
Lung Field Segmentation in Chest X-ray Images Using Superpixel Resizing and Encoder–Decoder Segmentation Networks



Abstract
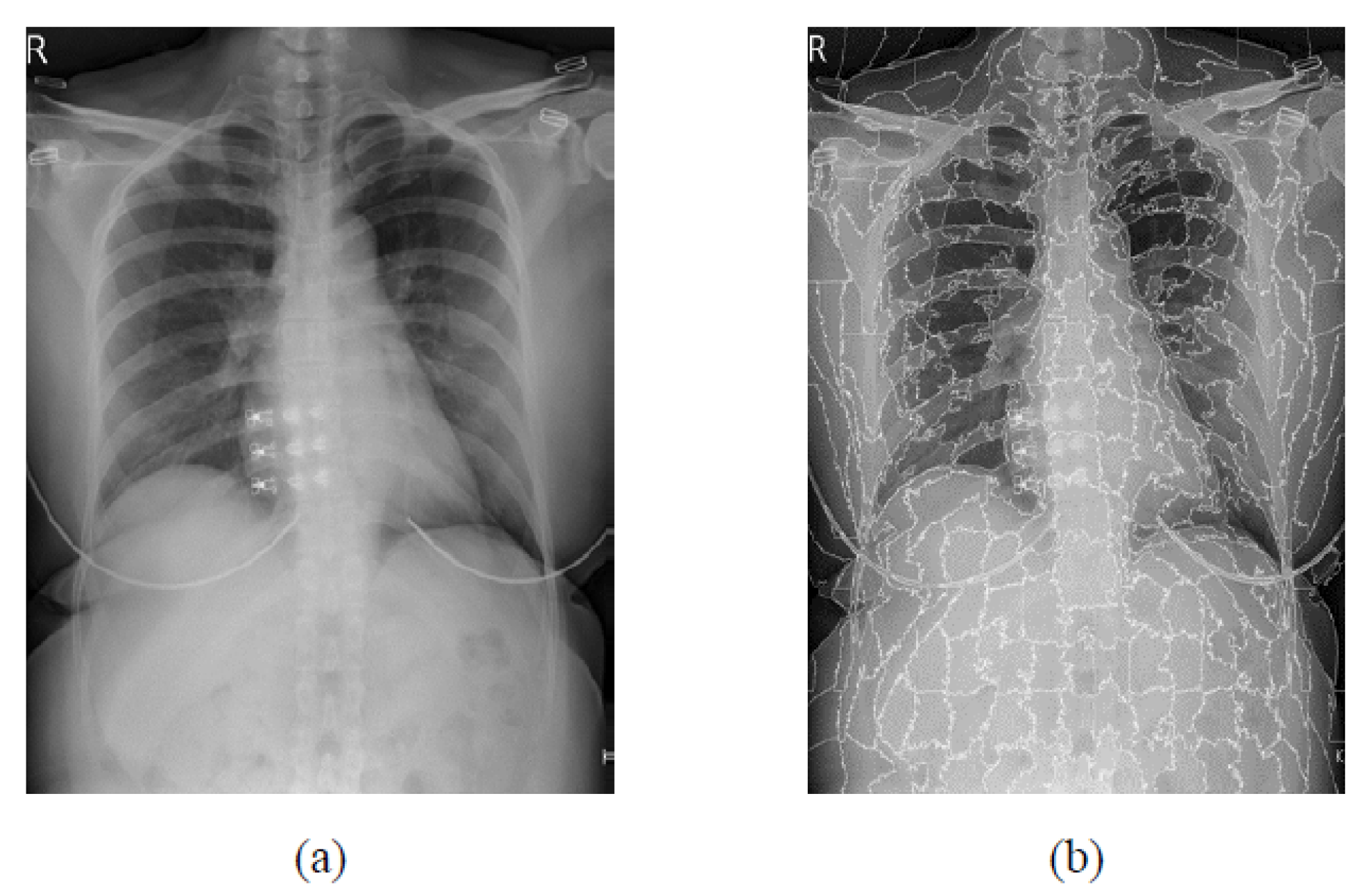
:1. Introduction
2. Related Work
2.1. Lung Field Segmentation
2.2. Superpixels
3. Materials and Methods
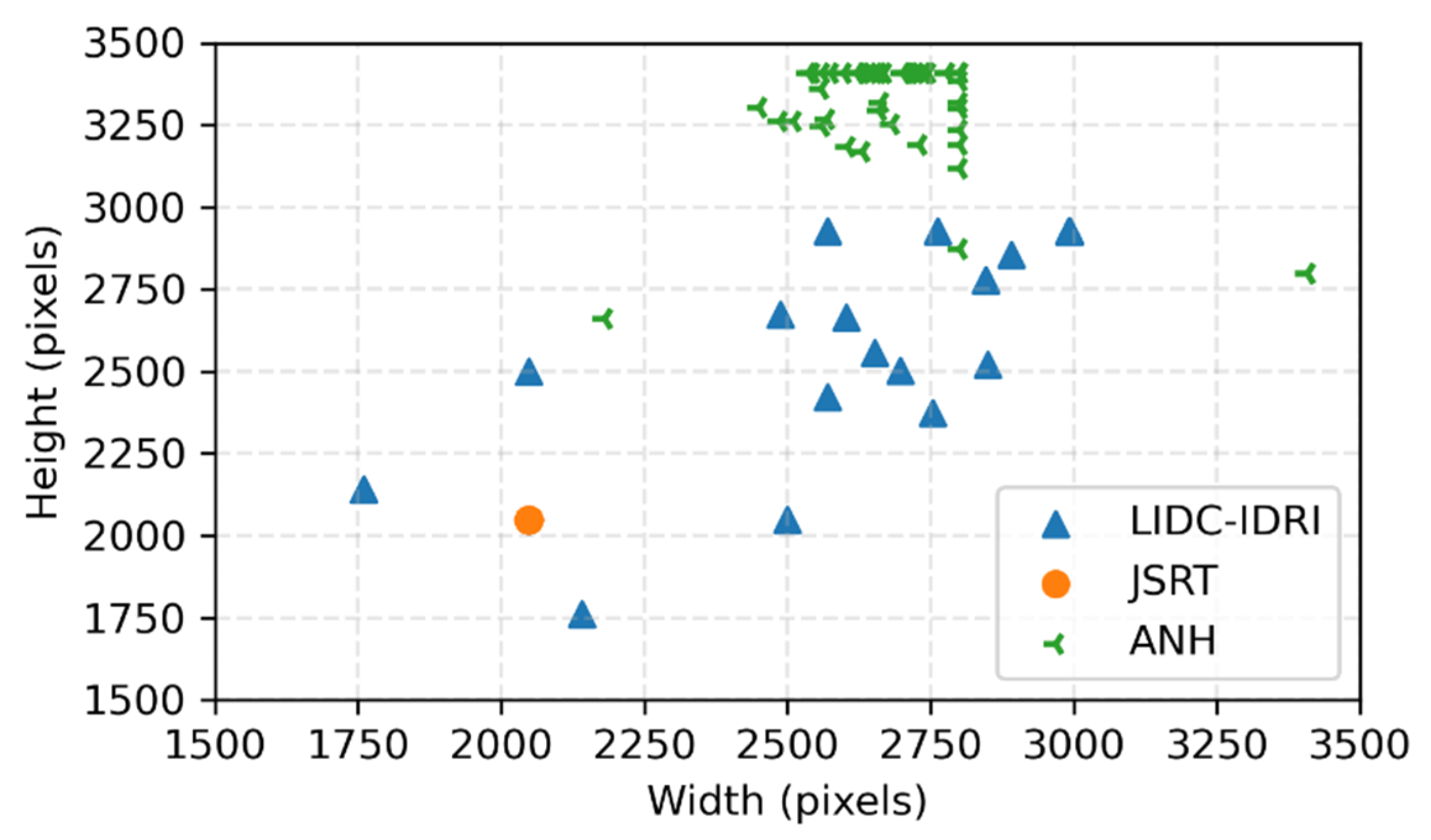
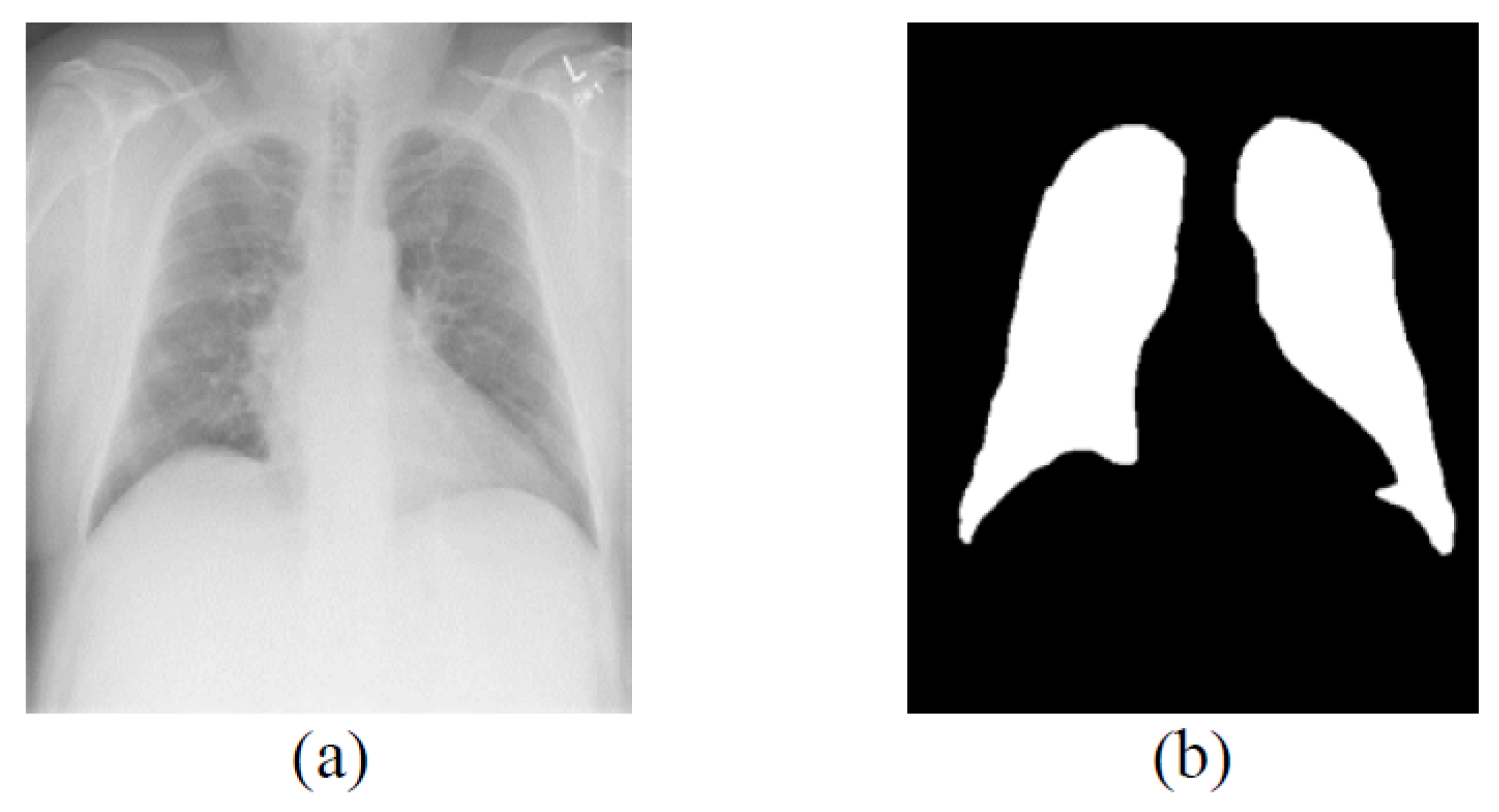
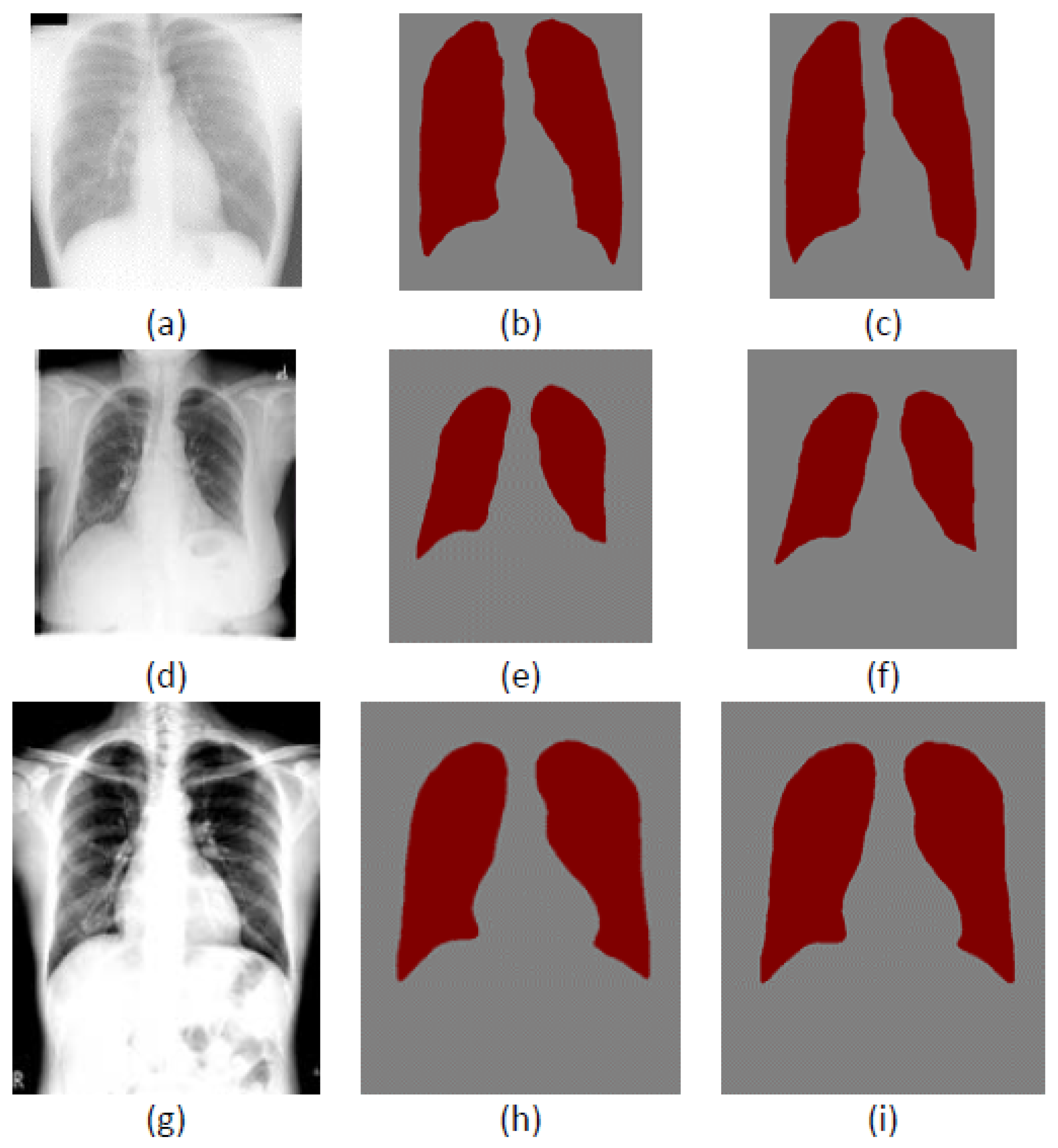
3.1. Datasets and Preprocessing
3.2. Overview of the Lung Field Segmentation
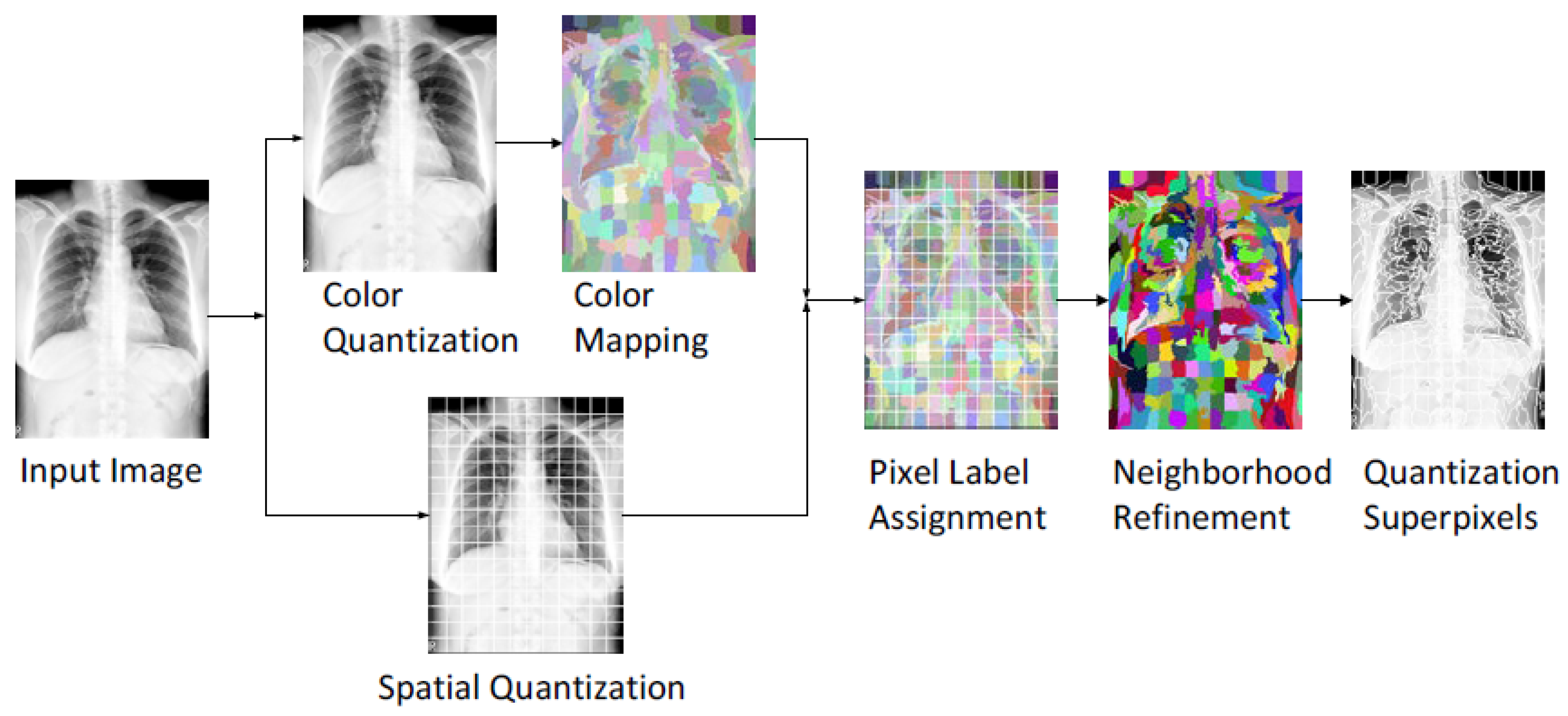
3.3. USEQ Superpixel Extraction
3.4. USEQ Superpixel Resizing Framework
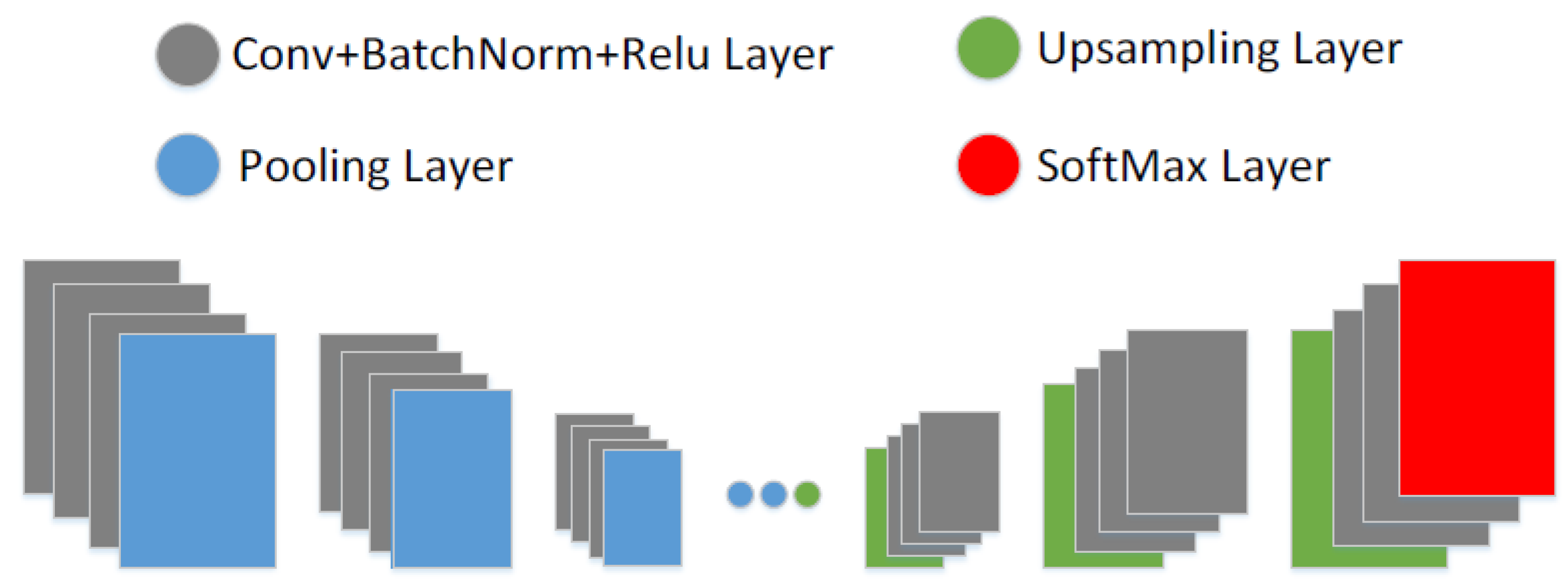
3.5. Encoder–Decoder Segmentation Networks
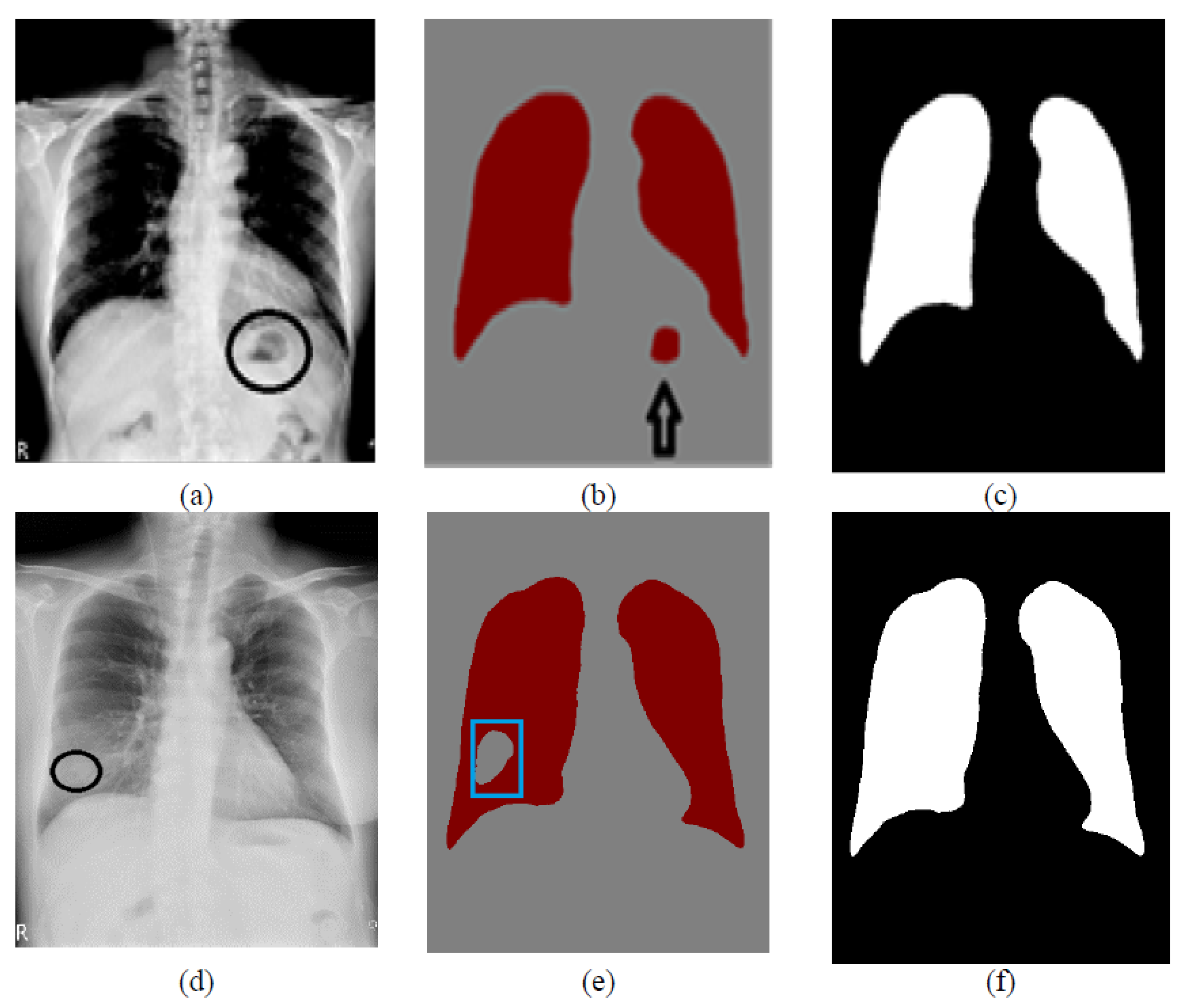
3.6. Post-Processing
| Algorithm 1. Lung Field Segmentation |
| Input: Given a set of CXR images X and a set of ground truth masks Y. and . |
| Output: O, the segmentation results. |
| 1 Decompose I into homogeneous matrix H of homogeneous regions and a boundary matrix B of the boundaries of superpixels using superpixel extraction. |
| 2 Downsample I to obtain the downsampled image using Equation (14). |
| 3 Downsample M to obtain the downsampled image . |
| 4 Store the superpixel label information for each pixel of I. |
| 5 In training phase: |
| 5.1 Input a set of and a set of to the encoder–decoder segmentation network to train the model. |
| 6 In prediction phase: |
| 6.1 Input to the encoder–decoder segmentation network to predict the low-resolution segmentation results |
| 6.2 Upsample to obtain the high-resolution segmentation results O using Equation (16). |
| 6.3 Run the post-processing procedure on O to correct the segmentation results. |
| 6.3.1 Keep the two largest regions and discard other small regions. |
| 6.3.2 Fill all the holes in the two largest regions. |
| 7 Output the final result O. |
4. Experimental Results
4.1. Datasets and Model Training
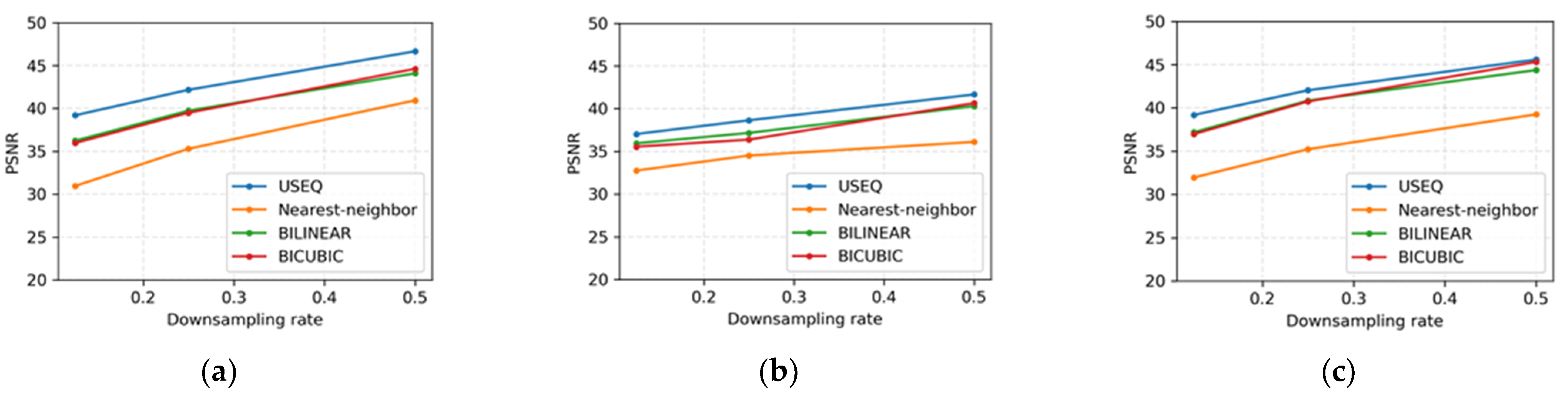
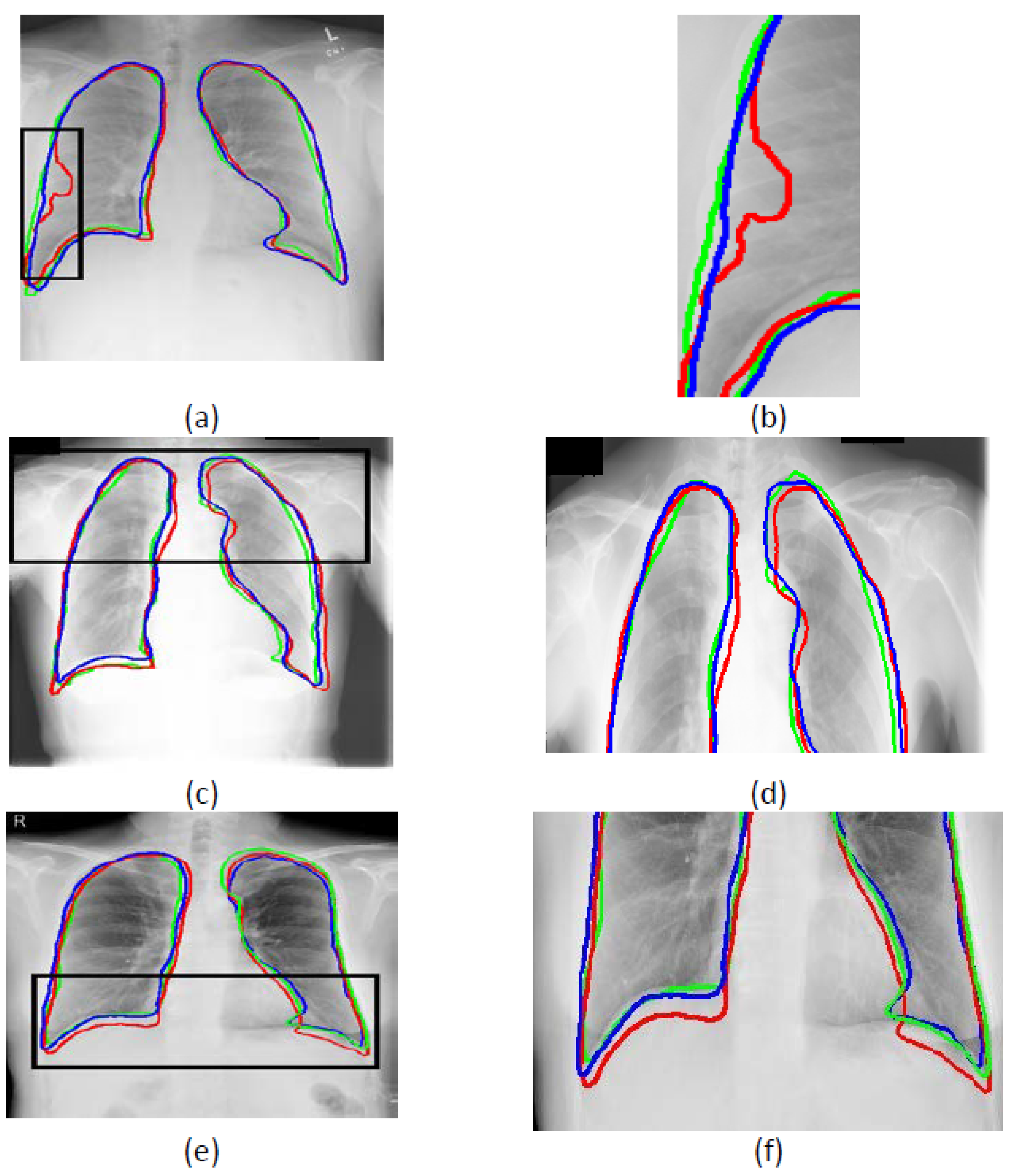
4.2. Performance Comparison of Superpixel and Bicubic Interpolations
4.3. Cross-Dataset Generalization
4.4. Comparison with other Lung Segmentation Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shiraishi, J.; Katsuragawa, S.; Ikezoe, J.; Matsumoto, T.; Kobayashi, T.; Komatsu, K.I.; Matsui, M.; Fujita, H.; Kodera, Y.; Doi, K. Development of a digital image database for chest radiographs with and without a lung nodule: Receiver operating characteristic analysis of radiologists’ detection of pulmonary nodules. Am. J. Roentgenol. 2000, 174, 71–74. [Google Scholar] [CrossRef] [PubMed]
- Wang, C. Segmentation of multiple structures in chest radiographs using multi-task fully convolutional networks. In Proceedings of the Scandinavian Conference on Image Analysis, Tromsø, Norway, 12–14 June 2017; pp. 282–289. [Google Scholar]
- Novikov, A.A.; Lenis, D.; Major, D.; Hladůvka, J.; Wimmer, M.; Bühler, K. Fully convolutional architectures for multi-class segmentation in chest radiographs. IEEE Trans. Med. Imaging 2018, 37, 1865–1876. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, W.; Liu, Y.; Lin, L.; Yun, Z.; Lu, Z.; Feng, Q.; Chen, W. Lung Field Segmentation in Chest Radiographs from Boundary Maps by a Structured Edge Detector. IEEE J. Biomed. Health Inform. 2018, 22, 842–851. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.-R.; Wang, W.-A.; Lin, S.-Y.; Lin, Y.-Y. USEQ: Ultra-fast superpixel extraction via quantization. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 1965–1970. [Google Scholar]
- Hu, S.; Hoffman, E.A.; Reinhardt, J.M. Automatic lung segmentation for accurate quantitation of volumetric X-ray CT images. IEEE Trans. Med. Imaging 2001, 20, 490–498. [Google Scholar] [CrossRef]
- Wang, J.; Li, F.; Li, Q. Automated segmentation of lungs with severe interstitial lung disease in CT. Med. Phys. 2009, 36, 4592–4599. [Google Scholar] [CrossRef] [Green Version]
- Jaffar, M.A.; Iqbal, A.; Hussain, A.; Baig, R.; Mirza, A.M. Genetic fuzzy based automatic lungs segmentation from CT scans images. Int. J. Innov. Comput. Inf. Control 2011, 7, 1875–1890. [Google Scholar]
- Sluimer, I.; Prokop, M.; Van Ginneken, B. Toward automated segmentation of the pathological lung in CT. IEEE Trans. Med. Imaging 2005, 24, 1025–1038. [Google Scholar] [CrossRef]
- Chama, C.K.; Mukhopadhyay, S.; Biswas, P.K.; Dhara, A.K.; Madaiah, M.K.; Khandelwal, N. Automated lung field segmentation in CT images using mean shift clustering and geometrical features. In Proceedings of the Medical Imaging 2013: Computer-Aided Diagnosis, Lake Buena Vista, FL, USA, 9–14 February 2013; p. 867032. [Google Scholar]
- Ibragimov, B.; Likar, B.; Pernus, F. A game-theoretic framework for landmark-based image segmentation. IEEE Trans. Med. Imaging 2012, 31, 1761–1776. [Google Scholar] [CrossRef]
- Van Ginneken, B.; Stegmann, M.B.; Loog, M. Segmentation of anatomical structures in chest radiographs using supervised methods: A comparative study on a public database. Med. Image Anal. 2006, 10, 19–40. [Google Scholar] [CrossRef] [Green Version]
- Shao, Y.; Gao, Y.; Guo, Y.; Shi, Y.; Yang, X.; Shen, D. Hierarchical lung field segmentation with joint shape and appearance sparse learning. IEEE Trans. Med. Imaging 2014, 33, 1761–1780. [Google Scholar] [CrossRef]
- Soliman, A.; Khalifa, F.; Elnakib, A.; El-Ghar, M.A.; Dunlap, N.; Wang, B.; Gimel’farb, G.; Keynton, R.; El-Baz, A. Accurate lungs segmentation on CT chest images by adaptive appearance-guided shape modeling. IEEE Trans. Med. Imaging 2017, 36, 263–276. [Google Scholar] [CrossRef]
- Sun, S.; Bauer, C.; Beichel, R. Automated 3-D segmentation of lungs with lung cancer in CT data using a novel robust active shape model approach. IEEE Trans. Med. Imaging 2012, 31, 449–460. [Google Scholar]
- Hu, J.; Li, P. An Automatic Lung Field Segmentation Algorithm Based on Improved Snake Model in X-ray Chest Radiograph. In Proceedings of the 2021 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 1845–1851. [Google Scholar]
- Bosdelekidis, V.; Ioakeimidis, N.S. Lung field segmentation in chest X-rays: A deformation-tolerant procedure based on the approximation of rib cage seed points. Appl. Sci. 2020, 10, 6264. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ciresan, D.; Giusti, A.; Gambardella, L.M.; Schmidhuber, J. Deep neural networks segment neuronal membranes in electron microscopy images. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 2843–2851. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Arora, R.; Saini, I.; Sood, N. Modified UNet++ Model: A Deep Model for Automatic Segmentation of Lungs from Chest X-ray Images. In Proceedings of the 2021 2nd International Conference on Secure Cyber Computing and Communications (ICSCCC), Jalandhar, India, 21–23 May 2021; pp. 166–169. [Google Scholar]
- Yahyatabar, M.; Jouvet, P.; Cheriet, F. Dense-Unet: A light model for lung fields segmentation in Chest X-ray images. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 1242–1245. [Google Scholar]
- Wang, D.; Arzhaeva, Y.; Devnath, L.; Qiao, M.; Amirgholipour, S.; Liao, Q.; McBean, R.; Hillhouse, J.; Luo, S.; Meredith, D.; et al. Automated Pneumoconiosis Detection on Chest X-rays Using Cascaded Learning with Real and Synthetic Radiographs. In Proceedings of the 2020 Digital Image Computing: Techniques and Applications (DICTA), Melbourne, Australia, 29 November–2 December 2020; pp. 1–6. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Moore, A.P.; Prince, S.J.; Warrell, J.; Mohammed, U.; Jones, G. Superpixel lattices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Veksler, O.; Boykov, Y.; Mehrani, P. Superpixels and supervoxels in an energy optimization framework. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 211–224. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef] [Green Version]
- Vedaldi, A.; Soatto, S. Quick shift and kernel methods for mode seeking. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 705–718. [Google Scholar]
- Vincent, L.; Soille, P. Watersheds in digital spaces: An efficient algorithm based on immersion simulations. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 583–598. [Google Scholar] [CrossRef] [Green Version]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. Turbopixels: Fast superpixels using geometric flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Armato III, S.G.; McLennan, G.; Bidaut, L.; McNitt-Gray, M.F.; Meyer, C.R.; Reeves, A.P.; Zhao, B.; Aberle, D.R.; Henschke, C.I.; Hoffman, E.A.; et al. The lung image database consortium (LIDC) and image database resource initiative (IDRI): A completed reference database of lung nodules on CT scans. Med. Phys. 2011, 38, 915–931. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.-R.; Huang, W.-Y.; Liao, Y.-S.; Lee, C.-C.; Yeh, Y.-W. A Content-Adaptive Resizing Framework for Boosting Computation Speed of Background Modeling Methods. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 1192–1204. [Google Scholar] [CrossRef]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Lee, M.; Tai, Y.-W. Robust all-in-focus super-resolution for focal stack photography. IEEE Trans. Image Process. 2016, 25, 1887–1897. [Google Scholar] [CrossRef] [PubMed]
- Smith, P. Bilinear interpolation of digital images. Ultramicroscopy 1981, 6, 201–204. [Google Scholar] [CrossRef]
- Ren, C.; He, X.; Teng, Q.; Wu, Y.; Nguyen, T.Q. Single image super-resolution using local geometric duality and non-local similarity. IEEE Trans. Image Process. 2016, 25, 2168–2183. [Google Scholar] [CrossRef]
- Candemir, S.; Jaeger, S.; Palaniappan, K.; Musco, J.P.; Singh, R.K.; Xue, Z.; Karargyris, A.; Antani, S.; Thoma, G.; McDonald, C.J. Lung segmentation in chest radiographs using anatomical atlases with nonrigid registration. IEEE Trans. Med. Imaging 2014, 33, 577–590. [Google Scholar] [CrossRef]
- Seghers, D.; Loeckx, D.; Maes, F.; Vandermeulen, D.; Suetens, P. Minimal shape and intensity cost path segmentation. IEEE Trans. Med. Imaging 2007, 26, 1115–1129. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
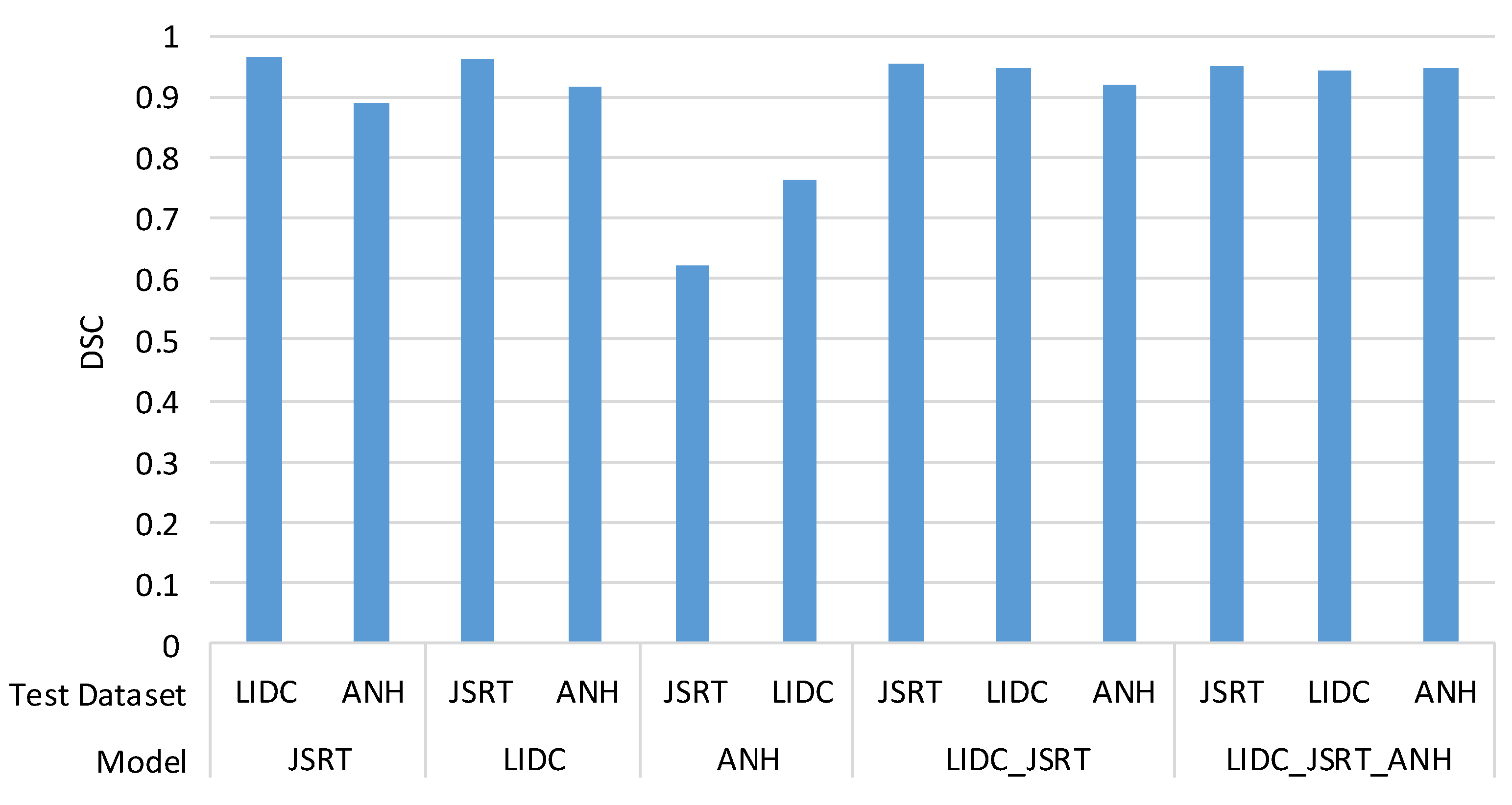{kind=link}
| Models | Training Data | Testing Data | Total |
|---|---|---|---|
| JSRT | 2370 | 594 | 2964 |
| LIDC | 1870 | 462 | 2332 |
| ANH | 836 | 208 | 1044 |
| LIDC_JSRT | 4240 | 1054 | 5294 |
| LIDC_JSRT_ANH | 5076 | 1262 | 6338 |
| Models | Lungs | USEQ Superpixel Interpolation | Bicubic Interpolation | ||||||
|---|---|---|---|---|---|---|---|---|---|
| DSC | Sensitivity | Specificity | MHD | DSC | Sensitivity | Specificity | MHD | ||
| JSRT | Left | 0.977 | 0.973 | 0.996 | 1.107 | 0.953 | 0.949 | 0.992 | 2.779 |
| Right | 0.978 | 0.975 | 0.999 | 1.002 | 0.96 | 0.958 | 0.992 | 4.201 | |
| LIDC | Left | 0.972 | 0.971 | 0.995 | 0.888 | 0.926 | 0.93 | 0.989 | 4.645 |
| Right | 0.972 | 0.97 | 0.994 | 1.718 | 0.938 | 0.934 | 0.989 | 6.72 | |
| ANH | Left | 0.97 | 0.979 | 0.999 | 1.942 | 0.953 | 0.936 | 0.994 | 4.428 |
| Right | 0.982 | 0.978 | 0.994 | 1.24 | 0.948 | 0.949 | 0.992 | 3.783 | |
| LIDC_JSRT | Left | 0.973 | 0.966 | 0.996 | 0.815 | 0.95 | 0.941 | 0.994 | 3.284 |
| Right | 0.979 | 0.978 | 0.995 | 1.448 | 0.948 | 0.941 | 0.991 | 3.755 | |
| LIDC_JSRT_ANH | Left | 0.964 | 0.967 | 0.994 | 1.736 | 0.947 | 0.962 | 0.991 | 2.962 |
| Right | 0.968 | 0.975 | 0.994 | 2.094 | 0.952 | 0.953 | 0.992 | 3.81 | |
| Average | 0.9735 | 0.9732 | 0.9956 | 1.399 | 0.9475 | 0.9453 | 0.9916 | 4.0367 | |
| Method | Ω (%) | DSC (%) | MBD (mm) | Time (s) |
|---|---|---|---|---|
| Proposed method | 95.5 ± 0.02 | 97.7 ± 0.01 | 0.542 ± 0.79 | CPU: 4.6 GPU:0.02 |
| SEDUCM [4] | 95.2 ± 1.8 | 97.5 ± 1.0 | 1.37 ± 0.67 | <0.1 |
| SIFT-Flow [43] | 95.4 ± 1.5 | 96.7 ± 0.8 | 1.32 ± 0.32 | 20∼25 |
| MISCP [44] | 95.1 ± 1.8 | / | 1.49 ± 0.66 | 13∼28 |
| Hybrid voting [12] | 94.9 ± 2.0 | / | 1.62 ± 0.66 | >34 |
| Local SSC [13] | 94.6 ± 1.9 | 97.2 ± 1.0 | 1.67 ± 0.76 | 35.2 |
| Human observer [12] | 94.6 ± 1.8 | / | 1.64 ± 0.69 | / |
| GTF [11] | 94.6 ± 2.2 | / | 1.59 ± 0.68 | 38 |
| InvertedNet [3] | 94.6 | 97.2 | 0.73 | 7.1 |
| PC post-processed [12] | 94.5 ± 2.2 | / | 1.61 ± 0.80 | 30 |
| ASM tuned [12] | 92.7 ± 3.2 | / | 2.30 ± 1.03 | 1 |
| ASM_SIFT [12] | 92.0 ± 3.1 | / | 2.49 ± 1.09 | 75 |
| AAM whiskers [12] | 91.3 ± 3.2 | / | 2.70 ± 1.10 | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, C.-C.; So, E.C.; Saidy, L.; Wang, M.-J. Lung Field Segmentation in Chest X-ray Images Using Superpixel Resizing and Encoder–Decoder Segmentation Networks. Bioengineering 2022, 9, 351. https://doi.org/10.3390/bioengineering9080351
Lee C-C, So EC, Saidy L, Wang M-J. Lung Field Segmentation in Chest X-ray Images Using Superpixel Resizing and Encoder–Decoder Segmentation Networks. Bioengineering. 2022; 9(8):351. https://doi.org/10.3390/bioengineering9080351
Chicago/Turabian StyleLee, Chien-Cheng, Edmund Cheung So, Lamin Saidy, and Min-Ju Wang. 2022. "Lung Field Segmentation in Chest X-ray Images Using Superpixel Resizing and Encoder–Decoder Segmentation Networks" Bioengineering 9, no. 8: 351. https://doi.org/10.3390/bioengineering9080351