1. Introduction
Peanut (
Arachis hypogaea L.) is an important raw material for edible oil production, which contains nutrients such as proteins, carbohydrates, lipids, and vitamins [
1]. Frequent consumption of peanuts can effectively reduce the risk of cardiovascular disease [
2,
3]. However, peanuts are prone to mildew in a humid and muggy environment. Toxins such as aflatoxins in moldy peanuts are carcinogenic and mutagenic to humans [
4,
5]. Therefore, it is necessary to screen out these moldy peanuts in food production. Hyperspectral technology is often used for rapid non-destructive testing of agricultural products [
6,
7,
8]. In previous studies, researchers have used hyperspectral technology to identify moldy peanuts [
9,
10,
11,
12]. For example, He et al. used visible-near infrared hyperspectral images to classify 150 peanuts naturally polluted by aflatoxin B1 at the particle level, and achieved a classification accuracy of 94% on the support vector machines (SVM) classifier [
9]. Liu et al. used 400–1000 nm hyperspectral images to classify 2171 peanuts and constructed a band selection model for feature selection to identify healthy, moldy, and damaged peanuts. The classification accuracy of 97.66% was achieved when 10 feature bands were used in the ShuffleNet V2 model [
10]. Therefore, it is feasible to carry out the identification of moldy peanuts based on hyperspectral technology.
In production, peanuts are usually exposed to the sun after harvest to remove excess moisture. According to the national standard GBT1532-2008 of China, the moisture content of sun-dried peanuts is generally less than 9%. In a humid environment, dry peanuts will absorb moisture from the environment and become moldy, and their moisture content will increase. In this way, the quality and moisture content of the same batch of peanuts will change greatly. In the study of moldy peanut identification, some researchers use oven drying or exposure to control the potential effect of moisture content on the spectrum [
13,
14,
15]. Some researchers directly used the original sample [
9,
16]. The peanut moisture content in actual production, especially the moisture content of different batches or different treatment conditions, will be quite different. However, there is a lack of study on the effect of peanut moisture content on classification in the current research.
Many studies have proved that the difference in moisture content will affect the identification accuracy of objects [
17,
18,
19]. For example, when identifying wood types, Russ et al. found that the successful recognition rate of wet wood chips was higher than that of dry wood chips [
17]. Wei et al. identified the main fungi of moldy walnut and the effects of storage conditions on walnut kernels. It was found that the effect of moisture content was greater than that of temperature and relative humidity [
19]. In the actual production, in addition to moisture content, there may also be impurity, germination, variety, clay, and other factors. Therefore, the scenario on the production line will be more complex than that of the training set used in model training. That is, the scenario of the test set will be more complex than that of the training set. To reduce and eliminate the influence of potential factors, data augmentation during model training is an effective way to improve the generalization ability and robustness of the model.
The common data augmentation methods mainly include four categories. One is based on geometric transformation, such as flipping, rotation, translation, scaling, clipping, and so on. For example, the Cutmix method [
20] replaces a rectangular region in one image with a rectangular region of the same size in another image. Mosaic Data Augmentation [
21] uses four images for random clipping, scaling, rotation, and other operations to synthesize an image, which is often used for data augmentation in target detection. The second is the method based on color transformation, including adding random noise, blur, color transformation, and so on. For example, the Cutout method [
22] generates new data by randomly erasing rectangles of indefinite position and size. The third is the method based on the idea of interpolation [
23,
24,
25,
26], such as SMOTE [
25] and Mixup [
27]. The principle of the Mixup method is to generate new samples by multi-sample weighting. Although it has a certain effect on improving the classification accuracy, the texture features of the new samples are destroyed and the interpretability is poor. The fourth is the method based on image generation, that is, the method of generative adversarial networks (GAN) [
28,
29,
30,
31] series. From GAN [
32], conditional generative adversarial networks (cGAN) [
33] to deep convolutional generative adversarial networks (DCGAN) [
34], stacked generative adversarial networks (StackGAN) [
35], and so on, the problem of mode collapse and vanishing gradients in this kind of method has not been well addressed [
36,
37], which makes the training process unstable and leads to the instability of the quality of the generated data.
Moreover, for hyperspectral images, Acción et al. constructed a dual-window superpixel method to generate new data by flipping and mirroring the internal regions of the patch images [
38]. Li et al. constructed a hyperspectral data augmentation method called pixel block pair [
39]. Qin et al. combined the Hapke equation and a priori knowledge of hyperspectral reflection to construct a new data augmentation method for mineral analysis [
40]. Haut et al. built a data augmentation method by randomly occluding the interior of image blocks [
41], which is similar to the idea of Cutout. Miftahushudur et al. expanded the training data from the perspective of color temperature through spectral correction under three color temperature scenarios [
42]. In addition, researchers proposed the data augmentation method by adding or subtracting the spectral mean [
43] or standard deviation [
44] from the original data. These methods build corresponding data augmentation methods for specific research objects and scenes. Their feasibility in peanut data needs to be verified.
In this paper, the peanut was taken as the research object, and moisture content was used as the influencing factor to study the hyperspectral data augmentation method suitable for moldy peanut identification. The specific objectives were to: (1) study the effect of moisture difference on the identification of moldy peanuts; (2) compare the identification effect of different classifiers on different varieties of peanut; (3) analyze the effect of different data augmentation methods on improving the identification accuracy.
2. Materials and Methods
2.1. Peanut Mildew Experiment
2.1.1. Experimental Control of Peanut Mildew
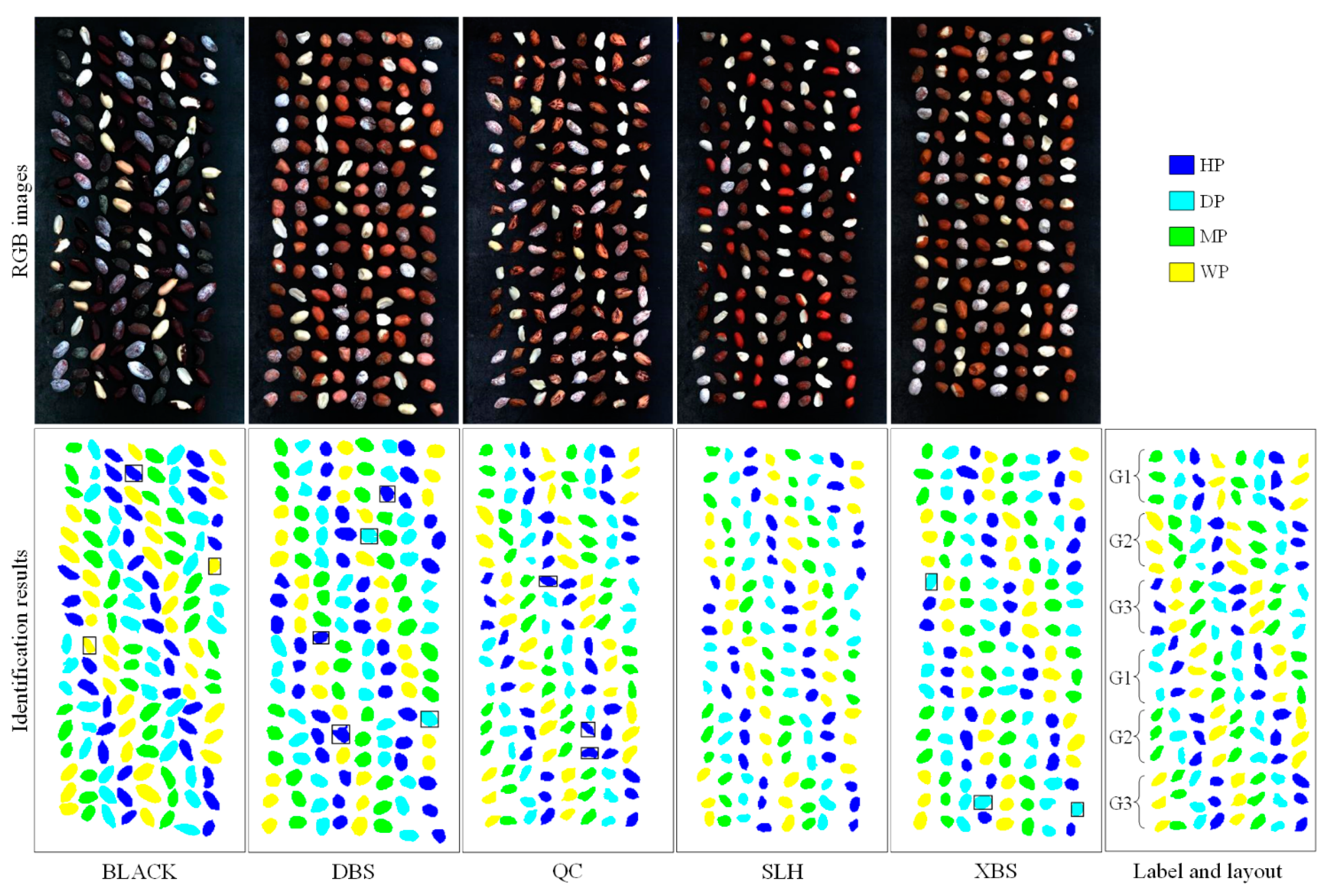
Five varieties of peanuts including Silihong (SLH), Dabaisha (DBS), Black peanut (BLACK), Qicai (QC), and Xiaobaisha (XBS) were selected for the experiment. Each variety was about 4 kg. The peanuts were divided into healthy peanuts (HP), damaged peanuts (DP), moldy peanuts (MP), and white moldy peanuts (WP). Among them, healthy peanuts are complete and shelled healthy peanuts. In the process of peanut machine screening, damaged peanuts are the category that often needs to be screened, so damaged peanuts are also included in this experiment. Moreover, damaged peanuts include peanuts with damaged seed coats and peanuts with broken kernels.
Moldy peanuts were obtained by natural mildew of peanuts through a constant temperature and humidity incubator. The control conditions were 35 °C and 80% relative humidity. To obtain samples with different mildew degrees, the mildew process was divided into three periods, and samples were collected at the end of each period. According to the mildew degree of peanuts, the first period was from the beginning to the 14th day. The second period was from 14 to 21 days, and the third period was from 21 to 28 days. In the first period, the mold changed slowly. It changed rapidly in the second and third periods. In addition, the mildew process of peanuts in their natural state is uneven. Therefore, all the samples in the incubator were fully shaken every two days in all experimental periods, so that all peanut kernels were infected by mold.
In addition to Aspergillus flavus, peanuts may also be infected by other molds to form black or white mildew spots. In our previous experiments, we found that peanuts that were soaked in water were prone to produce white mold. To obtain moldy peanuts of this character, the peanuts were put into a sealed plastic box and sprayed with the proper amount of water every two days. After the same period, the white moldy peanuts were obtained.
The color and texture features of moldy peanuts are different from those of healthy peanuts. To confirm that the cultured moldy peanuts produced aflatoxin, we commissioned the Agricultural Products Quality Supervision, Inspection, and Test Center of China Agricultural University to detect the aflatoxin content of moldy peanuts and white moldy peanuts. According to commission regulation, NO 165/2010 released by the European Union, the sum of aflatoxin B1, aflatoxin B2, aflatoxin G1, and aflatoxin G2 of peanuts directly for human consumption or as food ingredients cannot exceed 4 ug/kg. The results showed that the toxin content of all moldy peanuts had greatly exceeded the threshold. Therefore, it is considered that the peanut samples used in the experiment are accurate.
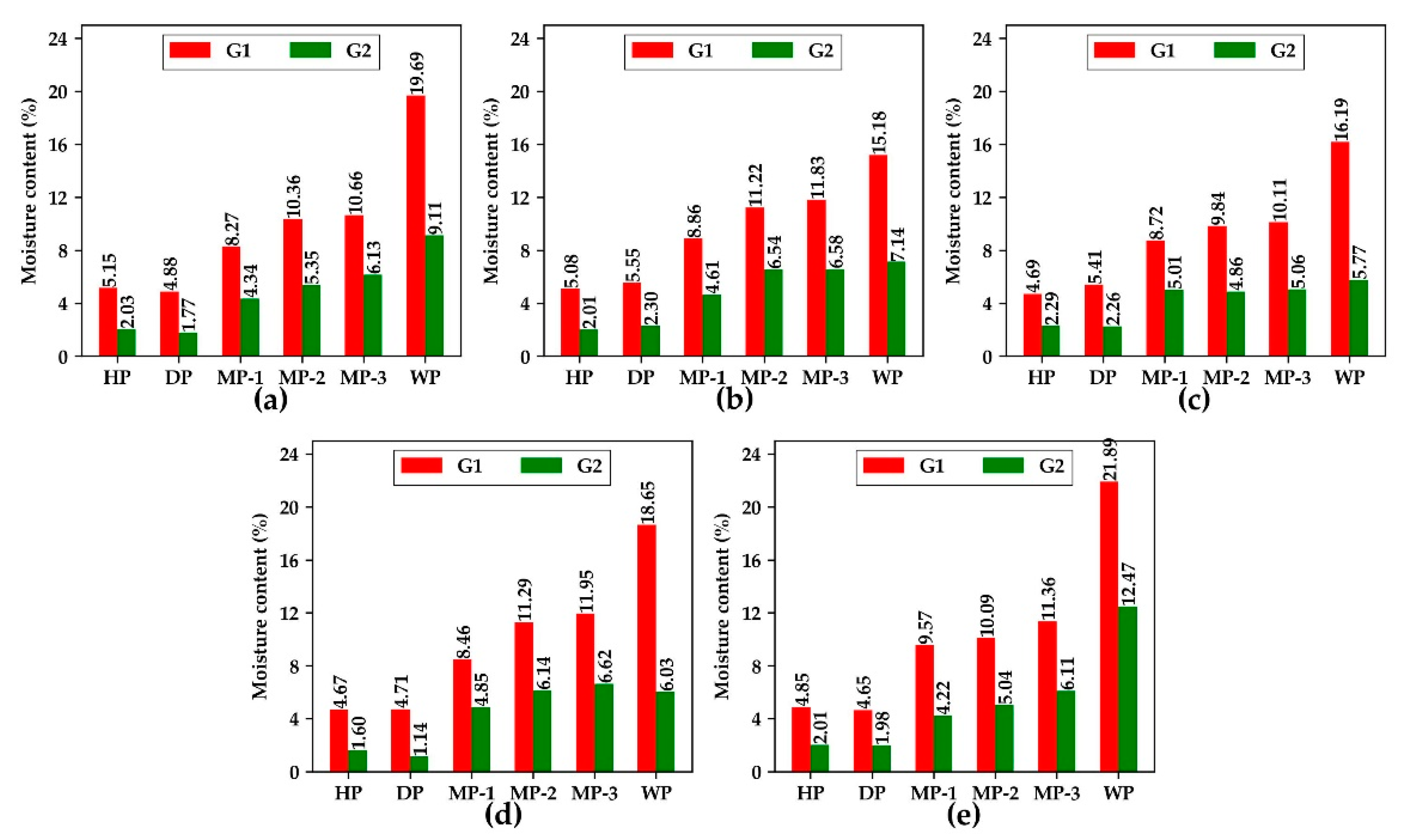
2.1.2. Controlling the Moisture Content Gradient of Peanut
To control the moisture content gradient of peanuts, some samples were used to bake at 70 °C and weighed every 2 h to observe the weight changes of peanuts. It was found that the moisture content of peanuts decreased to about half of the original moisture content after baking for 4 h. Therefore, the untreated peanut samples were taken as the first moisture content gradient. The samples dried at 70 °C for 4 h as the second moisture content gradient, and the samples dried at 70 °C to constant weight as the third moisture content gradient. The three gradients were named G1, G2, and G3, respectively. The following Formula (1) was used to calculate the moisture content (wet basis) of each gradient peanut:
where
is the moisture content of peanut,
is the weight of utensil and samples before baking,
is the weight of utensil and samples after baking, and
is the weight of utensil.
2.2. Data Acquisition and Preprocessing
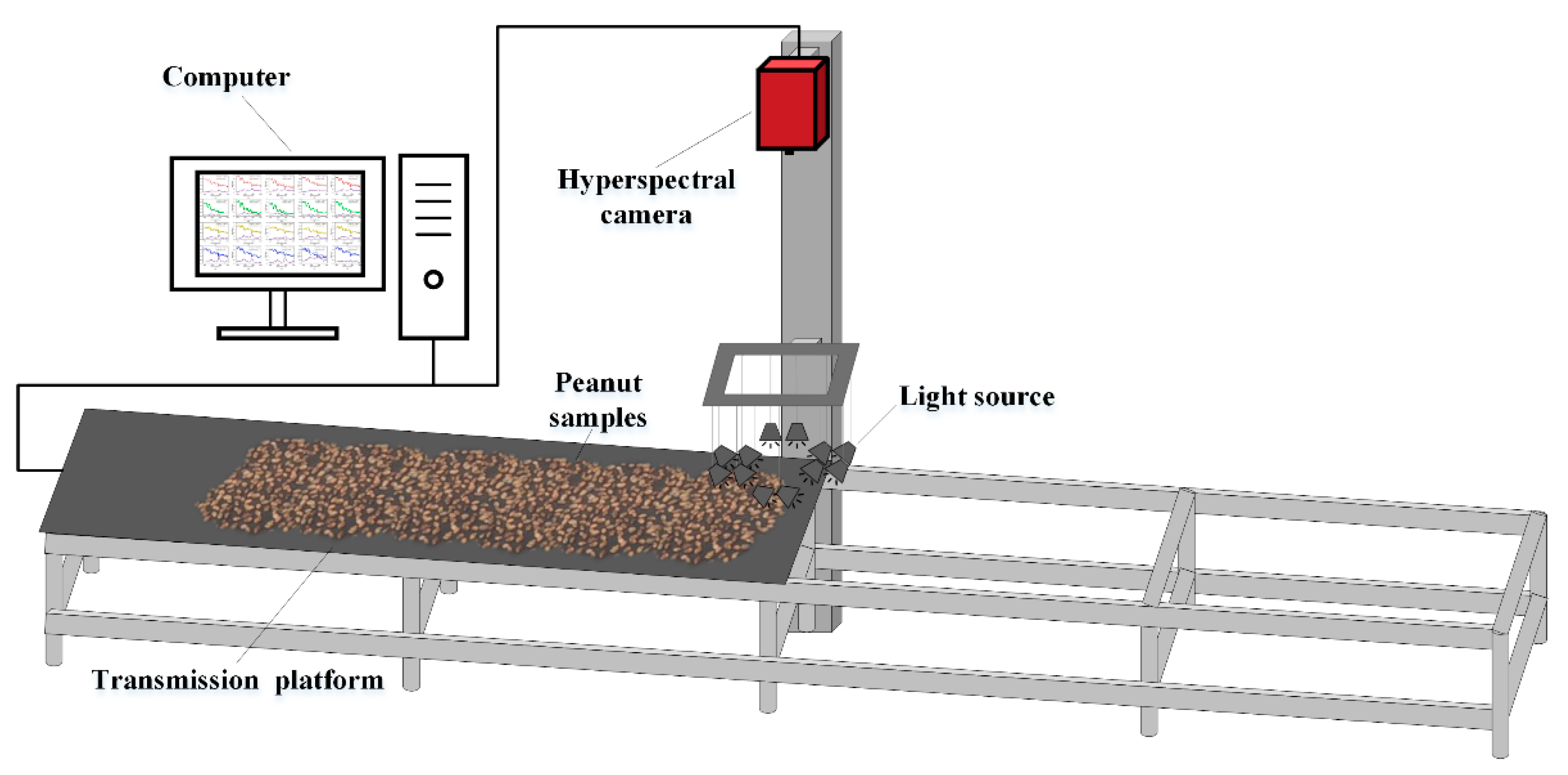
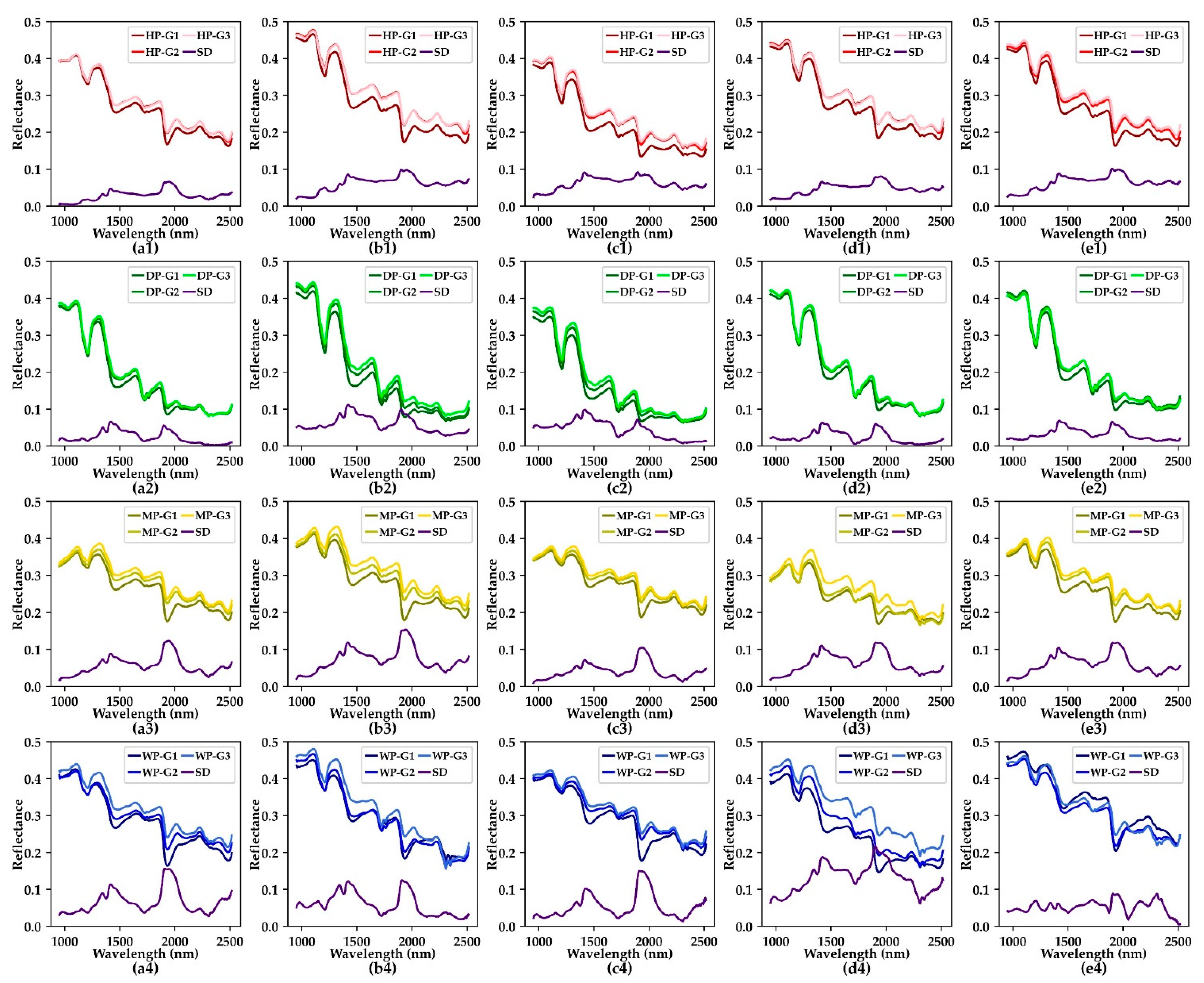
A hyperspectral image acquisition system was set up to collect the hyperspectral images of peanuts. The equipment schematic diagram is shown in
Figure 1. The spectrometer is HySpex SWIR-384 (Norsk Elektro Optikk AS, Norway) with the spectral range of 930–2500 nm. The spectral channel is 288 bands and the spectral sampling is 5.45 nm. The light source is composed of twelve halogen lamps (50 watts each). A strip whiteboard was placed at the beginning of the transmission platform for spectral reflection correction. During the scanning, the peanuts were placed on the transmission platform with a black background. The movement of the transmission platform was controlled by a computer, and the moving speed of the platform was the same as the scanning rate of the spectrometer.
According to the mildew period, peanut variety, and moisture content gradient, the corresponding hyperspectral images were obtained by the hyperspectral image acquisition system. The acquired data needs to be divided into a training set and a test set.
In the training set, for each variety, nine images of HP were collected with three images for each gradient. Six images of DP were collected with two images for each gradient. WP was the same as DP. Eighteen images of MP were collected with two images for each gradient and each period. A total of 195 images of the training set were obtained.
In the test set, for each variety, three mixed class images were collected for each variety and each period. In addition, three images of all varieties, classes, and gradients were collected. A total of 54 images were collected in the test set. Finally, a total of 249 images were obtained.
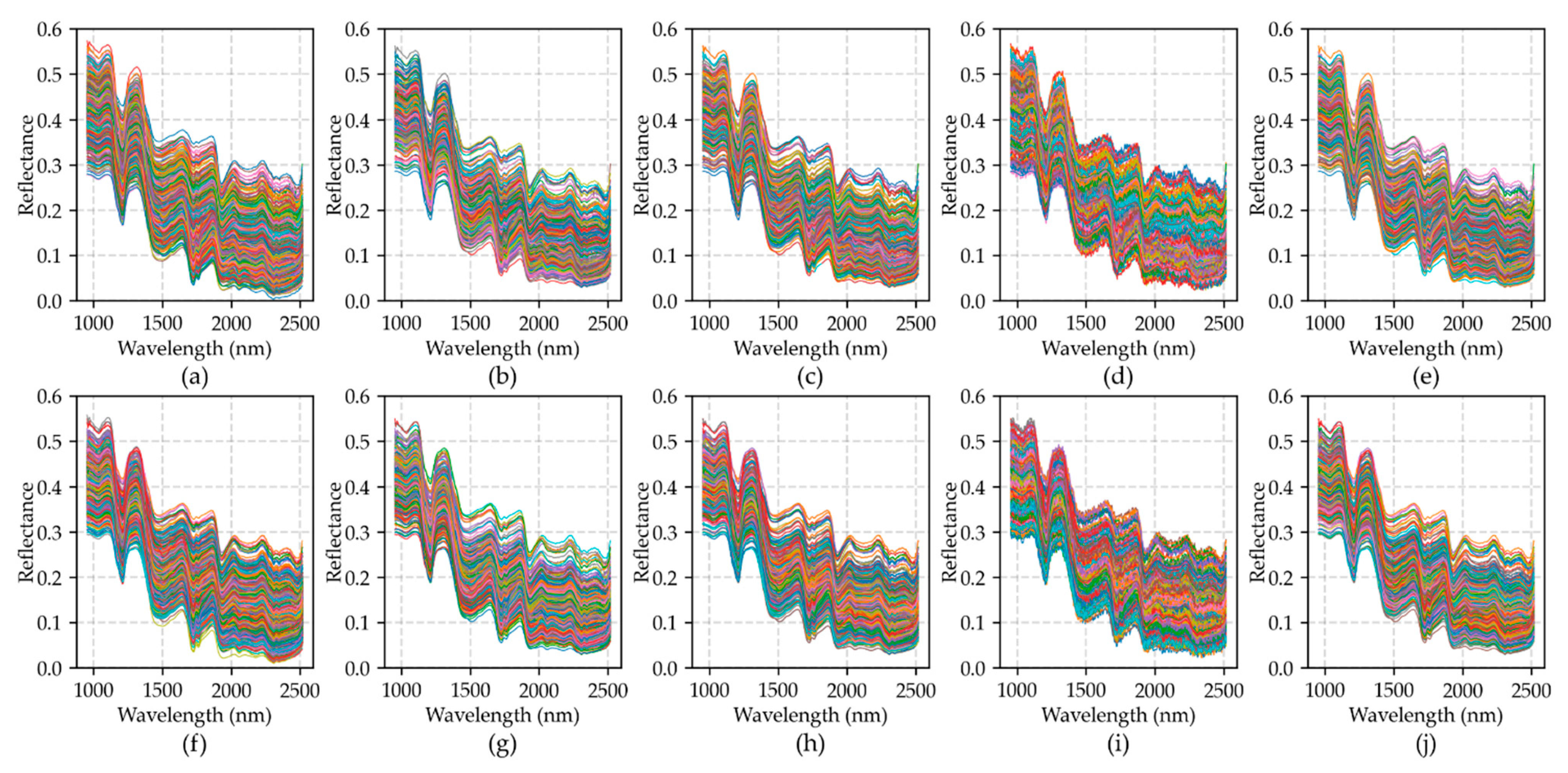
For each image, 162 peanuts were placed in the training set, 144 peanuts in the test set, and 120 peanuts in all varieties. Finally, a total number of 39,119 peanut kernels were obtained, including 7819 BLACK images, 7788 DBS images, 7820 QC images, 7869 SLH images, and 7823 XBS images.
The detailed data information is shown in
Table 1. Because the seed coat of healthy peanuts may fall off after baking, the category of healthy peanuts becomes damaged peanuts. In data processing, the peeled kernels in healthy peanuts were set as damaged samples. This did not occur in the samples of moldy peanuts and white moldy peanuts. The format of the obtained images was converted from digital number to radiance, and then a region of interest was selected in the white plate of the image for spectral correction. The correction formula is as follows:
where
is the corrected spectral reflectance,
is the original radiance,
is the spectral reflectance of dark plate, and
is the reflectance of white plate. Then the final reflectance data was obtained.
A feature band (1901 nm) was selected as the original mask for distinguishing peanut kernels and background. Firstly, the appropriate threshold was selected to distinguish the background and peanut kernels. The background pixels in the mask were set to 0, and the kernel pixels were set to different values according to the variety and class. Then, the noise and non-peanut pixel masks were set to zero by manual labeling. At the same time, a few adjacent kernels were also separated. All the hyperspectral images of peanut kernels were extracted by a watershed segmentation algorithm using a mask.
Because this paper used two types of the classification model, one was based on point spectral data, and another was based on hyperspectral image data. Therefore, for the method based on point spectrum, the average spectrum of each kernel was calculated as a training unit, and the corresponding label was set according to the type of peanut kernel. In this way, a peanut data set covering five varieties, four classes, three moisture content gradients, and two data types was completed.
2.3. Data Augmentation
2.3.1. Constructed Data Augmentation Method
To improve the identification accuracy of the classification model, a data augmentation method based on data interpolation was constructed. Compared with individual samples, the feature information of group samples may be more important. For the hyperspectral dataset
:
where
is the hyperspectral image cube of peanut kernels and
is the total number of samples.
Firstly, the average spectrum of each kernel was calculated, and the corresponding spectral dataset
was obtained.
where
is the average spectrum of each kernel,
is the number of peanut classes, and
are the sample number of each class of peanut. A feature band was selected to sort the sample reflectance values of each class. Then, the data of this class was divided into two parts with the median as the boundary, and the average spectrum of each part was calculated for generating the spectral difference
of the two parts. The
was used as the baseline of the original spectral offset. The generated spectral data
can be expressed as:
where
is a parameter used to adjust the offset of the original data. In this way, the data was interpolated by offsetting the original spectrum.
For kernel hyperspectral image data, the augmented data
can be expressed as:
The image rotation was added on the basis of spectral shift. Moreover, the maximum and minimum values of the reflectance of the extended data generally exceed the original reflectance. That is, it will produce some outliers. These outliers can fill the missing moisture content gradient data to some extent and increase the robustness of the model. In this way, the purpose of improving the generalization ability of the model was achieved. This method expanded the data through the difference in the spectral mean, so it was named the DSM method.
2.3.2. Compared Data Augmentation Methods
Some data augmentation methods showed good results in the original paper, but they were not suitable for the experimental data and subjects of this study. Therefore, according to the characteristics of peanut hyperspectral data, the commonly used methods and frontier methods were compared to verify their effects.
Specifically, the principle of the original random erasing method [
41] was to randomly erase a small rectangular area in the image. For the point spectral data, we modified it to randomly mask the spectrum of 10 bands, that is, randomly set 10 continuous bands to zero. In the random noise method, a random noise of [−0.01, 0.01] of the same length as the spectral data was added to the original spectrum to generate new data. The original Mixup method fused two images by weight to generate new data. Due to the point, spectral data does not contain texture information, it cannot be directly used in point spectral data. Here, we extended the implementation of this method to the weighted summation of two spectra and called it the two sample weighting (TSW) method. The formula is as follows:
where
are two spectral samples,
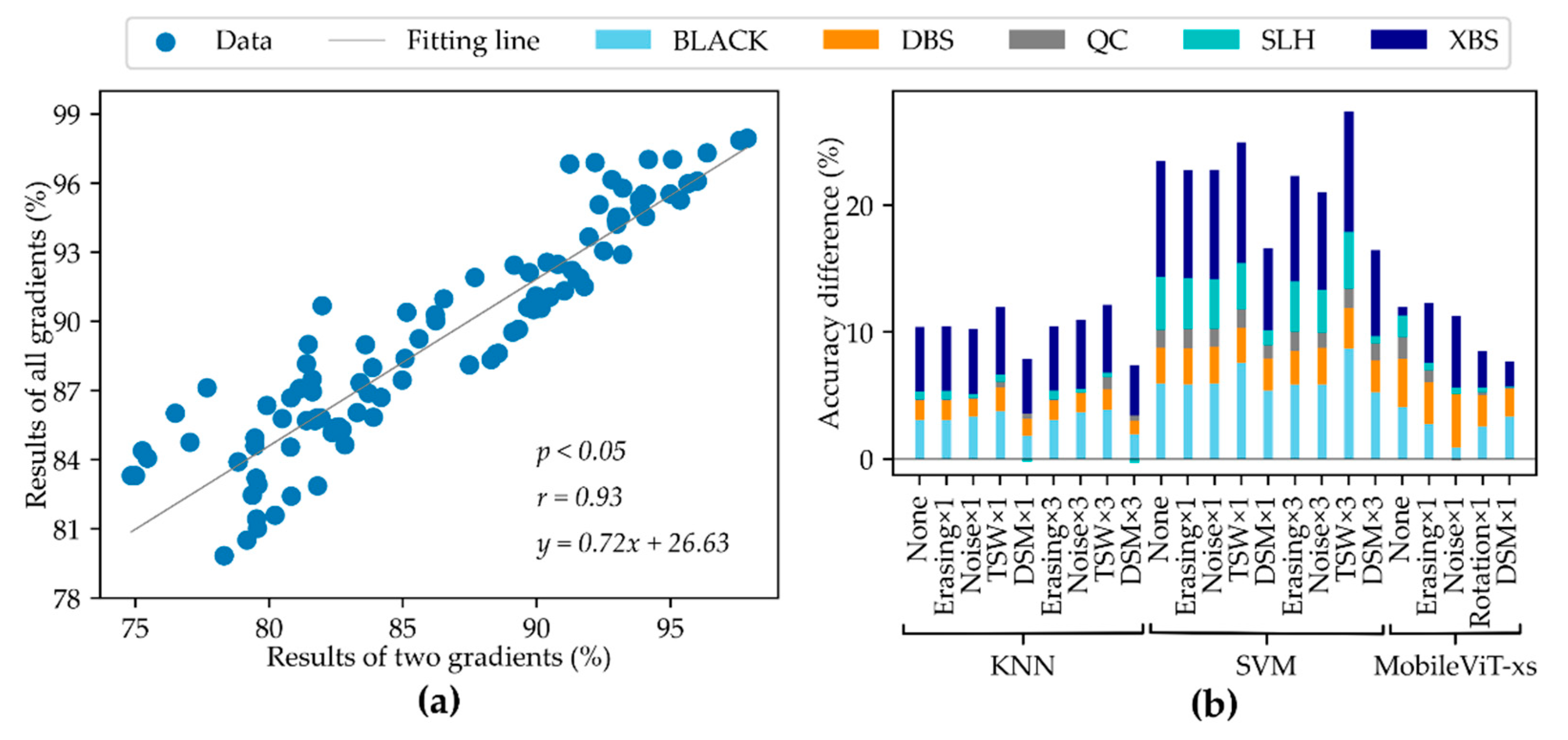
. On the whole, for the classification methods based on spectrum, the original data (None), random erasing (Erasing), random noise (Noise), TSW, and DSM were compared.
For the image-based classification method, the original data (None), random erasing (Erasing), random noise (Noise), rotation (Rotation), and DSM were compared. TSW method was not adopted for the reason that the texture information of the data will be destroyed and the generated data lacks interpretation. Similarly, a random erase area of was set in the random erasing method. In the random noise method, the random noise between [−0.01, 0.01] of the same shape as the hyperspectral image cube was generated. Then, it was added to the original spectral cube to get the augmented data. In the rotation method, under twice the sample size, the original image was rotated 90 degrees clockwise to generate augmented data. Under four times the sample size, the rotation of 90 degrees, 180 degrees, and 270 degrees was set.
2.4. Classification Model
Three classification models, KNN [
45], SVM [
46] and MobileViT [
47], were used for classification. Among them, KNN and SVM are classical pixel-based classifiers, which are widely used in classification research. The basic principle of the KNN algorithm is to judge the class of the input sample according to the class of the K points closest to the input sample. It is a supervised classification model that runs fast under a large amount of data. The training time of KNN is short, and it is not sensitive to abnormal values. The gradient data that do not participate in the training will contain many abnormal values. Given this feature, KNN was selected for classification.
The basic principle of SVM is to find a hyperplane in the feature space that can separate all data samples and minimize the distance between the data in the training set and the hyperplane. It is one of the most widely used classifiers. In many classification tasks, there is often a case of linear inseparability. Therefore, SVM based on kernel functions such as radial basis function, n-order polynomials, and sigmoid is used to solve this problem. The kernel function used in this paper is the radial basis function.
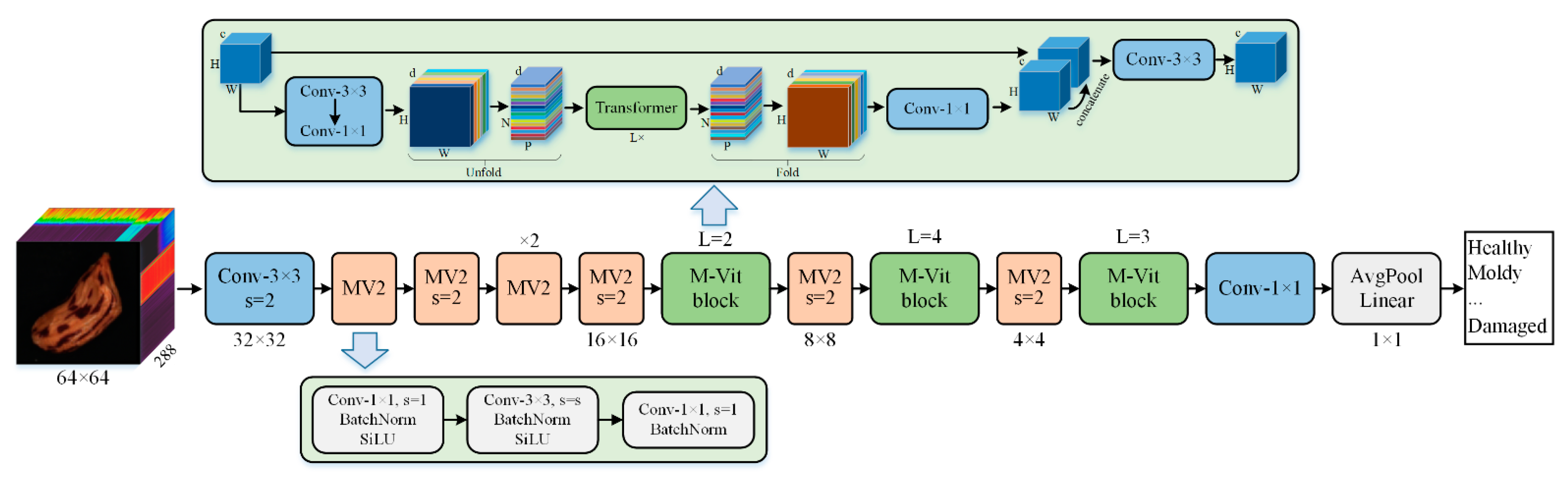
MobileViT is a lightweight deep learning model based on a transformer [
48], which shows good performance in image classification, semantic segmentation, and object detection. The model includes three architectures, namely, MobileViT-s, MobileViT-xs, and MobileViT-xxs, with different numbers of parameters. According to the results of the original research, MobileViT-xs was selected as the classification model of this study by weighing the parameters and accuracy. The model structure is shown in
Figure 2. The model is mainly composed of the MobileNetv2 block and MobileViT block, and the detailed description of the model can refer to the original literature [
47].
2.5. Statistical Analysis and Experimental platform
Pearson correlation coefficient was used to determine the relationship between two gradient results and all gradient results. The SciPy package in Python was used to calculate the Pearson correlation coefficient, where the parameters and reflect the significance level and correlation, respectively. Significant differences were considered when . The positive or negative value of reflected the positive or negative correlation. Difference analysis was used to analyze the differences of different gradient results, as well as to analyze the effect of data augmentation methods.
All the experiments were run on Intel Core i7-12700 (2.10 GHz), 64GB RAM and NVIDIA RTX3060 GPU with 12 GB memory. Python 3.7.1 was used to implement all program code. The functions in the Sckit-learn package were used to realize the KNN and SVM algorithms. The MobileViT-xs model was implemented by the deep learning framework PyTorch 1.10, and CUDA Toolkit 11.3 was used to accelerate the processing. More code details were posted at
https://github.com/mepleleo/DA_peanut (accessed on 1 April 2022).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}