

Predictive Analysis of Linoleic Acid in Red Meat Employing Advanced Ensemble Models of Bayesian and CNN-Bi-LSTM Decision Layer Fusion Based Hyperspectral Imaging
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Preparation
2.2. Determination of Chemical Values
2.3. Acquisition and Calibration of Hyperspectral Images
2.4. Extraction of Region of Interest and Division of the Data Set
2.5. Spectral Preprocessing and Selection of Characteristic Wavelengths
2.6. Model Construction
2.6.1. LSTM Networks and Bi-LSTM Networks
2.6.2. The Decision Layer Fusion Network Modeling Framework of the CNN and CNN-Bi-LSTM
2.6.3. Bayesian Algorithm Optimization
2.7. Modeling Evaluation
2.8. Data Analysis
3. Results and Discussion
3.1. Chemical Values and Spectral Curves
3.2. Outlier Detection and Division Prediction
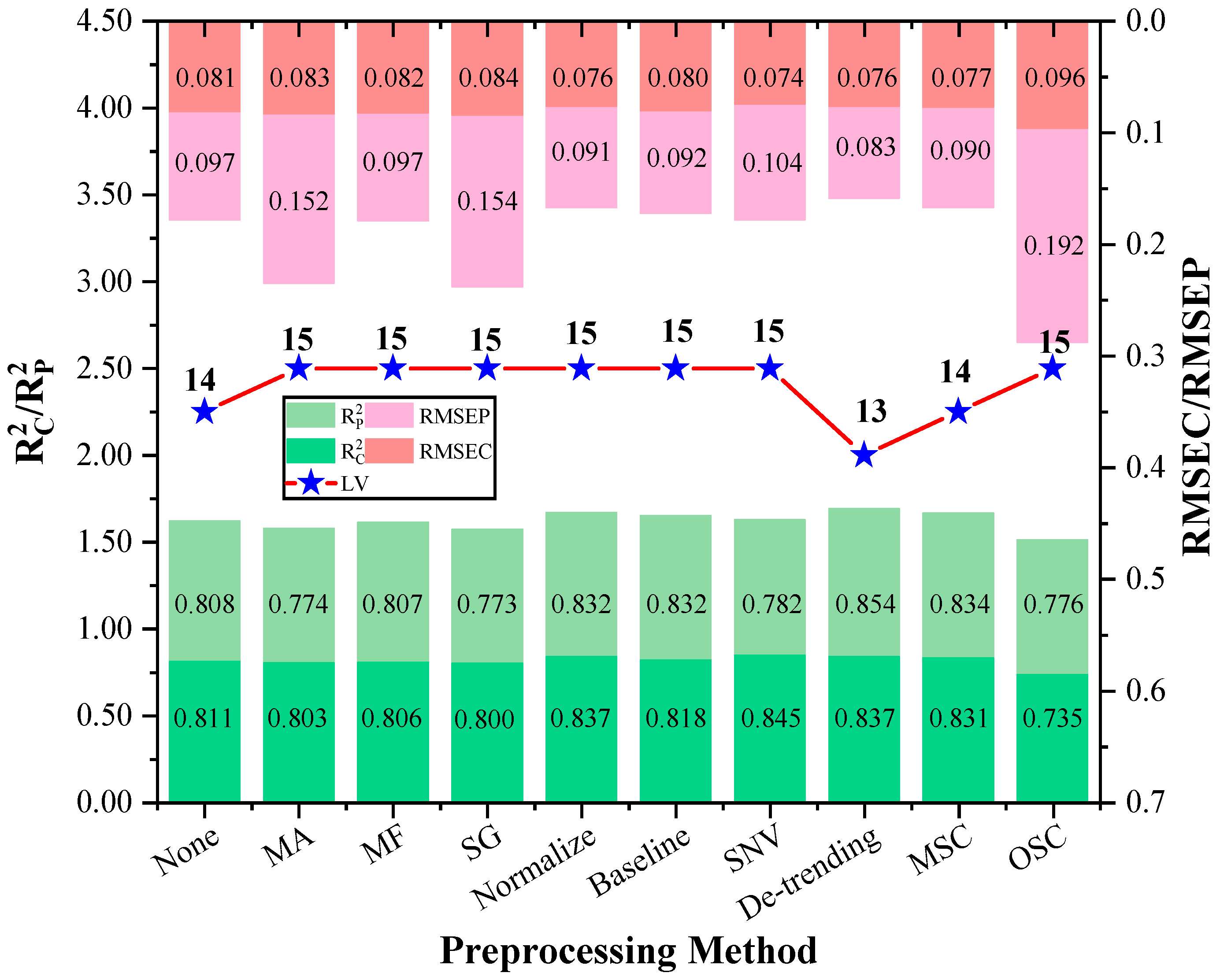
3.3. Spectral Data Preprocessing Methods
3.4. Modeling of Featured Wavelength Extraction
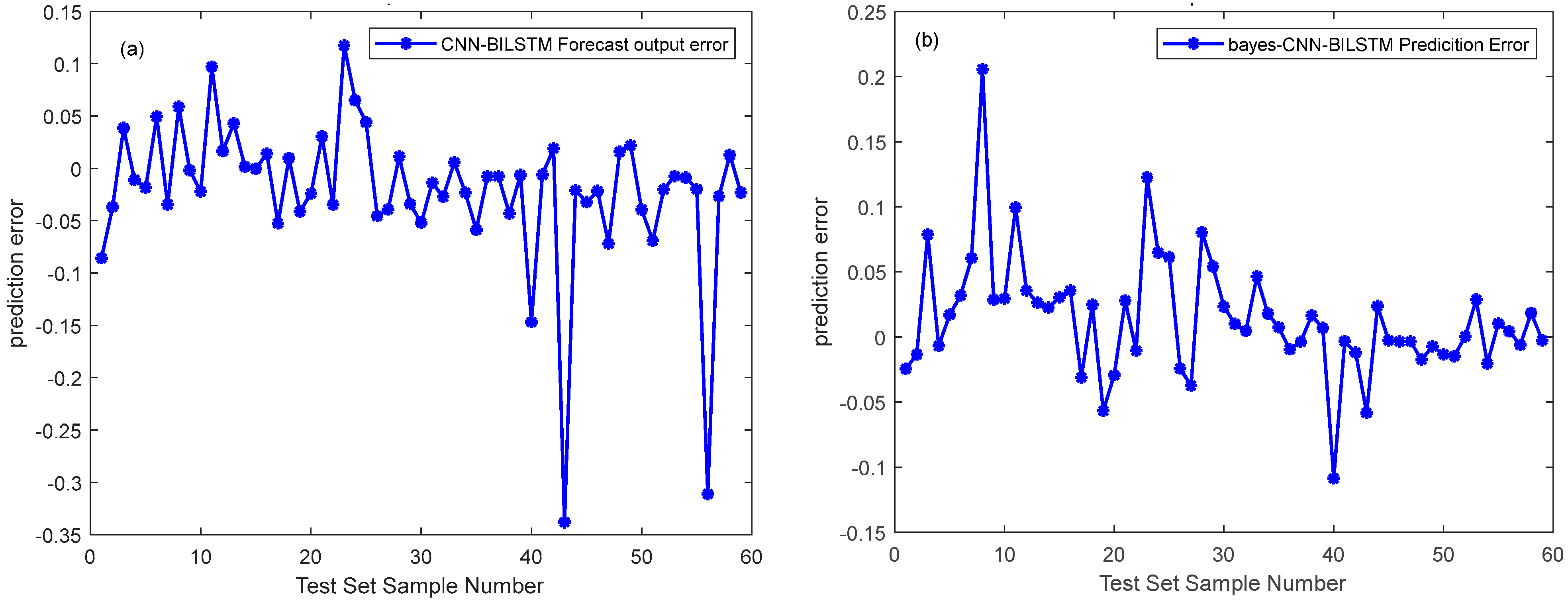
3.5. CNN-Bi-LSTM Network Model and Bayes-CNN-Bi-LSTM Model Framework
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McAfee, A.J.; McSorley, E.M.; Cuskelly, G.J. Red meat consumption, An overview of the risks and benefits. Meat Sci. 2010, 84, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.D.; Qing, L.W.; Yan, D.T. Hyperspectral imaging in combination with data fusion for rapid evaluation of tilapia fillet freshness. Food Chem. 2021, 348, 129129. [Google Scholar] [CrossRef]
- Valsta, L.M.; Tapanainen, H.; Männistö, S. Meat fats in nutrition. Meat Sci. 2005, 70, 525–530. [Google Scholar] [CrossRef] [PubMed]
- AJ, C. A prospective study of red and processed meat intake in relation to cancer risk. PLoS Med. 2007, 4, e325. [Google Scholar]
- Cao, Y.; Yao, X.; Ren, H. Determination of fatty acid composition and metallic element content of four Camellia species used for edible oil extraction in China. J. Consum. Prot. Food Saf. 2017, 12, 165–169. [Google Scholar] [CrossRef]
- Cheng, L.; Liu, G.; He, J. Non-destructive assessment of the myoglobin content of Tan sheep using hyperspectral imaging. Meat Sci. 2020, 167, 107988. [Google Scholar] [CrossRef]
- ElMasry, G.; Sun, D.W.; Allen, P. Non-destructive determination of water-holding capacity in fresh beef by using NIR hyperspectral imaging. Food Res. Int. 2011, 44, 2624–2633. [Google Scholar] [CrossRef]
- Mourot, B.P.; Gruffat, D.; Durand, D. Breeds and muscle types modulate performance of near-infrared reflectance spectroscopy to predict the fatty acid composition of bovine meat. Meat Sci. 2015, 99, 104–112. [Google Scholar] [CrossRef]
- Koca, N.; Rodriguez-Saona, L.E.; Harper, W.J. Application of Fourier transform infrared spectroscopy for monitoring short-chain free fatty acids in Swiss cheese. J. Dairy Sci. 2007, 90, 3596–3603. [Google Scholar] [CrossRef]
- Patil, A.G.; Oak, M.D.; Taware, S.P. Nondestructive estimation of fatty acid composition in soybean [Glycine max (L.) Merrill] seeds using near-infrared transmittance spectroscopy. Food Chem. 2010, 120, 1210–1217. [Google Scholar] [CrossRef]
- Sales-Campos, H.; Reis de Souza, P.; Crema Peghini, B. An overview of the modulatory effects of oleic acid in health and disease. Mini Rev. Med. Chem. 2013, 13, 201–210. [Google Scholar]
- Femenias, A.; Gatius, F.; Ramos, A.J. Use of hyperspectral imaging as a tool for Fusarium and deoxynivalenol risk management in cereals, A review. Food Control 2020, 108, 106819. [Google Scholar] [CrossRef]
- Baiano, A. Applications of hyperspectral imaging for quality assessment of liquid based and semi-liquid food products, A review. J. Food Eng. 2017, 214, 10–15. [Google Scholar] [CrossRef]
- Wang, C.; Wang, S.; He, X. Combination of spectra and texture data of hyperspectral imaging for prediction and visualization of palmitic acid and oleic acid contents in lamb meat. Meat Sci. 2020, 169, 108194. [Google Scholar] [CrossRef]
- Zhuang, Q.; Peng, Y.; Yang, D. Detection of frozen pork freshness by fluorescence hyperspectral image. J. Food Eng. 2022, 316, 110840. [Google Scholar] [CrossRef]
- Liu, S.; Dong, F.; Hao, J. Combination of hyperspectral imaging and entropy weight method for the comprehensive assessment of antioxidant enzyme activity in Tan mutton. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2023, 291, 122342. [Google Scholar] [CrossRef] [PubMed]
- Cui, J.; Li, K.; Hao, J. Identification of near geographical origin of wolfberries by a combination of hyperspectral imaging and multi-task residual fully convolutional network. Foods 2022, 11, 1936. [Google Scholar] [CrossRef] [PubMed]
- Al-Sarayreh, M.; Reis, M.M.; Yan, W.Q. Detection of red-meat adulteration by deep spectral–spatial features in hyperspectral images. J. Imaging 2018, 4, 63. [Google Scholar] [CrossRef]
- Jang, J.; Yang, G. A Bug Triage Technique Using Developer-Based Feature Selection and CNN-LSTM Algorithm. Appl. Sci. 2022, 12, 9358. [Google Scholar] [CrossRef]
- Xu, J.; He, Z.; Zhang, Y. CNN-LSTM combined network for IoT enabled fall detection applications. J. Phys. Conf. Ser. 2019, 1267, 012044. [Google Scholar]
- Li, H.; Lin, Z.; An, Z. Automatic electrocardiogram detection and classification using bidirectional long short-term memory network improved by Bayesian optimization. Biomed. Signal Process. Control 2022, 73, 103424. [Google Scholar] [CrossRef]
- Gao, J.; Zhao, L.; Li, J. Aflatoxin rapid detection based on hyperspectral with 1D-convolution neural network in the pixel level. Food Chem. 2021, 360, 129968. [Google Scholar] [CrossRef] [PubMed]
- Elegbede, C.F.; Papadopoulos, A.; Gauvreau, J. A Bayesian network to optimise sample size for food allergen monitoring. Food Control 2015, 47, 212–220. [Google Scholar] [CrossRef]
- Fleming, A.; Schenkel, F.S.; Chen, J. Prediction of milk fatty acid content with mid-infrared spectroscopy in Canadian dairy cattle using differently distributed model development sets. J. Dairy Sci. 2017, 100, 5073–5081. [Google Scholar] [CrossRef]
- Zhu, M.T.; Shi, T.; Chen, Y. Prediction of fatty acid composition in camellia oil by 1H NMR combined with PLS regression. Food Chem. 2019, 279, 339–346. [Google Scholar] [CrossRef] [PubMed]
- Christopherson, S.W.; Glass, R.L. Preparation of milk fat methyl esters by alcoholysis in an essentially nonalcoholic solution. J. Dairy Sci. 1969, 52, 1289–1290. [Google Scholar] [CrossRef]
- Dong, F.; Bi, Y.; Hao, J. A combination of near-infrared hyperspectral imaging with two-dimensional correlation analysis for monitoring the content of alanine in beef. Biosensors 2022, 12, 1043. [Google Scholar] [CrossRef] [PubMed]
- Lu, Z.; Lu, R.; Chen, Y. Nondestructive testing of pear based on Fourier near-infrared spectroscopy. Foods 2022, 11, 1076. [Google Scholar] [CrossRef] [PubMed]
- Galvao, R.K.H.; Araujo, M.C.U.; José, G.E. A method for calibration and validation subset partitioning. Talanta 2005, 67, 736–740. [Google Scholar] [CrossRef] [PubMed]
- Wan, G.; Liu, G.; He, J. Feature wavelength selection and model development for rapid determination of myoglobin content in nitrite-cured mutton using hyperspectral imaging. J. Food Eng. 2020, 287, 110090. [Google Scholar] [CrossRef]
- Gao, S.; Xu, J. Hyperspectral image information fusion-based detection of soluble solids content in red globe grapes. Comput. Electron. Agric. 2022, 196, 106822. [Google Scholar] [CrossRef]
- Fu, J.; Yu, H.D.; Chen, Z. A review on hybrid strategy-based wavelength selection methods in analysis of near-infrared spectral data. Infrared Phys. Technol. 2022, 125, 104231. [Google Scholar] [CrossRef]
- Konda Naganathan, G.; Grimes, L.M.; Subbiah, J. Partial least squares analysis of near-infrared hyperspectral images for beef tenderness prediction. Sens. Instrum. Food Qual. Saf. 2008, 2, 178–188. [Google Scholar] [CrossRef]
- Yuan, R.; Liu, G.; He, J. Classification of Lingwu long jujube internal bruise over time based on visible near-infrared hyperspectral imaging combined with partial least squares-discriminant analysis. Comput. Electron. Agric. 2021, 182, 106043. [Google Scholar] [CrossRef]
- Fujia, D.; Yongzhao, B.; Jie, H. A new comprehensive quantitative index for the assessment of essential amino acid quality in beef using Vis-NIR hyperspectral imaging combined with LSTM. Food Chem. 2024, 440, 138040. [Google Scholar]
- Yu, J.; Liu, G.; Zhang, J. Correlation among serum biochemical indices and slaughter traits, texture characteristics and water-holding capacity of Tan sheep. Ital. J. Anim. Sci. 2021, 20, 1781–1790. [Google Scholar] [CrossRef]
- Yang, S.; Tan, M.L.; Song, Q. Coupling SWAT and Bi-LSTM for improving daily-scale hydro-climatic simulation and climate change impact assessment in a tropical river basin. J. Environ. Manag. 2023, 330, 117244. [Google Scholar] [CrossRef] [PubMed]
- Acquarelli, J.; van Laarhoven, T.; Gerretzen, J. Convolutional neural networks for vibrational spectroscopic data analysis. Anal. Chim. Acta 2017, 954, 22–31. [Google Scholar] [CrossRef]
- Huang, Z.; Ma, Y.; Wang, R. A Model for EEG-Based Emotion Recognition, CNN-Bi-LSTM with Attention Mechanism. Electronics 2023, 12, 3188. [Google Scholar] [CrossRef]
- Quan, P.; Lou, Y.; Lin, H. Research on Fast Identification and Location of Contour Features of Electric Vehicle Charging Port in Complex Scenes. IEEE Access 2021, 10, 26702–26714. [Google Scholar] [CrossRef]
- Sasank, V.V.S.; Venkateswarlu, S. An automatic tumour growth prediction based segmentation using full resolution convolutional network for brain tumour. Biomed. Signal Process. Control 2022, 71, 103090. [Google Scholar] [CrossRef]
- Liu, K.; Cheng, J.; Yi, J. Copper price forecasted by hybrid neural network with Bayesian Optimization and wavelet transform. Resour. Policy 2022, 75, 102520. [Google Scholar] [CrossRef]
- Chen, X.; Jiao, Y.; Liu, B. Using hyperspectral imaging technology for assessing internal quality parameters of persimmon fruits during the drying process. Food Chem. 2022, 386, 132774. [Google Scholar] [CrossRef]
- Craigie, C.R.; Johnson, P.L.; Shorten, P.R. Application of Hyperspectral imaging to predict the pH, intramuscular fatty acid content and composition of lamb M. longissimus lumborum at 24 h post mortem. Meat Sci. 2017, 132, 19–28. [Google Scholar] [CrossRef]
- Ebrahimi, M.; Rajion, M.A.; Goh, Y.M. Impact of different inclusion levels of oil palm (Elaeis guineensis Jacq.) fronds on fatty acid profiles of goat muscles. J. Anim. Physiol. Anim. Nutr. 2012, 96, 962–969. [Google Scholar] [CrossRef] [PubMed]
- Guo, B.L.; Wei, Y.M.; Pan, J.R. Stable C and N isotope ratio analysis for regional geographical traceability of cattle in China. Food Chem. 2010, 118, 915–920. [Google Scholar] [CrossRef]
- Jia, B.; Yoon, S.C.; Zhuang, H. Prediction of pH of fresh chicken breast fillets by VNIR hyperspectral imaging. J. Food Eng. 2017, 208, 57–65. [Google Scholar] [CrossRef]
- Sanz, J.A.; Fernandes, A.M.; Barrenechea, E. Lamb muscle discrimination using hyperspectral imaging, Comparison of various machine learning algorithms. J. Food Eng. 2016, 174, 92–100. [Google Scholar] [CrossRef]
- Weng, S.; Guo, B.; Du, Y. Feasibility of authenticating mutton geographical origin and breed via hyperspectral imaging with effective variables of multiple features. Food Anal. Methods 2021, 14, 834–844. [Google Scholar] [CrossRef]
- Scollan, N.D.; Choi, N.J.; Kurt, E. Manipulating the fatty acid composition of muscle and adipose tissue in beef cattle. Br. J. Nutr. 2001, 85, 115–124. [Google Scholar] [CrossRef]
- Chen, D.; Wu, P.; Wang, K. Combining computer vision score and conventional meat quality traits to estimate the intramuscular fat content using machine learning in pigs. Meat Sci. 2022, 185, 108727. [Google Scholar] [CrossRef]
- Wang, W.; Peng, Y.; Sun, H. Spectral detection techniques for non-destructively monitoring the quality, safety, and classification of fresh red meat. Food Anal. Methods 2018, 11, 2707–2730. [Google Scholar] [CrossRef]
- Kalisch, M.; Michalak, M.; Sikora, M. Influence of outliers introduction on predictive models quality//Beyond Databases, Architectures and Structures. In Advanced Technologies for Data Mining and Knowledge Discovery: 12th International Conference, BDAS 2016, Ustroń, Poland, 31 May–3 June 2016, Proceedings 11; Springer International Publishing: New York, NY, USA, 2016; pp. 79–93. [Google Scholar]
- Cao, D.S.; Liang, Y.Z.; Xu, Q.S. A new strategy of outlier detection for QSAR/QSPR. J. Comput. Chem. 2010, 31, 592–602. [Google Scholar] [CrossRef]
- Mehmood, T.; Liland, K.H.; Snipen, L. A review of variable selection methods in partial least squares regression. Chemom. Intell. Lab. Syst. 2012, 118, 62–69. [Google Scholar] [CrossRef]
- Sun, Y.; Ding, S.; Zhang, Z. An improved grid search algorithm to optimize SVR for prediction. Soft Comput. 2021, 25, 5633–5644. [Google Scholar] [CrossRef]
- Gao, T.; Hu, L.; Jia, Z. SPXYE: An improved method for partitioning training and validation sets. Clust. Comput. 2019, 22, 3069–3078. [Google Scholar] [CrossRef]
- Carbone, A.; Kiyono, K. Detrending moving average algorithm: Frequency response and scaling performances. Phys. Rev. E 2016, 93, 063309. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E.; Long, S.R. On the trend, detrending, and variability of nonlinear and nonstationary time series. Proc. Natl. Acad. Sci. USA 2007, 104, 14889–14894. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.H.T.; Phan, Q.B. Hourly day ahead wind speed forecasting based on a hybrid model of EEMD, CNN-Bi-LSTM embedded with GA optimization. Energy Rep. 2022, 8, 53–60. [Google Scholar] [CrossRef]
- Ranftl, S.; Melito, G.M.; Badeli, V. Bayesian uncertainty quantification with multi-fidelity data and gaussian processes for impedance cardiography of aortic dissection. Entropy 2019, 22, 58. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Samples Removal | Number of Samples | LVs | Calibration Set | Verification Set | ||
|---|---|---|---|---|---|---|
| Rc2 | RMSEC | Rcv2 | RMSECV | |||
| Before elimination | 252 | 16 | 0.724 | 0.111 | 0.691 | 0.118 |
| After elimination | 244 | 12 | 0.805 | 0.087 | 0.786 | 0.098 |
| Datasets | Sample | Partition Method | LVs | R2 | RMSE | SE |
|---|---|---|---|---|---|---|
| Calibration set | 183 | KS | 15 | 0.794 | 0.097 | 0.097 |
| SPXY | 10 | 0.789 | 0.098 | 0.098 | ||
| RS | 14 | 0.811 | 0.081 | 0.082 | ||
| Prediction set | 61 | KS | 15 | 0.700 | 0.072 | 0.071 |
| SPXY | 10 | 0.739 | 0.060 | 0.060 | ||
| RS | 14 | 0.808 | 0.097 | 0.098 |
| Method | Partition Method | Numbers | Calibration Set | Prediction Set | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Rc2 | MSE | RMSE | MAE | Rp2 | MSE | RMSE | MAE | |||
| LSTM | UVE | 20 | 0.720 | 0.057 | 0.238 | 0.221 | 0.757 | 0.009 | 0.087 | 0.071 |
| VCPA | 11 | 0.821 | 0.072 | 0.269 | 0.256 | 0.809 | 0.020 | 0.109 | 0.075 | |
| CARS | 17 | 0.750 | 0.056 | 0.237 | 0.220 | 0.776 | 0.007 | 0.084 | 0.058 | |
| iVISSA | 45 | 0.756 | 0.063 | 0.250 | 0.236 | 0.740 | 0.011 | 0.107 | 0.072 | |
| IRIV | 52 | 0.724 | 0.077 | 0.277 | 0.261 | 0.745 | 0.008 | 0.093 | 0.065 | |
| Bi-LSTM | UVE | 20 | 0.774 | 0.075 | 0.230 | 0.210 | 0.787 | 0.007 | 0.086 | 0.062 |
| VCPA | 11 | 0.846 | 0.064 | 0.253 | 0.233 | 0.860 | 0.013 | 0.115 | 0.073 | |
| CARS | 17 | 0.790 | 0.076 | 0.276 | 0.260 | 0.810 | 0.007 | 0.085 | 0.064 | |
| iVISSA | 45 | 0.742 | 0.074 | 0.272 | 0.257 | 0.800 | 0.016 | 0.098 | 0.081 | |
| IRIV | 52 | 0.760 | 0.065 | 0.256 | 0.240 | 0.789 | 0.007 | 0.089 | 0.062 | |
| Method | Calibration Set | Prediction Set | ||||||
|---|---|---|---|---|---|---|---|---|
| Rc2 | RMSE | MSE | RPD | Rp2 | RMSE | MSE | RPD | |
| CNN-Bi-LSTM | 0.960 | 0.042 | 0.002 | 5.349 | 0.889 | 0.074 | 0.005 | 3.131 |
| Bayes-CNN-Bi-LSTM | 0.932 | 0.059 | 0.004 | 4.073 | 0.909 | 0.067 | 0.004 | 3.445 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, X.; Liu, S.; Wang, S.; Cui, J.; Wang, Y.; Lv, Y.; Li, H.; Feng, Y.; Luo, R.; Zhang, Z.; et al. Predictive Analysis of Linoleic Acid in Red Meat Employing Advanced Ensemble Models of Bayesian and CNN-Bi-LSTM Decision Layer Fusion Based Hyperspectral Imaging. Foods 2024, 13, 424. https://doi.org/10.3390/foods13030424
Yan X, Liu S, Wang S, Cui J, Wang Y, Lv Y, Li H, Feng Y, Luo R, Zhang Z, et al. Predictive Analysis of Linoleic Acid in Red Meat Employing Advanced Ensemble Models of Bayesian and CNN-Bi-LSTM Decision Layer Fusion Based Hyperspectral Imaging. Foods. 2024; 13(3):424. https://doi.org/10.3390/foods13030424
Chicago/Turabian StyleYan, Xiuwei, Sijia Liu, Songlei Wang, Jiarui Cui, Yongrui Wang, Yu Lv, Hui Li, Yingjie Feng, Ruiming Luo, Zhifeng Zhang, and et al. 2024. "Predictive Analysis of Linoleic Acid in Red Meat Employing Advanced Ensemble Models of Bayesian and CNN-Bi-LSTM Decision Layer Fusion Based Hyperspectral Imaging" Foods 13, no. 3: 424. https://doi.org/10.3390/foods13030424