Battiti, R. Using Mutual Information for Selecting Features in Supervised Neural Net Learning. IEEE Trans. Neural Networks 1994, 5, 537–550. [Google Scholar] [CrossRef] [PubMed]
- Pudjihartono, N.; Fadason, T.; Kempa-Liehr, A.W.; O’Sullivan, J.M. A Review of Feature Selection Methods for Machine Learning-Based Disease Risk Prediction. Front. Bioinform. 2022, 2, 927312. [Google Scholar] [CrossRef] [PubMed]
- Brown, G.; Pocock, A.; Zhao, M.J.; Luján, M. Conditional Likelihood Maximisation: A Unifying Framework for Information Theoretic Feature Selection. JMLR 2012, 13, 27–66. [Google Scholar]
- Leng, L.; Zhang, J. PalmHash Code vs. PalmPhasor Code. Neurocomputing 2013, 108, 1–12. [Google Scholar] [CrossRef]
- Leng, L.; Li, M.; Kim, C.; Bi, X. Dual-Source Discrimination Power Analysis for Multi-Instance Contactless Palmprint Recognition. Multimed. Tools Appl. 2017, 76, 333–354. [Google Scholar] [CrossRef]
- Wollstadt, P.; Schmitt, S.; Wibral, M. A Rigorous Information-Theoretic Definition of Redundancy and Relevancy in Feature Selection Based on (Partial) Information Decomposition. J. Mach. Learn. Res. 2023, 24, 1–44. [Google Scholar]
- Welstead, M.; Jenkins, N.D.; Russ, T.C.; Luciano, M.; Muniz-Terrera, G. A Systematic Review of Frailty Trajectories: Their Shape and Influencing Factors. Gerontologist 2021, 61, e463–e475. [Google Scholar] [CrossRef] [PubMed]
- Chmielewski, P.P.; Strzelec, B. Elevated Leukocyte Count as a Harbinger of Systemic Inflammation, Disease Progression, and Poor Prognosis: A Review. Folia Morphol. 2018, 77, 171–178. [Google Scholar] [CrossRef]
- Proctor, M.J.; McMillan, D.C.; Horgan, P.G.; Fletcher, C.D.; Talwar, D.; Morrison, D.S. Systemic Inflammation Predicts All-Cause Mortality: A Glasgow Inflammation Outcome Study. PLoS ONE 2015, 10, e0116206. [Google Scholar] [CrossRef]
- Klibanski, A.; Adams-Campbell, L.; Bassford, T.; Blair, S.N.; Boden, S.D.; Dickersin, K.; Gifford, D.R.; Glasse, L.; Goldring, S.R.; Hruska, K.; et al. Osteoporosis Prevention, Diagnosis, and Therapy. JAMA J. Am. Med. Assoc. 2001, 285, 785–795. [Google Scholar] [CrossRef]
- Baker, G.T.; Sprott, R.L. Biomarkers of Aging. Exp. Gerontol. 1988, 23, 223–239. [Google Scholar] [CrossRef] [PubMed]
- Lohman, T.; Bains, G.; Berk, L.; Lohman, E. Predictors of Biological Age: The Implications for Wellness and Aging Research. Gerontol. Geriatr. Med. 2021, 7, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Tracy, B.M.; Wilson, J.M.; Smith, R.N.; Schenker, M.L.; Gelbard, R.B. The 5-Item Modified Frailty Index Predicts Adverse Outcomes in Trauma. J. Surg. Res. 2020, 253, 167–172. [Google Scholar] [CrossRef]
- Chua, K.Y.; Lim, W.S.; Lin, X.; Yuan, J.-M.; Koh, W.-P. Handgrip Strength and Timed Up-and-Go (TUG) Test Are Predictors of Short-Term Mortality among Elderly in a Population-Based Cohort in Singapore. J. Nutr. Health Aging 2020, 24, 371–378. [Google Scholar] [CrossRef]
- Amann, J.; Vetter, D.; Blomberg, S.N.; Christensen, H.C.; Coffee, M.; Gerke, S.; Gilbert, T.K.; Hagendorff, T.; Holm, S.; Livne, M.; et al. To Explain or Not to Explain?—Artificial Intelligence Explainability in Clinical Decision Support Systems. PLOS Digit. Health 2022, 1, e0000016. [Google Scholar] [CrossRef]
- Markus, A.F.; Kors, J.A.; Rijnbeek, P.R. The Role of Explainability in Creating Trustworthy Artificial Intelligence for Health Care: A Comprehensive Survey of the Terminology, Design Choices, and Evaluation Strategies. J. Biomed. Inform. 2021, 113, 103655. [Google Scholar] [CrossRef]
- Belkin, M.; Hsu, D.; Mitra, P.P. Overfitting or Perfect Fitting? Risk Bounds for Classification and Regression Rules That Interpolate. arXiv 2018, arXiv:1806.05161. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | N | Median | IQR |
|---|---|---|---|
| Age | 103 | 76 | (71, 80) |
| Handgrip strength | 22.4 | (18.8, 25.2) | |
| TUG test time | 9.5 | (8.0, 13.8) | |
| Weight | 64 | (58, 70) | |
| Height | 162 | (158, 166) | |
| BMI | 24.4 | (21.7, 25.9) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kraus, M.; Stumpf, U.C.; Keppler, A.M.; Neuerburg, C.; Böcker, W.; Wackerhage, H.; Baumbach, S.F.; Saller, M.M. Development of a Machine Learning-Based Model to Predict Timed-Up-and-Go Test in Older Adults. Geriatrics 2023, 8, 99. https://doi.org/10.3390/geriatrics8050099
Kraus M, Stumpf UC, Keppler AM, Neuerburg C, Böcker W, Wackerhage H, Baumbach SF, Saller MM. Development of a Machine Learning-Based Model to Predict Timed-Up-and-Go Test in Older Adults. Geriatrics. 2023; 8(5):99. https://doi.org/10.3390/geriatrics8050099
Chicago/Turabian StyleKraus, Moritz, Ulla Cordula Stumpf, Alexander Martin Keppler, Carl Neuerburg, Wolfgang Böcker, Henning Wackerhage, Sebastian Felix Baumbach, and Maximilian Michael Saller. 2023. "Development of a Machine Learning-Based Model to Predict Timed-Up-and-Go Test in Older Adults" Geriatrics 8, no. 5: 99. https://doi.org/10.3390/geriatrics8050099