MANOVA and LDA
The four qualitative criteria of the multivariate hypothesis, namely Pillai’s Trace = 5.573 (F = 8.698, df = 540, p = 0.000, η2 = 0.929), Wilks’ Lambda = 0.000 (F = 22.251, df = 540, p = 0.000, η2 = 0.972), Hotelling’s Trace = 1034.279 (F = 102.151, df = 540, p = 0.000, η2 = 0.994), and Roy’s Largest Root = 789.550 (F = 526.367, df = 90, p = 0.000, η2 = 0.999) showed that there was a statistically significant effect of the botanical origin of honey on the semi-quantitative data of volatile compounds.
More specifically, 62 of the 94 volatile compounds were found to be significant (p < 0.05) for the botanical origin differentiation of honeys. Afterwards, these volatiles were subjected to LDA. The minimum tolerance level of the analysis was set at 0.001. Results showed that 4-terpineol, borneol, para-cymene, carvacrol methyl ether, thymoquinone, thymol, and eugenol did not pass the tolerance test. Therefore, these volatile compounds were excluded (SPSS program) a priori from the discriminant analysis. Therefore, 56 volatile compounds were subjected to LDA.
Results showed that six canonical discriminant functions were formed: Wilks’ Lambda = 0.000, X2 = 1624.974, df = 336, p = 0.000 for the first function; Wilks’ Lambda = 0.000, X2 = 1049.108, df = 275, p = 0.000 for the second function; Wilks’ Lambda = 0.006, X2 = 609.334, df = 216, p = 0.000 for the third function; Wilks’ Lambda = 0.032, X2 = 406.682, df = 159, p = 0.000 for the fourth function; Wilks’ Lambda = 0.122, X2 = 249.608, df = 104, p = 0.000 for the fifth function; and Wilks’ Lambda = 0.409, X2 = 106,005, df = 51, p = 0.000 for the sixth function.
The first discriminant function recorded the higher eigenvalue (127.977) and a canonical correlation of 0.996, accounting for 71.5% of total variance. The second discriminant function recorded a much lower eigenvalue (39.902) and a canonical correlation of 0.988, accounting for 22.3% of total variance. The third discriminant function recorded a much lower eigenvalue (4.530) and a canonical correlation of 0.905, accounting for 2.5% of total variance. Similarly, the fourth discriminant function recorded an even lower eigenvalue (2.764) and a canonical correlation of 0.857, accounting for 1.5% of total variance. Moreover, the fifth discriminant function had a lower eigenvalue (2.360) and a canonical correlation of 0.838, accounting for 1.3% of total variance. Finally, the sixth discriminant function had the lowest eigenvalue (1.446) and a canonical correlation of 0.769, accounting for 0.8% of total variance. All six discriminant functions accounted for 100% of total variance.
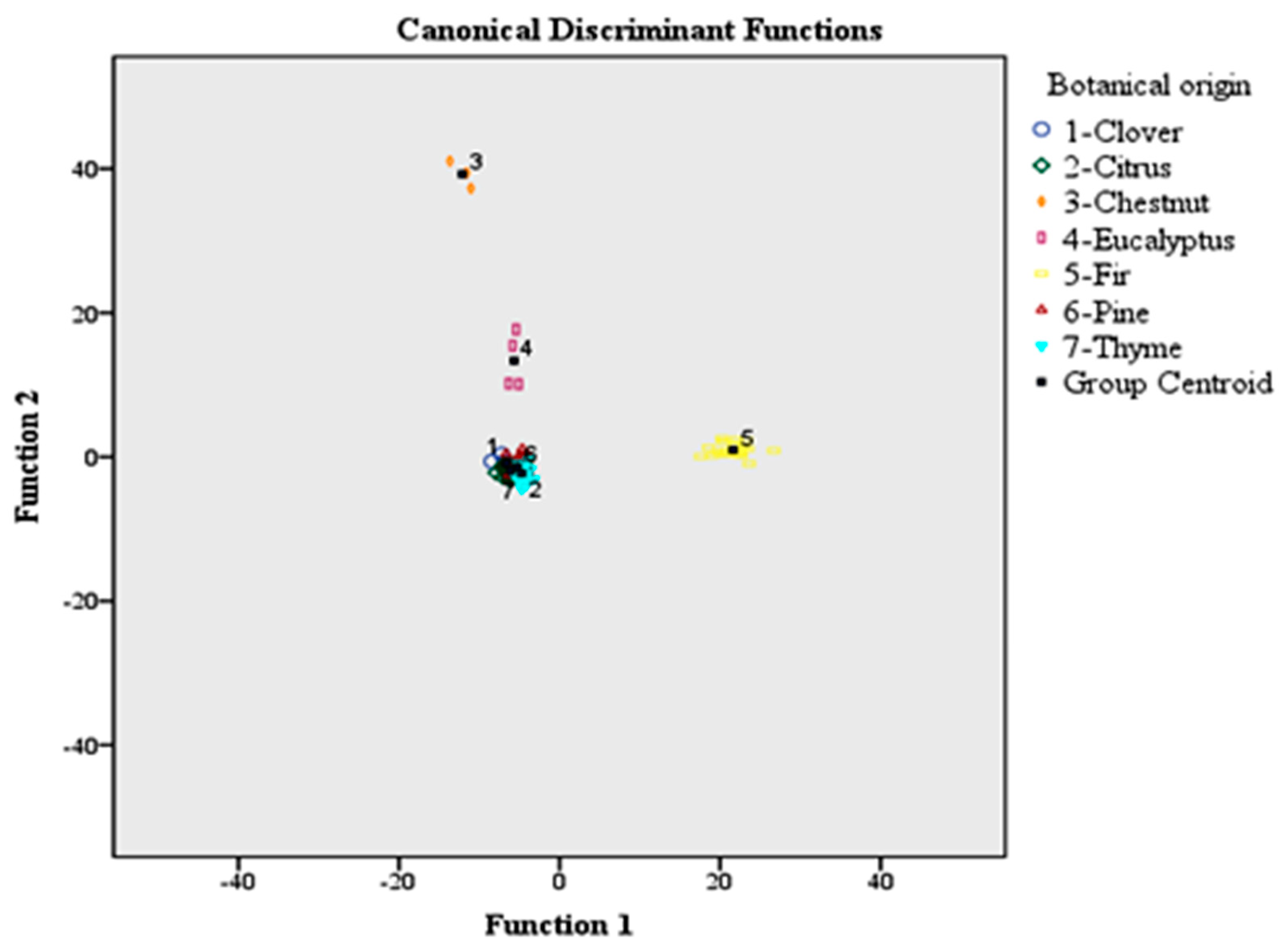
Figure 2 shows the differentiation of honeys according to botanical origin based on the use of 56 volatile compounds and LDA. The group centroid values which represent the unstandardized canonical discriminant functions evaluated at group means are also plotted. Each centroid gives information about the coordinates (discriminant functions) of the group means in the polyparametric space. The abscissa is the first discriminant function, and the ordinate is the second. So, the respective group centroid values were as follows: (−6.609, −0.891), (−6.081, −1.951), (−12.106, 39.255), (−5.664, 13.355), (21.632, 0.974), (−5.265, −1.395), and (−4.712, −2.268) for clover, citrus, chestnut, eucalyptus, fir, pine, and thyme honeys.
The classification rate was 95.4% using the original and 81.5% using the cross-validation method.
Supplementary Table S1 shows the significant variables (markers of botanical origin of clover, citrus, chestnut, eucalyptus, fir, pine, and thyme honeys) that were ordered by absolute size of correlation within function. The higher the absolute value of correlation, the best discrimination the variable provides within the discriminant function. The most pronounced markers of the botanical origin of honey are marked with an asterisk. In particular, octanoic acid ethyl ester, nonanoic acid ethyl ester, decanoic acid ethyl ester, dodecanoic acid ethyl ester, decanal, nonanal, 5-methyl-4-nonene, hexanoic acid ethyl ester, heptanoic acid ethyl ester, 4-ketoisophorone, octanol, tetradecanoic acid ethyl ester, geranyl acetone, 6-methyl-5-hepten-2-one, 1-(2-furanyl)-ethanone,
alpha-isophorone, and decanol contributed to discriminant function 1, whereas hexadecanoic acid ethyl ester contributed to discriminant function 2. It should be remembered that the first two discriminant functions explained 93.8% of total variance.
The botanical origin classification rate of honeys, based on the original method, followed the sequence: clover (87.5%), citrus (90.3%), chestnut (100%), eucalyptus (100%), fir (100%), pine (100%), and thyme (91.4%). In total, 12.5% of clover honeys (one sample) were allocated to pine honeys. In total, 9.7% of citrus honeys (three samples) were allocated to pine honeys. Finally, 8.6% of thyme honeys (three samples) were allocated to pine honeys.
On the contrary, the botanical origin classification rate of honeys, based on the cross-validation method followed the sequence: clover (62.5%), citrus (80.6%), chestnut (66.7%), eucalyptus (75%), fir (100%), pine (94.9%), and thyme (57.1%). In total, 25% of clover honeys (two samples) were allocated to pine honeys, whereas 12.5% of samples (one sample) were allocated to thyme honeys. In total, 19.4% of citrus honeys (six samples) were allocated to pine honeys. In total, 33.3% of chestnut honeys (one sample) were allocated to fir honeys. In total, 25% of eucalyptus honeys (one sample) were allocated to chestnut honeys. In total, 5.2% of pine honeys (two samples) were allocated in equal proportions (2.6%) to clover and chestnut honeys, respectively. Finally, 42.8% of thyme honeys were allocated to clover (11.4%) (four samples), citrus (2.9%) (one sample), chestnut (11.4%) (four samples), and pine (17.1%) (six samples) honeys, respectively (
Table 2).
It should be stressed that these results were accepted, given the fact that cross validation is a more pessimistic method of classification of a group of objects, since in cross validation, each case is classified by the functions derived from all cases rather than that particular case. The errors obtained in both classification techniques (original and cross-validation) reveal important findings regarding honey authentication. These errors show the contribution of numerous plants in the produced honeys, even in cases of honeydew honeys. Honeydew honeys are harvested after nectar honeys. Therefore, the contribution of flowering plants in honeydew honeys is quite common.
In addition, present findings may be related to beekeeper practices during the harvesting of different honey types. However, the classification results obtained support previous studies in the literature that focus on honey authentication using volatile compound analysis and chemometrics [
3,
4,
5,
8,
11]. The results obtained in the present study, which is collective in nature, show a clear differentiation of honeydew vs. nectar honeys.
K-Nearest Neighbors
For the k-NN analysis, the number of samples was randomly assigned to training and holdout partitions. The training sample consisted of 110 honey samples (72.8%), while the holdout sample consisted of 41 samples (27.2%). All cases (151 honey samples) (100%) were used in the statistical analysis, comprising a valid procedure.
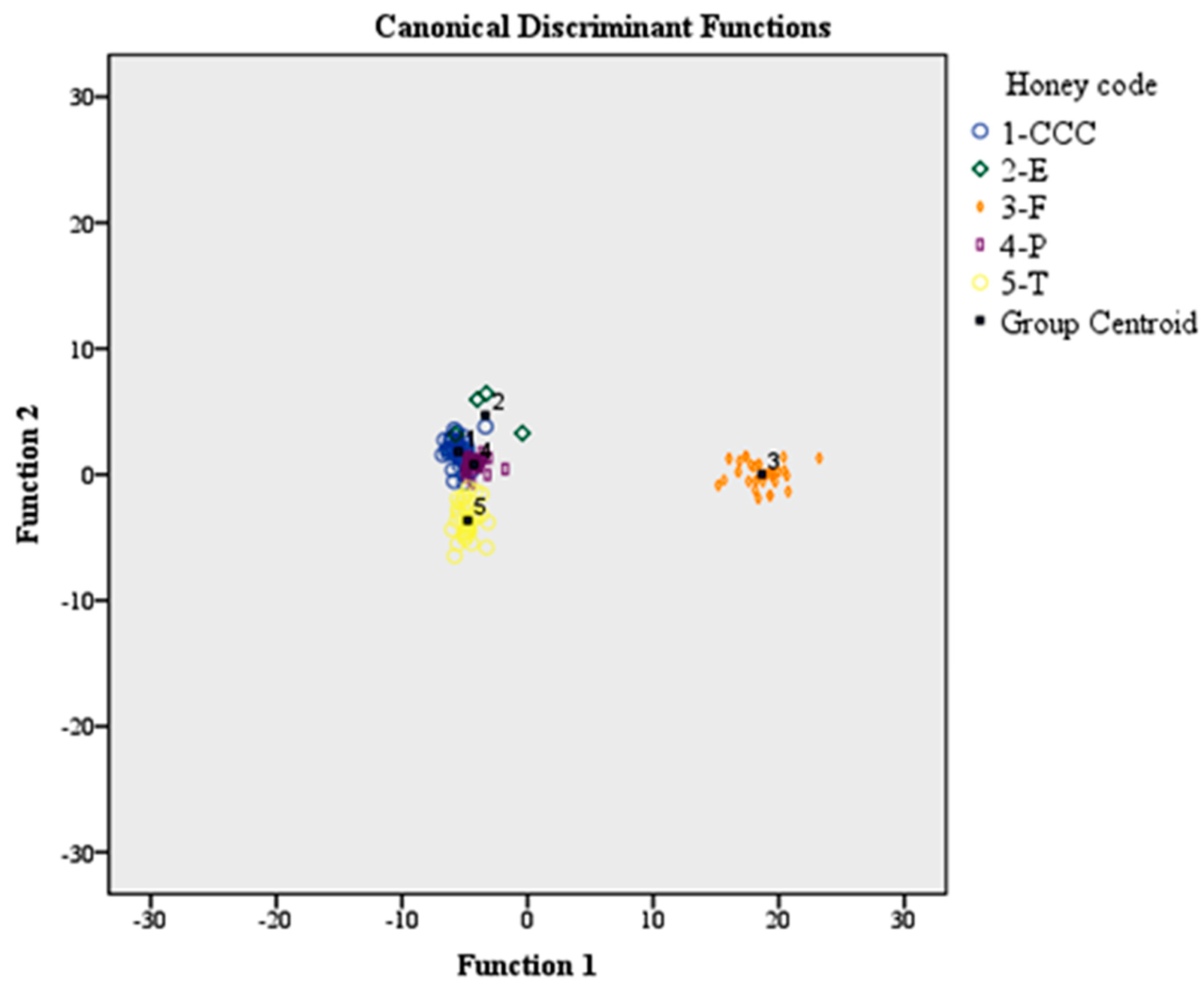
The overall classification rate was 77.3% for the training and 87.8% for the holdout sample and was satisfactory in both cases. The botanical origin classification rate of honey types for the training sample followed the sequence: clover (75%), citrus (70.8%), chestnut (0%), eucalyptus (0%), fir (95.8%), pine (92.3%), and thyme (58.3%). However, the zero classification rates of chestnut and eucalyptus honeys are attributed to the limited honey samples, since the majority of them were assigned to the holdout sample. Of the eight clover honey samples subjected to training analysis, six were assigned to clover and two to thyme honeys. Similarly, of the 24 citrus honey samples, 17 samples were assigned to citrus, one to clover, four to pine, and two to thyme honeys, respectively. One chestnut honey sample was assigned to eucalyptus honeys. Of the 24 fir honey samples, 23 were assigned to fir and only one to pine honeys. A similar trend was obtained for pine honeys—in which, 25 samples were assigned to pine and only one to fir honeys, respectively. Finally, of the 24 thyme honey samples, 14 were assigned to thyme, six to pine, three to clover, and one to citrus honeys, respectively.
Regarding the holdout sample classification rate, this was higher than the training sample by 10.5%. The botanical origin classification rate of honey types for the holdout sample followed the sequence: citrus (85.7%), chestnut (0%), eucalyptus (100%), fir (100%), pine (100%), and thyme (81.8%). The clover honeys were assigned previously to training sample. Therefore, no classification results were obtained. Of the seven citrus honey samples subjected to holdout analysis, six were assigned to citrus and one to pine honeys. Of the two chestnut honeys, one was assigned to citrus and one to eucalyptus honeys, respectively. Finally, of the 11 thyme honey samples, nine samples were assigned to thyme and two to pine, respectively (
Table 3).
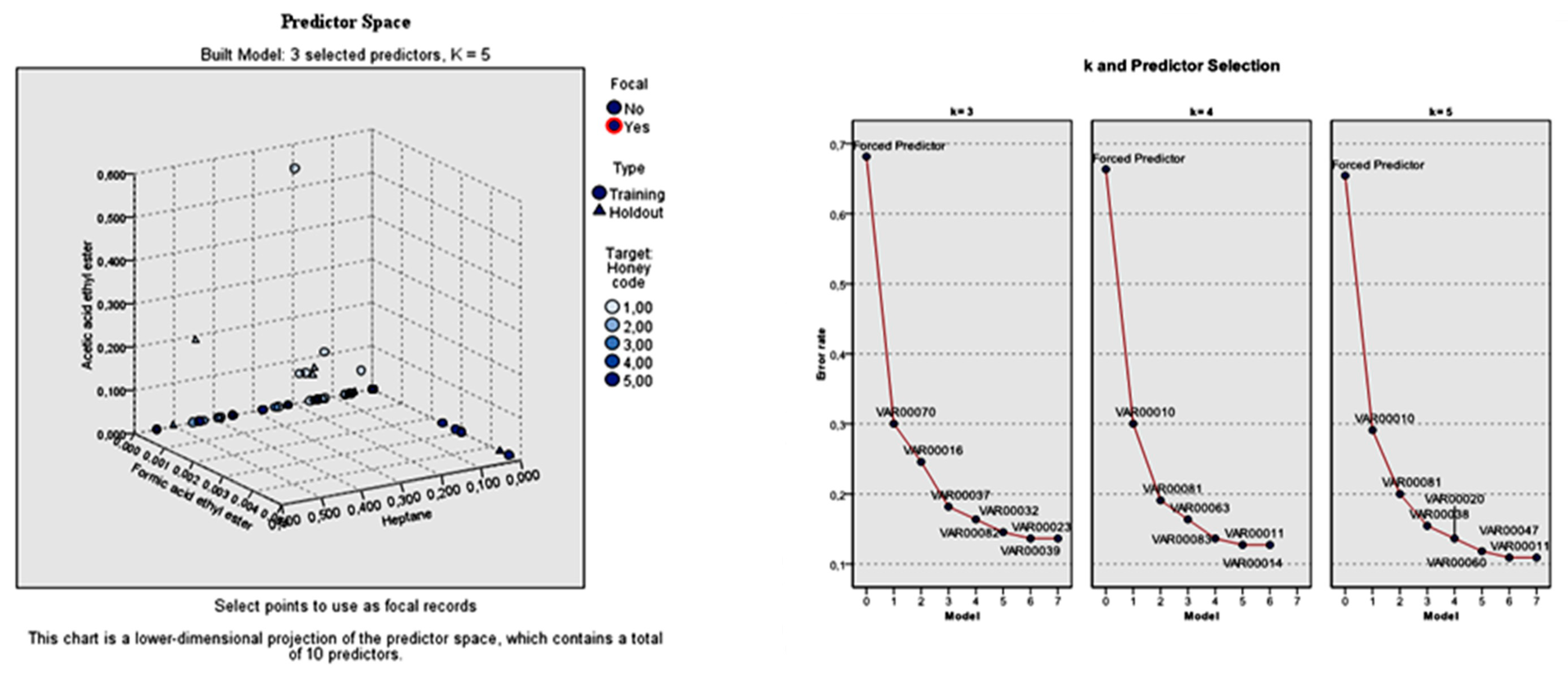
Among the 55 significant volatile compounds (predictors), the most effective predictors (k-nearest neighbors) that built the model were acetic acid ethyl ester, formic acid ethyl ester, and 2-methylbutanal. Based on this observation, the k-NN analysis was run again by performing feature selection in order to investigate whether the classification results could be improved. The selected features were the aforementioned volatile compounds.
For the specified
k-nearest neighbors analysis, the sample was divided again to training and holdout partitions. The training sample consisted of 100 honey samples (66.2%), whereas the holdout sample consisted of 51 (33.8%). Both partitions explained 100% of the procedure, indicating that all cases were valid. The analysis stopped when the absolute ratio was less than or equal to the minimum change, which was inserted by default equal to 0.01. The overall classification rate was 83% for the training and 74.5% for the holdout sample. The individual botanical classification rate was differentiated given the fact that the sample assignment to training and holdout partitions was also differentiated (
Table 4).
Considering the total standard error of the forced predictors, but also that of the individual predictors, the model built with k = 3 (nearest neighbors) was more applicable. The 10 predictors were the three specified predictors, followed by furfural, lilac aldehyde C, benzaldehyde, nonanol, para-cymene, 5-methyl-4-nonene, and nonane. The total error rate of the three specified features was 0.74. The respective individual error rate for the seven predictors left was: 0.39, 0.27, 0.25, 0.21, 0.18, 0.17, and 0.17.
On the contrary, the total error rate of the model built with
k = 4 nearest neighbors in relation to the three specified features was 0.75. The individual error rate for the seven predictors left was: 0.41, 0.28, 0.25, 0.23, 0.21, 0.20, and 0.20 for furfural, lilac aldehyde C, phenylethylalcohol, 5-methyl-4-nonene, 1-octen-3-ol, and nonane, respectively. The selection of the predictors during
k-NN analysis with
k = 3 and
k = 4 nearest neighbors according to the botanical origin of honey is shown in
Figure 3.
FA
During factor analysis, the 56 significant volatile compounds were reduced to 16 principal components (PCs) based on the rule of an eigenvalue greater than one. The rotated component matrix is given in
Supplementary Table S2. The total variance explained was 80.524% (ca. 80.52%).
The fitness of data for factor analysis was estimated by the Kaiser–Meyer–Olkin (KMO) test, which comprises a measure of the effective performance of factor analysis, to a set of data, indicating the sampling adequacy. The acceptable value was considered that of KMO ≥ 0.50. The suitability and applicability of factor analysis was further evaluated using Bartlett’s test of sphericity. This test highlights the hypothesis that the correlation matrix is an identity matrix, which would indicate that the variables incorporated into the model are unrelated and therefore unsuitable for structure detection. Small probability values (
p < 0.05) indicate that a factor analysis may be useful with data treatment [
20]. The value of the KMO test was 0.636. Furthermore, Bartlett’s test of sphericity had the following qualitative values: X
2 = 10,587.564, df = 1540, and
p = 0.000.
The factors that best explained the rotated component matrix were the following volatile compounds: Decanol (PC1, 10.454% of total variance), undecanoic acid ethyl ester (PC2, 10.380% of total variance), para-cymene (PC3, 7.768% of total variance), 2-hydroxyisophorone (PC4, 7.699% of total variance), nonane (PC5, 5.509% of total variance), dill ether (PC6, 5.058% of total variance), lilac aldehyde C (PC7, 4.412% of total variance), lilac aldehyde D (PC8, 4.352% of total variance), acetic acid ethyl ester (PC9, 3.918% of total variance), 5-methyl-2-phenylhexenal (PC10, 3.905% of total variance), decane (PC11, 3.596% of total variance), 1-(2-furanyl)-ethanone (PC12, 3.563% of total variance), benzeneacetonitrile (PC13, 3.240% of total variance), nonanol (PC14, 2.400% of total variance), 2-methylbutanal (PC15, 2.156% of total variance), and hexanoic acid ethyl ester (PC16, 2.113% of total variance).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}