
Comparison of Unsupervised Machine Learning Approaches for Cluster Analysis to Define Subgroups of Heart Failure with Preserved Ejection Fraction with Different Outcomes



Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Population
2.2. Machine Learning
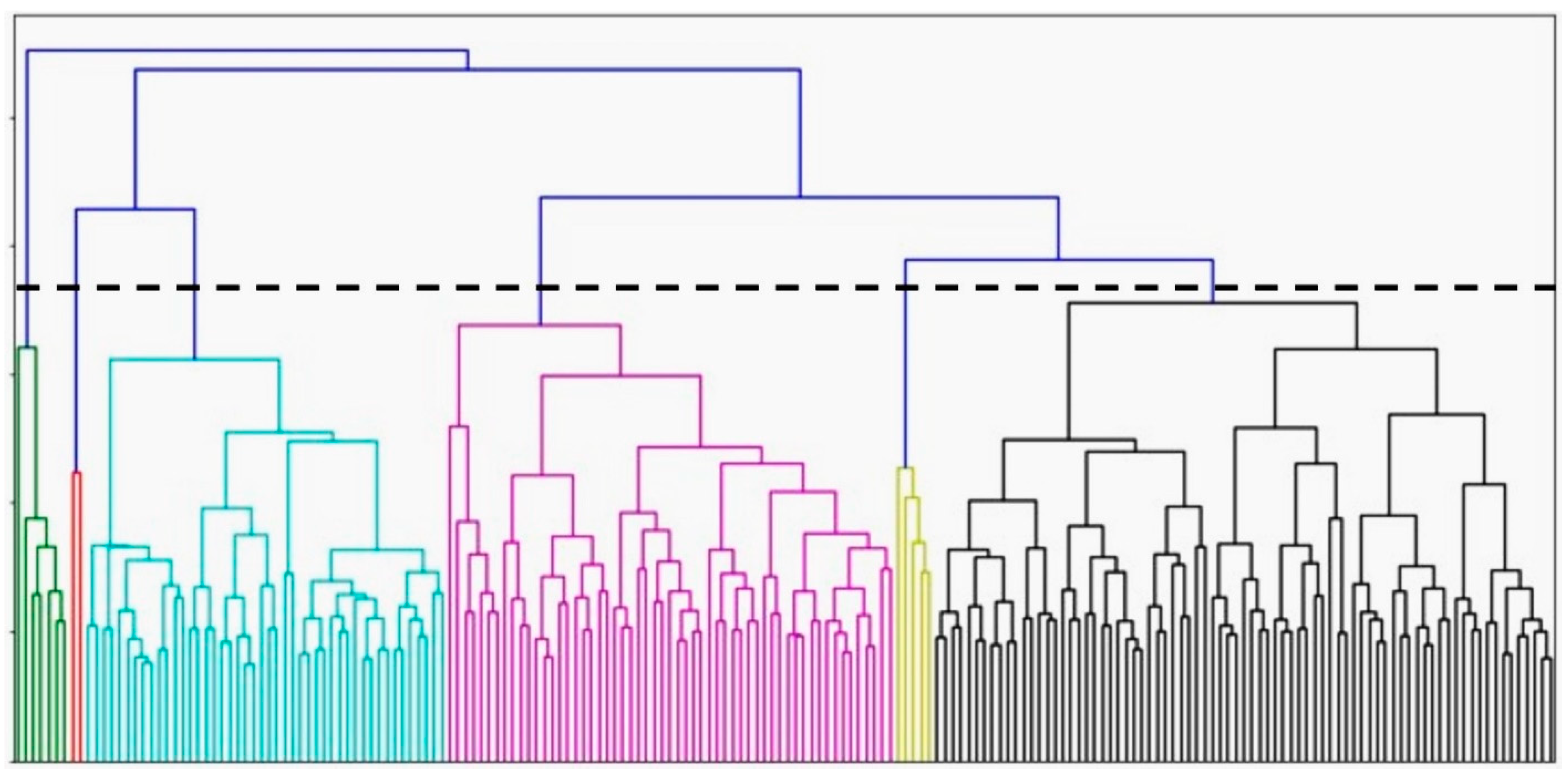
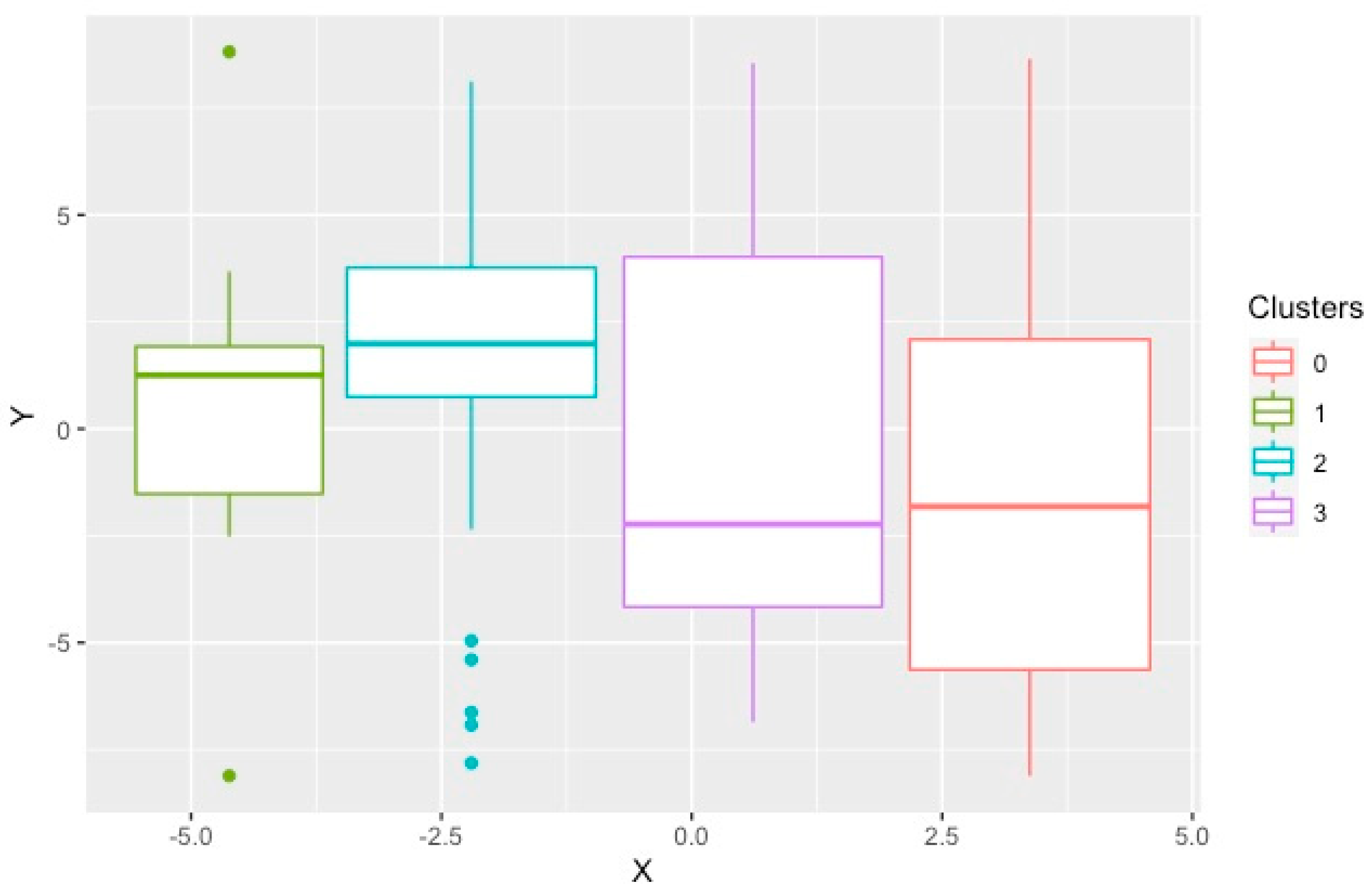
3. Results
4. Discussion
5. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Windgassen, S.; Moss-Morris, R.; Goldsmith, K.; Chalder, T. The importance of cluster analysis for enhancing clinical practice: An example from irritable bowel syndrome. J. Ment. Health 2018, 27, 94–96. [Google Scholar] [CrossRef] [PubMed]
- Magana-Serrano, J.A.; Almahmeed, W.; Gomez, E.; Al-Shamiri, M.; Adgar, D.; Sosner, P.; Herpin, D. Prevalence of heart failure with preserved ejection fraction in Latin American, middle eastern, and North African regions in the i PREFER study (identification of patients with heart failure and PREserved systolic function: An epidemiological regional stu. Am. J. Cardiol. 2011, 108, 1289–1296. [Google Scholar] [CrossRef] [PubMed]
- Reddy, Y.N.V.; Borlaug, B.A. Heart Failure With Preserved Ejection Fraction. Curr. Probl. Cardiol. 2016, 41, 145–188. [Google Scholar] [CrossRef] [PubMed]
- Warbrick, I.; Rabkin, S.W. Hypoxia-inducible factor 1-alpha (HIF-1α) as a factor mediating the relationship between obesity and heart failure with preserved ejection fraction. Obes. Rev. 2019, 20, 701–712. [Google Scholar] [CrossRef] [PubMed]
- Mishra, S.; Kass, D.A. Cellular and molecular pathobiology of heart failure with preserved ejection fraction. Nat. Rev. Cardiol. 2021, 18, 400–423. [Google Scholar] [CrossRef]
- Owan, T.E.; Hodge, D.O.; Herges, R.M.; Jacobsen, S.J.; Roger, V.L.; Redfield, M.M. Trends in prevalence and outcome of heart failure with preserved ejection fraction. N. Engl. J. Med. 2006, 355, 251–259. [Google Scholar] [CrossRef] [Green Version]
- Gustafsson, F.; Torp-Pedersen, C.; Brendorp, B.; Seibæk, M.; Burchardt, H.; Køber, L. Long-term survival in patients hospitalized with congestive heart failure: Relation to preserved and reduced left ventricular systolic function. Eur. Heart J. 2003, 24, 863–870. [Google Scholar] [CrossRef]
- Brouwers, F.P.; De Boer, R.A.; Van Der Harst, P.; Voors, A.A.; Gansevoort, R.T.; Bakker, S.J.; Hillege, H.L.; Van Veldhuisen, D.J.; Van Gilst, W.H. Incidence and epidemiology of new onset heart failure with preserved vs. reduced ejection fraction in a community-based cohort: 11-year follow-up of PREVEND. Eur. Heart J. 2013, 34, 1424–1431. [Google Scholar] [CrossRef]
- Shah, S.J. Precision Medicine for Heart Failure with Preserved Ejection Fraction: An Overview. J. Cardiovasc. Transl. Res. 2017, 10, 233–244. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar]
- Huang, Z. Extensions to the k-Means Algorithm for Clustering Large Data Sets with Categorical Values. Data Min. Knowl. Discov. 1998, 2, 283–304. [Google Scholar] [CrossRef]
- Mushtaq, H.; Khawaja, S.G.; Akram, M.U.; Yasin, A.; Muzammal, M.; Khalid, S.; Khan, S.A. A Parallel Architecture for the Partitioning Around Medoids (PAM) Algorithm for Scalable Multi-Core Processor Implementation with Applications in Healthcare. Sensors 2018, 18, 4129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, S.; Banerjee, A. Machine learning: A long way from implementation in cardiovascular disease. Heart 2020, 106, 318–320. [Google Scholar] [CrossRef] [PubMed]
- Nouraei, H.; Rabkin, S.W. A new approach to the clinical subclassification of heart failure with preserved ejection fraction. Int. J. Cardiol. 2021, 331, 138–143. [Google Scholar] [CrossRef] [PubMed]
- Ponikowski, P.; Voors, A.A.; Anker, S.D.; Bueno, H.; Cleland, J.G.F.; Coats, A.J.S.; Falk, V.; Gonzalez-Juanatey, J.R.; Harjola, V.-P.; Jankowska, E.A.; et al. 2016 ESC Guidelines for the Diagnosis and Treatment of Acute and Chronic Heart Failure. Rev. Esp. Cardiol. (Engl. Ed.) 2016, 69, 1167. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shah, S.J.; Katz, D.H.; Selvaraj, S.; Burke, M.A.; Yancy, C.W.; Gheorghiade, M.; Bonow, R.O.; Huang, C.-C.; Deo, R.C. Phenomapping for Novel Classification of Heart Failure With Preserved Ejection Fraction. Circulation 2015, 131, 269–279. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Segar, M.W.; Patel, K.V.; Ayers, C.; Basit, M.; Tang, W.H.W.; Willett, D.; Berry, J.; Grodin, J.L.; Pandey, A. Phenomapping of patients with heart failure with preserved ejection fraction using machine learning-based unsupervised cluster analysis. Eur. J. Heart Fail. 2020, 22, 148–158. [Google Scholar] [CrossRef] [PubMed]
- Lechevallier, Y.; Saporta, G. Keynote, Invited and Contributed Papers. In Proceedings of the COMPSTAT’2010 19th International Conference on Computational Statistics; Paris France, 22–27 August 2010; Physica: Berlin/Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Tavazoie, S.; Hughes, J.D.; Campbell, M.J.; Cho, R.J.; Church, G.M. Systematic determination of genetic network architecture. Nat. Genet. 1999, 22, 281–285. [Google Scholar] [CrossRef]
- Ichino, M. General metrics for mixed features-the cartesian space theory for pattern recognition. IEEE 1988, 1, 494–497. [Google Scholar]
- Moser, D.K.; Lee, K.S.; Wu, J.-R.; Mudd-Martin, G.; Jaarsma, T.; Huang, T.-Y.; Fan, X.-Z.; Strömberg, A.; Lennie, T.A.; Riegel, B. Identification of symptom clusters among patients with heart failure: An international observational study. Int. J. Nurs. Stud. 2014, 51, 1366–1372. [Google Scholar] [CrossRef] [Green Version]
- Budiaji, W.; Leisch, F. Simple K-medoids partitioning algorithm for mixed variable data. Algorithms 2019, 12, 177. [Google Scholar] [CrossRef] [Green Version]
- Kaufman, P. Rousseeuw, Finding Groups in Data. An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 1990. [Google Scholar]
- Kimes, P.K.; Liu, Y.; Neil Hayes, D.; Marron, J.S. Statistical significance for hierarchical clustering. Biometrics 2017, 73, 811–821. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Harada, D.; Asanoi, H.; Noto, T.; Takagawa, J. Different Pathophysiology and Outcomes of Heart Failure With Preserved Ejection Fraction Stratified by K-Means Clustering. Front. Cardiovasc. Med. 2020, 7, 607760. [Google Scholar] [CrossRef] [PubMed]
- Bose, E.; Radhakrishnan, K. Using Unsupervised Machine Learning to Identify Subgroups Among Home Health Patients With Heart Failure Using Telehealth. Comput. Inform. Nurs. 2018, 36, 242–248. [Google Scholar] [CrossRef] [PubMed]
- Preud’homme, G.; Duarte, K.; Dalleau, K.; Lacomblez, C.; Bresso, E.; Smail-Tabbone, M.; Couceiro, M.; Devignes, M.-D.; Kobayashi, M.; Huttin, O.; et al. Head-to-head comparison of clustering methods for heterogeneous data: A simulation-driven benchmark. Sci. Rep. 2021, 11, 4202. [Google Scholar] [CrossRef] [PubMed]
- Kao, D.P.; Lewsey, J.D.; Anand, I.S.; Massie, B.M.; Zile, M.R.; Carson, P.E.; McKelvie, R.S.; Komajda, M.; McMurray, J.J.V.; Lindenfeld, J. Characterization of subgroups of heart failure patients with preserved ejection fraction with possible implications for prognosis and treatment response. Eur. J. Heart Fail. 2015, 17, 925–935. [Google Scholar] [CrossRef] [Green Version]
- Hedman, Å.K.; Hage, C.; Sharma, A.; Brosnan, M.J.; Buckbinder, L.; Gan, L.-M.; Shah, S.J.; Linde, C.M.; Donal, E.; Daubert, J.-C.; et al. Identification of novel pheno-groups in heart failure with preserved ejection fraction using machine learning. Heart 2020, 106, 342–349. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Clusters | 1 | 2 | 3 | 4 | 5 | 6 | p-Value | |
|---|---|---|---|---|---|---|---|---|
| Number of subjects | 23 | 2 | 46 | 49 | 7 | 69 | ||
| Age (years) | 80 (72, 84) | 76 (75, 77) | 78 (70.5, 83) | 68 (59, 72) | 83 (68, 89) | 83 (71.5, 88) | <0.001 | |
| Male (%) | 13 | 0 | 57 | 73 | 86 | 23 | <0.001 | |
| Atrial fibrillation (%) | 17 | 0 | 24 | 14 | 43 | 35 | 0.100 | |
| Hypertension (%) | 65 | 100 | 83 | 73 | 86 | 68 | 0.410 | |
| Dyslipidemia (%) | 48 | 50 | 72 | 63 | 29 | 32 | <0.001 | |
| Diabetes (%) | 9 | 0 | 43 | 27 | 14 | 16 | 0.006 | |
| Coronary artery disease (%) | 17 | 50 | 57 | 43 | 29 | 26 | 0.007 | |
| Chronic kidney disease (%) | 4 | 0 | 22 | 12 | 29 | 26 | 0.153 | |
| Stroke or transient ischemic attack (%) | 0 | 50 | 7 | 4 | 14 | 14 | 0.046 | |
| Obstructive sleep apnea (%) | 0 | 0 | 13 | 8 | 14 | 6 | 0.447 | |
| Lung disease (%) | 17 | 0 | 13 | 4 | 0 | 6 | 0.260 | |
| Body mass index (kg/m2) | 23.1 (21, 26.6) | 30.6 (22, 39.1) | 25.9 (24.1, 28) | 28.1 (24, 32.7) | 38.5 (38, 38.5) | 24.6 (22.5, 28) | 0.004 | |
| Systolic blood pressure (mmHg) | 139 (129, 150) | 142.5 (140, 145) | 136.5 (123, 153) | 130 (120, 130) | 123 (101, 136) | 134 (120, 144) | 0.055 | |
| Low-density lipoprotein (mmol/L) | 2.4 (2, 3.4) | 2.7 (2, 3.3) | 1.6 (1.0, 2.2) | 2.0 (1.5, 2.7) | 2.2 (1.2, 2.5) | 2.1 (1.7, 2.8) | <0.001 | |
| Serum creatinine (mmol/L) | 69 (62, 96) | 81.5 (67, 96) | 94.5 (79, 119) | 90 (73,102) | 94 (91,155) | 87 (71, 133) | 0.012 | |
| HbA1c (%) | 5.8 (5.6, 6.1) | 9.1 (5.6, 12.6) | 6 (5.8, 6.7) | 6 (5.6, 6.7) | 5.8 (5.6, 6.4) | 5.8 (5.5, 6.2) | 0.111 | |
| Left ventricular ejection fraction (%) | 60 (56, 61) | 60 (55, 65) | 55 (51.8, 60) | 60 (53, 60) | 57 (55, 60) | 60 (55, 65) | <0.001 | |
| Right ventricle diameter (mm) | 30 (28, 33) | 37 (37, 37) | 35 (31.8, 38) | 34 (32, 38) | 38 (34, 43) | 36 (33.5,39) | <0.001 | |
| Left atrial volume index (mL/m2) | 35 (29, 40) | 30.5 (29, 32) | 39.5 (35, 47.3) | 33 (29, 37.5) | 53 (43, 55) | 47.4 (37.5, 55) | <0.001 | |
| Left ventricle end-diastolic diameter index (mm/m2) | 25 (22, 27) | 28.5 (23, 34) | 26 (23,28.6) | 24 (22, 26.3) | 22.5 (19, 25.2) | 28.1 (25, 30.8) | <0.001 | |
| Mitral valve E/A ratio | 0.7 (0.6, 0.8) | 0.8 (0.6, 1) | 1.1 (0.9, 1.2) | 0.9 (0.7, 1.3) | 3.7 (1.9, 4.8) | 1.2 (0.8, 1.7) | <0.001 | |
| Average E/e’ ratio | 12.8 (8.9, 15.6) | 10.3 (7.5, 13) | 15.1 (12, 17.5) | 8.8 (7.8, 11.5) | 21.6 (14.5, 27) | 16.7 (14, 19.5) | <0.001 | |
| Elevated filling pressure (%) | 21.7 | 0 | 80 | 26.5 | 100 | 91.3 | <0.001 | |
| Diastolic dysfunction (%) | Moderate | 8.7 | 0 | 71.7 | 24.5 | 57.1 | 72.5 | <0.001 |
| Severe | 0 | 0 | 4.3 | 0 | 42.9 | 11.6 | ||
| Meta-analysis Global Group in Chronic Heart Failure | 23.5 (18.8, 25) | 21.5 (21, 22) | 24 (18, 28) | 24 (15, 30) | 13 (13, 13) | 23 (18, 27.5) | 0.780 | |
| Heart failure exacerbation (%) | 17.4 | 0 | 28.3 | 8.1 | 85.7 | 46.4 | <0.001 | |
| Cardiovascular mortality (%) | 8.7 | 0 | 2.2 | 2 | 57.1 | 7.2 | <0.001 | |
| All-cause mortality (%) | 8.7 | 0 | 10.9 | 4.1 | 71.4 | 21.7 | <0.001 | |
| Composite endpoints (%) | 17.4 | 0 | 32.6 | 12.2 | 85.7 | 52.2 | <0.001 | |
| Clusters | 1 | 2 | 3 | 4 | p-Value | |
|---|---|---|---|---|---|---|
| Number of subjects | 61 | 9 | 53 | 73 | ||
| Age (years) | 80 (70.5, 87) | 83 (72, 89.5) | 84 (80, 87.5) | 69 (61, 74.5) | <0.001 | |
| Male (%) | 48 | 78 | 13 | 60 | <0.001 | |
| Atrial fibrillation (%) | 36 | 33 | 25 | 15 | 0.043 | |
| Hypertension (%) | 67 | 78 | 77 | 75 | 0.603 | |
| Dyslipidemia (%) | 56 | 33 | 38 | 59 | 0.065 | |
| Diabetes (%) | 33 | 11 | 17 | 23 | 0.183 | |
| Coronary artery disease (%) | 44 | 22 | 34 | 34 | 0.445 | |
| Chronic kidney disease (%) | 25 | 33 | 25 | 8 | 0.029 | |
| Stroke or transient ischemic attack (%) | 11 | 22 | 8 | 5 | 0.294 | |
| Lung disease (%) | 7 | 11 | 9 | 8 | 0.934 | |
| Obstructive sleep apnea (%) | 10 | 11 | 2 | 10 | 0.328 | |
| Body mass index (kg/m2) | 26.6 (24.1, 31.5) | 38.5 (28.5, 38.5) | 23.1 (21.2, 25) | 27.3 (24.1, 32.4) | <0.001 | |
| Systolic blood pressure (mmHg) | 137 (121.5, 150) | 115 (97, 134) | 135 (123, 144) | 132 (121, 144) | 0.022 | |
| Low-density lipoprotein (mmol/L) | 1.8 (1.2, 2.4) | 2.1 (1.3, 2.4) | 2.1 (1.6, 2.8) | 2.2 (1.6, 2.9) | <0.034 | |
| Serum creatinine (mmol/L) | 90 (78, 122.5) | 94 (82, 147) | 89 (68, 115) | 88 (71, 98.5) | 0.119 | |
| HbA1c (%) | 5.9 (5.6, 6.4) | 5.8 (5.4, 6.2) | 5.8 (5.6, 6.2) | 5.9 (5.6, 6.7) | 0.651 | |
| B-type natriuretic peptide (pg/mL) | 282 (111, 769) | 817 (514, 1276) | 128 (65, 515) | 78 (25, 175) | <0.001 | |
| Meta-analysis Global Group in Chronic Heart Failure | 23 (18, 27.8) | 13 (13, 13) | 24 (22, 29.5) | 19 (12.3, 22) | <0.001 | |
| Left ventricular ejection fraction (%) | 55 (53, 60) | 57 (55, 60) | 60 (60, 65) | 60 (55, 60) | <0.001 | |
Mild to Moderate mitral regurgitation (%) | 76 | 89 | 85 | 53 | <0.001 | |
| Mild to Moderate aortic stenosis (%) | 14 | 11 | 22 | 8 | 0.089 | |
| Mild to Moderate aortic regurgitation (%) | 22 | 44 | 57 | 11 | <0.001 | |
| Mild to Moderate tricuspid regurgitation (%) | 68 | 89 | 84 | 47 | <0.001 | |
| Right ventricle diameter (mm) | 36 (34, 40) | 38 (34, 43) | 34 (29, 37) | 34 (30, 37) | <0.001 | |
| Left atrial volume index (mL/m2) | 44 (36, 54) | 53 (43, 56) | 40 (35, 50) | 33 (29, 39) | <0.001 | |
| Left ventricle end-diastolic diameter index (mm/m2) | 27 (24, 29) | 22.5 (19, 24.5) | 28 (25, 30) | 25 (22.5, 28) | <0.001 | |
| Mitral valve E/A ratio | 1.2 (1, 1.9) | 2.1 (1.7, 4.5) | 0.8 (0.67, 1.1) | 0.9 (0.7, 1.2) | <0.001 | |
| Average E/e’ ratio | 15.8 (14.3, 19.6) | 21.6 (15, 25.2) | 16.7 (14, 19.3) | 9.3 (7.9, 11.4) | <0.001 | |
| Pulmonary artery pressure (mmHg) | 34 (27, 40) | 48 (33, 49) | 31 (24, 36) | 26 (23, 29) | <0.001 | |
| Elevated filling pressure (%) | 98 | 100 | 74 | 23 | <0.001 | |
| Diastolic dysfunction | Moderate | 80 | 67 | 60 | 19 | <0.001 |
| Severe | 15 | 33 | 0 | 1 | ||
| Heart failure exacerbation (%) | 41 | 89 | 34 | 11 | <0.001 | |
| Cardiovascular mortality (%) | 5 | 67 | 4 | 3 | <0.001 | |
| All-cause mortality (%) | 21 | 78 | 9 | 5 | <0.001 | |
| Composite endpoint (%) | 48 | 89 | 38 | 14 | <0.001 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nouraei, H.; Nouraei, H.; Rabkin, S.W. Comparison of Unsupervised Machine Learning Approaches for Cluster Analysis to Define Subgroups of Heart Failure with Preserved Ejection Fraction with Different Outcomes. Bioengineering 2022, 9, 175. https://doi.org/10.3390/bioengineering9040175
Nouraei H, Nouraei H, Rabkin SW. Comparison of Unsupervised Machine Learning Approaches for Cluster Analysis to Define Subgroups of Heart Failure with Preserved Ejection Fraction with Different Outcomes. Bioengineering. 2022; 9(4):175. https://doi.org/10.3390/bioengineering9040175
Chicago/Turabian StyleNouraei, Hirmand, Hooman Nouraei, and Simon W. Rabkin. 2022. "Comparison of Unsupervised Machine Learning Approaches for Cluster Analysis to Define Subgroups of Heart Failure with Preserved Ejection Fraction with Different Outcomes" Bioengineering 9, no. 4: 175. https://doi.org/10.3390/bioengineering9040175