
Multi-Dataset Comparison of Vision Transformers and Convolutional Neural Networks for Detecting Glaucomatous Optic Neuropathy from Fundus Photographs
Abstract
:1. Introduction
2. Materials and Methods
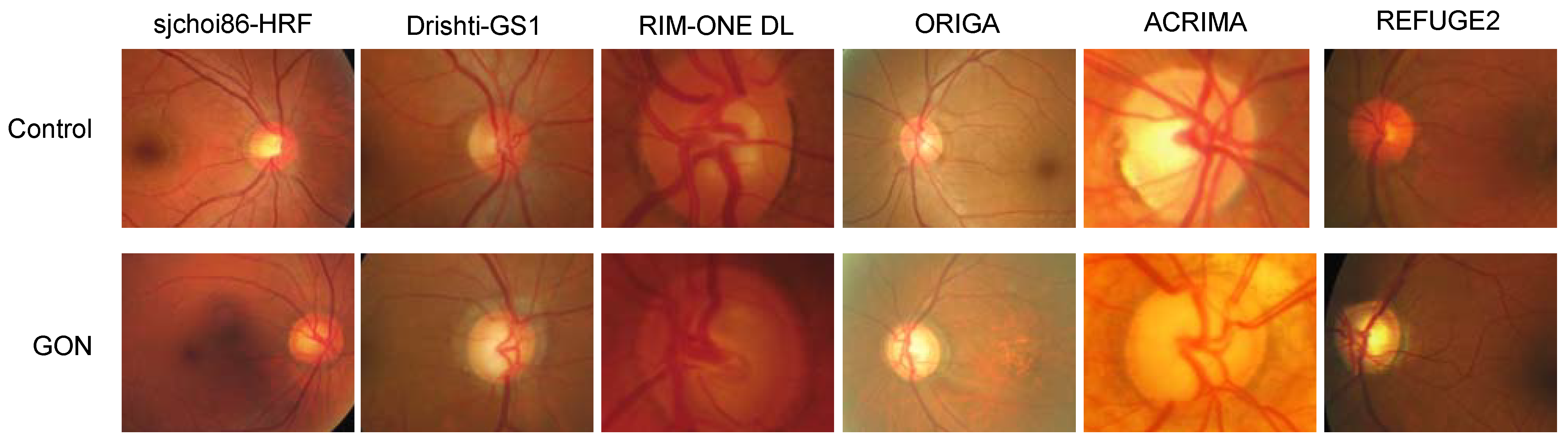
2.1. Datasets
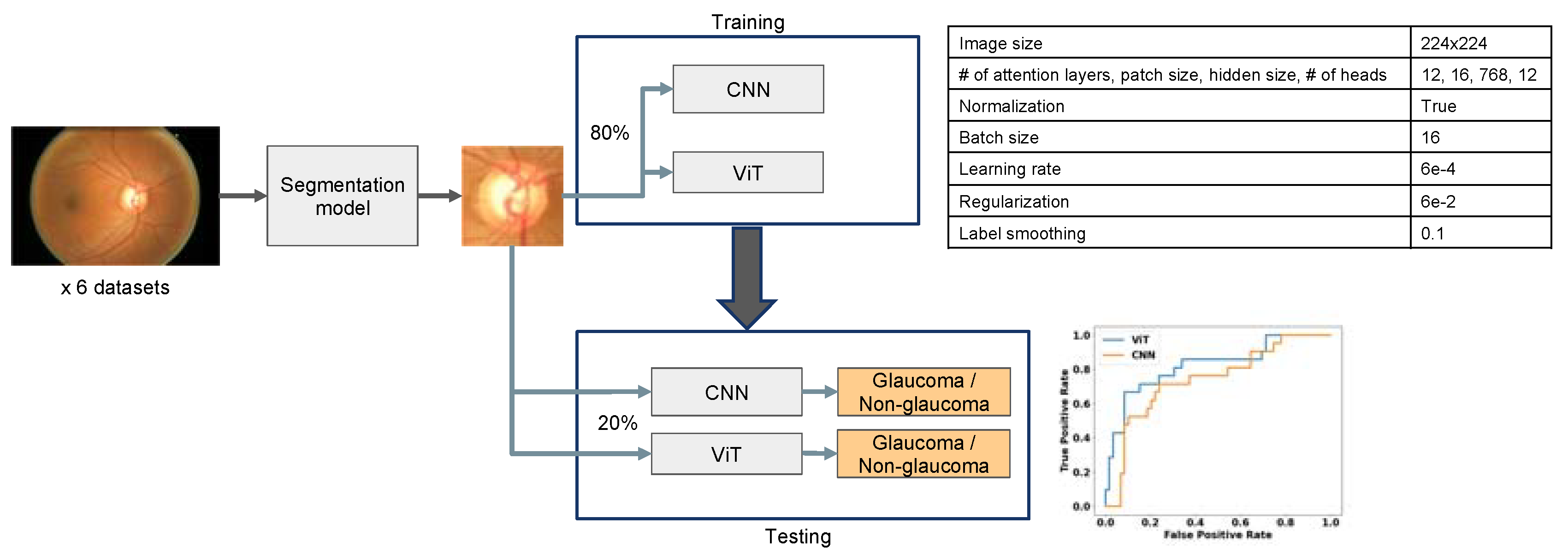
2.2. Image Preprocessing
2.3. Vision Transformer (ViT) and ResNet Training and Evaluation
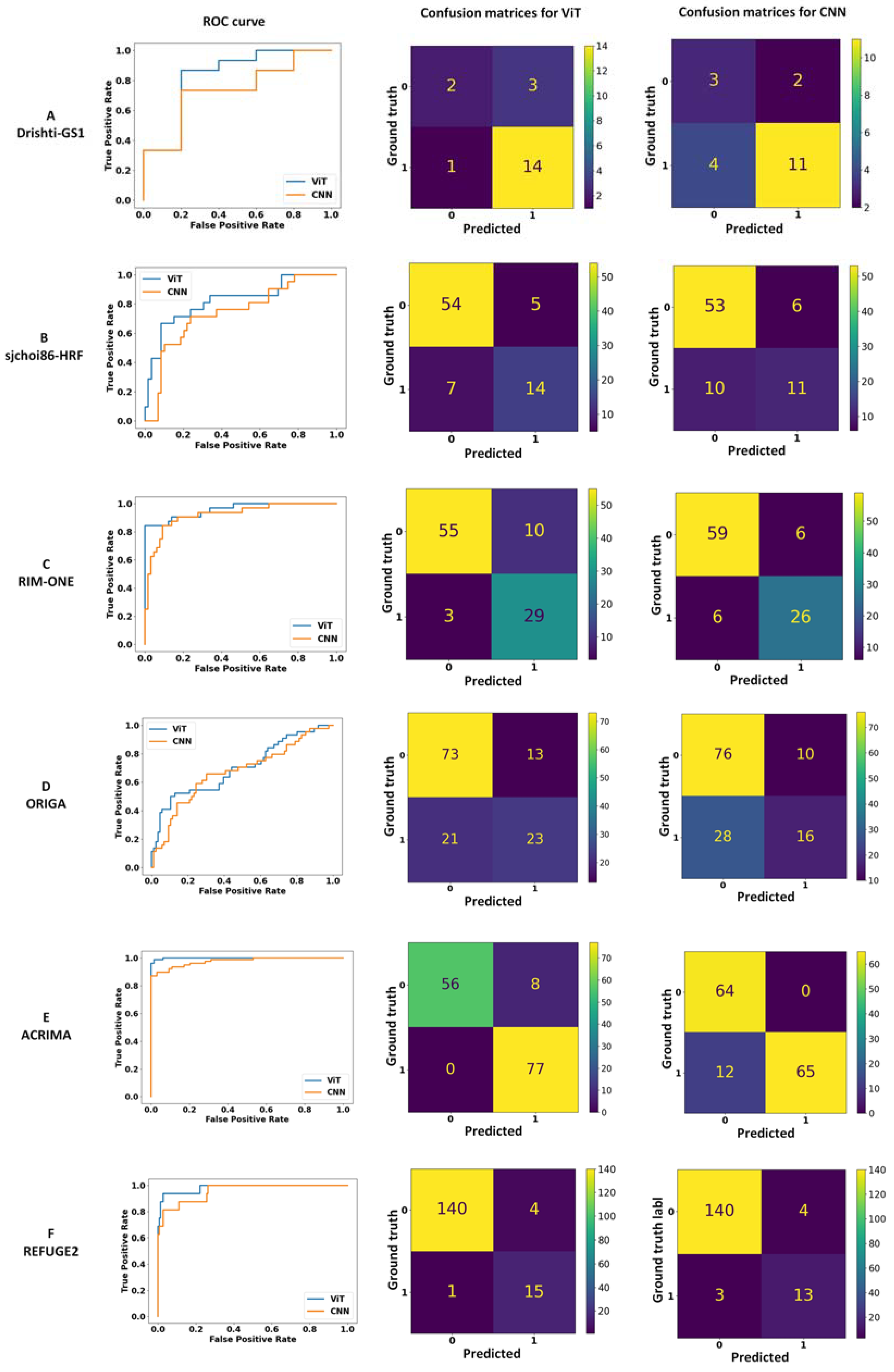
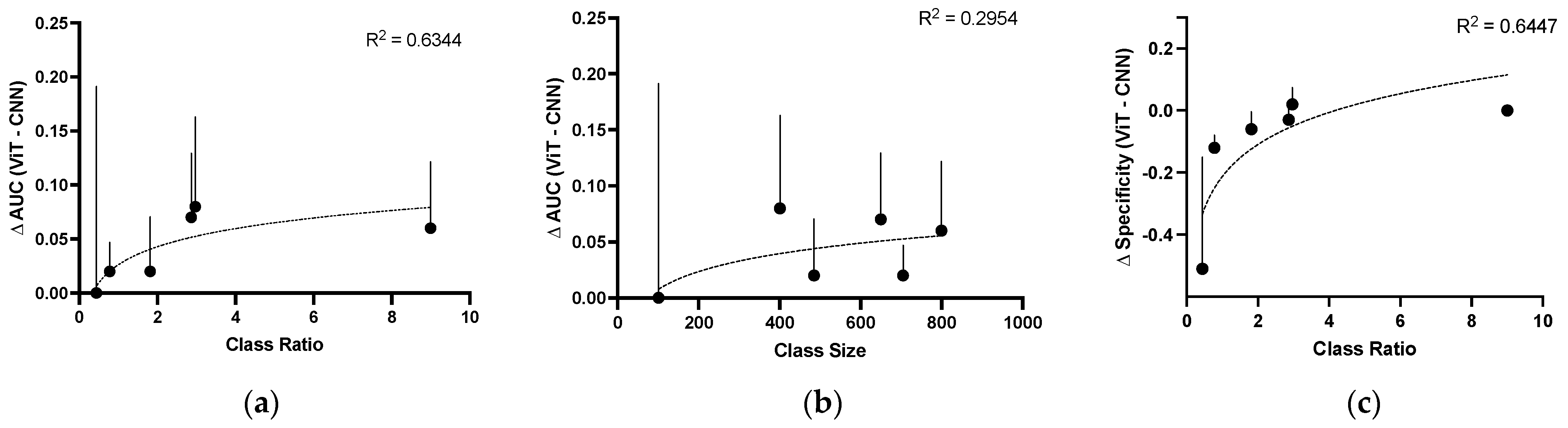
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tham, Y.-C.; Li, X.; Wong, T.Y.; Quigley, H.A.; Aung, T.; Cheng, C.-Y. Global prevalence of glaucoma and projections of glaucoma burden through 2040: A systematic review and meta-analysis. Ophthalmology 2014, 121, 2081–2090. [Google Scholar] [CrossRef] [PubMed]
- Vajaranant, T.S.; Wu, S.; Torres, M.; Varma, R. The changing face of primary open-angle glaucoma in the United States: Demographic and geographic changes from 2011 to 2050. Arch. Ophthalmol. 2012, 154, 303–314.e3. [Google Scholar] [CrossRef] [PubMed]
- Stein, J.D.; Khawaja, A.P.; Weizer, J.S. Glaucoma in Adults—Screening, Diagnosis, and Management: A Review. JAMA 2021, 325, 164–174. [Google Scholar] [CrossRef] [PubMed]
- Chou, R.; Selph, S.; Blazina, I.; Bougatsos, C.; Jungbauer, R.; Fu, R.; Grusing, S.; Jonas, D.E.; Tehrani, S. Screening for Glaucoma in Adults: Updated Evidence Report and Systematic Review for the US Preventive Services Task Force. JAMA 2022, 327, 1998–2012. [Google Scholar] [CrossRef]
- Thompson, A.C.; Jammal, A.A.; Medeiros, F.A. A Review of Deep Learning for Screening, Diagnosis, and Detection of Glaucoma Progression. Transl. Vis. Sci. Technol. 2020, 9, 42. [Google Scholar] [CrossRef]
- Chan, H.H.; Ong, D.N.; Kong, Y.X.; O’Neill, E.C.; Pandav, S.S.; Coote, M.A.; Crowston, J.G. Glaucomatous optic neuropathy evaluation (gone) project: The effect of monoscopic versus stereoscopic viewing conditions on optic nerve evaluation. Am. J. Ophthalmol. 2014, 157, 936–944. [Google Scholar] [CrossRef]
- Denniss, J.; Echendu, D.; Henson, D.B.; Artes, P.H. Discus: Investigating subjective judgment of optic disc damage. Optom. Vis. Sci. 2011, 88, E93–E101. [Google Scholar] [CrossRef]
- Jampel, H.D.; Friedman, D.; Quigley, H.; Vitale, S.; Miller, R.; Knezevich, F.; Ding, Y. Agreement Among Glaucoma Specialists in Assessing Progressive Disc Changes From Photographs in Open-Angle Glaucoma Patients. Arch. Ophthalmol. 2009, 147, 39–44.e1. [Google Scholar] [CrossRef]
- Nixon, G.J.; Watanabe, R.K.; Sullivan-Mee, M.; DeWilde, A.; Young, L.; Mitchell, G.L. Influence of Optic Disc Size on Identifying Glaucomatous Optic Neuropathy. Optom. Vis. Sci. 2017, 94, 654–663. [Google Scholar] [CrossRef]
- Shi, M.; Lokhande, A.; Fazli, M.S.; Sharma, V.; Tian, Y.; Luo, Y.; Pasquale, L.R.; Elze, T.; Boland, M.V.; Zebardast, N.; et al. Artifact-Tolerant Clustering-Guided Contrastive Embedding Learning for Ophthalmic Images in Glaucoma. IEEE J. Biomed. Health Inform. 2023, 27, 4329–4340. [Google Scholar] [CrossRef]
- Datta, S.; Mariottoni, E.B.; Dov, D.; Jammal, A.A.; Carin, L.; Medeiros, F.A. RetiNerveNet: Using recursive deep learning to estimate pointwise 24-2 visual field data based on retinal structure. Sci. Rep. 2021, 11, 12562. [Google Scholar] [CrossRef] [PubMed]
- Kang, J.H.; Wang, M.; Frueh, L.; Rosner, B.; Wiggs, J.L.; Elze, T.; Pasquale, L.R. Cohort Study of Race/Ethnicity and Incident Primary Open-Angle Glaucoma Characterized by Autonomously Determined Visual Field Loss Patterns. Transl. Vis. Sci. Technol. 2022, 11, 21. [Google Scholar] [CrossRef]
- Saini, C.; Shen, L.Q.; Pasquale, L.R.; Boland, M.V.; Friedman, D.S.; Zebardast, N.; Fazli, M.; Li, Y.; Eslami, M.; Elze, T.; et al. Assessing Surface Shapes of the Optic Nerve Head and Peripapillary Retinal Nerve Fiber Layer in Glaucoma with Artificial Intelligence. Ophthalmol. Sci. 2022, 2, 100161. [Google Scholar] [CrossRef]
- Yousefi, S.; Pasquale, L.R.; Boland, M.V.; Johnson, C.A. Machine-Identified Patterns of Visual Field Loss and an Association with Rapid Progression in the Ocular Hypertension Treatment Study. Ophthalmology 2022, 129, 1402–1411. [Google Scholar] [CrossRef] [PubMed]
- Mariottoni, E.B.; Datta, S.; Shigueoka, L.S.; Jammal, A.A.; Tavares, I.M.; Henao, R.; Carin, L.; Medeiros, F.A. Deep Learning–Assisted Detection of Glaucoma Progression in Spectral-Domain OCT. Ophthalmol. Glaucoma 2023, 6, 228–238. [Google Scholar] [CrossRef] [PubMed]
- Mariottoni, E.B.; Jammal, A.A.; Urata, C.N.; Berchuck, S.I.; Thompson, A.C.; Estrela, T.; Medeiros, F.A. Quantification of Retinal Nerve Fibre Layer Thickness on Optical Coherence Tomography with a Deep Learning Segmentation-Free Approach. Sci. Rep. 2020, 10, 402. [Google Scholar] [CrossRef]
- Medeiros, F.A.; Jammal, A.A.; Mariottoni, E.B. Detection of Progressive Glaucomatous Optic Nerve Damage on Fundus Photographs with Deep Learning. Ophthalmology 2021, 128, 383–392. [Google Scholar] [CrossRef]
- Shigueoka, L.S.; Mariottoni, E.B.; Thompson, A.C.; Jammal, A.A.; Costa, V.P.; Medeiros, F.A. Predicting Age From Optical Coherence Tomography Scans with Deep Learning. Transl. Vis. Sci. Technol. 2021, 10, 12. [Google Scholar] [CrossRef]
- Xiong, J.; Li, F.; Song, D.; Tang, G.; He, J.; Gao, K.; Zhang, H.; Cheng, W.; Song, Y.; Lin, F.; et al. Multimodal Machine Learning Using Visual Fields and Peripapillary Circular OCT Scans in Detection of Glaucomatous Optic Neuropathy. Ophthalmology 2022, 129, 171–180. [Google Scholar] [CrossRef]
- Yousefi, S. Clinical Applications of Artificial Intelligence in Glaucoma. J. Ophthalmic. Vis. Res. 2023, 18, 97–112. [Google Scholar] [CrossRef]
- Aggarwal, R.; Sounderajah, V.; Martin, G.; Ting, D.S.W.; Karthikesalingam, A.; King, D.; Ashrafian, H.; Darzi, A. Diagnostic accuracy of deep learning in medical imaging: A systematic review and meta-analysis. npj Digit. Med. 2021, 4, 65. [Google Scholar] [CrossRef]
- Krichen, M. Convolutional Neural Networks: A Survey. Computers 2023, 12, 151. [Google Scholar] [CrossRef]
- Shan, J.; Li, Z.; Ma, P.; Tun, T.A.; Yonamine, S.; Wu, Y.; Baskaran, M.; Nongpiur, M.E.; Chen, D.; Aung, T.; et al. Deep Learning Classification of Angle Closure based on Anterior Segment OCT. Ophthalmol. Glaucoma 2023. [Google Scholar] [CrossRef] [PubMed]
- Myburgh, J.C.; Mouton, C.; Davel, M.H. Tracking Translation Invariance in CNNs. In Southern African Conference for Artificial Intelligence Research; Springer International Publishing: Cham, Switzerland, 2020; pp. 282–295. [Google Scholar]
- Sadeghzadeh, H.; Koohi, S. Translation-invariant optical neural network for image classification. Sci. Rep. 2022, 12, 17232. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. Pr. Mach. Learn. Res. 2021, 139, 7358–7367. [Google Scholar]
- Vaid, A.; Jiang, J.; Sawant, A.; Lerakis, S.; Argulian, E.; Ahuja, Y.; Lampert, J.; Charney, A.; Greenspan, H.; Narula, J.; et al. A foundational vision transformer improves diagnostic performance for electrocardiograms. NPJ Digit. Med. 2023, 6, 108. [Google Scholar] [CrossRef]
- Kiyasseh, D.; Ma, R.; Haque, T.F.; Miles, B.J.; Wagner, C.; Donoho, D.A.; Anandkumar, A.; Hung, A.J. A vision transformer for decoding surgeon activity from surgical videos. Nat. Biomed. Eng. 2023, 7, 780–796. [Google Scholar] [CrossRef]
- Liu, H.; Teng, L.; Fan, L.; Sun, Y.; Li, H. A new ultra-wide-field fundus dataset to diabetic retinopathy grading using hybrid preprocessing methods. Comput. Biol. Med. 2023, 157, 106750. [Google Scholar] [CrossRef]
- Playout, C.; Duval, R.; Boucher, M.C.; Cheriet, F. Focused Attention in Transformers for interpretable classification of retinal images. Med. Image Anal. 2022, 82, 102608. [Google Scholar] [CrossRef]
- Yu, S.; Ma, K.; Bi, Q.; Bian, C.; Ning, M.; He, N.; Li, Y.; Liu, H.; Zheng, Y. MIL-VT: Multiple Instance Learning Enhanced Vision Transformer for Fundus Image Classification. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021, Proceedings, Part VIII 24; Springer International Publishing: Cham, Switzerland, 2021; pp. 45–54. [Google Scholar]
- Kihara, Y.; Shen, M.; Shi, Y.; Jiang, X.; Wang, L.; Laiginhas, R.; Lyu, C.; Yang, J.; Liu, J.; Morin, R.; et al. Detection of Nonexudative Macular Neovascularization on Structural OCT Images Using Vision Transformers. Ophthalmol. Sci. 2022, 2, 100197. [Google Scholar] [CrossRef] [PubMed]
- Li, A.L.; Feng, M.; Wang, Z.; Baxter, S.L.; Huang, L.; Arnett, J.; Bartsch, D.-U.G.; Kuo, D.E.; Saseendrakumar, B.R.; Guo, J.; et al. Automated Detection of Posterior Vitreous Detachment on OCT Using Computer Vision and Deep Learning Algorithms. Ophthalmol. Sci. 2023, 3, 100254. [Google Scholar] [CrossRef] [PubMed]
- Philippi, D.; Rothaus, K.; Castelli, M. A vision transformer architecture for the automated segmentation of retinal lesions in spectral domain optical coherence tomography images. Sci. Rep. 2023, 13, 517. [Google Scholar] [CrossRef]
- Xuan, M.; Wang, W.; Shi, D.; Tong, J.; Zhu, Z.; Jiang, Y.; Ge, Z.; Zhang, J.; Bulloch, G.; Peng, G.; et al. A Deep Learning–Based Fully Automated Program for Choroidal Structure Analysis Within the Region of Interest in Myopic Children. Transl. Vis. Sci. Technol. 2023, 12, 22. [Google Scholar] [CrossRef] [PubMed]
- Sivaswamy, J.; Krishnadas, S.R.; Joshi, G.D.; Jain, M.; Tabish, A.U.S. Drishti-Gs: Retinal Image Dataset for Optic Nerve Head(ONH) Segmentation. In Proceedings of the 2014 IEEE 11th International Symposium on Biomedical Imaging (ISBI), Beijing, China, 29 April–2 May 2014; pp. 53–56. Available online: https://cvit.iiit.ac.in/projects/mip/drishti-gs/mip-dataset2/Home.php (accessed on 16 October 2023).
- sjchoi86. sjchoi86-HRF. Available online: https://github.com/yiweichen04/retina_dataset (accessed on 20 October 2016).
- Fumero, F.; Diaz-Aleman, T.; Sigut, J.; Alayon, S.; Arnay, R.; Angel-Pereira, D. Rim-One Dl: A Unified Retinal Image Database for Assessing Glaucoma Using Deep Learning. Image Anal. Ster. 2020, 39, 161–167. [Google Scholar] [CrossRef]
- Zhang, Z.; Yin, F.S.; Liu, J.; Wong, W.K.; Tan, N.M.; Lee, B.H.; Cheng, J.; Wong, T.Y. ORIGA(-light): An online retinal fundus image database for glaucoma analysis and research. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2010, 2010, 3065–3068. Available online: https://www.kaggle.com/datasets/sshikamaru/glaucoma-detection (accessed on 16 October 2023). [CrossRef]
- Diaz-Pinto, A.; Morales, S.; Naranjo, V.; Köhler, T.; Mossi, J.M.; Navea, A. CNNs for automatic glaucoma assessment using fundus images: An extensive validation. Biomed. Eng. Online 2019, 18, 29. [Google Scholar] [CrossRef]
- Fang, H.; Li, F.; Wu, J.; Fu, H.; Sun, X.; Son, J.; Yu, S.; Zhang, M.; Yuan, C.; Bian, C. REFUGE2 Challenge: A Treasure Trove for Multi-Dimension Analysis and Evaluation in Glaucoma Screening. arXiv 2022, arXiv:2202.08994. Available online: https://ai.baidu.com/broad/download (accessed on 16 October 2023).
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Cham, Switzerland, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Vision & Eye Health Surveillance System. Review: Glaucoma. Available online: https://www.cdc.gov/visionhealth/vehss/data/studies/glaucoma.html (accessed on 12 October 2023).
- Dhillon, A.; Verma, G.K. Convolutional neural network: A review of models, methodologies and applications to object detection. Prog. Artif. Intell. 2019, 9, 85–112. [Google Scholar] [CrossRef]
- Wang, P.; Yuan, M.; He, Y.; Sun, J. 3D augmented fundus images for identifying glaucoma via transferred convolutional neural networks. Int. Ophthalmol. 2021, 41, 2065–2072. [Google Scholar] [CrossRef]
- Rogers, T.W.; Jaccard, N.; Carbonaro, F.; Lemij, H.G.; Vermeer, K.A.; Reus, N.J.; Trikha, S. Evaluation of an AI system for the automated detection of glaucoma from stereoscopic optic disc photographs: The European Optic Disc Assessment Study. Eye 2019, 33, 1791–1797. [Google Scholar] [CrossRef] [PubMed]
- Jammal, A.A.; Thompson, A.C.; Mariottoni, E.B.; Berchuck, S.I.; Urata, C.N.; Estrela, T.; Wakil, S.M.; Costa, V.P.; Medeiros, F.A. Human Versus Machine: Comparing a Deep Learning Algorithm to Human Gradings for Detecting Glaucoma on Fundus Photographs. Arch. Ophthalmol. 2020, 211, 123–131. [Google Scholar] [CrossRef] [PubMed]
- Thompson, A.C.; Jammal, A.A.; Medeiros, F.A. A Deep Learning Algorithm to Quantify Neuroretinal Rim Loss From Optic Disc Photographs. Arch. Ophthalmol. 2019, 201, 9–18. [Google Scholar] [CrossRef]
- Ma, J.; Bai, Y.; Zhong, B.; Zhang, W.; Yao, T.; Mei, T. Visualizing and Understanding Patch Interactions in Vision Transformer. In IEEE Transactions on Neural Networks and Learning Systems; IEEE: New York, NY, USA, 2023; pp. 1–10. [Google Scholar] [CrossRef]
- Fan, R.; Alipour, K.; Bowd, C.; Christopher, M.; Brye, N.; Proudfoot, J.A.; Goldbaum, M.H.; Belghith, A.; Girkin, C.A.; Fazio, M.A.; et al. Detecting Glaucoma from Fundus Photographs Using Deep Learning without Convolutions: Transformer for Improved Generalization. Ophthalmol. Sci. 2023, 3, 100233. [Google Scholar] [CrossRef]
- Song, D.; Fu, B.; Li, F.; Xiong, J.; He, J.; Zhang, X.; Qiao, Y. Deep Relation Transformer for Diagnosing Glaucoma With Optical Coherence Tomography and Visual Field Function. IEEE Trans. Med. Imaging 2021, 40, 2392–2402. [Google Scholar] [CrossRef] [PubMed]
- Hou, K.; Bradley, C.; Herbert, P.; Johnson, C.; Wall, M.; Ramulu, P.Y.; Unberath, M.; Yohannan, J. Predicting Visual Field Worsening with Longitudinal OCT Data Using a Gated Transformer Network. Ophthalmology 2023, 130, 854–862. [Google Scholar] [CrossRef]
- Yi, Y.; Jiang, Y.; Zhou, B.; Zhang, N.; Dai, J.; Huang, X.; Zeng, Q.; Zhou, W. C2FTFNet: Coarse-to-fine transformer network for joint optic disc and cup segmentation. Comput. Biol. Med. 2023, 164, 107215. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Z.; Nan, N.; Wang, X. TranSegNet: Hybrid CNN-Vision Transformers Encoder for Retina Segmentation of Optical Coherence Tomography. Life 2023, 13, 976. [Google Scholar] [CrossRef]
- Vali, M.; Mohammadi, M.; Zarei, N.; Samadi, M.; Atapour-Abarghouei, A.; Supakontanasan, W.; Suwan, Y.; Subramanian, P.S.; Miller, N.R.; Kafieh, R.; et al. Differentiating Glaucomatous Optic Neuropathy From Non-glaucomatous Optic Neuropathies Using Deep Learning Algorithms. Arch. Ophthalmol. 2023, 252, 1–8. [Google Scholar] [CrossRef]
- Christopher, M.; Belghith, A.; Bowd, C.; Proudfoot, J.A.; Goldbaum, M.H.; Weinreb, R.N.; Girkin, C.A.; Liebmann, J.M.; Zangwill, L.M. Performance of deep learning architectures and transfer learning for detecting glaucomatous optic neuropathy in fundus photographs. Sci. Rep. 2018, 8, 16685. [Google Scholar] [CrossRef]
- Luo, X.; Hu, M.; Song, T.; Wang, G.; Zhang, S. Semi-Supervised Medical Image Segmentation via Cross Teaching between CNN and Transformer. In Proceedings of the 5th International Conference on Medical Imaging with Deep Learning, Zurich, Switzerland, 6–8 July 2022; pp. 820–833. [Google Scholar]
- Li, A.; Cheng, J.; Wong, D.W.K.; Liu, J. Integrating holistic and local deep features for glaucoma classification. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 1328–1331. [Google Scholar]
- Li, L.; Xu, M.; Liu, H.; Li, Y.; Wang, X.; Jiang, L.; Wang, Z.; Fan, X.; Wang, N. A Large-Scale Database and a CNN Model for Attention-Based Glaucoma Detection. IEEE Trans. Med. Imaging 2020, 39, 413–424. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Patient Selection | Instrument | Ground Truth | Images | |||
|---|---|---|---|---|---|---|---|
| Non-GC (Control) | GC | Total Size | Class Ratio * | ||||
| Drishti-GS1 [37] | Glaucomatous and routine refraction images selected by experts from patients between ages 40 and 80 at Aravind Eye Hospital in India | Not noted | 4 experts | 31 | 70 | 101 | 0.44 |
| sfchoi86-HRF [38] | Unknown | Unknown | Unknown | 300 | 101 | 401 | 2.97 |
| RIM-ONE DL [39] | Curated extraction from RIM-ONE V1, V2, and V3 of glaucomatous and healthy patients from 3 hospitals in Spain | V1/V2: Nidek AFC-210 camera V3: Kowa WX 3D non-stereo camera | 2 experts with tiebreaker | 312 | 173 | 485 | 1.80 |
| ORIGA [40] | Glaucomatous and randomly selected non-GC images from cross-sectional population Singaporean study (SiMES) of Malay adults between ages 40 and 80 | Canon CR-DGi | ORIGA-GT | 482 | 168 | 650 | 2.87 |
| ACRIMA [41] | Glaucomatous and normal images selected by experts in Spain based on clinical findings | Topcon TRC retinal camera | 2 experts | 309 | 396 | 705 | 0.78 |
| REFUGE2 [42] | Random selection from glaucoma and myopia study cohorts in China (Zongshan Ophthalmic Center) | KOWA, TOPCON | 7 experts | 720 | 80 | 800 | 9.00 |
| ViT | CNN | |||||
|---|---|---|---|---|---|---|
| AUC | Sensitivity | Specificity | AUC | Sensitivity | Specificity | |
| Drishti-GS1 | 0.67 | 0.93 | 0.40 | 0.67 | 0.73 | 0.91 |
| (0.44, 0.97) | (0.79, 1.00) | (0.00, 1.00) | (0.38, 0.91) | (0.50, 0.93) | (0.00, 1.00) | |
| sjchoi86-HRF | 0.79 | 0.67 | 0.92 | 0.71 | 0.52 | 0.90 |
| (0.67, 90) | (0.46, 0.82) | (0.84, 0.98) | (0.59, 82) | (0.31, 0.75) | (0.81, 0.97) | |
| RIM-ONE DL | 0.88 | 0.91 | 0.85 | 0.86 | 0.81 | 0.91 |
| (0.81, 0.94) | (0.79, 1.00) | (0.76, 0.93) | (0.78, 0.93) | (0.67, 0.94) | (0.83, 0.97) | |
| ORIGA | 0.69 | 0.52 | 0.85 | 0.62 | 0.36 | 0.88 |
| (0.60, 0.77) | (0.37, 0.67) | (0.77, 0.92) | (0.54, 0.70) | (0.21, 0.52) | (0.81, 0.95) | |
| ACRIMA | 0.94 | 1.00 | 0.88 | 0.92 | 0.84 | 1.00 |
| (0.90, 0.97) | (1.00, 1.00) | (0.79, 0.95) | (0.88, 0.96) | (0.76, 0.92) | (1.00, 1.00) | |
| REFUGE2 | 0.95 | 0.94 | 0.97 | 0.89 | 0.81 | 0.97 |
| (0.88, 1.00) | (0.80, 1.00) | (0.94, 0.99) | (0.78, 0.99) | (0.60, 1.00) | (0.94, 0.99) | |
| ViT | CNN | |||||
| Accuracy | F1 Score | mAP | Accuracy | F1 Score | mAP | |
| Drishti-GS1 | 0.80 | 0.87 | 0.82 | 0.70 | 0.79 | 0.82 |
| (0.60, 0.95) | (0.73, 0.97) | (0.63, 0.99) | (0.50, 0.90) | (0.58, 0.93) | (0.61, 0.98) | |
| sjchoi86-HRF | 0.81 | 0.68 | 0.53 | 0.80 | 0.58 | 0.46 |
| (0.72, 0.89) | (0.51, 0.82) | (0.35, 0.72) | (0.71, 0.89) | (0.37, 0.76) | (0.28, 0.65) | |
| RIM-ONE DL | 0.87 | 0.82 | 0.70 | 0.88 | 0.81 | 0.72 |
| (0.79, 0.93) | (0.71, 0.90) | (0.56, 0.85) | (0.80, 0.94) | (0.69, 0.91) | (0.56, 0.86) | |
| ORIGA | 0.74 | 0.57 | 0.50 | 0.71 | 0.46 | 0.44 |
| (0.66, 0.82) | (0.44, 0.69) | (0.37, 0.63) | (0.63, 0.78) | (0.31, 0.60) | (0.32, 0.56) | |
| ACRIMA | 0.94 | 0.95 | 0.91 | 0.91 | 0.92 | 0.93 |
| (0.91, 0.98) | (0.91, 0.98) | (0.84, 0.96) | (0.87, 0.96) | (0.86, 0.96) | (0.89, 0.97) | |
| REFUGE2 | 0.97 | 0.83 | 0.72 | 0.96 | 0.79 | 0.64 |
| (0.94, 0.99) | (0.64, 0.95) | (0.47, 0.92) | (0.93, 0.99) | (0.60, 0.93) | (0.39, 0.86) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, E.E.; Chen, D.; Han, Y.; Jia, L.; Shan, J. Multi-Dataset Comparison of Vision Transformers and Convolutional Neural Networks for Detecting Glaucomatous Optic Neuropathy from Fundus Photographs. Bioengineering 2023, 10, 1266. https://doi.org/10.3390/bioengineering10111266
Hwang EE, Chen D, Han Y, Jia L, Shan J. Multi-Dataset Comparison of Vision Transformers and Convolutional Neural Networks for Detecting Glaucomatous Optic Neuropathy from Fundus Photographs. Bioengineering. 2023; 10(11):1266. https://doi.org/10.3390/bioengineering10111266
Chicago/Turabian StyleHwang, Elizabeth E., Dake Chen, Ying Han, Lin Jia, and Jing Shan. 2023. "Multi-Dataset Comparison of Vision Transformers and Convolutional Neural Networks for Detecting Glaucomatous Optic Neuropathy from Fundus Photographs" Bioengineering 10, no. 11: 1266. https://doi.org/10.3390/bioengineering10111266