1. Introduction
Magnetic resonance imaging (MRI) is a medical imaging modality that has seen widespread clinical adoption due to its superior soft tissue contrast and use of non-ionizing radiation. In particular, multi-coil (parallel) MRI acquisition combined with sub-sampling represents a means of reducing scan time and increasing scanner throughput [
1,
2,
3]. Given that sampling below the Nyquist rate gives rise to an ill-posed inverse problem, and hence can produce artifacts in reconstructed images, a wide area of research has been dedicated to image reconstruction algorithms for accelerated MRI. Recently, deep learning has achieved substantial improvements in reconstruction quality compared to classical methods [
4,
5,
6], and is rapidly heading toward clinical validation [
7].
One particular challenge that data-driven MRI reconstruction methods face is the availability of large datasets containing raw signal measurements (called k-space) acquired at a specific data site (client) in a multi-clinic setting. As independent institutions are often equipped with MRI scanners supplied by different vendors, together with different clinical needs in terms of patient population and institutional scanning protocols, this leads to a data heterogeneity problem, where a particular site may have both disparate and insufficient data to train a high-fidelity model. This has motivated researchers to investigate the transfer capabilities of deep learning for MRI reconstruction [
8] and led to the use of federated learning [
9]—a collaborative learning technique which leverages decentralized training—for medical image reconstruction in a cross-silo setting. Given data scarcity issues, together with regulatory and privacy constraints that prevent raw data from being shared between institutions [
10], federated learning is a promising tool for achieving robust generalization. Finally, models learned using federated learning have the potential to be further personalized [
11,
12], where models are adapted at the client side after learning has concluded in order to improve performance on the local sample distributions. One such application is for sites that may only be capable of acquiring and processing a limited number of fully sampled scans (e.g., due to specialized system hardware or limited resources) to also benefit from the learned model without having participated during training in the first place.
End-to-end unrolled optimization methods [
13] are considered state of the art for under-sampled MRI reconstruction [
8], and are the focus of this work. We investigate established adaptive federated learning algorithms applied to 2D (per slice) MRI reconstruction with end-to-end unrolled optimization. In the main federated learning stage, an adaptive optimization algorithm is used to learn an MRI reconstruction model without sharing data or features between clients. Subsequently, in the personalization stage, a client uses the small number of available fully sampled MRI scans (as few as 50 2D slices) to fine tune the global model on the target distribution using cross-validation early stopping. We perform experiments using subsets from the fastMRI [
14] knee and brain datasets, as well as publicly available axial knee and abdominal datasets [
15], and demonstrate that adaptive federated learning algorithms can efficiently learn reconstruction models across a wide range of anatomies, contrasts, and communication rates, and are also amenable to personalization via simple fine tuning.
1.1. Background
1.1.1. Federated Learning for MRI Reconstruction
Federated learning [
16] has recently gained substantial research interest in the broader machine learning field [
17] due to its ability to learn models in a distributed and privacy-oriented manner. A baseline federated optimization algorithm is given by federated averaging (FedAvg) [
16], where individual clients periodically upload their model weights to a central server, which performs simple averaging of the client-sided model weights. Powerful, FedAvg performance is known to degrade when data across clients are heterogeneous. The work in [
18] introduces the Scaffold algorithm as a solution to learning shared representations for heterogeneous data by including an adaptive momentum term at each communication round. Similarly, the work in [
19] proposes a family of adaptive optimization algorithms (termed FedAdam, FedAdaGrad, and FedYogi after their classical counterparts) for federated learning. In this work, we investigate the performance of these adaptive algorithms when applied to unrolled MRI reconstruction with deep networks.
Federated learning has recently been applied to medical imaging in the context of a synchronous, cross-silo setting, and is foreseen to have an impact on the future of digital health [
10]. Important challenges when dealing with medical image data are given by data heterogeneity [
20,
21], as well as the sensitive nature of raw patient data [
22]. When applied to MRI reconstruction, the FL-MRCM algorithm [
9] proposes an adversarial feature learning approach for handling the heterogeneous nature of the data. In this method, one of the clients is designated as an explicit target, and the feature representations of all other clients are optimized to be indistinguishable from that of the target. The recent work in [
23] used generative adversarial networks (GANs) to build on the FedGAN approach [
24] and proposed learning a deep generative prior using federated learning that is further personalized for each individual scan during test time. However, it is an open question if adversarial learning approaches are suitable for scenarios with very limited training data at client sites. The work in [
25] proposed a model splitting approach inspired by the layer personalization method in [
26] but this is only suitable for non-unrolled architectures, such as U-Net [
27]. The work in [
28] discussed strategies for splitting unrolled reconstruction models in centralized multi-task settings, but leaves as future work to investigate these in conjunction with federated learning and heterogeneous clients.
Client-sided personalization using fine tuning was previously introduced in [
29], where the authors investigated the efficiency of this approach on language tasks. The work in [
30] introduced a framework based on knowledge distillation to personalize the models in the final communication round in computation-bound settings. More recently, the work in [
31] provided theoretical justification for fine tuning in the context of linear models and the FedAvg algorithm. Inspired by this line of work, we also investigate the performance of fine tuning as a simple and efficient method of personalizing MRI reconstruction models.
1.1.2. Unrolled Optimization for MRI Reconstruction
Model-based unrolled optimization architectures represent a large area of research in ill-posed inverse problems [
13,
32], including medical imaging. The work in [
4] introduced the variational network (VarNet) approach, where differentiable optimization steps are interleaved with a forward pass of a deep neural network, and the entire architecture is trained end-to-end using a supervised reconstruction objective. A similar method was given by the model-based deep learning (MoDL) approach [
33], with differences in the type of unrolled optimization used. Extensions of these methods have been proposed to include automatic sensitivity map estimation [
34,
35,
36], dual domain (image and k-space) formulations [
37,
38], and self-supervised settings [
39].
While these works have greatly advanced MRI reconstruction benchmarks [
8], there are still open questions regarding how they scale in a federated learning regime with few local samples, as well as the best approach for handling domain shift [
21]. Our work aims to address the current research gap that exists at the intersection of federated learning and unrolled end-to-end optimization for MRI reconstruction. We focus on the baseline MoDL approach introduced in [
33], and investigate its performance in a federated setting, under different optimization algorithms and communication rates. We consider a multi-coil learning setup using realistic k-space measurements. This is in contrast to other works, where some of the measurements are simulated from coil-combined images. While the latter allows for simple implementations of deep learning methods, the results may not directly translate to a clinical settings [
40]. We investigate reconstruction performance in federated learning regimes with a small number of samples (slices) available for local training or personalization (as low as 50). Previous work in federated MRI reconstruction only considered up to four clients during learning [
9,
23], each having access to at least hundreds of training samples. While this is a valid setup for cross-silo federated learning, acquiring large amounts of data in under-resourced clinics may be untenable. In addition, previous work has shown that this data regime may already be sufficient to train unrolled models for MRI [
41], which we confirm in our experiments.
1.2. Contributions
A summary of our contributions in this work is the following:
We perform extensive experimental evaluations to determine the low data regime of federated learning end-to-end unrolled MRI reconstruction. This is the regime where each client has an insufficient number of samples to accommodate local (non-collaborative) learning, enabling federated learning to benefit every participant. We find that, across a wide range of anatomies and contrasts, this regime consistently occurs when fewer than 50 slices (across five patients) are available at each site.
We evaluate non-adaptive and adaptive federated learning algorithms (FedAvg, FedAdam, FedAdagrad, FedYogi, and Scaffold) applied to unrolled MRI reconstruction in the low data regime. We investigate both independent and identically distributed (i.i.d.) and non-i.i.d. client settings, as well as their performance as a function of the frequency of communication in a setting with fixed total computational power. Our findings indicate that federated unrolled optimization for MRI reconstruction is feasible with as few as four infrequent communication rounds.
We evaluate a client-sided model personalization via fine tuning after federated learning, using a small amount of fully sampled MRI scans. We find that this can learn an improved reconstruction network without heavily overfitting in the low-data regime, even for clients that did not originally participate in training. Fine tuning constitutes an easy, reproducible benchmark for future federated learning researchers to build and improve on.
3. Methods
3.1. Datasets and Model Architecture
We use three publicly available datasets in the experiments: fastMRI [
14], abdominal scans from [
15], which we refer to as the Stanford dataset, and axial knee scans from [
15], which we refer to as the NYU axial knee dataset. We use fastMRI for training due to its large number of available contrasts and field strengths, which allows us to simulate a federated scenario with heterogeneous client data distributions. In particular, we simulate a scenario with ten clients, each with different combinations of anatomy (knee and brain), contrast (PD, PDFS, T1, T2, and FLAIR), and field strength (1.5T and 3T). We use the Stanford and NYU axial knee datasets, in addition to two other anatomy and contrast combinations from fastMRI, as means of investigating reconstruction performance of clients that did not participate in the federated learning.
For all experiments, we assume an acceleration factor
with a random under-sampling mask along the phase encode (PE) direction and a fully sampled central region, which was taken as
of the total PE lines present. As the readout direction of the Stanford abdomen is horizontal, we first rotate k-space prior to reconstruction, and rotate back after. All data are normalized by the maximum value of the RSS image computed using the fully sampled central lines of k-space. We use the ESPIRiT algorithm [
46] in the BART toolbox [
47] to estimate the coil sensitivity maps. We use an MoDL architecture consisting of
unrolls. Data consistency blocks are implemented with
steps. The regularization network is a U-Net architecture which takes two input channels (real, imaginary), and consists of 481,092 trainable weights. Local clients were updated using the Adam optimizer [
48] with a batch size of one.
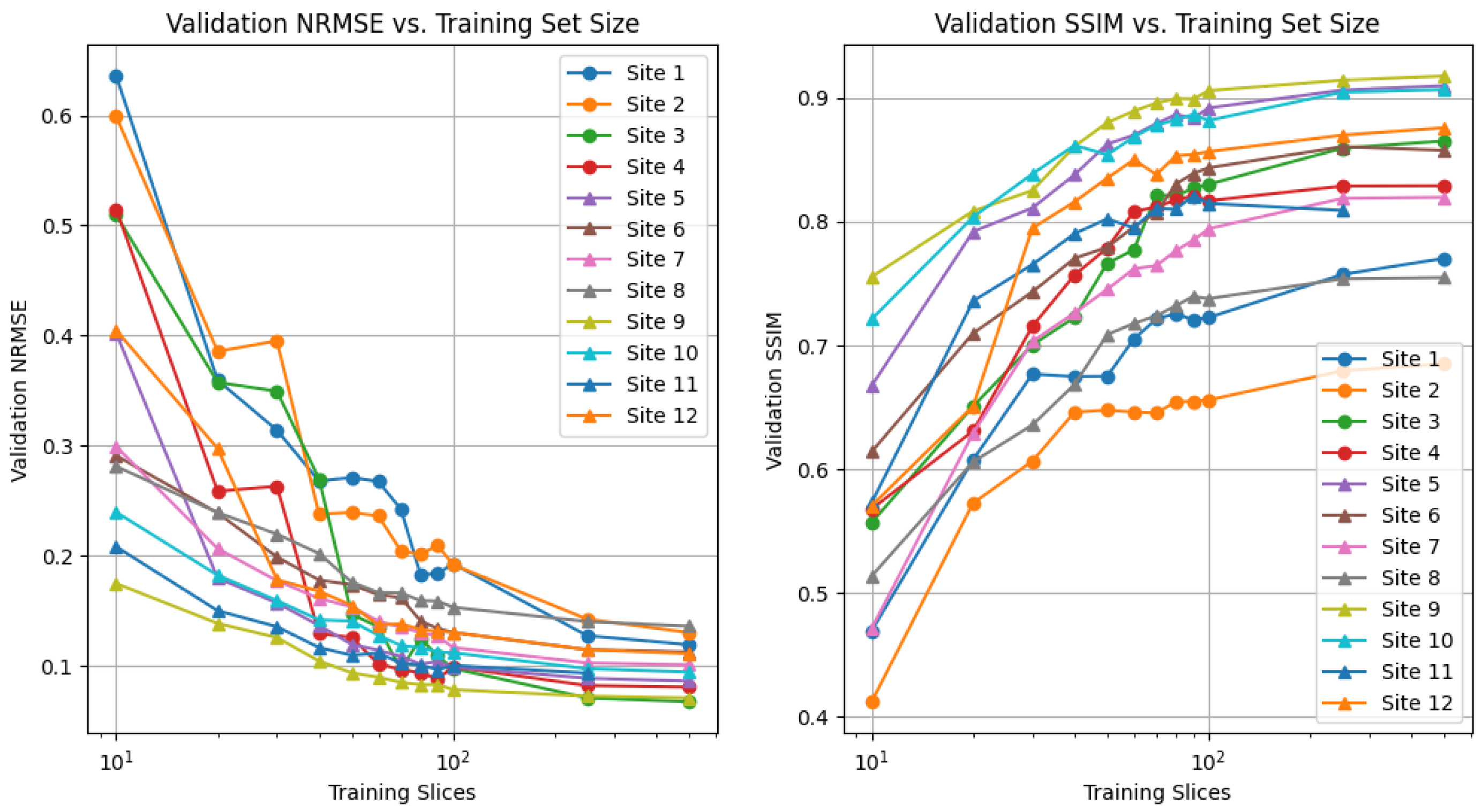
3.2. Low Data Regime for Federated Learning
As federated training of MRI reconstruction models aim to solve the issue of limited amounts of fully sampled data for some institutions, we first aim to determine the local sample count, which characterizes this notion of “limited data” for our setting. Specifically, we are interested in the number of local samples that causes a considerable drop in local performance but is still reasonably large to enable federated learning gains. To quantify this drop, we train local models using a variable amount of local training samples, without any federated learning involved, and empirically determine this dropping point. Specifically, we train centralized MoDL networks on each data distribution listed in
Table 1 (separate models for each) using a varying number of fully sampled training scans.
3.3. i.i.d. vs. Non-i.i.d. Client Distributions
Different client data distributions are a key issue that impacts the convergence of federated learning optimization, and are also highly common to MRI. In this section, we describe the methodology used to investigate the impact of heterogeneous, differently distributed clients on federated end-to-end unrolled approaches, and whether adaptive algorithms can mitigate these shifts. We first investigate the performance when all ten clients are composed of non-overlapping PDFS 1.5T scans (site 2) from the fastMRI dataset. In the case of non-i.i.d. client distributions, we sample the local data of each client from one of ten different distributions (sites), as summarized in
Table 1. This leads to no two clients sharing the same anatomy, contrast, or field strength combination, and is a realistic cross-silo federated learning setting. In both cases, we perform synchronous, full-participation federated learning for 240 aggregation rounds, where each round consists of two local epochs of training (100 local optimization steps).
We evaluate the following four adaptive federated optimization algorithms: Scaffold, FedAdam, FedYogi, and FedAdaGrad. We also evaluate the FL-MRCM approach in [
9], where we include the two additional Sites 4 and 12 in the federation for the non-i.i.d. case, and designate them as targets for the adversarial objective.
Scaffold [
18] is summarized in Algorithm 1 and uses auxiliary variables
and
that represent global and local momentum terms, respectively. During client optimization, their difference can be seen as an estimate of the client drift, and they are incorporated in the local updates (line 7 in Algorithm 1) to counteract this.
FedAdam,
FedYogi, and
FedAdaGrad [
19] are the federated versions of their namesake centralized algorithms.
The
FL-MRCM approach in [
9] proposes a solution to the problem of non-i.i.d. clients in federated learning by using an adversarial loss on the feature space of each client’s local reconstruction network. A key idea of the approach is to designate a specific client as a target, and to share its feature representations of the data with all other clients, where an adversarial feature objective between the local and the target client’s is used to make the feature representations as similar as possible.
| Algorithm 1 Scaffold [18] |
| Global inputs: Initial , , and global step size . |
| Client inputs: Local client datasets , initial , and local step size . |
| Output: Global model weights . |
- 1:
for round do - 2:
download and for all K clients - 3:
for client k in K do - 4:
for optimization step do - 5:
Compute gradient - 6:
- 7:
(i) , or (ii) - 8:
upload - 9:
- 10:
and
|
3.4. Personalized Unrolled Optimization
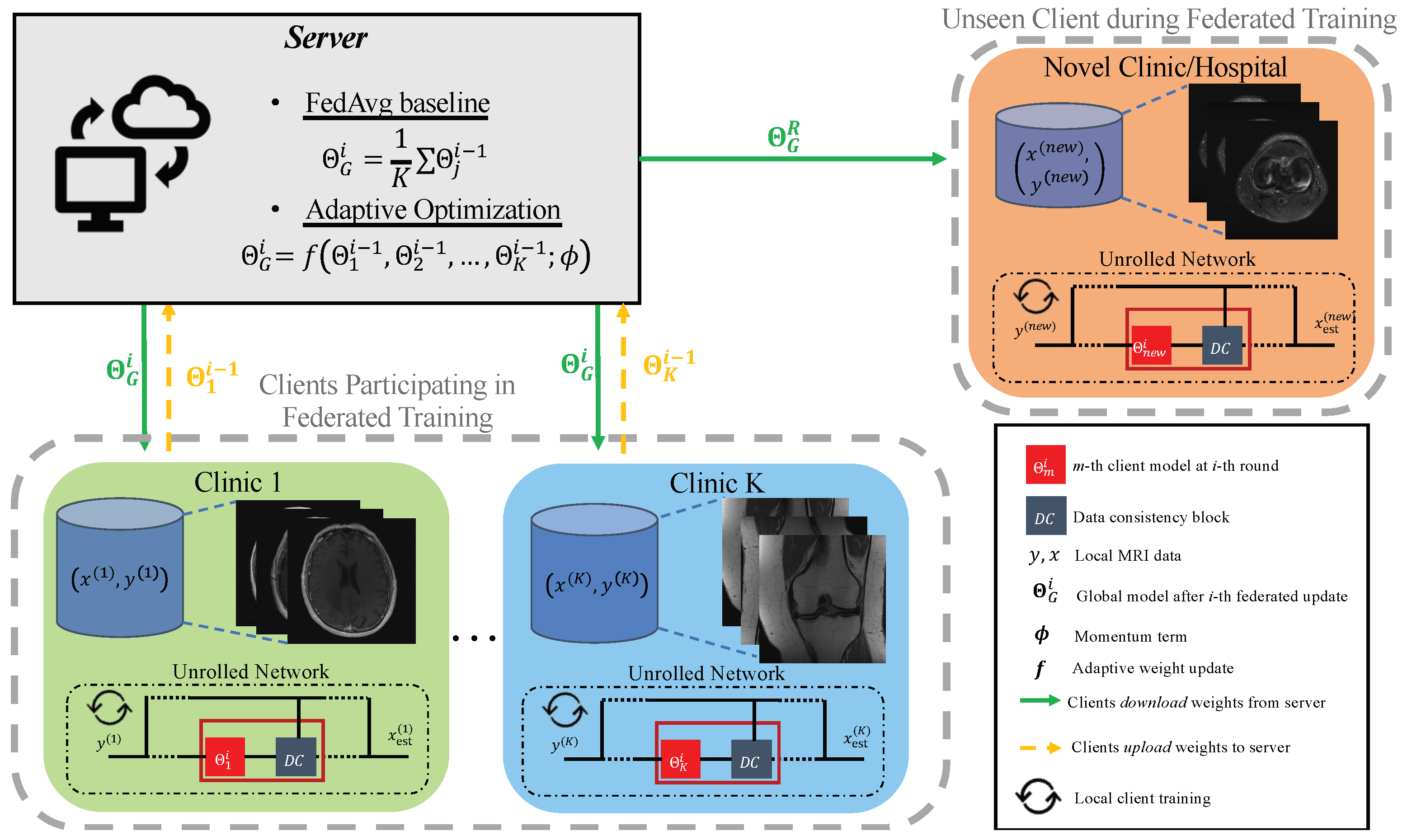
After a number of R communication rounds are completed, the server stops requesting weight uploads and communicates to all clients. This is a global model, trained to reconstruct multiple, potentially heterogeneous images resulting from differences in scan protocol, imaging anatomy, or system hardware. Therefore, there are two prevailing issues with directly using the global model that we study in this work:
Reconstruction performance may not be satisfactory for certain clients that participated in the federated learning process because characteristics of their image distributions (such as anatomy or contrast) are under-represented, hence client-sided personalization is an efficient tool for boosting performance.
New clients that do not have access to large training datasets may not benefit by from only using the pre-trained models provided by federated learning, if their data types are not well represented in the original federation of clients. This makes client-sided personalization a necessary component for acceptable quality reconstructions.
To address the above issues, we test the impact of client-sided personalization through fine tuning, which has recently been shown to be a competitive approach for improving performance on a local dataset [
31]. Formally, fine tuning is done with the same SSIM loss as in (
9) and is summarized in the right side of
Figure 1 for a new client. There are two important hyper-parameters that control personalization through fine-tuning: the learning rate
, and the number of fine-tuning epochs
. To select these hyper-parameters, we propose that each client perform a five-fold cross-validation approach using only its own local training data. We then use all available local client data and the selected hyper-parameter values to fine tune the federated model to the local client distribution.
We also investigate the impact of the communication budget on the personalization results after training. We focus on the non-i.i.d. case with Scaffold. In each scenario, the same total number of local update steps is allocated (24,000 local steps), except now a varying number of federated communication rounds (240, 120, 80, 60, 40, 24, or 4) is allowed. After learning the federated models, we test reconstruction performance both on clients that participated in the federated training and new, unseen clients.
3.5. Quantitative Metrics
We evaluate quantitative reconstruction performance using SSIM as defined in (
9) (higher is better) and normalized root mean squared error (NRMSE) between the RSS reconstruction and the fully sampled RSS (lower is better), where NRMSE between a reference
x and reconstruction
is defined as
Tables reporting SSIM and NRMSE represent the average value of the metric on the validation set.
5. Discussion
To train powerful data-driven reconstructions, it is crucial to procure large training datasets which faithfully represent the test data distribution. Due to privacy and regulatory constraints concerning sharing medical data, it may be infeasible for clinics to accrue a dataset locally which is both large enough and has the same distribution as the desired test data. Traditional federated learning attempts to solve the former in a privacy-preserving fashion by only sharing model weights across client institutions via model averaging. As data are often heterogeneous in an inter-client sense, client drift can inhibit the resulting federated model. A number of methods tailored to MRI reconstruction have been recently proposed to tackle this challenge, primarily by constraining the latent space of a feature representation either explicitly [
9] or implicitly [
25].
Unrolled methods are a powerful class of data-driven approaches for solving medical imaging inverse problems, and in a centralized scenario, they provide good reconstruction quality with as few as 250 training slices (
Figure 2). This characteristic motivates their use in federated scenarios where local data are limited in a meaningful sense. It is not immediately clear how to apply latent-space constrained methods to unrolled algorithms. Alternative reconstruction methods based on deep generative priors have recently shown competitive performance with end-to-end unrolled models [
43,
49,
50], and have a proclivity to be more robust to distribution shifts. FedGIMP [
23] in particular is a promising federated approach based on deep generative priors but requires adversarial training, which carries with it challenges, such as large training set sizes. Reconstruction times for generative models may also be an issue.
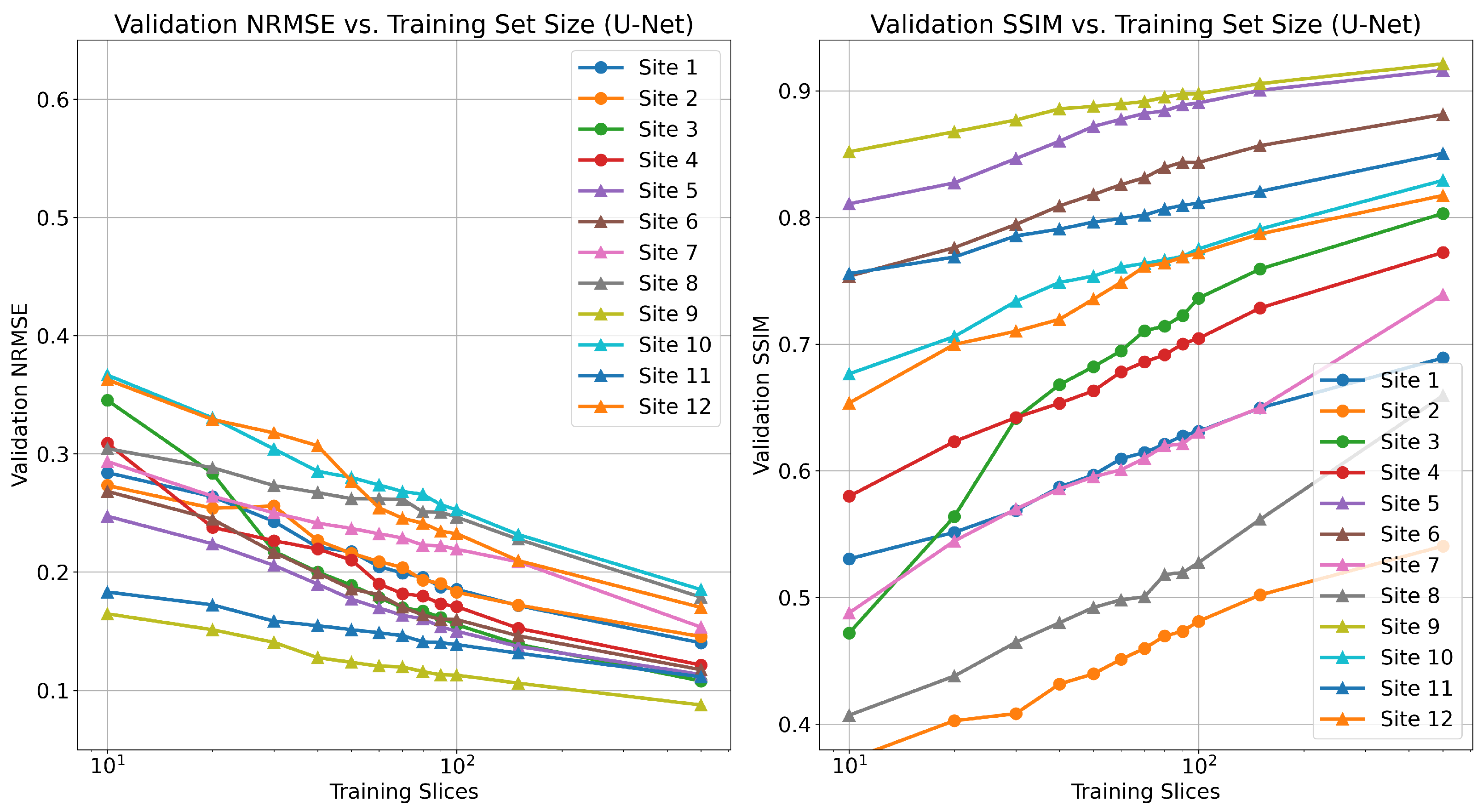
Recent work investigated the low-data regime for single-pass, supervised U-Net reconstruction of the RSS image directly, where it was shown that this approach requires at least thousands of local samples to saturate reconstruction performance [
41]. We validate this trend in
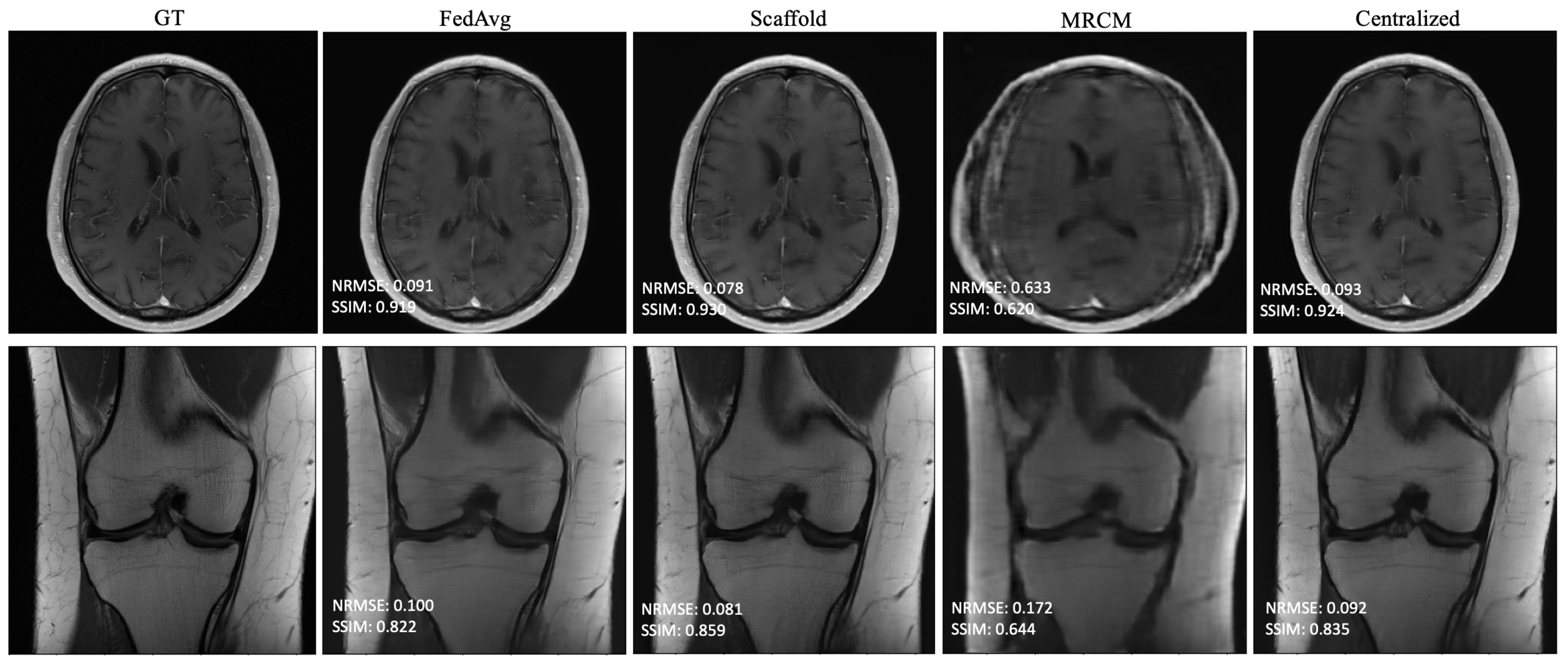
Figure A1, though we do not reach the saturation point in our experiments. This is in contrast to our findings on unrolled end-to-end models, where performance saturates when using as few as 100 local training samples. FL-MRCM shows a large decrease in performance compared to federated end-to-end approaches, which can likely be attributed to the single-pass U-Net reconstruction backbone it relies on and the same observation for the low-data regime.
At its core, federated learning seeks to provide a model that generalizes well to all clients (participating and not participating). This was the driving motivation for adaptive methods [
18,
19].
Table 2 shows that adaptive approaches at training time have little impact in the scenario where all clients are homogeneous (i.i.d.). Adaptivity becomes more important in the heterogeneous (non-i.i.d.) case as we show in
Table 3 and
Figure 3.
Table 3 shows the average validation performance evaluated on data from the same type that the client had access to during training. Adaptive approaches surpass the more simplistic weight aggregation in FedAvg, due to their use of auxiliary optimization variables at training time, designed to combat client drift. Not only do adaptive approaches surpass FedAvg in the non-i.i.d. scenario, they also often outperform the centralized model for high communication rates (
Table 3). This finding can be explained with the observation that, in the process of averaging individual models, each model is implicitly undergoing a form of regularization. Unlike the federated setting, the centralized setting we utilize does not use make use of any assumption of data heterogeneity, which may sometimes place its performance below that of adaptive federated learning algorithms that are designed with data heterogeneity in mind. This could in turn provide an approach to improve the performance of the centralized approach via a multi-task formulation, such as the one investigated in [
28].
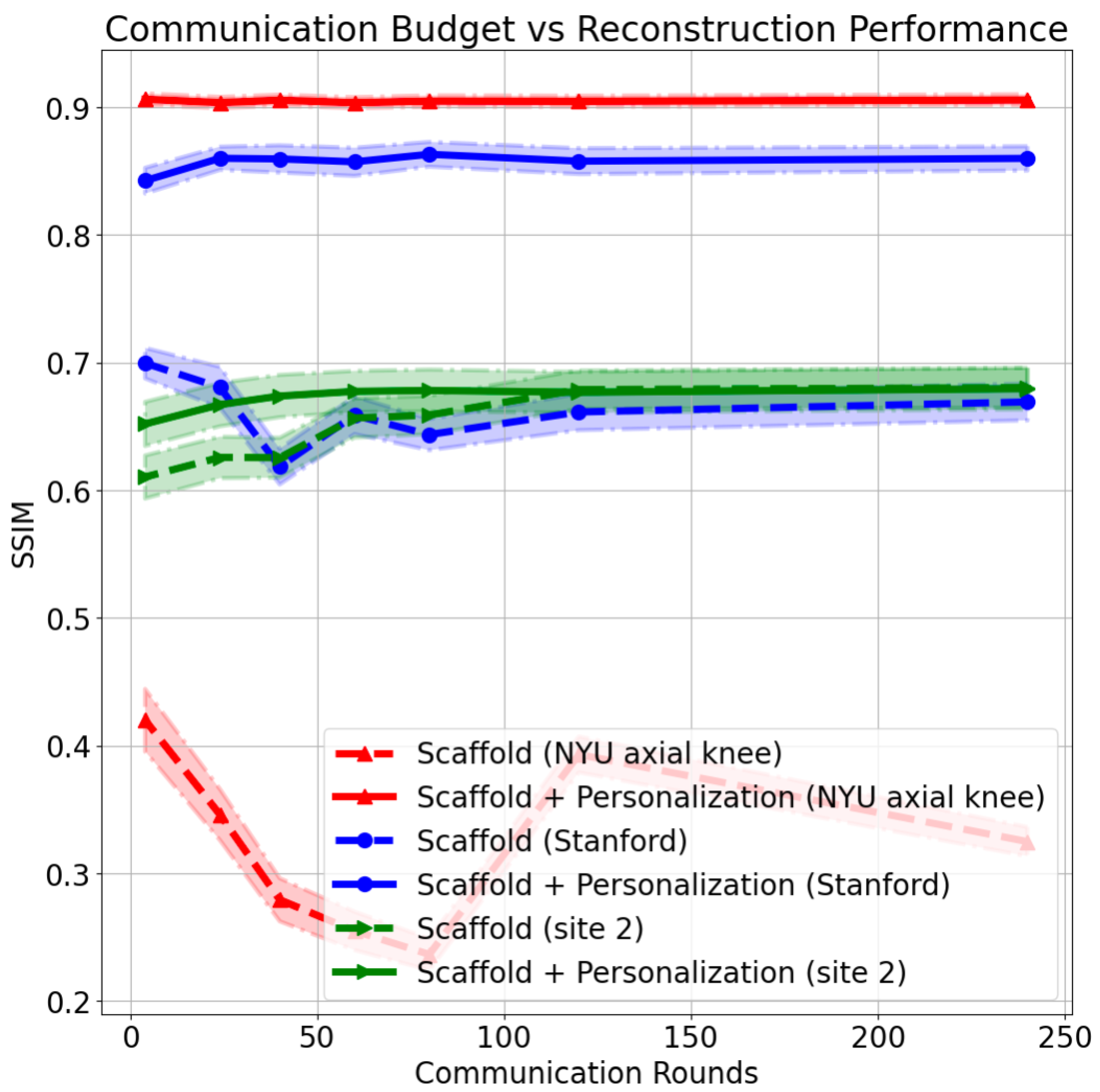
Another aspect in federated learning is the effect of a limited communication budget. When training is performed synchronously, global updates occur when at least a subset of individual clients are ready. This can create a communication bottleneck that restricts the number of global update rounds that occur during the training process. We found that limited communication between clients and the global server has an adverse effect for clients who are actively participating in the federated training. Interestingly, we find that a new client’s performance is almost agnostic to the communication rate, with the important caveat that reconstructions for novel clients at various communication rates may not be of diagnostic quality (
Figure 5).
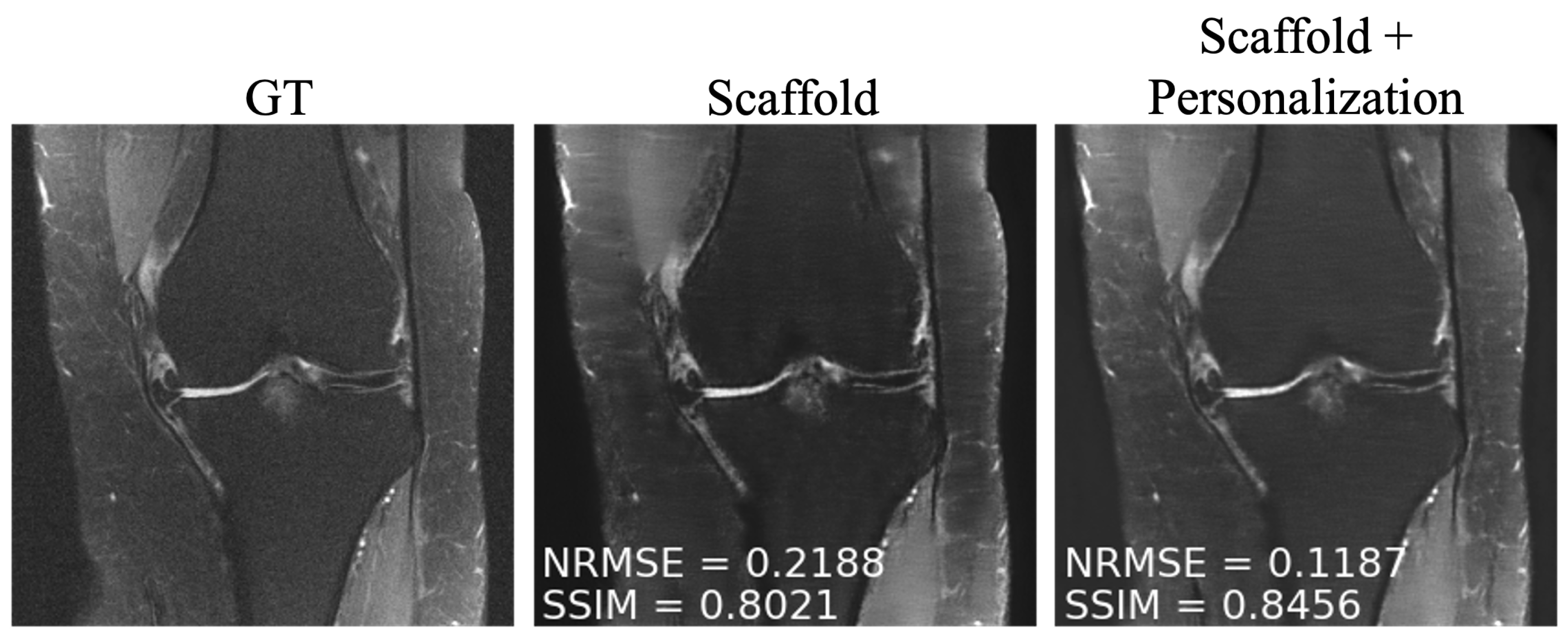
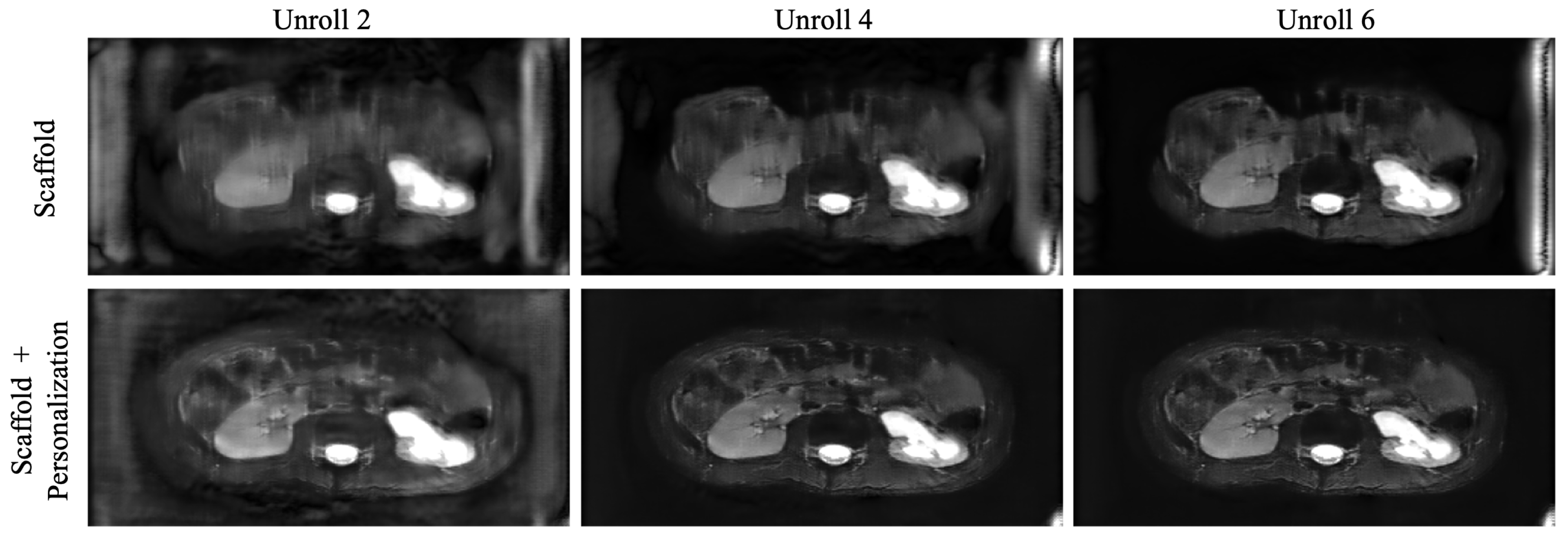
To overcome the performance drop experienced by participating clients in communication constrained settings, as well as to novel clients, we investigated simple personalization through model fine tuning. We observed that fine tuning enabled performance boosts both for under-represented clients participating in training and for those that did not participate in federated training at any time (
Figure 7). We found that 50 slices with five-fold cross-validation were sufficient to fine tune the model at each site.
In this work, we made several design choices, which do not cover all federated learning scenarios. The simplifications we assumed were synchronous training between clients, and no client drop-out at each communication round. We also assumed a single fixed acceleration factor and sampling pattern for all data. In future work, it will be crucial to investigate both the effects of asynchronous learning, varying levels of client dropout, and differences in scan protocol. Additionally, a promising future research direction is to investigate the performance of larger client pools (≫10), varying dataset sizes at each site, and varying scanning conditions, such as acceleration factor.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







