
A Multilayer Perceptron Model for Stochastic Synthesis



Abstract
:1. Introduction
2. Materials and Methods
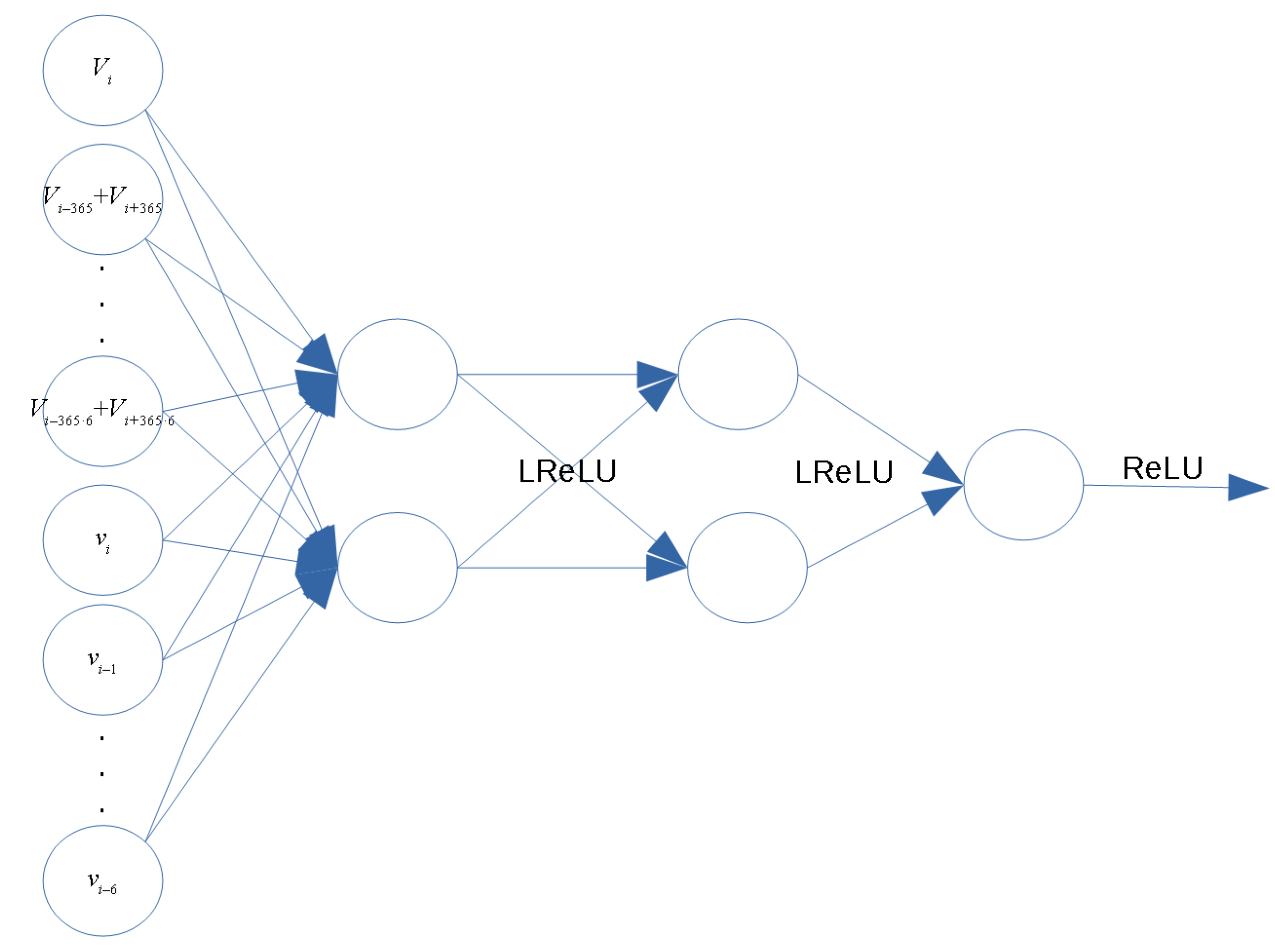
2.1. MLPS
2.1.1. Input Features
2.1.2. Topology
2.1.3. Cost Function
2.1.4. Training
2.2. WeaGETS
| 0.1 | Daily precipitation threshold |
| 700 | Number of years to generate |
| No | Smooth the parameters of precipitation occurrence and quantity |
| 1 | Order of Markov Chain to generate precipitation occurrence |
| Skewed normal | Distribution to generate wet day precipitation amount |
| Unconditional | Scheme to generate maximum and minimum temperatures |
| No | Correct the low-frequency variability of precipitation |
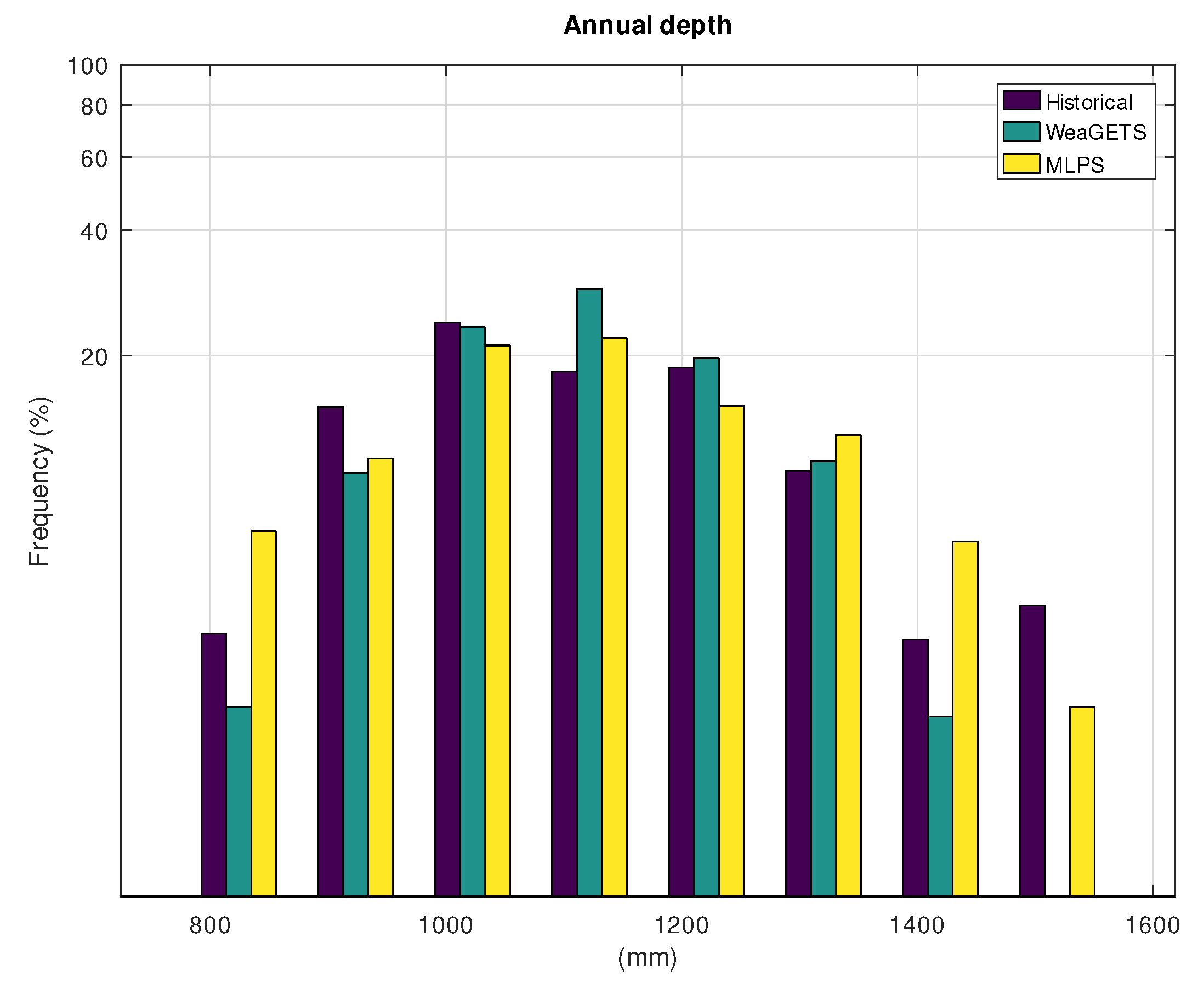
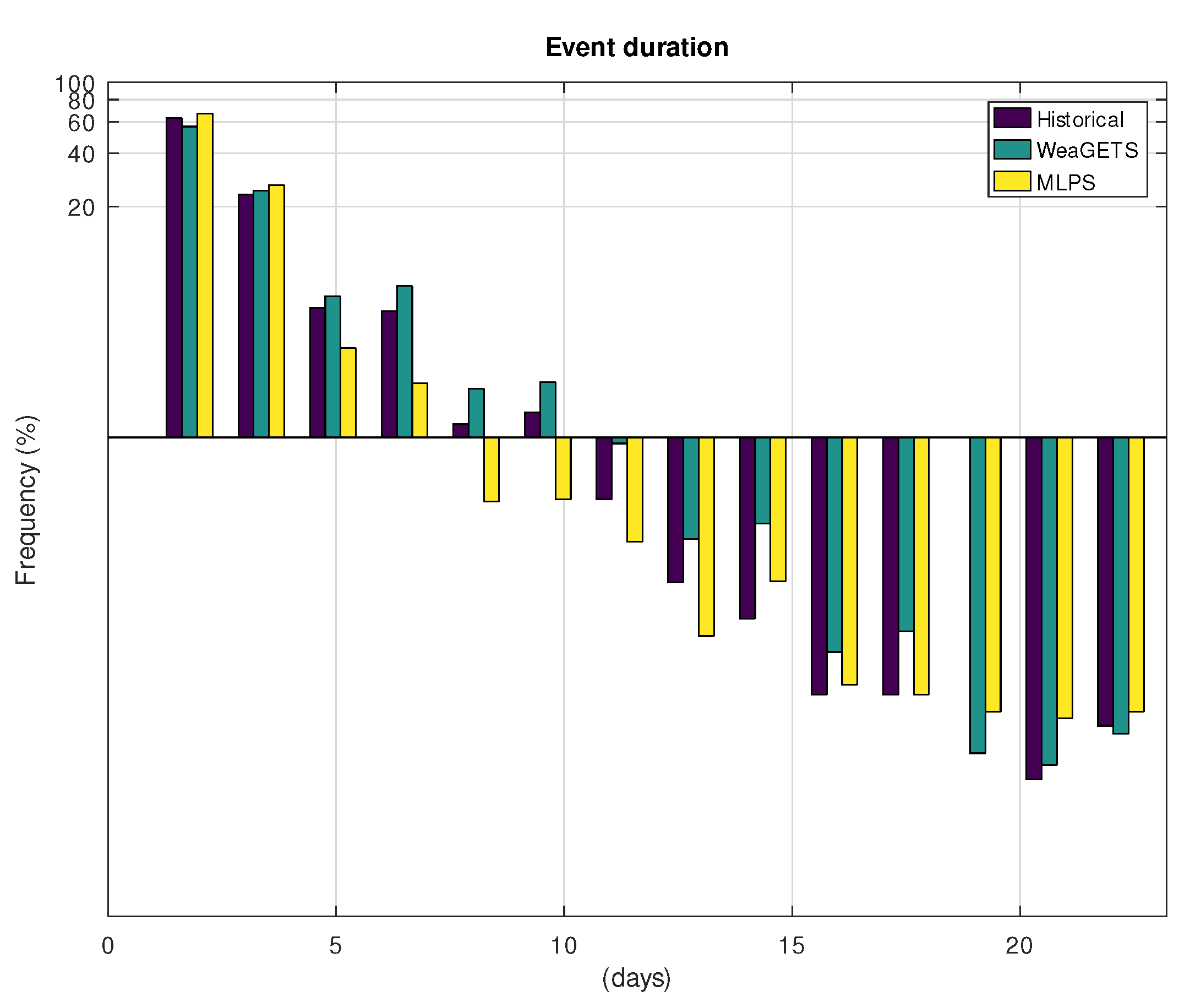
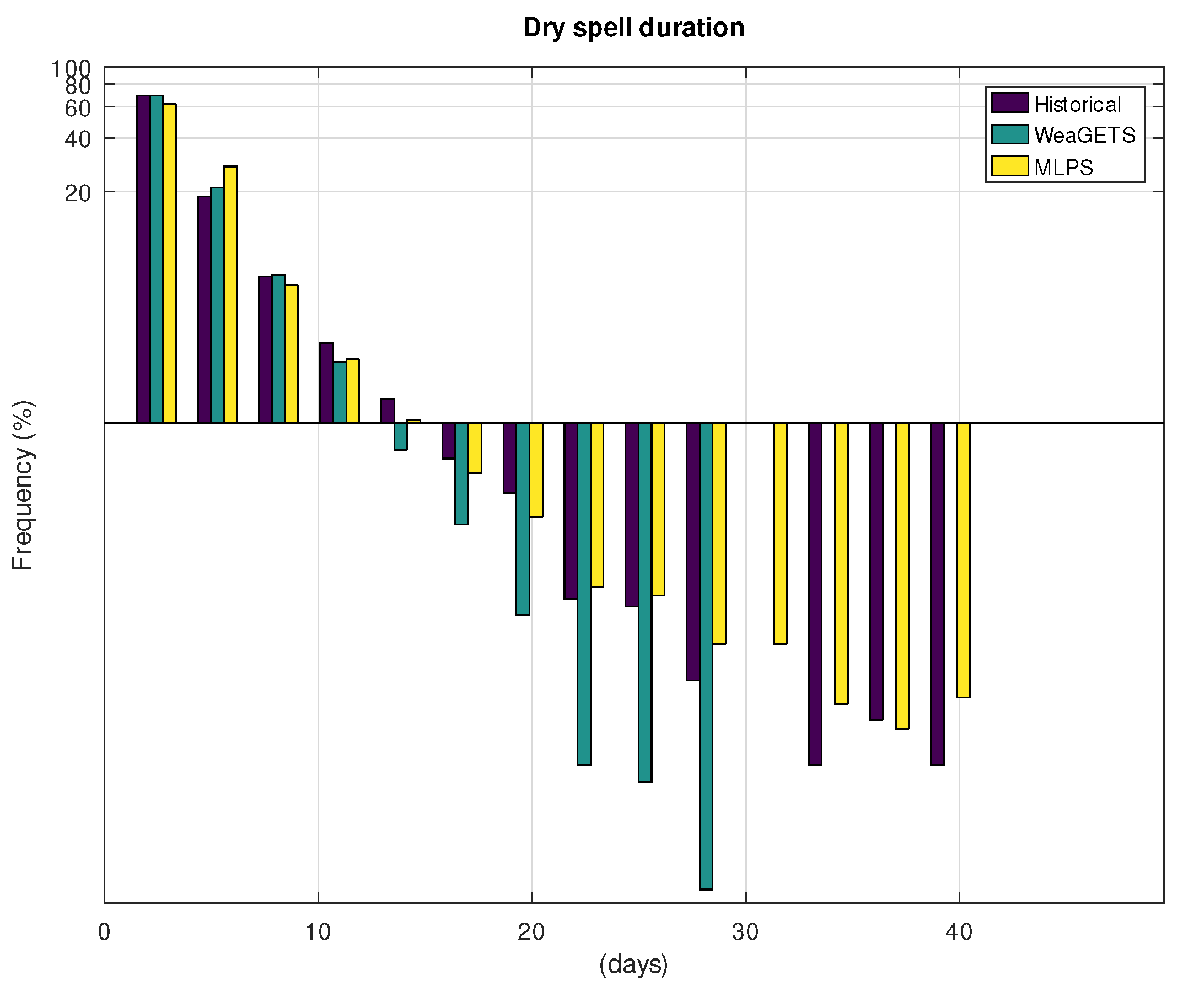
3. Results
3.1. Application to Hohenpeissenberg
3.2. Application to Gibraltar
4. Discussion
5. Conclusions
- Preserves the stochastic properties in multiple scales (e.g., daily, annual);
- Preserves the autocovariance structure including the long-term persistence in multiple lags;
- Is straightforward to apply; and
- Can handle a variety of stochastic problems despite being based on a simple concept.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MLP | multilayer perceptron |
| MLPS | multilayer perceptron stochastic model |
| AR | auto regressive |
| MA | moving average |
| ARMA | auto regressive moving average |
| IIDI | independent and identically distributed innovations |
| LSTM | long short-term memory |
| MSE | mean squared error |
| MAE | mean absolute error |
| IAHS | International Association of Hydrological Sciences |
| GA | genetic algorithms |
Appendix A. The MS Excel Date Format
References
- Barnes, F. Storage required for a city water supply. J. Inst. Eng. Aust. 1954, 26, 198–203. [Google Scholar]
- Thomas, H.A.; Fiering, M. Mathematical synthesis of streamflow sequences for the analysis of river basins by simulation. In Design of Water-Resource Systems; Maass, A., Dorfman, R., Fair, G.M., Hufschmidt, M.M., Marglin, S.A., Thomas, T.A., Jr., Eds.; Harvard University Press: Cambridge, MA, USA, 1962; Chapter 12. [Google Scholar]
- Box, G.; Jenkins, G. Time Series Analysis: Forecasting and Control; Holden-Day: San Francisco, CA, USA, 1970. [Google Scholar]
- Koutsoyiannis, D. A generalized mathematical framework for stochastic simulation and forecast of hydrologic time series. Water Resour. Res. 2000, 36, 1519–1533. [Google Scholar] [CrossRef] [Green Version]
- Koutsoyiannis, D. Coupling stochastic models of different timescales. Water Resour. Res. 2001, 37, 379–391. [Google Scholar] [CrossRef] [Green Version]
- Hurst, H.E. The Problem of Long-Term Storage in Reservoirs. Int. Assoc. Sci. Hydrol. Bull. 1956, 1, 13–27. [Google Scholar] [CrossRef] [Green Version]
- Koutsoyiannis, D. Hydrologic persistence and the Hurst phenomenon. In Water Encyclopedia, Vol. 4, Surface and Agricultural Water; Lehr, J.H., Keeley, J.W., Lehr, J.K., Kingery, T.B., Eds.; John Wiley & Sons: Hoboken, NJ, USA, 2005; Chapter 1. [Google Scholar]
- Castalia. A Computer System for Stochastic Simulation and Forecasting of Hydrologic Processes. 2021. Available online: http://www.itia.ntua.gr/en/softinfo/2 (accessed on 2 February 2021).
- Pan, F.; Nagaoka, L.; Wolverton, S.; Atkinson, S.F.; Kohler, T.A.; O’Neill, M. A Constrained Stochastic Weather Generator for Daily Mean Air Temperature and Precipitation. Atmosphere 2021, 12, 135. [Google Scholar] [CrossRef]
- Peleg, N.; Fatichi, S.; Paschalis, A.; Molnar, P.; Burlando, P. An advanced stochastic weather generator for simulating 2-D high-resolution climate variables. J. Adv. Model. Earth Syst. 2017, 9, 1595–1627. [Google Scholar] [CrossRef]
- Fatichi, S.; Ivanov, V.Y.; Caporali, E. Simulation of future climate scenarios with a weather generator. Adv. Water Resour. 2011, 34, 448–467. [Google Scholar] [CrossRef]
- Li, X.; Babovic, V. Multi-site multivariate downscaling of global climate model outputs: An integrated framework combining quantile mapping, stochastic weather generator and Empirical Copula approaches. Clim. Dyn. 2019, 52, 5775–5799. [Google Scholar] [CrossRef]
- Nearing, G.; Kratzert, F.; Sampson, A.; Pelissier, C.; Klotz, D.; Frame, J.; Prieto, C.; Gupta, H. What Role Does Hydrological Science Play in the Age of Machine Learning? Water Resour. Res. 2020. [Google Scholar] [CrossRef]
- Shuang, Q.; Zhao, R.T. Water Demand Prediction Using Machine Learning Methods: A Case Study of the Beijing–Tianjin–Hebei Region in China. Water 2021, 13, 310. [Google Scholar] [CrossRef]
- Rozos, E. Machine Learning, Urban Water Resources Management and Operating Policy. Resources 2019, 8, 173. [Google Scholar] [CrossRef] [Green Version]
- Shin, M.J.; Moon, S.H.; Kang, K.G.; Moon, D.C.; Koh, H.J. Analysis of Groundwater Level Variations Caused by the Changes in Groundwater Withdrawals Using Long Short-Term Memory Network. Hydrology 2020, 7, 64. [Google Scholar] [CrossRef]
- Rashid Niaghi, A.; Hassanijalilian, O.; Shiri, J. Estimation of Reference Evapotranspiration Using Spatial and Temporal Machine Learning Approaches. Hydrology 2021, 8, 25. [Google Scholar] [CrossRef]
- Minns, A.W.; Hall, M.J. Artificial neural networks as rainfall-runoff models. Hydrol. Sci. J. 1996, 41, 399–417. [Google Scholar] [CrossRef]
- Campos, L.; Vellasco, M.; Lazo, J. A Stochastic Model based on Neural Networks. In Proceedings of the IEEE International Joint Conference on Neural Networks, Maxwell/Lambda-Dee, San Jose, CA, USA, 31 July–5 August 2011; Chapter 1. pp. 1–7. [Google Scholar]
- Minsky, M.; Papert, S. Perceptrons: An Introduction to Computational Geometry; MIT Press: Cambridge, MA, USA, 1969. [Google Scholar]
- Rozos, E. Hydrology/Hydrodynamics Team of NOA—Software. 2021. Available online: https://sites.google.com/view/hydronoa/home/software (accessed on 2 February 2021).
- DATEVALUE Function. 2021. Available online: https://support.microsoft.com/en-us/office/datevalue-function-df8b07d4-7761-4a93-bc33-b7471bbff252 (accessed on 2 February 2021).
- Vogelpoel, V. Excel Serial Date to Day, Month, Year and Vice Versa. 2021. Available online: https://www.codeproject.com/Articles/2750/Excel-Serial-Date-to-Day-Month-Year-and-Vice-Versa (accessed on 2 February 2021).
- Chen, J.; Brissette, F.P.; Leconte, R. A daily stochastic weather generator for preserving low-frequency of climate variability. J. Hydrol. 2010, 388, 480–490. [Google Scholar] [CrossRef]
- Chen, J.; Brissette, F.P. Comparison of five stochastic weather generators in simulating daily precipitation and temperature for the Loess Plateau of China. Int. J. Climatol. 2014, 34, 3089–3105. [Google Scholar] [CrossRef]
- Richardson, C.W.; Wright, D.A. WGEN: A Model for Generating Daily Weather Variables; U.S. Department of Agriculture, Agricultural Research Service: Washington, DC, USA, 1984; 83p.
- Nelder, J.A.; Mead, R. A Simplex Method for Function Minimization. Comput. J. 1965, 7, 308–313. [Google Scholar] [CrossRef]
- Jordan, J. Normalizing Your Data (Specifically, Input and Batch Normalization). 2021. Available online: https://www.jeremyjordan.me/batch-normalization/ (accessed on 2 February 2021).
- Szandała, T. Bio-inspired Neurocomputing. Stud. Comput. Intell. 2021. [Google Scholar] [CrossRef]
- Dasaradh, S. A Gentle Introduction to Math Behind Neural Networks. 2021. Available online: https://towardsdatascience.com/introduction-to-math-behind-neural-networks-e8b60dbbdeba (accessed on 2 February 2021).
- Yellapragada, S. Common Loss Functions That You Should Know. 2021. Available online: https://medium.com/ml-cheat-sheet/winning-at-loss-functions-common-loss-functions-that-you-should-know-a72c1802ecb4 (accessed on 2 February 2021).
- Koutsoyiannis, D. Probability and Statistics for Geophysical Processes, 1st ed.; National Technical University of Athens: Athens, Greece, 2008; Available online: https://doi.org/10.13140/RG.2.1.2300.1849/1 (accessed on 2 February 2021).
- Guidelines for the Use of Units, Symbols and Equations in Hydrology. 2021. Available online: https://iahs.info/Publications-News/Other-publications/Guidelines-for-the-use-of-units-symbols-and-equations-in-hydrology.do (accessed on 2 February 2021).
- Chadalawada, J.; Babovic, V. Review and comparison of performance indices for automatic model induction. J. Hydroinform. 2017, 21, 13–31. [Google Scholar] [CrossRef] [Green Version]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization, and Machine Learning; Addison-Wesley: Boston, MA, USA, 2012. [Google Scholar]
- Hagan, M.T.; Demuth, H.B.; Beale, M.H.; De Jesus, O. Neural Network Design; Martin Hagan: Stillwater, OK, USA, 2016. [Google Scholar]
- Guo, J. AI Notes: Initializing Neural Networks—Deeplearning.ai. 2021. Available online: https://www.deeplearning.ai/ai-notes/initialization/ (accessed on 2 February 2021).
- Efron, B.; Tibshirani, R. An Introduction to the Bootstrap; Chapman & Hall/CRC: New York, NY, USA, 1998. [Google Scholar]
- Fitzgerald, J.; Azad, R.M.A.; Ryan, C. A Bootstrapping Approach to Reduce Over-Fitting in Genetic Programming. In Proceedings of the 15th Annual Conference Companion on Genetic and Evolutionary Computation, Amsterdam, The Netherlands, 15–19 July 2013; Association for Computing Machinery: New York, NY, USA, 2013. GECCO ’13 Companion. pp. 1113–1120. [Google Scholar] [CrossRef]
- Watterson, S. An Expansion of the Genetic Algorithm Package for GNU Octave That Supports Parallelisation and Bounds. 2021. Available online: https://github.com/stevenwatterson/GA (accessed on 2 February 2021).
- Dedicated Root Server, VPS & Hosting—Hetzner Online GmbH. 2021. Available online: https://www.hetzner.com/ (accessed on 2 February 2021).
- Koutsoyiannis, D. HESS Opinions “A random walk on water”. Hydrol. Earth Syst. Sci. 2010, 14, 585–601. [Google Scholar] [CrossRef] [Green Version]
- Dimitriadis, P.; Koutsoyiannis, D. Stochastic synthesis approximating any process dependence and distribution. Stoch. Environ. Res. Risk Assess. 2018, 32, 1493–1515. [Google Scholar] [CrossRef]
- Dimitriadis, P.; Koutsoyiannis, D.; Tzouka, K. Predictability in dice motion: How does it differ from hydro-meteorological processes? Hydrol. Sci. J. 2016, 61, 1611–1622. [Google Scholar] [CrossRef] [Green Version]
- Richardson, C.W. Stochastic simulation of daily precipitation, temperature, and solar radiation. Water Resour. Res. 1981, 17, 182–190. [Google Scholar] [CrossRef]
- Chadalawada, J.; Herath, H.M.V.V.; Babovic, V. Hydrologically Informed Machine Learning for Rainfall-Runoff Modeling: A Genetic Programming-Based Toolkit for Automatic Model Induction. Water Resour. Res. 2020, 56, e2019WR026933. [Google Scholar] [CrossRef]
- Herath, H.M.V.V.; Chadalawada, J.; Babovic, V. Hydrologically Informed Machine Learning for Rainfall-Runoff Modelling: Towards Distributed Modelling. Hydrol. Earth Syst. Sci. Discuss. 2020, 2020, 1–42. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Shalev, G.; Klambauer, G.; Hochreiter, S.; Nearing, G. Towards learning universal, regional, and local hydrological behaviors via machine learning applied to large-sample datasets. Hydrol. Earth Syst. Sci. 2019, 23, 5089–5110. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
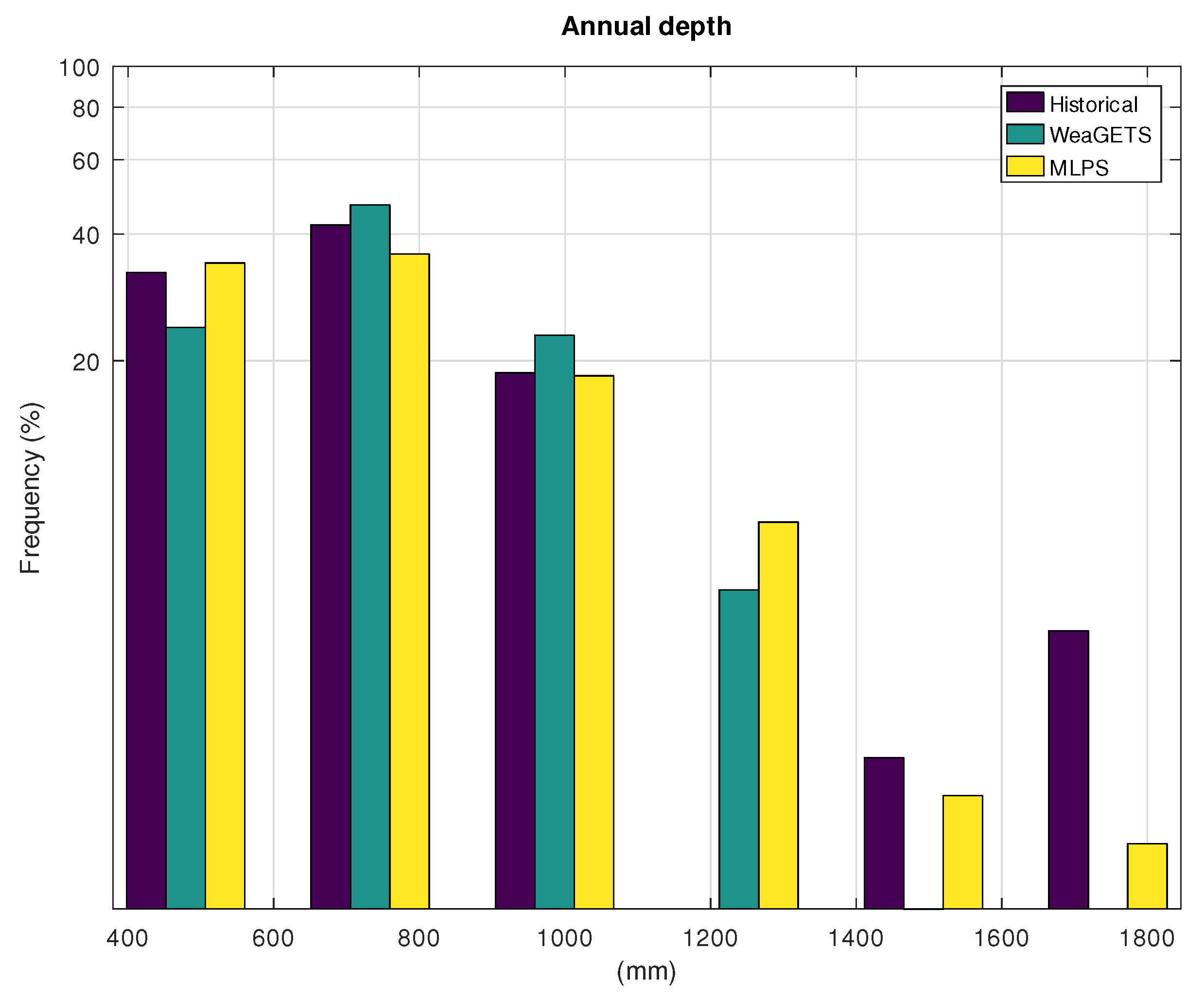{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hist. | WeaGETS | MLPS | |
|---|---|---|---|
| Standard deviation—year | 170 | 137 | 179 |
| Mean—day | 3.09 | 3.08 | 3.08 |
| Standard deviation—day | 6.57 | 6.50 | 7.07 |
| Skewness—day | 4.28 | 4.41 | 4.08 |
| Kurtosis—day | 33.4 | 35.2 | 27.8 |
| Auto correlation—day | 0.23 | 0.12 | 0.23 |
| Hist. | WeaGETS | MLPS | |
|---|---|---|---|
| Standard deviation—year | 320 | 201 | 306 |
| Mean—day | 2.07 | 2.08 | 2.08 |
| Standard deviation—day | 9.44 | 9.14 | 9.46 |
| Skewness—day | 11.95 | 9.78 | 12.43 |
| Kurtosis—day | 242.9 | 188.4 | 286.4 |
| Auto correlation—day | 0.24 | 0.11 | 0.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rozos, E.; Dimitriadis, P.; Mazi, K.; Koussis, A.D. A Multilayer Perceptron Model for Stochastic Synthesis. Hydrology 2021, 8, 67. https://doi.org/10.3390/hydrology8020067
Rozos E, Dimitriadis P, Mazi K, Koussis AD. A Multilayer Perceptron Model for Stochastic Synthesis. Hydrology. 2021; 8(2):67. https://doi.org/10.3390/hydrology8020067
Chicago/Turabian StyleRozos, Evangelos, Panayiotis Dimitriadis, Katerina Mazi, and Antonis D. Koussis. 2021. "A Multilayer Perceptron Model for Stochastic Synthesis" Hydrology 8, no. 2: 67. https://doi.org/10.3390/hydrology8020067