Imaging through a Scattering Medium under Different Intensities of Ambient Light Interference


Abstract
:1. Introduction
2. Principles and Methods
2.1. Physical Principles
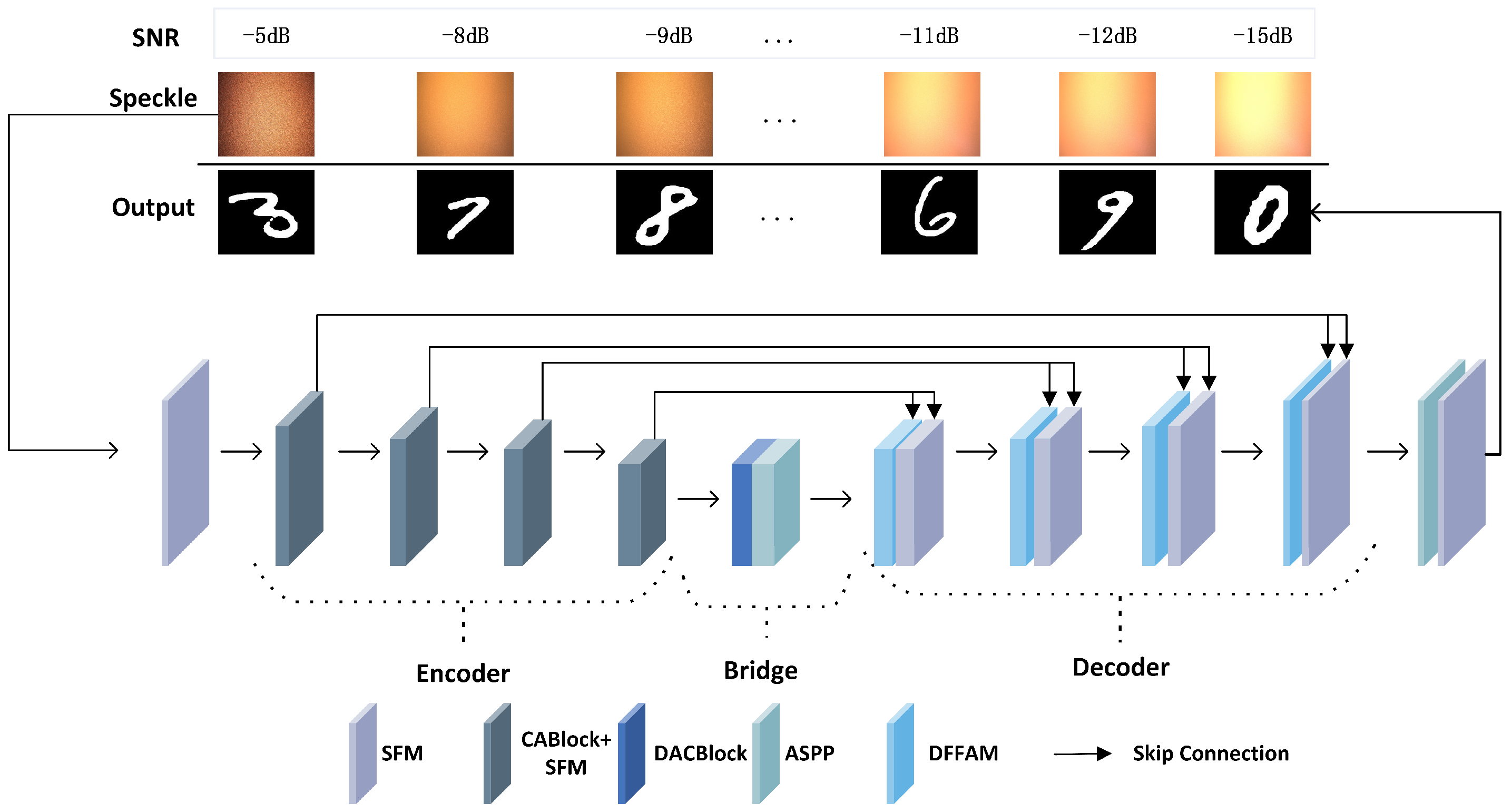
2.2. Module Design and Network Framework
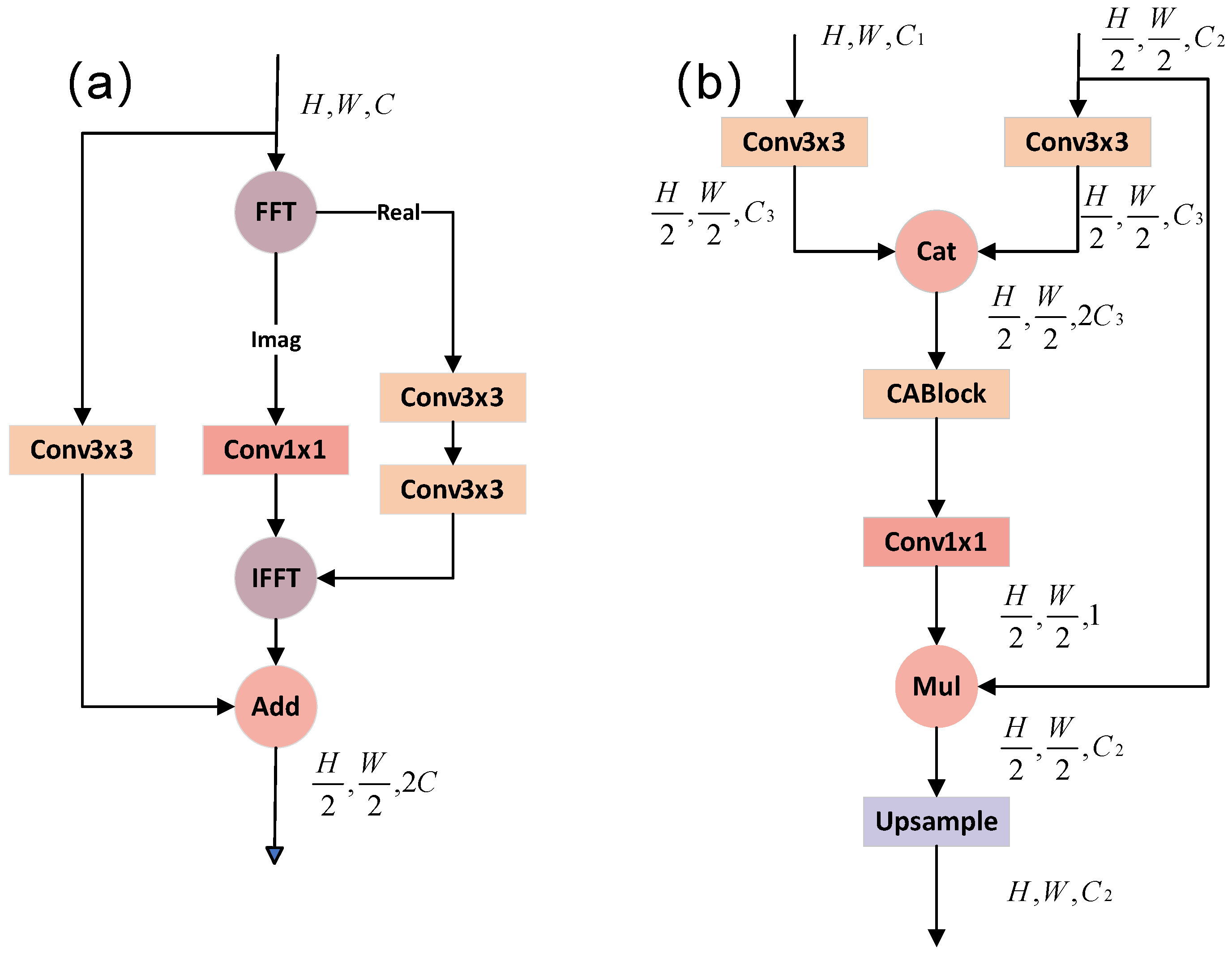
2.2.1. SFM and DFFAM
2.2.2. Model Design
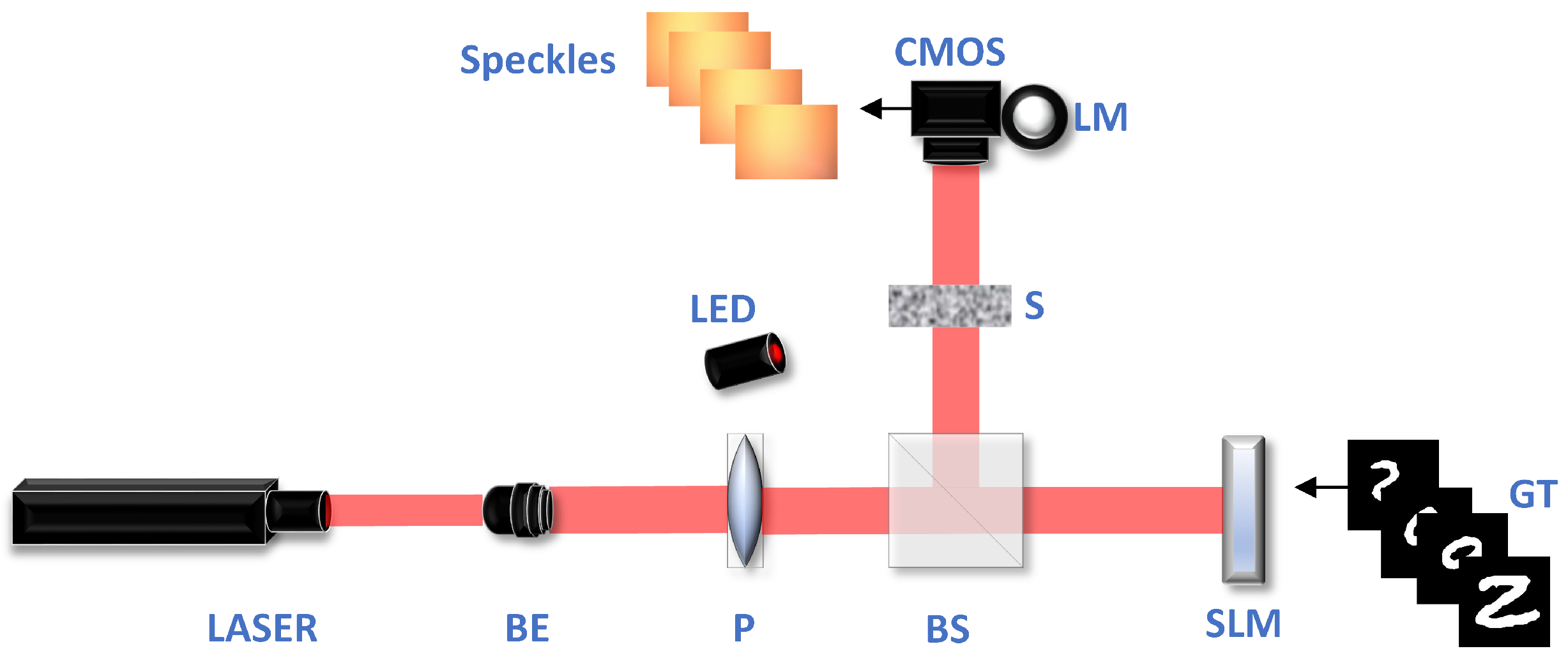
2.3. Measurement System
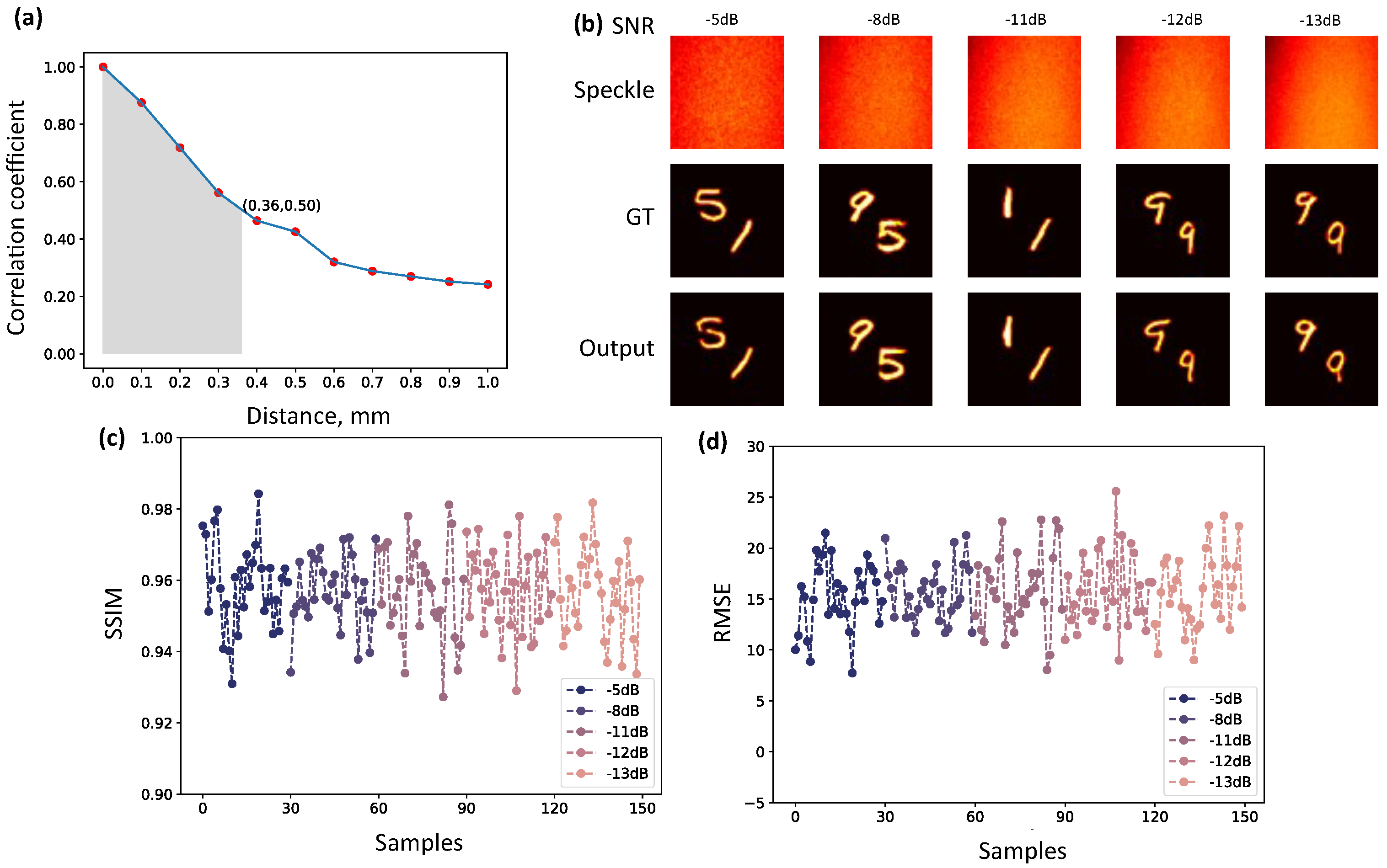
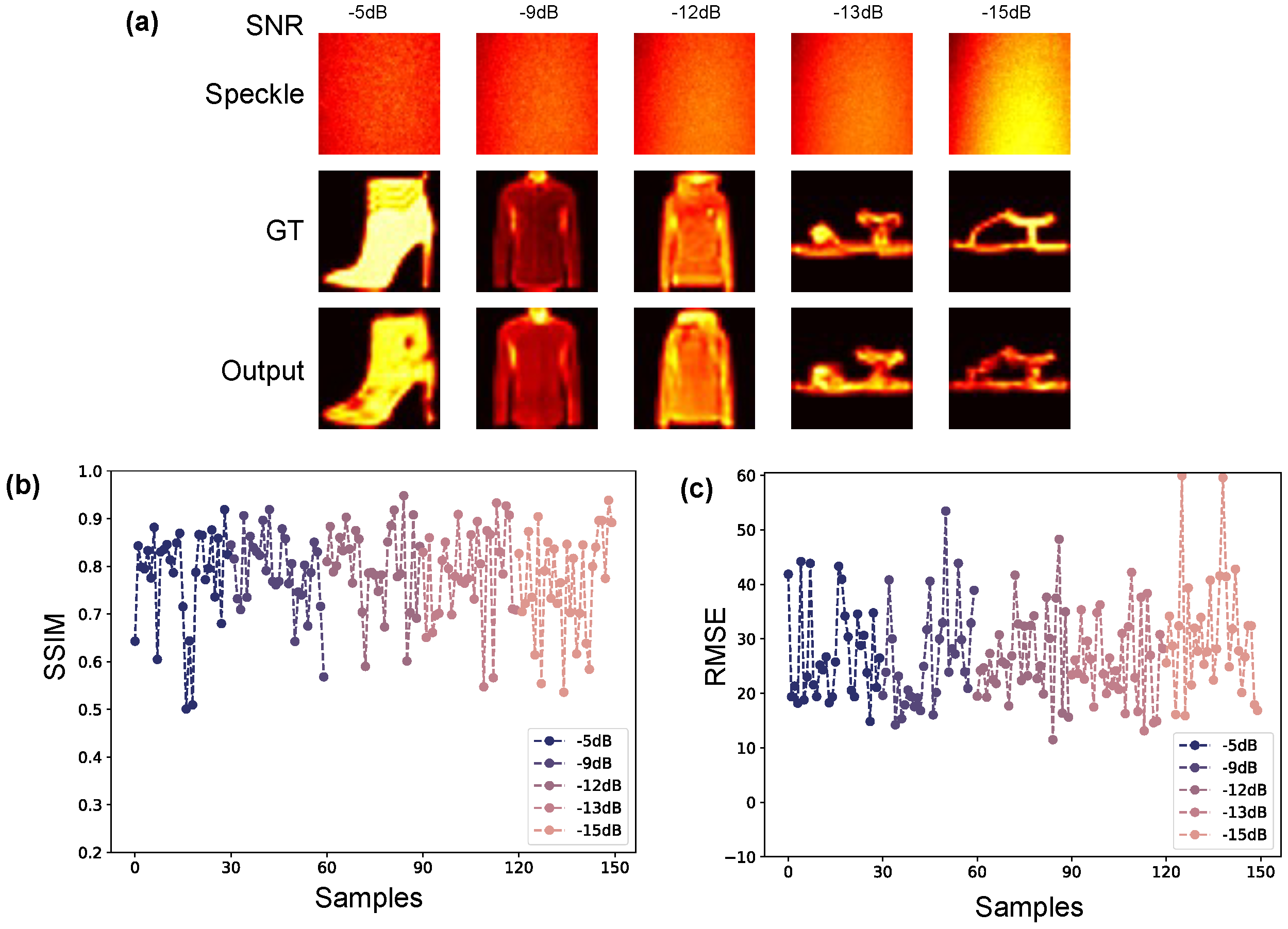
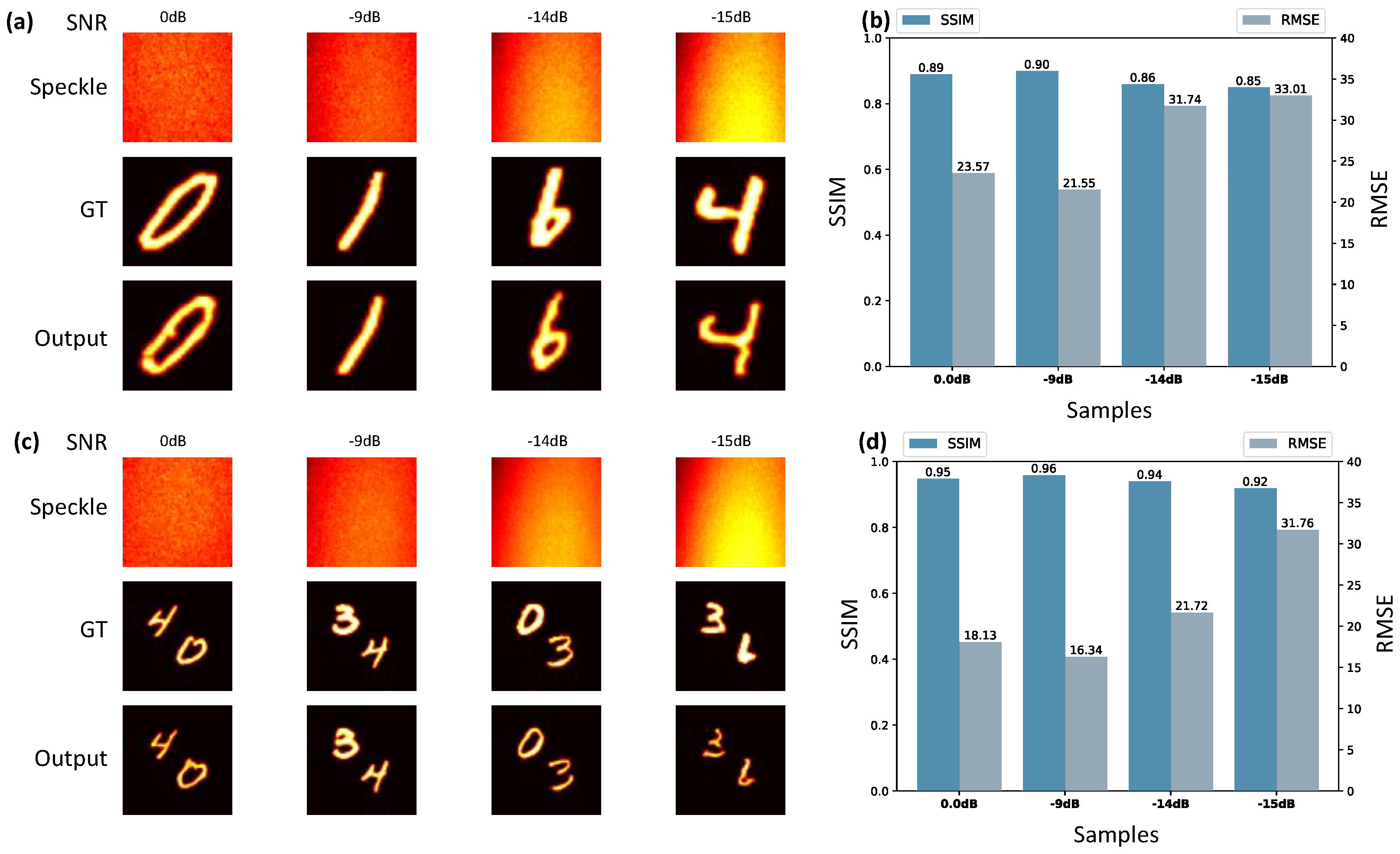
3. Results and Discussion
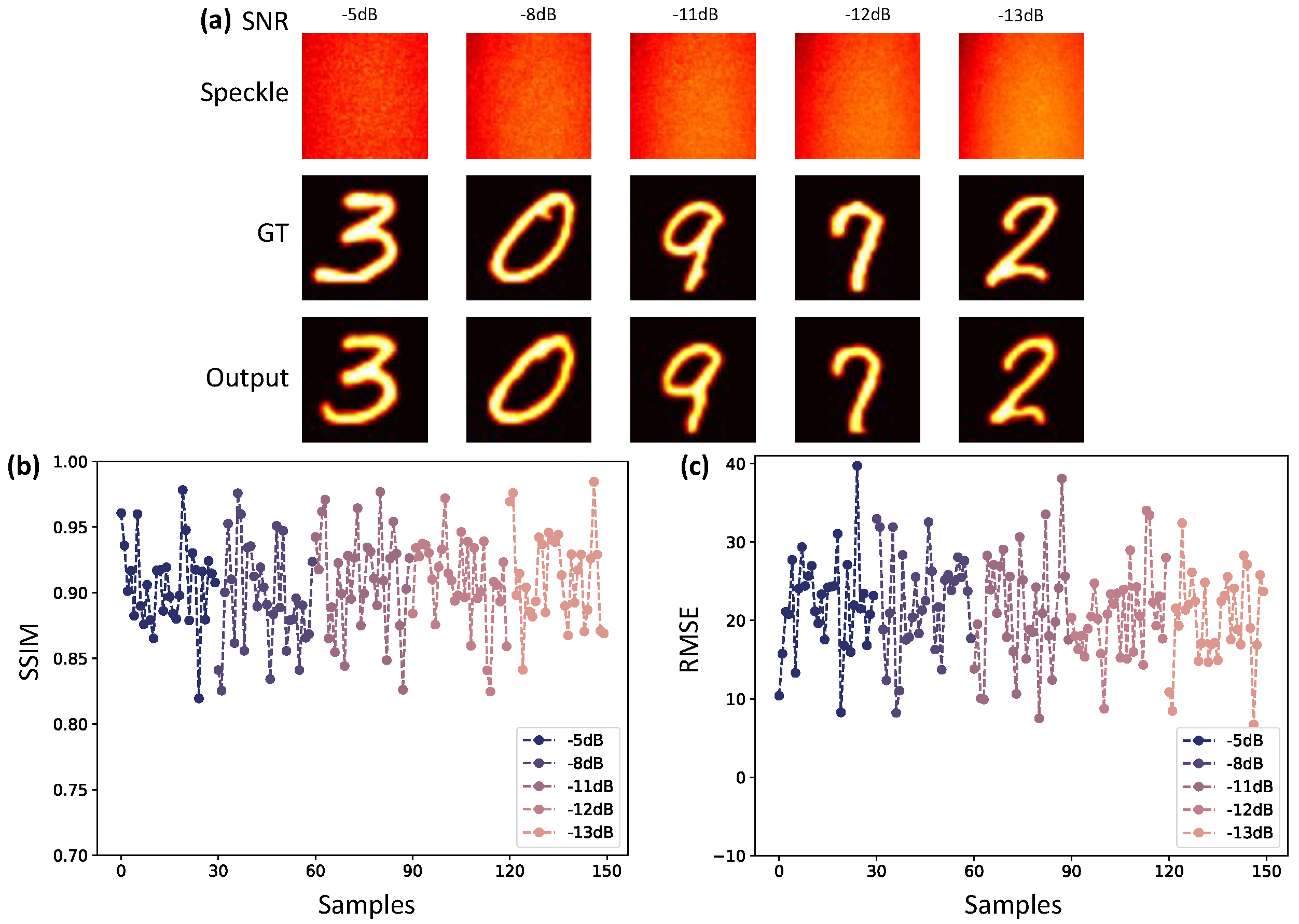
3.1. Imaging Recovery under Different Interference Intensities
3.2. Complex Target Imaging under Different Interference Intensities
3.3. Network Robustness and Generalization
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Galaktionov, I.; Nikitin, A.; Samarkin, V.; Sheldakova, J.; Kudryashov, A.V. Laser beam focusing through the scattering medium-low order aberration correction approach. In Unconventional and Indirect Imaging, Image Reconstruction, and Wavefront Sensing; SPIE: San Diego, CA, USA, 2018; Volume 10772, pp. 259–272. [Google Scholar] [CrossRef]
- Katz, O.; Small, E.; Silberberg, Y. Looking around Corners and through Thin Turbid Layers in Real Time with Scattered Incoherent Light. Nat. Photonics 2012, 6, 549–553. [Google Scholar] [CrossRef]
- Paudel, H.P.; Stockbridge, C.; Mertz, J.; Bifano, T. Focusing polychromatic light through scattering media. In Mems Adaptive Optics VII; SPIE: San Diego, CA, USA, 2013; Volume 8617, pp. 82–88. [Google Scholar] [CrossRef]
- Popoff, S.M.; Lerosey, G.; Carminati, R.; Fink, M.; Boccara, A.C.; Gigan, S. Measuring the Transmission Matrix in Optics: An Approach to the Study and Control of Light Propagation in Disordered Media. Phys. Rev. Lett. 2010, 104, 100601. [Google Scholar] [CrossRef] [PubMed]
- Tripathi, S.; Paxman, R.; Bifano, T.; Toussaint, K.C. Vector Transmission Matrix for the Polarization Behavior of Light Propagation in Highly Scattering Media. Opt. Express 2012, 20, 16067–16076. [Google Scholar] [CrossRef] [PubMed]
- Bertolotti, J.; Van Putten, E.G.; Blum, C.; Lagendijk, A.; Vos, W.L.; Mosk, A.P. Non-Invasive Imaging through Opaque Scattering Layers. Nature 2012, 491, 232–234. [Google Scholar] [CrossRef] [PubMed]
- Lu, D.; Feng, Y.; Peng, X.; He, W. Speckle Autocorrelation Separation for Multi-Target Scattering Imaging. Opt. Express 2023, 31, 6529–6539. [Google Scholar] [CrossRef]
- Matthews, T.E.; Medina, M.; Maher, J.R.; Levinson, H.; Brown, W.J.; Wax, A. Deep tissue imaging using spectroscopic analysis of multiply scattered light. Optica 2014, 1, 105–111. [Google Scholar] [CrossRef]
- Pfeiffer, N.; Chapman, G.H.; Kaminska, B. Optical imaging of structures within highly scattering material using an incoherent beam and a spatial filter. In Optical Interactions with Tissues and Cells XXI; SPIE: San Diego, CA, USA, 2010; Volume 7562, pp. 33–43. [Google Scholar] [CrossRef]
- Li, W.; Xi, T.; He, S.; Liu, L.; Liu, J.; Liu, F.; Wang, B.; Wei, S.; Liang, W.; Fan, Z. Single-Shot Imaging through Scattering Media under Strong Ambient Light Interference. Opt. Lett. 2021, 46, 4538–4541. [Google Scholar] [CrossRef]
- Niu, Y.; Gao, Z.; Zhao, J.; Deng, L.; Sa, Y.; Wang, S. An Improving Method of Imaging through Scattering Medium under Strong Background Illumination. Measurement 2023, 210, 112548. [Google Scholar] [CrossRef]
- Ma, K.; Wang, X.; He, S.; Li, L. Plug-and-Play Algorithm for Imaging through Scattering Media under Ambient Light Interference. Opt. Lett. 2023, 48, 1754–1757. [Google Scholar] [CrossRef]
- Cheng, Q.; Guo, E.; Gu, J.; Bai, L.; Han, J.; Zheng, D. De-Noising Imaging through Diffusers with Autocorrelation. Appl. Opt. 2021, 60, 7686–7695. [Google Scholar] [CrossRef]
- Lin, H.; Huang, C.; He, Z.; Zeng, J.; Chen, F.; Yu, C.; Li, Y.; Zhang, Y.; Chen, H.; Pu, J. Phase Imaging through Scattering Media Using Incoherent Light Source. Photonics 2023, 10, 792. [Google Scholar] [CrossRef]
- Li, W.; Abrashitova, K.; Osnabrugge, G.; Amitonova, L.V. Generative Adversarial Network for Superresolution Imaging through a Fiber. Phys. Rev. Appl. 2022, 18, 034075. [Google Scholar] [CrossRef]
- Lin, B.; Fan, X.; Li, D.; Guo, Z. High-Performance Polarization Imaging Reconstruction in Scattering System under Natural Light Conditions with an Improved U-Net. Photonics 2023, 10, 204. [Google Scholar] [CrossRef]
- Katz, O.; Heidmann, P.; Fink, M.; Gigan, S. Non-invasive single-shot imaging through scattering layers and around corners via speckle correlations. Nat. Photonics 2014, 8, 784–790. [Google Scholar] [CrossRef]
- Fienup, J.R. Phase Retrieval Algorithms: A Personal Tour [Invited]. Appl. Opt. 2013, 52, 45. [Google Scholar] [CrossRef] [PubMed]
- Fienup, J.R. Phase Retrieval Algorithms: A Comparison. Appl. Opt. 1982, 21, 2758–2769. [Google Scholar] [CrossRef]
- Chang, J.; Wetzstein, G. Single-Shot Speckle Correlation Fluorescence Microscopy in Thick Scattering Tissue with Image Reconstruction Priors. J. Biophotonics 2018, 11, e201700224. [Google Scholar] [CrossRef] [PubMed]
- Schniter, P.; Rangan, S. Compressive Phase Retrieval via Generalized Approximate Message Passing. IEEE Trans. Signal Process. 2015, 63, 1043–1055. [Google Scholar] [CrossRef]
- Goodman, J.W. Speckle Phenomena in Optics: Theory and Applications; Roberts and Company Publishers: Greenwood Village, CO, USA, 2007. [Google Scholar]
- Ma, R.; Wang, Z.; Manuylovich, E.; Zhang, W.L.; Zhang, Y.; Zhu, H.Y.; Liu, J.; Fan, D.Y.; Rao, Y.J.; Gomes, A.S. Highly coherent illumination for imaging through opacity. Opt. Lasers Eng. 2022, 149, 106796. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13713–13722. [Google Scholar] [CrossRef]
- Zhu, S.; Guo, E.; Gu, J.; Cui, Q.; Zhou, C.; Bai, L.; Han, J. Efficient Color Imaging through Unknown Opaque Scattering Layers via Physics-Aware Learning. Opt. Express 2021, 29, 40024–40037. [Google Scholar] [CrossRef] [PubMed]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. Ce-Net: Context Encoder Network for 2d Medical Image Segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected Crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Skarsoulis, K.; Kakkava, E.; Psaltis, D. Predicting Optical Transmission through Complex Scattering Media from Reflection Patterns with Deep Neural Networks. Opt. Commun. 2021, 492, 126968. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A Nested u-Net Architecture for Medical Image Segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Johansen, D.; De Lange, T.; Halvorsen, P.; Johansen, H.D. Resunet++: An Advanced Architecture for Medical Image Segmentation. In Proceedings of the 2019 IEEE International Symposium on Multimedia (ISM), San Diego, CA, USA, 9–11 December 2019; pp. 225–2255. [Google Scholar] [CrossRef]
- Tang, D.; Sahoo, S.K.; Tran, V.; Dang, C. Single-shot large field of view imaging with scattering media by spatial demultiplexing. Appl. Opt. 2018, 57, 7533–7538. [Google Scholar] [CrossRef] [PubMed]
- Guo, E.; Zhu, S.; Sun, Y.; Bai, L.; Zuo, C.; Han, J. Learning-Based Method to Reconstruct Complex Targets through Scattering Medium beyond the Memory Effect. Opt. Express 2020, 28, 2433–2446. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Jin, X.; Li, J.; Lian, X.; Ji, X.; Dai, Q. Prior-information-free single-shot scattering imaging beyond the memory effect. Opt. Lett. 2019, 44, 1423–1426. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Huang, H.; Wu, F.; Han, J.; Yang, Y.; Li, R. Imaging through a Scattering Medium under Different Intensities of Ambient Light Interference. Photonics 2023, 10, 1023. https://doi.org/10.3390/photonics10091023
Zhang Y, Huang H, Wu F, Han J, Yang Y, Li R. Imaging through a Scattering Medium under Different Intensities of Ambient Light Interference. Photonics. 2023; 10(9):1023. https://doi.org/10.3390/photonics10091023
Chicago/Turabian StyleZhang, Yantong, Huiling Huang, Feibin Wu, Jun Han, Yi Yang, and Ruyi Li. 2023. "Imaging through a Scattering Medium under Different Intensities of Ambient Light Interference" Photonics 10, no. 9: 1023. https://doi.org/10.3390/photonics10091023