
Supervised Analysis for Phenotype Identification: The Case of Heart Failure Ejection Fraction Class

 ,
,  , and
, and
Abstract
:1. Introduction
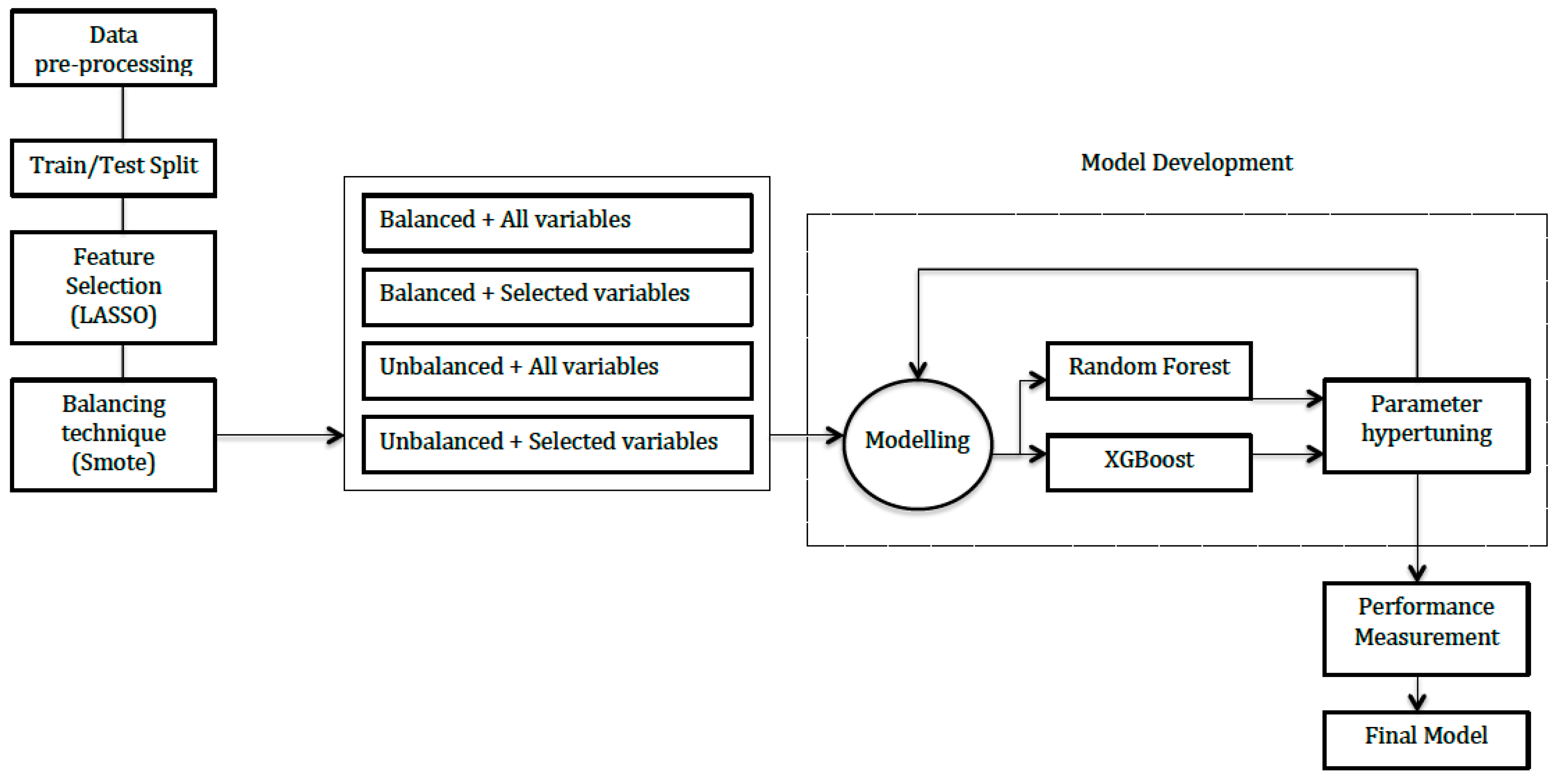
2. Materials and Methods
2.1. Data Source and Study Population
2.2. Selection of Variables and Analytical Procedure
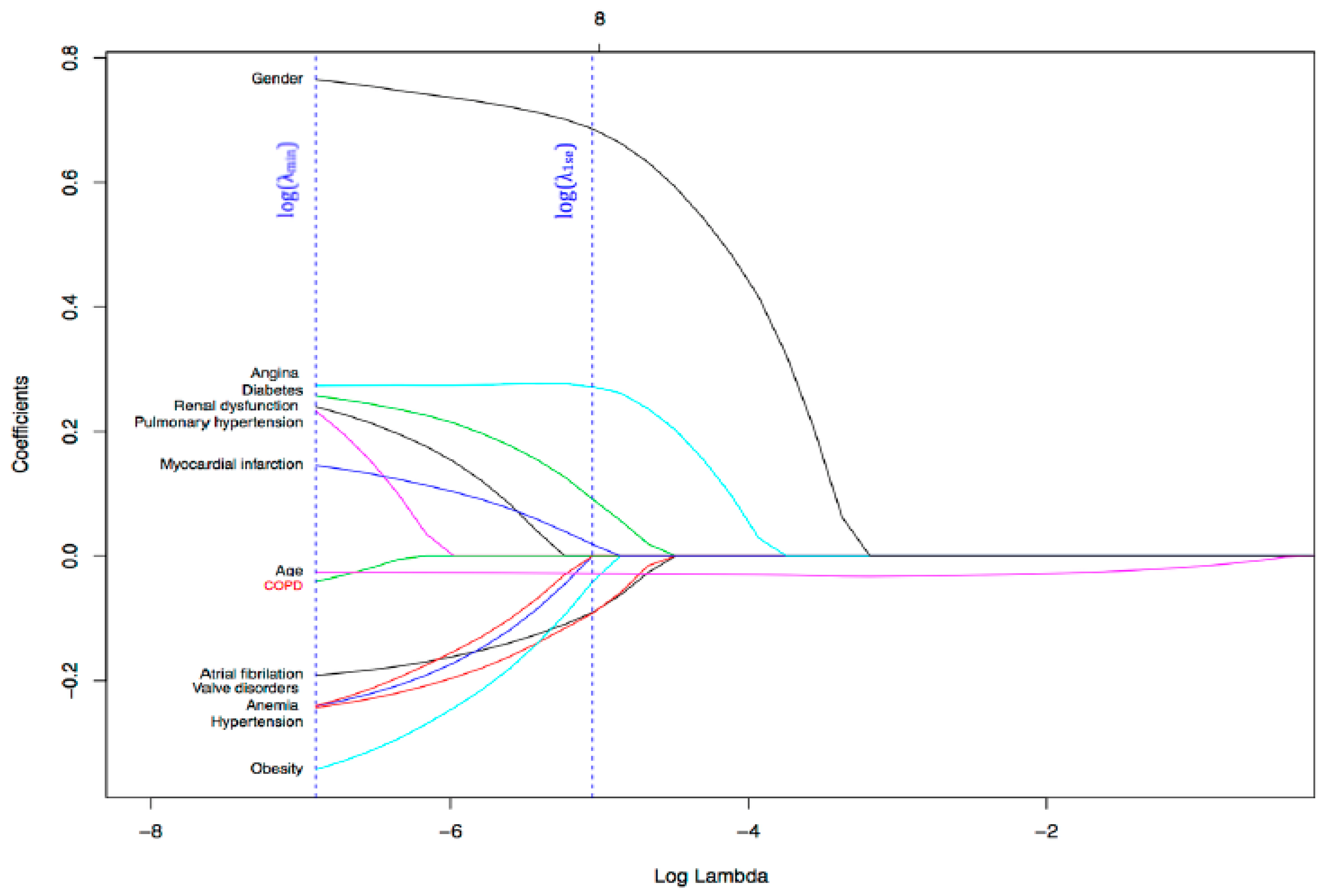
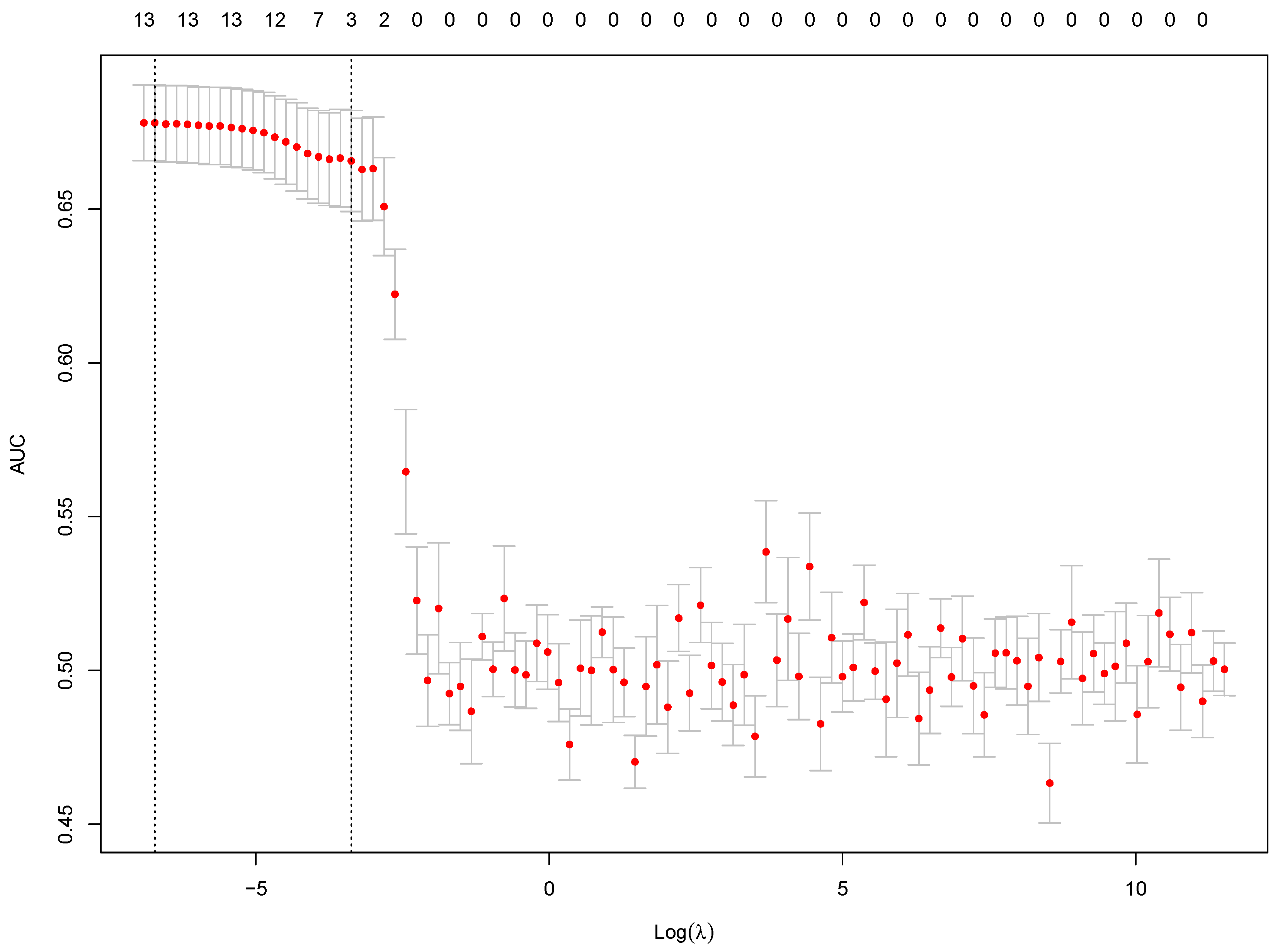
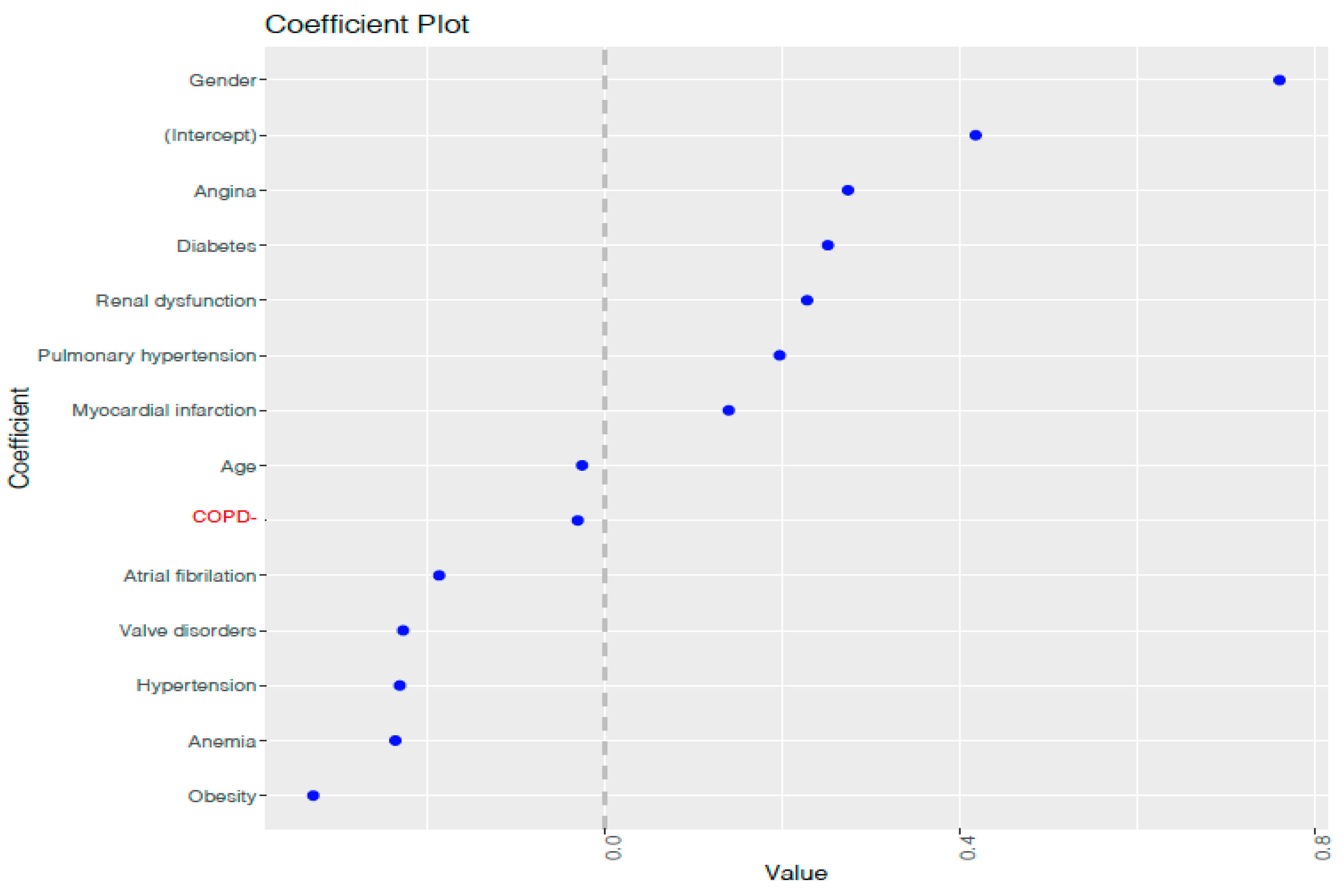
2.3. Feature Selection
2.4. Imbalanced Data Distribution
2.5. Model Development
2.6. Tools Used for Preparing and Running the Models
- Database partition caret package;
- Balancing the dataset DMwR package;
- LASSO implemented using glmnet package;
- Train with Random Forest and XGBoost packages;
- Plots ggplot2;
- Performance metrics Caret, ROCR & PRROC packages.
2.7. Performance Measurements
3. Results
3.1. Characteristics of the Study Population
3.2. Models Developed
3.3. Models Performance
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Silkoff, P.E.; Moore, W.C.; Sterk, P.J. Three Major Efforts to Phenotype Asthma: Severe Asthma Research Program, Asthma Disease Endotyping for Personalized Therapeutics, and Unbiased Biomarkers for the Prediction of Respiratory Disease Outcome. Clin. Chest Med. 2019, 40, 13–28. [Google Scholar] [CrossRef] [PubMed]
- Redfield, M.M. Heart Failure with Preserved Ejection Fraction. N. Engl. J. Med. 2016, 375, 1868–1877. [Google Scholar] [CrossRef] [Green Version]
- McMurray, J.J. Clinical practice. Systolic heart failure. N. Engl. J. Med. 2010, 362, 228–238. [Google Scholar] [CrossRef] [PubMed]
- Yancy, C.W.; Jessup, M.; Bozkurt, B.; Butler, J.; Casey, D.E., Jr.; Drazner, M.H.; Fonarow, G.C.; Geraci, S.A.; Horwich, T.; Januzzi, J.L.; et al. American College of Cardiology Foundation/American Heart Association Task Force on Practice Guidelines. 2013 ACCF/AHA guideline for the management of heart failure: A report of the American College of Cardiology Foundation/American Heart Association Task Force on practice guidelines. Circulation 2013, 128, e240–e327. [Google Scholar] [PubMed]
- Jessup, M.; Marwick, T.H.; Ponikowski, P.; Voors, A.A.; Yancy, C.W. 2016 ESC and ACC/AHA/HFSA heart failure guideline update—What is new and why is it important? Nat. Rev. Cardiol. 2016, 13, 623–628. [Google Scholar] [CrossRef] [PubMed]
- CVD Statistics. Available online: http://www.ehnheart.org/cvd-statistics.html. (accessed on 30 March 2020).
- Orange, D.E.; Agius, P.; DiCarlo, E.F.; Robine, N.; Geiger, H.; Szymonifka, J.; McNamara, M.; Cummings, R.; Andersen, K.M.; Mirza, S.; et al. Identification of Three Rheumatoid Arthritis Disease Subtypes by Machine Learning Integration of Synovial Histologic Features and RNA Sequencing Data. Arthritis Rheumatol. 2018, 70, 690–701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, S.; Zha, Y.; Li, W.; Wu, Q.; Li, X.; Niu, M.; Wang, M.; Qiu, X.; Li, H.; Yu, H.; et al. A fully automatic deep learning system for COVID-19 diagnostic and prognostic analysis. Eur. Respir. J. 2020, 56, 2000775. [Google Scholar] [CrossRef] [PubMed]
- Giger, M.L. Machine Learning in Medical Imaging. J. Am. Coll. Radiol. 2018, 15 Pt B, 512–520. [Google Scholar] [CrossRef] [PubMed]
- Deo, R.C. Machine Learning in Medicine. Circulation 2015, 132, 1920–1930. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahmad, T.; Pencina, M.J.; Schulte, P.J.; O’Brien, E.; Whellan, D.J.; Piña, I.L.; Kitzman, D.W.; Lee, K.L.; O’Connor, C.M.; Felker, G.M. Clinical implications of chronic heart failure phenotypes defined by cluster analysis. J. Am. Coll. Cardiol. 2014, 64, 1765–1774. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shah, S.J.; Katz, D.H.; Selvaraj, S.; Burke, M.A.; Yancy, C.W.; Gheorghiade, M.; Bonow, R.O.; Huang, C.C.; Deo, R.C. Phenomapping for novel classification of heart failure with preserved ejection fraction. Circulation 2015, 131, 269–279. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Supervised vs. Unsupervised Learning—Towards Data Science. Available online: https://towardsdatascience.com/supervised-vs-unsupervised-learning-14f68e32ea8d (accessed on 30 March 2020).
- Witten, D.M.; Tibshirani, R. A framework for feature selection in clustering. J. Am. Stat. Assoc. 2010, 105, 713–726. [Google Scholar] [CrossRef] [Green Version]
- (Tutorial) Regularization: Ridge, Lasso and Elastic Net—DataCamp. Available online: https://www.datacamp.com/community/tutorials/tutorial-ridge-lasso-elastic-net (accessed on 30 March 2020).
- Khoshgoftaar, T.M.; Van Hulse, J.; Napolitano, A. Supervised neural network modeling: An empirical investigation into learning from imbalanced data with labeling errors. IEEE Trans. Neural Netw. 2010, 21, 813–830. [Google Scholar] [CrossRef] [PubMed]
- Koivu, A.; Sairanen, M.; Airola, A.; Pahikkala, T. Synthetic minority oversampling of vital statistics data with generative adversarial networks. J. Am. Med. Inform. Assoc. 2020, 27, 1667–1674. [Google Scholar] [CrossRef] [PubMed]
- XGBoost Algorithm: Long May She Reign!—Towards Data Science. Available online: https://towardsdatascience.com/https-medium-com-vishalmorde-xgboost-algorithm-long-she-may-rein-edd9f99be63d (accessed on 30 March 2020).
- Zhou, M.; Chen, Y.; Xu, R. A Drug-Side Effect Context-Sensitive Network approach for drug target prediction. Bioinformatics 2019, 35, 2100–2107. [Google Scholar] [CrossRef] [PubMed]
- XGBoost, a Top Machine Learning Method on Kaggle, Explained. Available online: https://www.kdnuggets.com/2017/10/xgboost-top-machine-learning-method-kaggle-explained.html (accessed on 30 March 2020).
- Bovitz, T.; Gilbertson, D.T.; Herzog, C.A. Administrative Data and the Philosopher’s Stone: Turning Heart Failure Claims Data into Quantitative Assessment of Left Ventricular Ejection Fraction. Am. J. Med. 2016, 129, 223–225. [Google Scholar] [CrossRef] [PubMed]
- Desai, R.J.; Lin, K.J.; Patorno, E.; Barberio, J.; Lee, M.; Levin, R.; Evers, T.; Wang, S.V.; Schneeweiss, S. Development and Preliminary Validation of a Medicare Claims-Based Model to Predict Left Ventricular Ejection Fraction Class in Patients with Heart Failure. Circ. Cardiovasc. Qual. Outcomes 2018, 11, e004700. [Google Scholar] [CrossRef] [PubMed]
- Lee, M.P.; Glynn, R.J.; Schneeweiss, S.; Lin, K.J.; Patorno, E.; Barberio, J.; Levin, R.; Evers, T.; Wang, S.V.; Desai, R.J. Risk Factors for Heart Failure with Preserved or Reduced Ejection Fraction Among Medicare Beneficiaries: Application of Competing Risks Analysis and Gradient Boosted Model. Clin. Epidemiol. 2020, 12, 607–616. [Google Scholar] [CrossRef] [PubMed]
- Uijl, A.; Lund, L.H.; Vaartjes, I.; Brugts, J.J.; Linssen, G.C.; Asselbergs, F.W.; Hoes, A.W.; Dahlström, U.; Koudstaal, S.; Savarese, G. A registry-based algorithm to predict ejection fraction in patients with heart failure. ESC Heart Fail. 2020, 7, 2388–2397. [Google Scholar] [CrossRef] [PubMed]
- Ponikowski, P.; Voors, A.A.; Anker, S.D.; Bueno, H.; Cleland, J.G.F.; Coats, A.J.S.; Falk, V.; González-Juanatey, J.R.; Harjola, V.P.; Jankowska, E.A.; et al. ESC Scientific Document Group. 2016 ESC Guidelines for the diagnosis and treatment of acute and chronic heart failure: The Task Force for the diagnosis and treatment of acute and chronic heart failure of the European Society of Cardiology (ESC)Developed with the special contribution of the Heart Failure Association (HFA) of the ESC. Eur. Heart J. 2016, 37, 2129–2200. [Google Scholar] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Training Dataset | Test Dataset | ||||
| HFrEF | HFpEF | Total | HFrEF | HFpEF | Total | |
| n = 535 | n = 1749 | n = 2284 | n = 133 | n = 437 | n = 570 | |
| Demographics | ||||||
| Male | 386 (72.15) | 832 (47.57) | 1218 (53.33) | 92 (69.17) | 203 (46.45) | 295 (51.75) |
| Age, mean (SD) | 71.85 (11.14) | 75.8 (9.89) | 74.88 (10.33) | 69.92 (10.62) | 75.6 (9.8) | 74.27 (10.27) |
| Comorbidities | ||||||
| Atrial fibrillation | 197 (36.82) | 776 (44.37) | 973 (42.6) | 32 (24.06) | 225 (51.49) | 257 (45.09) |
| Anemia | 171 (31.96) | 745 (42.6) | 916 (40.11) | 45 (33.83) | 199 (45.54) | 244 (42.81) |
| Diabetes | 317 (59.25) | 911 (52.09) | 1228 (53.77) | 71 (53.38) | 224 (51.26) | 295 (51.75) |
| Hypertension | 418 (78.13) | 1470 (84.05) | 1888 (82.66) | 93 (69.92) | 368 (84.21) | 461 (80.88) |
| Obesity | 49 (9.16) | 226 (12.92) | 275 (12.04) | 11 (8.27) | 72 (16.48) | 83 (14.56) |
| Pulmonary HTN | 26 (4.86) | 71 (4.06) | 97 (4.25) | 3 (2.26) | 22 (5.03) | 25 (4.39) |
| CKD | 88 (16.45) | 245 (14.01) | 333 (14.58) | 12 (9.02) | 69 (15.79) | 81 (14.21) |
| Valve disorders | 66 (12.34) | 317 (18.12) | 383 (16.77) | 9 (6.77) | 69 (15.79) | 78 (13.68) |
| COPD | 147 (27.48) | 451 (25.79) | 598 (26.18) | 34 (25.56) | 84 (19.22) | 118 (20.7) |
| Myocardial infarction | 149 (27.85) | 311 (17.78) | 460 (20.14) | 42 (31.58) | 75 (17.16) | 117 (20.53) |
| Angina | 239 (44.67) | 560 (32.02) | 799 (34.98) | 61 (45.86) | 146 (33.41) | 207 (36.32) |
| n (%) | Original | Balance 1 | Balance 2 |
|---|---|---|---|
| Total size | 2284 | 2140 | 3745 |
| HFpEF class | 1749 (76.58) | 1070 (50) | 2140 (42.86) |
| HFrEF class | 535 (23.42) | 1070 (50) | 1605 (57.14) |
| AUC | AUCpr | Accuracy | Sensitivity | Specificity | PPV | NPV | HFrEF Class (%) * | ||
|---|---|---|---|---|---|---|---|---|---|
| XGBoost | Full models | ||||||||
| Original | 0.70 | 0.45 | 0.80 | 0.53 | 0.88 | 0.57 | 0.86 | 24.11 | |
| Smote 50-50 | 0.69 | 0.38 | 0.70 | 0.69 | 0.70 | 0.41 | 0.88 | 26.05 | |
| Smote balanced | 0.65 | 0.35 | 0.72 | 0.53 | 0.77 | 0.41 | 0.84 | 21.63 | |
| Reduced models | |||||||||
| Original | 0.70 | 0.46 | 0.81 | 0.49 | 0.90 | 0.60 | 0.85 | 17.47 | |
| Smote 50-50 | 0.68 | 0.38 | 0.72 | 0.61 | 0.76 | 0.44 | 0.86 | 25.05 | |
| Smote balanced | 0.66 | 0.36 | 0.71 | 0.53 | 0.76 | 0.40 | 0.84 | 19.04 | |
| RF | Full models | ||||||||
| Original | 0.70 | 0.51 | 0.83 | 0.46 | 0.95 | 0.72 | 0.85 | 4.23 | |
| Smote 50-50 | 0.69 | 0.38 | 0.73 | 0.65 | 0.75 | 0.44 | 0.88 | 16.57 | |
| Smote balanced | 0.72 | 0.44 | 0.77 | 0.62 | 0.82 | 0.51 | 0.88 | 15.42 | |
| Reduced models | |||||||||
| Original | 0.70 | 0.51 | 0.84 | 0.46 | 0.95 | 0.75 | 0.85 | 3.8 | |
| Smote 50-50 | 0.70 | 0.38 | 0.73 | 0.65 | 0.75 | 0.44 | 0.88 | 14.38 | |
| Smote balanced | 0.72 | 0.44 | 0.78 | 0.62 | 0.83 | 0.52 | 0.88 | 12.55 | |
| Variables | All Subjects (n = 79,057) | Primary Care (n = 26,376) |
|---|---|---|
| Demographics | ||
| Male | 36,539 (46.22) | 10,082 (38.22) |
| Age, mean (SD) | 77.75 (11.35) | 80.88 (10.36) |
| Comorbidities | ||
| Atrial fibrillation | 31,277 (39.56) | 6571 (24.91) |
| Anemia | 30,132 (38.11) | 9197 (34.87) |
| Diabetes | 31,607 (39.98) | 9998 (37.91) |
| Hypertension | 66,181 (83.71) | 21,048 (79.8) |
| Obesity | 17,599 (22.26) | 3757 (14.24) |
| Pulmonary HTN | 842 (1.07) | 260 (0.99) |
| CKD | 15,469 (19.57) | 2018 (7.65) |
| Valve disorders | 13,061 (16.52) | 1016 (3.85) |
| COPD | 20,569 (26.02) | 6647 (25.2) |
| Myocardial infarction | 13,243 (16.75) | 2038 (7.73) |
| Angina | 24,655 (31.19) | 4727 (17.92) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lopez, C.; Holgado, J.L.; Cortes, R.; Sauri, I.; Fernandez, A.; Calderon, J.M.; Nuñez, J.; Redon, J. Supervised Analysis for Phenotype Identification: The Case of Heart Failure Ejection Fraction Class. Bioengineering 2021, 8, 85. https://doi.org/10.3390/bioengineering8060085
Lopez C, Holgado JL, Cortes R, Sauri I, Fernandez A, Calderon JM, Nuñez J, Redon J. Supervised Analysis for Phenotype Identification: The Case of Heart Failure Ejection Fraction Class. Bioengineering. 2021; 8(6):85. https://doi.org/10.3390/bioengineering8060085
Chicago/Turabian StyleLopez, Cristina, Jose Luis Holgado, Raquel Cortes, Inma Sauri, Antonio Fernandez, Jose Miguel Calderon, Julio Nuñez, and Josep Redon. 2021. "Supervised Analysis for Phenotype Identification: The Case of Heart Failure Ejection Fraction Class" Bioengineering 8, no. 6: 85. https://doi.org/10.3390/bioengineering8060085